



Hey, it’s Alex, let me tell you why I think this week is an inflection point.
Just this week: Everyone is launching autonomous agents or features inspired by OpenClaw (Devin 2.2, Cursor, Claude Cowork, Microsoft, Perplexity and Nous announced theirs), METR and ArcAGI 2,3 benchmarks are getting saturated, 1 person companies nearing 1M ARR within months of operation by running AI agents 24/7 (we chatted with one of them on the show today, live as he broke $700K ARR barrier) and the US Department of War gives Anthropic an ultimatum to remove nearly all restrictions on Claude for war and Anthropic says NO.
I’ve been covering AI for 3 years every week, and this week feels, different. So if we are nearing the singularity, let me at least keep you up to date 😅
Today on the show, we covered most of the news in the first hour + breaking news from Google, Nano Banana 2 is here, and then had 3 interviews back to back. Ben Broca with Polsia, Nader Dabit with Cognition and Philip Kiely with BaseTen. Don’t miss those conversations starting at 1 hour in.
Anthropic vs Department of War

Earlier this week, the US “Department of War” invited Dario Amodei, CEO of Anthropic to a meeting, where-in Anthropic was given an ultimatum. “Remove the restrictions on Claude or Anthropic will be designated as a ‘supply chain risk’ company” and the DoD will potentially go as far as using the Defence Production Act to force Anthropic to ... comply.
The two restrictions that Anthropic has in place for their models are: No use for domestic surveillance of American citizens and NO fully autonomous lethal weapens decisions given to Claude. For context, Claude is the only model that’s deployed on AWS top secret GovCloud and is used through Palantir’s AI platform.

As I’m writing this, Anthropic issued a statement from Dario statement saying they will not budge on this, and will not comply. I fully commend Dario and Anthropic for this very strong backbone, but I fear that this matter is far from over, and we’ll continue to see what is the government response.
EDIT: Apparently the DoD is pressuring Google and OpenAI to agree to the stipulations and employees from both companies are signing this petition https://notdivided.org/ to protest against dividing the major AI labs on this topic.
Anthropic and OpenAI vs upcoming Deepseek

It’s baffling just how many balls are in the air for Anthropic, as just this week also, they have publicly named 3 Chinese AI makers in “Distillation Attacks”, claiming that they have broke Terms of Service to generate over 16M conversations with Claude to improve their own models, while using proxy networks to avoid detection. This marks the first time a major AI company publicly attributed distillation attacks to specific entities by name.
The most telling thing to me is not the distillation, given that Anthropic has just recently settled one of the largest copyright payouts in U.S history, paying authors about $3000/book, which was bought, trained on and destroyed by Anthropic to make Claude better.
No, the most telling thing here is the fact that Anthropic chose to put DeepSeek on top of the accusation list with merely 140K conversations, where the other labs created millions.
This, plus OpenAI formal memo to Congress about a similar matter, shows that the US labs are trying to prepare for Deepseek new model to drop, by saying “Every innovation they have, they stole from us”. Apparently Deepseek V4 is nearly here, it’s potentially multimodal and has been allegedly trained on Nvidia chips somewhere in Mongolia despite the export restrictions and it’s about to SLAP!
Benchmark? What benchmarks?
How will we know that we’re approaching the singularity? Will there be signs? Well, this week it seems that the signs are here.

