



Hey, this is Alex!
We’re finally so back! Tons of open source releases, OpenAI updates GPT and a few breakthroughs in audio as well, makes this a very dense week!
Today on the show, we covered the newly released GPT 5.1 update, a few open source releases like Terminal Bench and Project AELLA (renamed OASSAS), and Baidu’s Ernie 4.5 VL that shows impressive visual understanding!
Also, chatted with Paul from 11Labs and Dima Duev from the wandb SDK team, who brought us a delicious demo of LEET, our new TUI for wandb!
Tons of news coverage, let’s dive in 👇 (as always links and show notes in the end)
Open Source AI
Let’s jump directly into Open Source as this week has seen some impressive big company models.
Terminal-Bench 2.0 - a harder, highly‑verified coding and terminal benchmark (X, Blog, Leaderboard)
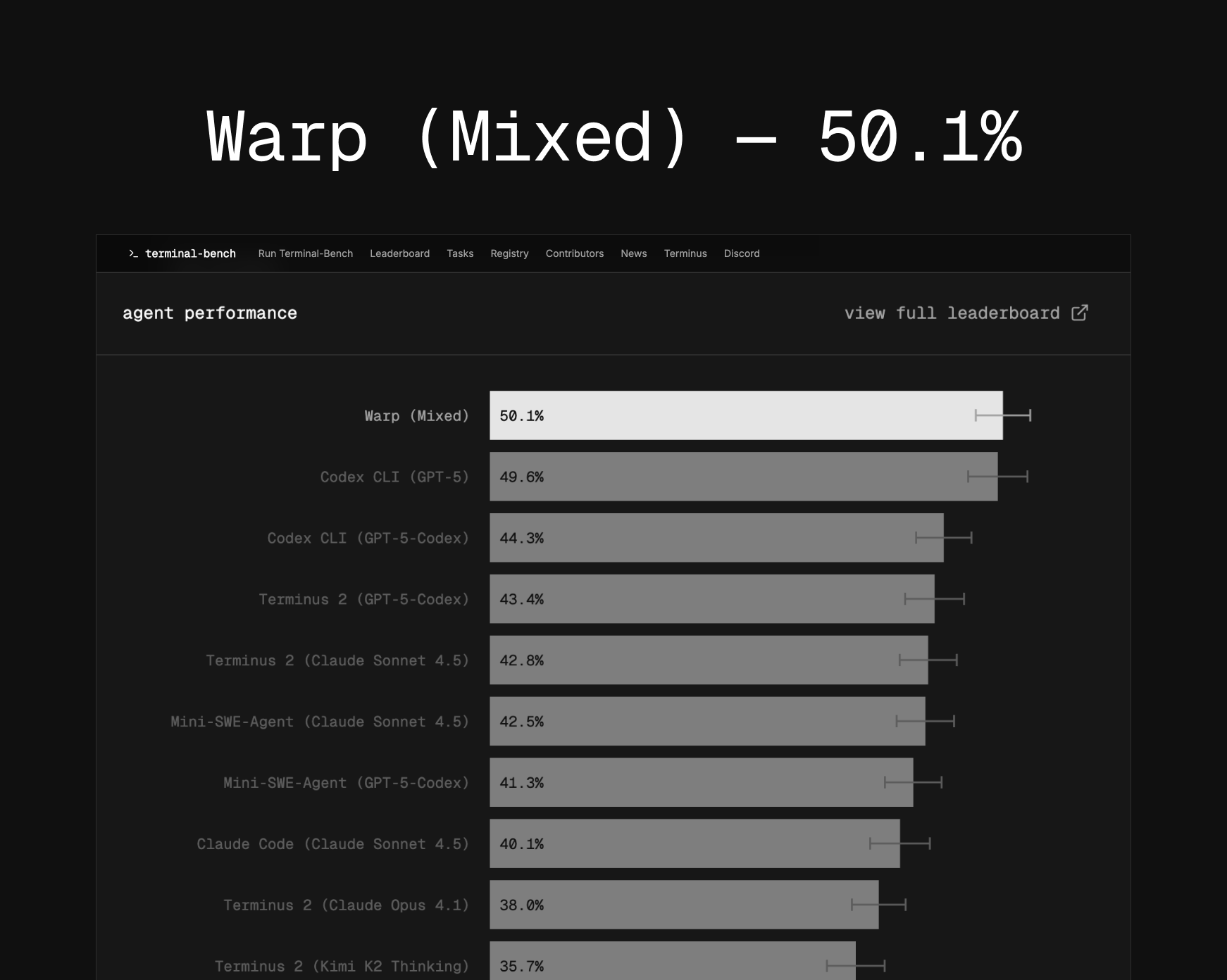
We opened with Terminal‑Bench 2.0 plus its new harness, Harbor, because this is the kind of benchmark we’ve all been asking for.
Terminal‑Bench focuses on agentic coding in a real shell. Version 2.0 is a hard set of 89 terminal tasks, each one painstakingly vetted by humans and LLMs to make sure it’s solvable and realistic. Think “I checked out master and broke my personal site, help untangle the git mess” or “implement GPT‑2 code golf with the fewest characters.”
