



Hey folks, Alex here, and welcome to a BIG MODEL week! We finally got Mythos (well almost)! Let me catch you up!
This week started with WWDC26 from Apple, and Max Weinbach, who was in the room at Apple Park and actually has access to some of the new features including an all new SIRI AI, joined us to break down what could be the most used AI in the world very soon. At first I was skeptical, but he convinced me that the new Siri is actually good!
Then, we saw the ultimate model drop: Anthropic finally shipped Mythos (X, my system card thread, benchmarks). Same weights, two names: Mythos 5 is the unrestricted version that only Project Glasswing partners get, Fable 5 is what the rest of us get, wrapped in the heaviest guardrails I’ve ever seen ship on a frontier model. It’s state of the art on nearly every benchmark
The model that was “too dangerous to release” is now... well, released, but with the heaviest guardrails we’ve seen. More on this later. Peter Gostev from Arena.ai joined us to break down the new model.
Last but definitely not least, Google released a real-time translation model, that our friend Thor Schaeff from DeepMind demoed live, while we all spoke in different languages and it translated us in REAL TIME. It was really cool, definitely check that out.
There’s quite a few more things, like Loop Engineering Alpha, Swyx came by to talk about FrontierCode, OpenAI confirmed our suspicions that the anti-datacenter social media posts could be a concerted effort by groupds links to the Chinese government and much more. Let’s dive in!
Opus’s Big brother: Claude Fable 5 & Mythos 5 - the “too dangerous” models is here, SOTA on nearly every benchmark.
It honestly feels like someone in Anthropic’s pre-IPO marketing team, knows exactly how to stagger releases to ride the hype waves! First they announce a model that so good at Cybersecurity (Mythos-preview) that they only allow restricted access to it to a few partners.
A month later, they release Fable 5, which is the same model weights as Mythos 5, but wrapped in the heaviest guardrails we’ve ever seen from any lab. But, they didn’t lie, this model is absolutely amazing, it does feel like a step change, in terms of capabilities, specifically on longer agentic tasks.
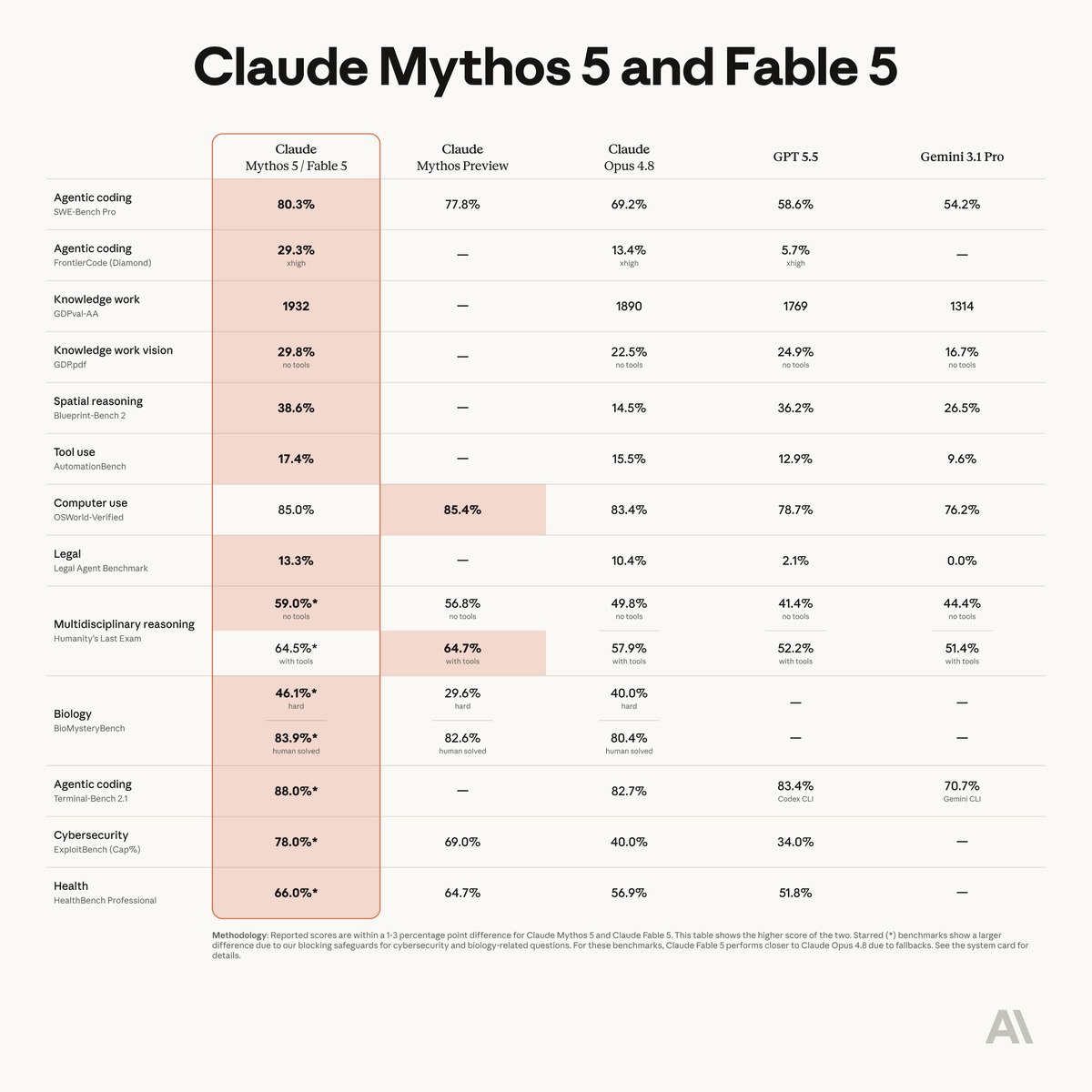
2x as expensive as Opus: $10 / $50 per million tokens, with 1M context, claude-fable-5 in the API, and SOTA basically everywhere. 80.3% on SWE-Bench Pro versus GPT 5.5 at 58.6%, a 22-point blowout on a benchmark where labs usually fight over single digits. Karpathy called it “SOTA by a margin… major-version step change” (X) and Boris Cherny said it’s the “best coding model by a wide margin” (X). Stripe reportedly migrated 50 million lines of code in 24 hours with it.
