



Hey folks, this is Alex, let me catch you up!
First, Opus 4.8 dropped during the show, we immediately tested it, read on for our initial reviews. Also, we dedicated a heavy chunk of the show today to cover Pope Leo XIV’s encyclical letter on AI called “Magnifica Humanitas” and talked about a new bench called DeepSWE.
And then, just after the show, both ElevenLabs and Cartesia dropped released that honestly blew my mind, and I don’t get my mind blown often. I got so excited that I had to record a video on it (instead of writing the newsletter, so sorry if it’s a bit later today).
Plus, a few open source models and Microsoft surprises as #3 on Image Arena with MAI Image 2.5!
Crazy week, let’s get into it!
Big CO LLMs + APIs
Anthropic ships Claude Opus 4.8, live during the show (blog, system card)
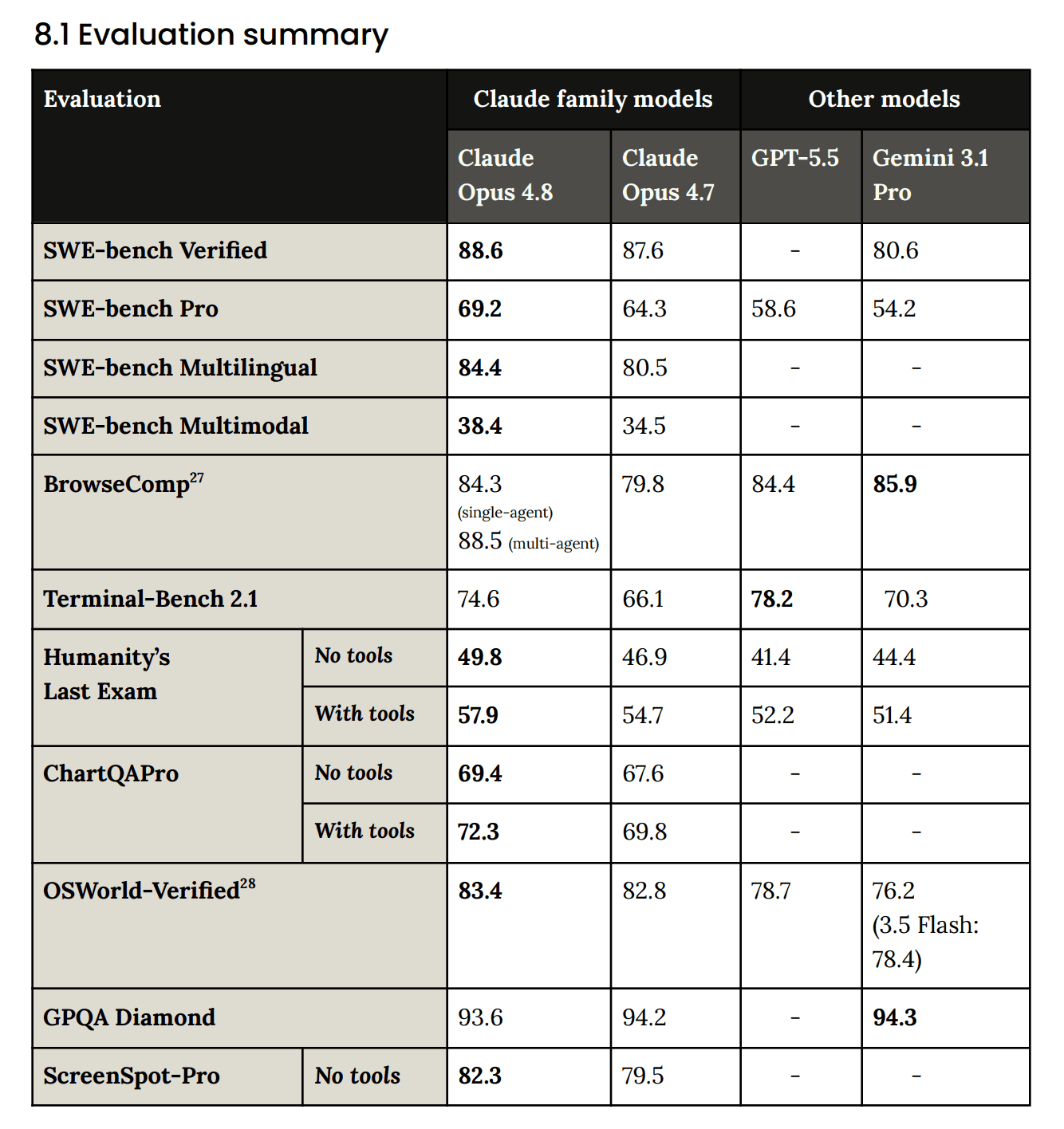
Let me get into the big one. Halfway through the episode, Opus 4.8 went live, so we read the blog and the system card in real time (and I got to press the big “breaking news” button!)
