



Hey folks 👋 Alex here, dressed as 🎅 for our pre X-mas episode!
We’re wrapping up 2025, and the AI labs decided they absolutely could NOT let the year end quietly. This week was an absolute banger—we had Gemini 3 Flash dropping with frontier intelligence at flash prices, OpenAI firing off GPT 5.2 Codex as breaking news DURING our show, ChatGPT Images 1.5, Nvidia going all-in on open source with Nemotron 3 Nano, and the voice AI space heating up with Grok Voice and Chatterbox Turbo. Oh, and Google dropped FunctionGemma for all your toaster-to-fridge communication needs (yes, really).
Today’s show was over three and a half hours long because we tried to cover both this week AND the entire year of 2025 (that yearly recap is coming next week—it’s a banger, we went month by month and you’ll really feel the acceleration). For now, let’s dive into just the insanity that was THIS week.
Big Companies LLM updates
Google’s Gemini 3 Flash: The High-Speed Intelligence King

If we had to title 2025, as Ryan Carson mentioned on the show, it might just be “The Year of Google’s Comeback.” Remember at the start of the year when we were asking “Where is Google?” Well, they are here. Everywhere.
This week they launched Gemini 3 Flash, and it is rightfully turning heads. This is a frontier-class model—meaning it boasts Pro-level intelligence—but it runs at Flash-level speeds and, most importantly, Flash-level pricing. We are talking $0.50 per 1 million input tokens. That is not a typo. The price-to-intelligence ratio here is simply off the charts.
I’ve been using Gemini 2.5 Flash in production for a while because it was good enough, but Gemini 3 Flash is a different beast. It scores 71 on the Artificial Analysis Intelligence Index (a 13-point jump from the previous Flash), and it achieves 78% on SWE-bench Verified. That actually beats the bigger Gemini 3 Pro on some agentic coding tasks!

What impressed me most, and something Kwindla pointed out, is the tool calling. Previous Gemini models sometimes struggled with complex tool use compared to OpenAI, but Gemini 3 Flash can handle up to 100 simultaneous function calls. It’s fast, it’s smart, and it’s integrated immediately across the entire Google stack—Workspace, Android, Chrome. Google isn’t just releasing models anymore; they are deploying them instantly to billions of users.
For anyone building agents, this combination of speed, low latency, and 1 million context window (at this price!) makes it the new default workhorse.
Google’s FunctionGemma Open Source release
We also got a smaller, quirkier release from Google: FunctionGemma. This is a tiny 270M parameter model. Yes, millions, not billions.
It’s purpose-built for function calling on edge devices. It requires only 500MB of RAM, meaning it can run on your phone, in your browser, or even on a Raspberry Pi. As Nisten joked on the show, this is finally the model that lets your toaster talk to your fridge.
Is it going to write a novel? No. But after fine-tuning, it jumped from 58% to 85% accuracy on mobile action tasks. This represents a future where privacy-first agents live entirely on your device, handling your calendar and apps without ever pinging a cloud server.
OpenAI Image 1.5, GPT 5.2 Codex and ChatGPT Appstore
OpenAI had a busy week, starting with the release of GPT Image 1.5. It’s available now in ChatGPT and the API. The headline here is speed and control—it’s 4x faster than the previous model and 20% cheaper. It also tops the LMSYS Image Arena leaderboards.

However, I have to give a balanced take here. We’ve been spoiled recently by Google’s “Nano Banana Pro” image generation (which powers Gemini). When we looked at side-by-side comparisons, especially with typography and infographic generation, Gemini often looked sharper and more coherent. This is what we call “hedonistic adaptation”—GPT Image 1.5 is great, but the bar has moved so fast that it doesn’t feel like the quantum leap DALL-E 3 was back in the day. Still, for production workflows where you need to edit specific parts of an image without ruining the rest, this is a massive upgrade.
🚨 BREAKING: GPT 5.2 Codex

