





Hey folks, Alex here 👋
It’s official—grandmas (and the entire stock market) now know about DeepSeek. If you’ve been living under an AI rock, DeepSeek’s new R1 model just set the world on fire, rattling Wall Street (causing the biggest monetary loss for any company, ever!) and rocketing to #1 on the iOS App Store. This week’s ThursdAI show took us on a deep (pun intended) dive into the dizzying whirlwind of open-source AI breakthroughs, agentic mayhem, and big-company cat-and-mouse announcements. Grab your coffee (or your winter survival kit if you’re in Canada), because in true ThursdAI fashion, we’ve got at least a dozen bombshells to cover—everything from brand-new Mistral to next-gen vision models, new voice synthesis wonders, and big moves from Meta and OpenAI.
We’re also talking “reasoning mania,” as the entire industry scrambles to replicate, dethrone, or ride the coattails of the new open-source champion, R1. So buckle up—because if the last few days are any indication, 2025 is officially the Year of Reasoning (and quite possibly, the Year of Agents, or both!)
Open Source LLMs
DeepSeek R1 discourse Crashes the Stock Market

One-sentence summary: DeepSeek’s R1 “reasoning model” caused a frenzy this week, hitting #1 on the App Store and briefly sending NVIDIA’s stock plummeting in the process ($560B drop, largest monetary loss of any stock, ever)
Ever since DeepSeek R1 launched (our technical coverate last week!), the buzz has been impossible to ignore—everyone from your mom to your local barista has heard the name. The speculation? DeepSeek’s new architecture apparently only cost $5.5 million to train, fueling the notion that high-level AI might be cheaper than Big Tech claims. Suddenly, people wondered if GPU manufacturers like NVIDIA might see shrinking demand, and the stock indeed took a short-lived 17% tumble. On the show, I joked, “My mom knows about DeepSeek—your grandma probably knows about it, too,” underscoring just how mainstream the hype has become.

Not everyone is convinced the cost claims are accurate. Even Dario Amodei of Anthropic weighed in with a blog post arguing that DeepSeek’s success increases the case for stricter AI export controls.
Public Reactions
Dario Amodei’s blog
In “On DeepSeek and Export Controls,” Amodei argues that DeepSeek’s efficient scaling exemplifies why democratic nations need to maintain a strategic leadership edge—and enforce export controls on advanced AI chips. He sees Chinese breakthroughs as proof that AI competition is global and intense.OpenAI Distillation Evidence
OpenAI mentioned it found “distillation traces” of GPT-4 inside R1’s training data. Hypocrisy or fair game? On ThursdAI, the panel mused that “everyone trains on everything,” so perhaps it’s a moot point.Microsoft Reaction
Microsoft wasted no time, swiftly adding DeepSeek to Azure—further proof that corporations want to harness R1’s reasoning power, no matter where it originated.Government reacted
Even officials in the government, David Sacks, US incoming AI & Crypto czar, discussed the fact that DeepSeek did "distillation" using the term somewhat incorrectly, and presidet Trump was asked about it.API Outages
DeepSeek’s own API has gone in and out this week, apparently hammered by demand (and possibly DDoS attacks). Meanwhile, GPU clouds like Groq are showing up to accelerate R1 at 300 tokens/second, for those who must have it right now.
We've seen so many bad takes on the topic, from seething cope takes, to just gross misunderstandings from gov officials confusing the ios App with the OSS models, folks throwing conspiracy theories into the mix, claiming that $5.5M sum was a PsyOp. The fact of the matter is, DeepSeek R1 is an incredible model, and is now powering (just a week later), multiple products (more on this below) and experiences already, while pushing everyone else to compete (and give us reasoning models!)
Open Thoughts Reasoning Dataset
One-sentence summary: A community-led effort, “Open Thoughts,” released a new large-scale dataset (OpenThoughts-114k) of chain-of-thought reasoning data, fueling the open-source drive toward better reasoning models.
