



Hey folks, Alex here, let me catch you up!
Most important news about this week came today, mid-show, OpenAI dropped GPT 5.4 Thinking (and 5.4 Pro), their latest flagship general model, less autistic than Codex 5.3, with 1M context, /fast mode and the ability to steet it mid-reasoning. We tested it live on the show, it’s really a beast.
Also, since last week, Anthropic said no to Department of War’s ultimatum and it looks like they are being designated as supply chain risk, OpenAI swooped in to sign a deal with DoW and the internet went ballistic (Dario also had some .. choice words in a leaked memo!)
On the Open Source front, the internet lost it’s damn mind when a friend of the pod Junyang Lin, announced his departure from Qwen in a tweet, causing an uproar, and the CEO of Alibaba to intervene.
Wolfram presented our new in-house wolfbench.ai and a lot more!
P.S - We acknowledge the war in Iran, and wish a quick resolution, the safety of civilians on both sides. Yam had to run to the shelter multiple times during the show.
OpenAI drops GPT 5.4 Thinking and 5.4 Pro - heavy weight frontier models with 1M context, /fast mode, SOTA on many evals
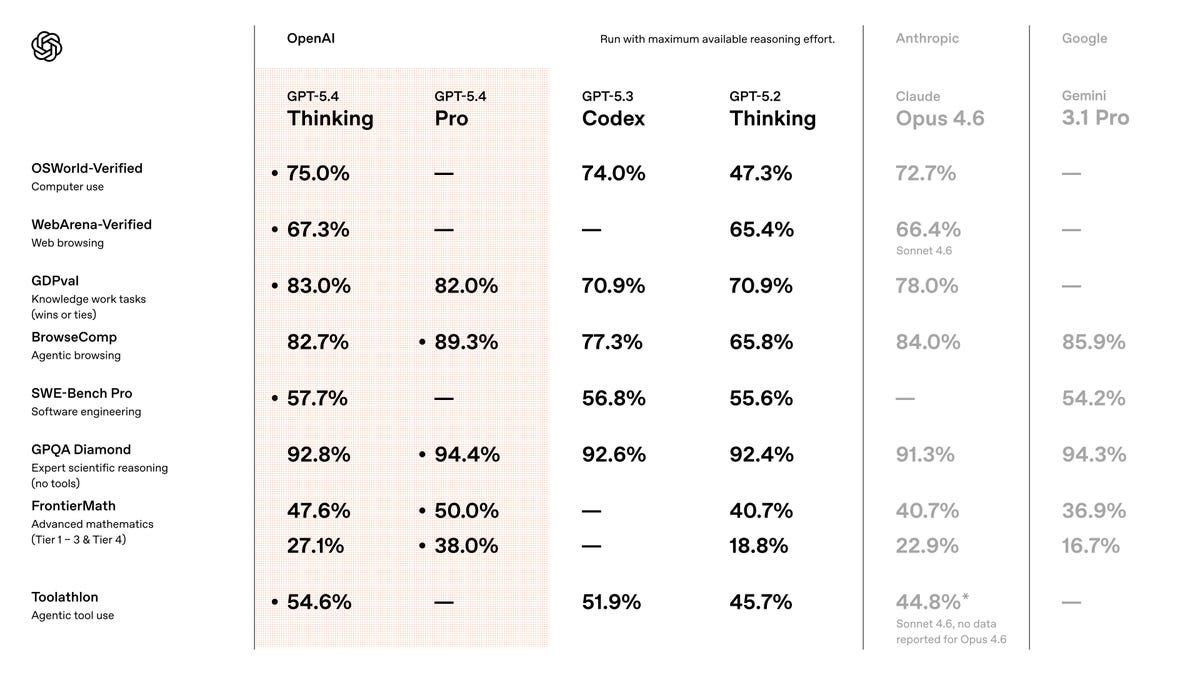
OpenAI actually opened this week with another model drop, GPT 5.3-instant, which... we can honestly skip, it was fairly insignificant besides noting that this is the model that most free users use. It is supposedly “less cringe” (actual words OpenAI used). We all wondered when 5.4 will, and OpenAI once again proved that we named the show after the right day. Of course it drops on a ThursdAI.
