






Hey folks, Alex here.
Can you believe it’s already the middle of October? This week’s show was a special one, not just because of the mind-blowing news, but because we set a new ThursdAI record with four incredible interviews back-to-back!
We had Jessica Gallegos from Google DeepMind walking us through the cinematic new features in VEO 3.1. Then we dove deep into the world of Reinforcement Learning with my new colleague Kyle Corbitt from OpenPipe. We got the scoop on Amp’s wild new ad-supported free tier from CEO Quinn Slack. And just as we were wrapping up, Swyx ( from Latent.Space , now with Cognition!) jumped on to break the news about their blazingly fast SWE-grep models.
But the biggest story? An AI model from Google and Yale made a novel scientific discovery about cancer cells that was then validated in a lab. This is it, folks. This is the “let’s fucking go” moment we’ve been waiting for. So buckle up, because this week was an absolute monster. Let’s dive in!
Open Source: An AI Model Just Made a Real-World Cancer Discovery
We always start with open source, but this week felt different. This week, open source AI stepped out of the benchmarks and into the biology lab.
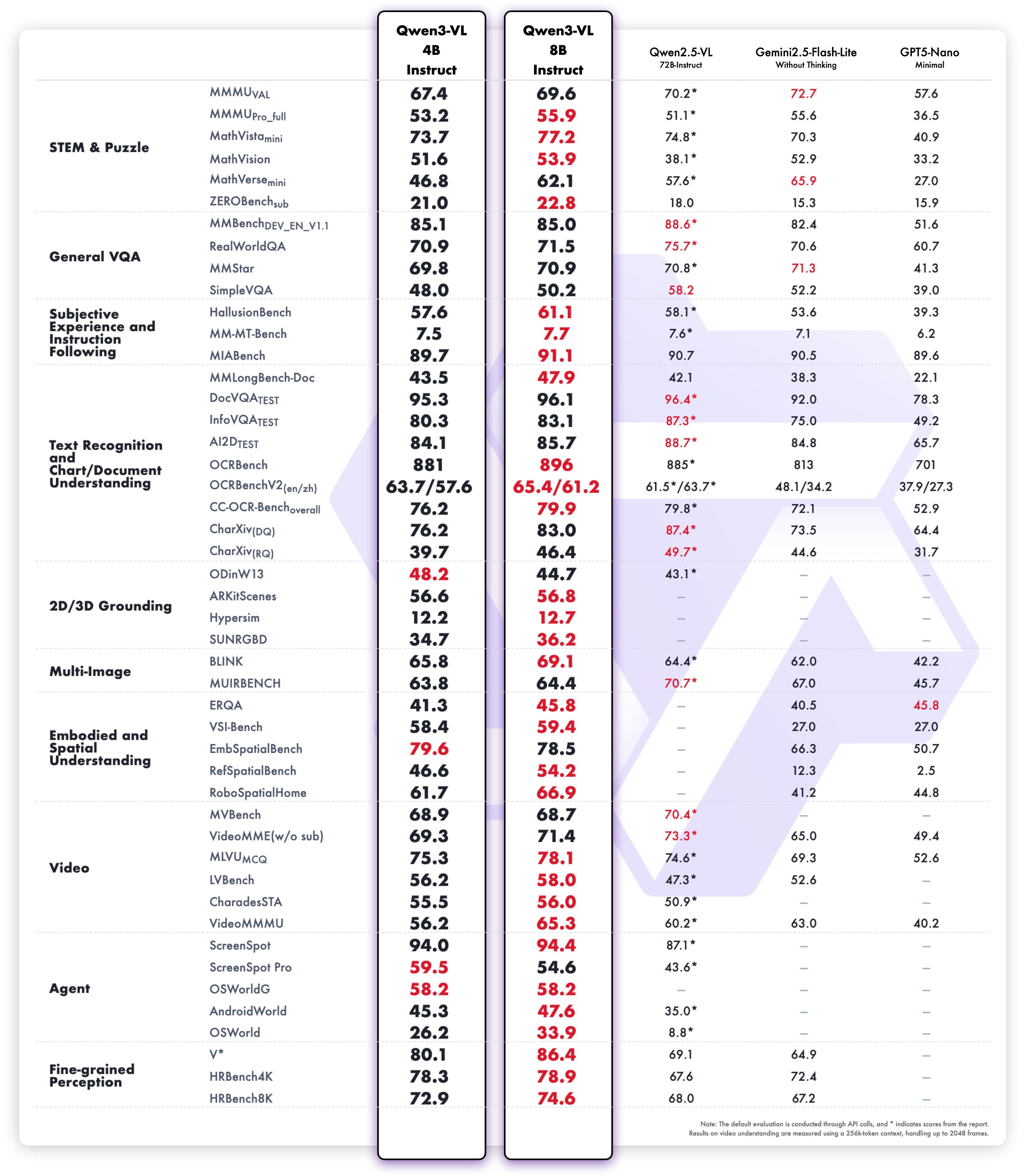
Our friends at Qwen kicked things off with new 3B and 8B parameter versions of their Qwen3-VL vision model. It’s always great to see powerful models shrink down to sizes that can run on-device. What’s wild is that these small models are outperforming last generation’s giants, like the 72B Qwen2.5-VL, on a whole suite of benchmarks. The 8B model scores a 33.9 on OS World, which is incredible for an on-device agent that can actually see and click things on your screen. For comparison, that’s getting close to what we saw from Sonnet 3.7 just a few months ago. The pace is just relentless.