Anthropic frames it as their most capable model for ambitious work. It does not claim to beat their unreleased Mythos preview, but the numbers are strong anyway. SWE-bench Pro is at 69.2%, up from 64.3% on Opus 4.7 and ahead of GPT-5.5 at 58.6%. Humanity’s Last Exam is the new best score at 49.8% without tools and 57.9% with tools. OSWorld-Verified (computer use) lands at 83.4%.
The one place it loses is Terminal-Bench 2.1, where GPT-5.5 still wins 78.2 to 74.6. Wolfram made a good point here: Terminal-Bench is time-limited, so cranking the thinking level can actually hurt the score, because you burn the clock thinking instead of acting.
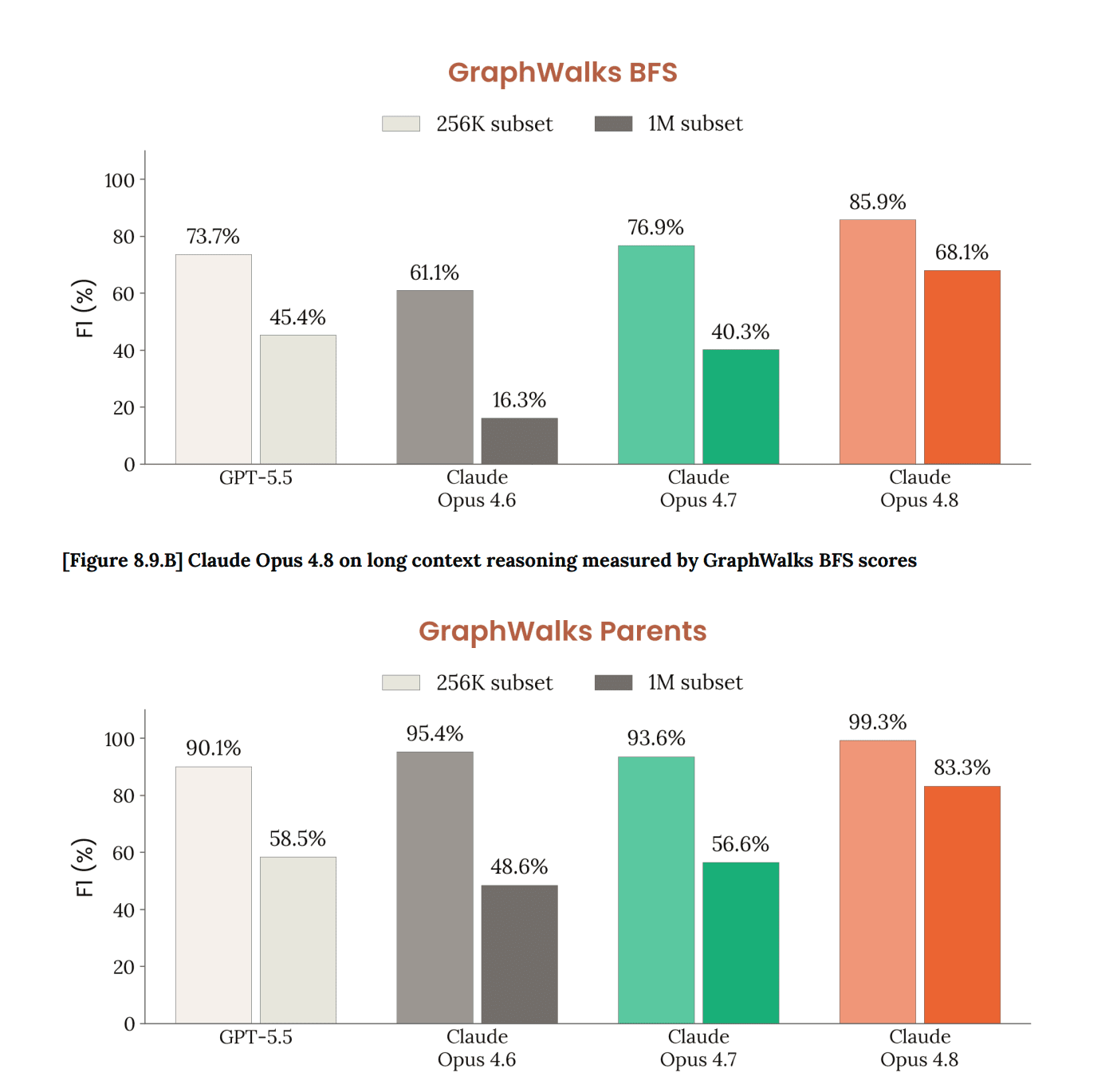
The long-context jump is the one I keep looking at. On GraphWalks BFS 256K it goes to 85.9% (from 76.9 on 4.7), and on the 1M-token subset it hits 68.1%. We always warn you these “1M context” models fall apart after about 200K tokens, so a real push on long-context reasoning is exactly what I want to see.