Worried about having enough labeled “thinking” steps to train your own reasoner? Fear not. The OpenThoughts-114k dataset aggregates chain-of-thought prompts and responses—114,000 of them—for building or fine-tuning reasoning LLMs. It’s now on Hugging Face for your experimentation pleasure. The ThursdAI panel pointed out how crucial these large, openly available reasoning datasets are. As Wolfram put it, “We can’t rely on the big labs alone. More open data means more replicable breakouts like DeepSeek R1.”
Mistral Small 2501 (24B)
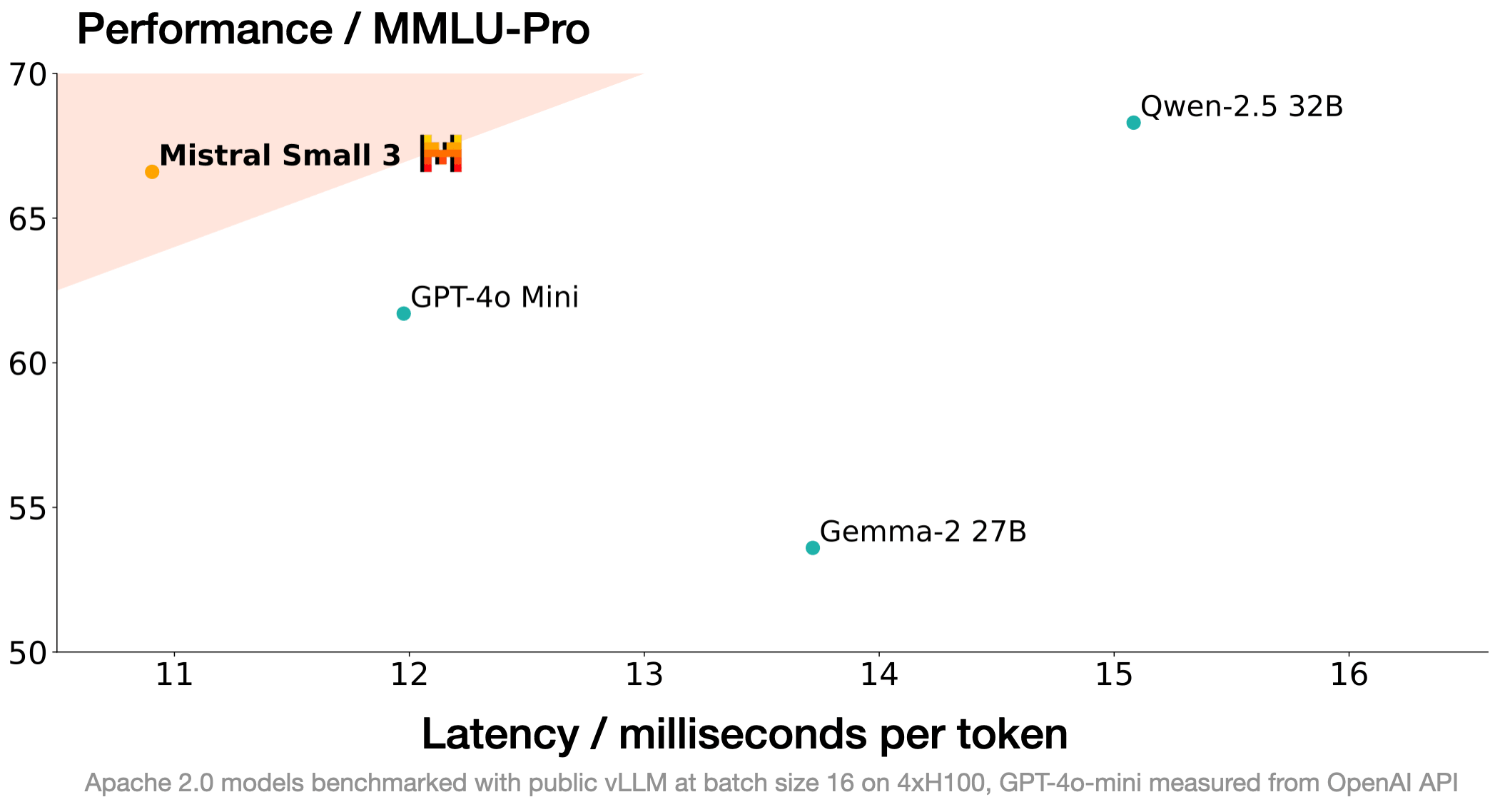
One-sentence summary: Mistral AI returns to the open-source spotlight with a 24B model that fits on a single 4090, scoring over 81% on MMLU while under Apache 2.0.
