



Hey ya’ll, Happy Thanskgiving to everyone who celebrates and thank you for being a subscriber, I truly appreciate each and every one of you!

Just wrapped up the third (1, 2) Thanksgiving special Episode of ThursdAI, can you believe November is almost over?
We had another banger week in AI, with a full feast of AI released, Anthropic dropped the long awaited Opus 4.5, which quickly became the top coding LLM, DeepSeek resurfaced with a math model, BFL and Tongyi both tried to take on Nano Banana, and Microsoft dropped a 7B computer use model in Open Source + Intellect 3 from Prime Intellect!
With so much news to cover, we also had an interview with Ido Sal & Liad Yosef (their second time on the show!) about MCP-Apps, the new standard they are spearheading together with Anthropic, OpenAI & more!
Exciting episode, let’s get into it! (P.S - I started generating infographics, so the show became much more visual, LMK if you like them)
Anthropic’s Opus 4.5: The “Premier Intelligence” Returns (Blog)

Folks, Anthropic absolutely cooked. After Sonnet and Haiku had their time in the sun, the big brother is finally back. Opus 4.5 launched this week, and it is reclaiming the throne for coding and complex agentic tasks.
First off, the specs are monstrous. It hits 80.9% on SWE-bench Verified, topping GPT-5.1 (77.9%) and Gemini 3 Pro (76.2%). But the real kicker? The price! It is now $5 per million input tokens and $25 per million output—literally one-third the cost of the previous Opus.
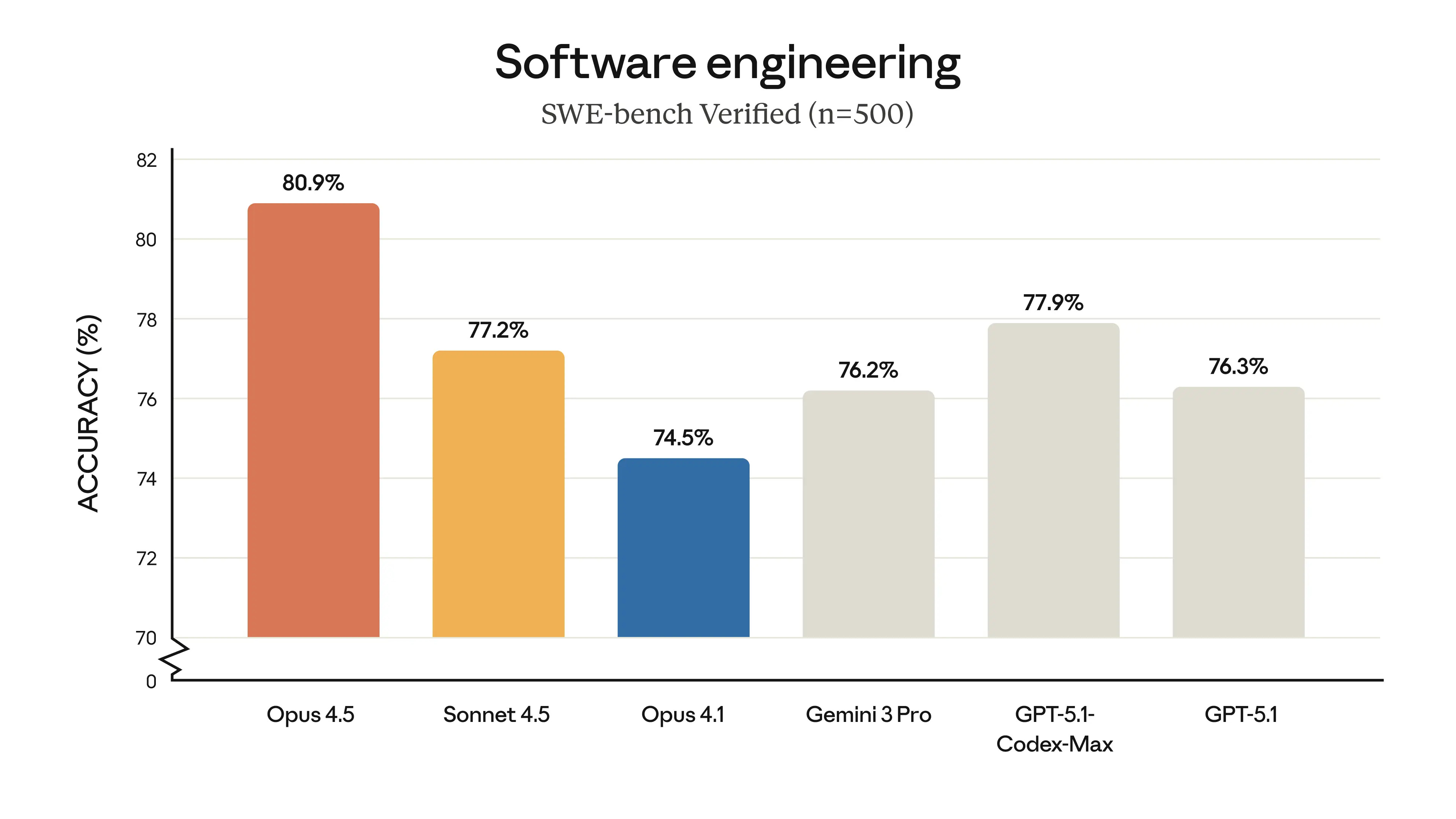
Yam, our resident coding wizard, put it best during the show: “Opus knows a lot of tiny details about the stack that you didn’t even know you wanted... It feels like it can go forever.” Unlike Sonnet, which sometimes spirals or loses context on extremely long tasks, Opus 4.5 maintains coherence deep into the conversation.
Anthropic also introduced a new “Effort” parameter, allowing you to control how hard the model thinks (similar to o1 reasoning tokens). Set it to high, and you get massive performance gains; set it to medium, and you get Sonnet-level performance at a fraction of the token cost. Plus, they’ve added Tool Search (cutting enormous token overhead for agents with many tools) and Programmatic Tool Calling, which effectively lets Opus write and execute code loops to manage data.
If you are doing heavy software engineering or complex automations, Opus 4.5 is the new daily driver.
📱 The Agentic Web: MCP Apps & MCP-UI Standard

