



Hey, Alex here 👋 Today was a special episode, as ThursdAI turns 3 🎉
We’ve been on air, weekly since Pi day, March 14th, 2023. I won’t go too nostalgic but I’ll just mention, back then GPT-4 just launched with 8K context window, could barely code, tool calls weren’t a thing, it was expensive and slow, and yet we all felt it, it’s begun!
Fast forward to today, and this week, we’ve covered Andrej Karpathy’s mini singularity moment with AutoResearcher, a whole fruit fly brain uploaded to a simulation, China’s OpenClaw embrace with 1000 people lines to install the agent. I actually created a new corner on ThursdAI, called it Singularity updates, to cover the “out of distribution” mind expanding things that are happening around AI (or are being enabled by AI)
Also this week, we’ve had 3 interviews, Chris from Nvidia came to talk to use about Nemotron 3 super and NVIDIA’s 26B commitment to OpenSource, Dotta (anon) with his PaperClips agent orchestration project reached 20K Github starts in a single week and Matt who created /last30days research skill + a whole bunch of other AI news! Let’s dive in.
Singularity updates - new segment

Andrej Karpathy open sources Mini Singularity with Auto Researcher (X)
If there’s 1 highlight this week in the world of AI, it’s this. Andrej, who previously started the AutoPilot program in Tesla, and co-founded OpenAI, is now, out there, in the open, just.. doing stuff like invent a completely autonomous ML research agent.
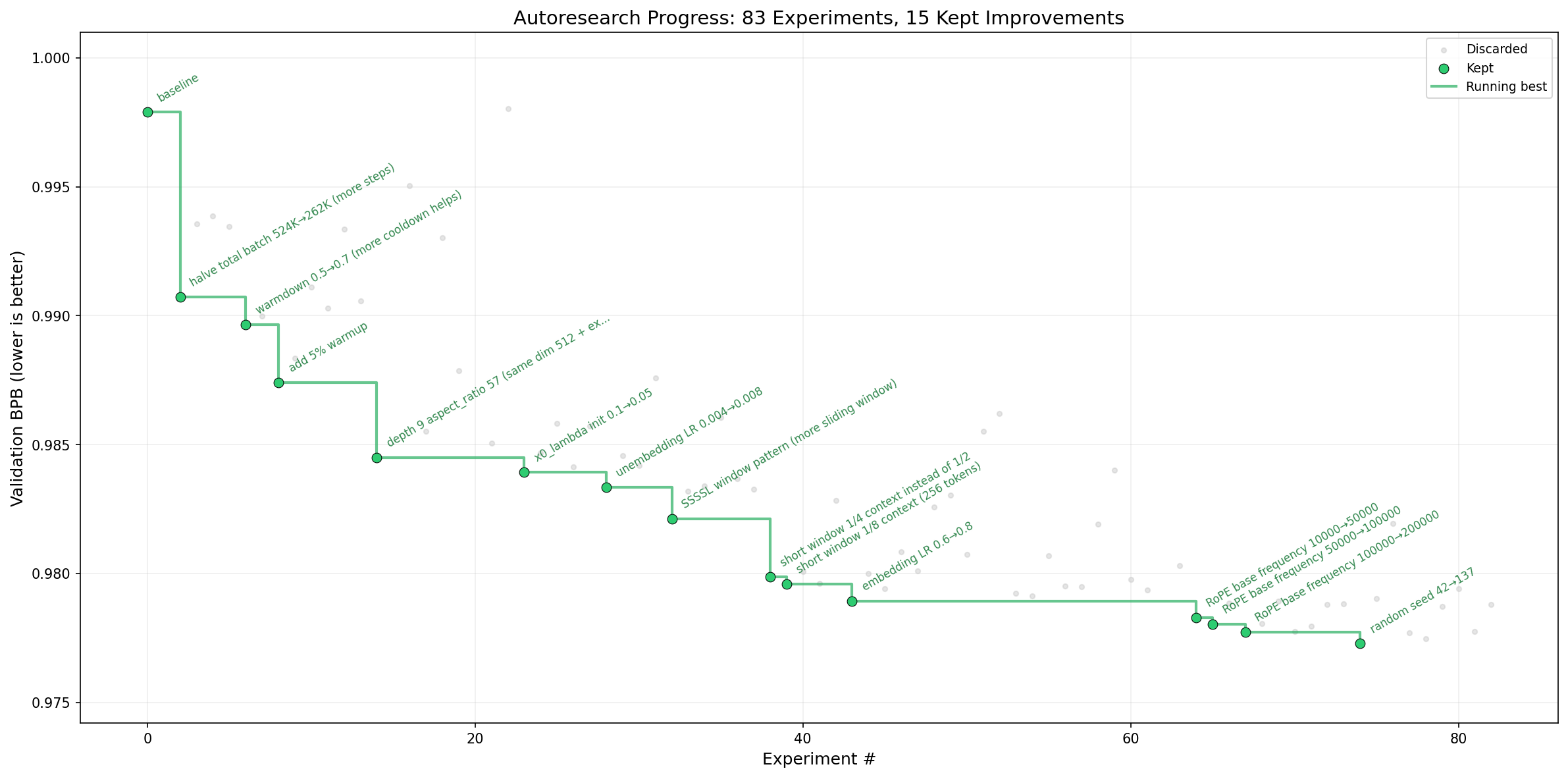
Andrej posted to his almost 2M followers that he opensourced AutoResearch, a way to instruct a coding agent to do experiments against a specific task, test the hypothesis, discard what’s not working and keep going in a loop, until.. forever basically. In his case, it was optimizing speed of training GPT-2. He went to sleep and woke up to 83 experiments being done, with 20 novel improvements that stack on top of each other to speed up the model training by 11%, reducing the training time from 2.02 hours to 1.8 hours.