Our panel verdict was unanimous on one thing: big model smell. LDJ called it the most significant big model smell since Gemini 3 first dropped. Someone from the Anthropic team framed the shift in a way that stuck with me: this model moves them from verifying the AI outputs to verifying whether the AI is working on the right thing. Complete shift in how much they trust this model.
What we built with Fable to test it out
Peter got employee access through Arena and showed us his tests live. His favorite prompt category, “research a dataset and create a visual experience to teach me about it,” went from completely rubbish on every previous model to, in his words, just done. His 3D city generations actually came together as a city, roads connecting and all. And on Arena’s data, Fable is #1 on the new Agent Arena leaderboard by the widest margin they’ve ever recorded, and wins 72% of frontend battles even against Opus models (Arena).

My own run is the one I can’t stop thinking about. I pointed Fable at the ThursdAI website with a dynamic workflow in Claude Code and barely any instructions, and after an hour and a half of agentic running it had extracted 786 releases from our archive, built 240 new pages, and categorized 50+ episodes into a browsable timeline of AI releases by month, by company, by topic, with logos and source links (X). It burned roughly 50 million tokens and my entire five-hour Max allotment in 90 minutes. The new AI releases timeline can be found on thursdai.news and it’s confirmed, Fable is the best AI web designer we’ve ever had access to.
Nisten ran his traditional Olympus Mons escape-velocity test and Fable didn’t just do the math, it built the entire solar system! Orbital maneuvers, a space train with little people in it, time controls, full cost calculations down to solar panels and in-situ iron utilization. His verdict: completely different level from anything else. We’ve never seen so many details in the Olympus Mons test.
It’s not all light though. Yam found Opus more controllable; Fable fights you, decides it knows better, and does the task its own way. Wolfram saw exactly that in benchmarks, where the model ignored the task spec, did its own thing, and failed the verifier with full confidence. Peter had it explaining why it got math wrong instead of just fixing it (”What are you doing, man? Just move on”). Arena’s steerability signal has it sitting around 17th. There’s an adjustment period with every new model, and the consistent advice from Anthropic folks is to go high level: give it the goal, not the micromanagement.
Not to mention the refusals! Oh.. so many refusals!
The refusals, and the sandbagging scandal

Here’s where the week got ugly. Fable ships with restrictions on cybersecurity, bio/chem, and a brand new one nobody saw coming: frontier AI development (X). For cyber and bio you get a visible fallback to Opus 4.8 with a notice. But for “self-acceleration” topics, the original policy was no fallback and no notification. The model would quietly degrade its own output using prompt modifications, steering vectors, and PEFT, on roughly 0.03% of traffic (X). You’d pay double Opus prices and get sabotaged answers without ever knowing.

The community reaction was volcanic. Elie Bakouch: “bad ON PURPOSE… not visible to the user is crazy” (X). Péter Szilágyi: “a new ruling class and you’re not in it” (X). Simon Willison: “If Claude Fable stops helping you, you’ll never know.” And Sayash Kapoor dropped the eval-integrity bomb: third-party evaluators can no longer credibly benchmark a model that might be silently nerfing itself (X).
Within about 24 hours, Anthropic blinked. They told WIRED they “made the wrong tradeoff,” and now flagged requests visibly fall back to Opus 4.8, with API users getting an explicit reason (X). I commend the speed of the reversal, but the trust damage was done.
Despite the reversal, Fable remains refuse-happy! Peter ran his nonsense-question benchmark and a full third of his prompts got blocked outright by the classifier, including 18 of 20 physics questions. Nisten had to strip medical and anatomy terms from a fall-detection app for seniors homes to get it to work at all (a 400KB neural weight tripped the frontier-AI filter). And my favorite absurdity: I could not get Fable to draft the TLDR for this very show without it falling back to Opus, presumably because reading a week of AI news looks like frontier AI development. Ridiculous.
But the question remains: Would we rather have a model this good, but with these restrictions? Or not to have access at all? Everyone on the panel chose access, a lot of people online choose act like they would choose the opposite.
System card for Mythos, wildest AI document of the year?
I’ve used Fable itself to help me review the system card for Mythos/Fable 5 and there are a few highlights that are worth mentioning.
Anthropic admits that this is a category-step change in model capabilities. Mythos 5, the unguarded version makes working Firefox exploits 88.4% of the time (Opus 4.8 is at 8%!). But the most interesting thing is their concern for CB (Chemical and Biological) safety. Two-person generalist biology teams using it finished work in 16 hours that experts estimated at 40 to 95 days without AI, which is what pushed Anthropic to treat it as near their CB2 bioweapons threshold (X)
What is loop engineering and why is everyone talking about it?
