



Hey dear subscriber, Alex here from W&B, let me catch you up!
This week started with Anthropic releasing /fast mode for Opus 4.6, continued with ByteDance reality-shattering video model called SeeDance 2.0, and then the open weights folks pulled up!
Z.ai releasing GLM-5, a 744B top ranking coder beast, and then today MiniMax dropping a heavily RL’d MiniMax M2.5, showing 80.2% on SWE-bench, nearly beating Opus 4.6! I’ve interviewed Lou from Z.AI and Olive from MiniMax on the show today back to back btw, very interesting conversations, starting after TL;DR!
So while the OpenSource models were catching up to frontier, OpenAI and Google both dropped breaking news (again, during the show), with Gemini 3 Deep Think shattering the ArcAGI 2 (84.6%) and Humanity’s Last Exam (48% w/o tools)... Just an absolute beast of a model update, and OpenAI launched their Cerebras collaboration, with GPT 5.3 Codex Spark, supposedly running at over 1000 tokens per second (but not as smart)
Also, crazy week for us at W&B as we scrambled to host GLM-5 at day of release, and are working on dropping Kimi K2.5 and MiniMax both on our inference service! As always, all show notes in the end, let’s DIVE IN!
Open Source LLMs
Z.ai launches GLM-5 - #1 open-weights coder with 744B parameters (X, HF, W&B inference)
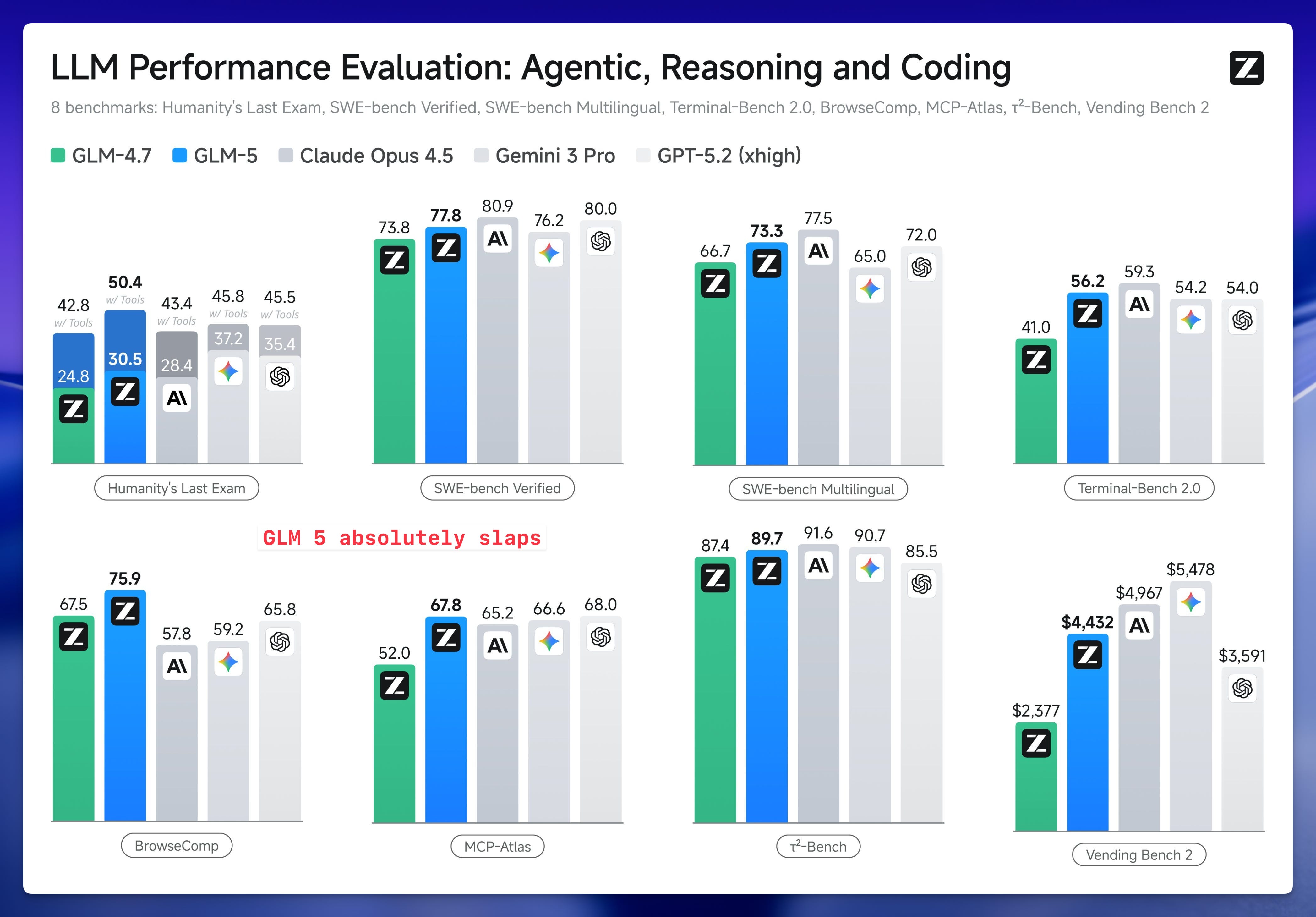
The breakaway open-source model of the week is undeniably GLM-5 from Z.ai (formerly known to many of us as Zhipu AI). We were honored to have Lou, the Head of DevRel at Z.ai, join us live on the show at 1:00 AM Shanghai time to break down this monster of a release.