GPT 5.4 Thinking is OpenAI latest “General” model, which can still code, yes (they folded most of the Codex 5.3 coding breakthroughs in here) but it also shows an incredible 83% on GDPVal (12% over Codex), 47% on Frontier Math and an incredible ability to use computers and browsers with 82% on BrowseComp beating Claude 4.6 at lower prices than Sonnet!

GPT 5.4 is also ... quite significantly improved at Frontend design? This landing page was created by GPT 5.4 (inside the Codex app, newly available on Windows) in a few minutes, clearly showing significant improvements in style.
I built it also to compare prices, all the 3 flagship models are trying to catch up to Gemini in 1M context window, and it’s important to note, that GPT 5.4 even at double the price after the 272K tokens cutoff is still.... cheaper than Opus 4.6. OpenAI is really going for broke here, specifically as many enterprises are adopting Anthropic at a faster and faster pace (it was reported that Anthropic is approaching 19B ARR this month, doubling from 8B just a few months ago!)
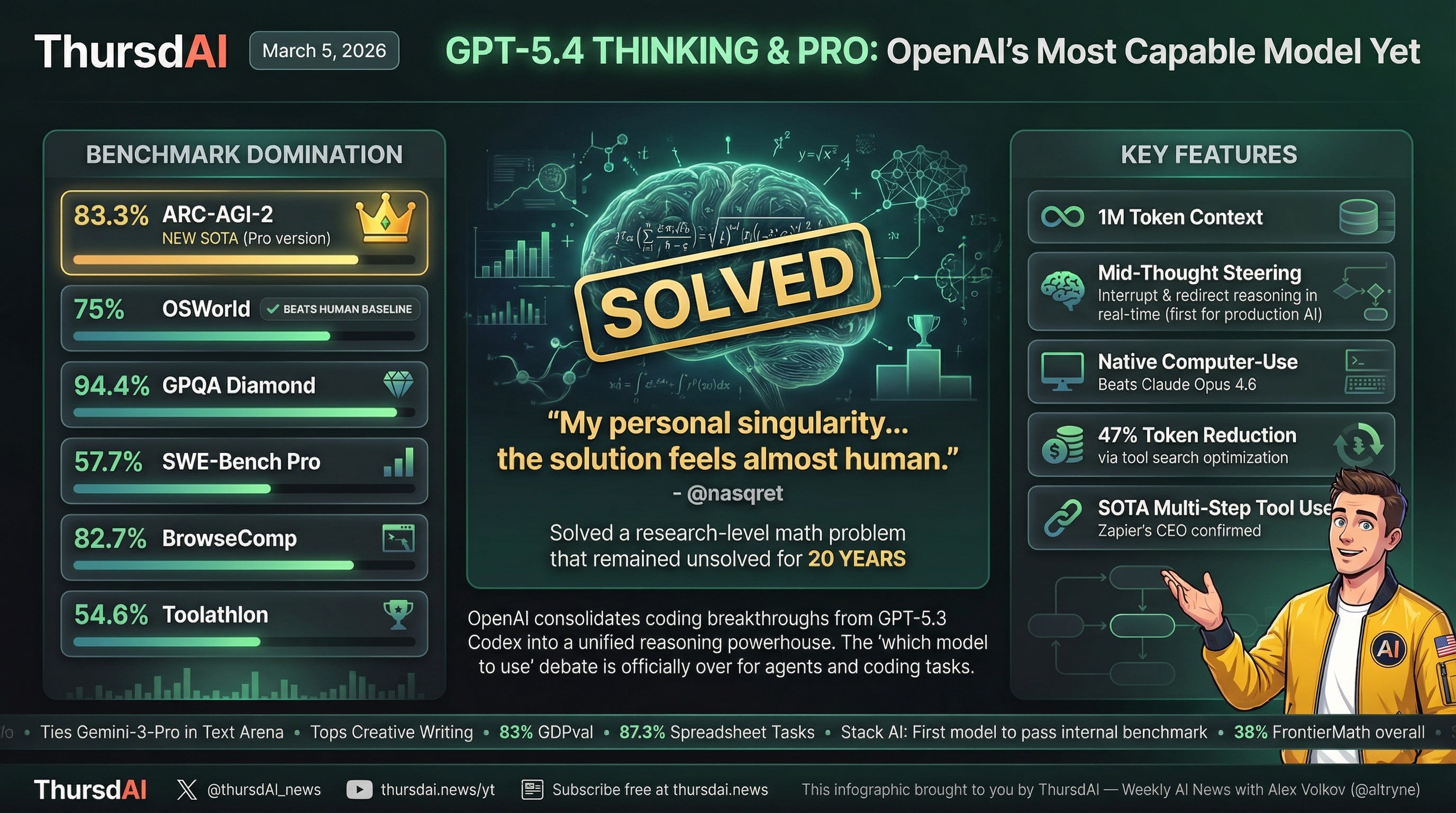
Frontier math wiz
The highlight from the 5.4 feedback came from a Polish mathematician Bartosz Naskręcki (@nasqret on X), who said GPT-5.4 solved a research-level FrontierMath problem he had been working on for roughly 20 years. He called it his “personal singularity,” and as overused as that word has become, I get why he said it. I’ve told you about this last week, we’re on the cusp.
