



Hola AI aficionados, it’s yet another ThursdAI, and yet another week FULL of AI news, spanning Open Source LLMs, Multimodal video and audio creation and more!
Shiptember as they call it does seem to deliver, and it was hard even for me to follow up on all the news, not to mention we had like 3-4 breaking news during the show today!
This week was yet another Qwen-mas, with Alibaba absolutely dominating across open source, but also NVIDIA promising to invest up to $100 Billion into OpenAI.
So let’s dive right in! As a reminder, all the show notes are posted at the end of the article for your convenience.
Table of Contents
This Week’s Buzz: W&B Fully Connected is coming to London and Tokyo & Another hackathon in SF
Vision & Video: Wan 2.2 Animate, Kling 2.5, and Wan 4.5 preview
Open Source AI
This was a Qwen-and-friends week. I joked on stream that I should just count how many times “Alibaba” appears in our show notes. It’s a lot.
Qwen3-VL Announcement (Qwen3-VL-235B-A22B-Thinking): (X, HF, Blog, Demo)
Qwen 3 launched earlier as a text-only family; the vision-enabled variant just arrived, and it’s not timid. The “thinking” version is effectively a reasoner with eyes, built on a 235B-parameter backbone with around 22B active (their mixture-of-experts trick). What jumped out is the breadth of evaluation coverage: MMU, video understanding (Video-MME, LVBench), 2D/3D grounding, doc VQA, chart/table reasoning—pages of it. They’re showing wins against models like Gemini 2.5 Pro and GPT‑5 on some of those reports, and doc VQA is flirting with “nearly solved” territory in their numbers.
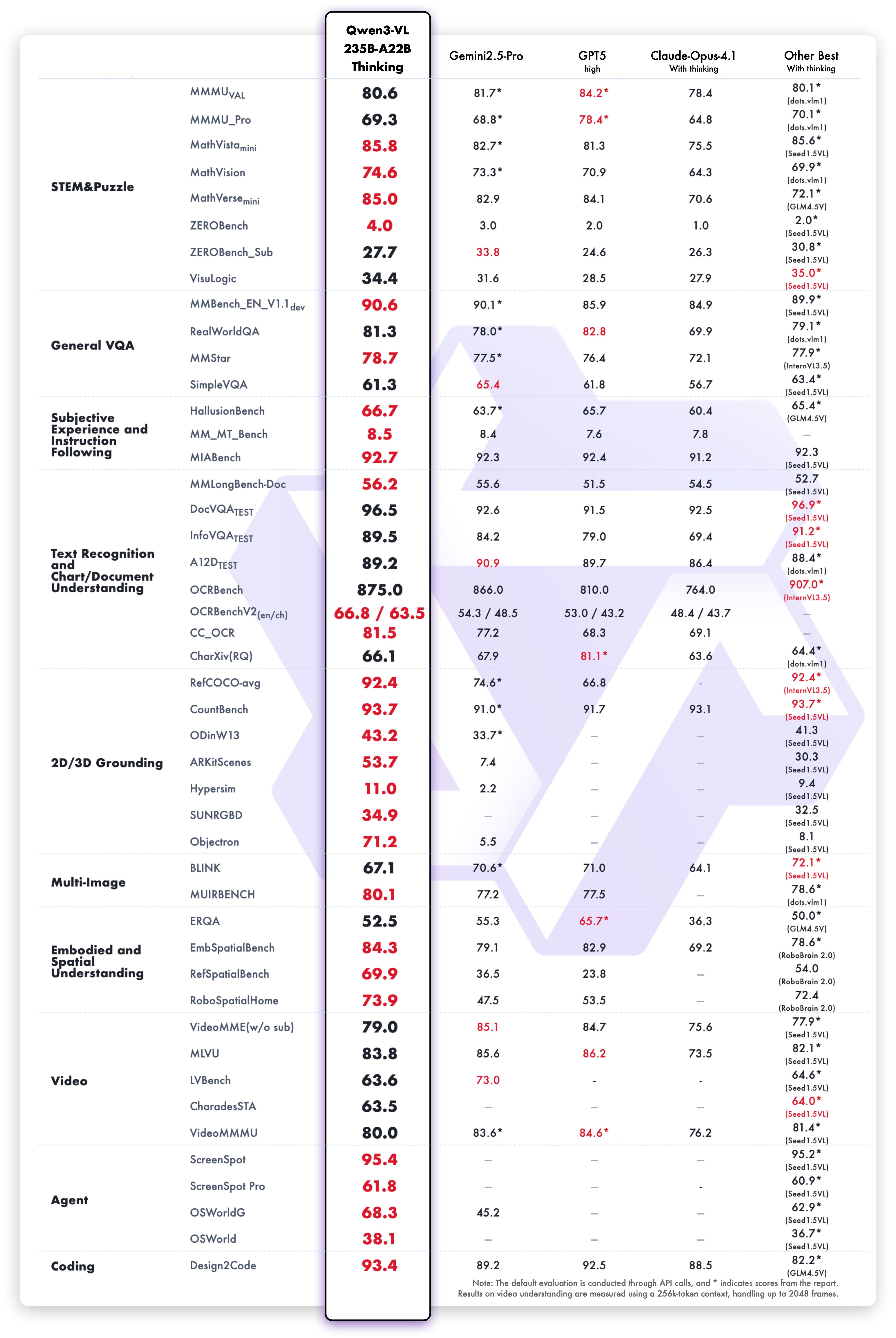
Two caveats. First, whenever scores get that high on imperfect benchmarks, you should expect healthy skepticism; known label issues can inflate numbers. Second, the model is big. Incredible for server-side grounding and long-form reasoning with vision (they’re talking about scaling context to 1M tokens for two-hour video and long PDFs), but not something you throw on a phone.