GLM-5 is massive, not something you run at home (hey, that’s what W&B inference is for!) but it’s absolutely a model that’s worth thinking about if your company has on prem requirements and can’t share code with OpenAI or Anthropic.
They jumped from 355B in GLM4.5 and expanded their pre-training data to a whopping 28.5T tokens to get these results. But Lou explained that it’s not only about data, they adopted DeepSeeks sparse attention (DSA) to help preserve deep reasoning over long contexts (this one has 200K)
Lou summed up the generational leap from version 4.5 to 5 perfectly in four words: “Bigger, faster, better, and cheaper.” I dunno about faster, this may be one of those models that you hand off more difficult tasks to, but definitely cheaper, with $1 input/$3.20 output per 1M tokens on W&B!
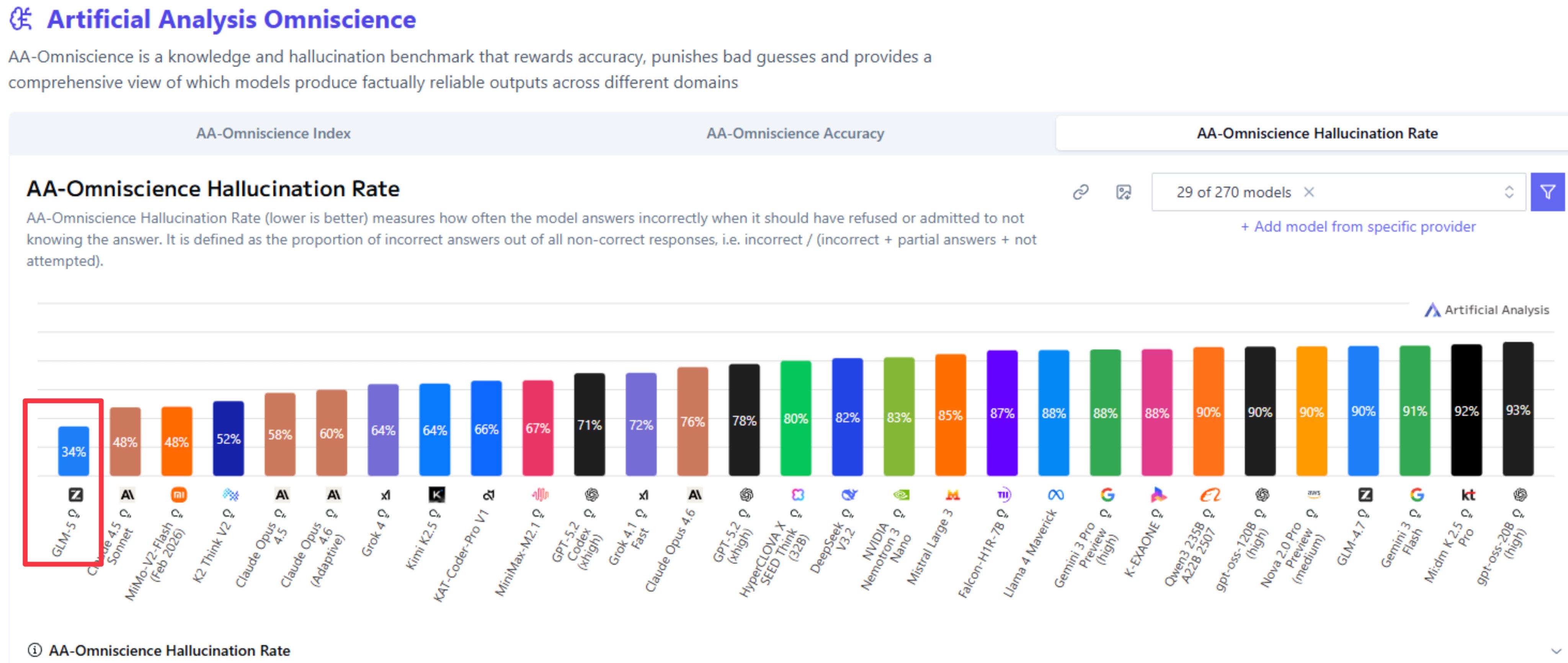
While the evaluations are ongoing, the one interesting tid-bit from Artificial Analysis was, this model scores the lowest on their hallucination rate bench!
