



Hey, it’s Alex.
Next month is my 40th b-day, and honestly, my wish for that month is to have a week like this week. A very chill, almost nothing announced week.
This week started strong, with Sakana announcing FUGU (AI router) that can beat Fable (which we didn’t get back yet), and then... quiet. The most important thing in AI this week from a release standpoint is that GLM 5.2 from Z.AI is having it’s DeepSeek moment! Tons of new love for this model since last week! (+ we have the fastest GLM 5.2 deployment in the world with CW inference!)
The rest we can quickly count on one hand, Anthropic added Claude to Slack (which made folks hate Andrej Karpathy), OpenAI announced their own inference chip, GPT 5.6 will be delayed and the US Gov will decide who gets it (yes really) and Sean Grove joined us to talk about Linzumi and his vision for running 10,000 agent hours per person per day.
Oh and next week, is a special AI Engineer live stream from World’s Fair! Don’t miss it
Let’s get into it!
GLM 5.2 is having its DeepSeek moment (HF, CW Inference)

We covered GLM 5.2 last week, but this week was when the rest verdict came in! We’ve never seen a better MIT licenced AI model! GLM 5.2 is scoring top scores on agentic benchmarks (Arena.ai), Design benchmarks, Legal tasks and full on software engineering tasks.

The jump in generations from prevoius GLM is also massive and notable, as the lab is working on creating the next version of GLM (per the CEO’s reply to Elon on X).
Peter from Arena pulled up the Agent Arena numbers and they align with the vibe. GLM 5.2 sits above 5.1 but below Opus and Fable, which feels about right. Where it gets wild is Web Dev Arena: second place, right after Fable. Peter’s take was that GLM has really good defaults. If you just say “give me a webpage” it gives you something nice. GPT models, by contrast, start off looking bad and need more steering.
Last week, I asked my agents with GLM 5.2 to create a custom ThursdAI.news page for itself and it did a marvelous job! Look at that beautiful font, the castle it made... this is all just delignful.
We also played Hassan’s blind test on the show. It’s a website that @nutlope built that lets you try and guess which webpage was built by which model. Nisten nailed it immediately by spotting Opus’s circular buttons. Wolfram guessed right too. I got one wrong. The point isn’t that GLM beats Opus, it’s that you genuinely can’t always tell which one costs 22 cents and which one costs 3 cents.
Wolfram did flag that GLM is not good in German. First response already had mistakes. So if you’re building for a non-English market, keep that in mind. It’s a workhorse model, not a conversationalist. His approach: use GPT 5.5 for planning and discussion, GLM for the actual work, then GPT reviews.
