




Hey folks, Alex here from Weights & Biases, with your weekly AI update (and a first live show of this year!)
For the first time, we had a co-host of the show also be a guest on the show, Ryan Carson (from Amp) went supernova viral this week with an X article (1.5M views) about Ralph Wiggum (yeah, from Simpsons) and he broke down that agentic coding technique at the end of the show.
LDJ and Nisten helped cover NVIDIA’s incredible announcements during CES with their Vera Rubin upcoming platform (4-5X improvements) and we all got excited about AI medicine with ChatGPT going into Health officially!
Plus, a bunch of Open Source news, let’s get into this:
Open Source: The “Small” Models Are Winning
We often talk about the massive frontier models, but this week, Open Source came largely from unexpected places and focused on efficiency, agents, and specific domains.
Solar Open 100B: A Data Masterclass
Upstage released Solar Open 100B, and it’s a beast. It’s a 102B parameter Mixture-of-Experts (MoE) model, but thanks to MoE magic, it only uses about 12B active parameters during inference. This means it punches incredibly high but runs fast.

What I really appreciated here wasn’t just the weights, but the transparency. They released a technical report detailing their “Data Factory” approach. They trained on nearly 20 trillion tokens, with a huge chunk being synthetic. They also used a dynamic curriculum that adjusted the difficulty and the ratio of synthetic data as training progressed. This transparency is what pushes the whole open source community forward.
Technically, it hits 88.2 on MMLU and competes with top-tier models, especially in Korean language tasks. You can grab it on Hugging Face.
MiroThinker 1.5: The DeepSeek Moment for Agents?
We also saw MiroThinker 1.5, a 30B parameter model that is challenging the notion that you need massive scale to be smart. It uses something they call “Interactive Scaling.”
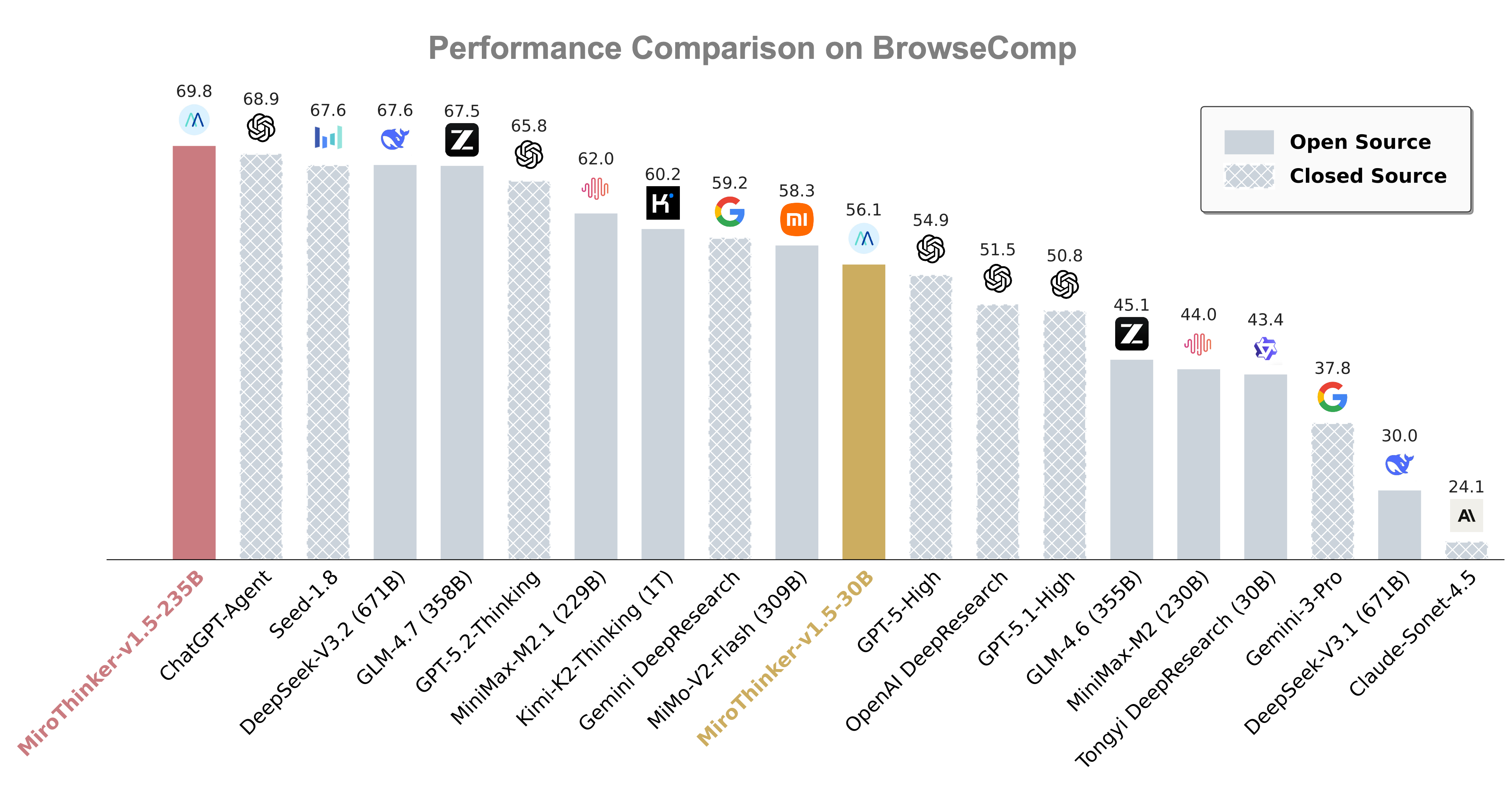
Wolfram broke this down for us: this agent forms hypotheses, searches for evidence, and then iteratively revises its answers in a time-sensitive sandbox. It effectively “thinks” before answering. The result? It beats trillion-parameter models on search benchmarks like BrowseComp. It’s significantly cheaper to run, too. This feels like the year where smaller models + clever harnesses (harnesses are the software wrapping the model) will outperform raw scale.
Liquid AI LFM 2.5: Running on Toasters (Almost)