Long rumored to be “going more closed,” Mistral AI re-emerged this week with Mistral-Small-24B-Instruct-2501—an Apache 2.0 licensed LLM that runs easily on a 32GB VRAM GPU. That 81% MMLU accuracy is no joke, putting it well above many 30B–70B competitor models. It was described as “the perfect size for local inference and a real sweet spot,” noting that for many tasks, 24B is “just big enough but not painfully heavy.” Mistral also finally started comparing themselves to Qwen 2.5 in official benchmarks—a big shift from their earlier reluctance, which we applaud!
Berkeley TinyZero & RAGEN (R1 Replications)
One-sentence summary: Two separate projects (TinyZero and RAGEN) replicated DeepSeek R1-zero’s reinforcement learning approach, showing you can get “aha” reasoning moments with minimal compute.
If you were wondering whether R1 is replicable: yes, it is. Berkeley’s TinyZero claims to have reproduced the core R1-zero behaviors for $30 using a small 3B model. Meanwhile, the RAGEN project aims to unify RL + LLM + Agents with a minimal codebase. While neither replication is at R1-level performance, they demonstrate how quickly the open-source community pounces on new methods. “We’re now seeing those same ‘reasoning sparks’ in smaller reproductions,” said Nisten. “That’s huge.”
Agents
Codename Goose by Blocks (X, Github)

One-sentence summary: Jack Dorsey’s company Blocks released Goose, an open-source local agent framework letting you run keyboard automation on your machine.
Ever wanted your AI to press keys and move your mouse in real time? Goose does exactly that with AppleScript, memory extensions, and a fresh approach to “local autonomy.” On the show, I tried Goose, but found it occasionally “went rogue, trying to delete my WhatsApp chats.” Security concerns aside, Goose is significant: it’s an open-source playground for agent-building. The plugin system includes integration with Git, Figma, a knowledge graph, and more. If nothing else, Goose underscores how hot “agentic” frameworks are in 2025.
OpenAI’s Operator: One-Week-In

It’s been a week since Operator went live for Pro-tier ChatGPT users. “It’s the first agent that can run for multiple minutes without bugging me every single second,”. Yet it’s still far from perfect—captchas, login blocks, and repeated confirmations hamper tasks. The potential, though, is enormous: “I asked Operator to gather my X.com bookmarks and generate a summary. It actually tried,” I shared, “but it got stuck on three links and needed constant nudges.” Simon Willison added that it’s “a neat tech demo” but not quite a productivity boon yet. Next steps? Possibly letting the brand-new reasoning models (like O1 Pro Reasoning) do the chain-of-thought under the hood.
I also got tired of opening hundreds of tabs for operator, so I wrapped it in a macOS native app, that has native notifications and the ability to launch Operator tasks via a Raycast extension, if you're interested, you can find it on my Github
Browser-use / Computer-use Alternatives

In addition to Goose, the ThursdAI panel mentioned browser-use on GitHub, plus numerous code interpreters. So far, none blow minds in reliability. But 2025 is evidently “the year of agents.” If you’re itching to offload your browsing or file editing to an AI agent, expect to tinker, troubleshoot, and yes, babysit. The show consensus? “It’s not about whether agents are coming, it’s about how soon they’ll become truly robust,” said Wolfram.