This weeks Buzz is all about GLM 5.2!
First, we may have not been the fastest, but I’m glad to announce that we’re the fastest provider to host GLM 5.2 on OpenRouter (at least at the time of writing this)!
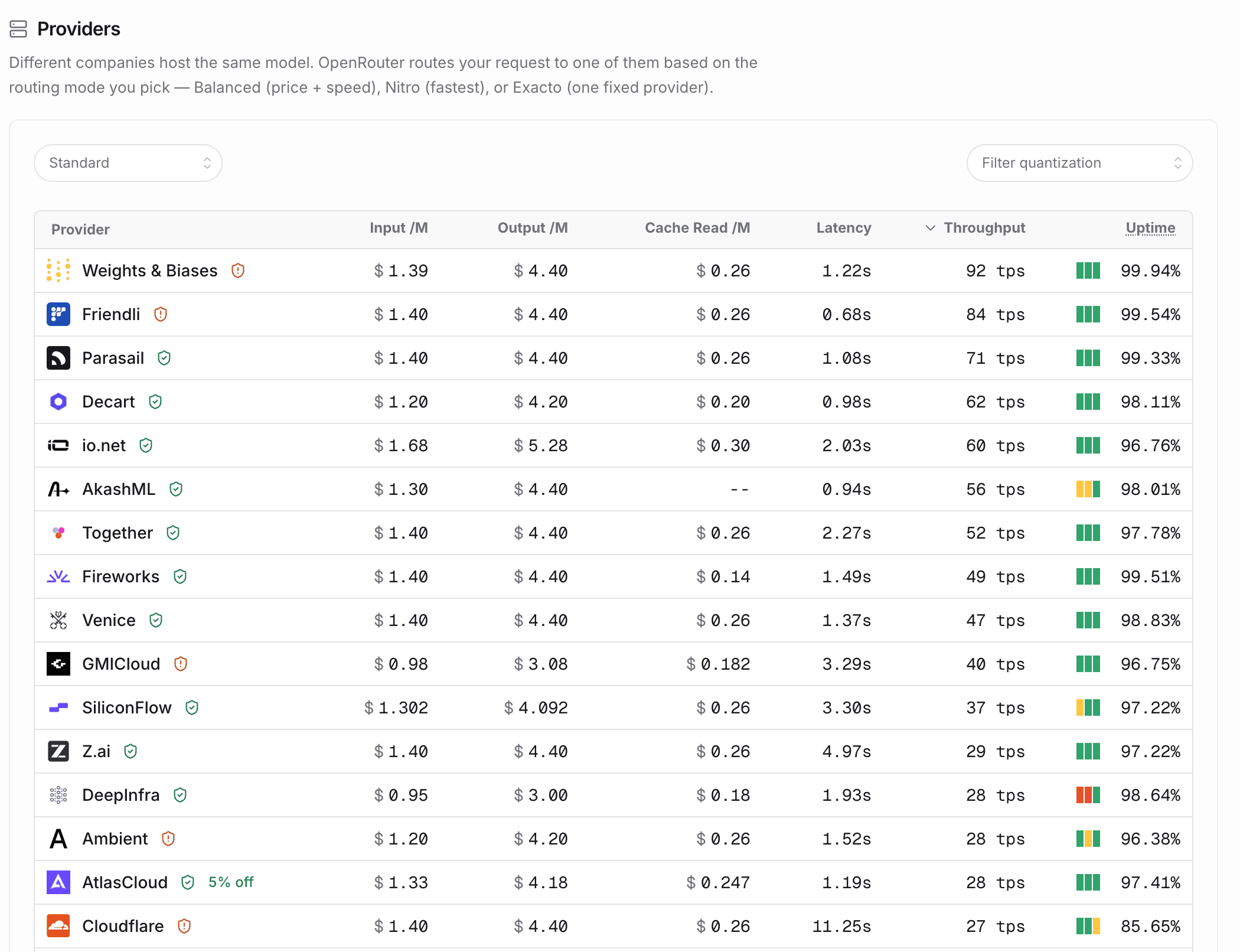
We’re also not to shabby on the Artificial Analysis checks, clocking at #4 among the providers they tested for speed, TTFT and cost
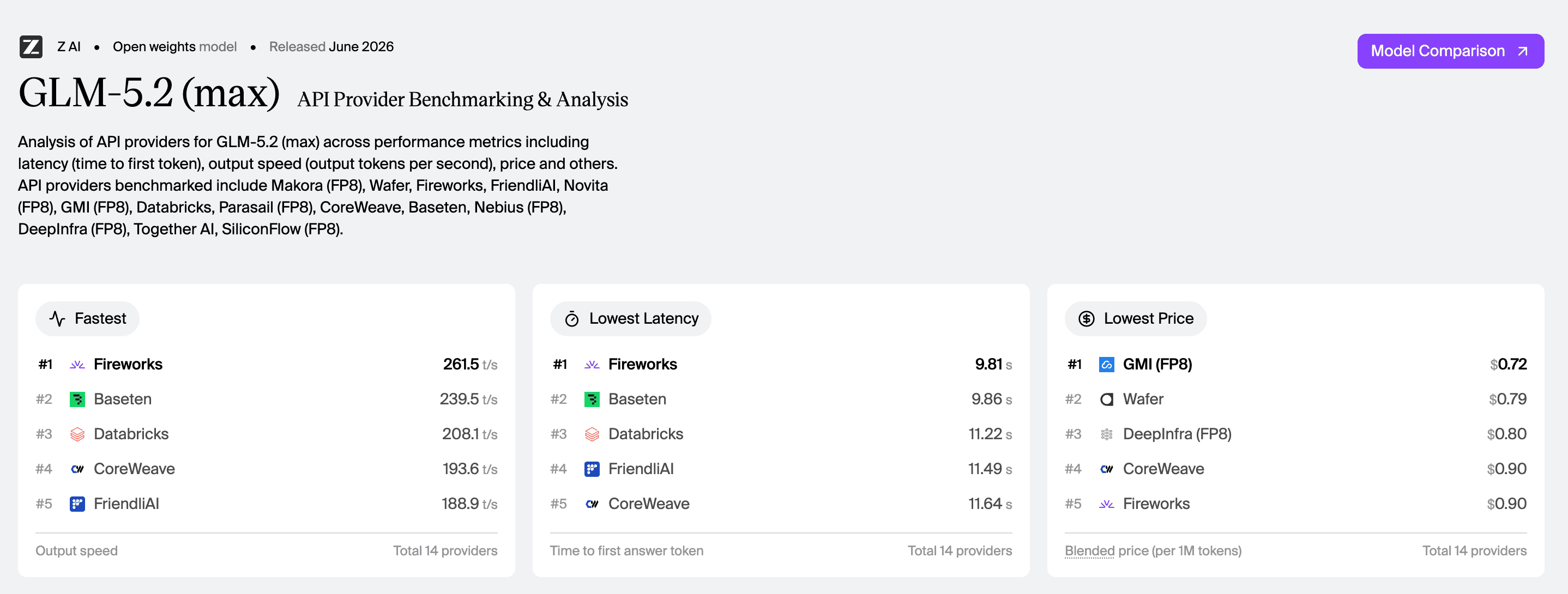
Also, Wolfram ran his WolfBench tests on GLM 5.2 and it’s the best open model he’s ever tested! In this new 3d view, wolfbench also shows the number of tokens it took for this test to run, and you can see that GLM 5.2 is fairly conservative with it’s thinking budgets!
Unsloth’s 1-bit GLM 5.2 runs on a Mac Studio (X, HF)
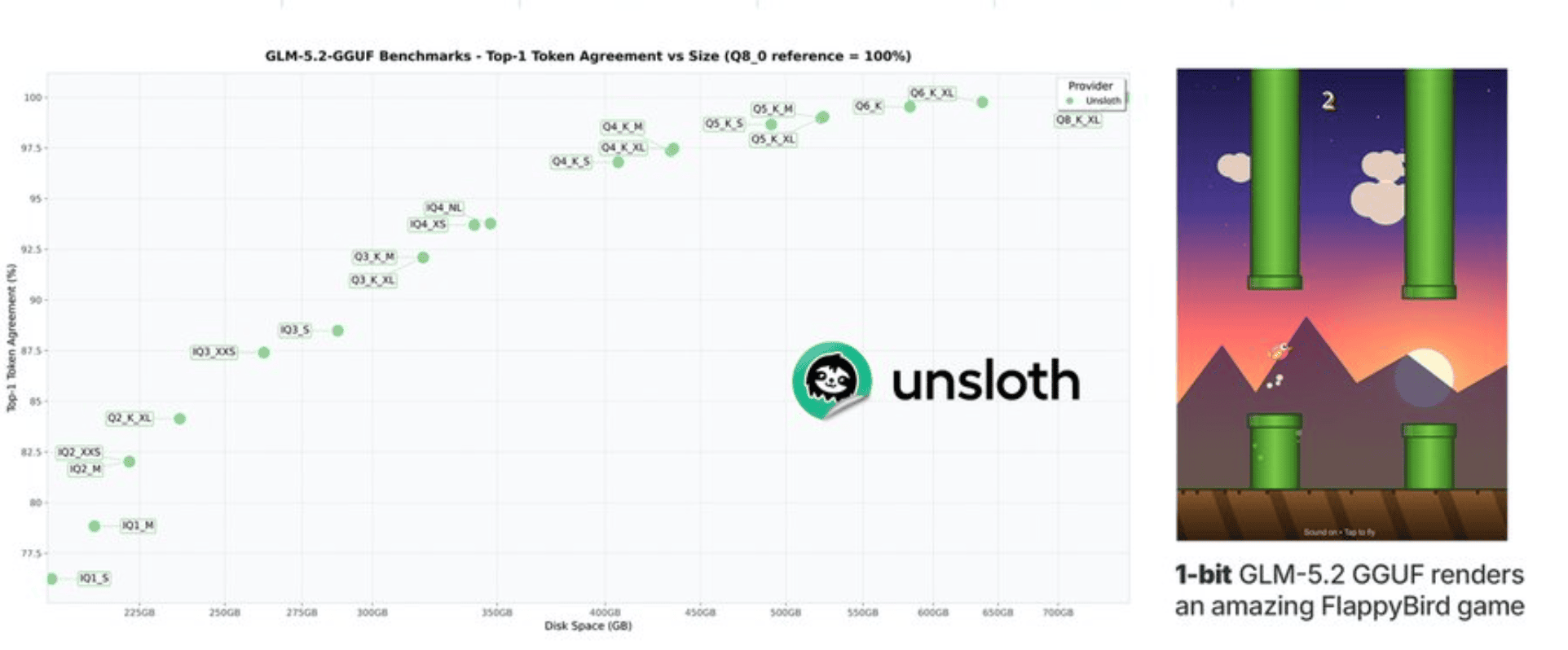
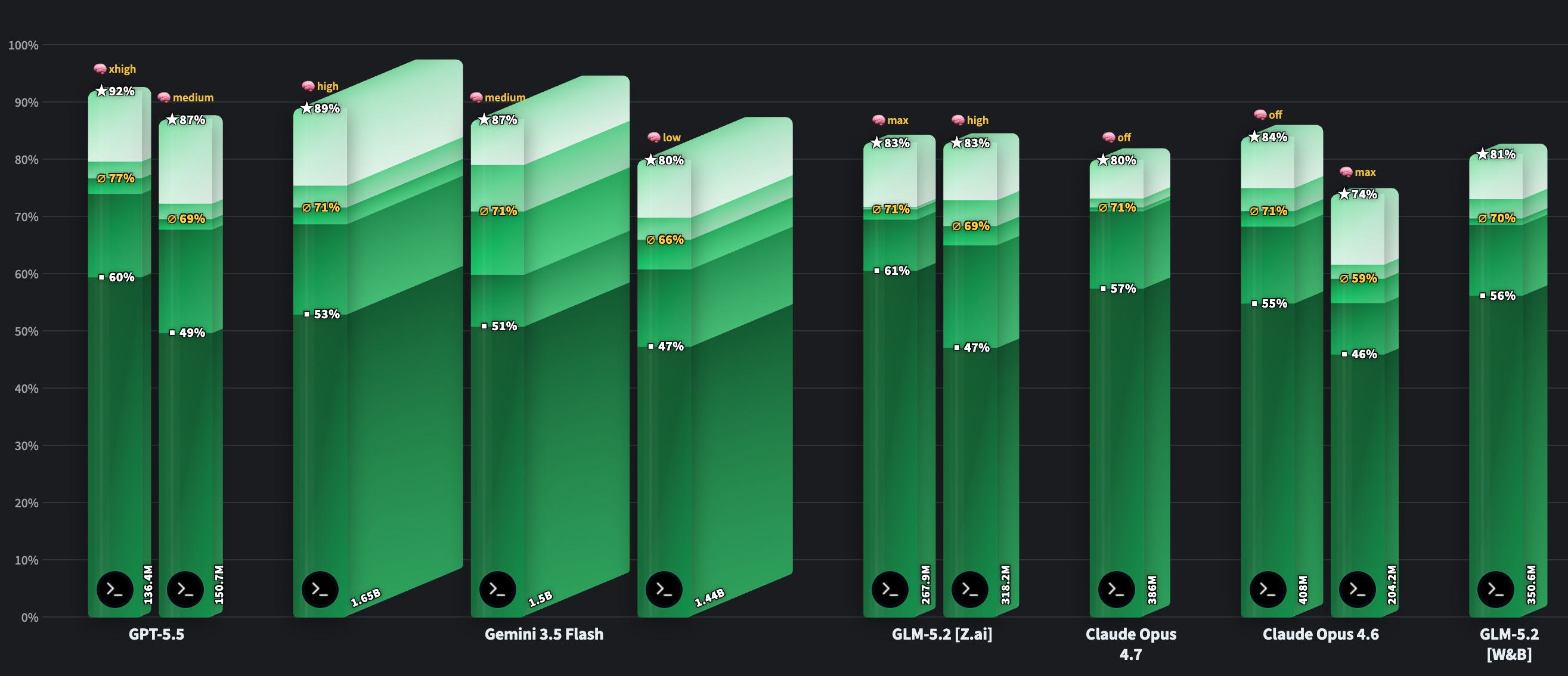
Shout out to Daniel Han and the Unsloth team, who took this 744B beast and quantized it down to a roughly 200GB GGUF that fits on a Mac Studio with 256GB of RAM. One bit still makes me laugh out loud. How does that even work. Nisten clarified it’s a mixed quant, a true 1-bit would be under 100GB, but still.
The wild part is the scores hold up. The 1-bit is within a point of GPT 5.5 on Frontier SWE, hits 62% on SWE-bench Pro, and 81% on Terminal-Bench. For a 1-bit quant that’s incredible!
