




Wow, holy s**t, insane, overwhelming, incredible, the future is here!, "still not there", there are many more words to describe this past week. (TL;DR at the end of the blogpost)
I had a feeling it's going to be a big week, and the companies did NOT disappoint, so this is going to be a very big newsletter as well.
As you may have read last week, I was very lucky to be in San Francisco the weekend before Google IO, to co-host a hackathon with Meta LLama-3 team, and it was a blast, I will add my notes on that in This weeks Buzz section.
Then on Monday, we all got to watch the crazy announcements from OpenAI, namely a new flagship model called GPT-4o (we were right, it previously was im-also-a-good-gpt2-chatbot) that's twice faster, 50% cheaper (in English, significantly more so in other languages, more on that later) and is Omni (that's the o) which means it is end to end trained with voice, vision, text on inputs, and can generate text, voice and images on the output.
A true MMIO (multimodal on inputs and outputs, that's not the official term) is here and it has some very very surprising capabilities that blew us all away. Namely the ability to ask the model to "talk faster" or "more sarcasm in your voice" or "sing like a pirate", though, we didn't yet get that functionality with the GPT-4o model, it is absolutely and incredibly exciting. Oh and it's available to everyone for free!
That's GPT-4 level intelligence, for free for everyone, without having to log in!

What's also exciting was how immediate it was, apparently not only the model itself is faster (unclear if it's due to newer GPUs or distillation or some other crazy advancements or all of the above) but that training an end to end omnimodel reduces the latency to incredibly immediate conversation partner, one that you can interrupt, ask to recover from a mistake, and it can hold a conversation very very well.
