




Holy shit, folks! I was off for two weeks, last week OpenAI released GPT-4o-mini and everyone was in my mentions saying, Alex, how are you missing this?? and I'm so glad I missed that last week and not this one, because while GPT-4o-mini is incredible (GPT-4o level distill with incredible speed and almost 99% cost reduction from 2 years ago?) it's not open source.
So welcome back to ThursdAI, and buckle up because we're diving into what might just be the craziest week in open-source AI since... well, ever!
This week, we saw Meta drop LLAMA 3.1 405B like it's hot (including updated 70B and 8B), Mistral joining the party with their Large V2, and DeepSeek quietly updating their coder V2 to blow our minds. Oh, and did I mention Google DeepMind casually solving math Olympiad problems at silver level medal 🥈? Yeah, it's been that kind of week.
TL;DR of all topics covered:
Open Source
Meta LLama 3.1 updated models (405B, 70B, 8B) - Happy LLama Day! (X, Announcement, Zuck, Try It, Try it Faster, Evals, Provider evals)
DeepSeek-Coder-V2-0724 update (API only)
Big CO LLMs + APIs
This weeks Buzz
Voice & Audio
Meta LLAMA 3.1: The 405B Open Weights Frontier Model Beating GPT-4 👑

Let's start with the star of the show: Meta's LLAMA 3.1. This isn't just a 0.1 update; it's a whole new beast. We're talking about a 405 billion parameter model that's not just knocking on GPT-4's door – it's kicking it down.
Here's the kicker: you can actually download this internet scale intelligence (if you have 820GB free). That's right, a state-of-the-art model beating GPT-4 on multiple benchmarks, and you can click a download button. As I said during the show, "This is not only refreshing, it's quite incredible."

Some highlights:
128K context window (finally!)
MMLU score of 88.6
Beats GPT-4 on several benchmarks like IFEval (88.6%), GSM8K (96.8%), and ARC Challenge (96.9%)
Has Tool Use capabilities (also beating GPT-4) and is Multilingual (ALSO BEATING GPT-4)
But that's just scratching the surface. Let's dive deeper into what makes LLAMA 3.1 so special.
The Power of Open Weights
Mark Zuckerberg himself dropped an exclusive interview with our friend Rowan Cheng from Rundown AI. And let me tell you, Zuck's commitment to open-source AI is no joke. He talked about distillation, technical details, and even released a manifesto on why open AI (the concept, not the company) is "the way forward".
As I mentioned during the show, "The fact that this dude, like my age, I think he's younger than me... knows what they released to this level of technical detail, while running a multi billion dollar company is just incredible to me."
Evaluation Extravaganza

The evaluation results for LLAMA 3.1 are mind-blowing. We're not just talking about standard benchmarks here. The model is crushing it on multiple fronts:
MMLU (Massive Multitask Language Understanding): 88.6%
IFEval (Instruction Following): 88.6%
GSM8K (Grade School Math): 96.8%
ARC Challenge: 96.9%
But it doesn't stop there. The fine folks at meta also for the first time added new categories like Tool Use (BFCL 88.5) and Multilinguality (Multilingual MGSM 91.6) (not to be confused with MultiModality which is not yet here, but soon)
Now, these are official evaluations from Meta themselves, that we know, often don't really represent the quality of the model, so let's take a look at other, more vibey results shall we?

On SEAL leaderboards from Scale (held back so can't be trained on) LLama 405B is beating ALL other models on Instruction Following, getting 4th at Coding and 2nd at Math tasks.
On MixEval (the eval that approximates LMsys with 96% accuracy), my colleagues Ayush and Morgan got a whopping 66%, placing 405B just after Clause Sonnet 3.5 and above GPT-4o

And there are more evals that all tell the same story, we have a winner here folks (see the rest of the evals in my thread roundup)
The License Game-Changer