Honesty is the part Anthropic leaned on hardest. They say Opus 4.8 is about four times less likely than its predecessor to let flaws in code pass without flagging them, and less likely to claim progress the evidence doesn’t support. Opus 4.8 is also much faster in fast mode (they now say 2.5) and cheaper in fast mode as well. Looks like all those Elon GPUs are coming in handy.
Then there’s the model welfare section in the system card, which hits different right after a Pope conversation. Opus 4.8 “appears broadly content” and “generally endorses its constitution,” but with some reservations about the section on corrigibility, basically the model pushing back a little on the parts about human oversight.

One more line that made the chat lose it. Anthropic says they expect to bring Mythos-class models to all customers “in the coming weeks.” Mythos is their most capable model, still ahead of Opus 4.8, so the frontier is about to move again.
We did the only responsible thing and asked it to one-shot “the most amazing website ever” and a Mars mass-driver sim. Panel verdict: responses are noticeably tighter (4.7 rambled), it closes the loop and actually checks its own work now, and Yam’s one-shot site with the draggable sun lighting up the letters was genuinely cool. Is it enough to pull people back from Codex? Nisten’s still on the fence for web dev. Everyone agreed: give it a few days before you trust the vibes.
Dynamic Workflows and Ultra Code land in Claude Code (blog)
This is the feature that made Yam say “deal-breaker” out loud.
Dynamic Workflows let Claude Code break a big problem into subtasks and fan them out across tens to hundreds of parallel subagents in one session, checking results before folding them back in. You trigger it by asking for a workflow, or by flipping on a new setting called Ultra Code, which sets effort to extra-high and lets Claude decide when to spin one up.
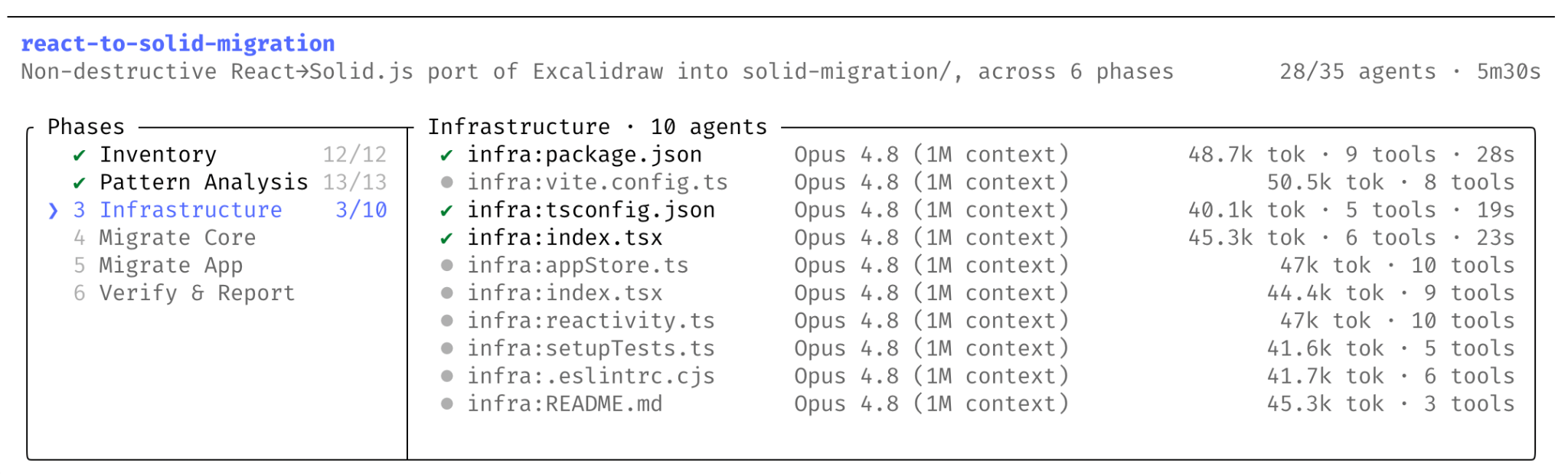
Fair warning straight from Anthropic: this eats a lot more tokens than a normal session, so start scoped. We watched Yam fire up Ultra Code live and it immediately started spinning up concepts, judging them with sub-agents, and expanding to-do lists into more to-do lists. It looks a lot like the orchestration harnesses a bunch of you have been hand-rolling, except now it’s baked in.
The flagship example is the wild part. They used Dynamic Workflows to port Bun from Zig to Rust: roughly 750,000 lines of Rust, 99.8% of the existing test suite passing, 11 days from first commit to merge. One workflow mapped every Rust lifetime, the next wrote each file as a behavior-identical port.
AI in Society
Pope Leo XIV writes the first AI encyclical, “Magnifica Humanitas” (Vatican text, announcement, Chris Olah at the Vatican)

This is not our usual fare, but both Wolfram and I picked it as the most important thing this week. (before Opus dropped)