So well, that indeed it seemed like, the Waifu future (digital girlfriends/wives) is very close to some folks who would want it, while we didn't get to try it (we got GPT-4o but not the new voice mode as Sam confirmed) OpenAI released a bunch of videos of their employees chatting with Omni (that's my nickname, use it if you'd like) and many online highlighted how thirsty / flirty it sounded. I downloaded all the videos for an X thread and I named one girlfriend.mp4, and well, just judge for yourself why:
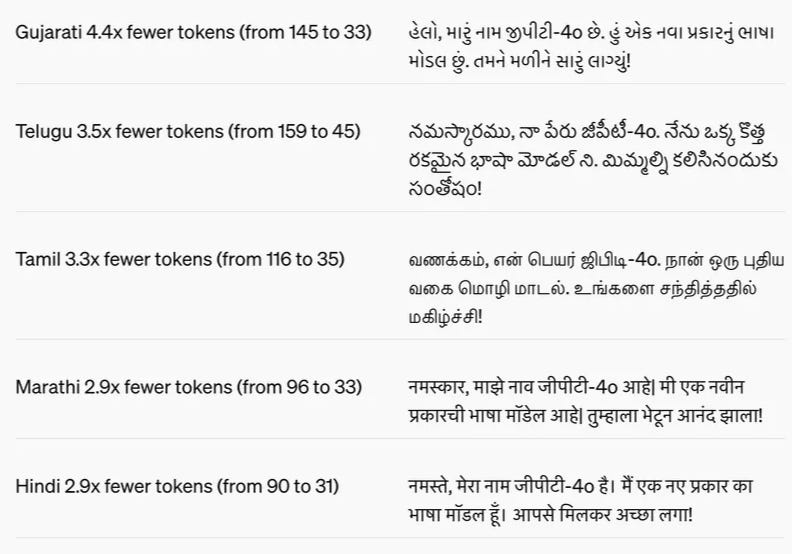
Ok, that's not all that OpenAI updated or shipped, they also updated the Tokenizer which is incredible news to folks all around, specifically, the rest of the world. The new tokenizer reduces the previous "foreign language tax" by a LOT, making the model way way cheaper for the rest of the world as well
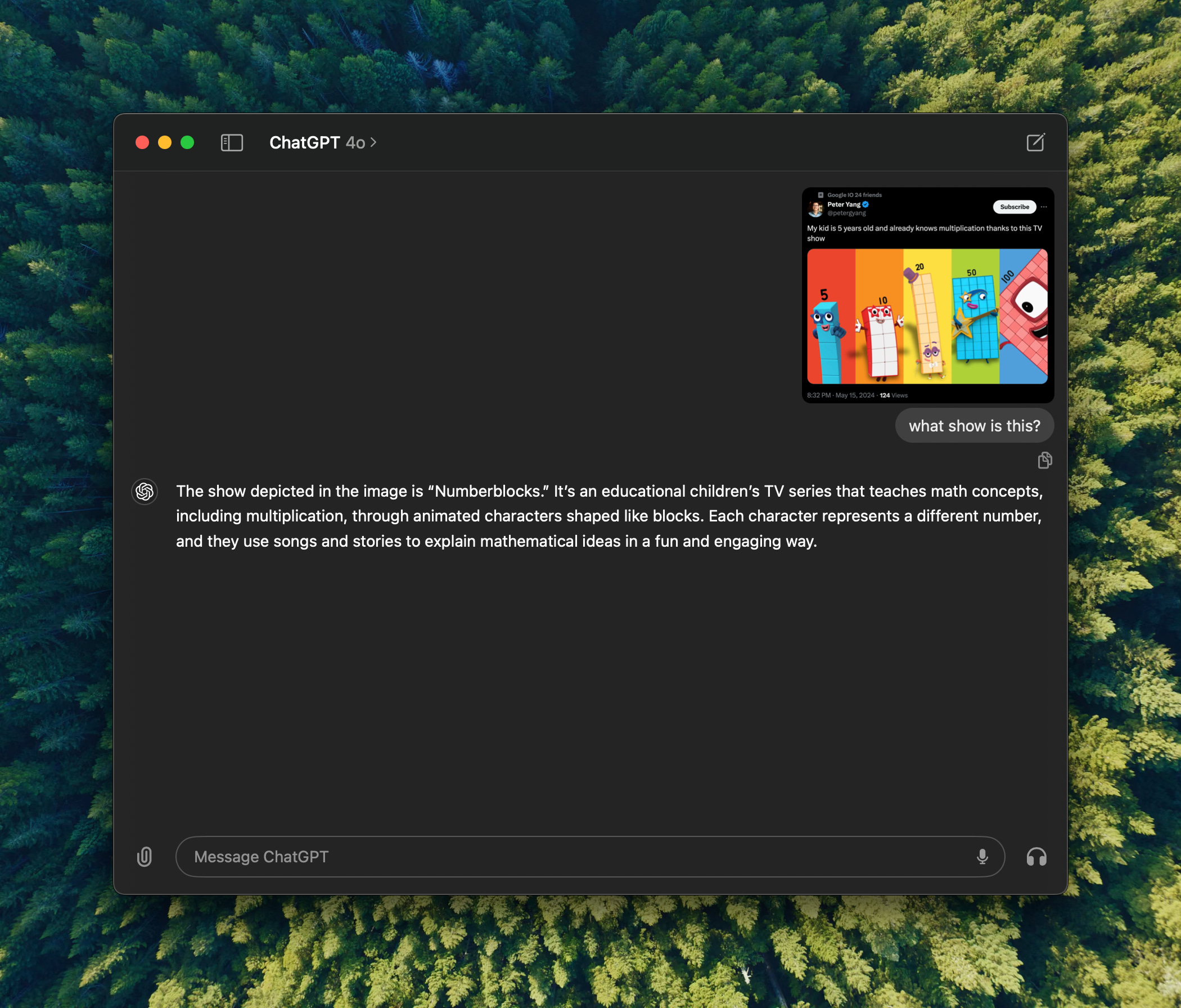
One last announcement from OpenAI was the desktop app experience, and this one, I actually got to use a bit, and it's incredible. MacOS only for now, this app comes with a launcher shortcut (kind of like RayCast) that let's you talk to ChatGPT right then and there, without opening a new tab, without additional interruptions, and it even can understand what you see on the screen, help you understand code, or jokes or look up information. Here's just one example I just had over at X. And sure, you could always do this with another tab, but the ability to do it without context switch is a huge win.
OpenAI had to do their demo 1 day before GoogleIO, but even during the excitement about GoogleIO, they had announced that Ilya is not only alive, but is also departing from OpenAI, which was followed by an announcement from Jan Leike (who co-headed the superailgnment team together with Ilya) that he left as well. This to me seemed like a well executed timing to give dampen the Google news a bit.
Google is BACK, backer than ever, Alex's Google IO recap

