



Hey, it’s Alex, let me catch you up!
Since last week, OpenAI convinced OpenClaw founder Peter Steinberger to join them, while keeping OpenClaw.. well... open. Anthropic dropped Sonnet 4.6 which nearly outperforms the previous Opus and is much cheaper, Qwen released 3.5 on Chinese New Year’s Eve, while DeepSeek was silent and Elon and XAI folks deployed Grok 4.20 without any benchmarks, and it’s 4 500B models in a trenchcoat?
Also, Anthropic updated rules state that it’s breaking ToS to use their plans for anything except Claude Code & Claude SDK (and then clarified that it’s OK? we’re not sure)
Then Google decided to drop their Gemini 3.1 Pro preview right at the start of our show, and it’s very nearly the best LLM folks can use right now (though it didn’t pass Nisten’s vibe checks)
Also, Google released Lyria 3 for music gen (though only 30 seconds?) and our own Ryan Carson blew up on X again with over 1M views for his Code Factory article, Wolfram did a deep dive into Terminal Bench and .. we have a brand new website:
Great week all in all, let’s dive in!
Big Companies & API updates
Google releases Gemini 3.1 Pro with 77.1% on ARC-AGI-2 (X, Blog, Announcement)
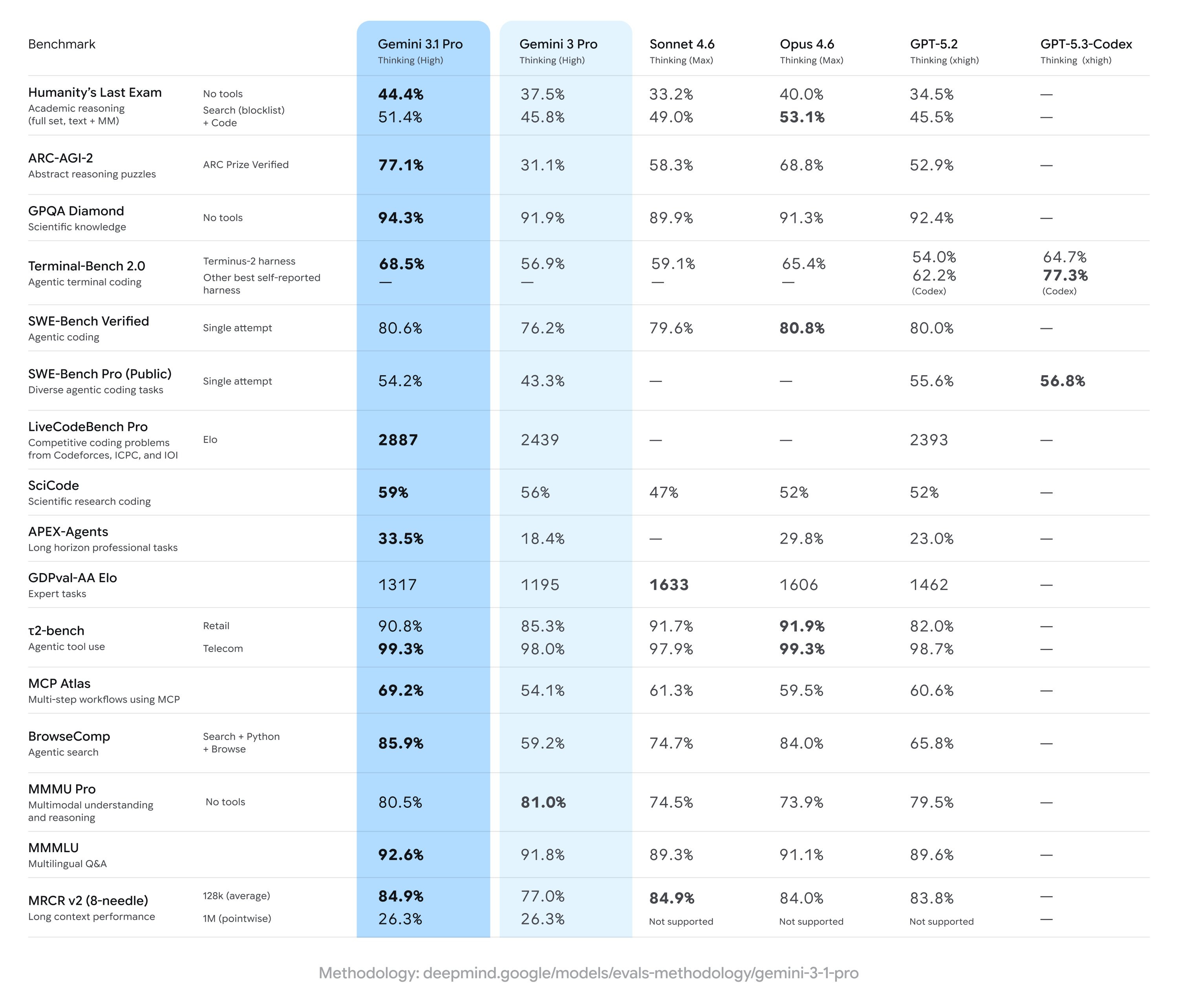
In a release that surprised no-one, Google decided to drop their latest update to Gemini models, and it’s quite a big update too! We’ve now seen all major labs ship big model updates in the first two months of 2026. With 77.1% on ARC-AGI 2, and 80.6% on SWE-bench verified, Gemini is not complete SOTA across the board but it’s damn near close.