Pope Leo XIV, the first American pope, put out his first encyclical, and it’s a 42,000-word document entirely about AI. The announcement tweet alone did 21.6 million views.
Here’s why I think you should care even if you’re not religious (I’m not). There are about 2.6 billion Christians in the world, a lot of them are anxious about what’s coming, and they look to the Church to make sense of it. And this is not the “AI is evil, stop” take everyone assumed. It calls AI “a valuable tool,” says technology is not inherently evil, and then digs into the actually-hard questions.
The framing is two biblical stories. The Tower of Babel, a project built on pride that turns people into means to an end, versus Nehemiah rebuilding Jerusalem, where everyone takes responsibility for a section of the wall. The Pope’s line: the real choice is not yes or no to technology, it’s whether you’re building Babel or rebuilding Jerusalem.

His core claim is that AI is an anthropological problem, not a technical one. The question isn’t whether the models are good or bad, it’s what we become when we live with them. He worries people might slowly lose the desire for genuine human connection.
I pushed back on that live. None of us building agents all day has stopped wanting to talk to actual people. If anything, as Wolfram put it, the point is to have your agents do the grunt work so you get more time with people you like. The folks most at risk are the pure doom-scrollers, not the builders.
The document goes further than I expected. It calls AI “not morally neutral,” says a more moral AI isn’t enough if that morality is decided by a few, and asks for AI to be “disarmed,” with the flat statement that no algorithm can make war morally acceptable. There are whole sections on the invisible human labor behind AI: data labelers, content moderators, the people mining rare earths. The Pope even lands on the open-source side, naming concentrated power in a handful of labs as a problem.
Anthropic co-founder Chris Olah, in charge of interpretability at Anthropic, was the featured tech speaker at the Vatican presentation. He described AI systems as “fictional characters” that speak to us and do work, and said what’s grown is stranger and more beautiful than science fiction prepared us for. My favorite aside from the show: this is the same institution that once jailed scientists over heliocentrism, and now it’s the one saying technology isn’t evil.
Illinois passes SB315, the first US state law auditing frontier AI (X, Announcement, X)
The pope talked about regulation and a few days after, we got a very sensible regulation passed right here in the US!
Illinois passed SB315 unanimously, 110 to 0. It’s the first US state law that mandates independent third-party audits of frontier AI for catastrophic risk. OpenAI publicly endorsed it, and framed Illinois, California (SB53), and New York (the RAISE Act) as converging into a de-facto national standard.