We love Liquid AI and they are great friends of the show. They announced LFM 2.5 at CES with AMD, and these are tiny ~1B parameter models designed to run on-device. We’re talking about running capable AI on your laptop, your phone, or edge devices (or the Reachy Mini bot that I showed off during the show! I gotta try and run LFM on him!)
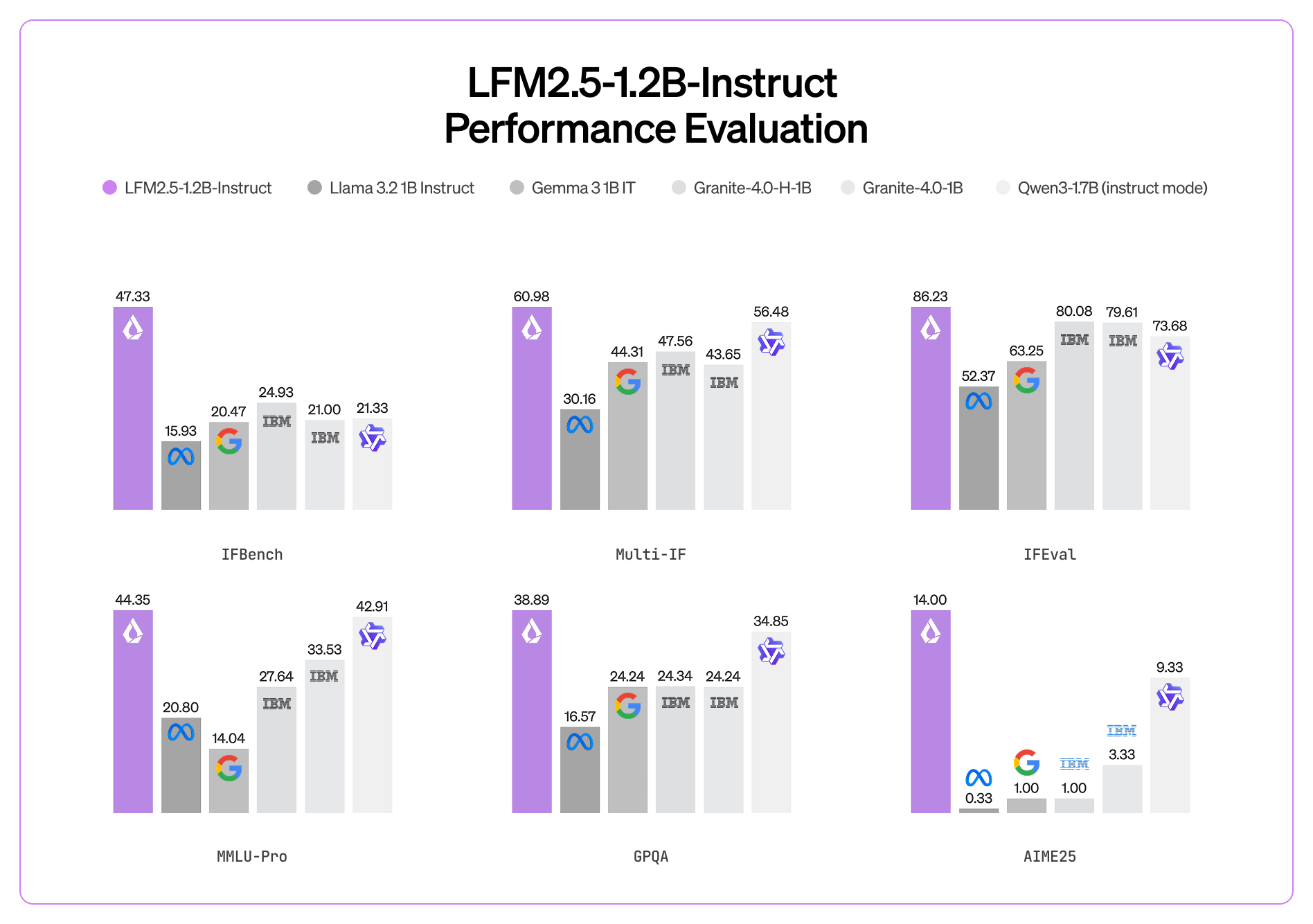
Probably the coolest part is the audio model. Usually, talking to an AI involves a pipeline: Speech-to-Text (ASR) -> LLM -> Text-to-Speech (TTS). Liquid’s model is end-to-end. It hears audio and speaks audio directly. We watched a demo from Maxime Labonne where the model was doing real-time interaction, interleaving text and audio. It’s incredibly fast and efficient. While it might not write a symphony for you, for on-device tasks like summarization or quick interactions, this is the future.
NousCoder-14B and Zhipu AI IPO
A quick shoutout to our friends at Nous Research who released NousCoder-14B, an open-source competitive programming model that achieved a 7% jump on LiveCodeBench accuracy in just four days of RL training on 48 NVIDIA B200 GPUs. The model was trained on 24,000 verifiable problems, and the lead researcher Joe Li noted it achieved in 4 days what took him 2 years as a teenager competing in programming contests. The full RL stack is open-sourced on GitHub and Nous published a great WandB results page as well!
And in historic news, Zhipu AI (Z.ai)—the folks behind the GLM series—became the world’s first major LLM company to IPO, raising $558 million on the Hong Kong Stock Exchange. Their GLM-4.7 currently ranks #1 among open-source and domestic models on both Artificial Analysis and LM Arena. Congrats to them!
Big Companies & APIs
NVIDIA CES: Vera Rubin Changes Everything