But then, Google dropped a bombshell. A 27-billion parameter Gemma-based model they developed with Yale, called C2S-Scale, generated a completely novel hypothesis about how cancer cells behave. This wasn’t a summary of existing research; it was a new idea, something no human scientist had documented before. And here’s the kicker: researchers then took that hypothesis into a wet lab, tested it on living cells, and proved it was true.

This is a monumental deal. For years, AI skeptics like Gary Marcus have said that LLMs are just stochastic parrots, that they can’t create genuinely new knowledge. This feels like the first, powerful counter-argument. Friend of the pod, Dr. Derya Unutmaz, has been on the show before saying AI is going to solve cancer, and this is the first real sign that he might be right. The researchers noted this was an “emergent capability of scale,” proving once again that as these models get bigger and are trained on more complex data—in this case, turning single-cell RNA sequences into “sentences” for the model to learn from—they unlock completely new abilities. This is AI as a true scientific collaborator. Absolutely incredible.
Big Companies & APIs
The big companies weren’t sleeping this week, either. The agentic AI race is heating up, and we’re seeing huge updates across the board.
Claude Haiku 4.5: Fast, Cheap Model Rivals Sonnet 4 Accuracy (X, Official blog, X)
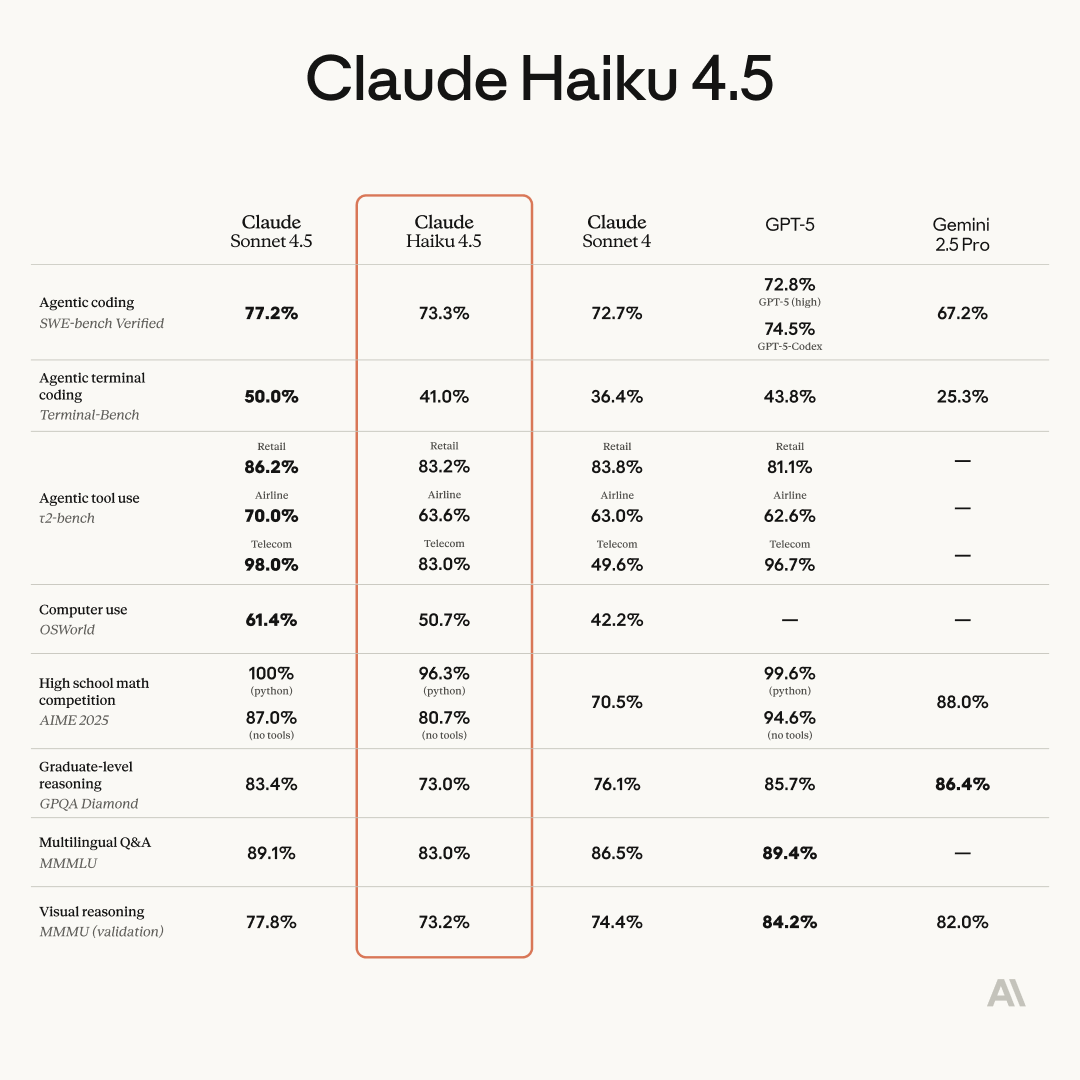
