



Hey folks, Alex here, let me catch you up!
I’ve had a feeling that this week is going to be crazy, as it started on the weekend MiniMax M3, then with Jensen announcing new RTX Spark, NVIDIA’s first PC chip packing 1 petaflop of local AI power into thin laptops.
A few days later at Microsoft BUILD, Satya & Mustafa from MAI dropped 7 AI models, completely pre-trained from scratch, including a new MAI-thinking-1, MAI-code and MAI-image 2.5 that started topping the image gen charts.
Then other image models started racing to the top of the Arena benchmarks, IdeoGram 4 hitting becoming SOTA open weights image-gen model, and Reve 2 beating Nano Banana just a few hours after that.
And then today, NVIDIA dropped Nemotron 3 Ultra, their latest 550B open weights model, data and training and Arena published a new agentic eval leaderboard and we got a new Gemma 4 12B.
I’ve had the great pleasure to host Chris (@llm_wizard) from Nvidia, Peter Gostev from Arena and Karan from Nous Research (who were featured prominently by Jensen!) all on the show.
Def don’t miss this one! Let’s get into the details.
Open Source LLMs
🔥 NVIDIA Nemotron 3 Ultra: The 550B Open Source Beast Built for Agents (X, Arxiv, Announcement)

This was the big one. Breaking news mid-show: NVIDIA drops Nemotron 3 Ultra, a 550 billion parameter sparse MoE model with 55 billion active parameters, built on a hybrid Mamba-Transformer architecture. Chris Alexiuk, AKA Joe Nemotron, joined us live from NVIDIA HQ in Santa Clara to walk us through it.
The headline number is 5.9x higher inference throughput compared to GLM-5.1 on decode-heavy workloads. Chris told us that this is a result of multiple things, their Hybrid Mamba-Transformer approach, the sparse attention, and that they optimized for decode-heavy workloads (the kinds of workloads agents do)

The architecture is fascinating. They’re mixing Mamba-2 state space layers with sparse attention, which means step 300 in an agent loop runs as fast as step 3. Pure transformers can’t do that because the attention cost keeps growing with context length. This kicks in big time at 64K+ sequence lengths, which is exactly where you end up in real agentic work when the model is having multi-turn conversations and people are dumping their entire codebase in.
P.S - We launched Nemotron 3 Ultra with 0-day support on CoreWeave Inference, it’s super fast and pretty cheap, give it a try here
They pretrained on 20 trillion tokens, extended context to 1 million tokens, and their post-training pipeline used multi-teacher on-policy distillation from over 10 specialized teacher models covering everything from SWE to terminal use to search to office work, which they are also going to open source soon!
One thing Chris emphasized that I really appreciate: NVIDIA doesn’t have their own harness. There’s no “NVIDIA Code.” Which means they actively resist the temptation to harness-max, to optimize for just one harness and look good on a specific leaderboard. Ultra should be a solid drop-in for whatever harness you’re used to, and that generality is worth a lot. It’s not the best thinker, but it is the highest score US based open weights model, so again, a huge huge win for the US AI ecosystem!
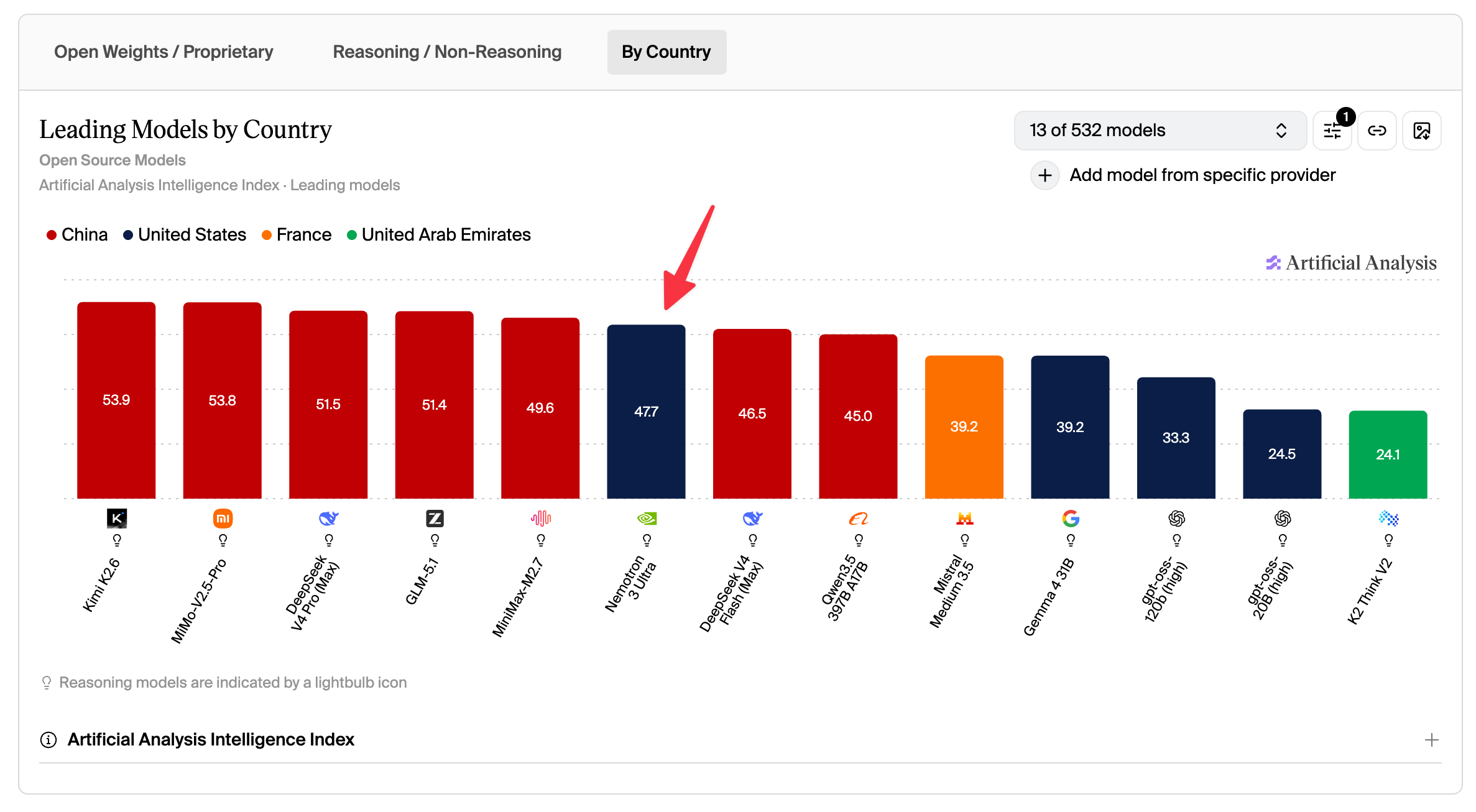
The Nemotron 3 Ultra release is open under the OpenMDW-1.1 license: base BF16, post-trained BF16, and NVFP4 quantized checkpoints, plus the GenRM, synthetic pre-training data for code, legal, and specialized domains, post-training datasets, RL environments via NeMo Gym, and training recipes in the Nemotron GitHub repo, which is absolutely bonkers! Kudos to team green for this awesome and very important release!
NVIDIA Nemotron 3.5 ASR: The Tiny Speed Demon (X, HF, Blog, Blog)
Oh, and NVIDIA wasn’t done. They also dropped Nemotron 3.5 ASR, a 600 million parameter open source multilingual streaming speech-to-text model covering 40 languages. It’s the fastest model Pipecat has ever tested, and the cost math is insane: roughly 5 cents an hour for enterprise deployment when typical API providers charge 10 cents to a dollar per hour. Our friend Kwindla from Daily and Pipecat put together a detailed writeup with benchmarks and cost analysis. Chris couldn’t stop praising NVIDIA’s speech team and honestly, I can’t either. Banger after banger.