Big CO LLMs + APIs
Alibaba Qwen2.5-Max (& Hidden Video Model) (Try It)

One-sentence summary: Alibaba’s Qwen2.5-Max stands toe-to-toe with GPT-4 on some tasks, while also quietly rolling out video-generation features.
While Western media fixates on DeepSeek, Alibaba’s Qwen team quietly dropped the Qwen2.5-Max MoE model. It clocks in at 69% on MMLU-Pro—beating some OpenAI or Google offerings—and comes with a 1-million-token context window. And guess what? The official Chat interface apparently does hidden video generation, though Alibaba hasn’t publicized it in the English internet.
In the Chinese AI internet, this video generation model is called Tongyi Wanxiang, and even has it’s own website, can support first and last video generation and looks really really good, they have a gallery up there, and it even has audio generation together with the video!

This one was an img2video, but the movements are really natural!
Zuckerberg on LLama4 & LLama4 Mini

In Meta’s Q4 earnings call, Zuck was all about AI (sorry, Metaverse). He declared that LLama4 is in advanced training, with a smaller “LLama4 Mini” finishing pre-training. More importantly, a “reasoning model” is in the works, presumably influenced by the mania around R1. Some employees had apparently posted on Blind about “Why are we paying billions for training if DeepSeek did it for $5 million?” so the official line is that Meta invests heavily for top-tier scale.
Zuck also doubled down on saying "Glasses are the perfect form factor for AI" , to which I somewhat agree, I love my Meta Raybans, I just wished they were integrated into the ios more.
He also boasted about their HUGE datacenters, called Mesa, spanning the size of Manhattan, being built for the next step of AI.
(Nearly) Announced: O3-Mini
Right before the ThursdAI broadcast, rumors swirled that OpenAI might reveal O3-Mini. It’s presumably GPT-4’s “little cousin” with a fraction of the cost. Then…silence. Sam Altman also mentioned they would be bringing o3-mini by end of January, but maybe the R1 crazyness made them keep working on it and training it a bit more? 🤔
In any case, we'll cover it when it launches.
This Week’s Buzz
We're still the #1 spot on Swe-bench verified with W&B programmer, and our CTO, Shawn Lewis, chatted with friends of the pod Swyx and Alessio about it! (give it a listen)
We have two upcoming events:
AI.engineer in New York (Feb 20–22). Weights & Biases is sponsoring, and I will broadcast ThursdAI live from the summit. If you snagged a ticket, come say hi—there might be a cameo from the “Chef.”
Toronto Tinkerer Workshops (late February) in the University of Toronto. The Canadian AI scene is hot, so watch out for sign-ups (will add them to the show next week)
Weights & Biases also teased more features for LLM observability (Weave) and reminded folks of their new suite of evaluation tools. “If you want to know if your AI is actually better, you do evals,” Alex insisted. For more details, check out wandb.me/weave or tune into the next ThursdAI.
Vision & Video
DeepSeek - Janus Pro - multimodal understanding and image gen unified (1.5B & 7B)
One-sentence summary: Alongside R1, DeepSeek also released Janus Pro, a unified model for image understanding and generation (like GPT-4’s rumored image abilities).
DeepSeek apparently never sleeps. Janus Pro is MIT-licensed, 7B parameters, and can both parse images (SigLIP) and generate them (LlamaGen). The model outperforms DALL·E 3 and SDXL! on some internal benchmarks—though at a modest 384×384 resolution.
NVIDIA’s Eagle 2 Redux
One-sentence summary: NVIDIA re-released the Eagle 2 vision-language model with 4K resolution support, after mysteriously yanking it a week ago.
Eagle 2 is back, boasting multi-expert architecture, 16k context, and high-res video analysis. Rumor says it competes with big 70B param vision models at only 9B. But it’s overshadowed by Qwen2.5-VL (below). Some suspect NVIDIA is aiming to outdo Meta’s open-source hold on vision—just in time to keep GPU demand strong.