AI’s second-order effects: Apple is raising prices

This one is AI news even though it doesn’t look like it. Apple just raised prices across the board, base versions up around 20%, citing memory shortages. Same reason your RAM and SSDs cost two to three times what they did a year ago.
We are so capacity constrained that memory is having its moment. Data center contracts are getting booked 18 months out, and here’s the twist Nisten flagged: even open models you can run at home increase demand, because now a business says “great, we’ll buy a rack of B200s and run it ourselves.” Sam Altman once said people saying “thank you” to ChatGPT costs them millions in generated “you’re welcome” replies. Multiply that by a billion users. Even Intel is flying right now because anyone who can make a chip is winning.
Is it worth it? I think yes. I love living in the era where Fable drops and we all get a taste of the future. But also I must admit this sucks and I hope that we’ll unlock performance gains with the extra power all this AI is bringing to the world. But ask me again once the new iPhone hits and it’s $300 more costly than the last one 😅
Baidu open-sources Unlimited-OCR (X, HF, Arxiv, GitHub)
It was a big OCR week. Baidu shipped a 3B model (only 500M active, it’s MoE) that parses 40+ pages in a single forward pass and hits 93.2% on OmniDocBench. The trick is constant KV cache during decoding, so no memory blowup and no progressive slowdown as the document gets longer. The intuition is lovely: it mimics how a human copies a book, glancing at the source and the last few characters you wrote, not re-reading everything. MIT licensed, weights on HF.
Nisten’s point here is the practical one: most small businesses don’t realize they can self-host something like this, point it at all their documents, and keep everything local. A lot of folks just throw it at Gemini instead, which works great, but the small dedicated models are now good and cheap enough to own.
Mistral OCR 4 (X, Announcement)
Mistral’s entry in OCR week adds bounding boxes, block classification, and per-region confidence scores. They ran a blind human eval across 600+ documents in 12+ languages and annotators preferred OCR 4 about 72% of the time. On the agentic ParseBench leaderboard it lands around fourth, just under LlamaParse and Reducto. Mistral is very enterprise and Europe focused, and it’s cheap, so for regulated, multilingual document work it’s a solid pick. As a sidenote, LlamaIndex’s own eval puts LlamaParse on top and Gemini around third, which says how good the general vision models have gotten at this too.