First, Agentica claimed that they solved all publicly available “hard for AI” tasks of the upcoming ArcAGI 3, then Confluence Labs announced that they got an unprecedented 97.9% on ArcAGI2 and finally METR published their results on the long-horizon tasks, which measure AI’s capability to solve task that take humans a certain amount of hours to do. And that graph is going parabolic, with Claude Opus 4.6 able to solve tasks of 14.6h (doubling every 49 days) with 50% success rate
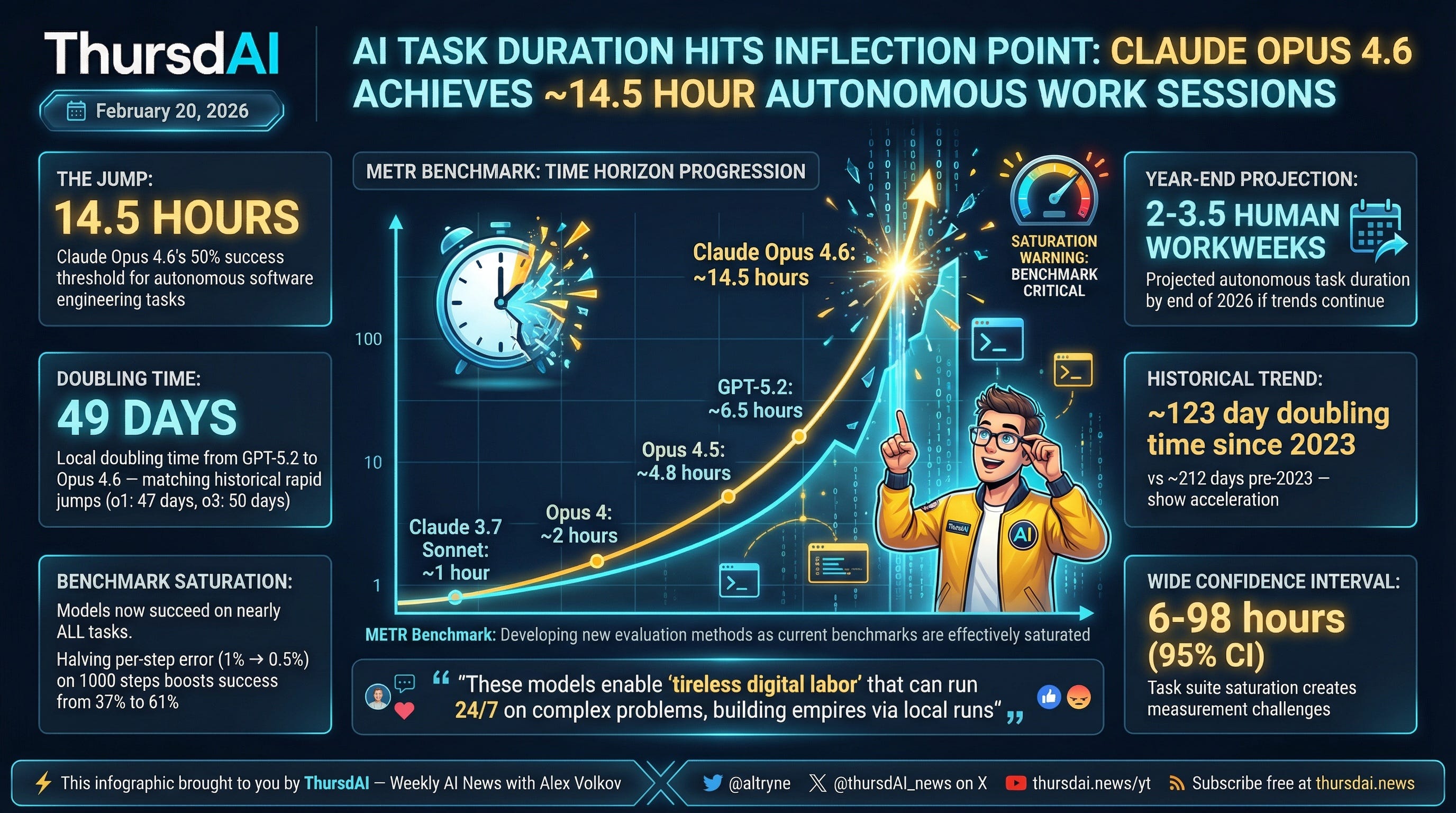
Why is this important? Well, this is just the benchmarks telling the story that everyone else in the industry is seeing, that approximately since December of 2025, and definitely fueled by early Feb drop of Opus 4.6 and Codex 5.3, something major shifted. Developers no longer write code, but ship 10x more features.

This became such a talking point, Swyx Latent.Space coined this with
https://wtfhappened2025.com/ where he collects evidence of a shelling point, something that happened in December and I think continued throughout February.
Speaking of benchmarks no longer being valid, OpenAI published that the divergence between the SWE-bench verified gains with real life performance is so vast, that they will no longer be using SWE-bench verified, and will be switching to SWE-bench pro for evaluations.