The kicker is, it’s VERY competitive on the pricing, with 1M context, $2 / $12 (<200k tokens), and Google’s TPU speeds, this is now the model to beat! Initial vibe checks live on stage did not seem amazing, Nisten wasn’t super impressed, Ryan took one glance at the SWE-bench pro not being SOTA and decided to skip, and he’s added that, at some point, it is benefitting to pick a model and stick to it, the constant context switching is really hard for folks who want to keep shipping.
But if you look at the trajectory, it’s really notable how quickly we’re moving, with this model being 82% better on abstract reasoning than the 3 pro released just a few months ago!
The 1 Million Context Discrepancy, who’s better at long context?
The most fascinating catch of the live broadcast came from LDJ, who has an eagle eye for evaluation tables. He immediately noticed something weird in Google’s reported benchmarks regarding long-context recall. On the MRCR v2 8-needle benchmark (which tests retrieval quality deep inside a massive context window), Google’s table showed Gemini 3.1 Pro getting a 26% recall score at 1 million tokens. Curiously, they marked Claude Opus 4.6 as “not supported” in that exact tier.
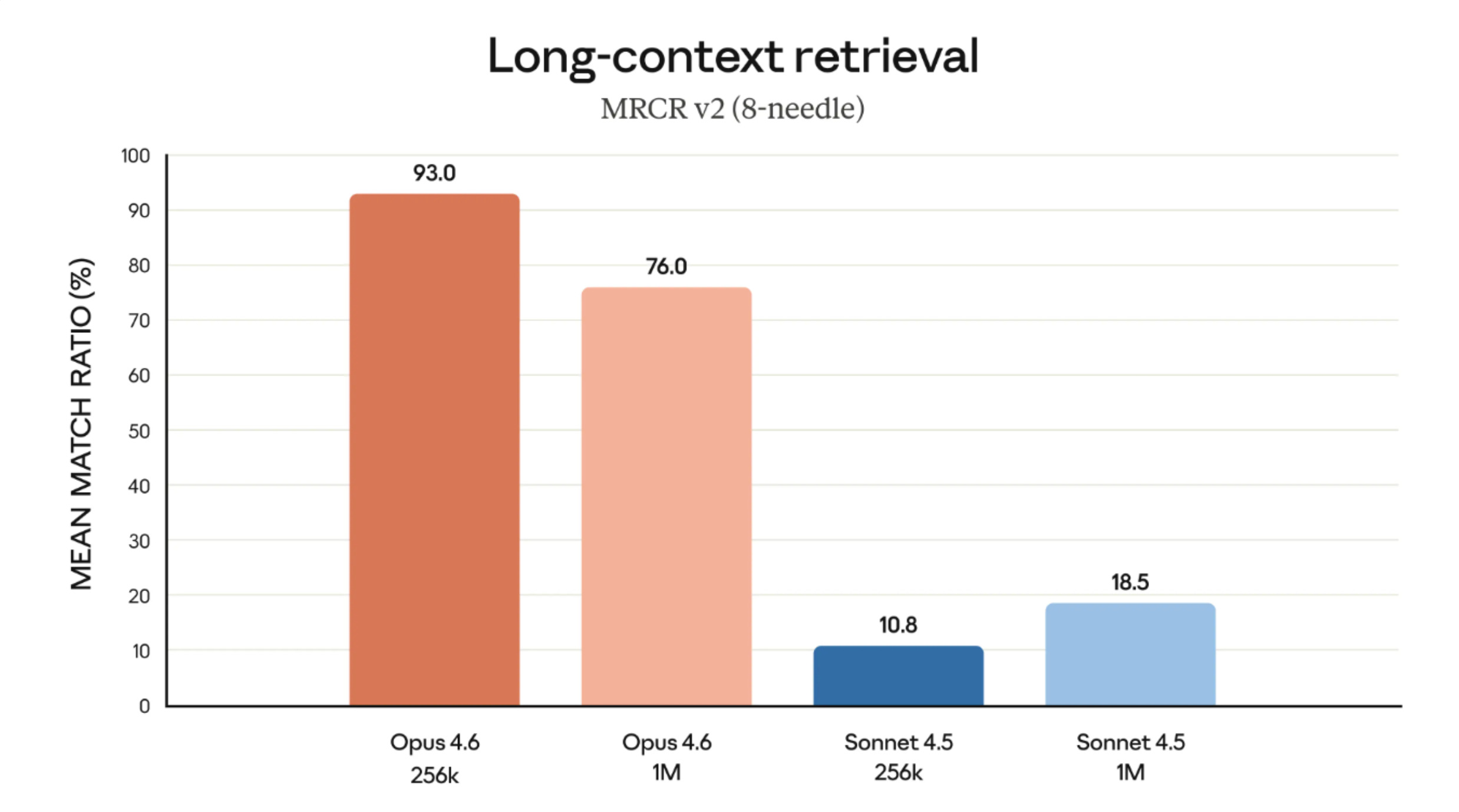