Speaking of MCP updates, Can you believe it’s been exactly one year since the Model Context Protocol (MCP) launched? We’ve been “MCP-pilled” for a while, but this week, the ecosystem took a massive leap forward.
We brought back our friends Ido and Liad, the creators of MCP-UI, to discuss huge news: MCP-UI has been officially standardized as MCP Apps. This is a joint effort adopted by both Anthropic and OpenAI.
Why does this matter? Until now, when an LLM used a tool (like Spotify or Zillow), the output was just text. It lost the brand identity and the user experience. With MCP Apps, agents can now render full, interactive HTML interfaces directly inside the chat!
Ido and Liad explained that they worked hard to avoid an “iOS vs. Android” fragmentation war. Instead of every lab building their own proprietary app format, we now have a unified standard for the “Agentic Web.” This is how AI stops being a chatbot and starts being an operating system.
Check out the standard at mcpui.dev.
🦃 The Open Source Thanksgiving Feast
While the big labs were busy, the open-source community decided to drop enough papers and weights to feed us for a month.
Prime Intellect unveils INTELLECT-3, a 106B MoE (X, HF, Blog, Try It)
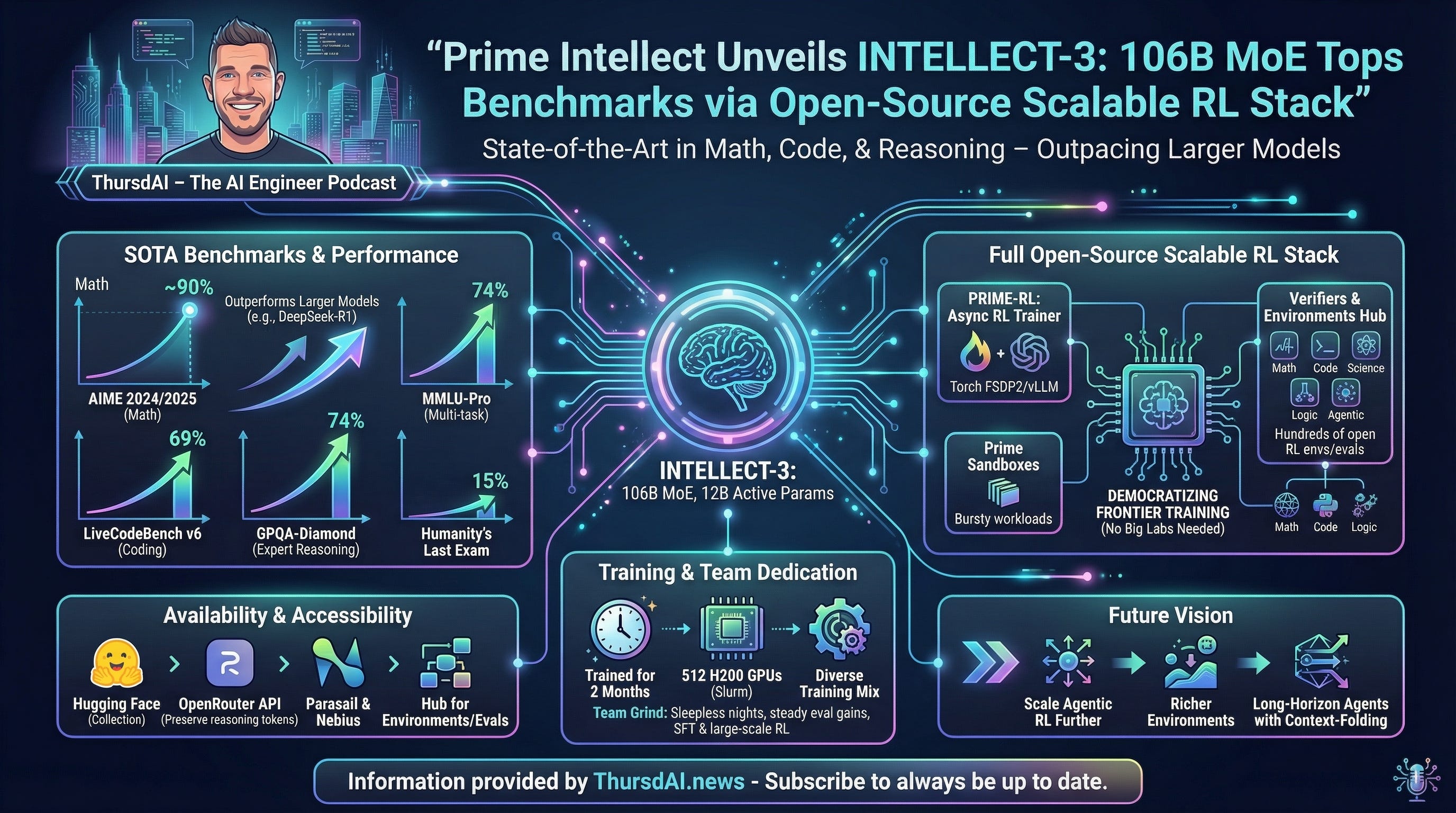
Prime Intellect releases INTELLECT-3, a 106B parameter Mixture-of-Experts model (12B active params) based on GLM-4.5-Air, achieving state-of-the-art performance for its size—including ~90% on AIME 2024/2025 math contests, 69% on LiveCodeBench v6 coding, 74% on GPQA-Diamond reasoning, and 74% on MMLU-Pro—outpacing larger models like DeepSeek-R1.
Trained over two months on 512 H200 GPUs using their fully open-sourced end-to-end stack (PRIME-RL async trainer, Verifiers & Environments Hub, Prime Sandboxes), it’s now hosted on Hugging Face, OpenRouter, Parasail, and Nebius, empowering any team to scale frontier RL without big-lab resources. Especially notable is their very detailed release blog, covering how a lab that previously trained 32B, finetunes a monster 106B MoE model!
Tencent’s HunyuanOCR: Small but Mighty (X, HF, Github, Blog)