Everyone’s Autonomous agents (and subagents) are here
Look, with over 250K Github stars, OpenAI getting Peter Steinberger on board, it’s clear now. OpenClaw made a huge dent in how people think about autonomous agents (and subagents!)
It may be a “moment in time” that the model capabilities were “just good enough” to be able to run agents async for a long time. but the big labs noticed the OpenClaw excitement and are shipping like never before to make sure their users don’t switch over!
Perplexity launched “Computer“, which has scheduled tasks in a compute environment, and can complete long lasting projects end to end, Cursor pivots from IDE only to running Agents in the cloud with their own environments, Claude Code added memory, and Remote Control, while Claude Cowork added Scheduled tasks, our friends from Nous shipped Hermes Agent and even Microsoft wants to bring this to their customers in Copilot. The most interesting one from these is the new Devin from Cognition.
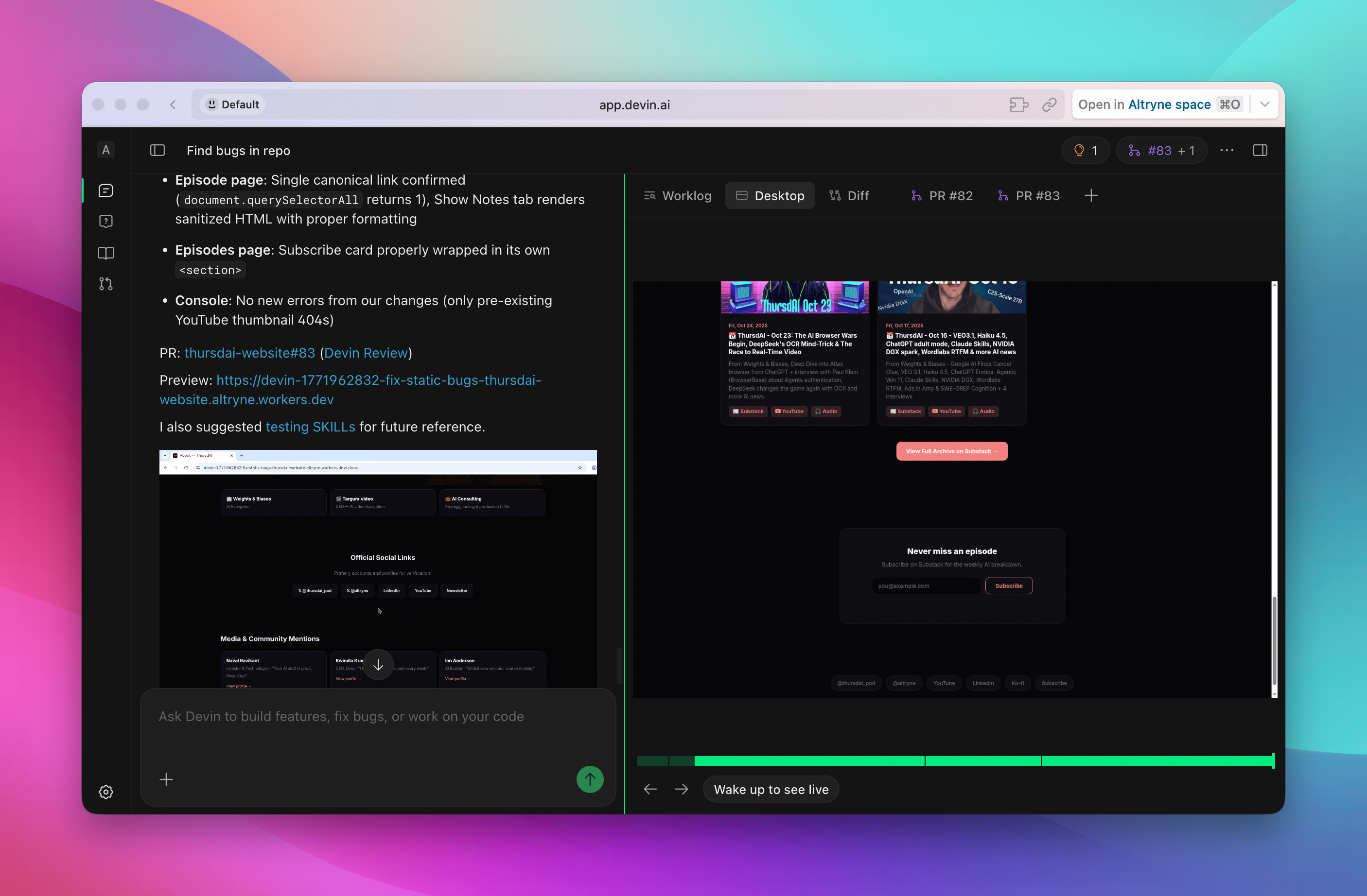
I’ve gotten access and chatted with Nader Dabit on the show about how Devin was the “OG” async coding Agent, but now as models capabilities are here, Devin can do so much more. PR reviews with devinreview.com can complete the loop between coding, fixing and testing something end to end. They have an integrated environment with a scrub so you can roll back and see what the agent did, scheduled tasks and video showing you how the agent tested your website.