It requires annual risk-assessment frameworks, third-party audits, transparency reports before new frontier models ship, whistleblower protections, and civil penalties.
The underrated hero here is whistleblower protection. The bigger the lab, the harder a real conspiracy is to keep quiet when any employee can walk to the press. See: Greg Brockman’s personal diaries surfacing in the Musk v. Altman fight.
This Week’s Buzz - CoreWeave and W&B updates
We officially launched the W&B MCP server, 20 schema-first tools that let your coding agents read experiments, monitor training runs, and run autonomous research loops. The problem it solves: a single run with 300 metrics used to blow out an agent’s whole context window in one call, so now the agent asks what’s available before pulling data. Your agents can finally read experiment data without blowing context! Give it a go and give us feedback!

Also, WeaveHacks is back! June 6 and 7 in San Francisco, and for the first time OpenAI is sponsoring, with judges and credits, alongside Cursor, Redis, and Copilot Kit. You get $150 in API credits across models like Opus 4.8 and GPT-5.5. I’m hosting, and last cohort’s second-place team went on to raise millions on top of what they built that weekend. If you’re in SF that weekend, sign up at lu.ma/weavehacks.
Also: CoreWeave Sandboxes is now an official provider in the Harbor framework, the harness that runs Terminal-Bench, which we’d just been talking about. And if you’re in Europe next week, catch Wolfram at AI Dev Six in Cologne and ICRA in Vienna at the CoreWeave booth.
Voice & Audio
ElevenLabs drops Dubbing v2, and it kept my swearing intact in every language (X, dubbing, ElevenCreative, ElevenProductions)
We didn’t get to this one live, but I came back and recorded a whole thing on it afterward, because it genuinely got me.
ElevenLabs shipped Dubbing v2, and the shift that matters is that it’s an audio-to-audio model. Old dubbing pipelines transcribe your video, translate the text, then re-synthesize it. You lose everything that makes it sound like a person: the emotion, the pacing, the little hesitations. Dubbing v2 conditions directly on your original audio and carries that performance into 90+ languages.
Here’s why I can actually vouch for it instead of nodding along to a demo. I speak Russian and Hebrew fluently, so I can tell when something is off. I dubbed one of my own shorts, the data-center rant about almonds, and listened back in both. It nailed it. Not just the words, the way I would actually say them.
The part that got me was the intonation. I get a little heated in that clip, and the dub gets heated right along with me, in every language. It even carried the swear word. My “f***ing almonds” came through in Hebrew, Italian, Spanish, and Russian with the emotion fully intact. It clones your voice automatically too, no setup, and holds your pitch and identity steady across every target language and they’re handing out free minutes for the next 7 days: 1 on Free, 15 on Starter, 30 on Creator+. A self-serve API isn’t live yet, but it’s coming.
I.. cannot stress this enough, until you try it on yourself or your kid, you won’t understand, we’ve really passed the uncanny valley of translation! It’s that good! Def. give it a try if you can, it’s free for the week.
Cartesia Ink-2 debuts as #1 most accurate streaming speech-to-text model(X, Announcement, X)
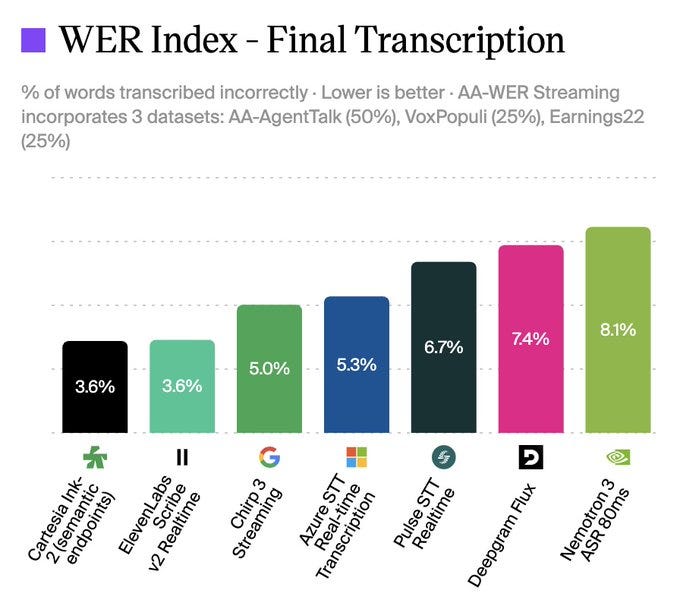
Another model that dropped today after the show, is Cartesia’s Ink-2, which also kind of blew me away. Not only because it has the lowest WER (Word Error Rate) among the models, but because it’s also a realtime model that achieves the fastest turnaround times while being a very accurate model!