Just a week after I told you about Cartesia Ink-2, NVIDIA drops an open version that’s pareto optimal, can run fully on-device and is blazing fast at transcription!?
Other notable open source announcements that would have made full headlines on any other week:
MiniMax announces M3, a natively multimodal, 1M, coding and agentic frontier model (X)
This one is very interesting, but not yet available as Open Weights so we haven’t tested it fully, we’re going to do it next week when the drop the tech report and the weightsGoogle drops Gemma 4 12B - encoder-free multimodal model that runs on your laptop with 16GB VRAM under Apache 2 (X, HF)
Our friends from DeepMind keep the western open source momentum going with a new 12B size for Gemma (which crossed some 100M downloads on Hugging Face recently).JetBrains Mellum2, a 12B MoE model with only 2.5B active, trained from scratch by a team of 7 people (X, Blog, HF, CW Inference)
The great folks at JetBrains, the company behind the IntelliJ IDEs, dropped a new model called Mellum2 which they trained from scratch. Very interesting to see them pivot in the world where IDE’s are dying at the hands of LLMs.H Company drops Holo 3.1: blazing fast local computer-use agents from 0.8B to 35B, with massive mobile benchmark jumps (X, Blog)
NVIDIA’s RTX Spark and reinventing the PC - announcement at Computex 2026