LDJ quickly pulled up the actual receipts: Opus 4.6 at a 1-million context window gets a staggering 76% recall score. That is a massive discrepancy! It was addressed by a member of DeepMind on X in a response to me, saying that Anthropic used an internal model for evaluating this (with receipts he pulled from the Anthropic model card)
Live Vibe-Coding Test for Gemini 3.1 Pro
We couldn’t just stare at numbers, so Nisten immediately fired up AI Studio for a live vibe check. He threw our standard “build a mars driver simulation game” prompt at the new Gemini.
The speed was absolutely breathtaking. The model generated the entire single-file HTML/JS codebase in about 20 seconds. However, when he booted it up, the result was a bit mixed. The first run actually failed to render entirely. A quick refresh got a version working, and it rendered a neat little orbital launch UI, but it completely lacked the deep physics trajectories and working simulation elements that models like OpenAI’s Codex 5.3 or Claude Opus 4.6 managed to output on the exact same prompt last week. As Nisten put it, “It’s not bad at all, but I’m not impressed compared to what Opus and Codex did. They had a fully working one with trajectories, and this one I’m just stuck.”
It’s a great reminder that raw benchmarks aren’t everything. A lot of this comes down to the harness—the specific set of system prompts and sandboxes that the labs use to wrap their models.