On the new leaderboard, top agents like Warp’s agentic console and Codex CLI + GPT‑5 sit around fifty percent success. That number is exactly what excites me: we’re nowhere near saturation. When everyone is in the 90‑something range, tiny 0.1 improvements are basically noise. When the best models are at fifty percent, a five‑point jump really means something.
A huge part of our conversation focused on reproducibility. We’ve seen other benchmarks like OSWorld turn out to be unreliable, with different task sets and non‑reproducible results making scores incomparable. Terminal‑Bench addresses this with Harbor, a harness designed to run sandboxed, containerized agent rollouts at scale in a consistent environment. This means results are actually comparable. It’s a ton of work to build an entire evaluation ecosystem like this, and with over a thousand contributors on their Discord, it’s a fantastic example of a healthy, community‑driven effort. This is one to watch!
Baidu’s ERNIE‑4.5‑VL “Thinking”: a 3B visual reasoner that punches way up (X, HF, GitHub)
Next up, Baidu dropped a really interesting model, ERNIE‑4.5‑VL‑28B‑A3B‑Thinking. This is a compact, 3B active‑parameter multimodal reasoning model focused on vision, and it’s much better than you’d expect for its size. Baidu’s own charts show it competing with much larger closed models like Gemini‑2.5‑Pro and GPT‑5‑High on a bunch of visual benchmarks like ChartQA and DocVQA.

During the show, I dropped a fairly complex chart into the demo, and ERNIE‑4.5‑VL gave me a clean textual summary almost instantly—it read the chart more cleanly than I could. The model is built to “think with images,” using dynamic zooming and spatial grounding to analyze fine details. It’s released under an Apache‑2.0 license, making it a serious candidate for edge devices, education, and any product where you need a cheap but powerful visual brain.
Open Source Quick Hits: OSSAS, VibeThinker, and Holo Two
We also covered a few other key open-source releases. Project AELLA was quickly rebranded to OSSAS (Open Source Summaries At Scale), an initiative to make scientific literature machine‑readable. They’ve released 100k paper summaries, two fine-tuned models for the task, and a 3D visualizer. It’s a niche but powerful tool if you’re working with massive amounts of research. (X, HF)
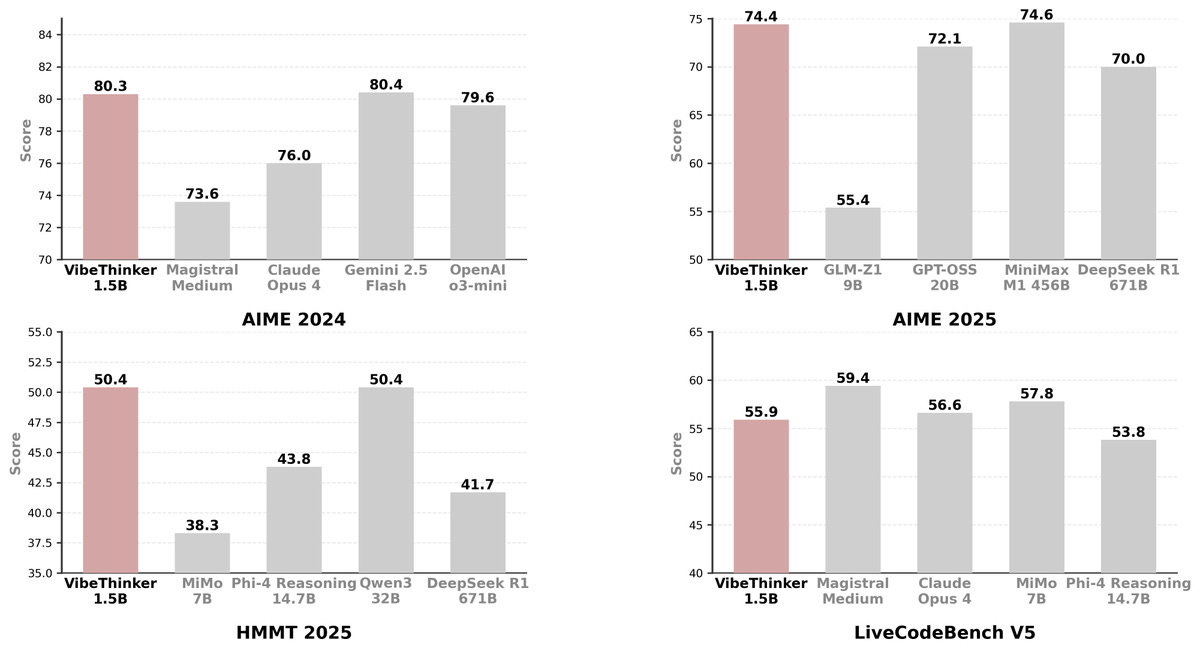
WeiboAI (from the Chinese social media company) released VibeThinker‑1.5B, a tiny 1.5B‑parameter reasoning model that is making bold claims about beating the 671B DeepSeek R1 on math benchmarks.