First up, Anthropic released Claude Haiku 4.5, and it is a beast. It’s a fast, cheap model that’s punching way above its weight. On the SWE-bench verified benchmark for coding, it hit 73.3%, putting it right up there with giants like GPT-5 Codex, but at a fraction of the cost and twice the speed of previous Claude models. Nisten has already been putting it through its paces and loves it for agentic workflows because it just follows instructions without getting opinionated. It seems like Anthropic has specifically tuned this one to be a workhorse for agents, and it absolutely delivers.
The thing to note also is the very impressive jump in OSWorld (50.7%), which is a computer use benchmark, and at this price and speed ($1/$5 MTok input/output) is going to make computer agents much more streamlined and speedy!
ChatGPT will loose restrictions; age-gating enables “adult mode” with new personality features coming (X)
Sam Altman set X on fire with a thread announcing that ChatGPT will start loosening its restrictions. They’re planning to roll out an “adult mode” in December for age-verified users, potentially allowing for things like erotica. More importantly, they’re bringing back more customizable personalities, trying to recapture some of the magic of GPT-4.0 that so many people missed. It feels like they’re finally ready to treat adults like adults, letting us opt-in to R-rated conversations while keeping strong guardrails for minors. This is a welcome change, and we’ve been advocating for this for a while, and it’s a notable change from the XAI approach I covered last week. Opt in for adults with verification while taking precautions vs engagement bait in the form of a flirty animated waifu with engagement mechanics.