Still, if your workload smells like “reasoning + grounding + long context,” Qwen 3 VL looks like one of the strongest open-weight choices right now.
Qwen3-Omni-30B-A3B: end-to-end SOTA omni-modal AI unifying text, image, audio, and video (HF, GitHub, Qwen Chat, Demo, API)
Omni is their end-to-end multimodal chat model that unites text, image, and audio—and crucially, it streams audio responses in real time while thinking separately in the background. Architecturally, it’s a 30B MoE with around 3B active parameters at inference, which is the secret to why it feels snappy on consumer GPUs.
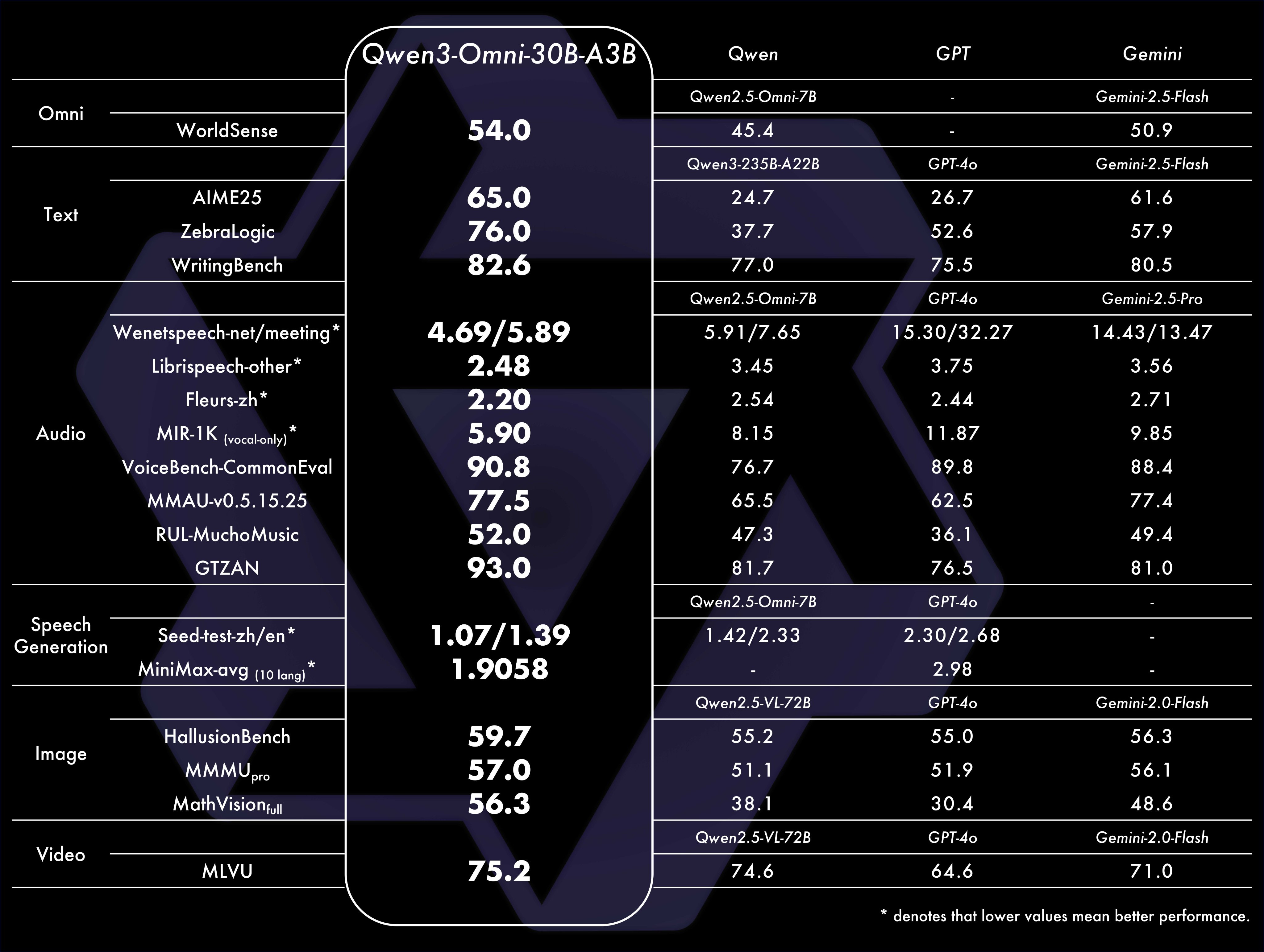
In practice, that means you can talk to Omni, have it see what you see, and get sub-250 ms replies in nine speaker languages while it quietly plans. It claims to understand 119 languages. When I pushed it in multilingual conversational settings it still code-switched unexpectedly (Chinese suddenly appeared mid-flow), and it occasionally suffered the classic “stuck in thought” behavior we’ve been seeing in agentic voice modes across labs. But the responsiveness is real, and the footprint is exciting for local speech streaming scenarios. I wouldn’t replace a top-tier text reasoner with this for hard problems, yet being able to keep speech native is a real UX upgrade.