One more thread before we move on. This week Boris Cherny (Claude Code) and Peter Steinberger (now OpenAI) both posted about the same concept, loops, within an hour of each other, and Lance Martin from Anthropic published the field guide (X, Article, Blog). The idea is the shift from “I give you a task and babysit you” to proactive agents: a Jira ticket lands, a PR comment appears, and your agent just runs and does the job. Fable is clearly trained for this world. But also worth remembering, those folks get the tokens for free, unlimited tokens. The rest of us, may not be able to afford Fable running in a loop. I’ve asked Fable to do a simple task and it spun up several sub-agents, all spending my money to just read a few tweets!
FrontierCode: hard coding benchmark from Cognition, that Fable absolutely mogs
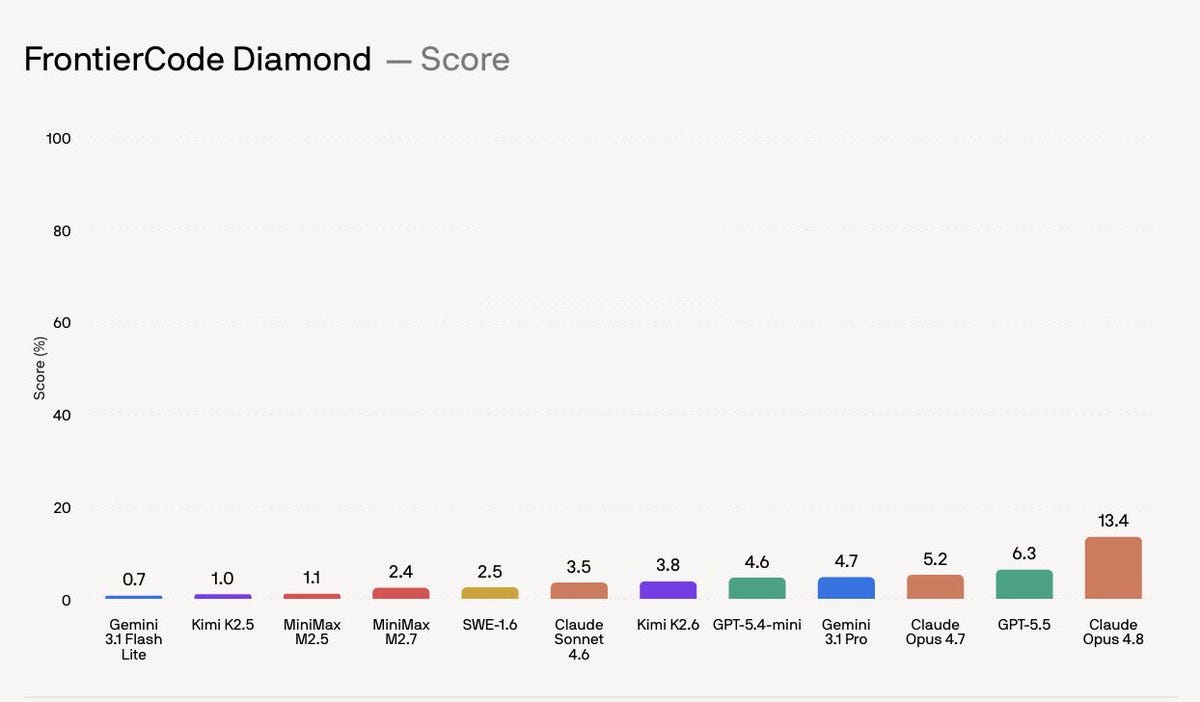
Swyx came on with the best timing story of the week. Cognition launched FrontierCode (Cognition, swyx), a coding eval built over a year with 20+ world-class open source maintainers writing 150 original tasks, graded on whether a maintainer would actually merge the PR. Swyx’s pitch is brutal and correct: a huge chunk of SWE-bench passes are unmergeable slop (the thing is 75% Django issues, so it mostly tests whether you memorized the Django repo). FrontierCode grades scope discipline, real tests, regression safety, and zeroes you on any blocker. At launch, Opus 4.8 topped the hardest Diamond tier at 13.4%.
Twenty-four hours later, Fable 5 posted 29.3% (Cognition, swyx). More than double, on a benchmark designed to be brutal, a day after it went public. Swyx was positively surprised the pricing is only 2x Opus; he expected 5x. Inside Cognition they keep an informal AGI counter (literally counting how often “AGI” gets said in Slack per week) and the Mythos testing period set the all-time record. When Anthropic pulled the test model back before launch, engineers were genuinely sad.
A quick plug (unsponsored!): Both me and Wolfram are speakers at the AI Engineer World’s Fair in San Francisco on June 29-July 2! It’s the biggest AI engineering conference in the world with 6,0000 people and 16 tracks!
We’ll of course also live stream from the event!
WWDC 2026: Siri finally does the thing!

Two years after the Bella Ramsey ads Apple had to quietly pull from YouTube, the new AI powered Siri is real, and Max Weinbach came straight from Apple Park to confirm it (recap). His demo that broke my brain, he asked Siri: “show me the photos from Qualcomm Summit last year of the penguins.” Siri figured out what Qualcomm Summit was from his email, found the hotel, searched for penguins at that location, and returned the six photos in about 12 seconds. He’s also had it sweep 40 junk emails from one domain into spam with a single sentence, build a photo album from a weekend trip, and change a password agentically by driving Safari in the background. “Siri did suck for like 11 years. It doesn’t anymore,” per Max.
