



Hey yall, Alex here, let me catch you up!
I came back from vacation expecting to cover Fable 5 after a week of using it. The first two days after we all first got access to a Mythos level model were super exciting! But then the news hit, US Government issued an order banning Anthropic from giving access to Fable 5 and Mythos 5 to any foreign national, causing Anthropic to pull the models completely (even internally to their employees!).
So, this wasn’t the show I planned, but it turned into a great show about Open Source, as two models hit the top rankings and are both MIT licence, filling a Fable shaped hole in our hearts!
GLM released 5.2 with folks really excited about it web building capabilities, and Kimi 2.7 Code released (and is available on CW Inference with crazy speeds!). We also saw the SpaceX IPO and Cursor $60B acquisition, Noam Shazeer joining Open and Midjourney, the image company, launching a new Ultrasound full body scanner to kill MRIs!
Great show today with Dexter Horthy from HumanLayer, Chris Van Pelt and Adrian Swanberg from W&B announcing our new product HiveMind and Tanishq Abraham came back to help cover Midjourney’s new Ultrasound scanner! Let’s dive in!
The US Government bans Fable 5! (X, Anthropic statement)

Here’s a story in 3 parts:
Anthropic announces Mythos 5 preview - saying that this model is to dangerous to release, and only gives corporations access to it via project GlassWing.
Anthropic works hard on limitations and safery and releases Fable 5 (same weights as Mythos 5) built with guardrails so strong it refuses to do any cybersecurity tasks and switches back to Opus frequently
US Government receives a tip (reportedly from Amazon) that Fable 5 can be jailbroken to do cybersecurity tasks, and issues an order to Anthropic, citing national security concerns, banning them from giving access to Fable 5 and Mythos 5 to any foreign national, causing Anthropic to pull the models completely (even internally to their employees!)
This is the first time that we see the US Government directly intervene in the AI space and restrict access to frontier models. The most updated reporting on this I could find is that Anthropic and US Government officials are in the process of negotiating a safe release framework. Given that preventing all jailbreaks is impossible, I hope they will land on a solution that gives me Fable 5 back!

This hit especially hard because last week we were all high on Fable. Not in the usual AI Twitter benchmark sense, in the actual “oh, this is a different level” sense. Me and my wife Fable maxxed throughout our flight to Vacation. Peter had saved outputs he kept going back to because other models suddenly felt like a step down. Dexter later said it was the closest he had felt in a while to the old “I need to keep prompting this thing overnight” feeling.
Peter Gostev made a point that stuck with me. It’s easy for us in the bubble to call this ridiculous, and on the technical merits it kind of is. But if you’ve spent weeks telling normal people “this thing is like a nuclear weapon, it’ll take everyone’s jobs,” and then someone asks “okay, can you make it safe?” and the answer is “no, I can’t,” then you can see how an outsider lands on “well, maybe you shouldn’t have it.” His takeaway, and I agree: we need to be way more careful with the imagery we use, because the nuclear-weapon framing came home to roost.
The bigger questions are the scary ones. Wolfram framed it as a sovereign AI wake-up call, and he’s right. For the first time we’re seeing a real gap in intelligence available to people based on their nationality. Imagine building a company on a model that an outside government can switch off with one letter. Peter pointed out it’s commercially bad for the US but completely disastrous for Europe, which has basically one frontier lab and a pile of startups that suddenly look very exposed. And there’s the obvious irony Nisten enjoyed a little too much: the Europeans who spent years lecturing everyone about AI restrictions just got restrictions imposed on them.
If anyone in the government is listening: we want Fable back, please.
SpaceX IPOs and acquires Cursor for $60B (X)
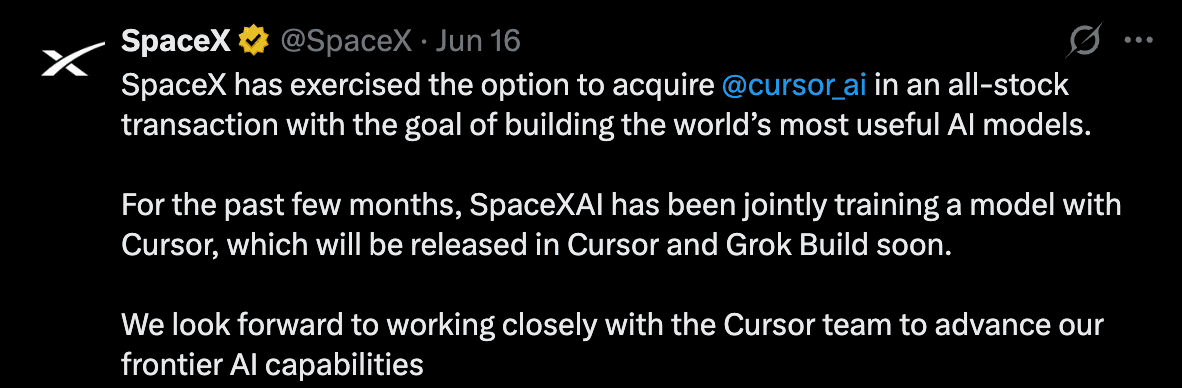
SpaceX went and did the largest IPO in the history of the world, around seventy-five billion dollars, which on a roughly two-trillion-dollar valuation made Elon the first trillionaire. (Did anything materially change for him? No. He can still fly his private plane. There’s nothing left to buy.) Three days later, SpaceX exercised its option and bought Cursor (Anysphere) for sixty billion dollars in an all-stock deal, paid in shares minted at the IPO and now trading around $211. The four Cursor co-founders are all billionaires now. Largest software acquisition ever, and for SpaceX it’s barely a blip on the radar.