I’ve used it to fix bugs in ThrusdAI.news and it found a few that Claude Code didn’t even know about! You can try out Devin (for free for a week?) here
This weeks buzz - W&B updates
I’m happy this week, because we finally launched both 2.5 open source models that we’re making the news lately.
Kimi 2.5 and MiniMax M2.5 are both live on our inference service, at very very decent prices!
Check them both out here and let me know if you need some credits.
From the show this week, most hosts agree that Kimi 2.5 is the best open source alternative to Opus inside OpenClaw, just give your agent the WANDB_API_KEY and ask it to set itself up with the new model!
Surfing the singularity with Ben Broca and Polsia, hitting $700K ARR since December
I’ve reached out to Ben and asked him to join the show this week because alongside OpenClaw blowing up since December, his Polsia startup, which builds and scales entire companies with AI agents running 24x7 has hit an unprecedented $700K ARR milestone after just a few months. We actually saw him break the $700K ARR on the show live 🎉 But get this, he’s the only employee, everything is done with AIs. He’s using Polsia to scale Polsia.
Polsia let’s anyone add an existing company or create a whole new one, and then a team of agents will spin up a marketing team, a GTM motion, a research arm and you and Polsia could work together to make this company a reality. Does this actually work? IDK, the whole thing is new, I’m trying out a few things and will let you know in a few weeks if any of this worked.
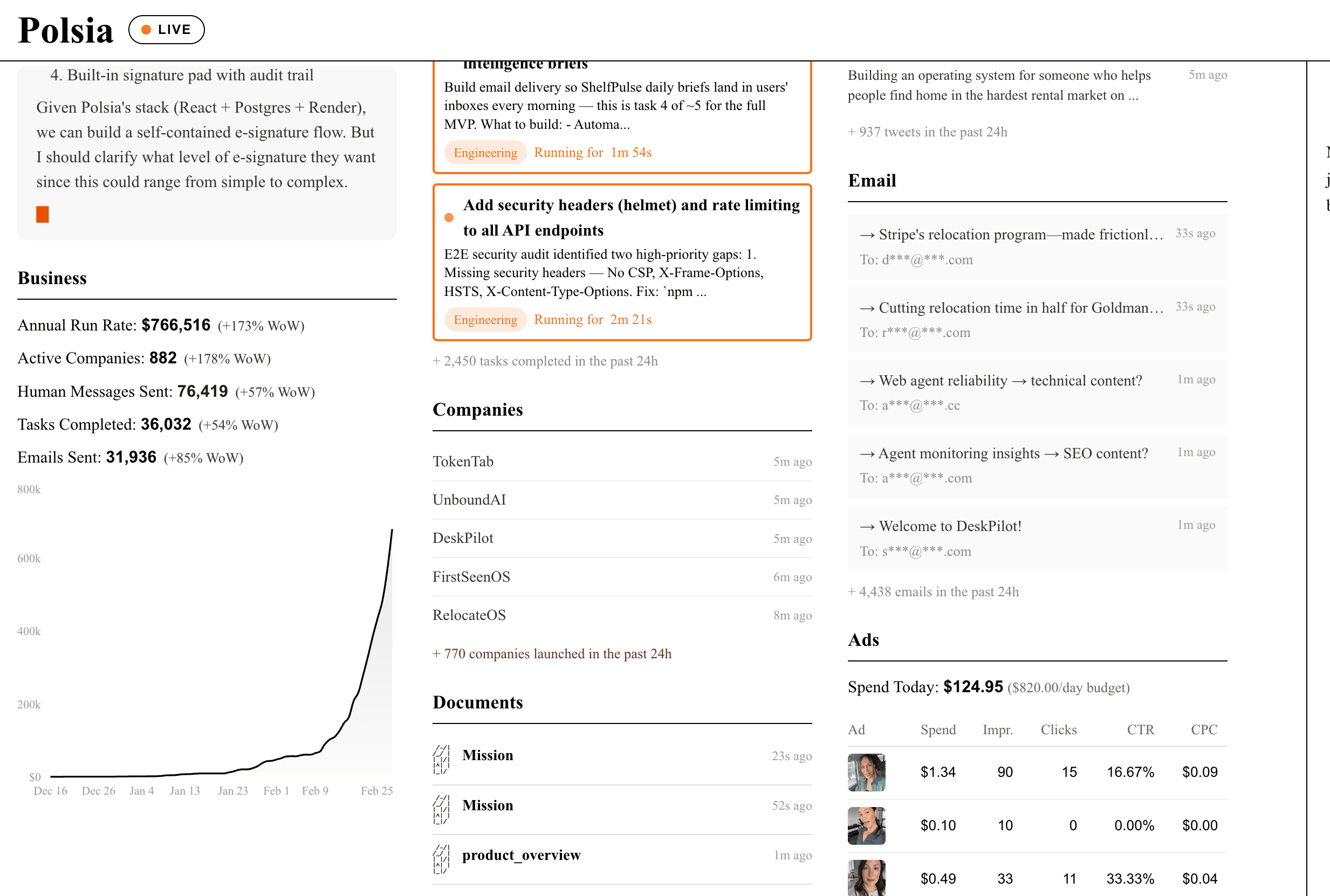
But it’s definitely blowing up, Ben showed us that over the last 24 hours, over 770 companies launched on Polsia, he’s hitting nearly 1M ARR with people paying $50/mo for him to run inference for them, marketing campaigns, and he just added Meta ads.
This ARR chart, the live dashboard, and Ben doing all of this Solo is underlining the whole “Singularity is near” thing for me! It’s impossible to imagine something like this working even... 5 months ago, and now we just accept it as .. sure, yeah, one person can manage AIs that manage checks notes over 700 companies.