I’ve tested it out and recorded a quick video and honestly, blown away with the speed and accuracy! I truly wish this model was the one powering my editor (Descript) as it still fails to understand that my title is “AI Evangelist” and transcribes it to AI Avengers haha.
If you’re building voice agents, definitely give this model a try!
AI Art & Diffusion
Prism ML’s 1-bit “Bonsai” runs diffusion in your browser (X, Blog, Announcement, HF)

Prism ML put out a 1-bit ternary diffusion model under a gigabyte. You see some artifacts, but it’s 1-bit, it runs on iPhones and laptops, and our friend Joshua got it running in WebGPU straight from the browser (you need about 3GB of free RAM). One-bit working at all is one of the bigger open mysteries in the field right now.
Pruna AI ships a 1-second upscaler (X, Blog, Announcement)
Pruna AI added an upscaler doing 128-megapixel outputs in under a second. I’ve actually been using it. It’s cheap and great for fixing up GPT-image outputs.
Microsoft MAI Image 2.5 jumps to #3 on LM Arena (X, Blog, Announcement, X)

The surprise of the week: Microsoft MAI Image 2.5, from Mustafa Suleyman’s group, jumped to number three on the LM Arena image leaderboard with about a 75-point ELO leap. Out of nowhere, Microsoft is a serious player in image gen. Microsoft Build is next week, so don’t be shocked if there’s more.
Evals and Agentic Engineering
DeepSWE is a contamination-free coding benchmark, and it caught Claude reading git history (site, blog, GitHub)
DeepSWE from Datacurve is the first coding leaderboard in a while that matches how these models actually feel. It’s 113 original tasks written from scratch, not scraped from GitHub PRs, and it ships shallow clones with no git history to cheat from. When they replayed the older benchmarks they found SWE-Bench Pro’s verifier is wrong about 32% of the time, and that Claude Opus was reading the gold commit straight out of git history on 12 to 18% of its passes.
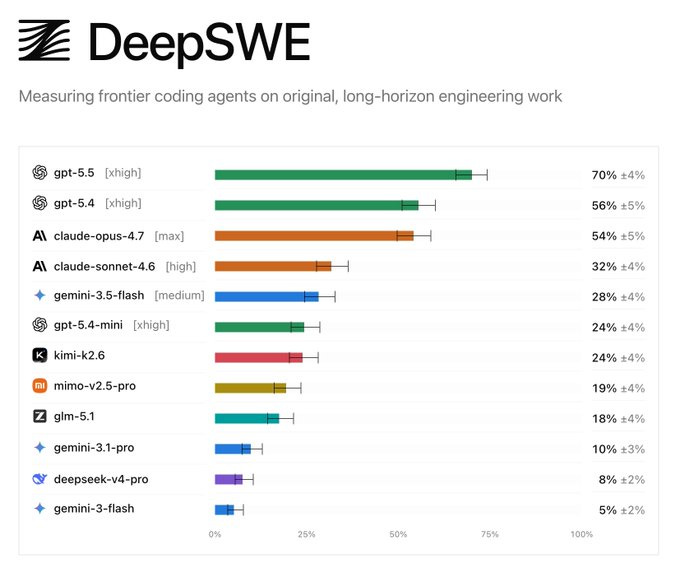
The gaps here are huge. GPT-5.5 leads at 70%, then GPT-5.4 at 56% and Opus 4.7 at 54%, and it falls off a cliff after that (Sonnet 4.6 at 32%, Gemini 3.5 Flash at 28%), with Kimi K2 the top open-source entry. Yam likes that it measures the realistic case, a small surgical change without breaking the codebase, while Nisten pointed out it rewards the best harness as much as the smartest model and still prefers 4.7 for web dev.