LDJ brought the heat on this one covering Jensen’s CES keynote that unveiled the Vera Rubin platform, and the numbers are almost hard to believe. We’re talking about a complete redesign of six chips: the Rubin GPU delivering 50 petaFLOPS of AI inference (5x Blackwell), the Vera CPU with 88 custom Olympus ARM cores, NVLink 6, ConnectX-9 SuperNIC, BlueField-4 DPU, and Spectrum-6 Ethernet.

Let me put this in perspective using LDJ’s breakdown: if you look at FP8 performance, the jump from Hopper to Blackwell was about 5x. The jump from Blackwell to Vera Rubin is over 3x again—but here’s the kicker—while only adding about 200 watts of power draw. That’s insane efficiency improvement.

The real-world implications Jensen shared: training a 10 trillion parameter mixture-of-experts model now requires 75% fewer GPUs compared to Blackwell. Inference token costs drop roughly 10x—a 1MW cluster goes from 1 million to 10 million tokens per second at the same power. HBM4 memory delivers 22 TB/s bandwidth with 288GB capacity, exceeding NVIDIA’s own 2024 projections by nearly 70%.
As Ryan noted, when people say there’s an AI bubble, this is why it’s hilarious. Jensen keeps saying the need for inference is unbelievable and only going up exponentially. We all see this. I can’t get enough inference—I want to spin up 10 Ralphs running concurrently! The NVL72 rack-scale system achieves 3.6 exaFLOPS inference with 20.7TB total HBM, and it’s already shipping. Runway 4.5 is already running on the new platform, having ported their model from Hopper to Vera Rubin NVL72 in a single day.
NVIDIA also recently acqui-hidred Groq (with a Q) in a ~$20 billion deal, bringing the inference chip expertise from the guy who created Google’s TPUs in-house.
Nemotron Speech ASR & The Speed of Voice (X, HF, Blog)
NVIDIA also dropped Nemotron Speech ASR. This is a 600M parameter model that offers streaming transcription with 24ms latency.
We showed a demo from our friend Kwindla Kramer at Daily. He was talking to an AI, and the response was virtually instant. The pipeline is: Nemotron (hearing) -> Llama/Nemotron Nano (thinking) -> Magpie TTS (speaking). The total latency is under 500ms. It feels like magic. Instant voice agents are going to be everywhere this year.
XAI Raises $20B While Grok Causes Problems (Again)

So here’s the thing about covering anything Elon-related: it’s impossible to separate signal from noise because there’s an army of fans who hype everything and an army of critics who hate everything. But let me try to be objective here.
XAI raised another massive Round E of $20 billion! at a $230 billion valuation, with NVIDIA and Cisco as strategic investors. The speed of their infrastructure buildout is genuinely incredible. Grok’s voice mode is impressive. I use Grok for research and it’s really good, notable for it’s unprecedented access to X !
But. This raise happened in the middle of a controversy where Grok’s image model was being used to “put bikinis” on anyone in reply threads, including—and this is where I draw a hard line—minors. As Nisten pointed out on the show, it’s not even hard to implement guardrails. You just put a 2B VL model in front and ask “is there a minor in this picture?” But people tested it, asked Grok not to use the feature, and it did it anyway. And yeah, putting Bikini on Claude is funny, but basic moderation is lacking!
The response of “we’ll prosecute illegal users” is stupid when there’s no moderation built into the product. There’s an enormous difference between Photoshop technically being able to do something after hours of work, and a feature that generates edited images in one second as the first comment to a celebrity, then gets amplified by the platform’s algorithm to millions of people. One is a tool. The other is a product with amplification mechanics. Products need guardrails. I don’t often link to CNN (in fact this is the first time) but they have a great writeup about the whole incident here which apparently includes the quitting of a few trust and safety folks and Elon’s pushback on guardrails. Crazy
That said, Grok 5 is in training and XAI continues to ship impressive technology. I just wish they’d put the same engineering effort into safety as they do into capabilities!
OpenAI Launches GPT Health