Think about this for a second, this model is neck-in-neck with Opus 4.5, and if Anthropic didn’t release Opus 4.6 just last week, this would be an open weights model that rivals Opus! One of the best models the western foundational labs with all their investments has out there. Absolutely insane times.
MiniMax drops M2.5 - 80.2% on SWE-bench verified with just 10B active parameters (X, Blog)
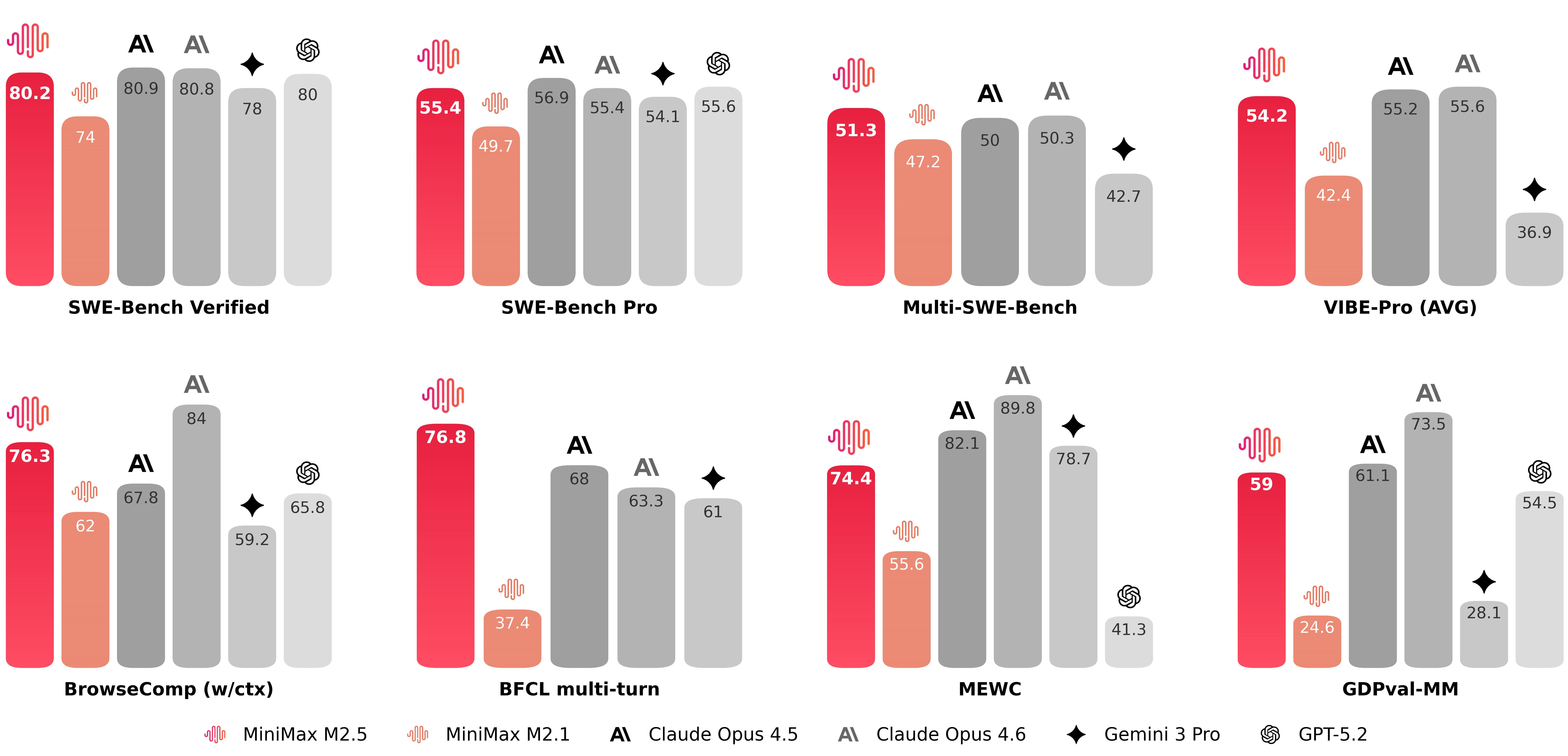
Just as we wrapped up our conversation with Lou, MiniMax dropped their release (though not weights yet, we’re waiting ⏰) and then Olive Song, a senior RL researcher on the team, joined the pod, and she was an absolute wealth of knowledge!
Olive shared that they achieved an unbelievable 80.2% on SWE-Bench Verified. Digest this for a second: a 10B active parameter open-source model is directly trading blows with Claude Opus 4.6 (80.8%) on the one of the hardest real-world software engineering benchmark we currently have. While being alex checks notes ... 20X cheaper and much faster to run? Apparently their fast version gets up to 100 tokens/s.

Olive shared the “not so secret” sauce behind this punch-above-its-weight performance. The massive leap in intelligence comes entirely from their highly decoupled Reinforcement Learning framework called “Forge.” They heavily optimized not just for correct answers, but for the end-to-end time of task performing. In the era of bloated reasoning models that spit out ten thousand “thinking” tokens before writing a line of code, MiniMax trained