The thing is, this code is already hand crafted, fine tuned and still, AI agents were able to discover new and novel ways to optimize this, running in a loop.

Folks, this is how the singularity starts, imagine that all major labs are now training their models in a recursive way, the models get better, and get better at training better models! Reminder, OpenAI chief scientist Jakub predicted back in October that OpenAI will have an AI capable of a junior level Research ability by September of this year, and it seems that... we’re moving quicker than that!
Practical uses of autoresearch

This technique is not just for ML tasks either, Shopify CEO Tobi got super excited about this concept, and just posted as I’m writing this, that he set an Autoresearch loop on Liquid, Shopify’s 20 year old templating engine, with the task to improve efficiency. His autoresearch loop was able to get a whopping 51% render time efficiency, without any regressions in the testing suite. This is just bonkers. This is a 20 year old, every day production used template. And some LLM running in a loop just made it 2x faster to render, just because Karpathy showed it the way.
I’m absolutely blown away by this, this isn’t a model release, like we usually cover on the pod, but still, a significant “unhobbling” moment that is possible with the current coding agents and models. Expect everything to become very weird from here on out!
Simulated fruit fly brains - uploaded into a simulator
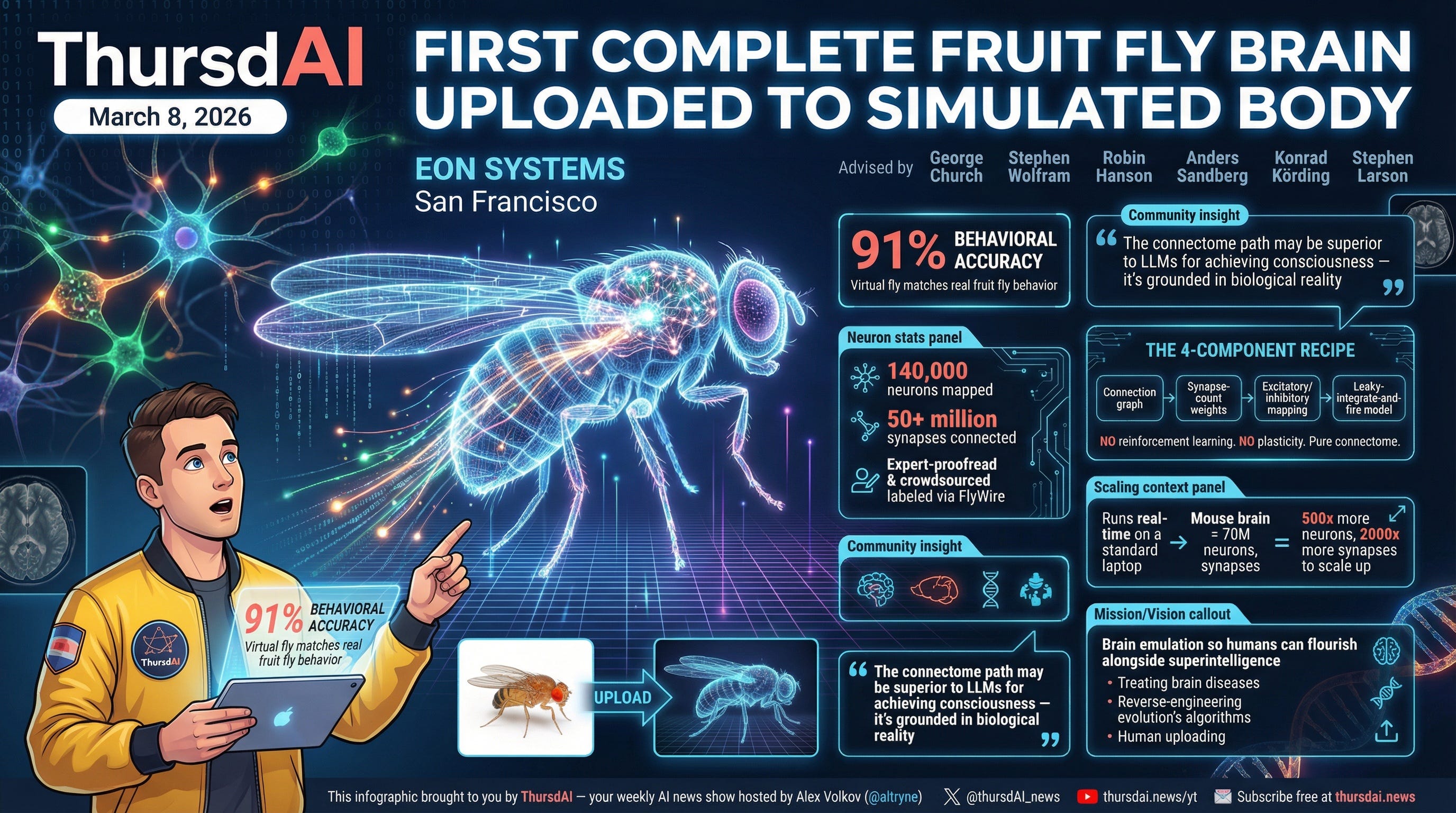
In another completely bonkers update that I can barely believe I’m sending over, a company called EON SYSTEMS, posted that they have achieved a breakthrough in brain simulation, and were able to upload a whole fruit fly brain connectome, of 140K neurons and 50+ million synapses into a simulation environment.