While we’re on the topic of NVIDIA, they opened the week with a huge announcement, including Microsoft, Dell, Lenovo, and HP and a bunch of other partners in it.
They announced RTX Spark, their first ever PC chip, which is a full system on a chip (SoC) focused on running AI workloads for things like OpenClaw and Hermes!
Announcing this on the stage at Computex, Jensen Huang called it the “the most amazing chip the world has ever built”, being able to run every app that Microsoft has ever run.
This is a huge deal, specifically because of how agentic the world is becoming, these machines (thin laptops and a mac-mini alternative were announced) will be able to run 120 billion parameter models on-device, gaming at the level of RTX 5070, and AI agents 24/7. I’m getting excited and I’m not a windows user!
Hermes victory + Hermes Desktop and an interview with Karan from Nous Research
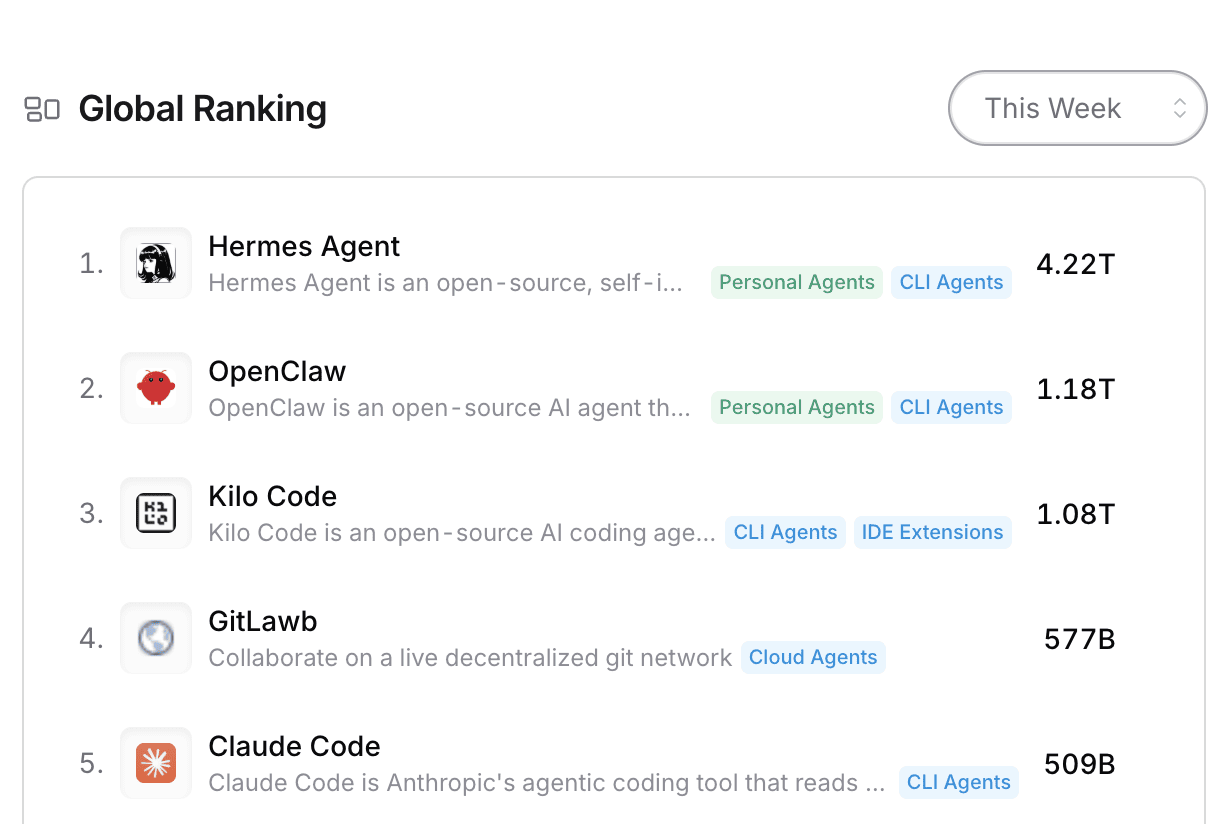
If you squint, you can see that by the little red OpenClaw, there’s another logo. That’s the Nous Girl logo of Nous Research, which was rebranded to be the logo of their Hermes Agent (an open source agentic harness that’s passed 181K starts on Github, and is the leader in global ranking on OpenRouter)
We’ve had the awesome pleasure of having Karan Malhotra (@karan4d), one of the co-founders of Nous Research on the show, and Karan broke down how Nous Research evolved from a research lab that created the long context innovations (YaRN) and finetuned models (Hermes used to be a series of models) to a full agentic company.
We also chatted with Karan about the new Hermes Desktop experience, which lets folks see the tools that are used, the code that’s being written by their agent, and how it feels to be featured by the worlds largest company on the global stage! Definitely check out the conversation with Karan.
Microsoft BUILD, new PC, becoming a frontier lab with MAI-thinking-1, MAI-code and MAI-image 2.5 (Blog)

From Jensen to Satya, the week was full of AI announcement that will impact the world. Microsoft’s annual Build conference happened just a few days after, with Jensen zooming in from Taipei to co-announce all these new PC models and chips.
Shortly after that, and after a lot of other announcements about less-exciting enterpris-y stuff, Satya handed the stage to Mustafa Suleyman (co-foudner of DeepMind and Inflection AI) and now CEO of Microsoft’s AI division (MAI) to announce all these new models!

A few of these (in previous versions) were already covered on the show, but the new LLMs are the most interesting! MAI-Thinking-1 is 1T total parameters with 35B active params, trained on 33.5T tokens (30T pre-training, 3.55T mid-training), without any distillation (which felt important for them to say given their proprietary access to OpenAI’s models). It’s not yet competitive with Opus and OpenAI’s flagship models, but they are claiming parity with Sonnet 4.5 and get 53% in Swe-bench Pro coding tasks!

Given that recently, OpenAI started offering their models on AWS, we’re now seeing a bit of a distancing between Microsoft and OpenAI, with Microsoft showing that can become a frontier lab on their own right, or well.. maybe a second tier frontier lab.
Of course, we shouldn’t forget that Microsoft kind of started the whole era of coding AI’s with CoPilot and completely lost to the Cursors and Windsurfs and Devins of the world given the huge head start they had with Github, so I’m really curious to see how strongly they will push this “second tier frontier lab” angle and if they have what it takes to compete with Google here (not to mention OpenAI and Anthropic)
And while the model wasn’t available for me to even test yet, MAI did drop an incredibly in depth 109 page technical report on it. Our friend of the pod Elie Bacouch (@eliebacouch) did a breakdown of the most interesting aspects of it, calling it a gold-mine for details about training models at this scale.
Image gen models race to the top of the Arena
This week was honestly chaotic for image gen. Three new SOTA models in basically 48 hours, I tried to use them all while preparing for the show, and here’s the comparison I ran:

Microsoft MAI-Image 2.5 (X, Try it)
One of the more surprising updates were about the MAI-image 2.5, it landed at #3 on text-to-image and #2 on image-to-image, surpassing Nano Banana Pro on the editing leaderboard. It comes in two flavors, MAI-Image-2.5 and a faster Flash variant, both running on H100s which means existing infra can serve it, and it’s already rolling out in OneDrive Photos for background cleanup and distractions removal.
That said, my honest take: I tried to generate a ThursdAI thumbnail with it and got “image failed” because I think the word “explosion” tripped its safety filter. I then tried to generate an “horse riding an astronaut on the moon” and got this, yep... this is .. not the best. IDK how and why they shot up so high on the leaderboards. But I guess we’ll see as more folks try these models.