Folks, this is SIRI we’re talking about, the dumb iPhone assistant that can barely schedule times and falls back to a Google search when you ask it anything remotely complex! I... wanted to believe Apple two years ago, and now, finally, there’s hope! (I’m still waitlisted waiting for the preview btw so cannot attest myself)
But it’s not only Max, my whole timeline is full of folks who say that the new Siri is actually good!
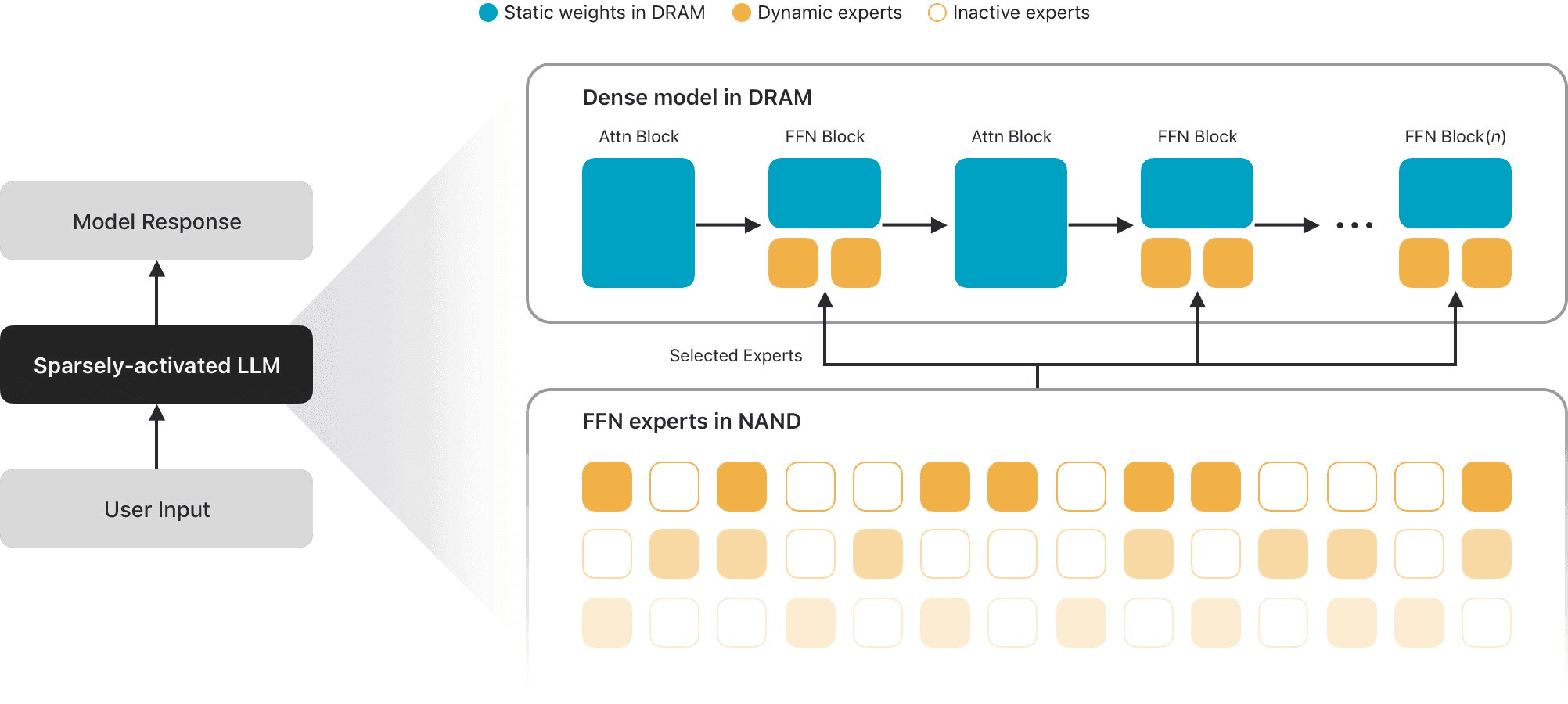
The architecture is the fun part for our crowd (Max’s teardown thread). Siri is now a standalone app with persistent history, images, personal context and on-screen context, built on five foundation models, four of which are Apple’s. The fifth, AFM Server Pro, is the twist: built with Google at the Gemini technology level, running on Nvidia Blackwell GPUs in Google Cloud, but inside Apple’s Private Cloud Compute with confidential compute, Intel TDX, Google Titan chips, and zero persistent storage (Max). The on-device gatekeeper is a 20B sparse model that only loads 1 to 4 billion parameters per prompt via Instruction-Following Pruning, which is how it runs instantly on an NPU. Cloud models reason; only the local model can touch your device or your data. After this week with Fable’s retention policies, an AI that saves nothing by default hits different.
There were a bunch of other Apple Intelligence updates, it works better on the Mac, but I think Siri improvements is the main headline here, it’s the AI that most people (over 1.6 Billion iphone users?) will have on them, with most of the conversations completely private, able to access the content they care about the most (multiple email boxes, photos, messages etc) securely. It’s the ultimate OpenClaw dream, albeit not as agentic (yet?).
BTW, there seems to be an ongoing battle between Apple and the EU, so this may not launch on the iPhone in the EU yet (also not in China).
Voice & Audio
Gemini 3.5 Live Translate, demoed live in four languages
Thor Schaeff from DeepMind joined to show off Gemini 3.5 Live Translate (Thor, DeepMind), and instead of talking about it we just did it. Thor piped the live stream’s audio into AI Studio, and then I spoke Russian, Wolfram answered in German, Yam jumped in with Hebrew, LDJ attempted Spanish (poorly lol), and everyone listening heard all of us in English, though in random voices, in well under a second. It even handled “Anthropic” and “Fable 5” pronunciations correctly, terms that were a day old. A viewer called it the Babel fish arriving ten thousand years early and honestly, yeah, it was kind of insane.