Anthropic launches Claude Sonnet 4.6, with 1M token context and near-Opus intelligence at Sonnet pricing
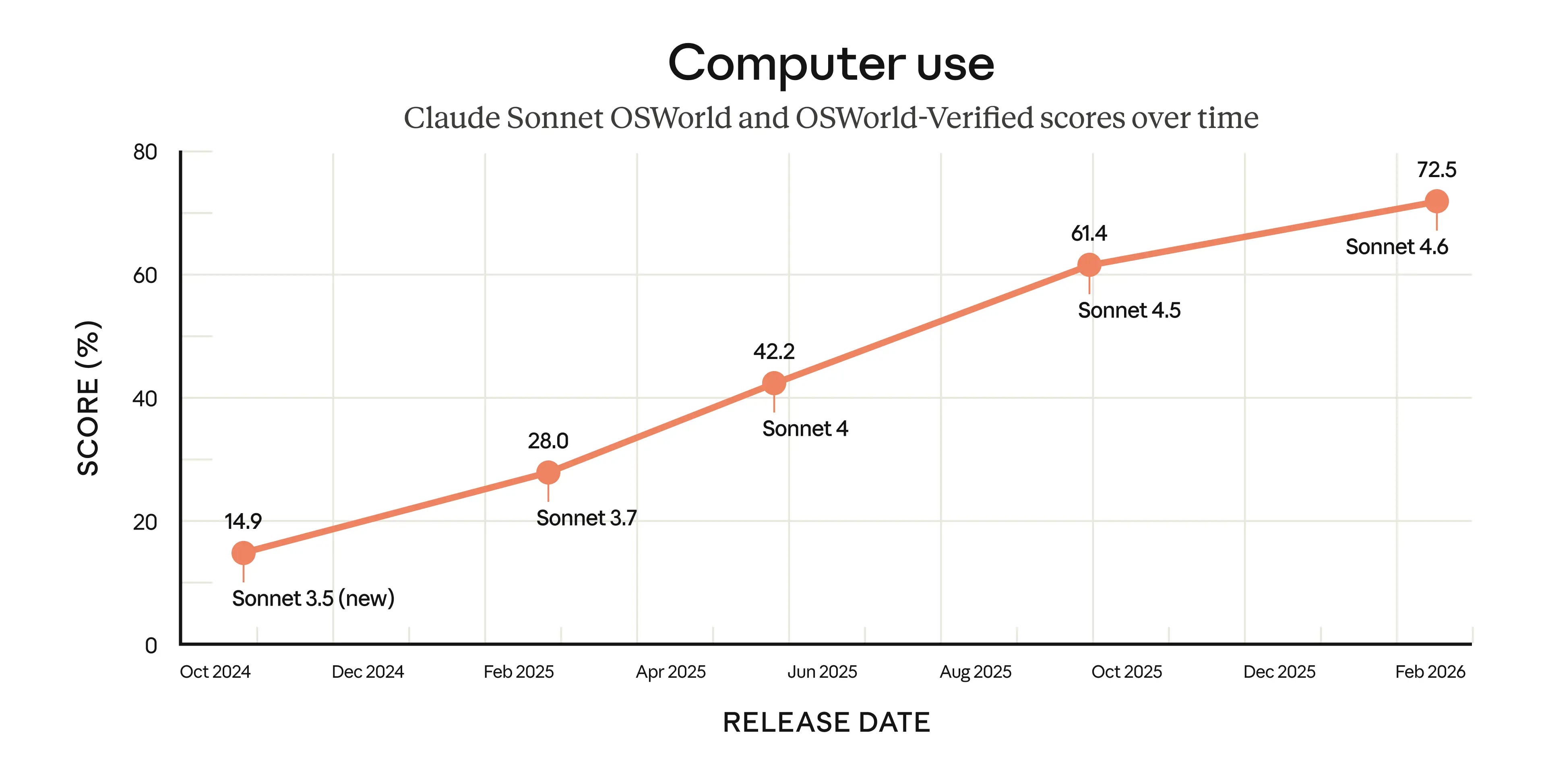
The above Gemini release comes just a few days after Anthropic has shipped an update to the middle child of their lineup, Sonnet 4.6. With much improved Computer Use skills, updated Beta mode for 1M tokens, it achieves 79.6% on SWE-bench verified eval, showing good coding performance, while maintaining that “anthropic trained model” vibes that many people seem to prefer.
Apparently in blind testing inside Claude Code, folks preferred this new model outputs to the latest Opus 4.5 around ~60% of the time, while preferring it over the previous sonnet 70% of the time.
With $3/$15 per million tokens pricing, it’s cheaper than Opus, but is still more expensive than the flagship Gemini model, while being quite behind.