We discussed the high probability of benchmark contamination, especially on tests like AIME24, but even with that caveat, getting strong chain‑of‑thought math out of a 1.5B model is impressive and useful for resource‑constrained applications. (X, HF, Arxiv)
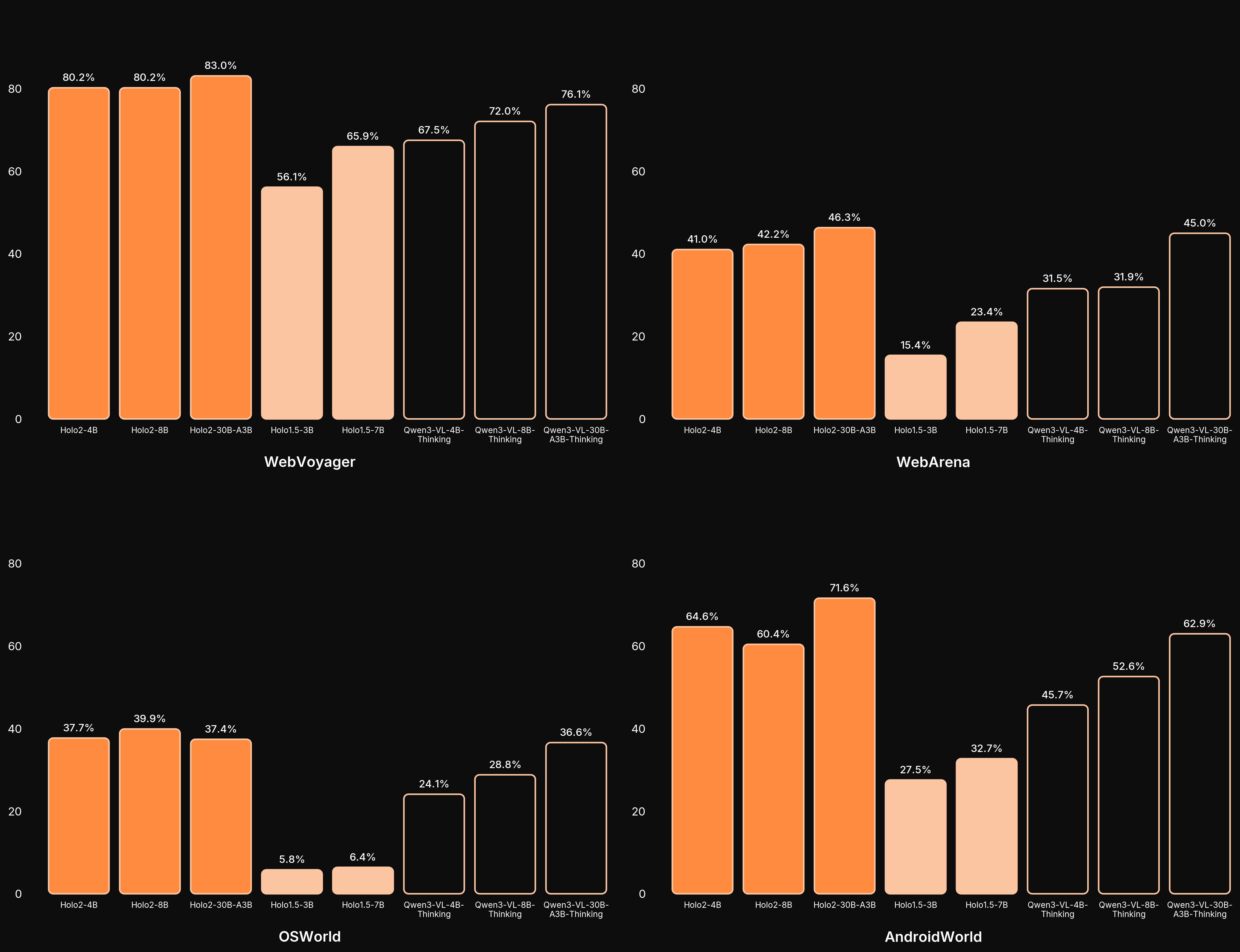
Finally, we had some breaking news mid‑show: H Company released Holo Two, their next‑gen multimodal agent for controlling desktops, websites, and mobile apps. It’s a fine‑tune of Qwen3‑VL and comes in 4B and 8B Apache‑2.0 licensed versions, pushing the open agent ecosystem forward. (X, Blog, HF)
Big Companies & APIs
GPT‑5.1: Instant vs Thinking, and a new personality bar
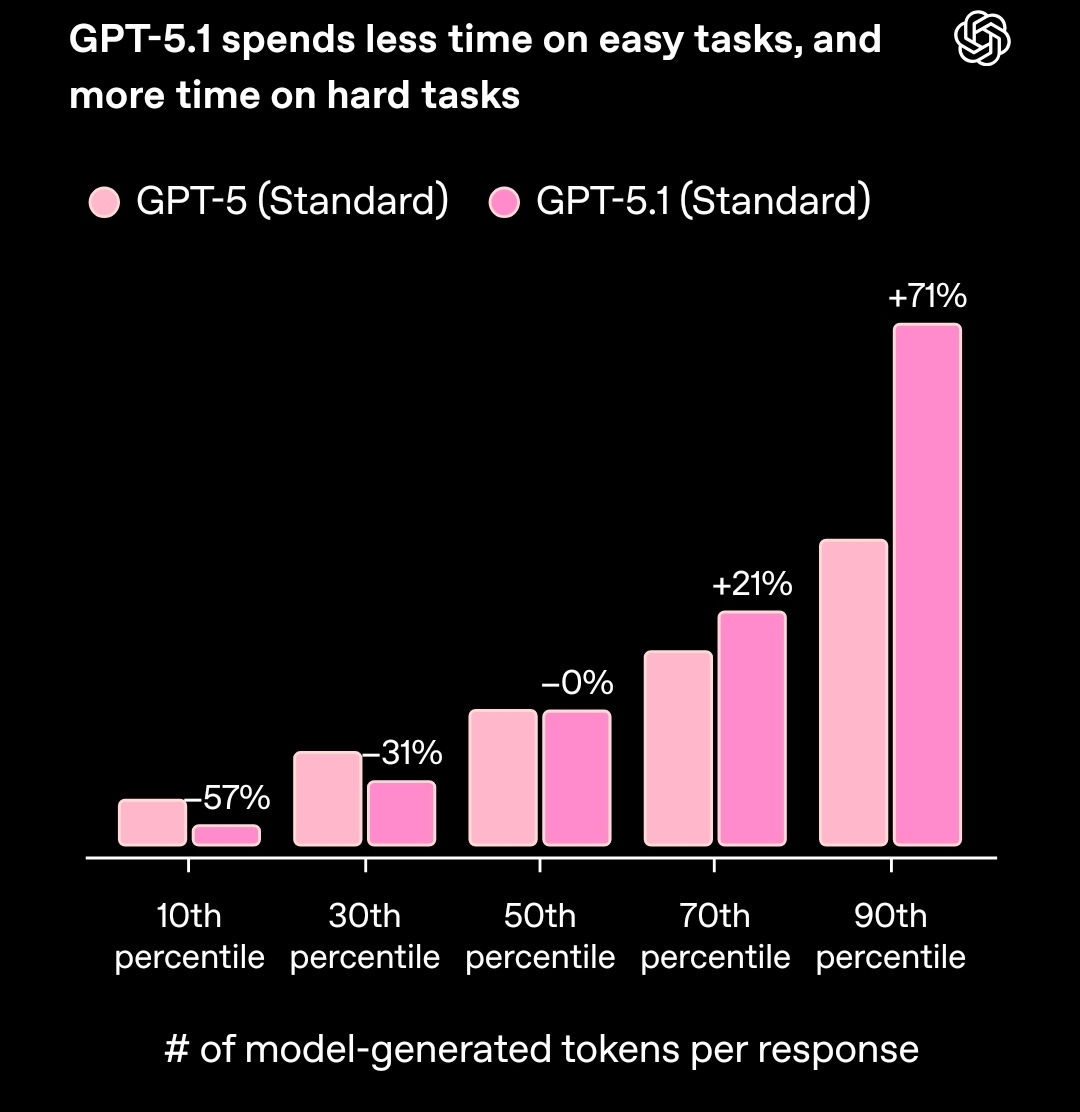
The biggest headline of the week was OpenAI shipping GPT‑5.1, and this was a hot topic of debate on the show. The update introduces two modes: “Instant” for fast, low‑compute answers, and “Thinking” for deeper reasoning on hard problems. OpenAI claims Instant mode uses 57% fewer tokens on easy tasks, while Thinking mode dedicates 71% more compute to difficult ones. This adaptive approach is a smart evolution.
The release also adds a personality dropdown with options like Professional, Friendly, Quirky, and Cynical, aiming for a more “warm” and customizable experience.

Yam and I felt this was a step in the right direction, as GPT‑5 could often feel a bit cold and uncommunicative. However, Wolfram had a more disappointing experience, finding that GPT‑5.1 performed significantly worse on his German grammar and typography tasks compared to GPT‑4 or Claude Sonnet 4.5. It’s a reminder that “upgrades” can be subjective and task‑dependent.

Since the show was recorded, GPT 5.1 is also released in the API and they have published a prompting guide and some evals! With some significant jumps across SWE-bench verified and GPQA Diamond! We’ll be testing this model out all week.