Ideogram 4.0 - new SOTA open weights image gen 🔥 (X, Blog, HF)

The one I want to celebrate hardest is Ideogram 4.0, because they opened the weights! For the previous three Ideogram versions you could only use them on their website, and now they dropped the next one as a 9.3 billion parameter open weights model (non-commercial license, but still). This is now new #1 open weights text-to-image model, with only closed models from OpenAI and Google ahead of it on DesignArena. At 9.3B params, it beats much larger models like Qwen-Image (20B), FLUX.2 dev (32B), and even the 80B MoE HunyuanImage 3.0 on text rendering benchmarks.
The architecture is wild. Instead of CLIP or T5 they use Qwen3-VL-8B as the text encoder, extract hidden states from 13 intermediate layers, and they trained exclusively on structured JSON captions with bounding boxes. That’s why it’s so good at layout control, you can prompt it with precise bounding box positions and hex color palettes, and you can see the layout shaping the generation as it converges.
In my thumbnail test it nailed almost everything but had a small typo (it generated “Nemotron” once and then a weird “Nemo 1” duplicate in another area). Still, very impressive for a first open weights release.
Reve 2 jumps to #2 above Nano Banana Pro (X, Blog, Try it)

I’ve talked about Reve before, and Reve 2.0 just dropped at #2 on the Text-to-Image Arena with a 1280 score, a +125 Elo jump over their v1.5 in a single release. That’s basically unheard of on the arena leaderboard. The thing that blows my mind is they’re a 65 person lab training at only 2,000 GPU scale, competing with labs that have orders of magnitude more compute.
The core innovation is that they separated planning from rendering. Every image is first laid out as structured code (composition, relationships, style, labeled segments) before it gets rendered at native 4K (true 16 megapixels, not upscaled). Because the image is represented as code, every element is addressable and editable, so you can manipulate specific regions without regenerating the whole thing. This is also agent-native by design, LLMs can reason directly about the image structure.
I demoed their editing interface live on the show and it’s the tightest layout control I’ve seen in any image model. When I moved my head box to the left, it worked. When I moved the logo to the bottom, it worked. When I changed the word “news” to “imploded”, the surrounding text stayed pixel-identical. That precision is genuinely new.
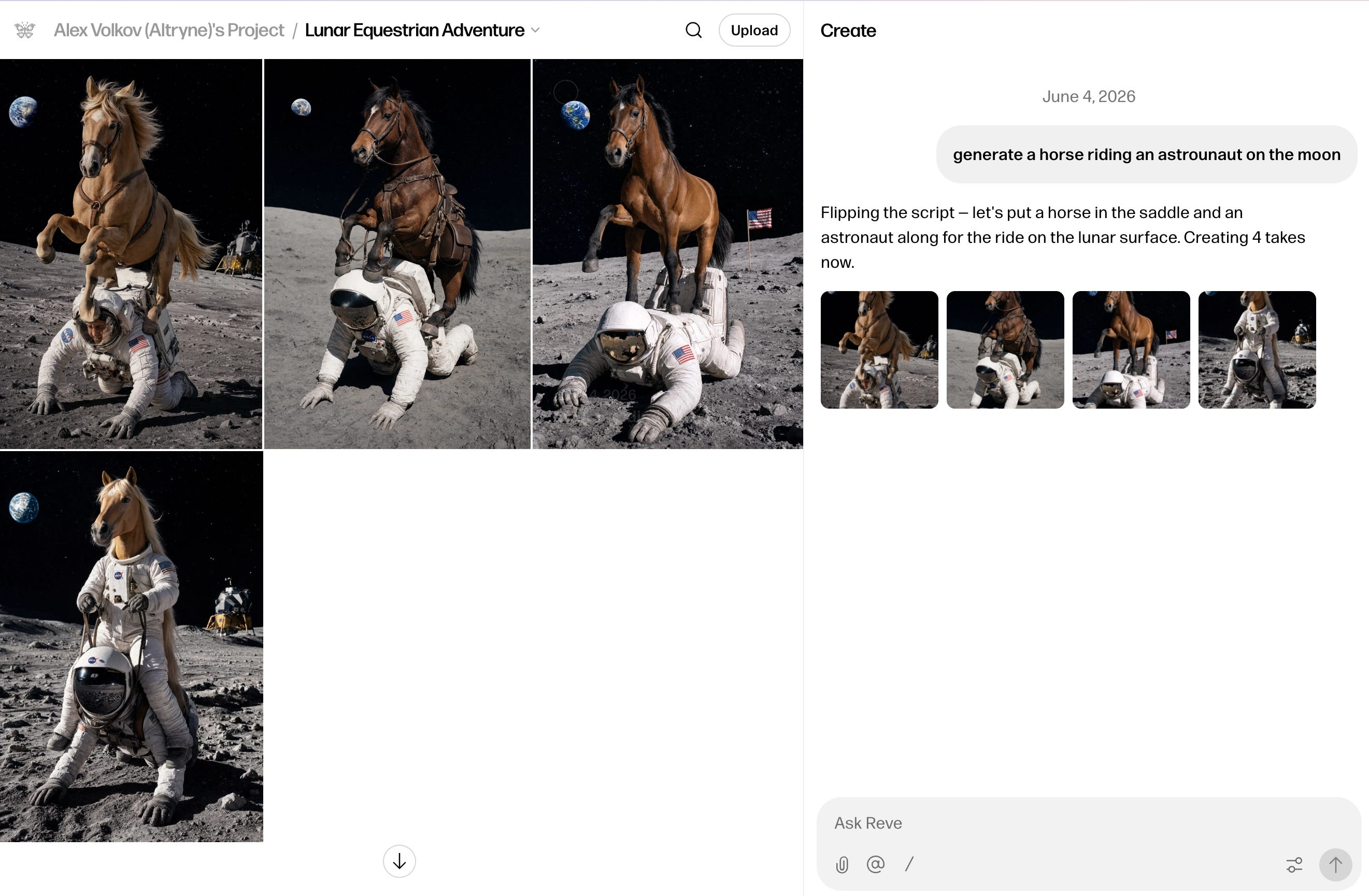
Honest tradeoff though, Peter Gostev flagged this on the show: they’re #2 on text-to-image but only around #9 on image editing. That matched my own experience nailing the thumbnail likeness, the layout work is amazing but the face came out a little googly-eyed and cartoonish, with one finger going somewhere fingers should not go.
For what it’s worth on my own thumbnail bake-off: Nano Banana Pro is still my pick for the absolute best instruction following (it nails my exact ThursdAI logo color every time), GPT Image 2 is still the highest fidelity but always comes out a little overcooked on the skin, Reve 2 is gorgeous on layout but the face needs work, and Ideogram 4 is the most exciting because it’s open. A lot of why I prefer Nano Banana is just that my prompts are very Nano Banana tuned by now.
Breaking news on the show: Agent Arena from LMArena
The breaking news of the day, while we were already on air, was Arena AI launching a brand new Agent Arena leaderboard. Nisten pasted the link in our group chat and three minutes later Peter Gostev himself jumped on the show to walk us through it. Got to love this format.