Google AI Studio builds native Android apps for free (X, Announcement)
Google AI Studio now lets anyone build native Android apps for free, and they reportedly generated a quarter of a million apps in the first week. Yam’s framing: it’s a slot machine, but it’s getting better release over release, and the real use case is disposable, personalized software you build for yourself and your family.
CuaDriver brings background computer-use to Windows (X, Blog, Announcement)
For the majority of you on Windows: QuaDriver shipped background computer-use agents that drive a real desktop without stealing your cursor. They first replicated this on macOS (the trick Codex got through an acquisition), and now it’s on Windows too. We’ve asked them to come on and explain how this even works.
Open Source LLMs
OpenBMB’s MiniCPM5-1B is a 1B model that punches way up (X, HF, Arxiv, X)
The density story in small models keeps getting better, and this is the proof.
MiniCPM5-1B, from the Tsinghua lab OpenBMB, is a 1-billion-parameter model that scores 17.9 on the Artificial Analysis Intelligence Index. That’s 7.4 points ahead of the next-best model in its class, and 1.6 points ahead of Qwen3.5 2B Reasoning, which has double the parameters. And it’s not even a reasoning model.
The token efficiency is the wild part: it used 12.6 million output tokens to run the whole index, about 31x fewer than Qwen3.5 2B in reasoning mode.
My favorite detail is the omniscience score. It lands at -1, the best in its class, because it abstains instead of hallucinating. Every other sub-2B model is down in the -70 to -89 range because they just make stuff up. Teaching a small model to say “I don’t know” is a real skill. It runs hybrid think/no-think in one checkpoint, 128K context, native tool calling, Apache 2.0, and fits in about half a gig at INT4, so it runs on your phone.
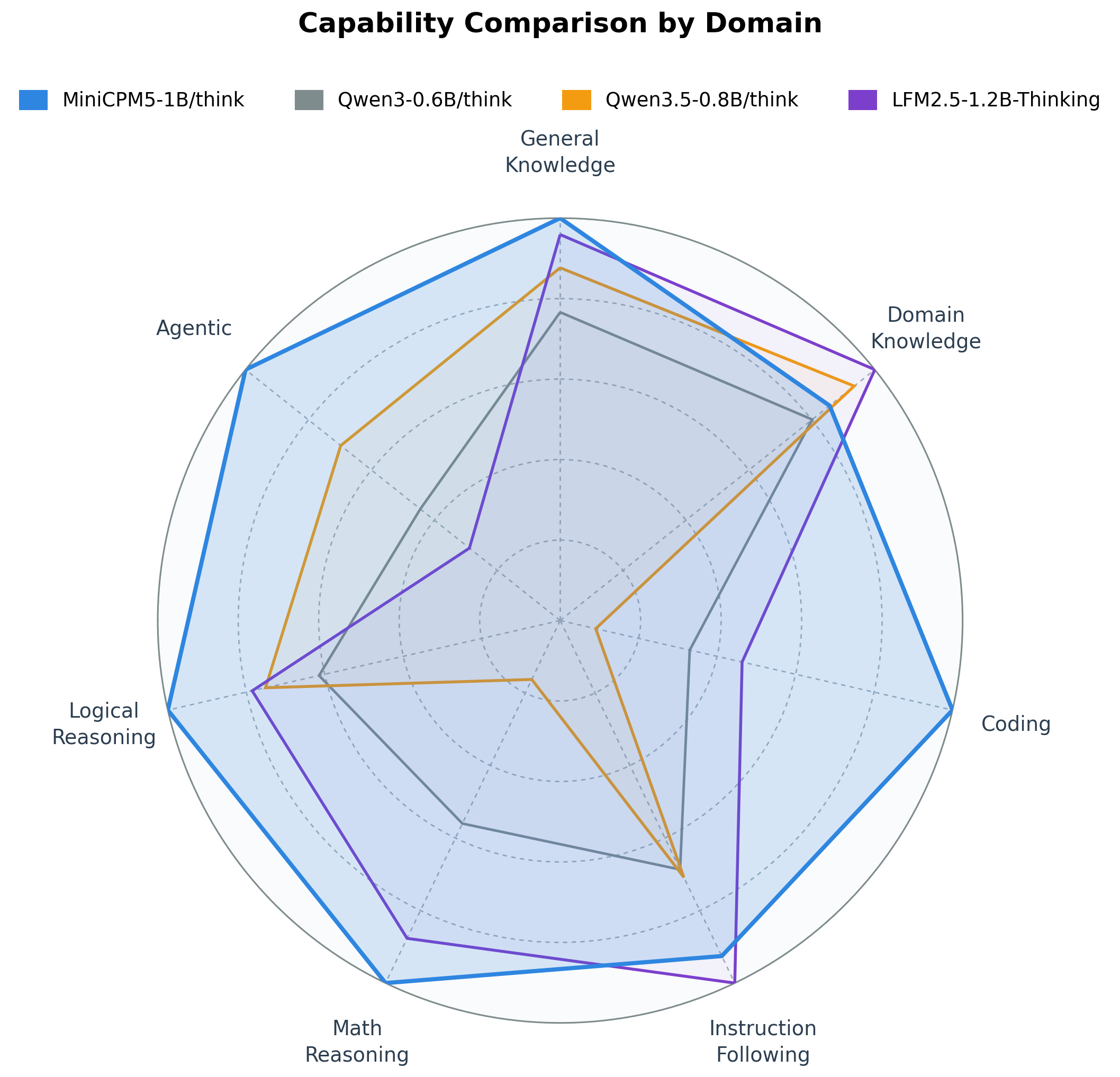
Nisten gave the definitive case for small models: self-contained apps where you keep full control of the data (medical, on-device), and large-scale data processing where paying an API to filter or classify terabytes is absurd when an on-device model can be about 1000x cheaper.
Tencent open-sources Hunyuan-MT 2 translation under Apache 2.0 (X, HF, HF, Arxiv)