Microsoft is making every windows 11 an AI PC with copilot voice input and agentic powers (Blog,X)
And in breaking news from this morning, Microsoft announced that every Windows 11 machine is becoming an AI PC. They’re building a new Copilot agent directly into the OS that can take over and complete tasks for you. The really clever part? It runs in a secure, sandboxed desktop environment that you can watch and interact with. This solves a huge problem with agents that take over your mouse and keyboard, locking you out of your own computer. Now, you can give the agent a task and let it run in the background while you keep working. This is going to put agentic AI in front of hundreds of millions of users, and it’s a massive step towards making AI a true collaborator at the OS level.
NVIDIA DGX - the tiny personal supercomputer at $4K (X, LMSYS Blog)

NVIDIA finally delivered their promised AI Supercomputer, and while the excitement was in the air with Jensen hand delivering the DGX Spark to OpenAI and Elon (recreating that historical picture when Jensen hand delivered a signed DGX workstation while Elon was still affiliated with OpenAI). The workstation was sold out almost immediately. Folks from LMSys did a great deep dive into specs, all the while, folks on our feeds are saying that if you want to get the maximum possible open source LLMs inference speed, this machine is probably overpriced, compared to what you can get with an M3 Ultra Macbook with 128GB of RAM or the RTX 5090 GPU which can get you similar if not better speeds at significantly lower price points.
Anthropic’s “Claude Skills”: Your AI Agent Finally Gets a Playbook (Blog)
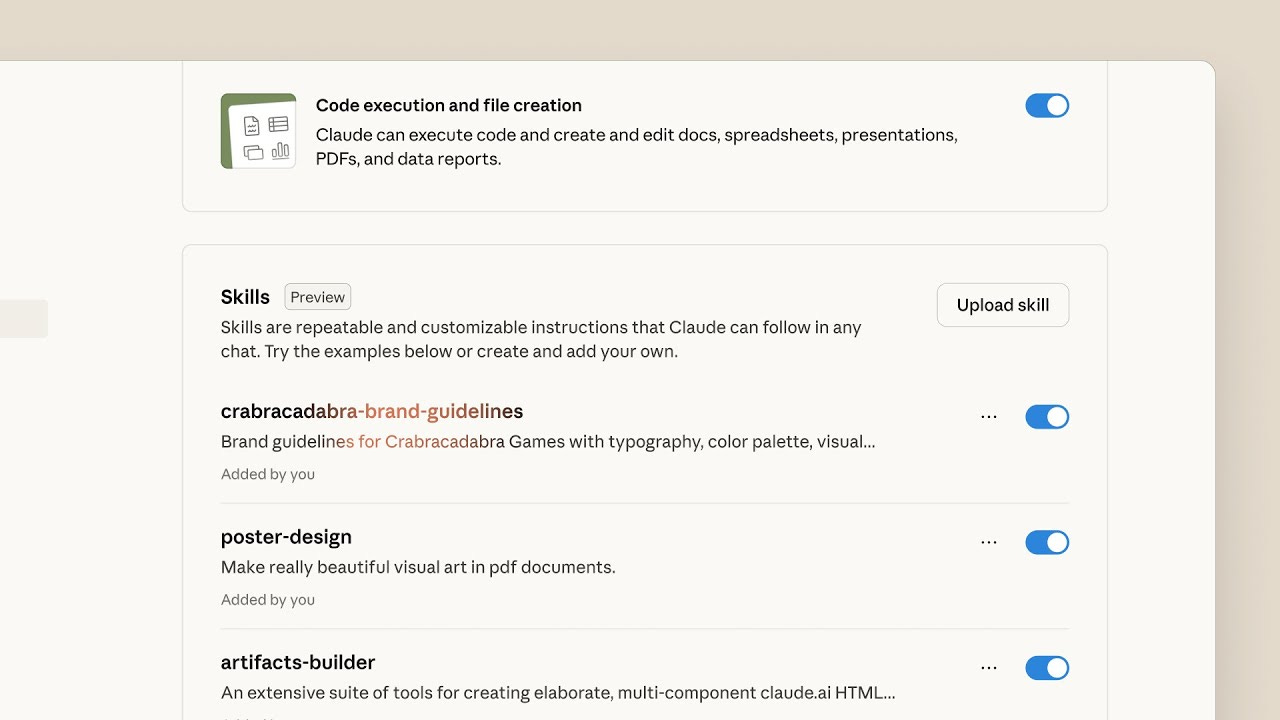
Just when we thought the week couldn’t get any more packed, Anthropic dropped “Claude Skills,” a huge upgrade that lets you give your agent custom instructions and workflows. Think of them as expertise folders you can create for specific tasks. For example, you can teach Claude your personal coding style, how to format reports for your company, or even give it a script to follow for complex data analysis.