Tencent released HunyuanOCR, a 1 billion parameter model that is absolutely crushing benchmarks. It scored 860 on OCRBench, beating massive models like Qwen3-VL-72B. It’s an end-to-end model, meaning no separate detection and recognition steps. Great for parsing PDFs, docs, and even video subtitles. It’s heavily restricted (no EU/UK usage), but technically impressive.
Microsoft’s Fara-7B: On-Device Computer Use

Microsoft quietly dropped Fara-7B, a model fine-tuned from Qwen 2.5, specifically designed for computer use agentic tasks. It hits 73.5% on WebVoyager, beating OpenAI’s preview models, all while running locally on-device. This is the dream of a local agent that can browse the web for you, click buttons, and book flights without sending screenshots to the cloud.
DeepSeek-Math-V2: open-weights IMO-gold math LLM (X, HF)
DeepSeek-Math-V2 is a 685B-parameter, Apache-2.0 licensed, open-weights mathematical reasoning model claiming gold-medal performance on IMO 2025 and CMO 2024, plus a near-perfect 118/120 on Putnam 2024.
Nisten did note some limitations—specifically that the context window can get choked up on extremely long, complex proofs—but having an open-weight model of this caliber is a gift to researchers everywhere.
🐝 This Week’s Buzz: Serverless LoRA Inference

A huge update from us at Weights & Biases! We know fine-tuning is powerful, but serving those fine-tunes can be a pain and expensive. We just launched Serverless LoRA Inference.
This means you can upload your small LoRA adapters (which you can train cheaply) to W&B Artifacts, and we will serve them instantly on CoreWeave GPUs on top of a base model. No cold starts, no dedicated expensive massive GPU instances for just one adapter.
I showed a demo of a “Mocking SpongeBob” model I trained in 25 minutes. It just adds that SaRcAsTiC tExT style to the Qwen 2.5 base model. You pass the adapter ID in the API call, and boom—customized intelligence instantly. You can get more details HERE and get started with your own LORA in this nice notebook the team made!
🎨 Visuals: Image & Video Generation Explosion
Flux.2: The Multi-Reference Image Creator from BFL (X, HF, Blog)

Black Forest Labs released Flux.2, a series of models including a 32B Flux 2[DEV]. The killer feature here is Multi-Reference Editing. You can feed it up to 10 reference images to maintain character consistency, style, or specific objects. It also outputs native 4-megapixel images.
Honestly, the launch timing was rough, coming right after Google’s Nano Banana Pro and alongside Z-Image, but for precise, high-res editing, this is a serious tool.
Tongyi drops Z-Image Turbo: 6B single-stream DiT lands sub‑second, 8‑step text‑to‑image (GitHub, Hugging Face)