What’s clever about Polsia’s architecture is the cross-company learning system: when an agent learns something useful (like “subject lines with emojis get better open rates”), that learning gets anonymized and generalized into a shared memory file that benefits every company on the platform. The more companies running on Polsia, the smarter every agent gets — like a platform effect but for agent intelligence.
AI Art, Video & Audio
Seedance 2.0 is finally “here”
This week has not been quiet in the multimodality world either, SeeDance 2.0 from ByteDance was delayed via the API partners (was supposed to launch Feb 24) due to copyright concerns, but apparently they dropped it inside CapCut, ByteDance’s video editing software! It’s really good though what makes it absolutely incredible IMO is the video transfer, and you can’t really do that in CapCut, so we’re keep waiting for the “full model”
Nano Banana 2 - Pro level intelligence, with Flash speed and pricing (Blog)
Google dropped a breaking news item before the show started today, and announced Nano Banana 2, which is supposed to be as good as Nano Banana Pro (which is incredible) but faster. It wasn’t really faster for me, as I got early access thanks to the DeepMind team, but apparently it’s just the rollout pains. But the quality is nearly matching Nano Banana Pro!

It can do the same super high quality text rendering, comes with a few new ratios to create ultra long images (4:1 and 1:4) and a new small 512 resolution for extra cheap generation. The additional thing is Image Search is now integrated into the model, allowing it to look something up before generating. Though, that didn’t really work for me as well, I tried to get it to look up images of Mike Intrator and Dario Amodei, and it kept showing me random people who look nothing like them, despite the thinking traces showing the search did happen.

Speaking of pricing, this model is around 50-30% cheaper than NBP, which is great given the added speed! Go play with it, it’s available on AI.dev and Gemini, go give it a try!