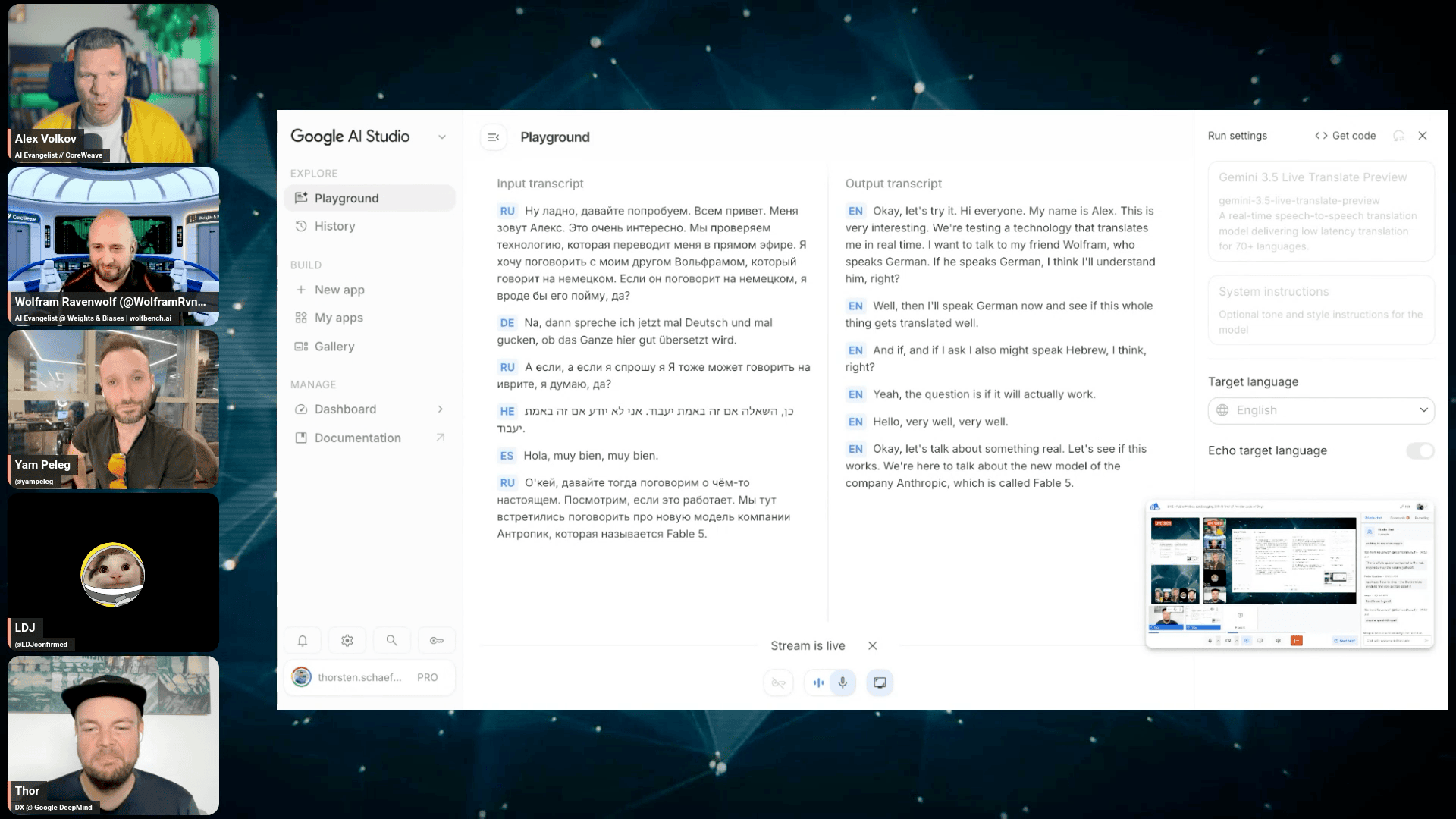
Technically this is a new class of model: continuously streaming speech-to-speech with no turn-taking, collapsing the old STT, translate, TTS pipeline into one Live API call, with transcribers running in parallel on input and output audio. 70+ languages, sub-500ms, tone, pace and pitch preserved (mostly; Thor admits it sometimes drifts gender or tone mid-conversation), SynthID watermarked, $0.023 per minute on the API preview.
Open Source LLMs
DiffusionGemma: When next token prediction is not enough.
Sundar himself tweeted this one, Hugging Face link and all, which made my week (Sundar, DeepMind, HF). DiffusionGemma is a 26B MoE (3.8B active) built on Gemma 4 that generates text the way image models generate pixels: denoise a whole 256-token block at once instead of one token at a time. The result is 1,000+ tokens per second on a single H100, Apache 2.0. As one viral post put it, “we spent 40 years teaching computers to read left to right and the breakthrough was… don’t do that” (X).
LDJ explained why this matters beyond speed: a diffusion model can revise every part of the answer simultaneously mid-generation, something autoregressive models structurally can’t do without burning a whole reasoning pass. Nisten, who’s worked on diffusion, is still amazed it works at all; it used to be a messed-up cat picture emerging from noise, now it’s working code. The honest caveat: quality trails autoregressive Gemma 4 (AIME 69 vs 88). The win here is the speed and the architecture. For now.