They have... uploaded a fly, and are observing a 91% behavioural accuracy. I will write this again, they have uploaded a fly’s brain into a simulation for chirst sake!

This isn’t just an “SF startup” either, the board of advisors is stacked with folks like George Church from Harvard, father of modern genome sequencing, Stephen Wolfram who needs no introduction but one of the top mathematicians in the world, whos’ thesis is “brains are programs”, Anders Sandberg from Oxford, Stephen Larson who apparently already uploaded a worms brain and connected it to lego robots before. These folks are gung ho on making sure that at some point, human brains are going to be able to get uploaded, to survive the upcoming AI foom.
The main discussion points on X were around the fact that there was no machine learning here, no LLMs, no attention mechanisms, no training. The behaviors of that fly were all a result of uploading a full connectome of neurons. This positions connectome (the complete diagram of a brain with neurons and connections) as an ananalouge to an pre-trained LLM network for biological intelligence.

I encourage everyone who’s reading this, to watch Pantheon on Netflix, to understand why this is of massive importance. Combined with the above Autoresearch, things are going to go very fast here. The next step is uploading a mouse brain, which will be a 500x Neurons and 2000x more synapses, but if we’re looking at the speed with which AI is improving, that’s NOT out of the realm of possibility for the next few years!
OpenClaw Mania Sweeps China: Thousand-Person Lines & Government Subsidies, Grandmas raising a “red lobster”

They’re calling it “raising a red lobster” (养小龙虾). That’s the phrase that swept Chinese social media for what is, at its core, installing an open source GitHub project on your laptop. Grandmas are doing it. Mac Minis are sold out. A cottage industry of paid installers popped up overnight on Xiaohongshu, charging up to $100 for an in-person setup. And yes, there are now also people charging to uninstall it.
On March 6th, roughly a thousand people lined up outside Tencent’s Shenzhen HQ for free OpenClaw installation. Appointment slots ran out within an hour. People brought NAS drives, MacBooks, mini PCs. Tencent engineers set up folding tables and just... started installing OpenClaw for strangers. I have pictures. I’m not making this up.

All five major Chinese cloud providers jumped in simultaneously: Tencent Cloud, Alibaba Cloud, ByteDance Volcano Engine, JD.com Cloud, and Baidu Intelligent Cloud, each racing to offer one-click OpenClaw deployment. Why? Follow the money. Per HelloChinaTech, ByteDance, Alibaba, and Tencent spent roughly $60B combined on AI infrastructure. Chatbots don’t burn enough tokens to justify that spend. But a single OpenClaw instance runs 24/7 and consumes 10-100x more tokens per day than a chatbot user. Every install is round-the-clock API revenue. The cheaper the models get, the more people run agents, the more infra gets sold. Self-reinforcing loop.
Local governments are pouring fuel on the fire. Shenzhen’s Longgang district is offering up to 2M yuan ($290K) per project. Hefei and Wuxi are going up to 10M yuan ($1.4M), plus free computing, office space, and accommodation for “one-person companies.” Meanwhile, China’s central cybersecurity agency issued TWO warnings, banning banks and state agencies from installing OpenClaw. So local governments are subsidizing it while the central authority is trying to pump the brakes. Peak 2026.
With nearly half of all 142,000+ publicly tracked OpenClaw instances are now from China. OpenClaw is the most-starred GitHub repo in history, surpassing Linux’s 30-year record in just 100 days. Device makers are piling on too — Xiaomi announced “miclaw” for smartphones, MiniMax built MaxClaw, Moonshot AI built a hosted version around Kimi.

Now, Ryan was honest on the show and I want to echo that honesty here: OpenClaw is still hard to get working. There are many failure states. It’s not “install and go to the beach.” Wolfram compared it to Linux in the late ‘90s — painful to set up, but if you push through, you can see the future behind the friction. This is real technology with real limitations, and a lot of disappointed folks in China are watching tokens burn with no actual work getting done.