Meta didn't just release a powerful model; they also updated their license to allow for synthetic data creation and distillation. This is huge for the open-source community.
LDJ highlighted its importance: "I think this is actually pretty important because even though, like you said, a lot of people still train on OpenAI outputs anyways, there's a lot of legal departments and a lot of small, medium, and large companies that they restrict the people building and fine-tuning AI models within that company from actually being able to build the best models that they can because of these restrictions."
This update could lead to a boom in custom models and applications across various industries as companies can start distilling, finetuning and creating synthetic datasets using these incredibly smart models.
405B: A Double-Edged Sword
While the 405B model is incredibly powerful, it's not exactly practical for most production use cases as you need 2 nodes of 8 H100s to run it in full precision. Despite the fact that pricing wars already started, and we see inference providers at as low as 2.7$/1M tokens, this hardly makes sense when GPT-4o mini is 15 cents.
However, this model shines in other areas:
Synthetic Data Generation & Distillation: Its power and the new license make it perfect for creating high-quality training data and use it to train smaller models
LLM as a Judge: The model's reasoning capabilities make it an excellent candidate for evaluating other AI outputs.
Research and Experimentation: For pushing the boundaries of what's possible in AI.
The Smaller Siblings: 70B and 8B
While the 405B model is grabbing headlines, don't sleep on its smaller siblings. The 70B and 8B models got significant upgrades too.
The 70B model saw impressive gains:
MMLU: 80.9 to 86
IFEval: 82 to 87
GPQA: 39 to 46
The 8B model, in particular, could be a hidden gem. As Kyle Corbitt from OpenPipe discovered, a fine-tuned 8B model could potentially beat a prompted GPT-4 Mini in specific tasks.
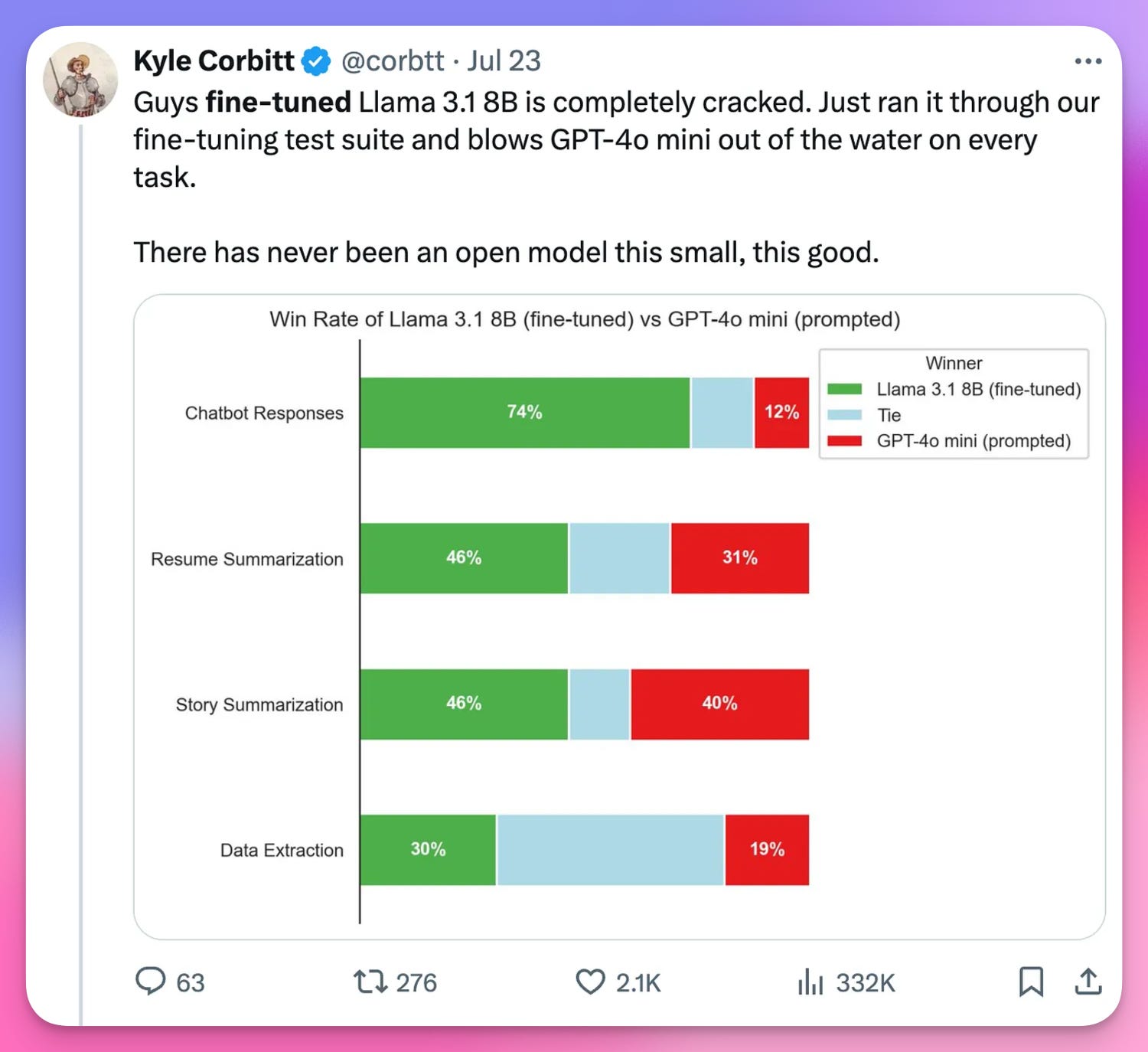
No multi-modality
While Meta definitely addressed everything we had to ask for from the Llama 3 release, context window, incredible performance, multi-linguality, tool-use, we still haven't seen multi-modality with Llama. We still can't show it pictures or talk to it!

