




Hey everyone,
December started strong and does NOT want to slow down!? OpenAI showed us their response to the Code Red and it’s GPT 5.2, which doesn’t feel like a .1 upgrade! We got it literally as breaking news at the end of the show, and oh boy! The new kind of LLMs is here.
GPT, then Gemini, then Opus and now GPT again... Who else feels like we’re on a trippy AI rolercoaster? Just me? 🫨

I’m writing this newsletter from a fresh “traveling podcaster” setup in SF (huge shoutout to the Chroma team for the studio hospitality).
P.S - Next week we’re doing a year recap episode (52st episode of the year, what is my life), but today is about the highest-signal stuff that happened this week.
Alright. No more foreplay. Let’s dive in. Please subscribe.
🔥 The main event: OpenAI launches GPT‑5.2 (and it’s… a lot)

We started the episode with “garlic in the air” rumors (OpenAI holiday launches always have that Christmas panic energy), and then… boom: GPT‑5.2 actually drops while we’re live.
What makes this release feel significant isn’t “one benchmark went up.” It’s that OpenAI is clearly optimizing for the things that have become the frontier in 2025: long-horizon reasoning, agentic coding loops, long context reliability, and lower hallucination rates when browsing/tooling is involved.
5.2 Instant, Thinking and Pro in ChatGPT and in the API
OpenAI shipped multiple variants, and even within those there are “levels” (medium/high/extra-high) that effectively change how much compute the model is allowed to burn. At the extreme end, you’re basically running parallel thoughts and selecting winners. That’s powerful, but also… very expensive.