Liquid AI ships the world’s smallest agentic LLM (X, HF)

Breaking on the show: Liquid AI dropped LFM2.5 at 230 million parameters. That’s roughly ten MP3s. Smaller than a Create React App, smaller than your node_modules folder. They call it the world’s smallest agentic LLM, and it runs fast on any CPU from the last decade, on a Raspberry Pi 5, on a Snapdragon, they even stuck it on a Unitree G1 robot.
I love the use cases here. I already run Cotypist on my Mac for on-device autocomplete, which uses a 6GB Gemma 4B. Swap in something this size and you get the same thing way lighter, and I don’t have to send everything I type to OpenAI. Or, as Nisten put it, a tiny backup brain on your Raspberry Pi that turns your Hermes or OpenClaw back on when it dies. We still need to ship Nisten a smart toaster so we can finally run inference on a toaster.
Big CO LLMs + APIs
Sakana AI launches Fugu, seven AI raccoons in a trench coat beating Fable (X, Announcement)

This was Wolfram’s highlight of the week and I get why. Sakana AI, the Japanese lab co-founded by one of the Transformers authors and David Ha, didn’t ship a new frontier model. They shipped an orchestration system behind a single API. You call one endpoint, and behind the scenes Fugu routes your task to a pool of models, assigns roles like thinker, worker, and verifier, and combines the results.

The numbers here are wild: 95.5 on GPQA Diamond, 93.3 on LiveCodeBench, 73 on SWE-Bench Pro, matching or beating Opus 4.8, Gemini 3.1, and GPT 5.5 on ten of eleven benchmarks. The kicker is they only use publicly accessible models (Nisten says it’s Opus, Codex, and Gemini under the hood), explicitly no Fable, no Mythos. So they’re beating frontier results by coordinating models anyone can call. Someone called it the Moneyball of AI and that’s exactly right. It’s backed by two ICLR papers, TRINITY and The Conductor, and being from Japan with no export-control baggage is a very deliberate bit of positioning.
Peter added the grounding note from Arena, where they’ve trained a prompt router too: if you just always ask for “the best model,” you basically get Opus half the time, so why not just talk to Opus. The real value of routing is aggressive cost reduction, sending easy tasks to cheap models. The catch is that Fugu is agentic and burns tokens fast. Brad in the comments couldn’t get through a single prompt on the $20 plan.
OpenAI unveils Jalapeno, its first custom inference chip (X, Announcement)

OpenAI dropped something massive that is not a model. They built a chip. Jalapeno is a custom inference ASIC made with Broadcom, and they’re claiming blank slate to tape-out in nine months. Engineering samples are already running GPT-5.3-Codex-Spark in the lab, and Broadcom’s CEO is citing a roughly 50% reduction in inference cost versus typical AI GPUs. They’re planning gigawatt-scale deployments starting late 2026 with a next-gen chip taped out in 2028.
Nisten ran it past his electrical engineering and chip-fab group chat and got mixed reactions. No specs were released, and the nine-month claim probably means the design work started two-ish years ago and just got finalized and sent to tape-out now. It’s a lot of smaller chips rather than one giant Cerebras-style wafer. This is inference only, Nvidia keeps the training market, but every dollar OpenAI spends on Broadcom is a dollar it isn’t spending on Nvidia. They join Google’s TPUs, Meta, AWS Inferentia, Groq, SambaNova, Huawei Ascend, and Cerebras in the custom-silicon club. And behind every one of them sits TSMC, Intel, or Samsung, and behind all of those, ASML.
Anthropic launches Claude Tag, an AI teammate in your Slack (X)

When I first heard about Claude Tag I thought, you can already tag Codex in Slack, what’s the big deal. It’s different. Claude joins your Slack as a persistent, proactive team member, not a bot you ping. Flip on ambient mode and it follows up on stale threads and flags relevant stuff across channels on its own. There’s one Claude per channel, so the context is shared and any teammate can pick up where another left off. Anthropic says 65% of their product team’s shipped code now comes from their internal version of this.