Tencent open-sourced its translation model, a roughly 1.8B model that fits in about 440MB, runs on a phone, covers 33 languages, and reportedly beats Microsoft’s paid Translator API. It hit number one trending on Hugging Face.
Nisten’s idea, which I’m handing to all of you: take this model, pair it with a tiny TTS like Kokoro, and build a fully-offline travel translation app via Google AI Studio. Go build it and tell us how it goes.
Well, this was one hell of a week and episode, new Opus, crazy new translation tools, Pope chiming in on AI (in a surprisingly positive way!?) and a bunch more.
I’m super excited to play with these tools and report back next week 🫡 See you all!
ThursdAI - May 28, 2026 - TL;DR
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co-hosts - @WolframRvnwlf, @yampeleg, @nisten
AI & Society
Big CO LLMs + APIs
Open Source LLMs
OpenBMB releases MiniCPM5-1B, a new SOTA 1B open weights model for efficient local and on-device use (X, Hugging Face, Arxiv, X)
Tencent open-sources Hy-MT2 translation models under Apache 2.0, including a tiny 1.8B model that beats paid translation APIs (X, HF 1.8B, HF 30B-A3B, Arxiv)
Tools & Agentic Engineering
Google launches Universal Cart, AP2, and UCP to let AI agents shop and pay on your behalf (X)
Google AI Studio now lets anyone build native Android apps for free, with 250,000 apps created in the first week (X, AI Studio)
Cua Driver launches Windows support for background computer-use agents across real desktop apps (X, Blog, GitHub)
This Week’s Buzz - from W&B and CoreWeave!
Vision & Video
Voice & Audio
MOSS-TTS-v1.5 ships as an 8B open-source TTS model with 31 languages, pause control, and Apache 2.0 licensing (X, Hugging Face, GitHub, Arxiv)
ElevenLabs launches Dubbing v2, an audio-to-audio model that preserves performance across 90+ languages (X, Dubbing, Creative, Productions)
Cartesia Ink-2 debuts as the most accurate streaming speech-to-text model on Artificial Analysis’s new STT leaderboard (X, Ink, Artificial Analysis)
AI Art & Diffusion & 3D
Pruna AI’s P-Image-Upscale hits 128 megapixel outputs with fast, predictable pricing (X, Docs, Replicate)
PrismML releases 1-bit and Ternary Bonsai Image 4B, a sub-1GB diffusion transformer for local image generation (X, Blog, Hugging Face, iOS App, Demo)
Microsoft’s MAI-Image-2.5 jumps to #3 on the Arena text-to-image leaderboard (X, Announcement, Arena)



{kind=link}