The best part is that Claude automatically detects which “Skill” is needed for a given task, so you don’t have to manually load them. This is a massive step towards making agents more reliable and personalized, moving beyond just a single custom instruction and into a library of repeatable, expert processes. It’s available now for all paid users, and it’s a feature I’ve been waiting for. Our friend Simon Willison things skills may be a bigger deal than MCPs!
🎬 Vision & Video: Veo 3.1, Sora Gets Longer, and Real-Time Worlds
The AI video space is exploding. We started with an amazing interview with Jessica Gallegos, a Senior Product Manager at Google DeepMind, all about the new Veo 3.1. This is a significant 0.1 update, not a whole new model, but the new features are game-changers for creators.
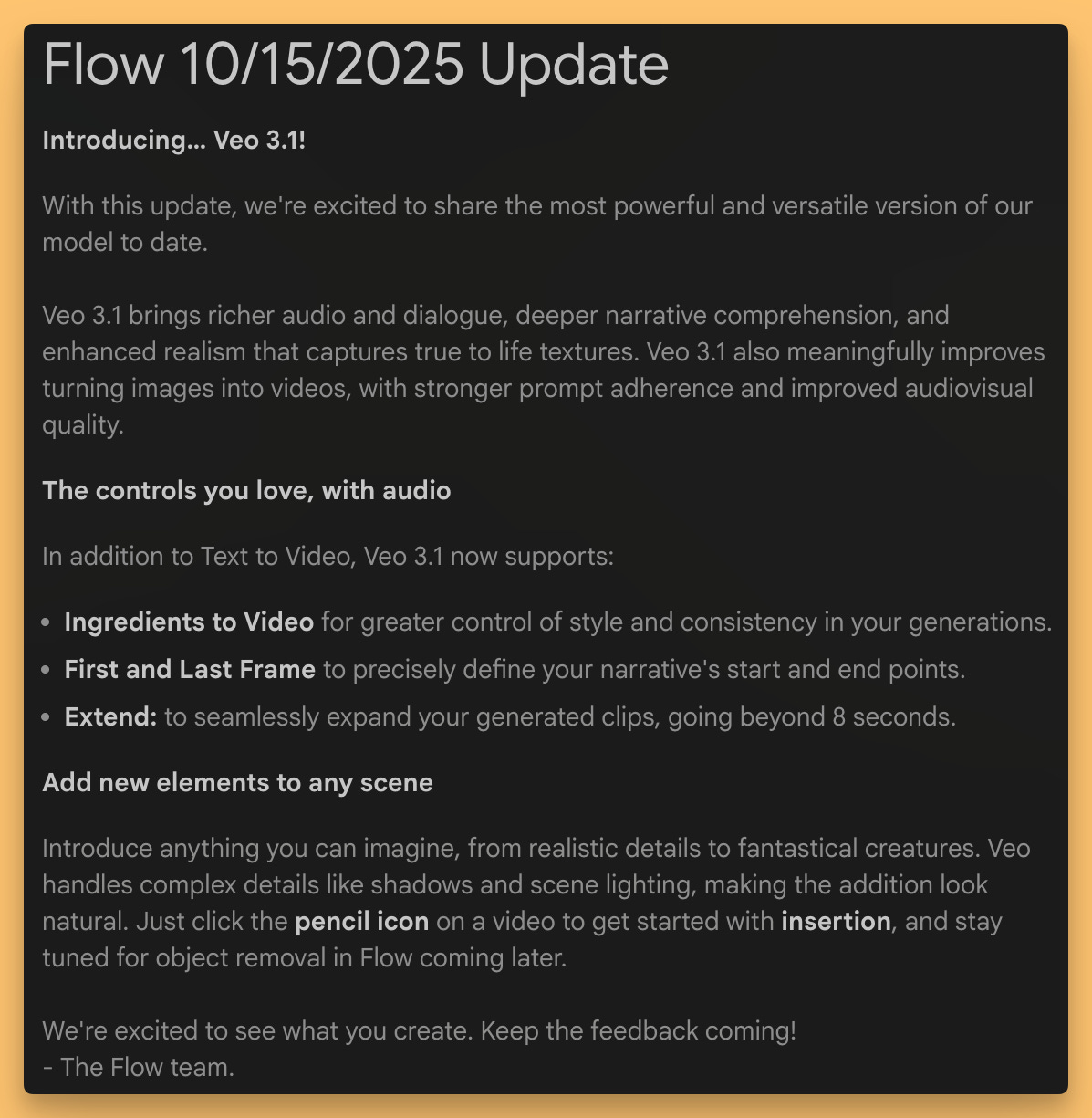
The audio quality is way better, and they’ve massively improved video extensions. The model now conditions on the last second of a clip—including the audio. This means if you extend a video of someone talking, they keep talking in the same voice! This is huge, saving creators from complex lip-syncing and dubbing workflows. They also added object insertion and removal, which works on both generated and real-world video. Jessica shared an incredible story about working with director Darren Aronofsky to insert a virtual baby into a live-action film shot, something that’s ethically and practically very difficult to do on a real set. These are professional-grade tools that are becoming accessible to everyone. Definitely worth listening to the whole interview with Jessica, starting at 00:25:44