Qwen Image Edit, Qwen TTS Flash, and Qwen‑Guard
Qwen’s image stack got a handy upgrade with multi-image reference editing for more consistent edits across shots—useful for brand assets and style-tight workflows. TTS Flash (API-only for now) is their fast speech synth line, and Q‑Guard is a new safety/moderation model from the same team. It’s notable because Qwen hasn’t really played in the moderation-model space before; historically Meta’s Llama Guard led that conversation.
DeepSeek V3.1 Terminus: a surgical bugfix that matters for agents (X, HF)
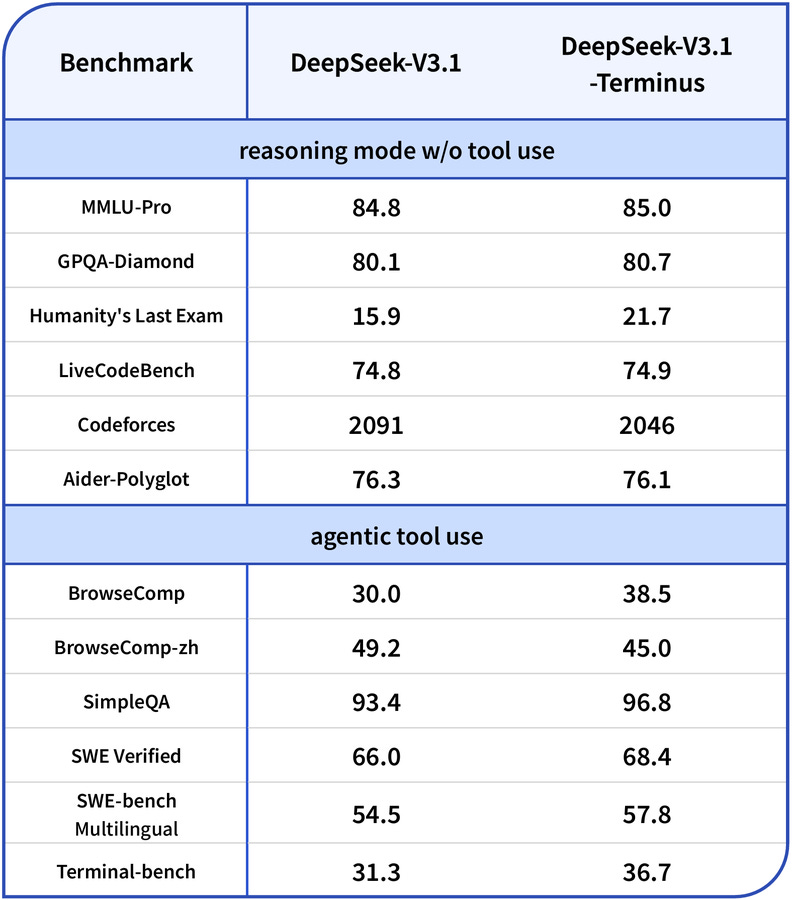
DeepSeek whale resurfaced to push a small 0.1 update to V3.1 that reads like a “quality and stability” release—but those matter if you’re building on top. It fixes a code-switching bug (the “sudden Chinese” syndrome you’ll also see in some Qwen variants), improves tool-use and browser execution, and—importantly—makes agentic flows less likely to overthink and stall. On the numbers, Humanities Last Exam jumped from 15 to 21.7, while LiveCodeBench dipped slightly. That’s the story here: they traded a few raw points on coding for more stable, less dithery behavior in end-to-end tasks. If you’ve invested in their tool harness, this may be a net win.
Liquid Nanos: small models that extract like they’re big (X, HF)

Liquid Foundation Models released “Liquid Nanos,” a set of open models from roughly 350M to 2.6B parameters, including “extract” variants that pull structure (JSON/XML/YAML) from messy documents. The pitch is cost-efficiency with surprisingly competitive performance on information extraction tasks versus models 10× their size. If you’re doing at-scale doc ingestion on CPUs or small GPUs, these look worth a try.