On Tuesday morning I showed up to Shoreline theater in Mountain View, together with creators/influencers delegation as we all watch the incredible firehouse of announcements that Google has prepared for us.
TL;DR - Google is adding Gemini and AI into all it's products across workspace (Gmail, Chat, Docs), into other cloud services like Photos, where you'll now be able to ask your photo library for specific moments. They introduced over 50 product updates and I don't think it makes sense to cover all of them here, so I'll focus on what we do best.
"Google with do the Googling for you"

Gemini 1.5 pro is now their flagship model (remember Ultra? where is that? 🤔) and has been extended to 2M tokens in the context window! Additionally, we got a new model called Gemini Flash, which is way faster and very cheap (up to 128K, then it becomes 2x more expensive)
Gemini Flash is multimodal as well and has 1M context window, making it an incredible deal if you have any types of videos to process for example.
Kind of hidden but important was a caching announcement, which IMO is a big deal, big enough it could post a serious risk to RAG based companies. Google has claimed they have a way to introduce caching of the LLM activation layers for most of your context, so a developer won't have to pay for repeatedly sending the same thing over and over again (which happens in most chat applications) and will significantly speed up work with larger context windows.
They also mentioned Gemini Nano, a on device Gemini, that's also multimodal, that can monitor calls in real time for example for older folks, and alert them about being scammed, and one of the cooler announcements was, Nano is going to be baked into the Chrome browser.
With Gemma's being upgraded, there's not a product at Google that Gemini is not going to get infused into, and while they counted 131 "AI" mentions during the keynote, I'm pretty sure Gemini was mentioned way more!
Project Astra - A universal AI agent helpful in everyday life

After a few of the announcements from Sundar, (newly knighted) Sir Demis Hassabis came out and talked about DeepMind research, AlphaFold 3 and then turned to project Astra.
This demo was really cool and kind of similar to the GPT-4o conversation, but also different. I'll let you just watch it yourself:
TK: project astra demo
And this is no fake, they actually had booths with Project Astra test stations and I got to chat with it (I came back 3 times) and had a personal demo from Josh Woodward (VP of Labs) and it works, and works fast! It sometimes disconnects and sometimes there are misunderstandings, like when multiple folks are speaking, but overall it's very very impressive.
If you remember the infamous video with the rubber ducky that was edited by Google and caused a major uproar when we found out? It's basically that, on steroids, and real and quite quite fast.
Astra has a decent short term memory, so if you ask it where something was, it will remember, and Google cleverly used that trick to also show that they are working on augmented reality glasses with Astra built in, which would make amazing sense.