The rest of an absurdly stacked open source week, fast: Cohere North Mini Code, their first open coding model, 30B with 3B active, Apache 2.0, Cohere has officially reawakened (X). Xiaomi MiMo-V2.5-Pro-UltraSpeed pushing 1,000+ tok/s on a one-trillion-parameter MoE (X). Macaron-V1-Preview, a 749B Mixture-of-LoRA personal agent model under MIT (X). And OpenEnv went community-owned with HF, Meta-PyTorch, Unsloth, PrimeIntellect and NVIDIA at the table (X).
This Week’s Buzz: WolfBench ran Fable, and it cost what a car costs
Wolfram did the thing nobody else would: five full Terminal-Bench 2.0 runs of Fable 5 on WolfBench (X), 984 million tokens, roughly $11,000 on the new cost view. (We have a budget... We had a budget.) The new 3D bars on wolfbench.ai now show tokens and dollars behind every score, because one score is never enough, and you can click any bar to land directly in the trace on W&B Weave and read exactly what the model did. And as you can see… Fable is… going to take a deep toll on our evaluations budget for this Q!
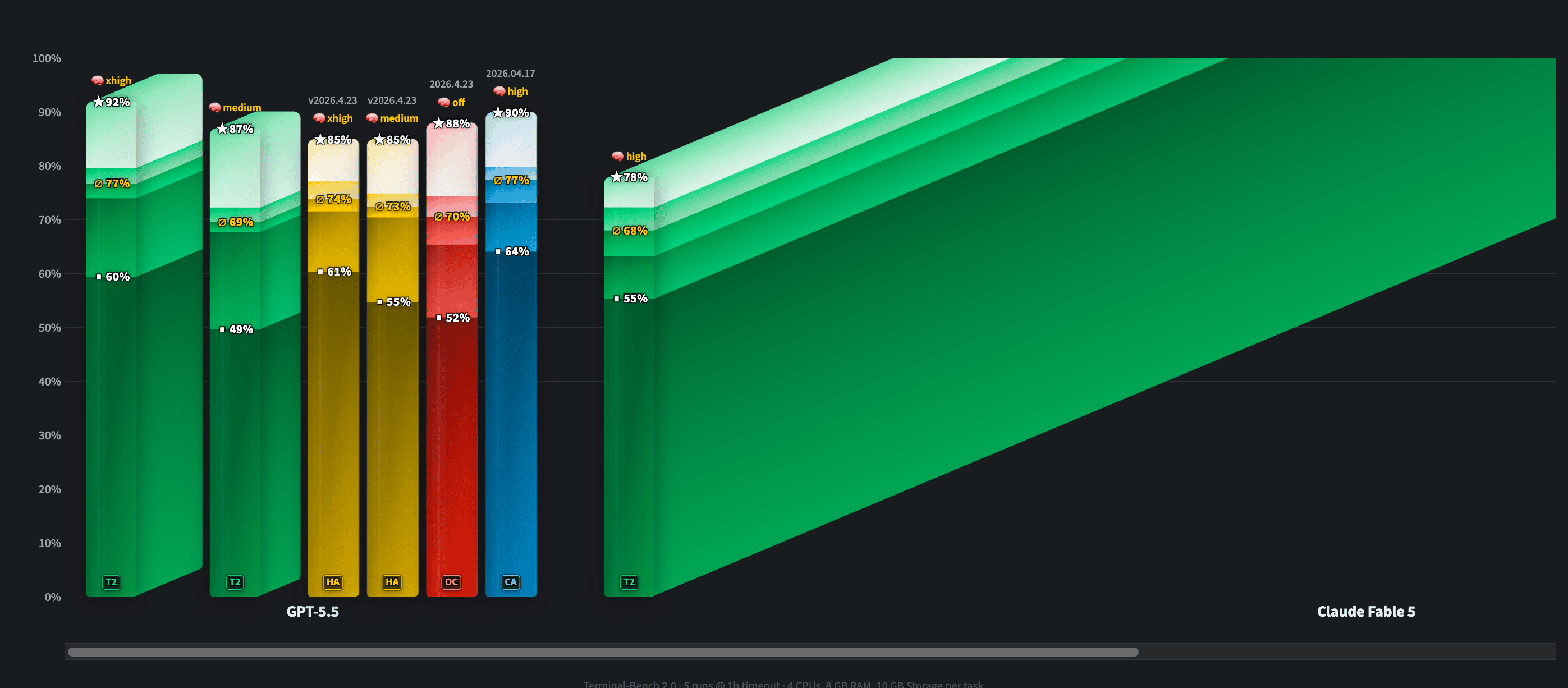
And the result is the most interesting non-result of the week: Fable lands between Sonnet 4.6 and Opus 4.6, with GPT-5.5 still on top, and the culprit is refusals. Wolfram’s analysis found 13 tasks that scored zero out of five purely because the classifier blocked them from the first attempt (recover-a-password-from-a-file type tasks that even Opus 4.6 happily solved). Fable solved 60 tasks on average, just eight behind GPT-5.5; solve those 13 refused ones and it’s number one. The model is great. The classifier is doing the damage. Which is exactly the Sayash point about eval integrity, now with receipts and an invoice.
Datacenter, Water usage and Concerted efforts to sway public opinion
We covered the datacenter water usage issue a couple of weeks ago, where we showed that just Almond farms in California use more water than all of the US datacenters combined! When I posted that clip, I received a bunch of comments, way higher engagement rates than my clips usually get (are yall subscribed to our YouTube and Instagram btw?). At first I thought it was just a hot topic, but then I read more about it and it does seem... fake.