This one’s exciting. OpenAI CEO Fidji Simo announced ChatGPT Health, a privacy-first space for personalized health conversations that can connect to electronic health records, Apple Health, Function Health, Peloton, and MyFitnessPal.
Here’s why this matters: health already represents about 5% of all ChatGPT messages globally and touches 25% of weekly active users—often outside clinic hours or in underserved areas. People are already using these models for health advice constantly.
Nisten, who has worked on AI doctors since the GPT-3 days and even published papers on on-device medical AI, gave us some perspective: the models have been fantastic for health stuff for two years now. The key insight is that medical data seems like a lot, but there are really only about 2,000 prescription drugs and 2,000 diseases (10,000 if you count rare ones). That’s nothing for an LLM. The models excel at pattern recognition across this relatively contained dataset.
The integration with Function Health is particularly interesting to me. Function does 160+ lab tests, but many doctors won’t interpret them because they didn’t order them. ChatGPT could help bridge that gap, telling you “hey, this biomarker looks off, you should discuss this with your doctor.” The bad news is, this is just a waitlist and you can add yourself to the waitlist here, we’ll keep monitoring the situation and let you know when it opens up
Doctronic: AI Prescribing Without Physician Oversight

Speaking of healthcare, Doctronic launched a pilot in Utah where AI can autonomously renew prescriptions for chronic conditions without any physician in the loop. The system covers about 190 routine medications (excluding controlled substances) at just $4 per renewal. Trial data showed 99.2% concordance with physician treatment plans, and they’ve secured pioneering malpractice insurance that treats the AI like a clinician.
Nisten made the case that it’s ethically wrong to delay this kind of automation when ER wait times keep increasing and doctors are overworked. The open source models are already excellent at medical tasks. Governments should be buying GPUs rather than creating administrative roadblocks. Strong strong agree here!
Google Brings Gmail into the Gemini Era (X)

Breaking news from the day of our show: Google announced Gmail’s biggest AI transformation since its 2004 launch, powered by Gemini 3. This brings AI Overviews that summarize email threads, natural language queries (”Who gave me a plumber quote last year?”), Help Me Write, contextual Suggested Replies matching your writing style, and the upcoming AI Inbox that filters noise to surface VIPs and urgent items.
For 3 billion Gmail users, this is huge. I’m very excited to test it—though not live on the show because I don’t want you reading my emails.
This weeks buzz - covering Weights & Biases updates

Not covered on the show, but a great update on stuff from WandB, Chris Van Pelt (@vanpelt), one of the 3 co-founders released a great project I wanted to tell you about! For coders, this is an app that allows you to run multiple Claude Codes on free Github sandboxes, so you can code (or Ralph) and control everything away from home!
GitHub gives personal users 120 free Codespaces hours/month, and Catnip automatically shuts down inactive instances so you can code for quite a while with Catnip!
It’s fully open source on Github and you can download the app here
Interview: Ryan Carson - What the hell is Ralph Wiggum?