The motivation is something we’ve been talking about for a year. The original Arena was built for the chatbot era, where you send one prompt and vote A vs B. But we’ve all moved to agents, long multi-step tasks running for many minutes or hours, and that comparison no longer captures what matters. Agent Arena fixes this by giving models a real workspace with web search, file system and terminal tools, then measures millions of live sessions across five signals: task success, steerability, error recovery, user praise, and tool hallucination. The launch snapshot is built from 300,000 tasks, 2 million tool calls, and 40 million lines of agent-written code.
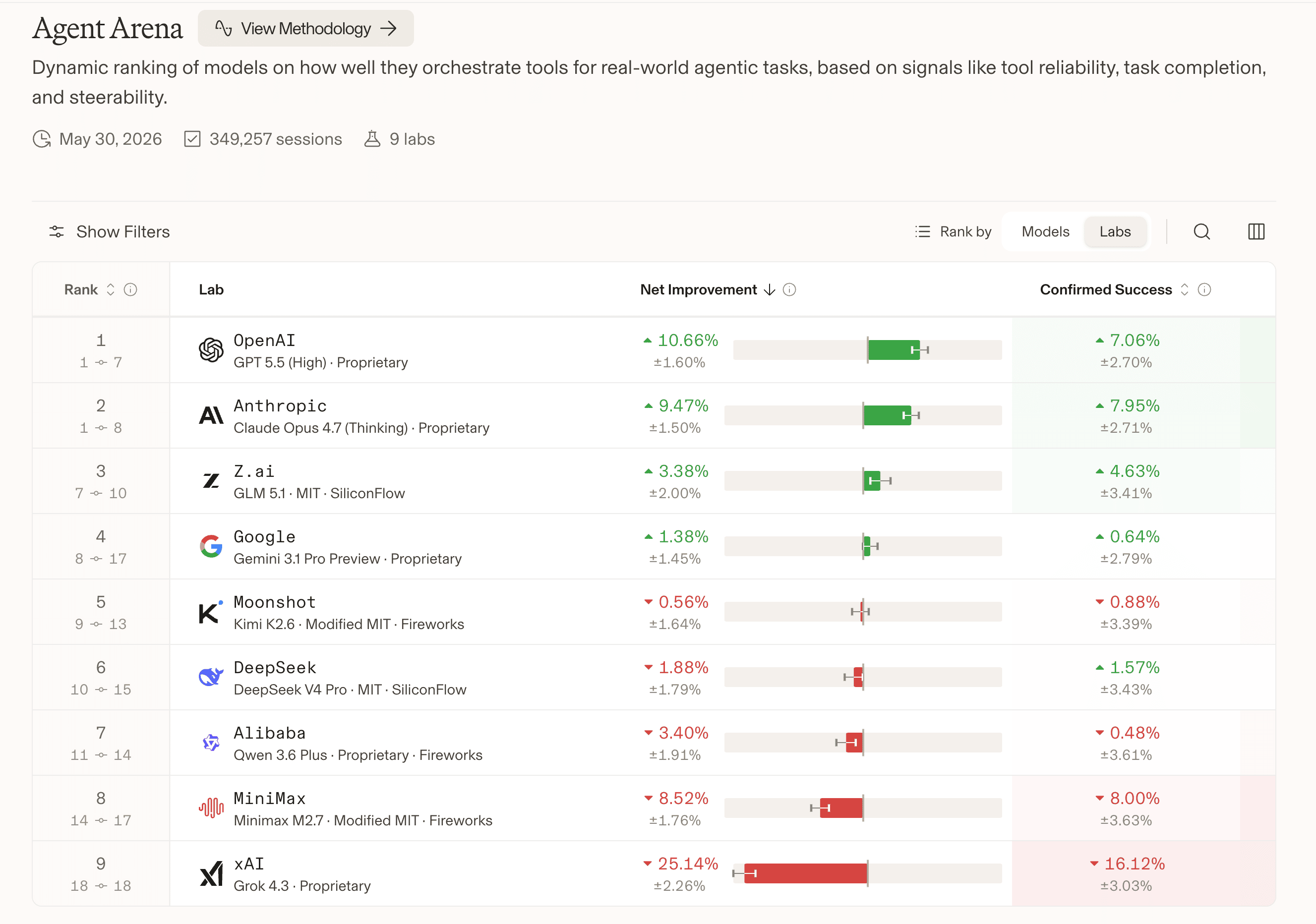
The results match the vibes on my feed perfectly. GPT-5.5 High is #1 by a comfortable margin, Claude Opus 4.7 right behind, and very interestingly ZAI’s GLM 5.1 (MIT licensed, fully open) lands at #3, above Google, Kimi and DeepSeek. The funniest moment of the show was when we’d been calling out Gemma 4 31B for being bad agentically purely based on vibes, and the brand new benchmark showed up 20 minutes later confirming exactly that. The other juicy signal is “bash recovery”, how quickly a model recovers when a command fails. GPT-5.5 leads at ~17%, and Grok 4.3 from xAI sits at -89%, which is so much worse it almost looks like a training bug.
I’m super into this. Give it a spin at arena.ai (@arena on X), they’re rolling new models in as labs send early access, so there’s a good chance you’ll spin up the next Mythos in their agent harness.
This week’s Buzz - WeaveHacks 4 + Nemotron on CW Inference + WolfBench 3D
A few things from our corner this week.
WeaveHacks 4 is this weekend in SF - not too late to join yet!
We’re hosting WeaveHacks 4 in San Francisco this weekend, and we still have a few spots left, so if you’re in town, please come join us at lu.ma/weavehacks. OpenAI is sponsoring us for the first time, Cursor is in too, we’ve got over $150K in credits to give out, food, and a great panel of judges I reached out to personally.
Nemotron 3 Ultra is live on CW Inference at full NVFP4