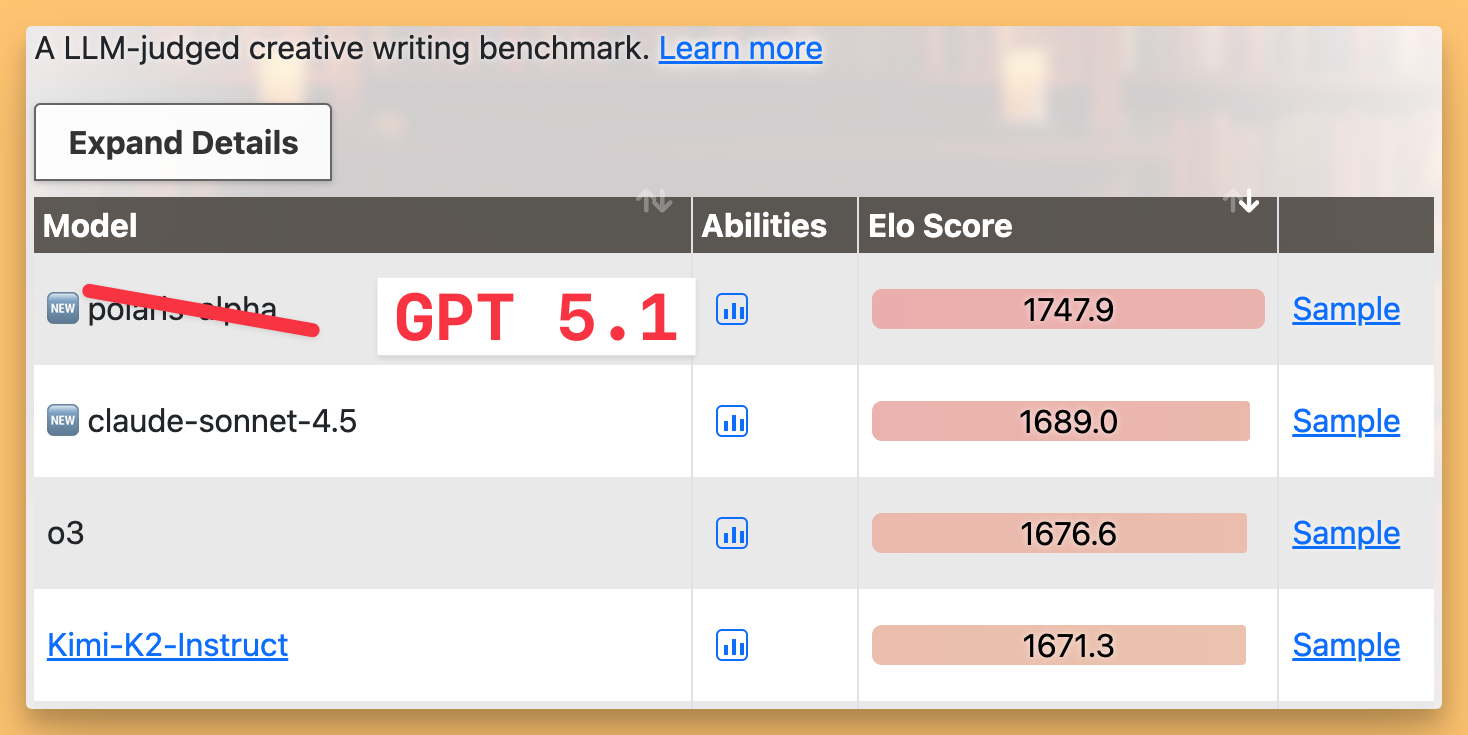
The highlight for this model is the creative writing, it was made public that this model was being tested on OpenRouter as Polaris-alpha and that one tops the eqbench creative writing benchmarks beating Sonnet 4.5 and Gemini!
Grok‑4 Fast: 2M context and a native X superpower
Grok‑4 Fast from xAI apparenly quietly got a substantial upgrade to a 2M‑token context window, but the most interesting part is its unique integration with X. The API version has access to internal tools for semantic search over tweets, retrieving top quote tweets, and understanding embedded images and videos. I’ve started using it as a research agent in my show prep, and it feels like having a research assistant living inside X’s backend—something you simply can’t replicate with public tools.
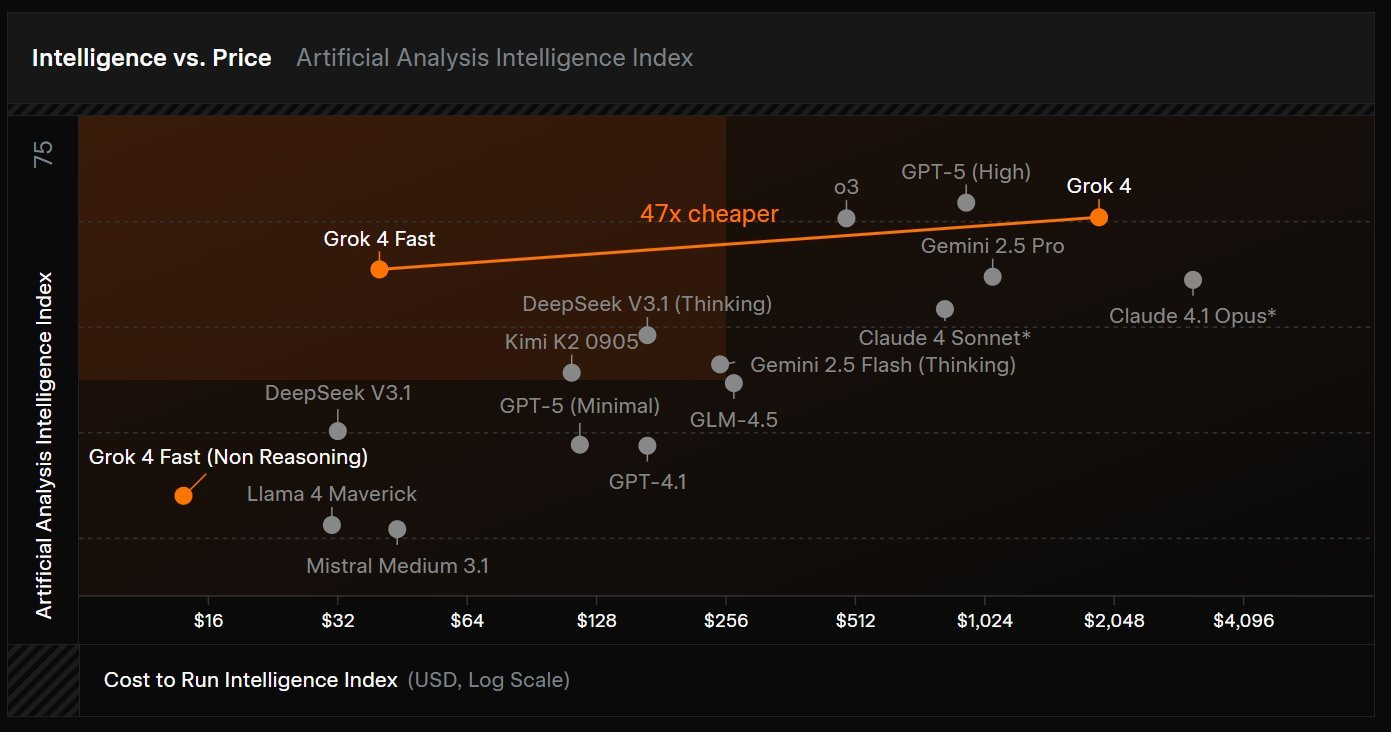
I still have my gripes about their “stealth upgrade” versioning strategy, which makes rigorous evaluation difficult, but as a practical tool, Grok‑4 Fast is incredibly powerful. It’s also surprisingly fast and cost‑effective, holding its own against other top models on benchmarks while offering a superpower that no one else has.
Google SIMA 2: Embodied Agents in Virtual Worlds
Google’s big contribution this week was SIMA 2, DeepMind’s latest embodied agent for 3D virtual worlds. SIMA lives inside real games like No Man’s Sky and Goat Simulator, seeing the screen and controlling the game via keyboard and mouse, using Gemini as its reasoning brain. Demos showed it following complex, sketch‑based instructions, like finding an object that looks like a drawing of a spaceship and jumping on top of it.
When you combine this with Genie 3—Google’s world model that can generate playable environments from a single image—you see the bigger picture: agents that learn physics, navigation, and common sense by playing in millions of synthetic worlds. We’re not there yet, but the pieces are clearly being assembled. We also touched on the latest Gemini Live voice upgrade, which users are reporting feels much more natural and responsive
More Big Company News: Qwen Deep Research, Code Arena, and Cursor