It’s very clearly aimed at the agentic world: coding agents that run in loops, tool-using research agents, and “do the whole task end-to-end” workflows where spending extra tokens is still cheaper than spending an engineer day.
Benchmarks
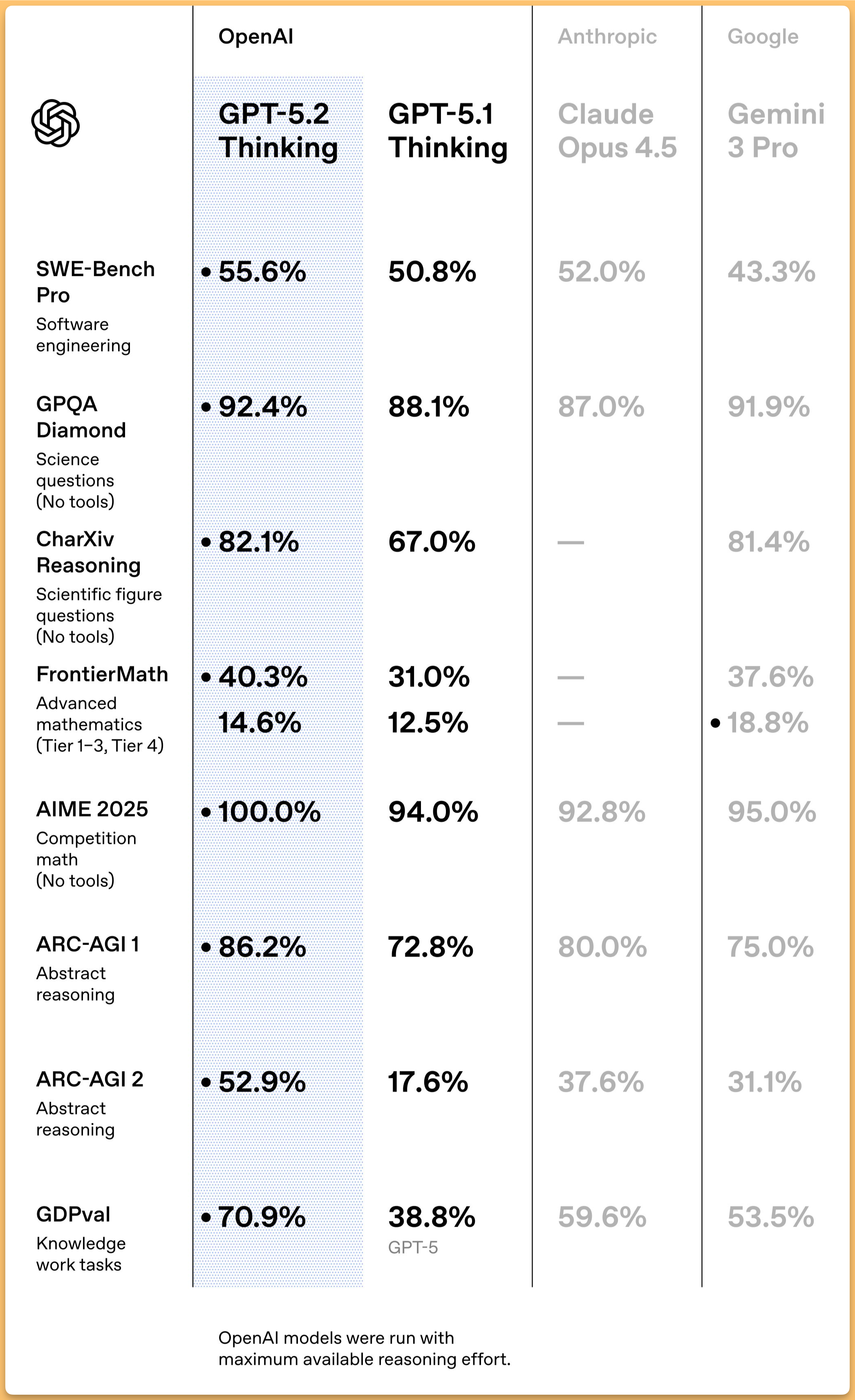
I’m not going to pretend benchmarks tell the full story (they never do), but the shape of improvements matters. GPT‑5.2 shows huge strength on reasoning + structured work.
It hits 90.5% on ARC‑AGI‑1 in the Pro X‑High configuration, and 54%+ on ARC‑AGI‑2 depending on the setting. For context, ARC‑AGI‑2 is the one where everyone learns humility again.
On math/science, this thing is flexing. We saw 100% on AIME 2025, and strong performance on FrontierMath tiers (with the usual “Tier 4 is where dreams go to die” vibe still intact). GPQA Diamond is up in the 90s too, which is basically “PhD trivia mode.”
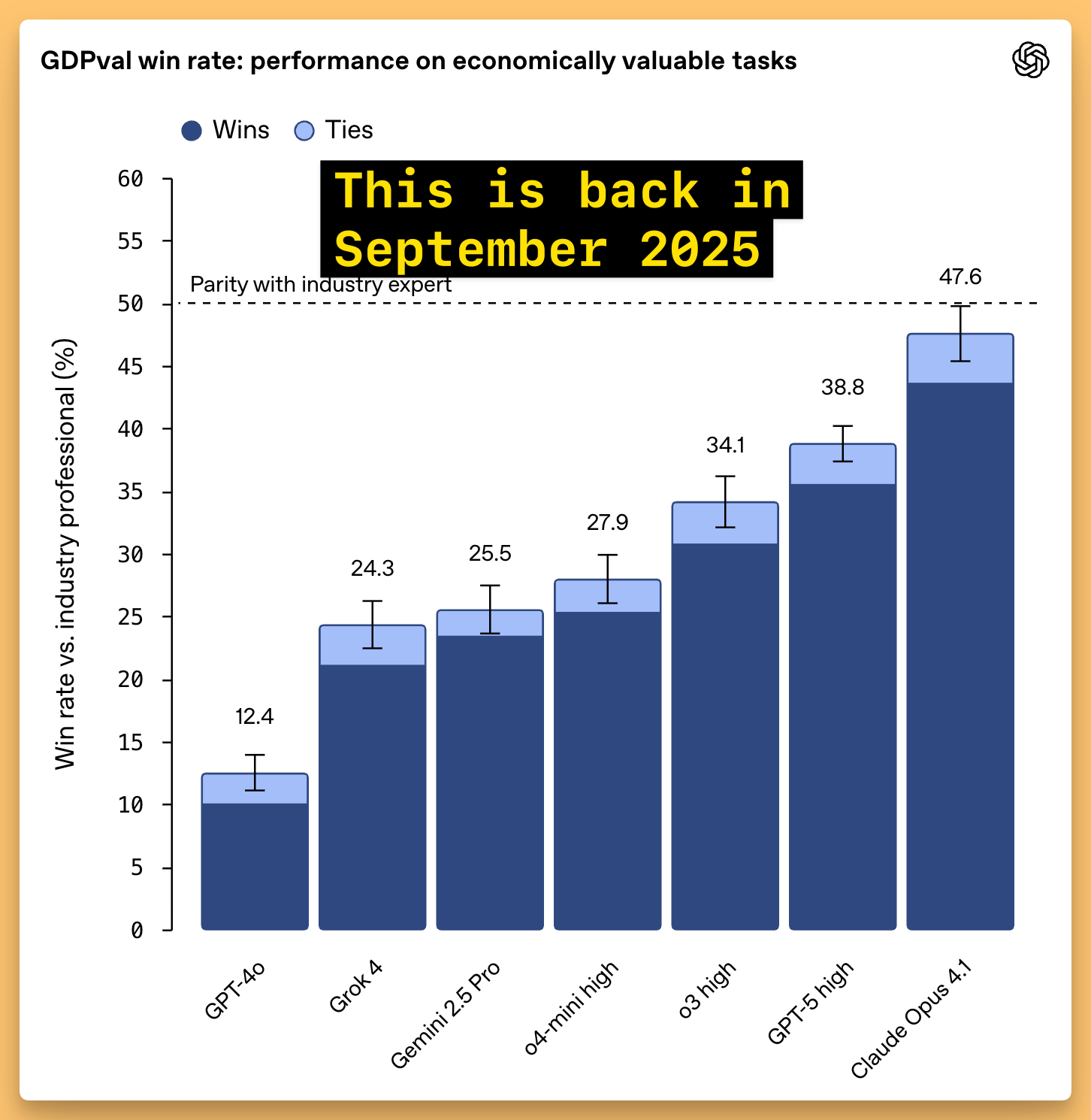
But honestly the most practically interesting one for me is GDPval (knowledge-work tasks: slides, spreadsheets, planning, analysis). GPT‑5.2 lands around 70%, which is a massive jump vs earlier generations. This is the category that translates directly into “is this model useful at my job.” - This is a bench that OpenAI launched only in September and back then, Opus 4.1 was a “measly” 47%! Talk about acceleration!
Long context: MRCR is the sleeper highlight