Coding efficiency
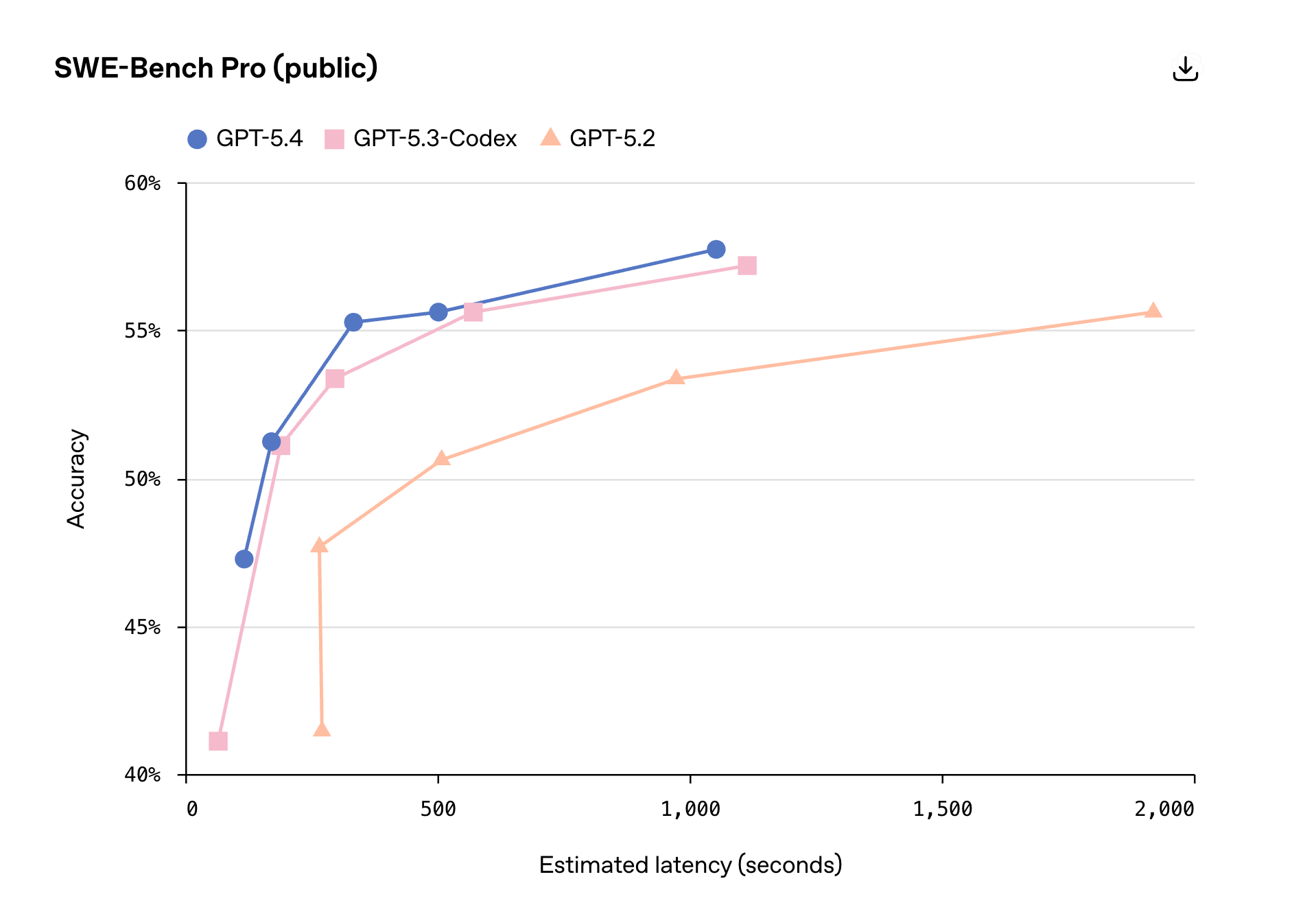
There’s tons of metrics in this release, but I wanted to highlight this one, where it may seem on first glance that on SWE-bench Pro, this model is on par with the previous SOTA GPT 5.3 codex, but these dots here are thinking efforts. And a medium thinking effort, GPT 5.4 matches 5.3 on hard thinking! This is quite remarkable, as lower thinking efforts have less tokens, which means they are cheaper and faster ultimately!
Fast mode arrives at OpenAI as well
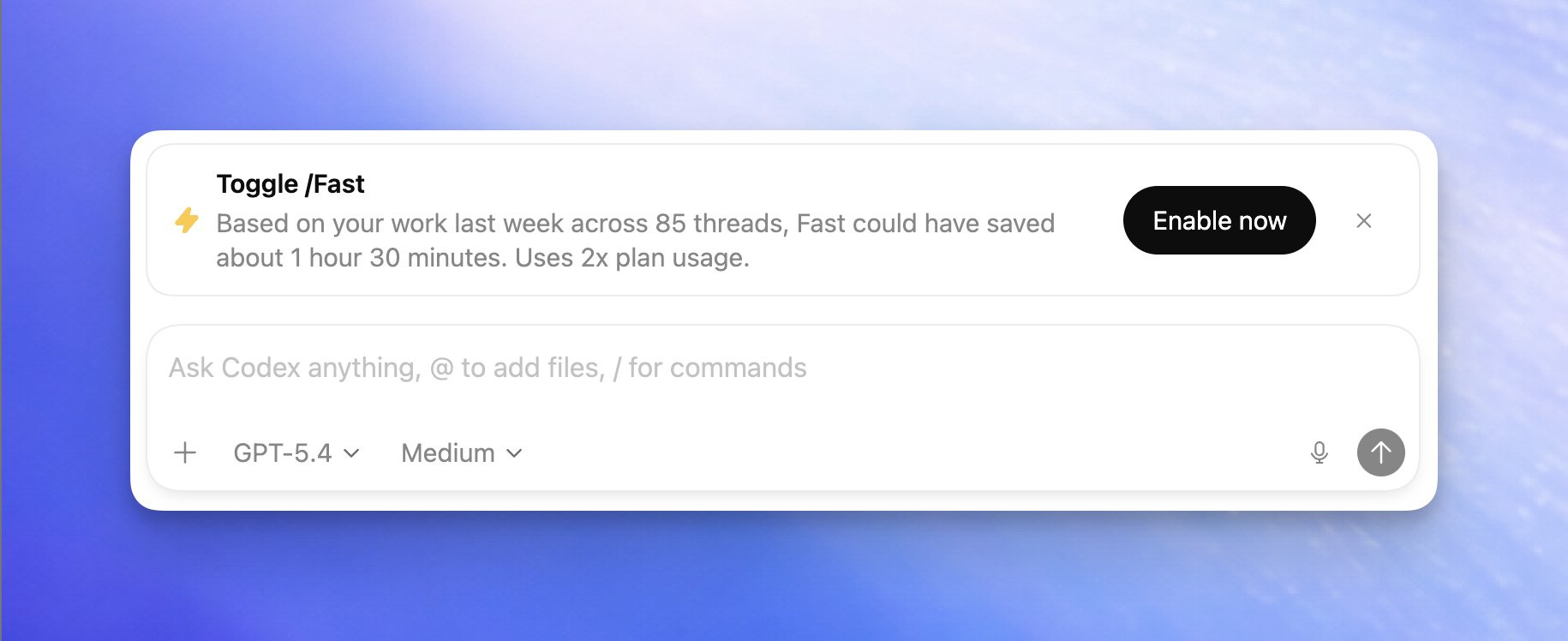
I think this one is a direct “this worked for Anthropic, lets steal this”, OpenAI enabled /fast mode that.. burns the tokens at 2x the rate, and prioritizes your tokens at 1.5x the speed. So, essentially getting you responses faster (which was one of the main complains about GPT 5.3 Codex). I can’t wait to bring the fast mode to OpenClaw with 5.4, which will absolutely come as OpenClaw is part of OpenAI now.
There’s also a really under-appreciated feature here that I think other labs are going to copy quickly: mid-thought steering. OpenAI now lets you interrupt the model while it’s thinking and redirect it in real time in ChatGPT and iOS. This is a godsend if you’re like me, sent a prompt, seeing the model go down the wrong path in thinking... and want to just.. steer it without stopping!