Alibaba’s Tongyi Lab released Z-Image Turbo, a 6B parameter model that generates images in sub-second time on H800s (and super fast on consumer cards).
I built a demo to show just how fast this is. You know that “Infinite Craft“ game? I hooked it up to Z-Image Turbo so that every time you combine elements (like Pirate + Ghost), it instantly generates the image for “Ghost Pirate.” It changes the game completely when generation is this cheap and fast.
HunyuanVideo 1.5 – open video gets very real
Tencent also shipped HunyuanVideo 1.5, which they market as “the strongest open‑source video generation model.” For once, the tagline isn’t entirely hype.
Under the hood it’s an 8.3B‑parameter Diffusion Transformer (DiT) model with a 3D causal VAE in front. The VAE compresses videos aggressively in both space and time, and the DiT backbone models that latent sequence.
The important bits for you and me:
It generates 5–10 second clips at 480p/720p with good motion coherence and physics.
With FP16 or FP8 configs you can run it on a single consumer GPU with around 14GB VRAM.
There’s a built‑in path to upsample to 1080p for “real” quality.
LTX Studio Retake: Photoshop for Video (X, Try It)
For the video creators, LTX Studio launched Retake. This isn’t just “regenerate video.” This allows you to select a specific 2-second segment of a video, change the dialogue (keeping the voice!), change the emotion, or edit the action, all for like $0.10. It blends it perfectly back into the original clip. We are effectively getting a “Director Mode” for AI video where you can fix mistakes without rolling the dice on a whole new generation.
A secret new model on the Arena called Whisper Thunder beats even Veo 3?
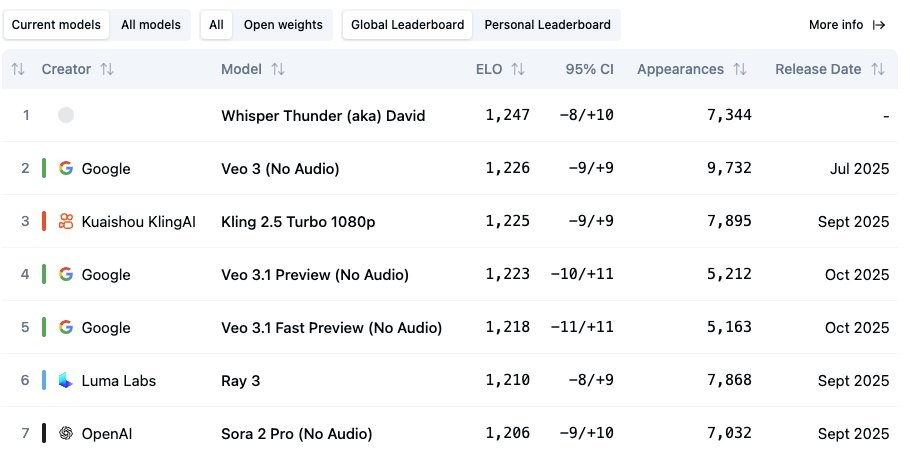
This was a surprise of the week, while new video models get released often, Veo 3 has been the top one for a while, and now we’re getting a reshuffling of the video giants! But... we don’t yet know who this video model is from! You can sometimes get its generations at the Artificial Analysis video arena here, and the outputs look quite awesome!
Thanksgiving reflections from the ThursdAI team
As we wrapped up the show, Wolfram suggested we take a moment to think about what we’re thankful for in AI, and I think that’s a perfect note to end on.
Wolfram put it well: he’s thankful for everyone contributing to this wonderful community—the people releasing models, creating open source tools, writing tutorials, sharing knowledge. It’s not just about the money; it’s about the love of learning and building together.

Yam highlighted something I think is crucial: we’ve reached a point where there’s no real competition between open source and closed source anymore. Everything is moving forward together. Even if you think nobody’s looking at that random code you posted somewhere, chances are someone found it and used it to accelerate their own work. That collective effort is what’s driving this incredible pace of progress.
For me, I want to thank Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez, Łukasz Kaiser, and Ilya Polosukhin for the 2017 paper “Attention Is All You Need.” Half Joking! But without the seminal attention is you need paper none of this AI was possible. But mostly I want to thank all of you—the audience, the co-hosts, the guests—for making ThursdAI what it is.
If you go back and watch our 2024 Thanksgiving episode, or the one from 2023, you’ll be shocked at how far we’ve come. Tools that seemed magical a year ago are now just... normal. That’s hedonic adaptation at work, but it’s also a reminder to stay humble and appreciate just how incredible this moment in history really is.
We’re living through the early days of a technological revolution, and we get to document it, experiment with it, and help shape where it goes. That’s something to be genuinely thankful for.
TL;DR and Show Notes
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co-Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed
Guests: @idosal1 @liadyosef - MCP-UI/MCP Apps
Big CO LLMs + APIs
Anthropic launches Claude Opus 4.5 - world’s top model for coding, agents, and tool use (X, Announcement, Blog)
OpenAI Integrates ChatGPT Voice Mode Directly into Chats (X)
Open Source LLMs
Interview: MCP Apps
MCP-UI standardized as MCP Apps by Anthropic and OpenAI (X, Blog, Announcement)
Vision & Video
AI Art & Diffusion
This Week’s Buzz