The highlights and magnitude of this release are quite something. Anthroipc is changing the pricing structure for themselves. This is no longer API charges, this is per seat + tokens structure. This is also VERY very sticky as more and more of your company’s context is going to sit in Claude/Slack and will not be easily portable.
Additional thoughts on this, the more your company uses this, the more other folks are exposed to Claude across the company. This doesn’t require them to download apps or run code, it’s just like a new team mate joined your Slack channel. And apparently Claude’s context is limited to the channel boundaries + this allows Claude to get the same permissions (which is huge in enterprise). For Legal, Claude will see the documents in the channel, for Eng, it will push Pull Requests etc.
This is also what triggers a bunch of folks to caution companies from adopting this new way of using AI. Context lock in is real, and this is goign to be very hard to impossible to untangle once folks are pouring months and years of work into this.
Andrej Karpathy, who’s now in Anthropic, has shared a tweet on this, saying
Imo this is the 3rd major redesign of LLM UIUX. The first paradigm was that the LLM is a website you go to, the second was that it is an app you download to your computer. This third one is that it is a self-contained, persistent, asynchronous entity with org-wide tools and context, working alongside teams of humans
This is quite a huge statement, and folks gave him a lot of shit for this on X, I think very much underserved! Andrej is known for calling things early (like Vibe Coding) and this is just another one of those, deeply new paradigms that people didn’t yet experience outside of frontier labs!
I can’t wait to test this out and let you know if this is the future of not, meanwhile, Simon Smith on X is breaking down their experience with Claude Tag, check him out
Tools & Agentic Engineering
OpenAI ships Codex Record & Replay (X)
You do a workflow once on your Mac, filing an expense report, creating a Jira ticket, whatever, and Codex watches your clicks, browser actions, and window switches, then generates an editable SKILL.md it can replay. The key thing, and what separates it from old RPA, is that at replay time it re-interprets the live screen instead of matching pixel coordinates, so it adapts when the UI moves. Wolfram’s right that OpenAI is dead serious about Codex. First the paste-a-screenshot feature, now this. Instead of writing ten-paragraph prompts about your personal workflow quirks, you just show it once.
Aside launches as an AI browser that beats the frontier on agentic benchmarks (X, Announcement)

YC-backed AI browser, runs everything locally and encrypted, and you bring your own Claude or ChatGPT subscription. It’s claiming number one on three browser-agent benchmarks, beating Claude Fable, OpenAI, and the rest, with 99% on Online-Mind2Web. It looks a bit like Arc and Dia but it’s a browser and an agent in one, with a password manager built for agents so it can log into your accounts without exposing credentials to the model. I actually tried it, it’s pretty cool, and with Arc deprioritized there’s a real gap it’s stepping into. I gave it a list of all the speakers at AI engineer and asked it to make me a X list and add them all one by one!
It actually did this wonderfully, failing in the middle and recovering with great success without my intervention!
The Interview: Sean Grove and Linzumi
We closed with Sean Grove (@sgrove), ex-OpenAI post-training and alignment, now on his third company and third YC batch, launching Linzumi (linzumi.com, YC). Sean also has one of the most-viewed AI Engineer talks ever, north of 1.2 million views, on the model spec and the idea of specs as the real source code. His framing: we craft the properties we want in a spec, and the code is just the compiler output, so maybe there’s a higher-level spec that produces the same result. He even described a “Socratic compiler” that interviews you about ambiguity and contradictions in your own intent, the way a linter or type checker does for code.

That fed straight into my AI Engineer talk next week about whether we should still read code at all. Sean’s firmly on the don’t-read-the-output side. He describes the properties he wants, leans on property-based testing the way QuickCheck does, and reads the failures to adhere to those properties rather than the diffs. His goal for Linzumi is for every person to drive ten thousand agent hours per day, and you can’t get there if you’re making every micro-decision.
Linzumi itself is a Slack-like team chat where humans and a fleet of coding agents share the same threads, except the agents run on your own machine, so the code actually works when you merge it. Behind the scenes it continuously compiles a spec for your company from your chats, your standups, even your customer calls, then generates a DAG of work for the agents and lets them verify against that spec instead of pinging you for every decision. The mental model that stuck with me: if Sean’s system isn’t calling him, everything is great. The knowledge is one omnipresent source of truth, but permissioned and viewed through each person’s lens. For a limited time they’re bundling free GLM 5.2 access via Wafer AI, which fits the week perfectly.