their model across thousands of diverse environments to use fewer tools, think more efficiently, and execute plans faster. As Olive noted, less time waiting and fewer tools called means less money spent by the user. (as confirmed by @swyx at the Windsurf leaderboard, developers often prefer fast but good enough models)
I really enjoyed the interview with Olive, really recommend you listen to the whole conversation starting at 00:26:15. Kudos MiniMax on the release (and I’ll keep you updated when we add this model to our inference service)
Big Labs and breaking news
There’s a reason the show is called ThursdAI, and today this reason is more clear than ever, AI biggest updates happen on a Thursday, often live during the show. This happened 2 times last week and 3 times today, first with MiniMax and then with both Google and OpenAI!
Google previews Gemini 3 Deep Think, top reasoning intelligence SOTA Arc AGI 2 at 84% & SOTA HLE 48.4% (X , Blog)

I literally went 🤯 when Yam brought this breaking news. 84% on the ARC-AGI-2 benchmark. For context, the highest score prior to this was 68% from Opus 4.6 just last week. A jump from 68 to 84 on one of the hardest reasoning benchmarks we have is mind-bending. It also scored a 48.4% on Humanity’s Last Exam without any tools.
Only available to Ultra subscribers to Gemini (not in API yet?) this model seem to be the current leader in reasoning about hard problems and is not meant for day to day chat users like you and me (though I did use it, and it’s pretty good at writing!)