On MRCR (multi-needle long-context retrieval), GPT‑5.2 holds up absurdly well even into 128k and beyond. The graph OpenAI shared shows GPT‑5.1 falling off a cliff as context grows, while GPT‑5.2 stays high much deeper into long contexts.
If you’ve ever built a real system (RAG, agent memory, doc analysis) you know this pain: long context is easy to offer, hard to use well. If GPT‑5.2 actually delivers this in production, it’s a meaningful shift.
Hallucinations: down (especially with browsing)
One thing we called out on the show is that a bunch of user complaints in 2025 have basically collapsed into one phrase: “it hallucinates.” Even people who don’t know what a benchmark is can feel when a model confidently lies.
OpenAI’s system card shows lower rates of major incorrect claims compared to GPT‑5.1, and lower “incorrect claims” overall when browsing is enabled. That’s exactly the direction they needed.
Real-world vibes:
We did the traditional “vibe tests” mid-show: generate a flashy landing page, do a weird engineering prompt, try some coding inside Cursor/Codex.
Early testers broadly agree on the shape of the improvement. GPT‑5.2 is much stronger in reasoning, math, long‑context tasks, visual understanding, and multimodal workflows, with multiple reports of it successfully thinking for one to three hours on hard problems. Enterprise users like Box report faster execution and higher accuracy on real knowledge‑worker tasks, while researchers note that GPT‑5.2 Pro consistently outperforms the standard “Thinking” variant. The tradeoffs are also clear: creative writing still slightly favors Claude Opus, and the highest reasoning tiers can be slow and expensive. But as a general‑purpose reasoning model, GPT‑5.2 is now the strongest publicly available option.
AI in space: Starcloud trains an LLM on an H100 in orbit

This story is peak 2025.
Starcloud put an NVIDIA H100 on a satellite, trained Andrej Karpathy’s nanoGPT on Shakespeare, and ran inference on Gemma. There’s a viral screenshot vibe here that’s impossible to ignore: SSH into an H100… in space… with a US flag in the corner. It’s engineered excitement, and I’m absolutely here for it.