My favorite moment: Sean said he’d have retired by now if not for this capability, because he wants to be present with his kids, and a Fable-level model is escape velocity for an AI-native company. I feel that. I also miss Fable, the same way I missed Sydney when Microsoft took it away. We’re all walking around with a little Fable withdrawal.
Wrap-up
That’s the chill week. No Fable comeback, nothing new from OpenAI, all the labs strangely waiting (possibly to see how the US government and Anthropic situation resolves before anyone moves). Meanwhile open source quietly closed the gap. GLM 5.2 is the headline, it’s incredible across benchmarks, really good at web design, and you can try it on CoreWeave inference today.
Next week is AI Engineer World’s Fair. Come find me and Wolfram in the bright yellow jackets. Wolfram’s WolfBench workshop is Monday, I’m talking Wednesday in the token-maxing track about the ZL continuum and whether AI engineers should still write code in 2026. And if you can’t make it, that’s the whole point of our coverage, we’ll bring you the vibe.
One last thing: thursdai.news now has a full timeline of every release we’ve ever covered plus an agentic search, so you can look up any model or any guest. It’s all built with agents, and I read exactly zero of the code that shipped it. See you next week, hopefully with some bigger model drops to talk about.
TL;DR and Show Notes - June 25, 2026
Hosts and Guests
Alex Volkov - AI Evangelist, Weights & Biases & CoreWeave (@altryne)
Co-hosts: @WolframRvnwlf, @nisten, @petergostev
Guest: Sean Grove, founder of Linzumi (@sgrove)
Open Source AI
GLM 5.2 - Z.ai’s 744B MoE open-weights model has its DeepSeek moment, tops open-model rankings, #2 on web dev arena behind Fable (HF, Z.ai)
Unsloth ships a 1-bit GGUF of GLM 5.2 that runs on a 256GB Mac Studio (X, HF)
Krea open-sources Krea 2, a 12B image model in Raw and Turbo versions (X, Turbo, Raw, Blog)
Baidu open-sources Unlimited-OCR, a 3B model that parses 40+ pages in one pass at 93% on OmniDocBench (X, HF, Arxiv, GitHub)
Liquid AI ships LFM2.5-230M, the world’s smallest agentic LLM (X)
Big CO LLMs + APIs
Sakana AI launches Fugu, a multi-agent orchestration system behind one API matching frontier models with only publicly accessible models (X, Announcement)
OpenAI unveils Jalapeno, its first custom inference chip built with Broadcom, blank slate to tape-out in 9 months (X, Announcement)
Anthropic launches Claude Tag, Claude as a persistent proactive teammate in Slack (X)
OpenAI expands Daybreak with a Codex Security plugin and GPT-5.5-Cyber hitting 85.6% on CyberGym (X, Blog)
OpenAI updates GPT-5.5 Instant, the model free users get
New Siri AI lands with the iOS 27.2 update
This Week’s Buzz (Weights & Biases & CoreWeave)
GLM 5.2 is live on CoreWeave Serverless Inference at $1.39 in / $4.40 out, near 200 tok/s (X, HF)
WolfBench ranks GLM 5.2 the third best model ever tested, and one of the cheapest (wolfbench.ai)
Tools & Agentic Engineering
OpenAI ships Codex Record & Replay: demonstrate a workflow once, get a reusable SKILL.md (X)
Aside launches as a local-first AI browser that tops three agentic browser benchmarks (X, Announcement)
Mistral OCR 4 drops with bounding boxes, block classification, and 72% human preference across 12+ languages (X, Announcement)
Vision & Video
Interview
Sean Grove launches Linzumi, a YC-backed team chat for orchestrating fleets of coding agents, bundling free GLM 5.2 via Wafer AI (linzumi.com, YC)