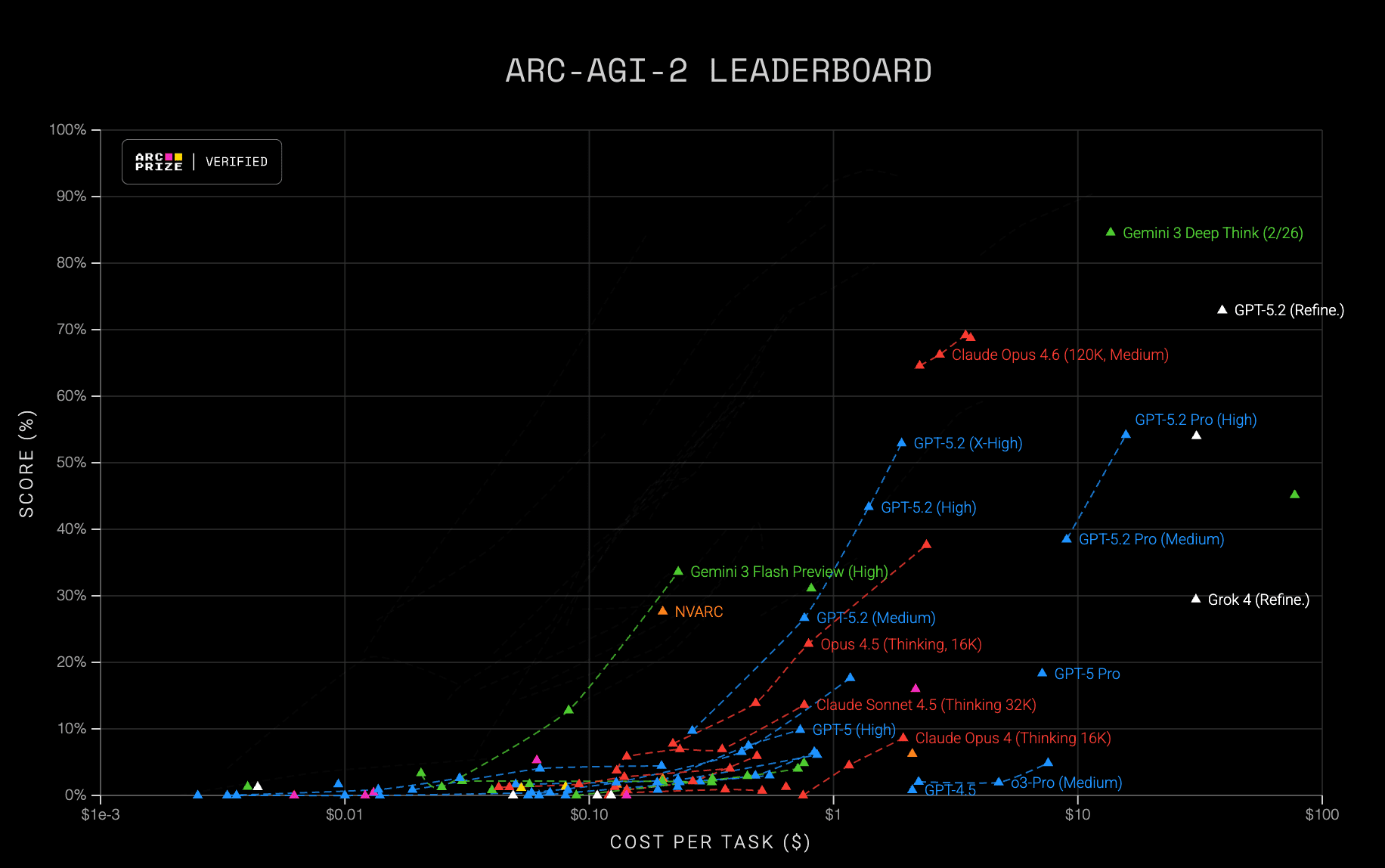
They posted Gold-medal performance on 2025 Physics and Chemistry Olympiads, and an insane 3455 ELO rating at CodeForces, placing it within the top 10 best competitive programmers. We’re just all moving so fast I’m worried about whiplash! But hey, this is why we’re here, we stay up to date so you don’t have to.
OpenAI & Anthropic fast modes
Not 20 minutes passed since the above news, when OpenAI announced a new model that works only for Pro tier members (I’m starting to notice a pattern here 😡), GPT 5.3 Codex Spark.
You may be confused, didn’t we just get GPT 5.3 Codex last week? well yeah, but this one, this one is its little and super speedy brother, hosted by the Cerebras partnership they announced a while ago, which means, this coding model absolutely slaps at over 1000t/s.
Yes, over 1K tokens per second can be generated with this one, though there are limits. It’s not as smart, it’s text only, it has 128K context, but still, for MANY subagents, this model is an absolute beast. It won’t refactor in one shot your whole code-base but it’ll generate and iterate on it, very very quick!
OpenAI also previously updated Deep Research with GPT 5.2 series of models, and we can all say bye bye to the “older” version of models, like 5, o3 and most importantly GPT 4o, which got a LOT of people upset (enough that they have a hashtag going, #keep4o) !