We also briefly covered Qwen’s new Deep Research feature, which offers an OpenAI‑style research agent inside their ecosystem. LMSYS launched Blog, a fantastic live evaluation platform where models build real web apps agentically, with humans voting on the results. And in the world of funding, the AI‑native code editor Cursor raised a staggering $2.3 billion, a clear sign that AI is becoming the default way developers interact with code.
This Week’s Buzz: W&B LEET – a terminal UI that sparks joy
For this week’s buzz, I brought on Dima Duev from our SDK team at Weights & Biases to show off a side project that has everyone at the company excited: LEET, the Lightweight Experiment Exploration Tool. Imagine you’re training on an air‑gapped HPC cluster, living entirely in your terminal. How do you monitor your runs? With LEET.
You run your training script in W&B offline mode, and in another terminal, you type wandb beta leet. Your terminal instantly turns into a full TUI dashboard with live metric plots, system stats, and run configs. You can zoom into spikes in your loss curve, filter metrics, and see everything updating in real time, all without a browser or internet connection. It’s one of those tools that just sparks joy. It ships with the latest wandb SDK (v0.23.0+), so just upgrade and give it a try!
Voice & Audio: Scribe v2 Realtime and Omnilingual ASR
ElevenLabs Scribe v2 Realtime: ASR built for agents (X, Announcement, Demo)
We’ve talked a lot on this show about ElevenLabs as “the place you go to make your AI talk.” This week, they came for the other half of the conversation. Paul Asjes from ElevenLabs joined us to walk through Scribe v2 Realtime, their new low‑latency speech‑to‑text model. If you’re building a voice agent, you need ears, a brain, and a mouth. ElevenLabs already nailed the mouth, and now they’ve built some seriously good ears.
Scribe v2 Realtime is designed to run at around 150 milliseconds median latency, across more than ninety languages. Watching Paul’s live demo, it felt comfortably real‑time. When he switched from English to Dutch mid‑sentence, the system just followed along without missing a beat. Community benchmarks and our own impressions show it holding its own or beating competitors like Whisper and Deepgram in noisy, accented, and multi‑speaker scenarios. It’s also context‑aware enough to handle code, initialisms, and numbers correctly, which is critical for real‑world agents. This is a production‑ready ASR for anyone building live voice experiences.