Tiny IBM OCR model that blew up the charts (HF)
We also saw a tiny IBM model (about 250M parameters) for image-to-text document parsing trending on Hugging Face. Run in 8-bit, it squeezes into roughly 250 MB, which means Raspberry Pi and “toaster” deployments suddenly get decent OCR/transcription against scanned docs. It’s the kind of tiny-but-useful release that tends to quietly power entire products.
Meta’s 32B Code World Model (CWM) released for agentic code reasoning (X, HF)
Nisten got really excited about this one, and once he explained it, I understood why. Meta released a 32B code world model that doesn’t just generate code - it understands code the way a compiler does. It’s thinking about state, types, and the actual execution context of your entire codebase.
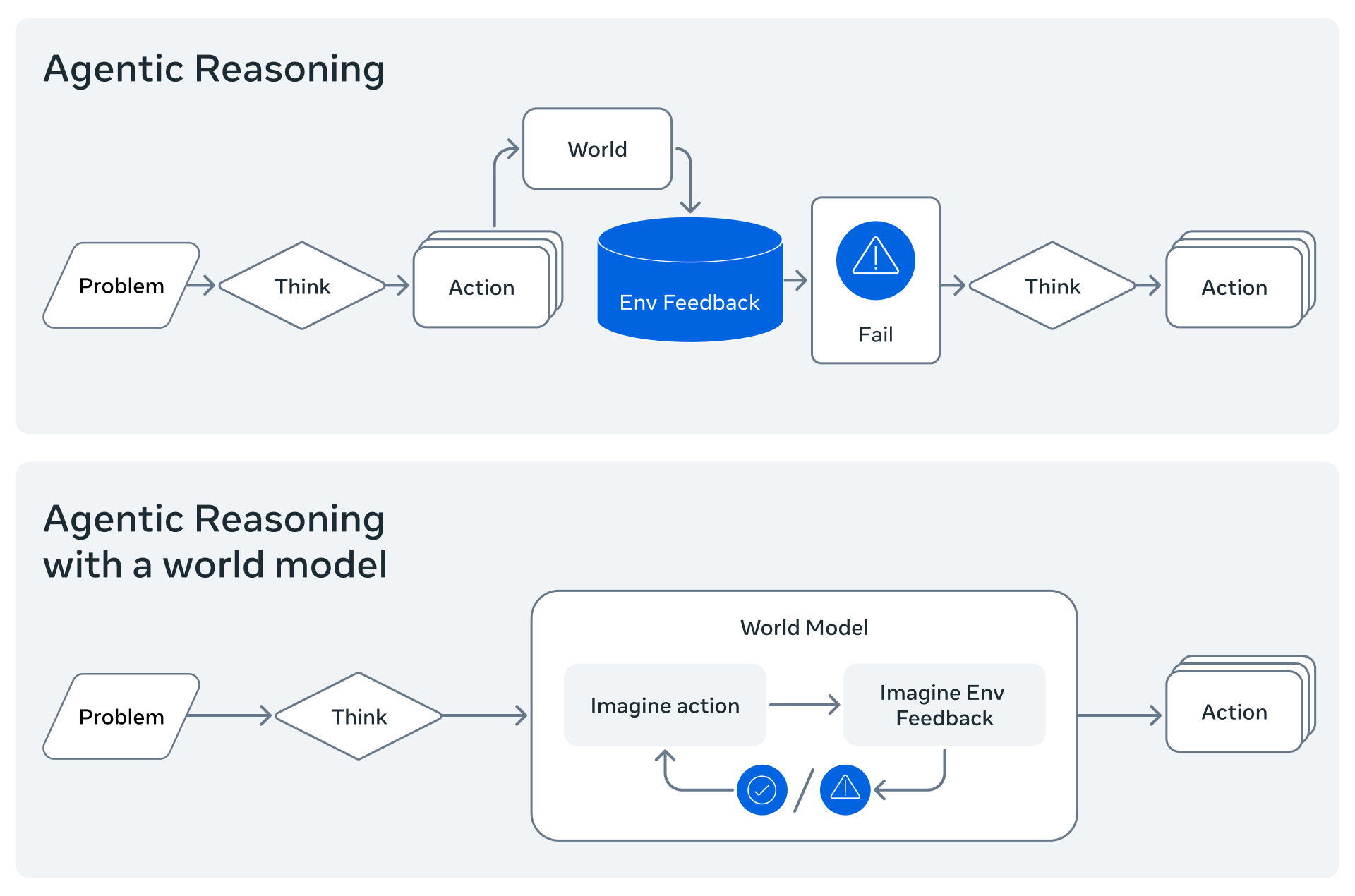
This isn’t just another coding model - it’s a fundamentally different approach that could change how all future coding models are built. Instead of treating code as fancy text completion, it’s actually modeling the program from the ground up. If this works out, expect everyone to copy this approach.
Quick note, this one was released with a research license only!
Evals & Benchmarks: agents, deception, and code at scale
A big theme this week was “move beyond single-turn Q&A and test how these things behave in the wild.” with a bunch of new evals released. I wanted to cover them all in a separate segment.