Anthropic also announced their fast mode (using /fast) in Claude Code btw on Saturday, and that one is absolutely out of the scope for many users, with $225/1M tokens on output, this model will just burn through your wallet. Unlike the Spark version, this seems to be the full Opus 4.6 just... running on some dedicated hardware? I thought this was a rebranded Sonnet 5 at first but Anthropic folks confirmed that it wasn’t.
Vision & Video
ByteDance’s Seedance 2.0 Shatters Reality (and nobody in the US can use it)
I told the panel during the show: my brain is fundamentally broken after watching the outputs from ByteDance’s new Seedance 2.0 model. If your social feed isn’t already flooded with these videos, it will be so very soon (supposedly the API launches Feb 14 on Valentines Day)
We’ve seen good video models before. Sora blew our minds and then Sora 2, Veo is (still) great, Kling was fantastic. But Seedance 2.0 is an entirely different paradigm. It is a unified multimodal audio-video joint generation architecture. What does that mean? It means you can simultaneously input up to 9 reference images, 3 video clips, 3 audio clips, and text instructions all at once to generate a 15-second cinematic short film. It character consistency is beyond what we’ve seen before, physics are razor sharp (just looking at the examples folks are posting, it’s clear it’s on another level)
I think very soon though, this model will be restricted, but for now, it’s really going viral due to the same strategy Sora did, folks are re-imagining famous movie and TV shows endings, doing insane mashups, and much more! Many of these are going viral over the wall in China.
The level of director-like control is unprecedented. But the absolute craziest part is the sound and physics. Seedance 2.0 natively generates dual-channel stereo audio with ASMR-level Foley detail. If you generate a video of a guy taking a pizza out of a brick oven, you hear the exact scratch of the metal spatula, the crackle of the fire, the thud of the pizza box, and the rustling of the cardboard as he closes it. All perfectly synced to the visuals.
Seedance 2 feels like “borrowed realism”. Previous models had only images and their training to base their generations on. It 2 accepts up to 3 video references in addition to images and sounds.
This is why some of the videos feel like a new jump in visual capabilities. I have a hunch that ByteDance will try and clamp down on copyrighted content before releasing this model publicly, but for now the results are very very entertaining and I can’t help but wonder, who is the first creator that will just..remake the ending of GOT last season!?
Trying this out is hard right now, especially in the US, but there’s a free way to test it out with a VPN, go to doubao.com/chat when connected from a VPN and select Seedream 4.5 but ask for “create a video please” in your prompt!
AI Art & Diffusion: Alibaba’s Qwen-Image-2.0 (X, Blog)

The Qwen team over at Alibaba has been on an absolute tear lately, and this week they dropped Qwen-Image-2.0. In an era where everyone is scaling models up to massive sizes, Alibaba actually shrank this model from 20B parameters down to just 7B parameters, while massively improving performance (tho didn’t drop the weights yet, they are coming)
Despite the small size, it natively outputs 2K (2048x2048) resolution images, giving you photorealistic skin, fabric, and snow textures without needing a secondary upscaler. But the real superpower of Qwen-Image-2.0 is its text rendering, it supports massive 1,000-token prompts and renders multilingual text (English and Chinese) flawlessly.

It’s currently #3 globally on AI Arena for text-to-image (behind only Gemini-3-Pro-Image and GPT Image 1.5) and #2 for image editing. My results with it were not the best, I tried to generate this weeks Thumbnails with it and .. they turned out meh at best?
In fact, my results were so so bad compared to their launch blog that I’m unsure that they are serving me the “new” model 🤔 Judge for yourself, the above infographic was created with Nano Banana Pro, and this one, same prompt, with Qwen Image on their website:

But you can test it for free at chat.qwen.ai right now, and they’ve promised open-source weights after the Chinese New Year!
🛠️ Tools & Orchestration: Entire Checkpoints & WebMCP
With all these incredibly smart, fast models, the tooling ecosystem is desperately trying to keep up. Two massive developments happened this week that will change how we build with AI, moving us firmly away from hacky scripts and into robust, agent-native development.