Just as we were nearing the end of the show, OpenAI decided to drop some breaking news: GPT 5.2 Codex.
This is a specialized model optimized specifically for agentic coding, terminal workflows, and cybersecurity. We quickly pulled up the benchmarks live, and they look significant. It hits 56.4% on SWE-Bench Pro and a massive 64% on Terminal-Bench 2.0.
It supports up to 400k token inputs with native context compaction, meaning it’s designed for those long, complex coding sessions where you’re debugging an entire repository. The coolest (and scariest?) stat: a security researcher used this model to find three previously unknown vulnerabilities in React in just one week.
OpenAI is positioning this for “professional software engineering,” and the benchmarks suggest a 30% improvement in token efficiency over the standard GPT 5.2. We are definitely going to be putting this through its paces in our own evaluations soon.
ChatGPT ... the AppStore!
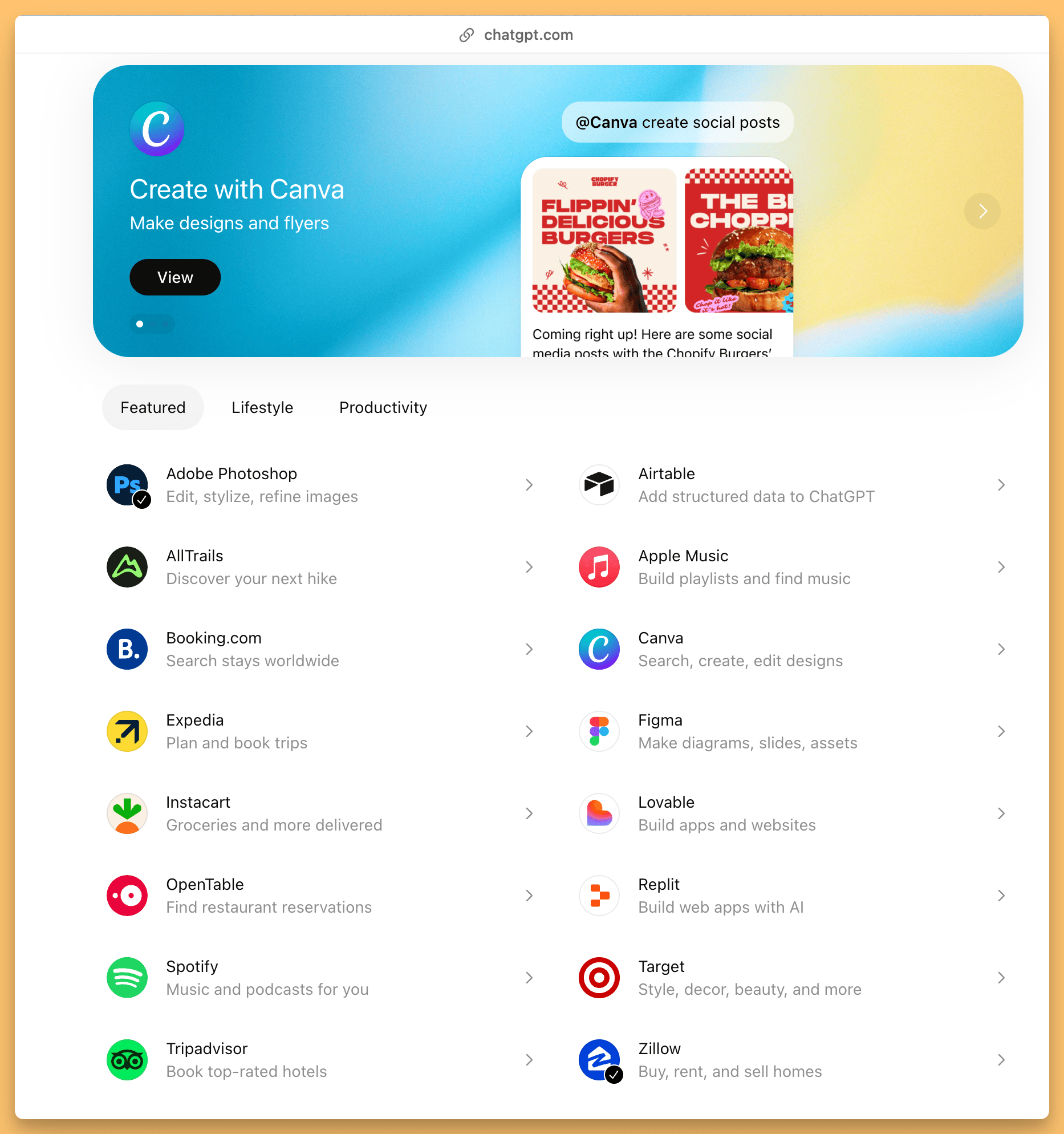
Also today (OpenAI is really throwing everything they have to the end of the year release party), OpenAI has unveiled how their App Store is going to look and opened the submission forms to submit your own apps!
Reminder, ChatGPT apps are powered by MCP and were announced during DevDay, they let companies build a full UI experience right inside ChatGPT, and given OpenAi’s almost 900M weekly active users, this is a big deal! Do you have an app you’d like in there? let me know in the comments!
Open Source AI
🔥 Nvidia Nemotron 3 Nano: The Most Important Open Source Release of the Week (X, HF)