Open Source LLMs
Google open sourced PaliGemma VLM

Giving us something in the open source department, adding to previous models like RecurrentGemma, Google has uploaded a whopping 116 different checkpoints of a new VLM called PaliGemma to the hub, which is a State of the Art vision model at 3B.
It's optimized for finetuning for different workloads such as Visual Q&A, Image and short video captioning and even segmentation!
They also mentioned that Gemma 2 is coming next month, will be a 27B parameter model that's optimized to run on a single TPU/GPU.
Nous Research Hermes 2 Θ (Theta) - their first Merge!
Collaborating with Charles Goddard from Arcee (the creators of MergeKit), Teknium and friends merged the recently trained Hermes 2 Pro with Llama 3 instruct to get a model that's well performant on all the tasks that LLama-3 is good at, while maintaining capabilities of Hermes (function calling, Json mode)

Yi releases 1.5 with apache 2 license
The folks at 01.ai release Yi 1.5, with 6B, 9B and 34B (base and chat finetunes)

Showing decent benchmarks on Math and Chinese, 34B beats LLama on some of these tasks while being 2x smaller, which is very impressive
This weeks Buzz - LLama3 hackathon with Meta
Before all the craziness that was announced this week, I participated and judged the first ever Llama-3 hackathon. It was quite incredible, with over 350 hackers participating, Groq, Lambda, Meta, Ollama and others sponsoring and giving talks and workshops it was an incredible 24 hours at Shak 15 in SF (where Cerebral Valley hosts their hackathons)

Winning hacks were really innovative, ranging from completely open source smart glasses for under 20$, to a LLM debate platform with an LLM judge on any moral issue, and one project that was able to jailbreak llama by doing some advanced LLM arithmetic. Kudos to the teams for winning, and it was amazing to see how many of them adopted Weave as their observability framework as it was really easy to integrate.
Oh and I got to co-judge with the 🐐 of HuggingFace

This is all the notes for this week, even though there was a LOT lot more, check out the TL;DR and see you here next week, which I'll be recording from Seattle, where I'll be participating in the Microsoft BUILD event, so we'll see Microsoft's answer to Google IO as well. If you're coming to BUILD, come by our booth and give me a high five!
TL;DR of all topics covered:
OpenAI Announcements
GPT-4o
Voice mode
Desktop App
Google IO recap:
Google Gemini
Gemini 1.5 Pro: Available globally to developers with a 2-million-token context window, enabling it to handle larger and more complex tasks.
Gemini 1.5 Flash: A faster and less expensive version of Gemini, optimized for tasks requiring low latency.
Gemini Nano with Multimodality: An on-device model that processes various inputs like text, photos, audio, web content, and social videos.
Project Astra: An AI agent capable of understanding and responding to live video and audio in real-time.
Google Search
AI Overviews in Search Results: Provides quick summaries and relevant information for complex search queries.
Video Search with AI: Allows users to search by recording a video, with Google's AI processing it to pull up relevant answers.
Google Workspace
Gemini-powered features in Gmail, Docs, Sheets, and Meet: Including summarizing conversations, providing meeting highlights, and processing data requests.
"Chip": An AI teammate in Google Chat that assists with various tasks by accessing information across Google services.
Google Photos
"Ask Photos": Allows users to search for specific items in photos using natural language queries, powered by Gemini.
Video Generation
Veo Generative Video: Creates 1080p videos from text prompts, offering cinematic effects and editing capabilities.
Other Notable AI Announcements
NotebookLM: An AI tool to organize and interact with various types of information (documents, PDFs, notes, etc.), allowing users to ask questions about the combined information.
Video Overviews (Prototyping): A feature within NotebookLM that generates audio summaries from uploaded documents.
Code VR: A generative video AI model capable of creating high-quality videos from various prompts.
AI Agents: A demonstration showcasing how AI agents could automate tasks across different software and systems.
Generative Music: Advancements in AI music generation were implied but not detailed.
Open Source LLMs
This weeks Buzz (What I learned with WandB this week)
Llama3 hackathon with Meta, Cerebral Valley, HuggingFace and Weights & Biases
Vision & Video
Google announces VEO - High quality cinematic generative video generation (X)
AI Art & Diffusion & 3D
Google announces Imagen3 - their latest Gen AI art model (Blog)
Tools
Cursor trained a model that does 1000tokens/s and editing 😮 (X)


