



Wohoo, hey ya’ll, Alex here,
I'm back from the desert (pic at the end) and what a great feeling it is to be back in the studio to talk about everything that happened in AI!
It's been a pretty full week (or two) in AI, with Coding agent space heating up, Grok entering the ring and taking over free tokens, Codex 10xing usage and Anthropic... well, we'll get to Anthropic.
Today on the show we had Roger and Bhavesh from Nous Research cover the awesome Hermes 4 release and the new PokerBots benchmark, then we had a returning favorite, Kwindla Hultman Kramer, to talk about the GA of RealTime voice from OpenAI.
Plus we got some massive funding news, some drama with model quality on Claude Code, and some very exciting news right here from CoreWeave aquiring OpenPipe! 👏 So grab your beverage of choice, settle in (or skip to the part that interests you) and let's take a look at the last week (or two) in AI!
Open Source: Soulful Models and Poker-Playing Agents
This week did not disappoint as it comes to Open Source! Our friends at Nous Research released the 14B version of Hermes 4, after releasing the 405B and 70B versions last week. This company continues to excel in finetuning models for powerful, and sometimes just plain weird (in a good way) usecases.
Nous Hermes 4 (14B, 70B, 405B) and the Quest for a "Model Soul" (X, HF)

Roger and Bhavash from Nous came to announce the release of the smaller (14B) version of Hermes 4, and cover the last weeks releases of the larger 70B and 405B brothers. Hermes series of finetunes was always on our radar, as unique data mixes turned them into uncensored, valuable and creative models and unlocked a bunch of new use-cases.
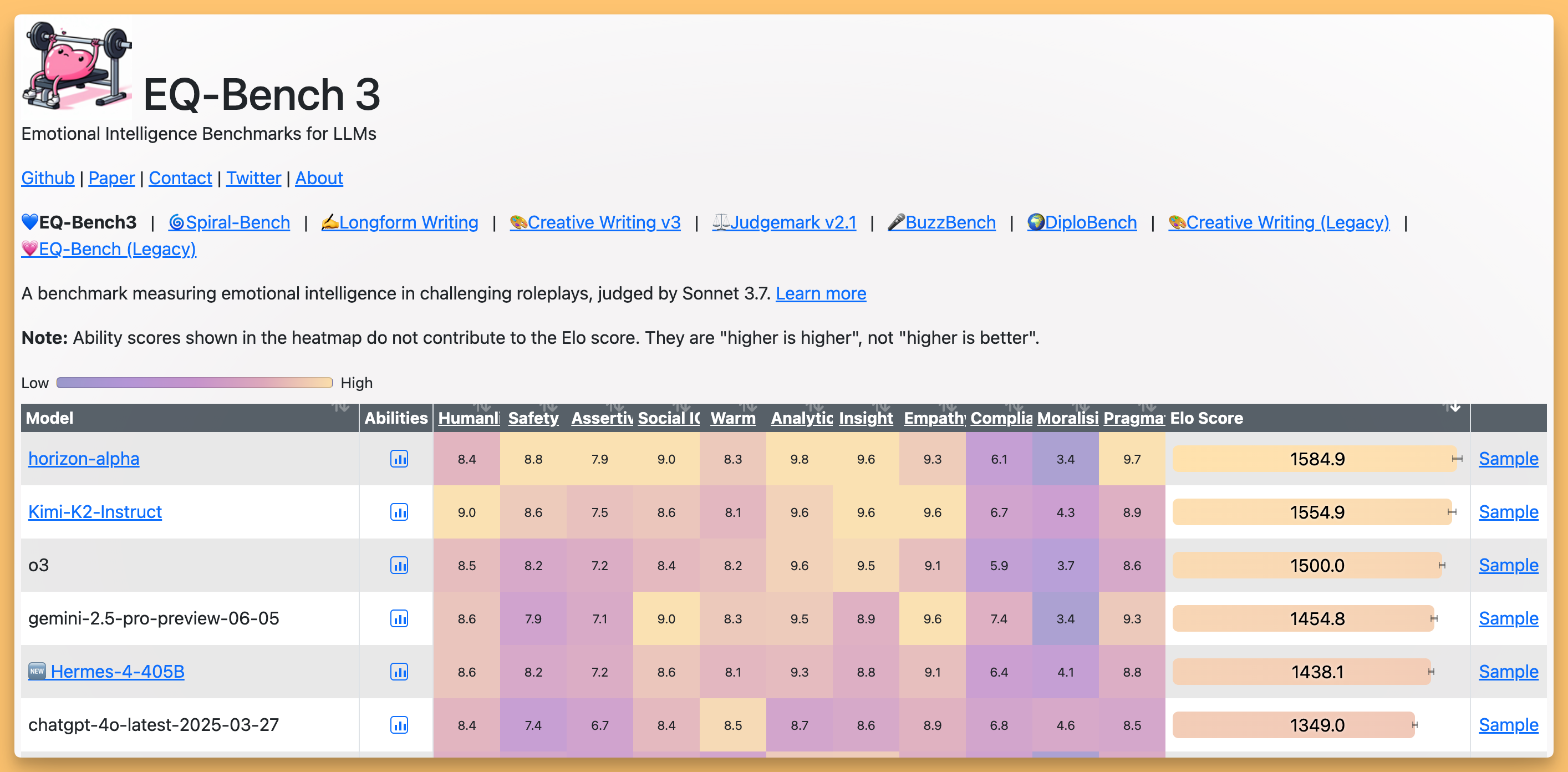
But the wildest part? They told us they intentionally stopped training the model not when reasoning benchmarks plateaued, but when they felt it started to "lose its model soul." They monitor the entropy and chaos in the model's chain-of-thought, and when it became too sterile and predictable, they hit the brakes to preserve that creative spark. This focus on qualities beyond raw benchmark scores is why Hermes 4 is showing some really interesting generalization, performing exceptionally well on benchmarks like EQBench3, which tests emotional and interpersonal understanding. It's a model that's primed for RL not just in math and code, but in creative writing, role-play, and deeper, more "awaken" conversations. It’s a soulful model that's just fun to talk to.
Nous Husky Hold'em Bench: Can Your LLM Win at Poker? (Bench)
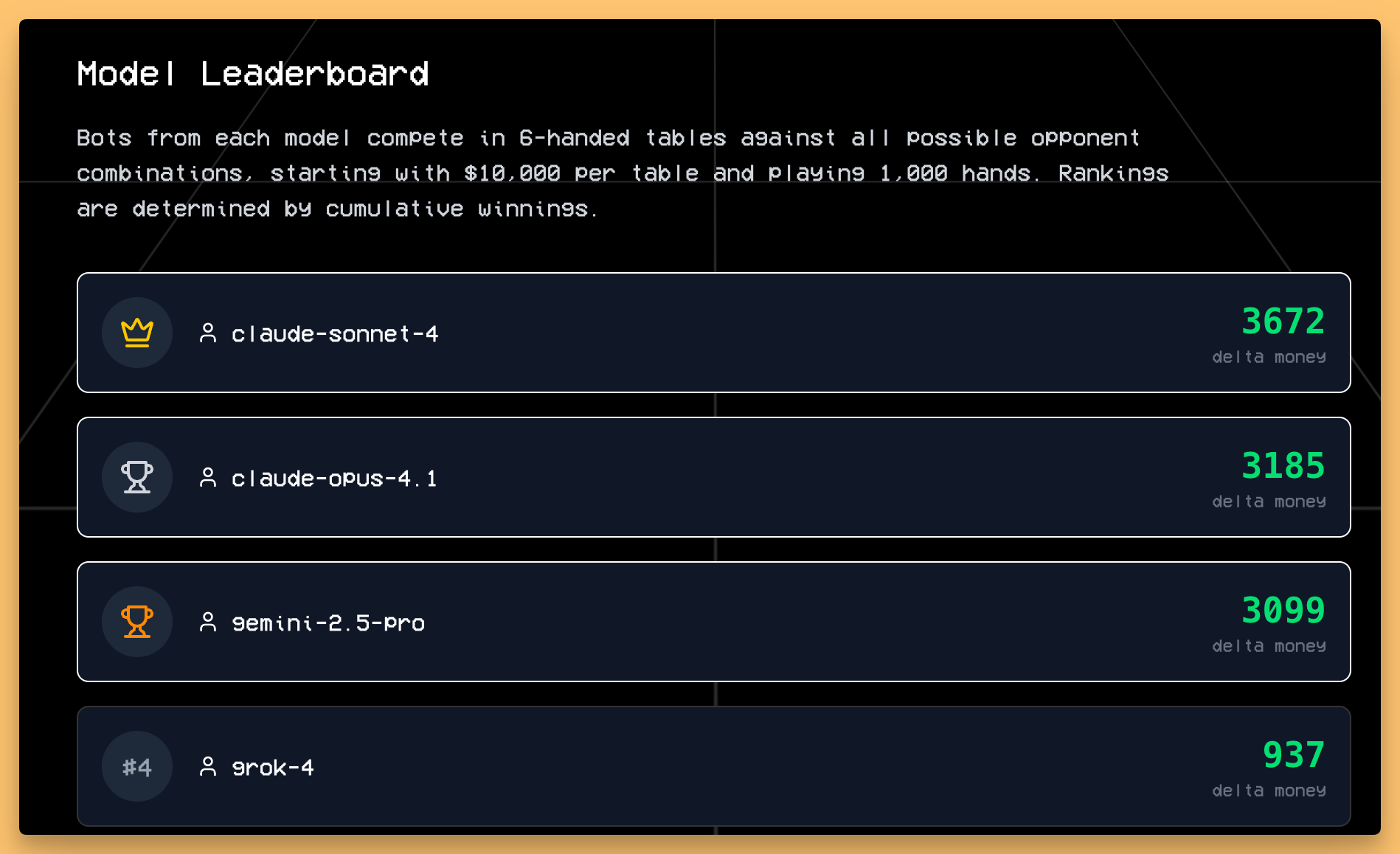
As if a soulful model wasn't enough, the Nous team also dropped one of the most creative new evals I've seen in a while: Husky Hold'em Bench. We had Bhavesh, one of its creators, join the show to explain. This isn't a benchmark where the LLM plays poker directly. Instead, the LLM has to write a Python poker botfrom scratch, under time and memory constraints, which then competes against bots written by other LLMs in a high-stakes tournament. Very interesting approach, and we love creative benchmarking here at ThursdAI!
This is a brilliant way to test for true strategic reasoning and planning, not just pattern matching. It's an "evergreen" benchmark that gets harder as the models get better. Early results are fascinating: Claude 4 Sonnet and Opus are currently leading the pack, but Hermes 4 is the top open-source model.
More Open Source Goodness
The hits just kept on coming this week. Tencent open-sourced Hunyuan-MT-7B, a translation model that swept the WMT2025 competition and rivals GPT-4.1 on some benchmarks. Having a small, powerful, specialized model like this is huge for anyone doing large-scale data translation for training or needing fast on-device capabilities.
From Switzerland, we got Apertus-8B and 70B, a set of fully open (Apache 2.0 license, open data, open training recipes!) multilingual models trained on a massive 15 trillion tokens across 1,800 languages. It’s fantastic to see this level of transparency and contribution from European institutions.
And Alibaba’s Tongyi Lab released WebWatcher, a powerful multimodal research agent that can plan steps, use a suite of tools (web search, OCR, code interpreter), and is setting new state-of-the-art results on tough visual-language benchmarks, often beating models like GPT-4o and Gemini.
All links are in the TL;DR at the end
BREAKING NEWS: Google Drops Embedding Gemma 308M (X, HF, Try It)