But here’s the thing I keep coming back to. The memetic velocity of OpenClaw is unlike anything I’ve seen in tech. It’s not just a tool, it’s a concept that penetrated the cultural resistance to AI. People who are scared of terminals, people who’ve never touched GitHub — they’re standing in line for this. I broke through that resistance with my own fiancée. She’s now running two OpenClaws. Not enough for her. She needs another one.
Every major US lab is watching this closely. OpenAI brought Peter Steinberger on staff. Perplexity just announced they’re building a local agent for Mac. Anthropic has Claude Cowork. This is where all of computing is headed — always-on, autonomous, personal AI that actually does things for you. OpenClaw is the first front door, not the final destination. But what a front door it is.
Open Source: Nvidia Goes All In with Nemotron 3 Super 120B (X, Blog, HF)

We had Chris Alexiuk from Nvidia join us — a friend from a dinner Nisten and I hosted in Toronto. Chris is basically “NeMo” embodied, sitting at the intersection of product and research, and he gave us the full breakdown on what might be the most complete open-source model release we’ve seen from a major lab.
Here are the numbers: 120B total parameters, 12B active during inference (it’s a Mixture of Experts), 1 million token context window, and a hybrid Mamba-Transformer architecture they call “Hybrid Mamba Latent MoE with Multi-Token Prediction.” It’s hitting 450 tokens per second on the Terminal Bench leaderboard — faster than any other model on there. Modal is reporting over 50% faster token generation compared to other top open models.
What Chris was emphatic about — and I want to highlight this — is that “most open” is a real designation here. They released the model checkpoint in three precisions (BF16, FP8, NVFP4), the base checkpoint before post-training, the SFT training data, and in a move that genuinely surprised people, pre-training data and a full end-to-end training recipe. You can, in theory, reproduce their training run. That’s rare. That’s a real commitment to open source.

There’s also a huge piece of news in the background here: there’s a confirmed report that Nvidia will spend $26 billion over the next five years building the world’s best open source models. Jensen presumably has GTC remarks incoming on this. America is genuinely back in the open source AI race, and it’s Nvidia leading the charge. Chris has been in the open source world since the Hugging Face early days and said it feels genuine inside the company — not a PR exercise. And I tend to believe him. Now, all eyes are on GTC next week!
I ran Nemotron 3 Super with my own OpenClaw instance yesterday via W&B inference and it’s genuinely fast and capable. At $0.20/M input tokens and $0.80/M output tokens on W&B inference, it’s not going to replace Opus for your hardest tasks — but for running an always-on agent that needs to be cost-efficient? It’s an incredible option. More on that in the this weeks buzz section below.