Vibing with Sonnet 4.6
I’ve tested out Sonnet 4.6 inside my OpenClaw harness for a few days, and it was decent. It did annoy me a bit more than Opus, with misunderstanding what I ask it, but it definitely does have the same “emotional tone” as Opus. Comparing it to Codex 5.3 is very easy, it’s much nicer to talk to. IDK what kind of Anthropic magic they put in there, but if you’re on a budget, Sonnet is definitely the way to go when interacting with Agents (and you can get it to orchestrate as many Codex instances as you want if you don’t like how it writes code)
For Devs: Auto prompt caching and Web Search updates
One nice update Anthropic also dropped is that prompt caching (which leads to almost 90% decrease in token pricing) for developers (Blog) and a new and improved Web Search for everyone else that can now use tools
Grok 4.20 - 4 groks in a trenchcoat?

In a very weird release, Grok has been updated with the long hyped Grok 4.20. Elon has been promising this version for a while (since late last year in fact) and this “release” definitely felt underwhelming. There was no evaluations, no comparisons to other labs models, no charts (heck, not even a blogpost on X.ai).
What we do know, is that Grok 4.20 (and Grok 4.20 Heavy) use multiple agents (4 for Grok, 16 for Heavy) to do a LOT of research and combine their answers somehow. This is apparently what the other labs use for their ultra expensive models (GPT Pro and Gemini DeepThink) but Grok is showing it in the UI, and gives these agents... names and personalities.
Elon has confirmed also that what’s deployed right now is ~500B “small” base version, and that bigger versions are coming, in one of the rarest confirmations about model size from the big labs.
Vibe checking this new grok, it’s really fast at research across X and the web, but I don’t really see it as a daily driver for anyone who converses with LLMs all the time. Supposedly they are planning to keep teaching this model and get it “improved week over week” so I’ll keep you up to date with major changes here.
Open Source AI
It seems that all the chinese OSS labs were shipping before the Chinese New Year, with Qwen being the last one of them, dropping the updated Qwen 3.5.
Alibaba’s Qwen3.5 397B-A17B: First open-weight native multimodal MoE model (X, HF)

Qwen decided to go for Sparse MoE architecture with this release, with a high number of experts (512) and only 17B active parameters.
It’s natively multi-modal with a hybrid architecture, able to understand images/text, while being comparable to GPT 5.2 and Opus 4.5 on benches including agentic tasks.
Benchmarks aside, the release page of Qwen models is a good sniff test on where these model labs are going, they have multimodality in there, but they also feature an example of how to use this model within OpenClaw, which doesn’t necessarily show off any specific capabilities, but shows that the Chinese labs are focusing on agentic behavior, tool use and mostl of all pricing!
This model is also available as Qwen 3.5 Max with 1M token window (as opposed to the 256K native one on the OSS side) on their API.
Agentic Coding world - The Clawfather is joining OpenAI, Anthropic loses dev mindshare

This was a heck of a surprise to many folks, Peter Steinberger, announced that he’s joining OpenAI, while OpenClaw (that now sits on >200K stars in Github, and is adopted by nearly every Chinese lab) is going to become an Open Source foundation.
OpenAI has also confirmed that it’s absolutely ok to use your ChatGPT plus/pro subscriptions to use inside OpenClaw, and it’s really a heck of a thing to see how quickly Peter jumped from relative anonymity (after scaling and selling PSPDFKIT ) into a spotlight. Apparently Mark Zuckerberg reached out directly as well as Sam Altman, and Peter decided to go with OpenAI despite Zuck offering more money due to “culture”
This whole ClawdBot/OpenClaw debacle also shines a very interesting and negative light on Anthropic, who recently changed their ToS to highlight that their subscription can only be used for Claude Code and nothing else. This scared a lot of folks who used their Max subscription to run their Claws 24/7. Additionally Ryan echoed how the community feel about lack of DevEx/Devrel support from Anthropic in a viral post.
However, it does not seem like Anthropic cares? Their revenue is going exponential (much of it due to Claude Code)

Very interestingly, I went to a local Claude Code meetup here in Denver, and the folks there are.. a bit behind the “bubble” on X. Many of them didn’t even try Codex 5.3 or OpenClaw, they are maximizing their time with Claude Code like there’s no tomorrow. It has really shown me that the alpha keeps changing really fast, and many folks don’t have the time to catch up!
P.S - this is why ThursdAI exists, and I’m happy to deliver the latest news to ya.