Okay, let’s talk about the character everyone is seeing on their timeline: Ralph Wiggum. My co-host Ryan Carson went viral this week with an article about this technique, and I had to have him break it down.
Ralph isn’t a new model; it’s a technique for running agents in a loop to perform autonomous coding. The core idea is deceptively simple: Ralph is a bash script that loops an AI coding agent. In a loop, until it a certain condition is met. But why is it blowing up?
Normally when you use a coding agent like Cursor, Claude Code, or AMP, you need to be in the loop. You approve changes, look at code, fix things when the agent hits walls or runs out of context. Ralph solves this by letting the agent run autonomously while you sleep.
Here’s how it works: First, you write a Product Requirements Doc (PRD) by talking to your agent for a few minutes about what you want to build. Then you convert that PRD into a JSON file containing atomic user stories with clear acceptance criteria. Each user story is small enough for the agent to complete in one focused thread.
The Ralph script then loops: it picks the first incomplete user story, the agent writes code to implement it, tests against the acceptance criteria, commits the changes, marks the story as complete, writes what it learned to a shared “agents.md” file, and loops to the next story. That compound learning step is crucial—without it, the agent would keep making the same mistakes.
What makes this work is the pre-work. As Ryan put it, “no real work is done one-shot.” This is how software engineering has always worked—you break big problems into smaller problems into user stories and solve them incrementally. The innovation is letting AI agents work through that queue autonomously while you sleep! Ryan’s excellent (and viral) X article is here!
Vision & Video
LTX-2 Goes Fully Open Source (HF, Paper)
Lightricks finally open-sourced LTX-2, marking a major milestone as the first fully open audio-video generation model. This isn’t just “we released the weights” open—it’s complete model weights (13B and 2B variants), distilled versions, controllable LoRAs, a full multimodal trainer, benchmarks, and evaluation scripts. For a video model that is aiming to be the open source SORA, supports audio and lipsync
The model generates synchronized audio and video in a single DiT-based architecture—motion, dialogue, ambience, and music flow simultaneously. Native 4K at up to 50 FPS with audio up to 10 seconds. And there’s also a distilled version (Thanks Pruna AI!) hosted on Replicate
ComfyUI provided day-0 native support, and community testing shows an A6000 generating 1280x720 at 120 frames in 50 seconds. This is near Sora-level quality that you can fine-tune on your own data for custom styles and voices in about an hour.
What a way to start 2026. From chips that are 5x faster to AI doctors prescribing meds in Utah, the pace is only accelerating. If anyone tells you we’re in an AI bubble, just show them what we covered today. Even if the models stopped improving tomorrow, the techniques like “Ralph” prove we have years of work ahead of us just figuring out how to use the intelligence we already have.
Thank you for being a ThursdAI subscriber. See you next week!
As always, here’s the show notes and TL;DR links:
Hosts & Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co-Hosts - @WolframRvnwlf, @nisten, @ldjconfirmed
Special Guest - Ryan Carson (@ryancarson) breaking down the Ralph Wiggum technique.
Open Source LLMs
Solar Open 100B - Upstage’s 102B MoE model. Trained on 19.7T tokens with a heavy focus on “data factory” synthetic data and high-performance Korean reasoning (X, HF, Tech Report).
MiroThinker 1.5 - A 30B parameter search agent that uses “Interactive Scaling” to beat trillion-parameter models on search benchmarks like BrowseComp (X, HF, GitHub).
Liquid AI LFM 2.5 - A family of 1B models designed for edge devices. Features a revolutionary end-to-end audio model that skips the ASR-LLM-TTS pipeline (X, HF).
NousCoder-14B - competitive coding model from Nous Research that saw a 7% LiveCodeBench accuracy jump in just 4 days of RL (X, WandB Dashboard).
Zhipu AI IPO - The makers of GLM became the first major LLM firm to go public on the HKEX, raising $558M (Announcement).
Big Co LLMs & APIs
NVIDIA Vera Rubin - Jensen Huang’s CES reveal of the next-gen platform. Delivers 5x Blackwell inference performance and 75% fewer GPUs needed for MoE training (Blog).
OpenAI ChatGPT Health - A privacy-first vertical for EHR and fitness data integration (Waitlist).
Google Gmail Era - Gemini 3 integration into Gmail for 3 billion users, featuring AI Overviews and natural language inbox search (Blog).
XAI $20B Raise - Elon’s XAI raises Series E at a $230B valuation, even as Grok faces heat over bikini-gate and safety guardrails (CNN Report).
Doctronic - The first US pilot in Utah for autonomous AI prescription renewals without a physician in the loop (Web).
Alexa+ Web - Amazon brings the “Smart Alexa” experience to browser-based chat (Announcement).
Autonomous Coding & Tools
Ralph Wiggum - The agentic loop technique for autonomous coding using small, atomic user stories. Ryan Carson’s breakdown of why this is the death of “vibe coding” (Viral X Article).
Catnip by W&B - Chris Van Pelt’s open-source iOS app to run Claude Code anywhere via GitHub Codespaces (App Store, GitHub).
Vision & Video
LTX-2 - Lightricks open-sources the first truly open audio-video generation model with synchronized output and full training code (GitHub, Replicate Demo).
Avatar Forcing - KAIST’s framework for real-time interactive talking heads with ~500ms latency (Arxiv).
Qwen Edit 2512 - Optimized by PrunaAI to generate high-res realistic images in under 7 seconds (Replicate).
Voice & Audio
Nemotron Speech ASR - NVIDIA’s 600M parameter streaming model with sub-100ms stable latency for massive-scale voice agents (HF).