Tools & Agentic Engineering
Paperclip: Zero Human Companies, Now Open Source (Github)
We had the anonymous Dotta on the show — the first AI video avatar anon person to join ThursdAI — to talk about Paperclip, an open source agent orchestration framework that hit 20,000 GitHub stars in its first week. The premise is simple and audacious: build zero-human companies.
Now this may sound familiar to you, as we had Ben from Polsia on just two weeks ago, which is a similar concept, but Paperclip is an OpenSource project, which you can run right now on your own.
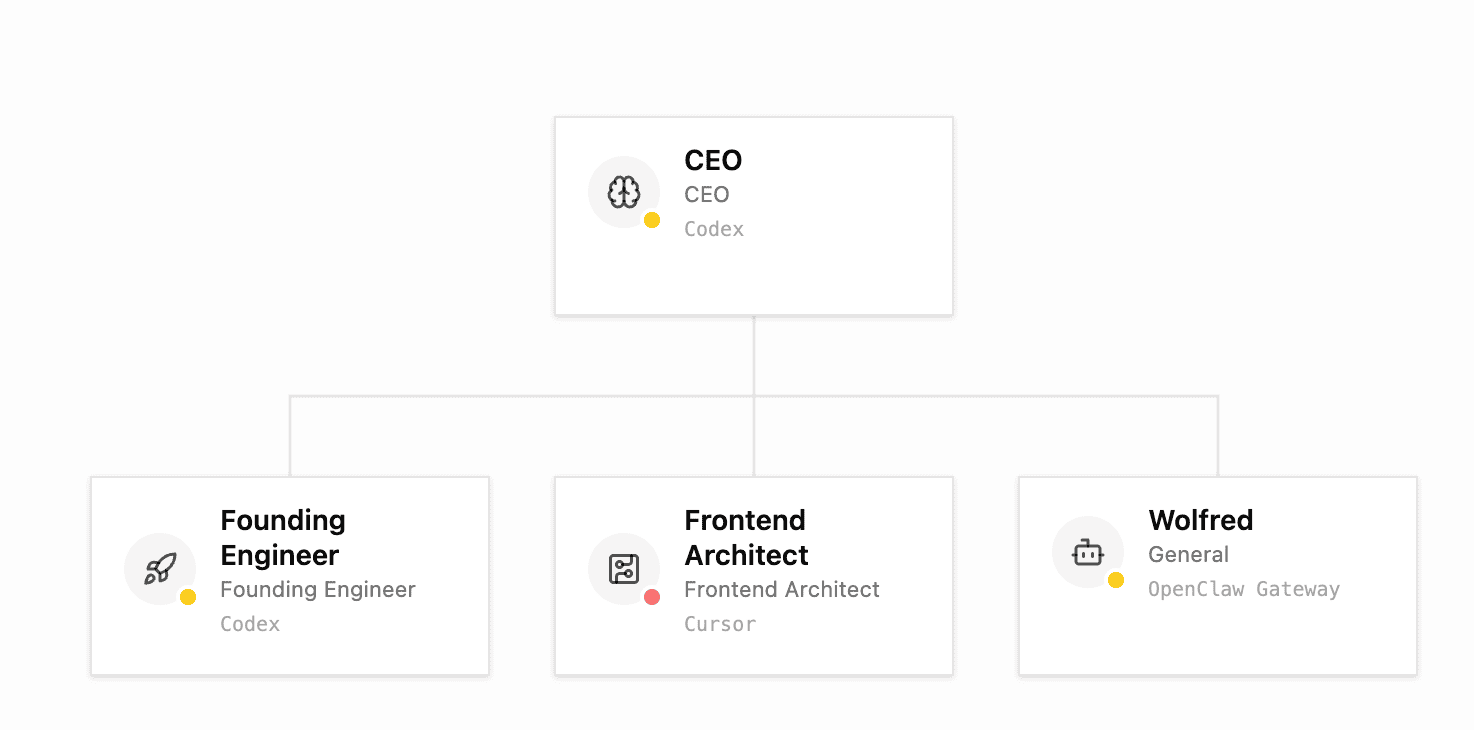
The core “thing” that got me excited about Paperclip is that you can “hire” your own existing OpenClaw agents, or Cursor or Codex or whatever else to play roles in this autonomous company. The premise is simple, you’re the board of directors, you hire an AI Agent CEO, and it then asks you if it needs to “hire” more AI agents to do tasks autonomously. These tasks all live inside Paperclip interface, and you or your Agents can open them.
The core concept of this whole system is the heartbeat concept, each agent receives their own instructions on what to do every time they are “woken up” by a timer. This is what’s driving the “autonomous” part of the whole thing, but it’s also what’s eating the tokens up, even if there’s no work being done, agents are still burning tokens asking “is there work to be done?”
Dotta gave us a great metaphor, asking if we saw the movie Memento, where the protagonist lost his memory and every time he woke up, he woke up with a blank slate, and had to reconstruct the memories. AI agents are like the memento man, and Paperclip is an attempt to give those agents the whole context so they can continue working on your tasks productively. Dotta told us that the future of Paperclip is the ability to “fork” entire companies, structures that will actually run and do things on your behalf. Looking forward to that future, but for now I will be turning off my Paperclip interface as it’s costing me real money without the need.
Symphony: Agents Writing Their Own Jira Tickets
We mentioned Symphony last week, and I texted Ryan the link before the show, and voila, of course, he set it up and went viral, yet again! We’re so lucky to have Ryan on the show to tell us from first hand experience what it’s like to run this thing.
Symphony was open sourced by OpenAI last week, and it’s basically an instruction manual for how to run agents autonomously via Linear ticketing system. (Github)
The highlight for Ryan was, the whole system is running creating pull requests while he’s a sleep, and at some point, he noticed a ticket that he didn’t create. One of the agents found a bug, and created a very detailed ticket for him to approve.
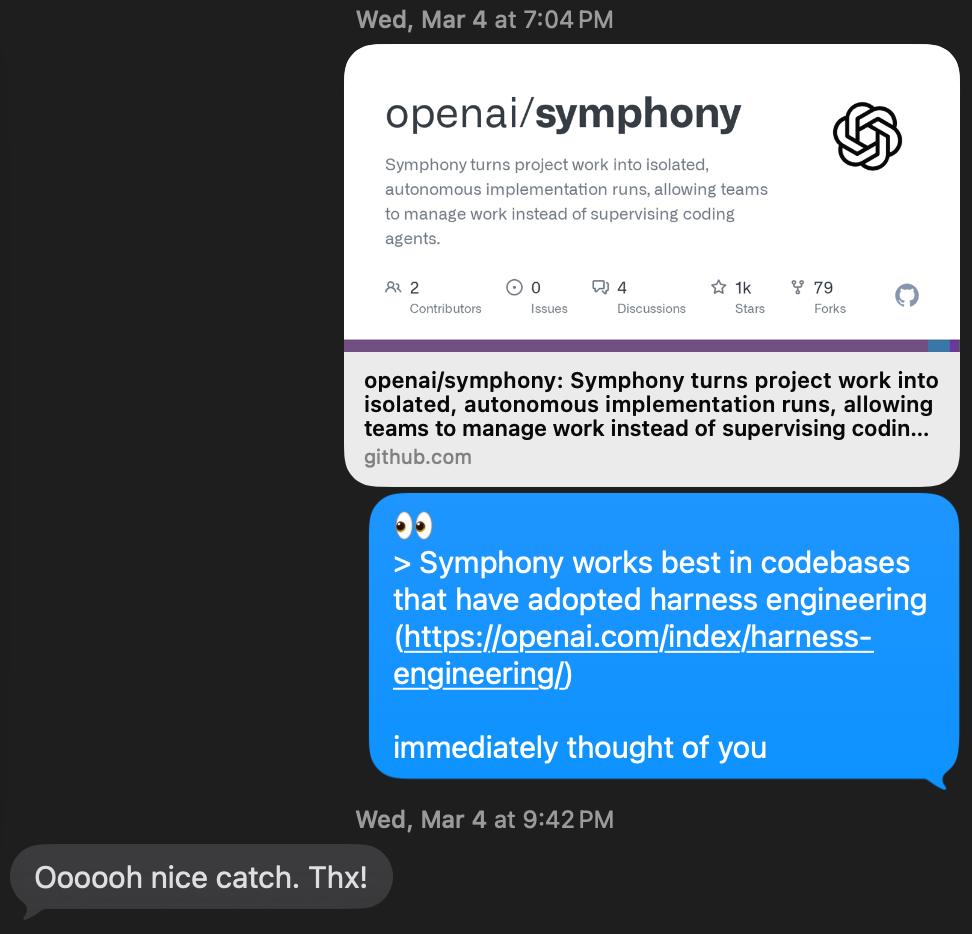
I’m just happy that I can keep even my co-hosts up to date hehe
This weeks buzz - we’ve got skills and nemotrons!