I said it above but it bears repeating, our inference team got Nemotron 3 Ultra live on day zero on CoreWeave Inference (via Weights & Biases) at full NVFP4 precision. Nisten plugged it straight into his medical anatomy harness (which was originally built for Kimi and Qwen) and it just worked, plug and play, agentically highlighting body parts and calling custom tools, at around 15 cents cached input. Try it at wandb.me/nemotron-ultra.
WolfBench gets a 3D bar update
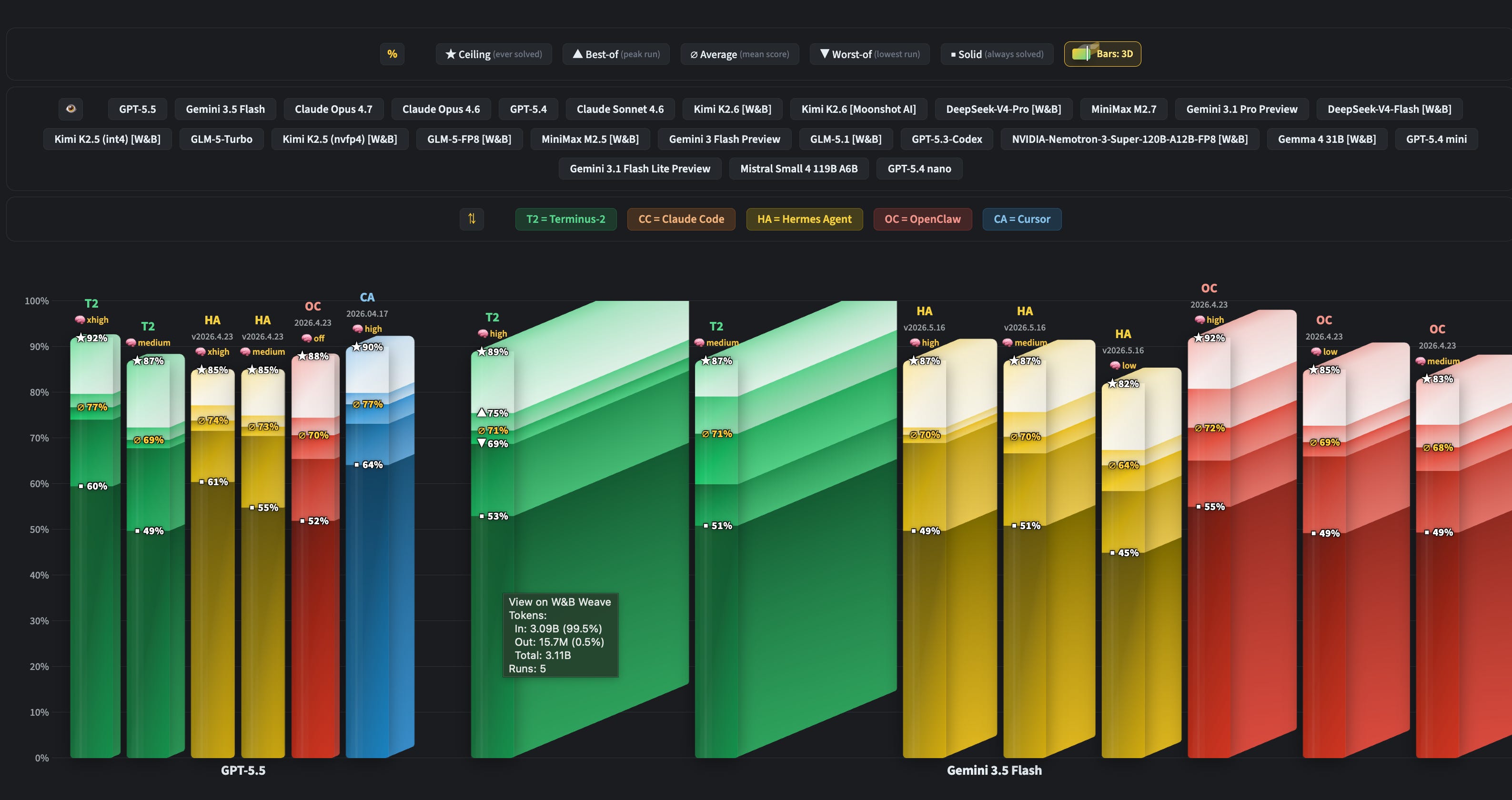
Wolfram shipped a quietly important feature on WolfBench: 3D bars where the depth of each bar represents how many tokens the model used to get its score. The 2D view shows Gemini 3.5 Flash sitting comfortably at #2 on the agentic scores, almost matching GPT-5.5. But flip on 3D mode and the picture is very different. Gemini Flash burned over 3 billion input tokens to get that score, where GPT-5.5 used a couple hundred to reach the same level. That’s the difference between “cheap fast model” and “actually cheap to run end to end”. Wolfram’s writing up the full analysis on the W&B blog next week. Check out the new 3D view on wolfbench.ai
AI in Society
Look, tons of other stuff happened this week as well, that honestly deserves its own newsletter, we are focused on models and agents, but it’s hard to ignore the bigger picture.
Senator Bernie Sanders, introduced a public bill called The American AI Sovereign Wealth Fund Act would have the government tax AI companies, take 50% of the stock, and put it under public control. Which I personally find ridiculous, but apparently caused Sam Altman to request a meeting with Bernie.