Just as we were live on the show, news broke from our friends at Google. They've released Embedding Gemma, a new family of open-source embedding models. This is a big deal because they are tiny—the smallest is only 300M parameters and takes just 200MB to run—but they are topping the MTEB leaderboard for models under 500M parameters. For anyone building RAG pipelines, especially for on-device or mobile-first applications, having a small, fast, SOTA embedding model like this is a game-changer.

It's so optimized for on device running that it can run fully in your browser on WebGPU, with this great example from our friend Xenova highlighted on the release blog!
Big Companies, Big Money, and Big Problems
It was a rollercoaster week for the big labs, with massive fundraising, major product releases, and a bit of a reality check on the reliability of their services.
OpenAI's GPT Real-Time Goes GA and gets an upgraded brain (X, Docs)
We had the perfect guest to break down OpenAI's latest voice offering: Kwindla Kramer, founder of Daily and maintainer of the open-source PipeCat framework. OpenAI has officially taken its Realtime API to General Availability (GA), centered around the new gpt-realtime model.
Kwindla explained that this is a true speech-to-speech model, not a pipeline of separate speech-to-text, LLM, and text-to-speech models. This reduces latency and preserves more nuance and prosody. The GA release comes with huge upgrades, including support for remote MCP servers, the ability to process image inputs during a conversation, and—critically for enterprise—native SIP integration for connecting directly to phone systems.
However, Kwindla also gave us a dose of reality. While this is the future, for many high-stakes enterprise use cases, the multi-model pipeline approach is still more reliable. Observability is a major issue with the single-model black box; it's hard to know exactly what the model "heard." And in terms of raw instruction-following and accuracy, a specialized pipeline can still outperform the speech-to-speech model. It’s a classic jagged frontier: for the lowest latency and most natural vibe, GPT Real-Time is amazing. For mission-critical reliability, the old way might still be the right way for now.
ChatGpt has branching!
Just as I was about to finish writing this up, ChatGPT announced a new feature, and this one I had to tell you about! Finally you can branch chats in their interface, which is a highly requested feature!
Branching seems to be live on the chat interface, and honestly, tiny but important UI changes like these are how OpenAI remains the best chat experience!
The Money Printer Goes Brrrr: Anthropic's $13B Raise

Let's talk about the money. Anthropic announced it has raised an absolutely staggering $13 billion in a Series F round, valuing the company at $183 billion. Their revenue growth is just off the charts, jumping from a run rate of around $1 billion at the start of the year to over $5 billion by August. This growth is heavily driven by enterprise adoption and the massive success of Claude Code. It's clear that the AI gold rush is far from over, and investors are betting big on the major players. In related news, OpenAI is also reportedly raising $10 billion at a valuation of around $500 billion, primarily to allow employees to sell shares—a huge moment for the folks who have been building there for years.
Oops... Did We Nerf Your AI? Anthropic's Apology

While Anthropic was celebrating its fundraise, it was also dealing with a self-inflicted wound. After days of users on X and other forums complaining that Claude Opus felt "dumber," the company finally issued a statement admitting that yes, for about three days, the model's quality was degraded due to a change in their infrastructure stack.

Honestly, this is not okay. We're at a point where hundreds of thousands of developers and businesses rely on these models as critical tools. To have the quality of that tool change under your feet without any warning is a huge problem. It messes with people's ability to do their jobs and trust the platform. While it was likely an honest mistake in pursuit of efficiency, it highlights a fundamental issue with closed, proprietary models. You're at the mercy of the provider. It's a powerful argument for the stability and control that comes with open-source and self-hosted models. These companies need to realize that they are no longer just providing experimental toys; they're providing essential infrastructure, and that comes with a responsibility for stability and transparency.
This Week's Buzz: CoreWeave Acquires OpenPipe! 🎉
Super exciting news from the Weights & Biases and CoreWeave family - we've acquired OpenPipe! Kyle and David Corbett and their team are joining us to help build out the complete AI infrastructure stack from metal to model.