Meta’s drops Omnilingual ASR: 1,600+ languages, many for the first time + a bunch of open source models (X, Blog, Announcement, HF)
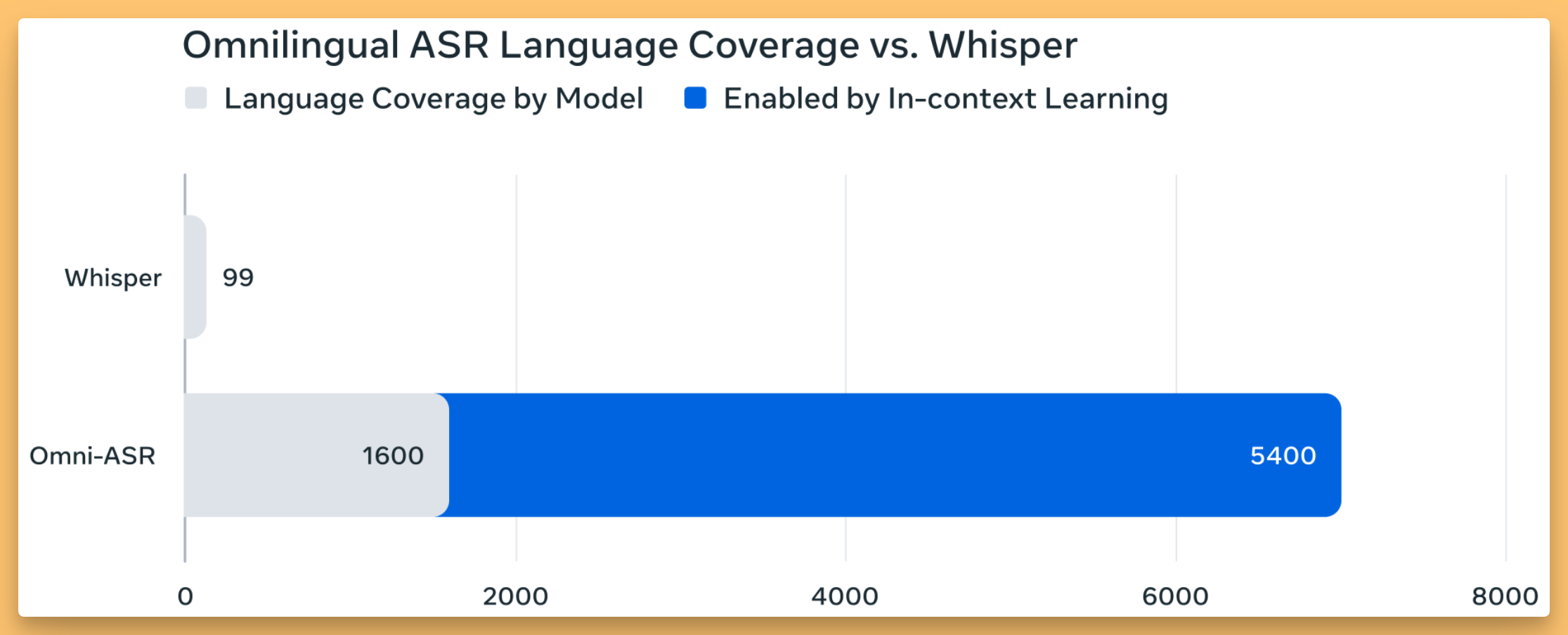
On the other end of the spectrum, Meta released something that’s less about ultra‑low latency and more about sheer linguistic coverage: Omnilingual ASR. This is a family of models and a dataset designed to support speech recognition for more than 1,600 languages, including about 500 that have never had any ASR support before. That alone is a massive contribution.
Technically, it uses a wav2vec 2.0 backbone scaled up to 7B parameters with both CTC and LLM‑style decoders. The LLM‑like architecture allows for in‑context learning, so communities can add support for new languages with only a handful of examples. They’re also releasing the Omnilingual ASR Corpus with data for 350 underserved languages. The models and code are Apache‑2.0, making this a huge step forward for more inclusive speech tech.