Why are we covering a stock-market story? Because it’s not really a coding-tools story, it’s an AI story. Cursor gave away its IDE to a lot of people while collecting their data, then quietly became a training company with Composer. SpaceX/xAI was always strong on compute and weak on code, and the missing ingredient was exactly that kind of data. Now Composer 2.5 is already showing up rebranded inside the xAI stack, and if you pay for X Premium you can use it. Composer 3, trained on the Memphis supercluster, is reportedly coming very soon and is going to hit hard.

Nisten’s take was the spicy one. For the data alone it’s worth it, because xAI now has insight into how essentially every enterprise that touched Cursor operates. And he had zero sympathy for the companies that assumed “no data retention for training” meant the data was actually gone. We see in legal cases all the time that deleted data is still there. His view: it should have gone open source.
Cursor has over a million paying customers, $2.6 billion in revenue, projected to hit $6 to $10 billion by end of 2026. But here’s the thing that matters for us, the AI coding angle. Cursor was one of Anthropic’s biggest revenue pipelines because Composer runs on Claude under the hood. That pipeline is now owned by xAI. They’re already jointly training Grok 4.3, a 1.5 trillion parameter model, with Cursor’s proprietary coding data injected directly into pre-training, not fine-tuning. Pre-training. That’s a fundamentally different thing. Composer 2.5 was already Pareto dominant on coding benchmarks before the deal closed. Now pair that with Colossus, the biggest GPU cluster in the world.
Will this be enough to put XAI (now SpaceXAI) at the frontline of the AI race? Will Grok 5 be Fable level code? We’ll find out. Either way, this is the most consequential AI acquisition we’ve seen. Period.
Open Source AI
GLM-5.2 takes the open source crown (X, Blog, HF, Docs)

Z.ai dropped GLM-5.2 and it’s now the strongest open source model for coding and long-horizon work. The headline number: 74.4% on FrontierSWE, which measures whether an agent can finish full engineering projects over hours. That trails Opus 4.8 by about one point and beats GPT-5.5. On Terminal-Bench 2.1 it jumps to 81% from GLM-5.1’s 63.5%, which is a big leap. It’s a 753B parameter MoE, MIT licensed, no regional restrictions, weights on HuggingFace. The 1M context window is real and usable, backed by a clever IndexShare technique that cuts per-token FLOPs by about 2.9x at full context. People are reporting roughly 8x cost savings versus Opus 4.8 for comparable quality on real coding tasks.
The most interesting thing on the show was that this was a confusing release, in a good way. Peter put it well: normally a catching-up lab ships cherry-picked benchmarks and then independent testing deflates them. Here it’s the opposite, almost every benchmark holds up, even crossing above Fable at certain points, and yet when he actually used it over a couple of days he wasn’t blown away. His verdict, and I think it’s the calibration we needed: this is clearly an amazing model, and the fact that it’s open and you can run it is incredible, but it is nowhere near Fable, and it would frankly be implausible if a 700-odd-billion-parameter model matched a model that’s rumored to be in the trillions.