But we actually had a real debate on the show: is “GPUs in space” just sci‑fi marketing, or does it make economic sense?
Nisten made a compelling argument that power is the real bottleneck, not compute, and that big satellites already operate in the ~20kW range. If you can generate that power reliably with solar in orbit, the economics start looking less insane than you’d think. LDJ added the long-term land/power convergence argument: Earth land and grid power get scarcer/more regulated, while launch costs trend down—eventually the curves may cross.
I played “voice of realism” for a minute: what happens when GPUs fail? It’s hard enough to swap a GPU in a datacenter, now imagine doing it in orbit. Cooling and heat dissipation become a different engineering problem too (radiators instead of fans). Networking is nontrivial. But also: we are clearly entering the era where people will try weird infra ideas because AI demand is pulling the whole economy.
Big Company: MCP gets donated, OpenRouter drops a report on AI
Agentic AI Foundation Lands at the Linux Foundation

This one made me genuinely happy.
Block, Anthropic, and OpenAI came together to launch the Agentic AI Foundation under the Linux Foundation, donating key projects like MCP, AGENTS.md, and goose. This is exactly how standards should happen: vendor‑neutral, boring governance, lots of stakeholders.
It’s not flashy work, but it’s the kind of thing that actually lets ecosystems grow without fragmenting.

BTW, I was recording my podcast while Latent.Space were recording theirs in the same office, and they have a banger episode upcoming about this very topic! All I’ll say is Alessio Fanelli introduced me to David Soria Parra from MCP 👀 Watch out for that episode on Latent space dropping soon!
OpenRouter’s “State of AI”: 100 Trillion Tokens of Reality

OpenRouter and a16z dropped a massive report analyzing over 100 trillion tokens of real‑world usage. A few things stood out:
Reasoning tokens now dominate. Above 50%, around 60% of all tokens since early 2025 are reasoning tokens. Remember when we went from “LLMs can’t do math” to reasoning models? That happened in about a year.
Programming exploded. From 11% of usage early 2025 to over 50% recently. Claude holds 60% of the coding market. (at least.. on Open Router)
Open source hit 30% market share, led by Chinese labs: DeepSeek (14T tokens), Qwen (5.59T), Meta LLaMA (3.96T).
Context lengths grew massively. Average prompt length went from 1.5k to 6k+ tokens (4x growth), completions from 133 to 400 tokens (3x).
The “Glass Slipper” effect. When users find a model that fits their use case, they stay loyal. Foundational early-user cohorts retain around 40% at month 5. Claude 4 Sonnet still had 50% retention after three months.
Geography shift. Asia doubled to 31% of usage (China key), while North America is at 47%.
Yam made a good point that we should be careful interpreting these graphs—they’re biased toward people trying new models, not necessarily steady usage. But the trends are clear: agentic, reasoning, and coding are the dominant use cases.
Open Source Is Not Slowing Down (If Anything, It’s Accelerating)
One of the strongest themes this week was just how fast open source is closing the gap — and in some areas, outright leading. We’re not talking about toy demos anymore. We’re talking about serious models, trained from scratch, hitting benchmarks that were frontier‑only not that long ago.
Essential AI’s Rnj‑1: A Real Frontier 8B Model

This one deserves real attention. Essential AI — led by Ashish Vaswani, yes Ashish from the original Transformers paper — released Rnj‑1, a pair of 8B open‑weight models trained fully from scratch. No distillation. No “just a fine‑tune.” This is a proper pretrain.
What stood out to me isn’t just the benchmarks (though those are wild), but the philosophy. Rnj‑1 is intentionally focused on pretraining quality: data curation, code execution simulation, STEM reasoning, and agentic behaviors emerging during pretraining instead of being bolted on later with massive RL pipelines.
In practice, that shows up in places like SWE‑bench Verified, where Rnj‑1 lands in the same ballpark as much larger closed models, and in math and STEM tasks where it punches way above its size. And remember: this is an 8B model you can actually run locally, quantize aggressively, and deploy without legal gymnastics thanks to its Apache 2.0 license.
Mistral Devstral 2 + Vibe: Open Coding Goes Hard

Mistral followed up last week’s momentum with Devstral 2, and Mistral Vibe!
The headline numbers are: the 123B Devstral 2 model lands right at the top of open‑weight coding benchmarks, nearly matching Claude 3.5 Sonnet on SWE‑bench Verified. But what really excited the panel was the 24B Devstral Small 2, which hits high‑60s SWE‑bench scores while being runnable on consumer hardware.
This is the kind of model you can realistically run locally as a coding agent, without shipping your entire codebase off to someone else’s servers. Pair that with Mistral Vibe, their open‑source CLI agent, and you suddenly have a credible, fully open alternative to things like Claude Code, Codex, or Gemini CLI.
We talked a lot about why this matters. Some teams can’t send code to closed APIs. Others just don’t want to pay per‑token forever. And some folks — myself included — just like knowing what’s actually running under the hood. Devstral 2 checks all those boxes.
🐝 This week’s Buzz (W&B): Trace OpenRouter traffic into Weave with zero code