Anthropic is now designated as supply-chain risk by DoW

Last week I left you with a cliffhanger: Anthropic had received an ultimatum from the Department of War (previously the Department of Defense) to remove their two remaining restrictions on Claude — no autonomous kill chain without human intervention, and no surveillance of US citizens. Anthropic’s response? “we cannot in good conscience acceede to their request”
So much has happened since then; US President Trump said “I fired Anthropic” referring to his Truth Social post demanding intelligence agencies drop the use of Claude (which apparently was used in the war with Iran regardless); Sam Altman announced that OpenAI has agreed to DoW and will provide OpenAI models, causing a lot of people to cancel their OpenAI subscriptions, and later apologizing for the “rushed rollout”; Dario Amodei posted a very contentious internal memo that leaked, in which he name-called the presidency, Sam Altman and his motives, Palantir and their “safety theater”, for which he later apologized

Honestly this whole thing is giving me whiplash trying to follow, but here’s the facts. Anthropic is now the first US company in history, being designated “supply chain risk” which means no government agency can use Claude, and neither can any company that does contracts with DoW.

Anthropic says it’s illegal and will challenge this in court , while reporting $19B in annual recurring revenue, nearly doubling since last 3 months, and very closely approaching OpenAI at $25B.
Look, did I want to report on this stuff when I decided to cover AI? no... I wanted to tell you about cool models and capabilities, but the world is changing, and it’s important to know that the US Government understands now that AI is inevitable, and I think this is just the first of many clashes between tech and government we’ll see. We’ll keep reporting on both. (but let me know in the comments if you’d prefer just model releases)
OpenAI’s GPT-5.3 Instant Gets Less Cringe, Google’s Flash-Lite Gets Faster (X, Announcement)
We also got two fast-model updates this week that are worth calling out because these are the models that often end up powering real product flows behind the scenes. As I wrote before, OpenAI’s instant model is nothing to really mention, but it’s worth mentioning that OpenAI seems to have an answer for every Gemini release.

Gemini released Gemini Flash-lite this week, which boasts an incredible 363 tokens/s speed, which doing math at a very good level, 1M context and great scores compared to the instant/fast models like Haiku from Anthropic. Folks called out that this model is more expensive than the previous 2.5 Flash-lite. But with 86.9% on GPQA Diamond beating GPT-5 mini, and 76.8% MMMU-pro multimodal reasoning, this is definitely worth taking a look at for many agentic, super fast responses!