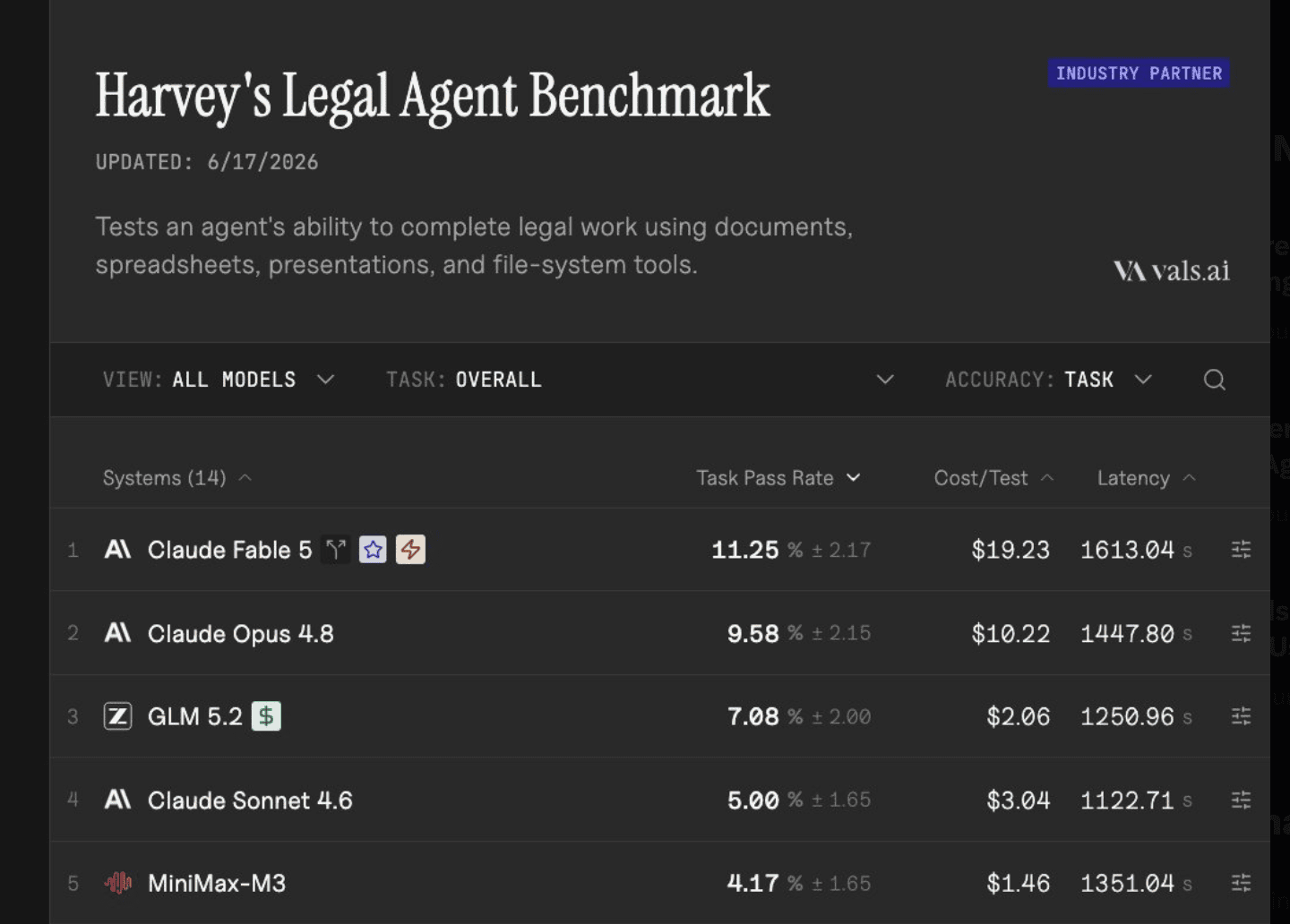
Though, I think the comparison to Fable is really really unfair, and the comments online seem to suggest that 5.2 from GLM is a banger model. Just looking at this Harvey benchmark on legal tasks from Vals, a benchmark that there’s 0 chance Z.ai folks have seen! GLM 5.2 scores #3 on this benchmark! Just after Fable and Opus, and per TeorTaxes on X, previous GLM 5.1 scored an absolute 0% on this one!
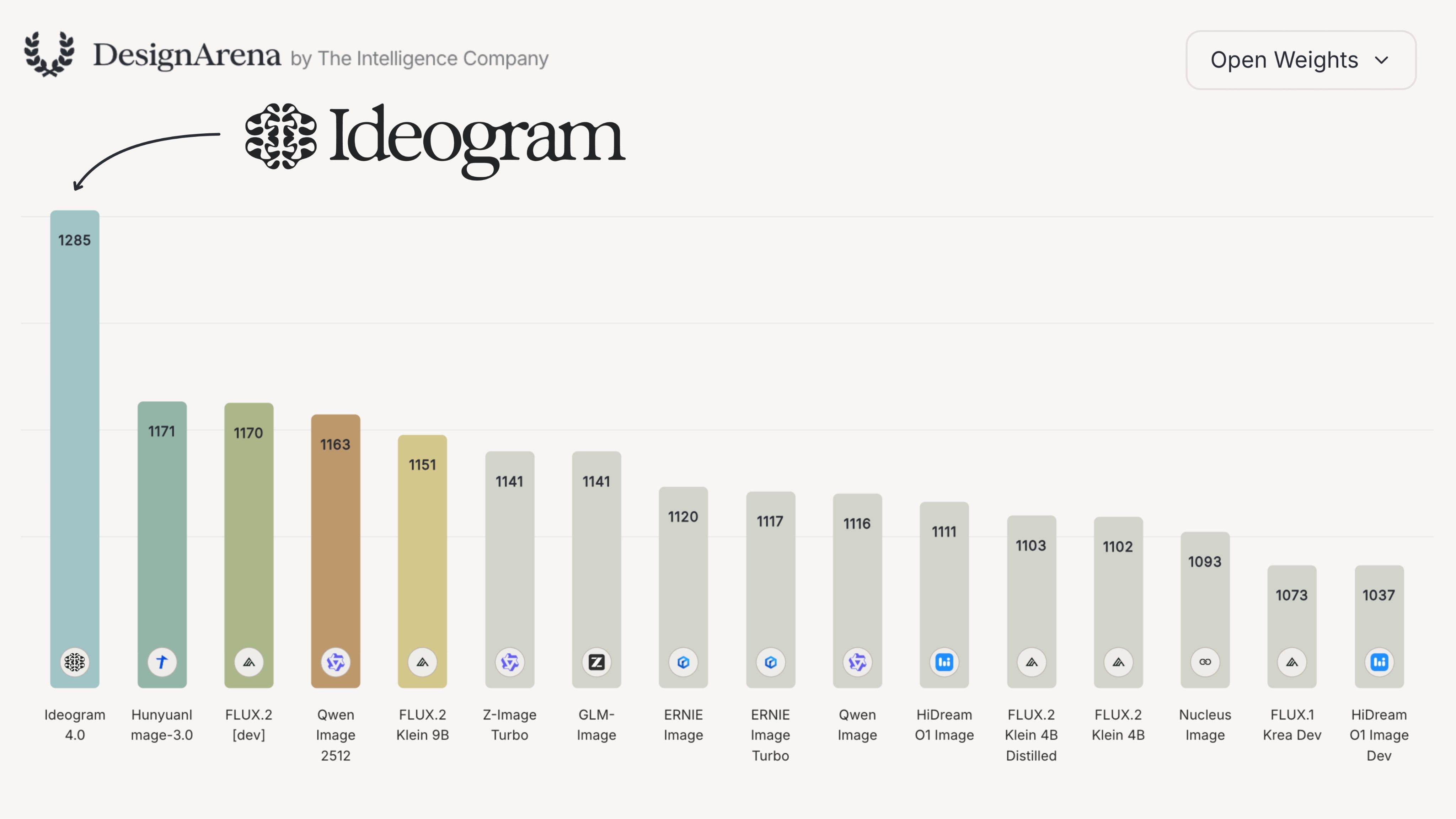
Where it genuinely shines is design. On Design Arena, which is a head-to-head ELO vote, people have been picking GLM-5.2’s website designs over Fable’s by a real margin (around 1360 to 1350). LDJ’s framing is the one I buy: specialization is becoming valuable again, and GLM is clearly leaning into front-end design and taste. Wolfram added the necessary asterisk, every benchmark only tells you the model did well on that specific test, so “as good as Fable” should always carry the “on this benchmark, with these tasks” disclaimer. Fair. I’d just say this: I don’t want to compare everything to Fable, because we can’t even use Fable anymore. Compared to the models we can actually touch, GLM-5.2 is a fantastic deal.
Kimi K2.7 Code from Moonshot (X, HF, Announcement)

The other big drop. Kimi is the darling of open source while we wait on DeepSeek, and Moonshot shipped K2.7 Code, a 1 trillion parameter MoE built specifically for coding, available through Kimi Code and the API, with a modified MIT license. The standout for me isn’t a single benchmark, it’s efficiency: roughly 30% fewer reasoning tokens than K2.6, which matters enormously when you’re running long agentic loops that burn tokens like crazy.
Benchmark jumps over K2.6 are real (+21.8% on their Code Bench v2, +11% on Program Bench), though Peter and Wolfram both noticed something odd, on a few benchmarks including their Agentic Arena, the older K2.6 actually edged out K2.7. The likely explanation is that K2.7 is narrowly trained for code with reduced reasoning, so it may trade away some general capability. Moonshot themselves recommend K2.6 for general non-coding tasks. Also worth knowing: it’s not multimodal, no vision, which is a real gap for coding these days. And thinking-off isn’t supported, it’s reasoning-on by default.
The model is available on our CW Inference, with the fastest token streaming in the industry, over 280 tok/s (Announcement, try it), with very decent pricing $0.94 - $0.19 - $4.00 (input - cached - output) per million tokens.