We did a quick “Buzz” segment on a feature that I think a lot of builders will love:
OpenRouter launched Broadcast, which can stream traces to observability vendors. One of those destinations is W&B Weave.
The magic here is: if you’re using a tool that already talks to OpenRouter, you can get tracing into Weave without instrumenting your code. That’s especially useful when instrumentation is hard (certain agent frameworks, black-box tooling, restricted environments, etc.).
If you want to set it up: OpenRouter Broadcast settings.
Vision Models Are Getting Practical (and Weirdly Competitive)
Vision‑language models quietly had a massive week.
Jina‑VLM: Small, Multilingual, and Very Good at Docs

Jina released a 2.4B VLM that’s absolutely dialed in on document understanding, multilingual VQA, and OCR‑heavy tasks. This is exactly the kind of model you’d want for PDFs, charts, scans, and messy real‑world docs — and it’s small enough to deploy without sweating too much.
Z.ai GLM‑4.6V: Long Context, Tool Calling, Serious Agent Potential

Z.ai’s GLM‑4.6V impressed us with its 128K context, native tool calling from vision inputs, and strong performance on benchmarks like MathVista and WebVoyager. It’s one of the clearest examples yet of a VLM that’s actually built for agentic workflows, not just answering questions about images.
That said, I did run my unofficial “bee counting test” on it… and yeah, Gemini still wins there 😅
Perceptron Isaac 0.2: Tiny Models, Serious Perception
Perceptron’s Isaac 0.2 (1B and 2B variants) showed something I really like seeing: structured outputs, focus tools, and reliability in very small models. Watching a 2B model correctly identify, count, and point to objects in an image is still wild to me.
These are the kinds of models that make physical AI, robotics, and edge deployments actually feasible.
🧰 Tools: Cursor goes visual, and Google Stitch keeps getting scarier (in a good way)
Cursor: direct visual editing inside the codebase
Cursor shipped a new feature that lets you visually manipulate UI elements—click/drag/resize—directly in the editor. We lumped this under “tools” because it’s not just a nicety; it’s the next step in “IDE as design surface.”
Cursor is also iterating fast on debugging workflows. The meta trend: IDEs are turning into agent platforms, not text editors.
Stitch by Google: Gemini 3 Pro as default, plus clickable prototypes
I showed Stitch on the show because it’s one of the clearest examples of “distribution beats raw capability.”