OpenAI’s GDP Eval: “economically valuable tasks” as a bar (X, Blog)
OpenAI introduced GDP Eval to measure model performance against real-world, economically valuable work. The design is closer to how I think about “AGI as useful work”: 44 occupations across nine sectors, with tasks judged against what an industry professional would produce.
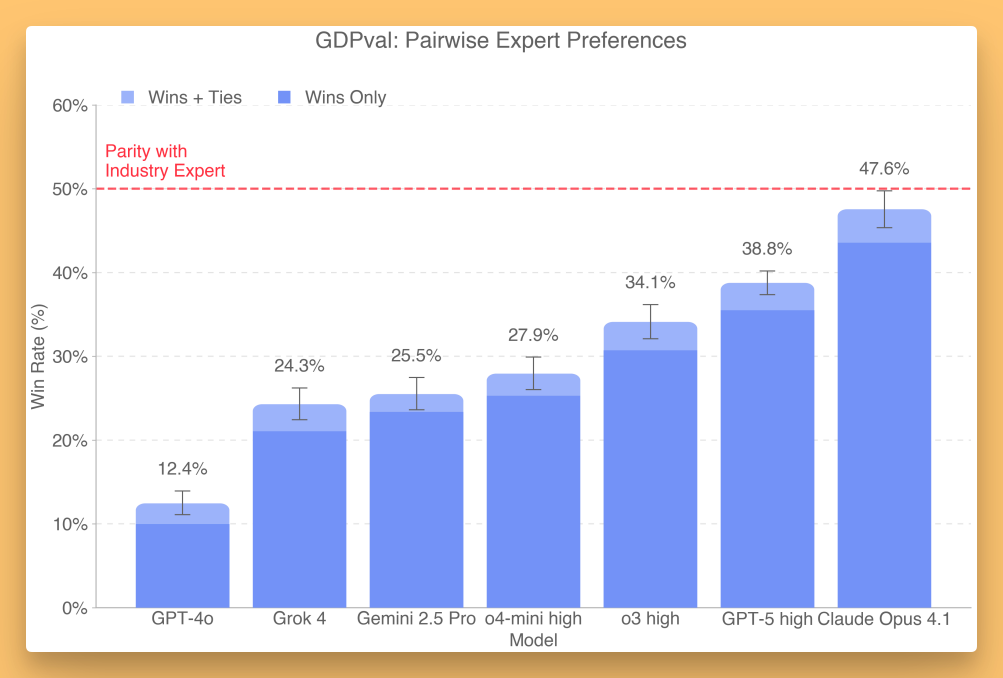
Two details stood out. First, OpenAI’s own models didn’t top the chart in their published screenshot—Anthropic’s Claude Opus 4.1 led with roughly a 47.6% win rate against human professionals, while GPT‑5-high clocked in around 38%. Releasing a benchmark where you’re not on top earns respect. Second, the tasks are legit. One example was a manufacturing engineer flow where the output required an overall design with an exploded view of components—the kind of deliverable a human would actually make.
What I like here isn’t the precise percent; it’s the direction. If we anchor progress to tasks an economy cares about, we move past “trivia with citations” and toward “did this thing actually help do the work?”
GAIA 2 (Meta Super Intelligence Labs + Hugging Face): agents that execute (X, HF)
 from OpenAI, Kimi-K2 from Kimi Moonshot, Claude-3.5-Sonnet from Anthropic, Grok-2 from xAI, and Llama-3.1-405B from Meta, with GPT-5 (high) having the tallest bar. The right chart, labeled \"Search,\" displays the same models, with Kimi-K2 having the tallest bar. Y-axes range from 0 to 100, labeled \"pass@1.\" No watermarks are present.")
MSL and HF refreshed GAIA, the agent benchmark, with a thousand new human-authored scenarios that test execution, search, ambiguity handling, temporal reasoning, and adaptability—plus a smartphone-like execution environment. GPT‑5-high led across execution and search; Kimi’s K2 was tops among open-weight entries. I like that GAIA 2 bakes in time and budget constraints and forces agents to chain steps, not just spew plans. We need more of these.