For example, the heartbeat response in OpenClaw.
Qwen 3.5 Small Models & The Departure of Junyang Lin (X, HF, HF, HF)
Alibaba’s Qwen team continued releasing their Qwen 3.5 family, this time with Qwen 3.5 Small, a series of models at 0.8B, 2B, 4B, and 9B parameters with native multimodal capabilities. The flagship 9B model is beating GPT-OSS-120B on multiple benchmarks, scoring 82.5 on MMLU-Pro and 81.7 on GPQA Diamond. These models can handle video, documents, and images natively, support up to 201 languages, and can process up to 262K tokens of context. And.. they are great! They are trending on HF right now.
What’s also trending is, tech lead for Qwen, a friend of the pod Junyang Lin, has posted a cryptic tweet that went viral with over 6M views. There was a lot of discussions on why he and other Qwen leads are stepping away, what’s goig to happen with the future of OpenSource. The full picture seems to be, there are a lot of internal tensions and politics, with Junyang being one of the youngest P10 leaders in the Alibaba org.
A Chinese website 36KR ( Kind of like a chinese techcrunch) reported that this matter went all the way up to Alibaba CEO, who is no co-leading the qwen team, and that this resignation was related to an internal dispute over resource allocation and team consolidation, not a firing.
I’m sure Junyang is going to land somewhere incredible and just wanted to highlight just how much he did for the open source community, pushing Qwen relentlessly, supporting and working with a lot of inference providers (and almost becoming a co-host for ThursdAI with 9! appearances!)
StepFun releases Step 3.5 Flash Base (X, HF, HF, Announcement, Arxiv)

Speaking of Open Source, StepFun just broke through the noise with a new model, a 196B parameter sparse Mixture of Experts model activating just 11B parameters when ran. It has some great benchmarks, but the main thing is this: they are releasing the pretrained base weights, a midtrain checkpoint optimized for code and agents, the complete SteptronOSS training framework, AND promising to release their SFT data soon - all under Apache 2.0!
Technically the model looks strong too, with multi-token prediction, 74.4% on SWE-bench verified bench (though, as we told you last week, it’s.. no longer trusted) and full apache 2!