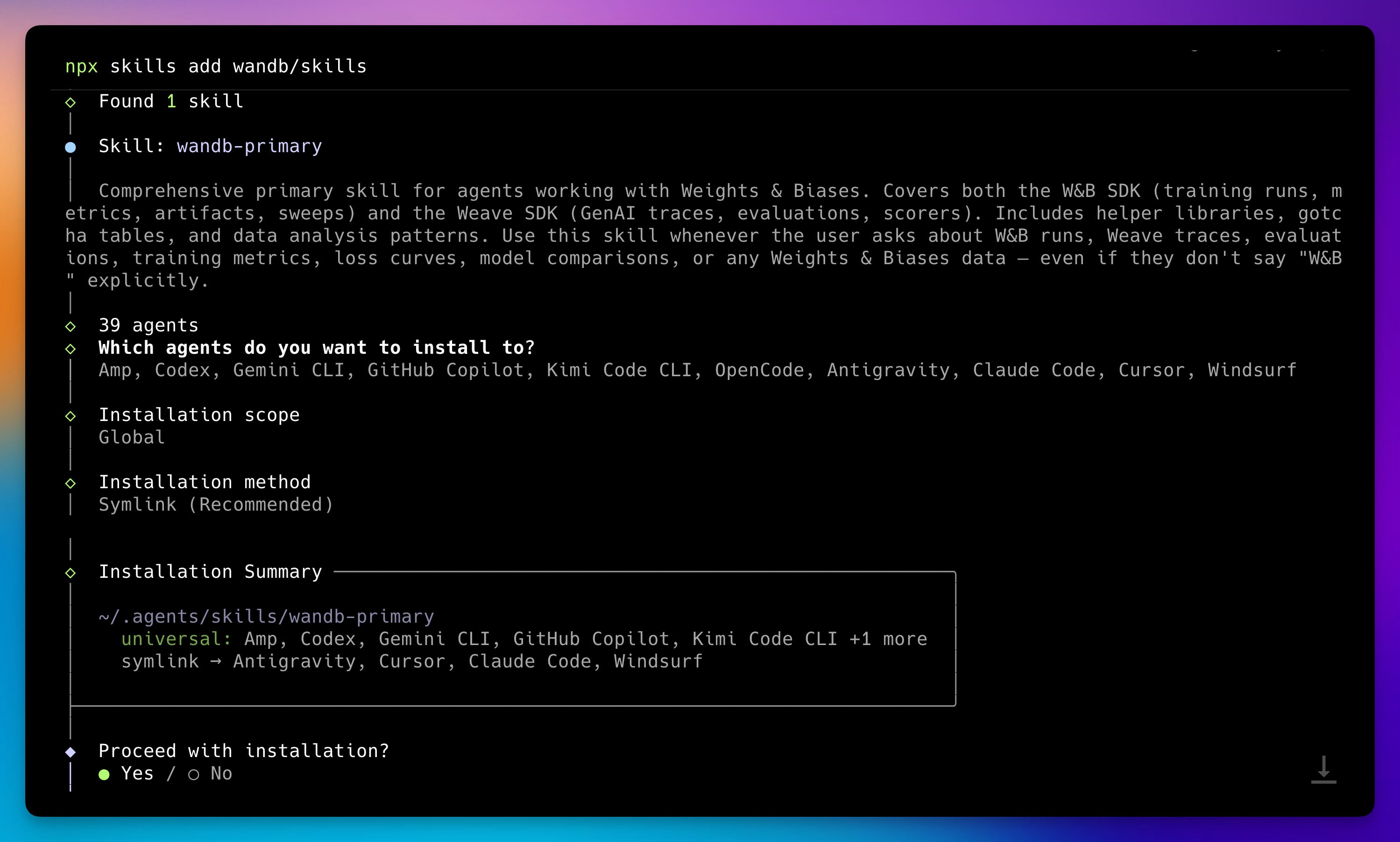
Look, we told you about Skills in the start of the year, since then, via OpenClaw, Hermes Agent, Claude Code, they exploded in popularity. One downside of skills is, it’s very easy to make a bad one! So, we’re answering the challenge, and are publishing the official wandb skill 🎉
Installing it is super simple, npx skills add wandb/skills and voila, your agents are now officially “I know kung fu” pilled with the best Weights & Biases practices. For both Weave and Models 👏 Please give us feedback on Github if you have used the skills! Github
Also, we’ve partnered with Nvidia to support the best US open source model on day 0, and we have Nemotron 3 Super on our inference service, for all to use at $0.20/1Mtok! It’s super easy to setup with something like Hermes Agent or OpenClaw and runs really really fast! Check it out here.