AI Art, Diffusion & 3D
Qwen Image Edit + Multi‑Angle LoRA: moving the camera after the fact (X, HF, Fal)

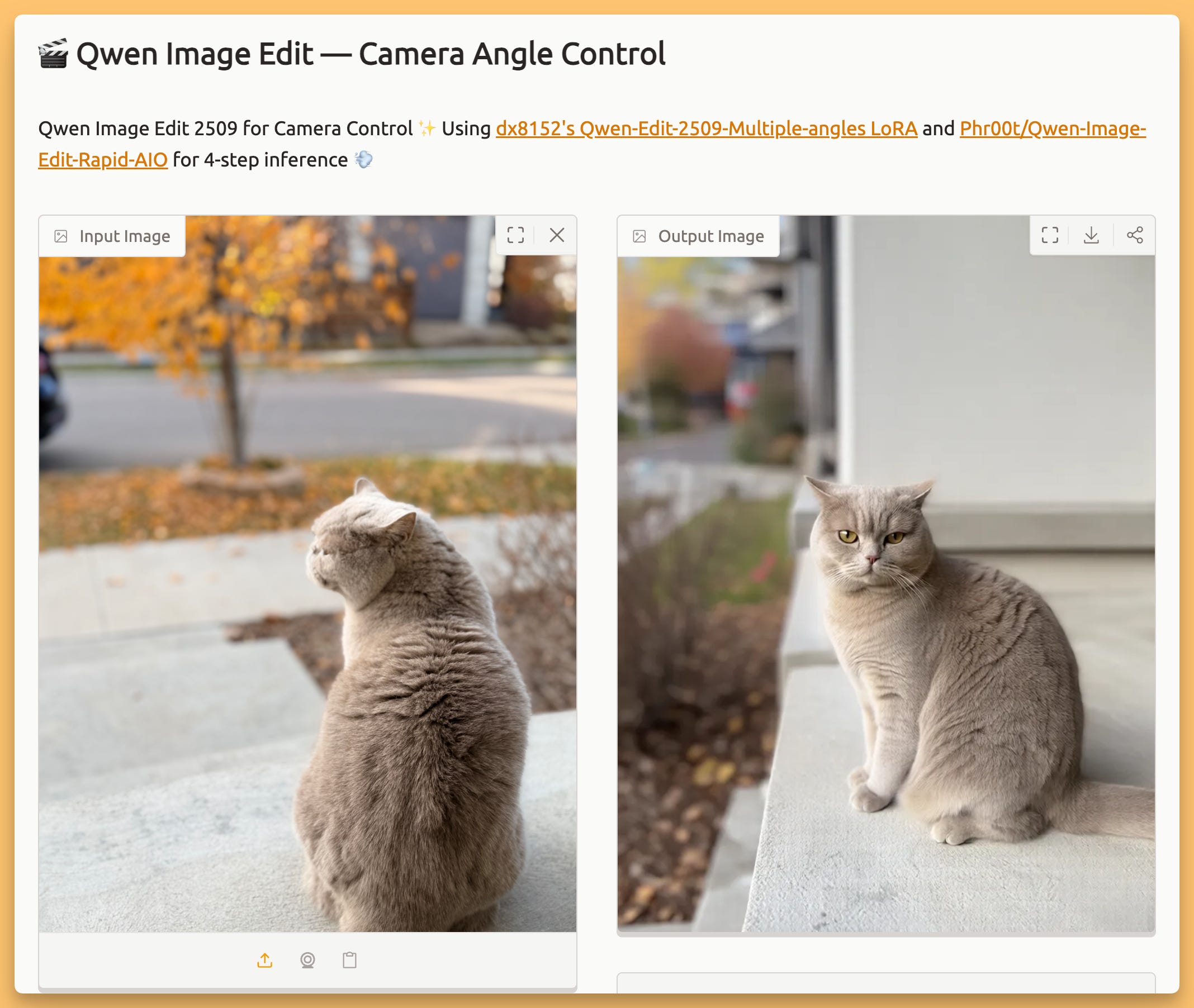
This one was pure fun. A new set of LoRAs for Qwen Image Edit adds direct camera control to still images. A Hugging Face demo lets you upload a photo and use sliders to rotate the camera up to 90 degrees, tilt from a bird’s‑eye to a worm’s‑eye view, and adjust the lens. We played with it live on the show with a portrait of Wolfram and a photo of my cat, generating different angles and then interpolating them into a short “fly‑around” video. It’s incredibly cool and preserves details surprisingly well, feeling like you have a virtual camera inside a 2D picture.
NVIDIA ChronoEdit‑14B Upscaler LoRA (X, HF)
Finally, NVIDIA released an upscaler LoRA based on their ChronoEdit‑14B model and merged the pipeline into Hugging Face Diffusers. ChronoEdit reframes image editing as a temporal reasoning task, like generating a tiny video. This makes it good for maintaining consistency in edits and upscales. It’s a heavy model, requiring ~34GB of VRAM, and for aggressive upscaling, specialized tools might still be better. But for moderate upscales where temporal coherence matters, it’s a very interesting new tool in the toolbox.
Phew, we made it through this dense week! Looking to next week, I’ll be recoridng the show live from the AI Engieer CODE summit in NY, and we’ll likely see a few good releases from the big G? Maybe? finally?
TL;DR and Show Notes
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co-Hosts - @WolframRvnwlf, @yampeleg, @ldjconfirmed
Guest: Dima Duev - SDK team Wandb
Guest: Paul Asjes - Eleven Labs (@paul_asjes)
Open Source LLMs
Terminal-Bench 2.0 and Harbor launch (X, Blog, Docs, Announcement)
Baidu releases ERNIE-4.5-VL-28B-A3B-Thinking (X, HF, GitHub, Blog, Platform)
Project AELLA (OSSAS): 100K LLM-generated paper summaries (X, HF)
WeiboAI’s VibeThinker-1.5B (X, HF, Arxiv, Announcement)
Code Arena — live, agentic coding evaluations (X, Blog, Announcement)
Big CO LLMs + APIs
This weeks Buzz
Voice & Audio
AI Art & Diffusion & 3D