OpenPipe has been doing incredible work on SFT and RL workflows with their open source ART framework. As Yam showed during the show, they demonstrated you can train a model to SOTA performance on deep research tasks for just $300 in a few hours - and it's all automated! The system can generate synthetic data, apply RLHF, and evaluate against any benchmark you specify.
This fits perfectly into our vision at CoreWeave - bare metal infrastructure, training and observability with Weights & Biases, fine-tuning and RL with OpenPipe's tools, evaluation with Weave, and inference to serve it all. We're building the complete platform, and I couldn't be more excited!
Vision & Speed: Apple's FastVLM (HF)
Just before Apple's event next week, they dropped FastVLM - a speed-first vision model that's 85x faster on time-to-first-token than comparable models. They released it in three sizes (7B, 1.5B, and 0.5B), all optimized for on-device use.
The demo that blew my mind was real-time video captioning running in WebGPU. HF CEO Clem showed it processing Apple's keynote video with maybe 250ms latency - the captions were describing what was happening almost in real-time. When someone complained it wasn't accurate because it described "an older man in headphones" when showing an F1 car, Clem pointed out that was actually the previous frame showing Tim Cook - the model was just slightly behind!
Tools Showdown: Codex vs Claude Code
To wrap up, we dove into the heated debate between Codex and Claude Code. Sam Altman reported that Codex usage is up 10x in the past two weeks (!) and improvements are coming. Yam gave us a live demo, and while Claude Code failed to even start up during the show (highlighting why people are switching), Codex with GPT-5 was smooth as butter.
The key advantages? Codex authenticates with your OpenAI account (no API key juggling), it has MCP support, and perhaps most importantly - it's not just a CLI tool. You can use it for PR reviews on GitHub, as a cloud-based agent, and integrated into Cursor and Windsurf. Though as Yam pointed out, OpenAI really needs to stop calling everything "Codex" - there are like five different products with that name now! 😅
If you're tried Codex (the CLI!) when it was released, and gave up, give it a try now, it's significantly upgraded!
Ok, phew, what a great episode we had, if you're only reading, I strongly recommend checking out the live recording or the edited podcast, and of course, if this newsletter is helpful to you, the best way you can do to support it is to subscribe, and share with friends 👏
P.S - Just came back after my first burning man, it was a challenging, all consuming experience, where I truly disconnected for the first time (first ThursdAI in over 2 years that I didn't know what's going on with AI). It was really fun but I'm happy to =be back! See you next week!

TL;DR and Show Notes
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed
Guests - Roger Jin - @rogershijin & Bhavesh Kumar @bha_ku21
Kwindla Kramer - @kwindla
Open Source LLMs
Nous Hermes 4 — 14B launches: compact hybrid reasoning model with tool calling for local and cloud use (X, HF, Tech Report)
Tencent open-sources Hunyuan-MT-7B translation model after sweeping WMT2025 (X, HF)
Nous - Husky Hold'em Bench launches as an open-source pokerbot eval for LLM strategic play (X, Bench)
WebWatcher: Alibaba's Tongyi Lab open-sources a vision-language deep research agent that sets new SOTA (X, HF)
Apertus-8B and 70B launch as Switzerland's fully open, multilingual LLMs trained on 15T tokens across 1,800+ languages (X, HF)
Google releases Embedding Gemma - 300M param SOTA embeddings model for RAG ([Breaking News])
Big CO LLMs + APIs
Mistral adds 20+ MCP-powered connectors and controllable Memories to Le Chat for enterprise workflows (X, Blog)
Anthropic raises $13B Series F at a $183B post-money valuation (X, Blog)
OpenAI fundraises $10B at ~$500B valuation - buyback for employees
OpenAI ships gpt-realtime and takes Realtime API to GA with remote MCP tools, image input, and SIP phone calling (X)
OpenAI releases projects for free users with larger file uploads and project-only memory controls
OpenAI acquires Statsig & Alex for $1.1B+ to strengthen applications team
Grok Code 1 - now taking 50% of coding traffic on OpenRouter
Codex usage up 10x in 2 weeks per Sam Altman, with improvements coming
Anthropic admits to Claude Opus quality degradation for 3 days due to infrastructure changes
This weeks Buzz
CoreWeave buys OpenPipe! 🎉 (Blog)
Vision & Video
AI Art & Diffusion & 3D
Nano Banana (Imagen 3) continues to dominate as Google's best image model (ai.studio/banana)
Tools
Codex vs Claude Code discussion → Codex now significantly better with GPT-5 engine, GitHub PR reviews, and cloud agents