This Week’s Buzz: W&B launched HiveMind 🐝 - track all your agentic work in one place (X, Try it, GitHub)
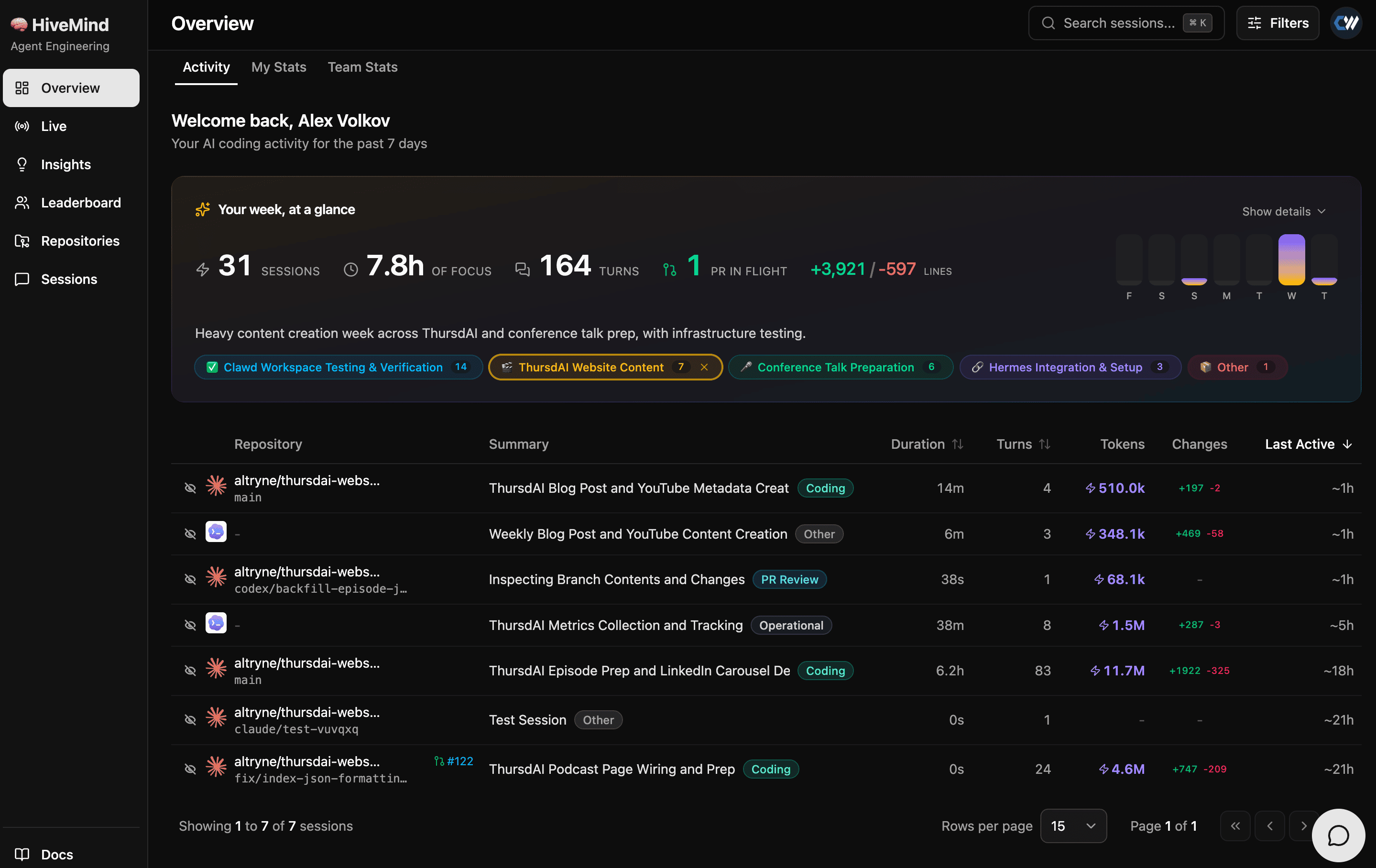
This is the one I’ve been sitting on for months. We brought on Chris Van Pelt (CVP), Weights & Biases co-founder, and Adrian Swanberg to launch HiveMind, and I’ll be honest, I’ve been a beta user for a while and I’m thrilled I can finally talk about it.
The premise: what it means to be a software developer has fundamentally changed, and your work is now scattered across six or seven agent dashboards. HiveMind is a tiny daemon that sits on your machine, picks up sessions from whatever harness you’re running (Claude Code, Codex, Cursor, Gemini CLI, OpenCode, GitHub Copilot, Pi), and within about 30 seconds they show up in one shared dashboard. It breaks each session into chapters, shows which files the agent touched, what to-dos it wrote, where context got compacted. W&B has been running it internally for six months.
A few things genuinely delighted me. There’s a fork button: HiveMind pulls down a compacted history of a session and lets you relaunch it in a different harness, so you stay harness-agnostic. CVP’s line: “this has proven invaluable when Anthropic servers are on fire and I just gotta get something done.”
Then there’s the skill engine, which to me is the real magic. It reads your team’s sessions and can clone a power user’s whole approach into a reusable persona, at CoreWeave they built a “Talk to Tim” skill from Tim Sweeney’s sessions, and apparently a virtual Tim is now a popular way to get guidance. And the insights feature detects where you kept correcting the agent, clusters those pitfalls across the org, and hands you a smart-merge command to drop the fix straight into your AGENTS.md.