This Week’s Buzz from Weights & Biases
Our very own Wolfram Ravenwolf took over the Buzz corner this week to school us on the absolute chaos that is AI benchmarking. With his new role at W&B, he’s been stress-testing all the latest models on Terminal Bench 2.0.
Why Terminal Bench? Because if you are building autonomous agents, multiple-choice tests like MMLU are basically useless now. You need to know if an agent can actually interact with an environment. Terminal Bench asks the agent to perform 89 real-world tasks inside a sandboxed Linux container—like building a Linux kernel or cracking a password-protected archive.
Wolfram highlighted some fascinating nuances that marketing slides never show you. For example, did you know that on some agentic tasks, turning off the model’s “thinking/reasoning” mode actually results in a higher score? Why? Because overthinking generates so many internal tokens that it fills the context window faster, causing the model to hit its limits and fail harder than a standard zero-shot model! Furthermore, comparing benchmarks between labs is incredibly difficult because changing the benchmark’s allowed runtime from 1 hour to 2 hours drastically raises the ceiling of what models can achieve.
He also shared a great win: while evaluating GLM-5 for our W&B inference endpoints, he got an abysmal 5% score. By pulling up the Weave trace data, Wolfram immediately spotted that the harness was injecting brain-dead Python syntax errors into the environment. He reported it, engineering fixed it in minutes, and the score shot up to its true state-of-the-art level. This is exactly why you need powerful tracing and evaluation tools when dealing with these black boxes! So y’know... check out Weave!
Vision & BCI
Zyphra’s ZUNA: Thought-to-Text Gets Real (X, Blog, GitHub)

LDJ flagged this as his must-not-miss: Zyphra released ZUNA, a 380M parameter open-source BCI (Brain-Computer Interface) foundation model. It takes EEG signals from your brain and reconstructs clinical-grade brain signals from sparse, noisy data. People are literally calling it “thought to text” hahaha.
At 380M parameters, it could potentially run in real-time on a consumer GPU. Trained on 2 million channel-hours of EEG data from 208 datasets. The wild part: it can upgrade cheap $500 consumer EEG headsets to high-resolution signal quality without retraining, something many folks are posting about and are excited to test out! Non Invasive BCI is the dream!
Nisten was genuinely excited, noting it’s probably the best effort in this field and it’s fully Apache 2.0. Will probably need personalized training per person, but the potential is real: wear a headset, look at a screen, fire up your agents with your thoughts. Not there yet, but this feels like the actual beginning.
Tools & Agentic Coding (The End of “Vibe Coding”) - Ryan Carson’s Code Factory & The “One-Shot Myth”
This one is for developers, but in modern times, everyone can become a developer so if you’re not one, at least skim this.

We spent a big chunk of the show today geeking out over agentic workflows. Ryan Carson went incredibly viral on X again this week with a phenomenal deep-dive on establishing a “Code Factory.” If you are still just chatting with models and manually copying code back into your IDE, you are doing it wrong.
Ryan’s methodology (heavily inspired by a recent OpenAI paper on harness engineering) treats your AI agents like a massive team of junior engineers. You don’t just ask them for code and ship it. You should build a rigid, machine-enforced loop.
Here is the flow:
The coding agent (Codex, OpenClaw, etc.) writes the code.
The GitHub repository enforces risk-aware checks. If a core system file or route is touched, the PR is automatically flagged as high risk.
A secondary code review agent (like Greptile) kicks off and analyzes the PR.
CI/CD GitHub Actions run automated tests, including browser testing.
If a test fails, or the review agent leaves a comment, a remediation agent is automatically triggered to fix the issue and loop back.
The loop spins continuously until you get a flawless, green PR.
As Ryan pointed out, we used to hate this stuff as human engineers. Waiting for CI to pass made you want to pull your hair out. But agents have infinite time and infinite patience. You force them to grind against the machine-enforced contract (YAML/JSON gates) until they get it right. It takes a week to set up properly, and you have to aggressively fight “document drift” to make sure your AI doesn’t forget the architecture, but once it’s humming, you have unprecedented leverage.
My Hard Truth: One-Shot is a Myth I completely agree with Ryan btw! Over the weekend, my OpenClaw agent kindly informed me that the hosting provider for the old ThursdAI website was shutting down. I needed a new website immediately.