I’ve played with the new VEO in Google Flow, and while I was somewhat (still) disappointed with the UI itself (it froze sometimes and didn’t play). I wasn’t able to upload my own videos to use the insert/remove features Jessica mentioned yet, but saw examples online and they looked great!
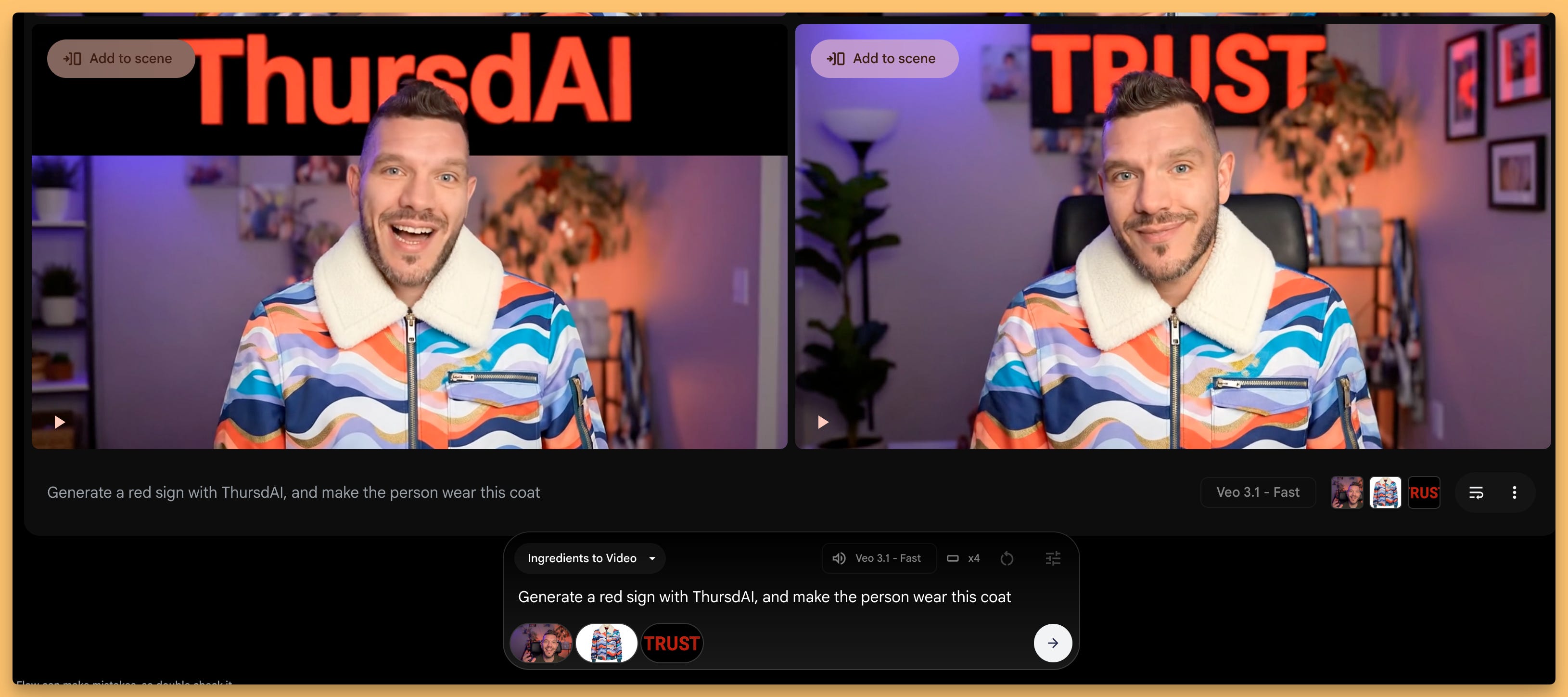
Ingredients were also improved with VEO 3.1, where you can add up to 3 references, and they will be included in your video but not as first frame, the model will use them to condition the vidoe generation. Jessica clarified that if you upload sound, as in, your voice, it won’t show up in the model as your voice yet, but maybe they will add this in the future (at least this was my feedback to her).
SORA 2 extends video gen to 15s for all, 25 seconds to pro users with a new storyboard
Not to be outdone, OpenAI pushed a bit of an update for Sora. All users can now generate up to 15-second clips (up from 8-10), and Pro users can go up to 25 seconds using a new storyboard feature. I’ve been playing with it, and while the new scene-based workflow is powerful, I’ve noticed the quality can start to degrade significantly in the final seconds of a longer generation (posted my experiments here) as you can see. The last few shot so the cowboy don’t have any action, and the face is a blurry mess.
Worldlabs RTFM: Real-Time Frame Model renders 3D worlds at interactive speeds on a single H100 ( X, Blog, Demo )