I’m excited to finally show this to you, it’s been genuinely helpful (for example, last week I was able to test Fable and tell you the number of tokens it used until i maxxed out my Claude Subscription!) - give it a try at hivemind.wandb.tools
HumanLayer launches its Agentic IDE, and a real talk about code slop (X, humanlayer.dev, 12-factor-agents)
Dexter Horthy, friend of the show and the team behind 12 Factor Agents and the Research-Plan-Implement framework (now running inside Block and Uber), launched HumanLayer’s Agentic IDE this week, and we got into one of my favorite conversations of the year. The whole product is explicitly anti-slop. His argument: the “lights-off loop,” where humans only write tickets and the agent codes, verifies, ships, and feeds its own crashes back to itself, is the fastest way to trash a codebase. Vibe coding is great for zero-to-one and side projects nobody depends on. But if you’re a staff engineer in a high-stakes codebase, dear God, read the code.

This ties directly into my AI Engineer World’s Fair talk, the ZL continuum, which Dexter half-inspired. On one end you’ve got the YOLO camp (Ryan from OpenAI, one billion tokens a day, nobody can read that much code) and on the other Mario from PI (read every line of critical code). Those two are now the sixth and seventh most-watched AI Engineer talks globally, which tells you the whole field is wrestling with this. Dexter’s answer is leverage. Don’t aim for a perfect spec, because a perfect spec is just code. Get it 80% right, then zoom down a level at a time so the chunk you’re steering is human-consumable. He claims that an hour of upfront prep on architecture and even program design turns a three-hour code review into a twenty-minute one.
I pushed him on the obvious counter: why does code quality even matter if Fable-class models keep arriving and maintenance is a prompt away? His answer was the most grounded thing I heard all week. Code quality matters for the same reason it mattered in the 1970s software crisis: pile in code without structure and your velocity tanks, every change starts breaking something else. And here’s the irony, we train models on beautifully architected projects (Django, Redis, Spring on SWE-bench multilingual), yet they still reward-hack their way to “just make the test pass.” We don’t yet have a penalty function or a verifier for “this code is harder to maintain,” and that’s hard to build, so humans are still needed in the loop. He played with Fable too, threw an 8K-line React PR refactor at it, and the first pass was bad, it introduced React context and patterns they don’t use. Better than before, not a step change that lets you drop the reins. We’re not there yet. It’s BYOK, $100/user/month for pro with a free tier for teams of three.
OpenRouter Fusion: near-Fable quality at half the price (X, Blog, Announcement)

Wolfram spotted this one and it’s clever. OpenRouter’s Fusion is a single API call that fans your prompt out to a panel of models, then a judge model reads all the responses and a synthesizer writes the best combined answer. It’s the LLM consortium idea (the thing we used to do by hand, asking several models and stitching the best parts together), now baked into the API so you don’t build it yourself.
The wild result: on Perplexity’s DRACO deep-research benchmark, a budget panel beats solo GPT-5.5 and solo Opus 4.8 and lands within 1% of Fable 5 at roughly half the cost. The most interesting finding is that about three quarters of the lift comes from the synthesis step, not from model diversity, they even fused Opus with itself and got a 6.7-point jump. The catch is latency, it’s 2-3x slower, so it’s a deep-research and planning tool, not a quick-query tool. Big shout out to OpenRouter.
Vision and video
Google Gemini Omni, finally with API access, takes #1 on video benchmarks (X, Announcement)
We covered Google’s new video model Omni at Google I/O, and it finally landed as an API. It’s Google’s first any-to-any model, one single unified system for text, image, video, audio, and music. Think Nano Banana, but for video. Peter tested it and it scored really, really well, the kind of jump between generations you saw with GPT-image-2. Independent testing put it at #1 for realistic body physics and #2 behind Seedance for complex action, and it topped MovieGenBench for preference and instruction following. The session-memory piece is the part I find most useful: you can keep editing across turns, characters stay consistent, you say “continue” and it picks up where it left off. It’s live in the Gemini app, Google Flow, and YouTube Shorts
Grok Imagine Video 1.5 (X, Blog, Docs)
xAI’s Grok video work has been quietly getting really good, and they finally gave us an actual version number instead of silently updating “Grok Imagine” over and over (which drove me nuts). Grok Imagine Video 1.5 generates a 6-second 720p clip in about 25 seconds, down from 40-plus, so nearly 2x faster, with native audio generated in the same pass: sound effects, ambience, dialogue, lip sync, no post-production stitching. It hit #1 on the Design Arena image-to-video board with a 1,357 Elo and a ~49 point lead, and it’s generally available in the API. I ran my standard astronaut-riding-a-horse-on-the-moon prompt and it came back with music too. Genuinely cool.