I think the most important release of this week in open source was Nvidia Nemotron 3 Nano, and it was pretty much everywhere. Nemotron is a series of models from Nvidia that’s been pushing efficiency updates, finetune innovations, pruning, and distillations—all the stuff Nvidia does incredibly well.
Nemotron 3 Nano is a 30 billion parameter model with only 3 billion active parameters, using a hybrid Mamba-MoE architecture. This is huge. The model achieves 1.5 to 3.3x faster inference than competing models like Qwen 3 while maintaining competitive accuracy on H200 GPUs.

But the specs aren’t even the most exciting part. NVIDIA didn’t just dump the weights over the wall. They released the datasets—all 25 trillion tokens of pre-training and post-training data. They released the recipes. They released the technical reports. This is what “Open AI” should actually look like.
What’s next? Nemotron 3 Super at 120B parameters (4x Nano) and Nemotron 3 Ultra at 480B parameters (16x Nano) are coming in the next few months, featuring their innovative Latent Mixture of Experts architecture.
Check out the release on HuggingFace
Other Open Source Highlights
LDJ brought up BOLMO from Allen AI—the first byte-level model that actually reaches parity with similar-size models using regular tokenization. This is really exciting because it could open up new possibilities for spelling accuracy, precise code editing, and potentially better omnimodality since ultimately everything is bytes—images, audio, everything.

Wolfram highlighted OLMO 3.1, also from Allen AI, which is multimodal with video input in three sizes (4B, 7B, 8B). The interesting feature here is that you can give it a video, ask something like “how many times does a ball hit the crown?” and it’ll not only give you the answer but mark the precise coordinates on the video frames where it happens. Very cool for tracking objects throughout a video!
Mistral OCR 3 (X)

Mistral also dropped Mistral OCR 3 this week—their next-generation document intelligence model achieving a 74% win rate over OCR 2 across challenging document types. We’re talking forms, low-quality scans, handwritten text, complex tables, and multilingual documents.
The pricing is aggressive at just $2 per 1,000 pages (or $1 with Batch API discount), and it outperforms enterprise solutions like AWS Textract, Azure Doc AI, and Google DocSeek. Available via API and their new Document AI Playground.
🐝 This Week’s Buzz: Wolfram Joins Weights & Biases!
I am so, so hyped to announce this. Our very own co-host and evaluation wizard, Wolfram RavenWlf, is officially joining the Weights & Biases / CoreWeave family as an AI Evangelist and “AIvaluator” starting in January!

Wolfram has been the backbone of the “vibe checks” and deep-dive evals on this show for a long time. Now, he’ll be doing it full-time, building out benchmarks for the community and helping all of us make sense of this flood of models. Expect ThursdAI to get even more data-driven in 2026. Match made in heaven! And if you’re as excited as we are, give Weave a try, it’s free to get started!
Voice & Audio: Faster, Cheaper, Better
If 2025 was the year of the LLM comeback, the end of 2025 is the era of Voice AI commoditization. It is getting so cheap and so fast.
Grok Voice Agent API (X)

xAI launched their Grok Voice Agent API, and the pricing is aggressive: $0.05 per minute flat rate. That significantly undercuts OpenAI and others. But the real killer feature here is the integration.
If you drive a Tesla, this is what powers the voice command when you hold down the button. It has native access to vehicle controls, but for developers, it has native tool calling for Real-time X Search. This means your voice agent can have up-to-the-minute knowledge about the world, something purely pre-trained models struggle with. It ranks #1 on Big Bench Audio, and with that pricing, we’re going to see voice ubiquity very soon.