Open source AI

This week in OpenSource, our friends from Qwen came back with a set of 3 models, the middle medium one is a hybrid architecture with only 3B parameters that beats their 235B flagship Qwen3 from before! It’s really good at longer context especially given the hybrid attention similar to Jamba that we covered before. (X, HF, HF, HF, Blog)
Additionally, Liquid AI releases their largest LFM, 24B (X, HF, Blog) and that is also deployable on consumer laptops.
One note on AI tools, LM Studio, our favorite way of running these models on your hardware, have launched LMLink, powered by Tailscale, which let’s you run local inference on once device and stream tokens to any other device in your network securely! You can use this to run your OpenClaw with Qwen medium for example, for a complete off the grid OpenClaw!
Check it out here: https://lmstudio.ai/link
I really didn’t want to sound hype-y but this week things are moving so fast that I was not sure how it’s possible to talk about all this, covering the news while also having 3 interviews. I think we’ve done a good job, but I am honestly getting to a point whereI have to do deep prioritization of what content is the most important in my eyes. I hope you guys enjoy my prioritization, and do leave comments of what you’d like to see more, or see less of! I am hungry for feedback!
If you enjoyed this week’s newsletter, checkout the whole edited video and share it with a friend or two? See you next week!
Here’s the TL;DR and show notes:
ThursdAI - Feb 26, 2026 - TL;DR
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed @ryancarson
Ben Cera (@bencera_) - Founder Polsia
Nader Dabit (@dabit3) - Growth at Cognition
Philip Kiely (@philipkiely) - Devrel Base10, Author Inference Engineering
ThursdAI new website: https://thursdai.news
Big CO LLMs + APIs
Anthropic vs Chinese OSS - Accuses DeepSeek, Minimax, ZAI at distillation attacks (Blog)
Pentagon Issues an ultimatum to Anthropic: Give military unfettered Claude access by Friday or face Defense Production Act - Anthropic says NO (Blog)
OpenAI releases GPT-5.3-Codex, their most capable agentic coding model, to all developers via the Responses API (X, Announcement)
Open Source LLMs
Alibaba: Qwen 3.5 Medium - 35B model with only 3B active parameters outperforms their previous 235B flagship (X, HF, HF, HF, Blog)
Liquid AI releases LFM2-24B-A2B: A 24B MoE model with only 2.3B active parameters that runs on consumer laptops (X, HF, Blog)
Perplexity launches ppxl-embed - SOTA embedding models (Blog, HF, API) by our friend Bo Wang
Evals & Benchmarks
Tools & Agentic Engineering
Happy 1 year Birthday Claude Code!
Devin AI 2.2 - autonomous agent with computer use, browser, self verify and self fix it’s own work - interview with Nader Dabit (X)
LMStudio launches LMLink - use your local models from everywhere with TailScale! (try it)
Claude Code introduces Remote Control: Control your local coding sessions from your phone or any device (X, Docs) and memory (X)
Claude Cowork and Codex both now have automations (Cron Jobs) to do tasks for you (Cowork)
Cursor launches cloud agents that onboard to codebases, run in isolated VMs, and deliver video demos of completed PRs (X)
Nous research agent (X)
Perplexity Computer (blog)
Microsoft Copilot tasks (blog)
This weeks Buzz - Weights & Biases update
W&B adds MiniMax 2.5 and Kimi K2.5 on our Inference Service (LINK)
Interviews mention links
Ben Broca - polsia.com/live Polsia Dashboard
Nader Dabit - on seeing the future (blog)
Philip Kiely - Inference Engineering book (Book)
Vision & Video
Seedance 2.0 finally available in Capcut in US. API release apparently held back due to copyright issues (X)
Voice & Audio
OpenAI releases gpt-audio-1.5 and gpt-realtime-1.5 models with major improvements in speech-to-speech AI capabilities (X, Announcement)
AI Art & Diffusion & 3D
Google DeepMind launches Nano Banana 2 (X, Announcement)
Quiver solves SVG with Arrow 1.0 (X)
Others
Taalas AI - 15,000 tokens per second demo (chatjimmy.ai/)