I decided to practice what we preach and talk to my ClawdBot to build the entire thing. It was an incredible process. I used Opus 4.6 to mock up 3 designs based on other podcast sites. Then, I deployed a swarm of sub-agents to download and read the raw text transcripts of all 152 past episodes of our show. Their job was to extract the names of every single guest (over 160 guests, including 15 from Google alone!) to build a dynamic guest directory, generating a dedicated SEO page and dynamic OpenGraph tag for every single one of them, a native website podcast player with synced sections, episode pages with guests highlighted and much more. It would have taken me months to write the code for this myself.
Was it magical? Yes. But was it one-shot? Absolutely not.
The amount of back-and-forth conversation, steering, and correction I had to provide to keep the CSS coherent across pages was exhausting. I set up an automation to work while I slept, and I would wake up every morning to a completely different, sometimes broken website.
Yam Peleg chimed in with the quote of the week: “It’s not a question of whether a model can mess up your code, it’s just a matter of when. Because it is a little bit random all the time. Humans don’t mistakenly delete the entire computer. Models can mistakenly, without even realizing, delete the entire computer, and a minute later their context is compacted and they don’t even remember doing it.”
This is why you must have gates. This is also why I don’t think engineers are going to be replaced with AI completely. Engineers who don’t use AI? yup. But if you embrace these tools and learn to work with you, you won’t have an issue getting a job! You need that human taste-maker in the loop to finish the last 5%, and you need strict CI/CD gates to stop the AI from accidentally burning down your production database.
Voice & Audio
Google DeepMind launches Lyria 3 (try it)
Google wasn’t just dropping reasoning models this week; DeepMind officially launched Lyria 3, their most advanced AI music generation model, integrating it directly into the Gemini App.
Lyria 3 generates 30-second high-fidelity tracks with custom lyrics, realistic vocals across 8 different languages, and granular controls over tempo and instrumentation. You can even provide an image and it’ll generate a soundtrack (short one) for that image.
While it is currently limited to 30-second tracks (which makes it hard to compare to the full-length song structures of Suno or Udio), early testers are raving that the actual audio fidelity and prompt adherence of Lyria 3 is far superior. All tracks are invisibly watermarked with Google’s SynthID to ensure provenance, and it automatically generates cover art using Nano Banana. I tried to generate a jingle
That’s a wrap for this weeks episode folks, what an exclirating week! ( Yes I know it’s a typo, but how else would you know that I’m human?)
Please go check out our brand new website (and tell me if anything smells off there, it’s definitely not perfect!), click around the guests directory and the episodes pages (the last 3 have pages, I didn’t yet backfill the rest) and let me know what you think!
See you all next week!
-Alex
ThursdAI - Feb 19, 2026 - TL;DR
TL;DR of all topics covered:
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed @ryancarson
🔥 New website: thursdai.news with all our past guests and episodes
Open Source LLMs
Big CO LLMs + APIs
OpenClaw founder joins OpenAI
Google releases Gemini 3.1 Pro with 2.5x better abstract reasoning and improved coding/agentic capabilities (X, Blog, Announcement)
Anthropic launches Claude Sonnet 4.6, its most capable Sonnet model ever, with 1M token context and near-Opus intelligence at Sonnet pricing (X, Blog, Announcement)
ByteDance releases Seed 2.0 - a frontier multimodal LLM family with Pro, Lite, Mini, and Code variants that rivals GPT-5.2 and Claude Opus 4.5 at 73-84% lower pricing (X, blog, HF)
Anthropic changes the rules on Max use, OpenAI confirms it’s 100% fine.
Grok 4.20 - finally released, a mix of 4 agents
This weeks Buzz
Wolfram deep dives into Terminal Bench
We’ve launched Kimi K2.5 on our inference service (Link)
Vision & Video
Voice & Audio
Google DeepMind launches Lyria 3, its most advanced AI music generation model, now available in the Gemini App (X, Announcement)
Tools & Agentic Coding
Ryan is viral once again with CodeFactory! (X)
Ryan uses Agentation.dev for front end development closing the loop on componenets
Dreamer launches beta: A full-stack platform for building and discovering agentic apps with no-code AI (X, Announcement)