However, apparently they have trained it to be mutli-modal as well but haven't yet released those weights, but they went into this in great detail in the paper and even showed a roadmap, stating that they will release it soon-ish (not in EU though)
This Week's Buzz: Weave-ing Through LLama Providers
In the spirit of thorough evaluation, I couldn't resist putting LLAMA 3.1 through its paces across different providers. Using Weights & Biases Weave (https://wandb.me/weave), our evaluation and tracing framework for LLMs, I ran a comparison between various LLAMA providers.

Here's what I found:
Different providers are running the model with varying optimizations (VLLM, FlashAttention3, etc.)
Some are serving quantized versions, which can affect output style and quality
Latency and throughput vary significantly between providers
The full results are available in a Weave comparison dashboard, which you can check out for a deep dive into the nuances of model deployment and code is up on Github if you want to verify this yourself or see how easy this is to do with Weave
Mistral Crashes the Party with Large V2 123B model (X, HF, Blog, Try It)
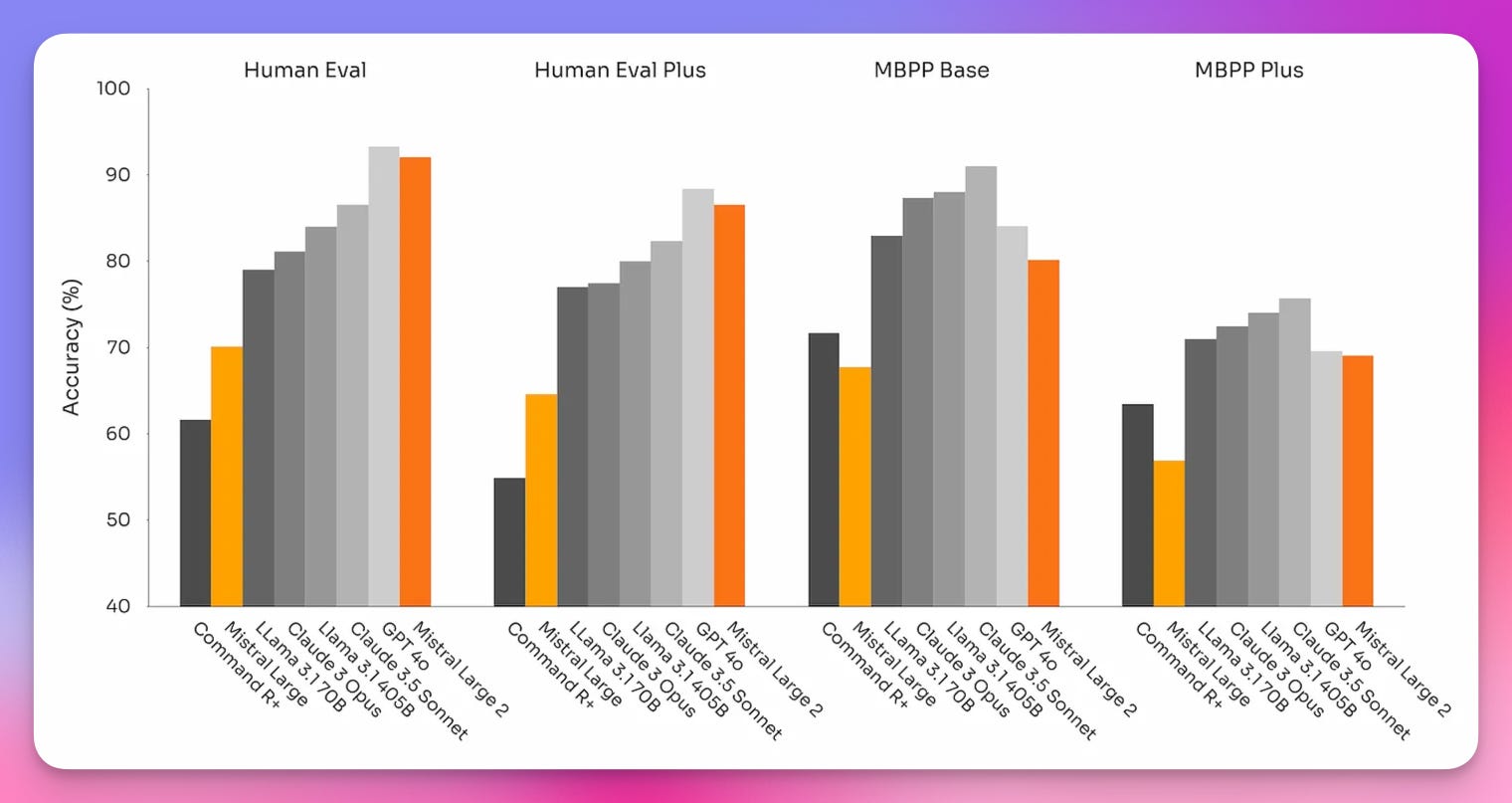
Just when we thought Meta had stolen the show, Mistral AI decided to drop their own bombshell: Mistral Large V2. This 123 billion parameter dense model is no joke, folks. With an MMLU score of 84.0, 128K context window and impressive performance across multiple benchmarks, it's giving LLAMA 3.1 a run for its money, especially in some coding tasks while being optimized to run on a single node!