Entire Raises $60M Seed for OSS Agent Workflows
Agent orchestration is the hottest problem in tech right now, and a new company called Entire just raised a record-breaking $60 Million seed round (at a $300M valuation—reportedly the largest seed ever for developer tools) to solve it. Founded by former GitHub CEO Thomas Dohmke, Entire is building the “GitHub for the AI agent era.”
Their first open-source release is a CLI tool called Checkpoints.
Checkpoints integrates via Git hooks and automatically captures entire agent sessions—transcripts, prompts, files modified, token usage, and tool calls—and stores them as versioned Git data on a separate branch (entire/checkpoints/v1). It creates a universal semantic layer for agent tracing. If your Claude Code or Gemini CLI agent goes off the rails, Checkpoints allows you to seamlessly rewind to a specific state in the agent’s session.
We also have to shout out our own Ryan Carson, who shipped his open-source project AntFarm this week to help orchestrate these agents on top of Open-Claw!
Chrome 146 Introduces WebMCP
Finally, an absolutely massive foundational shift is happening on the web. Chrome 146 Canary is shipping an early preview of WebMCP.
We have been talking about web-browsing agents for a while, and the biggest bottleneck has always been brittle DOM scraping, guessing CSS selectors, and simulating clicks via Puppeteer or Playwright. It wastes an immense amount of tokens and breaks constantly. Chrome 146 is fundamentally changing this by introducing a native browser API.
Co-authored by Google and Microsoft under the W3C Web Machine Learning Community Group, WebMCP allows websites to declaratively expose structured tools directly to AI agents using JSON schemas via navigator.modelContext. You can even do this declaratively through HTML form annotations using tool-name and tool-description attributes. No backend MCP server is required;
I don’t KNOW if this is going to be big or not, but it definitely smells like it, because even the best agentic AI assistants are struggling with browsing the web, given the constrained context windows cannot just go by HTML content and screenshots! Let’s see if this will help agents browsing the web!
All right, that about sums it up I think for this week, it was an absolute banger of a week, for open the one thing I didn’t cover as a news item but mentioned last week, is that many folks report being overly tired, barely able to go to sleep while their agentic things are running, and all of us are trying to get to the bottom of how to work with these new agentic coding tools.
Steve Yegge noticed the same and called it “the AI vampire“ while Matt Shumer went ultraviral (80M+ views) on his article about “something big is coming“ which terrified a lot of folks. What’s true for sure, is that we’re going through an inflection point in humanity, and I believe that staying up to date is essential as we go through it, even if some of it seems scary or “too fast”.
This is why ThursdAI exists, I first and foremost wanted this for ME to stay up to date, and after that to share this with all of you. Having recently hit a few milestones for ThursdAI, all I can say is thanks for sharing, reading, listening and tuning in from week to week 🫡
ThursdAI - Feb 12, 2026 - TL;DR
TL;DR of all topics covered:
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed) @ryancarson
Olive Song - Lead RL at Minimax @olive_jy_song
Open Source LLMs
Big CO LLMs + APIs
XAI cofounders quit/let go after X restructuring (X, TechCrunch)
Anthropic releases Claude Opus 4.6 sabotage risk report, preemptively meeting ASL-4 safety standards for autonomous AI R&D (X, Blog)
OpenAI upgrades Deep Research to GPT-5.2 with app integrations, site-specific searches, and real-time collaboration (X, Blog)
Gemini 3 Deep Think SOTA on Arc AGI 2, HLE (X)
OpenAI releases GPT 5.3 Codex spark, backed by Cerebras with over 1000tok/sec (X)
This weeks Buzz
Vision & Video
ByteDance Seedance 2.0 launches with unified multimodal audio-video generation supporting 9 images, 3 videos, 3 audio clips simultaneously (X, Blog, Announcement)
AI Art & Diffusion & 3D
Alibaba launches Qwen-Image-2.0: A 7B parameter image generation model with native 2K resolution and superior text rendering (X, Announcement)
Tools & Links
Entire raises $60M seed to build open-source developer platform for AI agent workflows with first OSS release ‘Checkpoints’ (X, GitHub, Blog)
Chrome 146 introduces WebMCP: A native browser API enabling AI agents to directly interact with web services (X)
RyanCarson AntFarm - Agent Coordination (X)
Steve Yegge’s “The AI Vampire” (X)
Matt Shumer’s “something big is happening” (X)