Stitch (Google’s product born from the Galileo AI acquisition) is doing Shipmas updates and now defaults to “Thinking with Gemini 3 Pro.” It can generate complex UIs, export them, and even stitch multiple screens into prototypes. The killer workflow is exporting directly into AI Studio / agent tooling so you can go from UI idea → code → repo without playing copy-paste Olympics.
Site:
https://stitch.withgoogle.com
🎬 Disney invests $1B into OpenAI (and Sora gets Disney characters)
This is the corporate story that made me do a double take.
Disney—arguably the most IP-protective company on Earth—is investing $1B into OpenAI and enabling use of Disney characters in Sora. That’s huge. It signals the beginning of a more explicit “licensed synthetic media” era, where major IP holders decide which model vendors get official access.
It also raises the obvious question: does Disney now go harder against other model providers that generate Disney-like content without permission?
We talked about how weird the timing is too, given Disney has also been sending legal pressure in the broader space. The next year of AI video is going to be shaped as much by licensing and distribution as by model quality.
Closing thoughts: the intelligence explosion is loud, messy, and accelerating
This episode had everything: open-source models catching up fast, foundation-level standardization around agents, a usage report that shows what developers actually do with LLMs, voice models getting dramatically better, and OpenAI shipping what looks like a serious “we’re not losing” answer to Gemini 3.
And yes: we’re also apparently putting GPUs in space.
Next week’s episode is our year recap, and—of course—we now have to update it because GPT‑5.2 decided to show up like the final boss.
If you missed any part of the show, check out the chapters in the podcast feed and jump around. See you next week.
TL;DR + Show Notes (links for everything)
Hosts
Alex Volkov — AI Evangelist @ Weights & Biases: @altryne. I host ThursdAI and spend an unhealthy amount of time trying to keep up with this firehose of releases.
Co-hosts — @WolframRvnwlf, @yampeleg, @nisten, @ldjconfirmed. Each of them brings a different “lens” (agents, infra, evaluation, open source, tooling), and it’s why the show works.
Open Source LLMs
Essential AI — RNJ‑1 (8B base + instruct): tweet, blog, HF instruct, HF base. This is a from-scratch open pretrain led by Ashish Vaswani, and it’s one of the most important “Western open model” signals we’ve seen in a while.
Mistral — Devstral 2 + Devstral Small 2 + Mistral Vibe: tweet, Devstral Small 2 HF, Devstral 2 HF, news, mistral-vibe GitHub. Devstral is open coding SOTA territory, and Vibe is Mistral’s swing at the CLI agent layer.
AI in Space
Starcloud trains and runs an LLM in orbit on an H100: Philip Johnston, Adi Oltean, CNBC, Karpathy reaction. A satellite H100 trained nanoGPT on Shakespeare and ran Gemma inference, igniting a real debate about power, cooling, repairability, and future orbital compute economics.
Putnam Math Competition
Nous Research — Nomos 1 (Putnam scoring run): tweet, HF, GitHub harness, Hillclimb. This is a strong open-weight math reasoning model plus an open harness, and it shows how orchestration matters as much as raw weights.
Axiom — AxiomProver formal Lean proofs on Putnam: tweet, repo. Formal proofs are the “no excuses” version of math reasoning, and this is a serious milestone even if you argue about exact framing.
Big Company LLMs + APIs
OpenAI — GPT‑5.2 release: Alex tweet, OpenAI announcement, ARC Prize verification, Sam Altman tweet. GPT‑5.2 brings major jumps in reasoning, long context, and agentic workflows, and it’s clearly positioned as an answer to the Gemini 3 era.
OpenRouter x a16z — State of AI report (100T+ tokens): tweet, landing page, PDF. The report highlights the dominance of programming/agents, the rise of reasoning tokens, and real-world usage patterns that explain why everyone is shipping agent harnesses.
Agentic AI Foundation under Linux Foundation (AAIF): Goose tweet, Block blog, aaif.io, Linux Foundation tweet. MCP + AGENTS.md + Goose moving into vendor-neutral governance is huge for interoperability and long-term ecosystem stability.
Disney invests $1B into OpenAI / Sora characters: (covered on the show as a major IP + distribution moment). This is an early signal of licensed synthetic media becoming a first-class business line rather than a legal gray zone.
This week’s Buzz (W&B)
OpenRouter Broadcast → W&B Weave tracing: Broadcast settings. You can trace OpenRouter-based traffic into Weave with minimal setup, which is especially useful when you can’t (or don’t want to) instrument code directly.
Vision & Video
Jina — jina‑VLM (2.4B): tweet, arXiv, HF, blog. A compact multilingual VLM optimized for doc understanding and VQA.
Z.ai — GLM‑4.6V + Flash: tweet, HF collection, GLM‑4.6V, Flash, blog. Strong open VLMs with tool calling and long context, even if my bee counting test still humbled it.
Perceptron — Isaac 0.2 (1B/2B): tweet, HF 2B, HF 1B, blog, demo. The Focus/zoom tooling and structured outputs point toward “VLMs as reliable perception modules,” not just chatty describers.
Voice & Audio
Google DeepMind — Gemini 2.5 TTS (Flash + Pro): AI Studio tweet, GoogleAI devs tweet, blog, AI Studio speech playground. The key upgrades are control and consistency (emotion, pacing, multi-speaker) across many languages.
OpenBMB — VoxCPM 1.5: tweet, HF, GitHub. Open TTS keeps getting better, and this release is especially interesting for fine-tuning and voice cloning workflows.
Tools
Cursor — direct visual editing (new UI workflow): (covered on the show as a major step toward “IDE as design surface”). Cursor continues to push the agentic IDE category into new territory.
Stitch by Google — Shipmas updates + Gemini 3 Pro “Thinking” + Prototypes: tweet 1, tweet 2, site, plus background articles: TechCrunch launch, acquisition detail. Stitch is turning prompt-to-UI into a full prototype-to-code pipeline with real export paths.