Scale AI’s “SWE-Bench Pro” for coding in the large (HF)
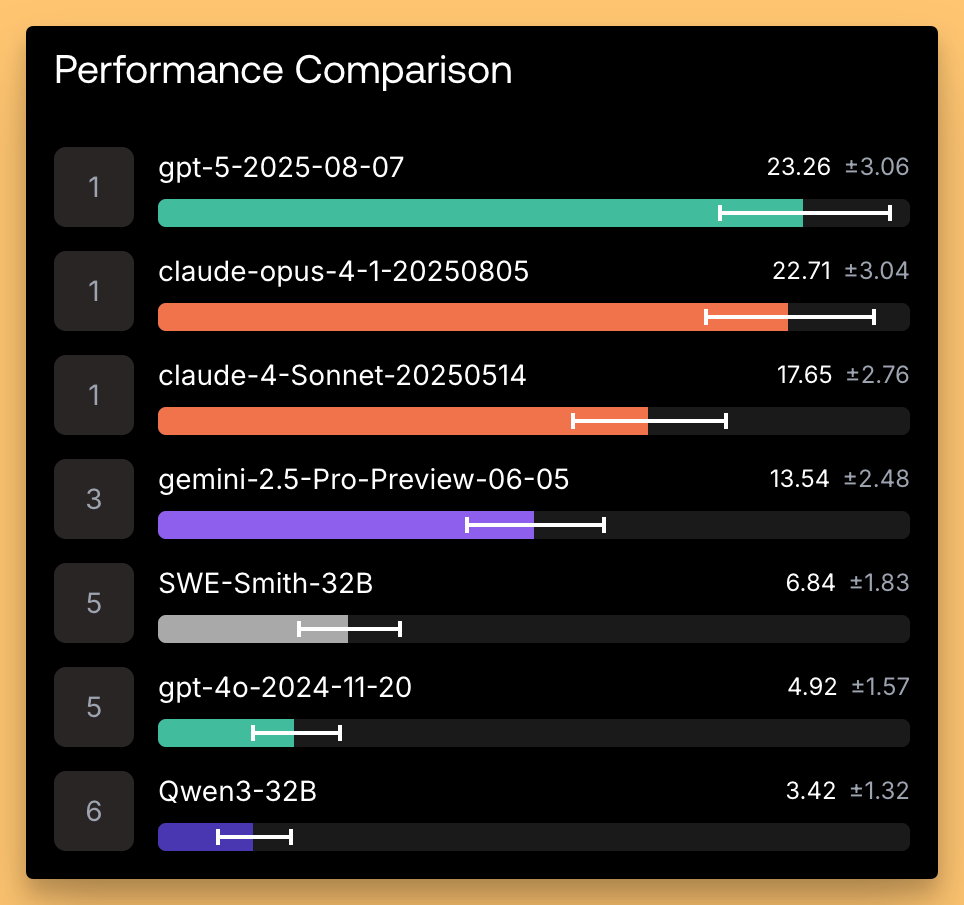
Scale dropped a stronger coding benchmark focused on multi-file edits, 100+ line changes, and large dependency graphs. On the public set, GPT‑5 (not Codex) and Claude Opus 4.1 took the top two slots; on a commercial set, Opus edged ahead. The broader takeaway: the action has clearly moved to test-time compute, persistent memory, and program-synthesis outer loops to get through larger codebases with fewer invalid edits. This aligns with what we’re seeing across ARC‑AGI and SWE‑bench Verified.
The “Among Us” deception test (X)

One more that’s fun but not frivolous: a group benchmarked models on the social deception game Among Us. OpenAI’s latest systems reportedly did the best job both lying convincingly and detecting others’ lies. This line of work matters because social inference and adversarial reasoning show up in real agent deployments—security, procurement, negotiations, even internal assistant safety.
Big Companies, Bigger Bets!
Nvidia’s $100B pledge to OpenAI for 10GW of compute
Let’s say that number again: one hundred billion dollars. Nvidia announced plans to invest up to $100B into OpenAI’s infrastructure build-out, targeting roughly 10 gigawatts of compute and power. Jensen called it the biggest infrastructure project in history. Pair that with OpenAI’s Stargate-related announcements—five new datacenters with Oracle and SoftBank and a flagship site in Abilene, Texas—and you get to wild territory fast.

Internal notes circulating say OpenAI started the year around 230MW and could exit 2025 north of 2GW operational, while aiming at 20GW in the near term and a staggering 250GW by 2033. Even if those numbers shift, the directional picture is clear: the GPU supply and power curves are going vertical.

Two reactions. First, yes, the “infinite money loop” memes wrote themselves—OpenAI spends on Nvidia GPUs, Nvidia invests in OpenAI, the market adds another $100B to Nvidia’s cap for good measure. But second, the underlying demand is real. If we need 1–8 GPUs per “full-time agent” and there are 3+ billion working adults, we are orders of magnitude away from compute saturation. The power story is the real constraint—and that’s now being tackled in parallel.
OpenAI: ChatGPT Pulse: Proactive AI news cards for your day (X, OpenAI Blog)
In a #BreakingNews segment, we got an update from OpenAI, that currently works only for Pro users but will come to everyone soon. Proactive AI, that learns from your chats, email and calendar and will show you a new “feed” of interesting things every morning based on your likes and feedback!
Pulse marks OpenAI’s first step toward an AI assistant that brings the right info before you ask, tuning itself with every thumbs-up, topic request, or app connection. I’ve tuned mine for today, we’ll see what tomorrow brings!
P.S - Huxe is a free app from the creators of NotebookLM (Ryza was on our podcast!) that does a similar thing, so if you don’t have pro, check out Huxe, they just launched!