This Week’s Buzz: presenting Wolfbench.ai
I’m so excited about this weeks “this weeks buzz”, Wolfram has been hard at work preparing and presenting a new framework to test out these models, and named it wolfbench.ai
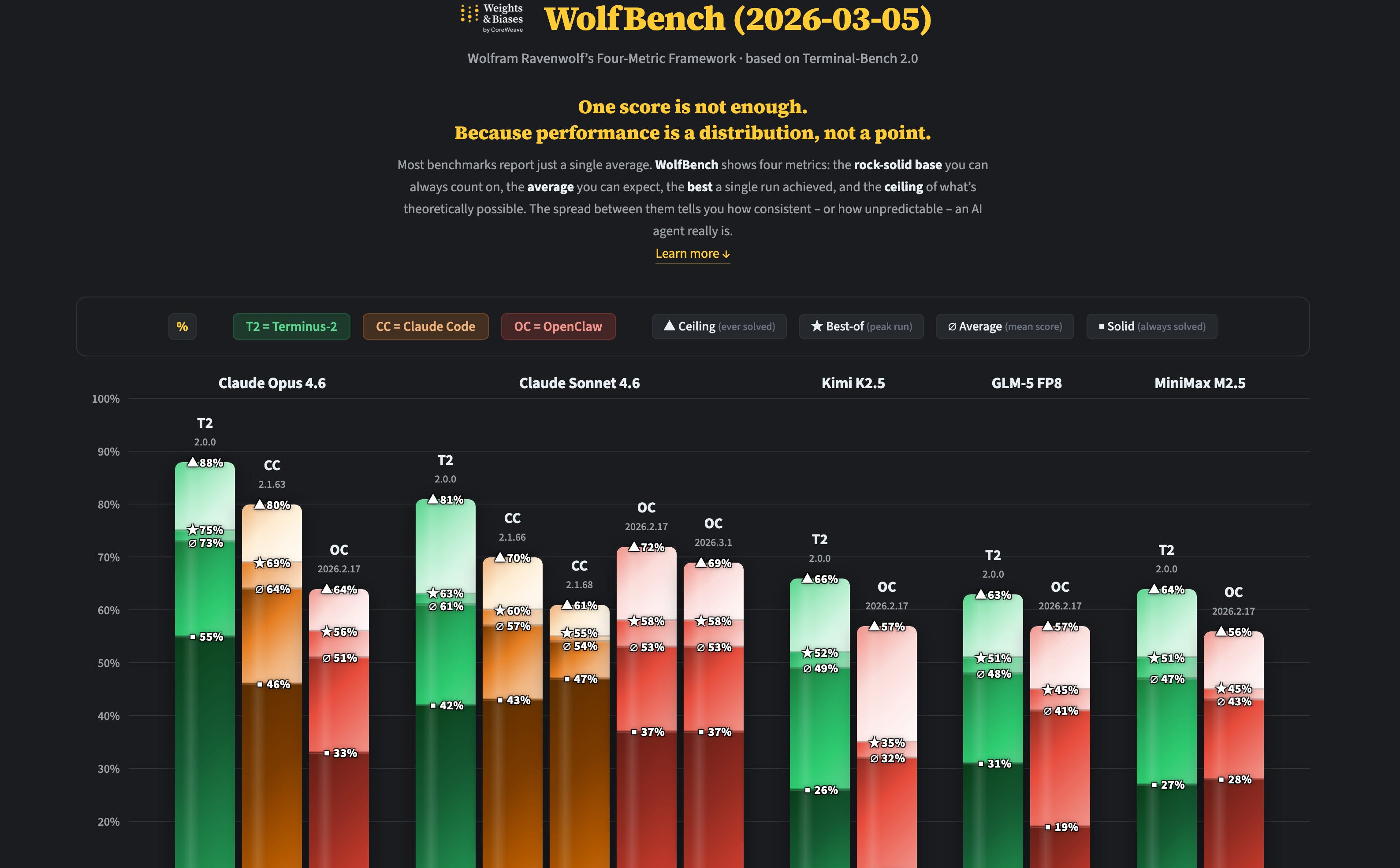
Wolfbench is our attempt to compare how the same model performs via different agentic harnesses like ClaudeCode, OpenClaw and Terminalbench’s own Terminus.
You can check out the website on wolfbench.com but the short of it is, a single number is not telling the full story.
Wolf Bench breaks it into a four-metric framework: the average score across runs, the best single run, the ceiling (how many tasks can the model solve at least once across all runs), and the floor (how many tasks does it solve consistently across every single run). That last one is what I find most illuminating. Opus 4.6 might be able to solve 88% of Terminal Bench tasks on average, but only about 55% of tasks it solves every single time. Reliability matters enormously for agents, and benchmarks almost never surface this.
If you want to run your own evals with the same config, reach out to Wolfram—he’s open to community contributions. Wolfram has also already kicked off a Wolf Bench run on GPT-5.4 since we tested it live today, so stay tuned for those results.
There’s quite a few more releases we didn’t have time to get into on the show given the GPT 5.4 drop, you’ll find all those links in the show notes!
Next week will mark 3 years since I’ve started talking about AI on the internet and created ThursdAI (It was March 14th, 2023, same day as GPT4 launched) and we’ll have a little celebration, I do hope you join us live 🔥
As a birthday present, you may choose to share ThursdAI with a friend or two, or rate us in your podcast player of choice! See you next week,
Alex 🫡
ThursdAI - Mar 05, 2026 - TL;DR
TL;DR of all topics covered:
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed @ryancarson
Big CO LLMs + APIs
Evals and Benchmarks
Open Source LLMs
Tools & Agentic Engineering
This weeks Buzz
Early preview of Wolf Bench (wolfbench.ai) from W&B
AI Art & Diffusion & 3D
Black Forest Labs introduces Self-Flow (X, Announcement)