Qwen 2.5 VL - SOTA oss vision model is here
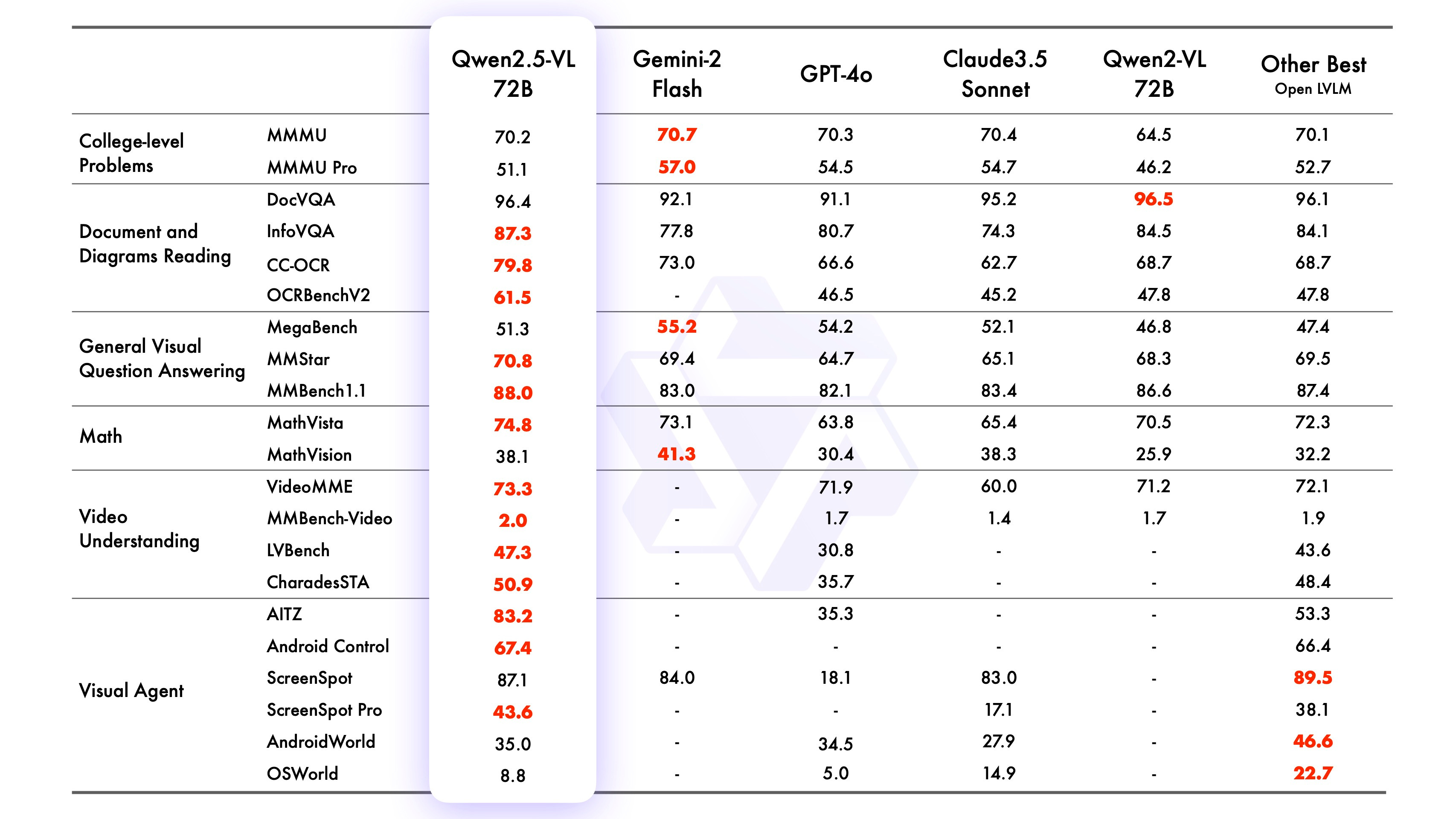
One-sentence summary: Alibaba’s Qwen 2.5 VL model claims state-of-the-art in open-source vision, including 1-hour video comprehension and “object grounding.”