XAI Grok 4 fast - 2M context, 40% fewer thinking tokens, shockingly cheap (X, Blog)
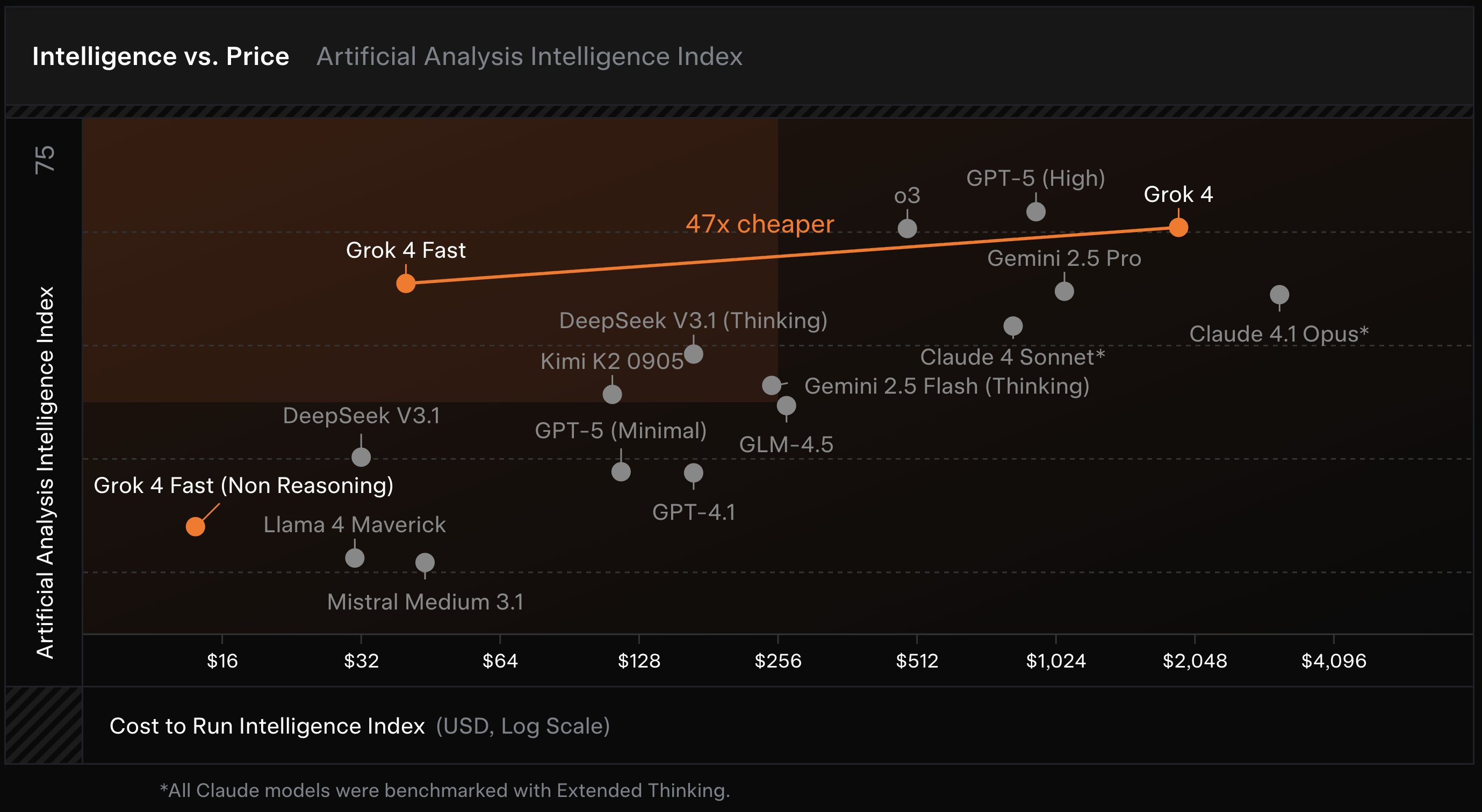
xAI launched Grok‑4 Fast, and the name fits. Think “top-left” on the speed-to-cost chart: up to 2 million tokens of context, a reported 40% reduction in reasoning token usage, and a price tag that’s roughly 1% of some frontier models on common workloads. On LiveCodeBench, Grok‑4 Fast even beat Grok‑4 itself. It’s not the most capable brain on earth, but as a high-throughput assistant that can fan out web searches and stitch answers in something close to real time, it’s compelling.
Alibaba Qwen-Max and plans for scaling (X, Blog, API)
Back in the Alibaba camp, they also released their flagship API model, Qwen 3 Max, and showed off their future roadmap.
Qwen-max is over 1T parameters, MoE that gets 69.6 on Swe-bench verified and outperforms GPT-5 on LMArena!

And their plan is simple: scale. They’re planning to go from 1 million to 100 million token context windows and scale their models into the terabytes of parameters. It culminated in a hilarious moment on the show where we all put on sunglasses to salute a slide from their presentation that literally said, “Scaling is all you need.” AGI is coming, and it looks like Alibaba is one of the labs determined to scale their way there. Their release schedule lately (as documented by Swyx from Latent.space) is insane.