And just when we thought we’d seen it all, World Labs dropped a breaking news release: RTFM, the Real-Time Frame Model. This is a generative world model that renders interactive, 3D-consistent worlds on the fly, all on a single H100 GPU. Instead of pre-generating a 3D environment, it’s a “learned renderer” that streams pixels as you move. We played with the demo live on the show, and it’s mind-blowing. The object permanence is impressive; you can turn 360 degrees and the scene stays perfectly coherent. It feels like walking around inside a simulation being generated just for you.
This Week’s Buzz: RL Made Easy with Serverless RL + interview with Kyle Corbitt
It was a huge week for us at Weights & Biases and CoreWeave. I was thrilled to finally have my new colleague Kyle Corbitt, founder of OpenPipe, back on the show to talk all things Reinforcement Learning (RL).
RL is the technique behind the massive performance gains we’re seeing in models for tasks like coding and math. At a high level, it lets a model try things, and then you “reward” it for good outcomes and penalize it for bad ones, allowing it to learn strategies that are better than what was in its original training data. The problem is, it’s incredibly complex and expensive to set up the infrastructure. You have to juggle an inference stack for generating the “rollouts” and a separate training stack for updating the model weights.
This is the problem Kyle and his team have solved with Serverless RL, which we just launched and we covered last week. It’s a new offering that lets you run RL jobs without managing any servers or GPUs. The whole thing is powered by the CoreWeave stack, with tracing and evaluation beautifully visualized in Weave.