Meanwhile there’s no doubt that AI hate is growing, and that the public sentiment is very negative, as we can see on the issue of Datacenter water usage for example. Despite Satya Nadella’s claim that the latest Microsoft Datacenters are using a closed loop water system, that use less water than 1 restaurant (X), and that datacenters use less than 1% of total water usage in the US, a lot of politicians, and social media users are still pushing the narrative that datacenters are are a water-guzzling monster and need to be stopped.
Anthropic’s “When AI builds builds” report (X)
Anthropic released a report today called “When AI builds itself” with haunting graphic.
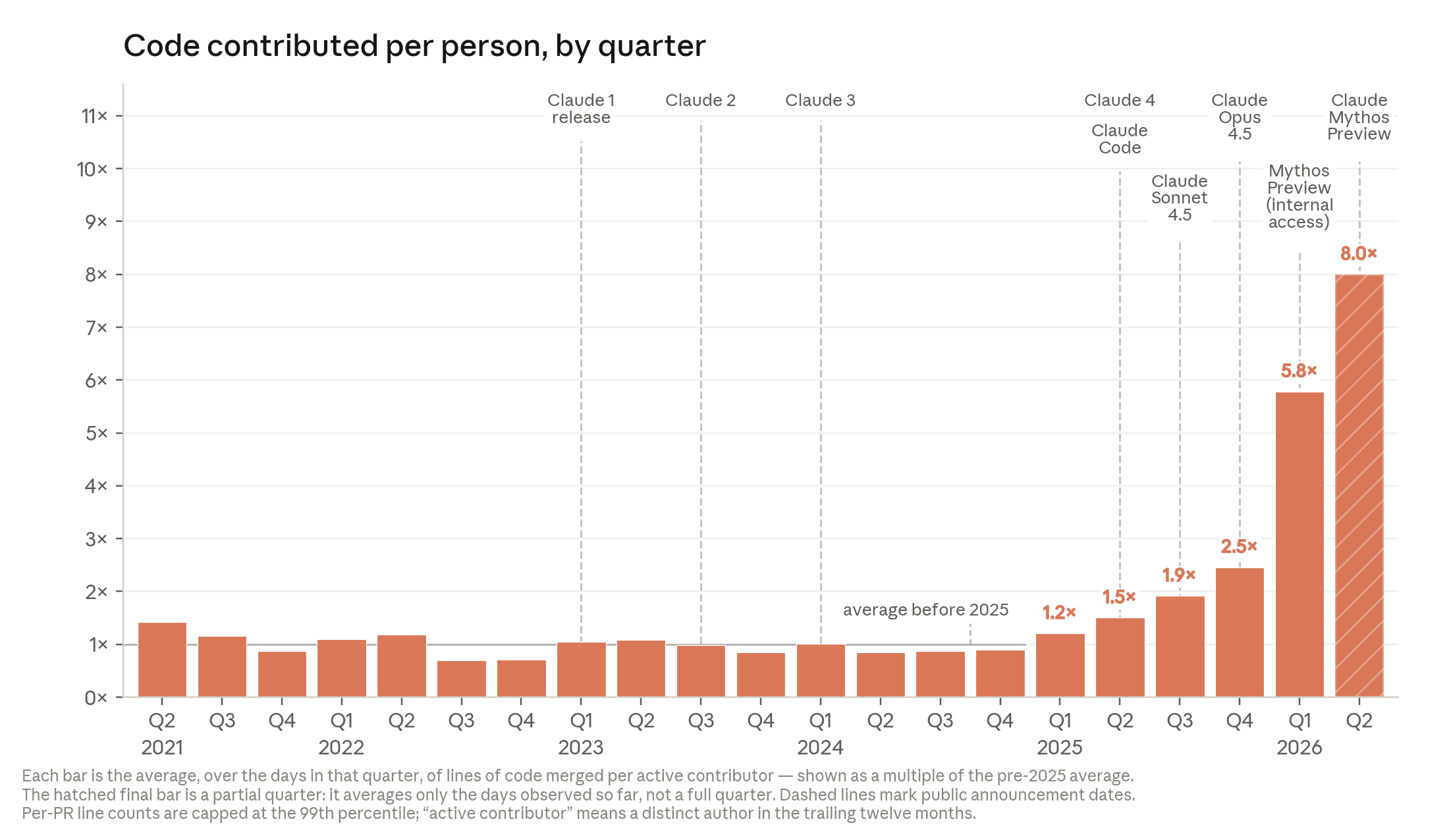
They have a bunch of previously unreleased data in there on how AI is shaping the work inside Anthropic and outline 3 potential futures:
1 - AI progress stalls, humans are able to catch up. Unlikely
2 - AI labs continue to see compounding efficiency gains - The most likely scenario, in which the nature of work changes, 100-person companies could do the work of 10,000- or 100,000-person organizations. The role of humans at companies like Anthropic would shift - Most Likely Scenario per Anthropc
3- AI systems themselves become capable of full recursive self-improvement, and begin building their successors - the most unclear scenario of whether these systems will be aligned to human values or not.
This is a fascinating and yes scary read, as Anthropic fully acknowledges that it would be dope if everyone chills for a second and stops building recursive self-improving AI’s that we aren’t sure could be aligned, but that it’s likely not going to happen, because it’ll just let other labs or in face other countries to catch up and change the frontier.
AI Leaders from top labs Urge Congress to Mandate Synthetic DNA Screening