Especially interesting is the function calling on which they claim SOTA, without telling us which metric they used (or comparing to Llama 3.1) but are saying that they now support parallel and sequential function calling!

DeepSeek updates DeepSeek Coder V2 to 0724
While everyone was busy gawking at Meta and Mistral, DeepSeek quietly updated their coder model, and holy smokes, did they deliver! DeepSeek Coder v2 is now performing at GPT-4 and Claude 3.5 Sonnet levels on coding tasks. As Junyang Lin noted during our discussion, "DeepSeek Coder and DeepSeek Coder v2 should be the state of the art of the code-specific model."
Here's the result from BigCodeBench

and from Aider Chat (code editing dashboard)
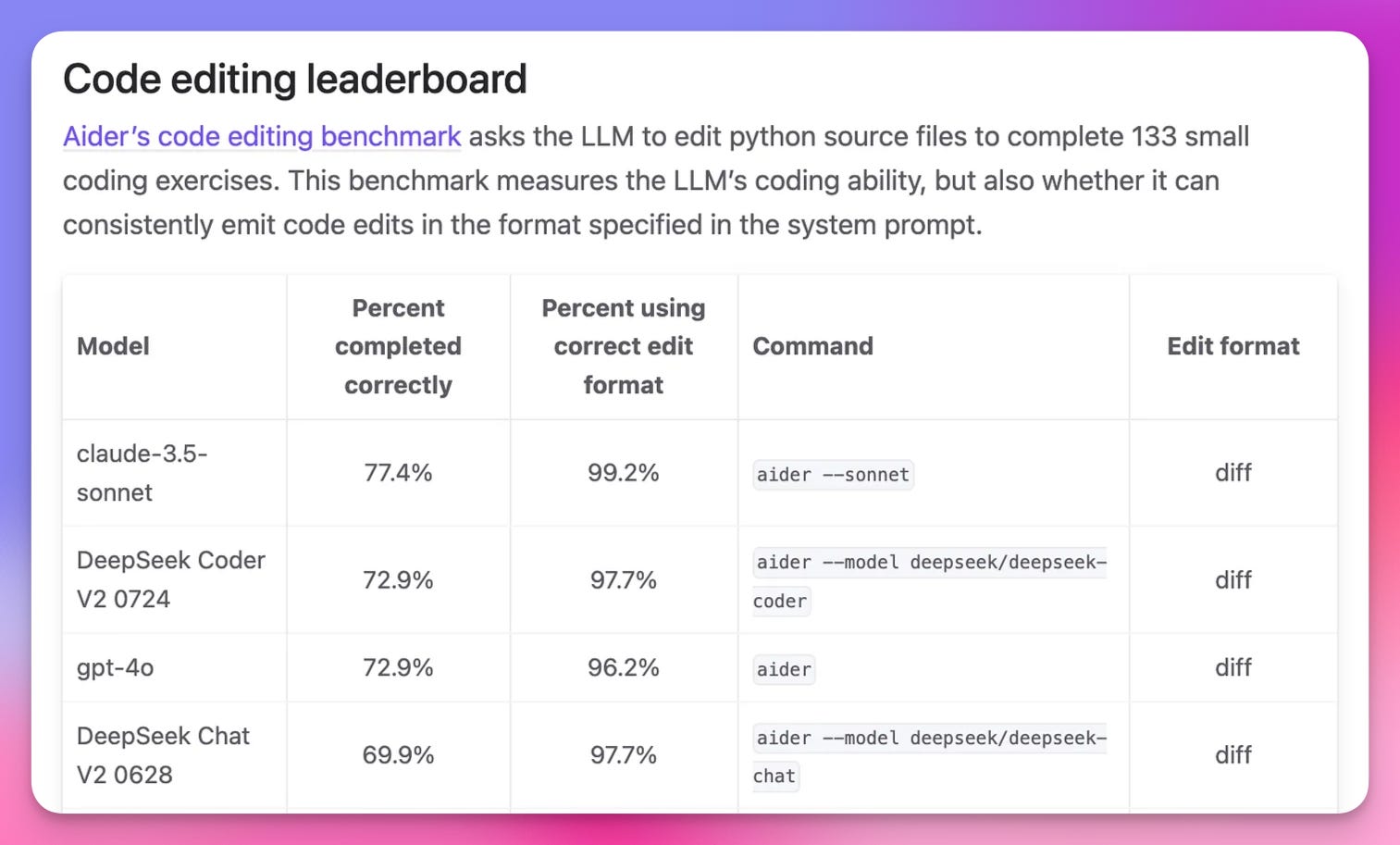
But it's not just about raw performance. DeepSeek is bringing some serious innovation to the table. They've added JSON mode, function calling, and even a fill-in-the-middle completion feature in beta. Plus, they've bumped up their max token generation to 8K. And let's talk about that API pricing – it's ridiculously cheap, at 14c / 1M tokens!.
We're talking about costs that are competitive with GPT-4 Mini, but with potentially better performance on coding tasks. It's a game-changer for developers and companies looking to integrate powerful coding AI without breaking the bank.
Google DeepMind's Math Wizardry: From Silver Medals to AI Prodigies
Just when we thought this week couldn't get any crazier, Google DeepMind decides to casually drop a bombshell that would make even the most decorated mathletes sweat. They've created an AI system that can solve International Mathematical Olympiad (IMO) problems at a silver medalist level. I mean, come on! As if the AI world wasn't moving fast enough, now we've got silicon-based Math Olympians?