Kwindla had great insights here: it feels like they optimized for the Tesla use case where it’s a question and an answer. You can see this because Big Bench Audio is a hard audio Q&A benchmark but not multi-turn. So it’s super exciting, but it’s not necessarily what we’ll use for multi-turn conversational voice agents yet.
Here’s what’s really interesting: the entire voice stack was built in-house with custom VAD, tokenizer, and audio models for end-to-end optimization. Tesla was a critical design partner—Grok now powers millions of Tesla vehicles. If you’re building AI voice agents, will you give Grok Voice SDK a try?
Resemble AI’s Chatterbox Turbo (X, HF, GitHub, Blog)
For the open-source heads, Resemble AI dropped a bombshell with Chatterbox Turbo. This is a 350M parameter open-source TTS model that is beating proprietary giants like ElevenLabs in blind tests.

It allows for zero-shot voice cloning from just 5 seconds of audio and supports paralinguistic tags—meaning you can type [laugh] or [sigh]and the model actually acts it out naturally. Plus, it has built-in watermarking for safety. It’s MIT licensed, so you can run this yourself. The fact that an open model is winning on quality against the paid APIs is a huge moment for the community.
Meta SAM Audio

Finally, Meta extended their “Segment Anything” magic to audio with SAM Audio. You know how you can click an object in an image to select it? Now you can do that with sound.
With Sam Audio, you could isolate just the sound of a train from a messy audio track, or pick out a specific instrument from a song. You can prompt it with text (”guitar”), visual clicks on a video, or time stamps. It’s incredible for creators and audio engineers, effectively automating what used to be painful manual editing.
Wrapping Up

What a week to close out 2025. Google proved once again that they’re the gorilla that’s learned to dance—Gemini 3 Flash delivering frontier intelligence at flash prices is going to change how people build AI applications. Nvidia showed that the most valuable company in the world is all-in on open source. OpenAI fired off GPT 5.2 Codex just to make sure we don’t forget about them. And the voice AI space is heating up with options that would have seemed impossible just a year ago.
Look out for the full 2025 yearly recap episode coming next week—it’s a banger. We went month by month through every major AI release and talked about what we thought were the best overall. You’ll really feel the acceleration from that one.
Happy holidays, folks! And as always, thanks for being part of the ThursdAI community.
TL;DR and Show Notes
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co-hosts: @WolframRvnwlf, @yampeleg, @nisten, @ldjconfirmed, @ryancarson
Special Guest: @kwindla - CEO of Daily
Open Source LLMs
NVIDIA Nemotron 3 Nano - 30B-3A hybrid Mamba-MoE model (X, HF, HF FP8)
FunctionGemma - 270M parameter function calling model (X, Blog, Docs)
Mistral OCR 3 - Document intelligence model with 74% win rate over v2 (X, Blog, Console)
BOLMO from Allen AI - First byte-level model reaching parity with regular tokenization (X)
OLMO 2 from Allen AI - Multimodal with video input (4B, 7B, 8B sizes) (X)
Big CO LLMs + APIs
Google Gemini 3 Flash - Frontier intelligence at $0.50/1M input tokens, 78% SWE-bench Verified (X, Announcement)
OpenAI GPT Image 1.5 - 4x faster, 20% cheaper, #1 on LMSYS Image Arena (X)
OpenAI GPT 5.2 Codex - 56.4% SWE-Bench Pro, 64% Terminal-Bench 2.0, 400K context (X, Blog)
ChatGPT App Store - MCP-powered apps submission now open (X)
This Week’s Buzz
🐝 Wolfram joins Weights & Biases / CoreWeave as AI Evangelist and AIvaluator!
Try Weave for AI evaluations
Voice & Audio
xAI Grok Voice Agent API - #1 Big Bench Audio (92.3%), $0.05/min flat rate, powers Tesla vehicles (X)
Resemble AI Chatterbox Turbo - MIT-licensed 350M TTS, beats ElevenLabs in blind tests (X, HF, GitHub, Blog)
Meta SAM Audio - Audio source separation with text/visual/temporal prompts (X, HF, GitHub)
Show Links
Full 2025 Yearly Recap - Coming next week!