Sci-Fi is here: Midjourney announces a full-body ultrasound scanner to compete with MRIs (X, Announcement)
I’m still processing this one. Midjourney, you know, the image generation company, announced medical hardware. A new division called Midjourney Medical, and its first product is a full-body ultrasonic scanner. Tanishq Abraham was there in the front row and joined us to break it down.
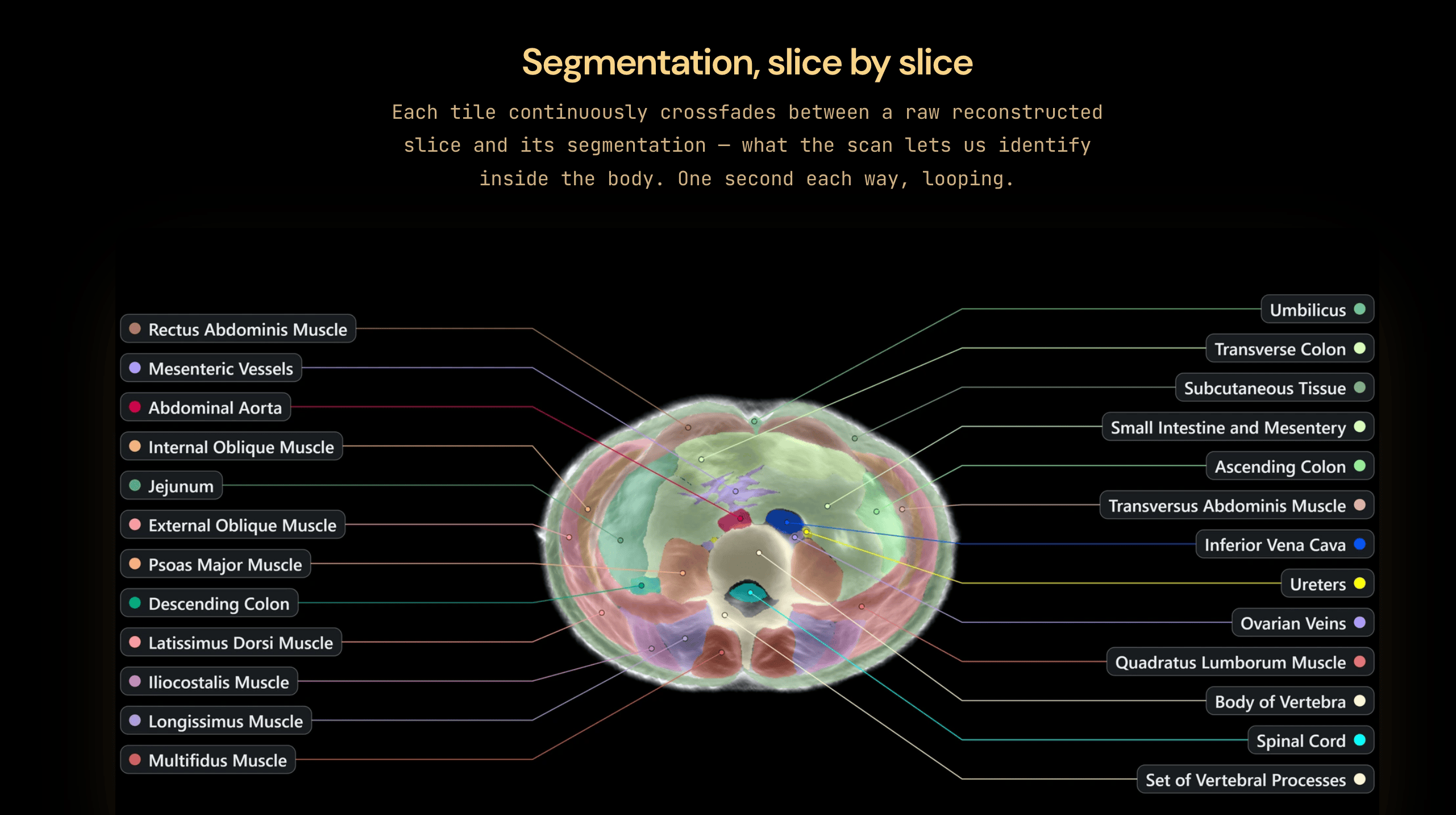
The device uses thousands of ultrasonic transducers arranged in a ring. Because sound doesn’t propagate well through air, you’re lowered into a tank of water, the sound travels through your body at 1,481 meters per second, and in under 60 seconds you get a 3D anatomical map of 25-plus organs. The raw data is roughly 806 terabytes per scan, streaming at about 16-17 gigabytes per second, and the only way to handle that firehose is AI. No radiation, no magnets, no superconductors, which is what makes MRI so expensive. David Holz has apparently wanted a medical imaging lab for two years, and because Midjourney is fully self-funded with no VCs, they can chase wild projects like this.