This isn't just any run-of-the-mill calculator on steroids. We're talking about a combination of AlphaProof, a new breakthrough model for formal reasoning, and AlphaGeometry 2, an upgraded version of their previous system. These AI math whizzes tackled this year's six IMO problems, covering everything from algebra to number theory, and managed to solve four of them. That's 28 points, folks - enough to bag a silver medal if it were human!
But here's where it gets really interesting. For non-geometry problems, AlphaProof uses the Lean theorem prover, coupling a pre-trained language model with the same AlphaZero reinforcement learning algorithm that taught itself to crush humans at chess and Go. And for geometry? They've got AlphaGeometry 2, a neuro-symbolic hybrid system powered by a Gemini-based language model. It's like they've created a math genius that can not only solve problems but also explain its reasoning in a formal, verifiable way.
The implications here are huge, folks. We're not just talking about an AI that can do your homework; we're looking at a system that could potentially advance mathematical research and proof verification in ways we've never seen before.
OpenAI takes on Google, Perplexity (and Meta's ownership of this week) with SearchGPT waitlist (Blog)

As I write these words, Sam posts a tweet, saying that they are launching SearchGPT, their new take on search, and as I click, I see a waitlist 😅 But still, this looks so sick, just look:
RTVI - new open standard for real time Voice and Video RTVI-AI (X, Github, Try it)

Ok this is also great and can't be skipped, even tho this week was already insane. These models are great to text with but we want to talk to them, and while we all wait for GPT-4 Omni with voice to actually ship, we get a new contender that gives us an open standard and a killer demo!
Daily + Groq + Cartesia + a lot of other great companies have releases this incredible demo (which you can try yourself here) and an open source standard to deliver something like a GPT-4o experience with incredible end to end latency, which feels like almost immediate responses.
While we've chatted with Moshi previously which has these capabilities in the same model, the above uses LLama 3.1 70B even, which is an actual production grade LLM, which is a significant different from what Moshi offers. 🔥
Ok holy shit, did I actually finish the writeup for this insane week? This was indeed one of the craziest weeks in Open Source AI, I honestly did NOT expect this to happen but I'm so excited to keep playing with all these tools, but also to see how the amazing open source community of finetuners will meet all these LLamas. Which I'm sure I'll be reporting on from now on until the next huge big AI breakthrough!
Till then, see you next week, if you're listening to the podcast, please give us 5 stars on Apple podcast / Spotify? It really does help, and I'll finish with this:
IT'S SO GOOD TO BE BACK! 😂🫡