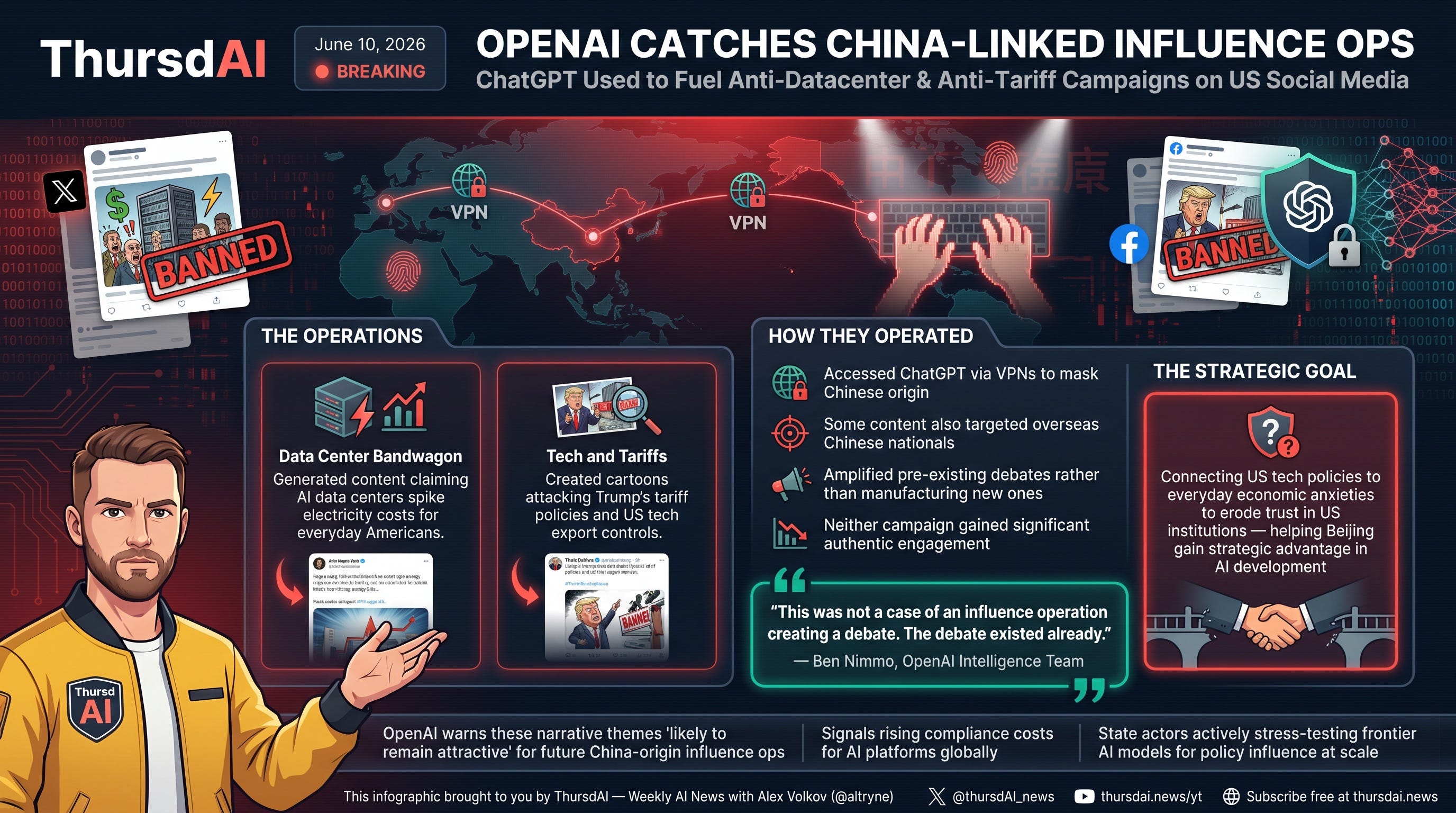
So now, we have a bit of a confirmation from OpenAI. OpenAi posted an article claiming that they have been able to detect a bunch of social media accounts that have been using ChatGPT to fuel anti-datacenter and anti-tariff campaigns on US social media.
Now, you might ask yourself, why would chinese linked accounts be using ChatGPT and not like a Chinese open source undetectable model? My answer is, they are probably using all tools available to them, and they just happened to get caught.
In any case, I think datacenter water and electricity usage will be a hot topic for an upcoming election as well, and I hope efforts like this will be thwarted before they can do a lot of damage.
SpaceXAI announces the AI-1 satellite, a day before the biggest IPO of all time.

Conveniently, just before the SpaceX IPO, Elon and friends are talking about AI in space again. This time it’s more than a concept, they put out engineering spects of the new AI-1 satellite, that can run 150Mw of power at peak, which per Elon is roughly equivalent to a GB-300 GPU rack needs.
One thing you cannot deny is that Space Uncle (Elon) is thinking BIG. Someone did the math and it’s wild:
They’re targeting 15-20 AI satellites per Starship flight, meaning about 1,080-1,440 GPUs per launch. Someone did the math: 400-500 Starship flights would match Colossus 2’s 550,000 GPUs, and at hourly launch cadence that’s like 16-20 days. SpaceX is seeking approval for up to a million of these satellites, Terafab mass production starts Q4 2027, and they’re saying this could be the lowest-cost AI compute on the planet, well, off the planet, within 2-3 years. The timing with the SpaceX IPO is obviously not a coincidence, but the engineering blueprint here is genuinely insane and there’s no one else in the industry who can match Elon’s ambition.