The fun reveal from Tanishq: there’s no AI in the actual image reconstruction yet, it’s basic signal processing right now, with physics simulators and possibly NeRF-style neural fields on the roadmap (there was a hallway conversation with John Barron about exactly that). So this is a prototype with enormous headroom. The business model is the spa, a 24,000-square-foot space about ten minutes from Union Square in SF with around ten scanners, targeting end of 2027, then custom sensors in 2028, scaling toward 50,000 scanners doing a billion scans a month.
Now, for a dose of reality, this is just an announcement, and ultrasound won’t replace MRIs anytime soon. For one, ultrasound cannot penetrate bone and air, so lungs (full of air) and brain (literally encased in bone) are out, but it’s still great ot see Dave Holz innovating in the medical space and I’m excited to try this out!
Wrapping up
What a strange, whiplash week. We got the best model any of us had ever used taken away by a government letter, watched a meme become a real Mistral roadmap, saw open source close the gap on the models we can actually run, and watched an image company casually announce it might kill the MRI. I came back from vacation thinking I’d write you a Fable love letter and instead I’m writing about deemed-export law and ultrasonic water tanks. That’s the job, and honestly I wouldn’t trade it.
If you’re heading to AI Engineer World’s Fair, come find Wolfram and me, Weights & Biases and CoreWeave are sponsoring the whole thing, and my ZL continuum talk will name-check a lot of what we covered today (Day 3 • Wed, July 1 · 10:45am-11:05am) . And if Fable comes back next week, you’ll hear me yell about it first.
See you next week, and please, US government, give us Fable back.
ThursdAI - Jun 18, 2026 - TL;DR
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases, CoreWeave (@altryne)
Co-Hosts - @WolframRvnwlf, @ldjconfirmed, @petergostev (Arena), @nisten, @yampeleg
Dexter Horthy (@dexhorthy) - Founder, HumanLayer
Chris Van Pelt (@vanpelt) - Co-founder, Weights & Biases (HiveMind)
Adrian Swanberg - Weights & Biases (HiveMind)
Tanishq Abraham (@iScienceLuvr) - Founder, Sophont AI (reporting from the Midjourney Medical event)
Big CO LLMs + APIs
Noam Shazeer is joining OpenAI - co-author of the Transformers paper and co-founder of Character AI, teaming up with Noam Brown
US government orders Anthropic to shut down Fable 5 and Mythos 5 access for all foreign nationals (including its own employees), citing national security; Anthropic disables both for everyone to comply (X)
SpaceX acquires Cursor (Anysphere) for $60B in an all-stock deal, the largest software acquisition in history, days after its record IPO (X)
Open Source LLMs
GLM-5.2 drops as the strongest open-source coding model with solid 1M context, MIT-licensed, trailing Opus 4.8 by just 1% on FrontierSWE (X, Blog, HF, Announcement)
Moonshot AI open-sources Kimi-K2.7-Code, a 1T MoE coding model with 30% fewer reasoning tokens and big benchmark jumps over K2.6 (X, HF, Announcement)
Mistral CEO Arthur Mensch playfully confirms the ‘Le Gros Chaton’ meme, hinting at an upcoming fat-but-sparse open-weight model family (X, Summary, Blog)
This Week’s Buzz - W&B and CoreWeave
Weights & Biases launches HiveMind, a unified dashboard to track spend and ROI across all your AI coding agents (X, Announcement, GitHub)
Kimi K2.7 Code is live on W&B / CoreWeave Inference at 289 tok/s (NVFP4 on Blackwell + speculative decoding), top of Artificial Analysis for speed and price-performance
Tools & Agentic Engineering
Claude Design gets a major update: design system imports with self-audit, canvas editing, bidirectional Claude Code sync (/design-sync), and PDF/PowerPoint export (X, X, Announcement)
HumanLayer launches its Agentic IDE to fight AI code slop, already deployed at Block and Uber (X, Blog, 12-Factor Agents)
OpenRouter launches Fusion API: a panel of budget models beats GPT-5.5 and Opus 4.8, lands within 1% of Claude Fable 5 at half the price (X, Blog, Announcement)
OpenAI rolls out Codex Computer Use, Chrome extension, Memory, and Chronicle to European users in the EEA, UK, and Switzerland (X, Announcement)
Vision & Video
Google DeepMind launches Gemini Omni, their first any-to-any generative model starting with video editing and creation (X, Announcement)
xAI launches Grok Imagine Video 1.5 with near-2x faster generation, native audio, and a #1 leaderboard position (X, Blog, Announcement)
Sci-Fi is here
Midjourney announces ‘Midjourney Medical’ - a full-body ultrasonic scanner that captures 806 TB of data per scan in under 60 seconds (X, X, Announcement)