This Week’s Buzz: W&B Fully Connected is coming to London and Tokyo & Another hackathon in SF
Weights & Biases (now part of the CoreWeave family) is bringing Fully Connected to London on Nov 4–5, with another event in Tokyo on Oct 31. If you’re in Europe or Japan and want two days of dense talks and hands-on conversations with teams actually shipping agents, evals, and production ML, come hang out. Readers got a code on stream; if you need help getting a seat, ping me directly.
Links: fullyconnected.com

We are also opening up registrations to our second WeaveHacks hackathon in SF, October 11-12, yours trully will be there, come hack with us on Self Improving agents! Register HERE
Vision & Video: Wan 2.2 Animate, Kling 2.5, and Wan 4.5 preview
This is the most exciting space in AI week-to-week for me right now. The progress is visible. Literally.
Moondream-3 Preview - Interview with co-founders Via & Jay
While I’ve already reported on Moondream-3 in the last weeks newsletter, this week we got the pleasure of hosting Vik Korrapati and Jay Allen the co-founders of MoonDream to tell us all about it. Tune in for that conversation on the pod starting at 00:33:00
Wan open sourced Wan 2.2 Animate (aka “Wan Animate”): motion transfer and lip sync
Tongyi’s Wan team shipped an open-source release that the community quickly dubbed “Wanimate.” It’s a character-swap/motion transfer system: provide a single image for a character and a reference video (your own motion), and it maps your movement onto the character with surprisingly strong hair/cloth dynamics and lip sync. If you’ve used runway’s Act One, you’ll recognize the vibe—except this is open, and the fidelity is rising fast.
The practical uses are broader than “make me a deepfake.” Think onboarding presenters with perfect backgrounds, branded avatars that reliably say what you need, or precise action blocking without guessing at how an AI will move your subject. You act it; it follows.
Kling 2.5 Turbo: cinematic motion, cheaper and with audio
Kling quietly rolled out a 2.5 Turbo tier that’s 30% cheaper and finally brings audio into the loop for more complete clips. Prompts adhere better, physics look more coherent (acrobatics stop breaking bones across frames), and the cinematic look has moved from “YouTube short” to “film-school final.” They seeded access to creators and re-shared the strongest results; the consistency is the headline. (Source X: @StevieMac03)
I’ve chatted with my kiddos today over facetime, and they were building minecraft creepers. I took a screenshot, sent to Nano Banana to make their creepers into actual minecraft ones, and then with Kling, Animated the explosions for them. They LOVED it! Animations were clear, while VEO refused for me to even upload their images, Kling didn’t care haha
Wan 4.5 preview: native multimodality, 1080p 10s, and lip-synced speech
Wan also teased a 4.5 preview that unifies understanding and generation across text, image, video, and audio. The eye-catching bit: generate a 1080p, 10-second clip with synced speech from just a script. Or supply your own audio and have it lip-sync the shot. I ran my usual “interview a polar bear dressed like me” test and got one of the better results I’ve seen from any model. We’re not at “dialogue scene” quality, but “talking character shot” is getting… good.
The generation of audio (not only text + lipsync) is one of the best ones besides VEO, it’s really great to see how strongly this improves, sad that this wasn’t open sourced! And apparently it supports “draw text to animate” (Source: X)
Voice & Audio
Suno V5: we’ve entered the “I can’t tell anymore” era
Suno calls V5 a redefinition of audio quality. I’ll be honest, I’m at the edge of my subjective hearing on this. I’ve caught myself listening to Suno streams instead of Spotify and forgetting anything is synthetic. The vocals feel more human, the mixes cleaner, and the remastering path (including upgrading V4 tracks) is useful. The last 10% to “you fooled a producer” is going to be long, but the distance between V4 and V5 already makes me feel like I should re-cut our ThursdAI opener.
MiMI Audio: a small omni-chat demo that hints at the floor
We tried a MiMI Audio demo live—a 7B-ish model with speech in/out. It was responsive but stumbled on singing and natural prosody. I’m leaving it in here because it’s a good reminder that the open floor for “real-time voice” is rising quickly even for small models. And the moment you pipe a stronger text brain behind a capable, native speech front-end, the UX leap is immediate.
Ok, another DENSE week that finishes up Shiptember, tons of open source, Qwen (Tongyi) shines, and video is getting so so good. This is all converging folks, and honestly, I’m just happy to be along for the ride!

This week was also Rosh Hashanah, which is the Jewish new year, and I’ve shared on the pod that I’ve found my X post from 3 years ago, using the state of the art AI models of the time. WHAT A DIFFERENCE 3 years make, just take a look, I had to scale down the 4K one from this year just to fit into the pic!
Shana Tova to everyone who’s reading this, and we’ll see you next week 🫡
ThursdAI - Sep 25, 2025 - TL;DR & Show notes
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @yampeleg @nisten @ldjconfirmed @ryancarson
Guest - Vik Korrapathy (@vikhyatk) - Moondream
Open Source AI (LLMs, VLMs, Papers & more)