Is it going to perform like Opus 4.6? No. But are you going to run Opus 4.6 at 20 cents per million? Also no.
Gemini drops SOTA embeddings and gets dethroned 2 days later live on the show.
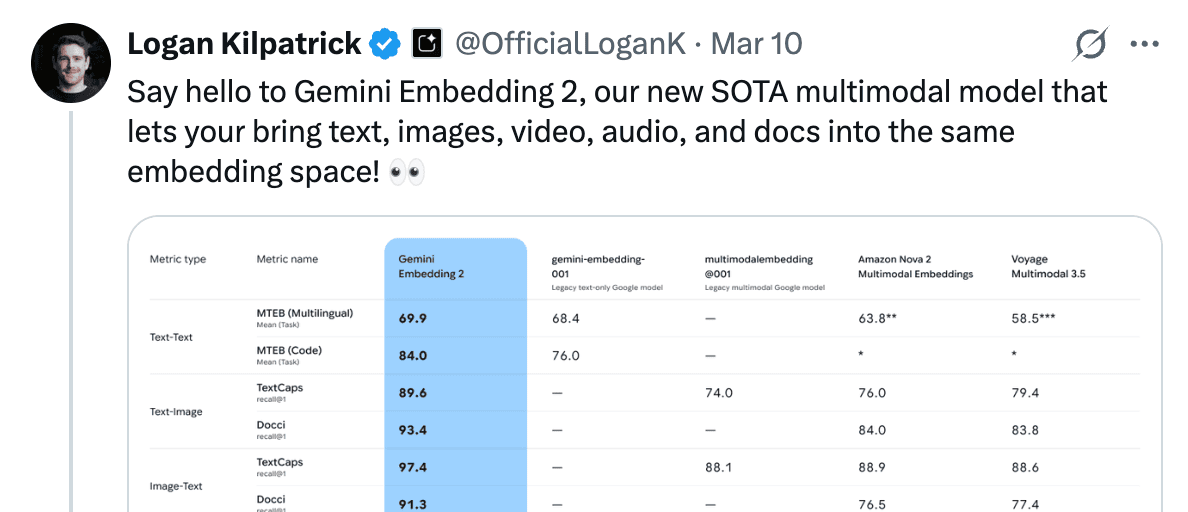
This always happens, but I didn’t expect this to happen in a fairly niche segment of the AI world... multimodal embeddings!
Gemini posted an update earlier this week with Gemini Embeddings 2.0, a way to unify images, text, video, audio embeddings under 1 roof, and posted a SOTA embedding model!
Then, just as we launch the show, a friend of the pod Benjamin Clavie, drops me a DM, basically saying that his company Mixbread is going to deploy an embedding model that will beat Gemini Embedding 2 on almost every benchmark on that table, and then... they did!

The most notable (and absolutely crazy) jump in this comparison is, the LIMIT benchmark, where they achieved a 98% score vs Gemini’s ... 6.9 percent. I didn’t believe this at first, but asked Ben to explain the findings, and he did. Congrats to folks for moving the search space forward every 2 days!