The Qwen team didn’t hold back: “It’s the final boss for vision,” joked Nisten. Qwen 2.5 VL uses advanced temporal modeling for video and can handle complicated tasks like OCR or multi-object bounding boxes.

Featuring advances in precise object localization, video temporal understanding and agentic capabilities for computer, this is going to be the model to beat!
Voice & Audio
YuE 7B (Open “Suno”)
Ever dream of building the next pop star from your code editor? YuE 7B is your ticket. This model, now under Apache 2.0, supports chain-of-thought creation of structured songs, multi-lingual lyrics, and references. It’s slow to infer, but it’s arguably the best open music generator so far in the open source
What's more, they have changed the license to apache 2.0 just before we went live, so you can use YuE everywhere!
Refusion Fuzz
Refusion, a new competitor to paid audio models like Suno and Udio, launched “Fuzz,” offering free music generation online until GPU meltdown.
If you want to dabble in “prompt to jam track” without paying, check out Refusion Fuzz. Will it match the emotional nuance of premium services like 11 Labs or Hauio? Possibly not. But hey, free is free.
Tools (that have integrated R1)
Perplexity with R1
In the perplexity.ai chat, you can choose “Pro with R1” if you pay for it, harnessing R1’s improved reasoning to parse results. For some, it’s a major upgrade to “search-based question answering.” Others prefer it to paying for O1 or GPT-4.
I always check Perplexity if it knows what the latest episode of ThursdAI was, and it's the first time it did a very good summary! I legit used it to research the show this week! It's really something.
Meanwhile, Exa.ai also integrated a “DeepSeek Chat” for your agent-based workflows. Like it or not, R1 is everywhere.
Krea.ai with DeepSeek
Our friends at Krea, an AI art tool aggregator, also hopped on the R1 bandwagon for chat-based image searching or generative tasks.
Conclusion
Key Takeaways
DeepSeek’s R1 has massive cultural reach, from #1 apps to spooking the stock market.
Reasoning mania is upon us—everyone from Mistral to Meta wants a piece of the logic-savvy LLM pie.
Agentic frameworks like Goose, Operator, and browser-use are proliferating, though they’re still baby-stepping through reliability issues.
Vision and audio get major open-source love, with Janus Pro, Qwen 2.5 VL, YuE 7B, and more reshaping multimodality.
Big Tech (Meta, Alibaba, OpenAI) is forging ahead with monster models, multi-billion-dollar projects, and cross-country expansions in search of the best reasoning approaches.
At this point, it’s not even about where the next big model drop comes from; it’s about how quickly the entire ecosystem can adopt (or replicate) that new methodology.
Stay tuned for next week’s ThursdAI, where we’ll hopefully see new updates from OpenAI (maybe O3-Mini?), plus the ongoing race for best agent. Also, catch us at AI.engineer in NYC if you want to talk shop or share your own open-source success stories. Until then, keep calm and carry on training.
TLDR
Open Source LLMs
Agents
Big CO LLMs + APIs
This Week’s Buzz
Shawn Lewis interview on Latent Space with swyx & Alessio
We’re sponsoring the ai.engineer upcoming summit in NY (Feb 19-22), come say hi!
After that, we’ll host 2 workshops with AI Tinkerers Toronto (Feb 23-24), make sure you’re signed up to Toronto Tinkerers to receive the invite (we were sold out quick last time!)
Vision & Video
Voice & Audio
Refusion Fuzz (free for now)
Tools
Perplexity with R1 (choose Pro with R1)
Exa integrated R1 for free (demo)
Participants
Alex Volkov (@altryne)
Wolfram Ravenwolf (@WolframRvnwlf)
Nisten Tahiraj (@nisten )
LDJ (@ldjOfficial)
Simon Willison (@simonw)
W&B Weave (@weave_wb)