Sam Altman of OpenAI, Dario Amodei of Anthropic, Demis Hassabis of Google DeepMind, and others signed an open letter on June 3, 2026, pushing for required screening of synthetic DNA and RNA orders to block known risky sequences. The letter, backed by Nobel winners, biotech CEOs, and security experts, notes AI’s ability to outpace human experts in biology, heightening biosecurity risks despite voluntary industry efforts since 2009. I think everyone agrees that this is a good idea, especially given the above Anthropic report. Very happy to see this happening.
Pheeeeew what a week.
This was a looong week, I wasn’t sure if we’d be able to cover everything, and it feels like we did a decent job! I know it’s exhausting, and I hope we on ThursdAI help you readers and listeners to stay on top of things without spending too many cycles.
If you enjoyed this newsletter or episode, please share it with a friend and consider subscribing to our Youtube Channel (thursdai.news/yt) to help more folks stay up to date.
TL;DR and Show Notes - June 4, 2026
Show Notes & Guests
Alex Volkov - AI Evangelist & Weights & Biases CoreWeave (@altryne)
Co Hosts - @WolframRvnwlf @yampeleg @ldjconfirmed
Guests: Chris Alexiuk / @llm_wizard from NVIDIA Nemotron
Karan Malhotra from Nous Research
Peter Gostev from Arena
Open Source LLMs
NVIDIA released Nemotron 3 Ultra, a 550B / 55B-active open-weight MoE built for long-running agents, with weights, data, recipes, GenRM, and training assets released (X, Tech Report, Announcement, HF).
NVIDIA also shipped Nemotron 3.5 ASR, a 600M open multilingual streaming STT model for voice agents (X, HF, Benchmark, Voice Agent Repo).
Google dropped Gemma 4 12B, an encoder-free multimodal model that runs locally under Apache 2.0 (X, HF).
MiniMax announced M3, a natively multimodal, 1M-context coding and agentic model with open weights coming soon (X, API, Code).
JetBrains released Mellum2, a 12B MoE with 2.5B active params trained from scratch by a small team (X, Blog, HF).
H Company launched Holo 3.1, local computer-use agents from 0.8B to 35B with new quantized checkpoints (X, Blog).
Big CO LLMs + APIs
NVIDIA announced RTX Spark, its new Arm + Blackwell PC platform for local AI agents and 120B-class local inference (coverage).
Microsoft AI launched seven new MAI models, including MAI-Thinking-1, MAI-Code-1-Flash, MAI-Image-2.5, MAI-Transcribe-1.5, and MAI-Voice-2 (Blog, Tech Report).
AI Art & Diffusion & 3D
MAI-Image-2.5 landed near the top of Arena image leaderboards, though hands-on tests were mixed (X, Try it).
Ideogram 4.0 became the top open-weight text-to-image model with strong typography and layout control (X, Blog, HF).
Reve 2.0 jumped to #2 on Text-to-Image Arena with native 4K, code-like layout control, and precise editing (X, Blog, Try it).
xAI released Grok Imagine Video 1.5 Preview for image-to-video with synced audio (xAI).
Tools & Agentic Engineering
Arena launched Agent Arena, a new leaderboard for real agent workflows instead of one-shot chatbot prompts (Arena).
Cognition rebranded Windsurf into Devin Desktop, a multi-agent command center with ACP support (X, Announcement).
Nous Research launched Hermes Desktop, bringing Hermes Agent into a native desktop app for Mac, Windows, and Linux (X, Site).
This Week’s Buzz
WeaveHacks 4 is this weekend in SF with OpenAI, Cursor, DeepMind, and more joining (lu.ma/weavehacks).
Nemotron 3 Ultra is live on CoreWeave Inference through W&B at full NVFP4 precision (Try it).
WolfBench added 3D token-depth bars, making model efficiency much easier to see (wolfbench.ai).
Voice & Audio
ElevenLabs launched Dubbing v2, an audio-to-audio dubbing model that preserves performance across 90+ languages (X, Dubbing).
Cartesia launched Ink-2, a fast streaming STT model built for voice agents (X, Ink, AA).
NVIDIA’s Nemotron 3.5 ASR looks like a major open-source voice-agent infrastructure drop (HF).
AI in Society
Bernie Sanders proposed the American AI Sovereign Wealth Fund Act, calling for public equity stakes in major AI companies (coverage).
Anthropic published When AI Builds Itself, laying out scenarios for AI-driven AI R&D and recursive self-improvement (Anthropic).
AI leaders urged Congress to mandate synthetic DNA/RNA screening and recordkeeping (WIRED).
Anthropic confidentially filed for an IPO, adding another frontier-lab public-market storyline to watch (Axios).