Grok 4.20 in the API for $2/1Mtok
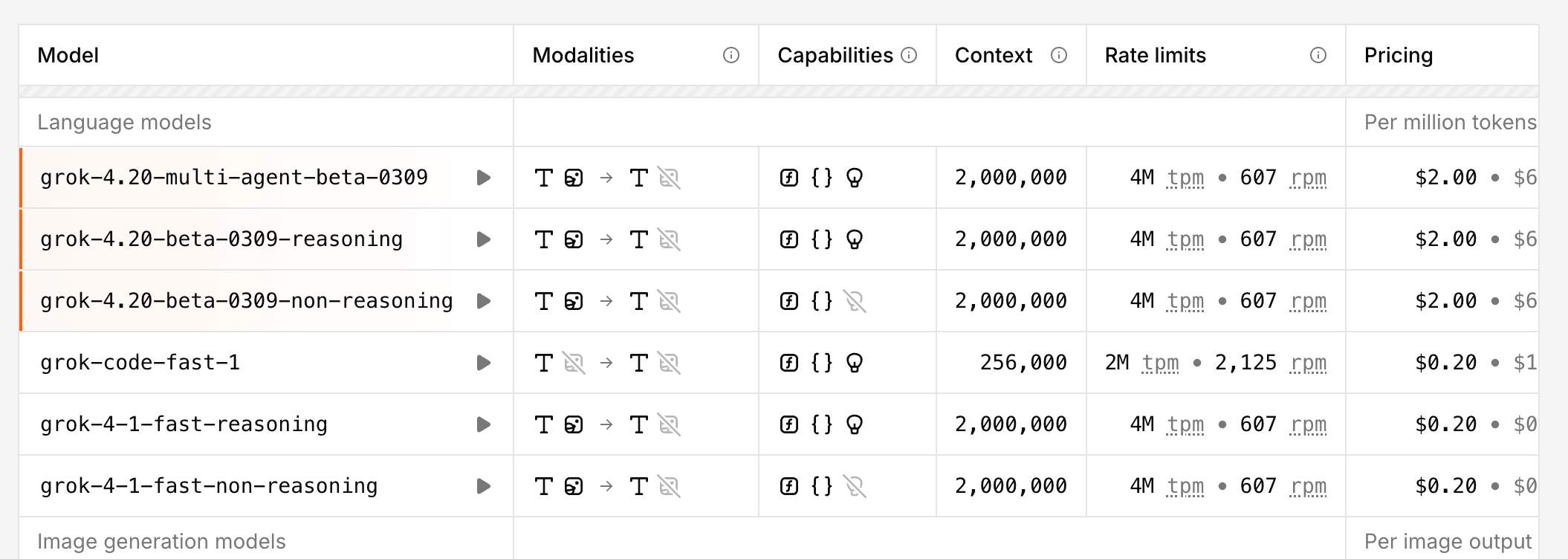
Elon Musk and XAI co finally released Grok 4.20 in the API. Look I said what I said about XAI models, they are great for research, and for factuality, but they aren’t beating the major labs. The last firing of almost of XAI folks doesn’t help either. So this model was not “released” in any traditional sense, there’s no benchmarks, no evals, and everyone who got access to it evaluated it and, it’s no better than GLM5 on many benchmarks. So it does makes sense to release it quietly.
It is very fast though, and again, for research and for X access, it’s an absolute beast, so I’ll be trying this out!

Parting thoughts and a small reflection. For the past 3 years, we’ve had a front-row seat to the singularity shaping up. 2.5 years ago, I went all in, decided to pivot into podcasting full time. In those years, ThursdAI became known, we’ve had guests from nearly all major AI labs (including Chinese ones, for which I’m particularly proud), I got to meet with executives, ask leaders questions about where this is all going, and most of all, share this journey with all of you, candidly. We rarely do hype on the show, we don’t speculate, we try to do a positive outlook on the whole thing, and counter doomerism, as there’s too much of that out there.
I am very glad this resonates, and continue to be thankful for your attention! If you wanted to give us any kind of a birthday present, subscribe or give us a 5 star review on Apple Podcasts or Spotify, it’ll greatly help other folks to discover us.
See you next week,
Alex 🫡
ThursdAI - Mar 12, 2026 - TL;DR
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed) @ryancarson
Chris Alexiuk from Nvidia (@llm_wizard) - Nemotron
@dotta - creator of Paperclip.ing AI agent orchestration framework
Matt Van Horn - @mvanhorn - creator of @slashlast30days
Singularity updates
Andrej Karpathy’s autoresearch achieves 11% speedup on GPT-2 training through autonomous AI agent experimentation (X, GitHub, GitHub)
Eon Systems uploads first complete fruit fly brain to a physics-simulated body, achieving 91% behavioral accuracy (X, Announcement, Announcement)
OpenClaw mania sweeps China as all five major cloud providers race to support it (HelloChinaTech, Reuters, SCMP, MIT Tech Review)
Big CO LLMs + APIs
xAI quietly releases Grok 4.20 API with massive 2M token context window and multi-agent capabilities (X, Blog)
Google launches Gemini Embedding 2, the first natively multimodal embedding model supporting text, images, video, audio, and PDFs in a unified vector space (X, Announcement)
Open Source LLMs
NVIDIA launches Nemotron 3 Super: 120B open MoE model with 1M context window designed for agentic AI at 5x higher throughput (X, Announcement)
MiroMind releases MiroThinker-1.7 and H1 - open-source research agents with 256K context, 300 tool calls, achieving SOTA on deep research benchmarks (X, HF, HF, HF)
Covenant-72B: World’s largest permissionless decentralized LLM pre-training achieves 72B parameters on Bittensor with 146x gradient compression (X, Arxiv, HF, HF)
Tools & Agentic Engineering
ACP is the open standard that lets any AI coding agent plug into any editor — and this week Cursor officially joined the registry, meaning you can now run Cursor’s agent inside JetBrains IDEs (JetBrains blog, Cursor blog)
This weeks Buzz
W&B launches official Agent Skills for coding agents, turning experiment dashboards into terminal queries (X, Announcement, Announcement)
Video
Voice & Audio
Fish Audio launches S2: Open-source TTS with sub-150ms latency and absurdly controllable emotion (X, HF, Blog, Announcement)
Show notes and links