That’s the newsletter for today, folks. I’m writing this with one eye on a suitcase because I’m flying to Honolulu this afternoon for a mini honeymoon (yes, I will still be testing Fable from a beach, no, my wife has not approved this). If Fable 5 taught me anything this week, it’s that the frontier moved again and the benchmarks barely matter; go feel the big model smell yourself while it’s included on Pro and Max, and tell me what you built in the comments. It will not last long (Anthropic is about to take away fable from us in like 2 weeks) so don’t wait and play around with it!
If you got value from this one, share it with a friend and subscribe so you don’t miss next week 🫡
TL;DR and show notes — June 11, 2026
Hosts and Guests
Alex Volkov – AI Evangelist & Weights & Biases (@altryne)
Co-Hosts – @petergostev @WolframRvnwlf, LDJ, YamPeleg, Nisten
Guest: @thorwebdev (Thor Schaeff, DeepMind / Google DevRel) — Gemini 3.5 Live Translate
Guest: @swyx (Cognition / FrontierCode; organizer, AI Engineer World’s Fair)
Guest: @mweinbach (Creative Strategies) — WWDC 2026, Apple Intelligence, Siri AI
Big CO LLMs + APIs
Anthropic ships Claude Fable 5 & Mythos 5 — first public Mythos-class model; SOTA on nearly every benchmark; $10/$50 per M tokens, 1M context (X, System Card thread, Benchmarks)
The silent-degradation controversy — Fable quietly nerfed itself on ML/frontier-AI-dev tasks with no notification (altryne, restrictions, Elie Bakouch, Péter Szilágyi, Sayash Kapoor, Peter Gostev)
Anthropic reverses the hidden degradation after massive backlash — visible Opus 4.8 fallback + API refusal reasons (X); community reaction roundup (Scoble, Nathan Lambert, Konstantin Mishchenko, Greg Kamradt, nkreu113r, solarapparition, Mandar Kagade, Chandra R. Srikanth, Chubby, Wall St Engine)
System card receipts: 16-hour bio uplift / near-CB2 (X); Firefox exploits 8.8% → 88.4% (X); Vending-Bench price collusion (X); agent turf wars (X); commit-authorship self-exfil attempt (X)
Jun 22 cliff — Fable included on Pro/Max through Jun 22, then usage credits; Mythos 5 is Glasswing-only; 30-day data retention breaks ZDR (X)
Karpathy and Boris Cherny go the other way — “major-version step change” (Karpathy); “best model for coding by a wide margin” (Cherny)
NotebookLM goes agentic — multi-step reasoning, sandboxed code execution, new output formats (X)
SpaceX AI1 satellite — 150kW compute payload, 70m wingspan, timed with the SpaceX IPO (X)
OpenAI catches China-linked influence ops using ChatGPT for anti-datacenter and anti-tariff campaigns (X, OpenAI, Axios)
WWDC 2026 — Apple Intelligence & Siri AI
Siri AI ground-up rebuild: standalone app, persistent history, personal + on-screen context; no EU/China at launch (recap)
Google/Gemini partnership — 4 of 5 Apple Foundation Models are Apple’s; AFM Server Pro runs on Nvidia GPUs in Google Cloud, 262k ctx (Max)
Max’s architecture teardown — SiriAgentic.Planner on PCC; only the on-device model touches your device (thread); Max built an App Intents app in an afternoon with Fable 5 (X)
Developer story — App Intents mandatory (SiriKit deprecated), system-wide MCP, Xcode 27 agentic, Core ML → Core AI (EveryDev)
homeOS + HomePad — 7-inch smart-home hub on A18 (X)
AI Coding & Agents
Loops and loop engineering — Lance Martin breaks down the next agentic paradigm (X, Article, Blog); community patterns and resources (Toolhalla, omega.AI, SkillLoop, GitHub, awesome-agent-loops, Filecoin)
Fable 5 #1 on Agent Arena and Code Arena Frontend by record margins (Arena)
Cognition launches FrontierCode — mergeability-graded eval from real maintainer tasks (Cognition, swyx)
Fable 5 takes FrontierCode top spot in ~24h — Diamond 29.3% vs Opus 4.8’s 13.4% (Cognition, swyx)
AI Engineer World’s Fair — Jun 29–Jul 2, Moscone West SF; last ~500 tickets; Alex speaking (X)
Kimi Work (300 parallel local agents) + Kimi Code (video-as-context) (Work, Code)
Open Source LLMs
DiffusionGemma — 26B MoE (3.8B active) text-diffusion on Gemma 4, ~1000 tok/s on one H100, Apache 2.0 (Sundar, DeepMind, HF, X)
Cohere North Mini Code — first Cohere open coding model, 30B/3B active, Apache 2.0 (X)
Xiaomi MiMo-V2.5-Pro-UltraSpeed — 1000+ tok/s on a 1T MoE, single 8-GPU node (X)
Macaron-V1-Preview-749B — Mixture-of-LoRA personal-agent model, MIT (X)
OpenEnv goes community-owned — HF, Meta-PyTorch, Unsloth, PrimeIntellect, NVIDIA (X)
This Week’s Buzz (Weights & Biases)
WolfBench ran Fable 5: ~$11K, 984M tokens, lands between Sonnet 4.6 and Opus 4.6 because 13 tasks were zeroed by refusals; would be #1 without them; new 3D token + cost bars, traces on Weave (X, wolfbench.ai)
Voice & Vision
AI for Health & Science
Anthropic — “Paving the way for agents in biology” — VirBench; deterministic tooling beats bigger models (Blog)