We also launched a new model from the OpenPipe team on our inference service: a fine-tune-friendly “instruct” version of Qwen3 14B. The team is not just building amazing products, they’re also contributing great open-source models. It’s awesome to be working with them.
🛠️ Tools & Agents: Free Agents & Lightning-Fast Code Search
The agentic coding space saw two massive announcements this week, and we had the representatives of both companies on the show to discuss them!

First, Quinn Slack from Amp announced that they’re launching a completely free, ad-supported tier. I’ll be honest, my first reaction was, “Ads? In my coding agent? Eww.” But the more I thought about it, the more it made sense. My AI subscriptions are stacking up, and this model makes powerful agentic coding accessible to students and developers who can’t afford another $20/month. The ads are contextual to your codebase (think Baseten or Axiom), and they’re powered by a rotating mix of models using surplus capacity from providers. It’s a bold and fascinating business model.
This move was met with generally positive responses, though folks from a competing agent, claim that Amp is serving Grok-4-fast which XAI is giving out for free anyway? We’ll see how this shakes up.
Cognition announces SWE-grep: RL-powered multi-turn context retriever for agentic code search (Blog, X, Playground, Windsurf)
Then, just as we were about to sign off, friend of the pod Swyx (now from Cognition) dropped in with breaking news about SWE-grep. It’s a new, RL-tuned sub-agent for their Windsurf editor that makes code retrieval and context gathering ridiculously fast. We’re talking over 2,800 tokens per second. (yes, they are using Cerebras under the hood)
The key insight from Swyx is that their model was trained for natively parallel tool calling, running up to eight searches on a codebase simultaneously. This speeds up the “read” phase of an agent’s workflow—which is 60-70% of the work—by 3-5x. It’s all about keeping the developer in a state of flow, and this is a huge leap forward in making agent interactions feel instantaneous. Swyx also dropped a hint that the next thing that comes is CodeMaps and they will make these retrievers look trivial!
This was one for the books, folks. An AI making a novel cancer discovery, video models taking huge leaps, and the agentic coding space is on fire. The pace of innovation is just breathtaking. Thank you for being a ThursdAI subscriber, and as always, here’s the TL:DR and show notes for everything that happened in AI this week.
TL;DR and Show Notes
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed
Jessica Gallegos, Sr. Product Manager, Google DeepMind
Kyle Corbitt (@corbtt) - OpenPipe//W&B
Quinn Slack (@sqs) - Amp
Swyx (@swyx) - Cognition
Open Source LLMs
Big CO LLMs + APIs
Claude Haiku 4.5: Fast, Cheap Model Rivals Sonnet 4 Accuracy (X, Official blog)
ChatGPT will loose restrictions; age-gating enables “adult mode” with new personality features coming (X)
OpenAI updates memory management - no more “memory full” (X, FAQ)
Microsoft is making every windows 11 an AI PC with copilot voice input (X)
Claude Skills: Custom instructions for AI agents now live (X, Anthropic News, YouTube Demo)
Hardware
NVIDIA DGX Spark: desktop personal supercomputer for AI prototyping and local inference (LMSYS Blog)
Apple announces M5 chip with double AI performance (Apple Newsroom)
OpenAI and Broadcom set to deploy 10 gigawatts of custom AI accelerators (Official announcement)
This weeks Buzz
Vision & Video
Veo 3.1: Google’s Next-Gen Video Model Launches with Cinematic Audio (Developers Blog)
Sora up to 15s and pro now up to 25s generation with a new storyboard feature
Baidu’s MuseStreamer has >20 second generations (X)
AI Art & Diffusion & 3D
Worldlabs RTFM: Real-Time Frame Model renders 3D worlds at interactive speeds on a single H100 (Blog, Demo)
DiT360: SOTA Panoramic Image Generation with Hybrid Training (Project page, GitHub)
Riverflow 1 tops the image‑editing leaderboard (Sourceful blog)
Tools
Amp launches a Free tier - powered by ads and surplus model capacity (Website)
Cognition SWE-grep: RL-powered multi-turn context retriever for agentic code search (Blog, Playground)





