




Brief outline for your convenience:
[00:00] Introduction by Alex Volkov
[06:00] Discussing the Platypus models and data curation process by Ariel, Cole and Nathaniel
[15:00] Merging Platypus with OpenOrca model by Alignment Labs
Combining strengths of Platypus and OpenOrca
Achieving state-of-the-art 13B model
[40:00] Mixture of Experts (MOE) models explanation by Prateek and Far El
[47:00] Ablation studies on different fine-tuning methods by Teknium
Full transcript is available for our paid subscribers 👇 Why don’t you become one?
Here’s a list of folks and models that appear in this episode:
ThursdAI cohosts - Alex Volkov, Yam Peleg, Nisten Tajiraj
Alignment Lab - Austin, Teknium (Discord server)
SkunkWorks OS - Far El, Prateek Yadav, Alpay Ariak (Discord server)

I am recording this on August 18th, which marks the one month birthday of the Lama 2 release from Meta. It was the first commercially licensed large language model of its size and quality, and we want to thank the great folks at MetaAI. Yann LeCun, BigZuck and the whole FAIR team. Thank you guys. It's been an incredible month since it was released.
We saw a Cambrian explosion of open source communities who make this world better, even since Lama 1. For example, LLaMa.Cpp by Georgi Gerganov is such an incredible example of how open source community comes together and this one guy in the weekend Took the open source weights and made it run on CPUs and much, much faster.
Mark Zuckerberg even talked about this, how amazing the open source community has adopted LLAMA, and that Meta is also now adopting many of those techniques and developments back to run their own models cheaper and faster. And so it's been exactly one month since LLAMA 2 was released.
And literally every ThursdAI since then, we have covered a new state of the art open source model all based on Lama 2 that topped the open source model charts on Hugging Face.
Many of these top models were fine tuned by Discord organizations of super smart folks who just like to work together in the open and open source their work.
Many of whom are great friends of the pod.
Nous Research, with whom we've had a special episode a couple of weeks back Teknium1 seems to be part of every orgm Alignment Labs and GarageBaind being the last few folks topping the charts.
I'm very excited not to only bring you an interview with Alignment Labs and GarageBaind, but also to give you a hint of two additional very exciting efforts that are happening in some of these discords.
I also want to highlight how many of those folks do not have data scientist backgrounds. Some of them do. So we had a few PhDs or PhD studies folks, but some of them studied all this at home with the help of GPT 4. And some of them even connected via ThursdAI community and space, which I'm personally very happy about.
So this special episode has two parts. The first part we're going to talk with Ariel. Cole and Natniel, currently known as GarageBaind, get it? bAInd, GarageBaind, because they're doing AI in their garage. I love it.
🔥 Who are now holding the record for the best performing open source model called Platypus2-70B-Instruct.
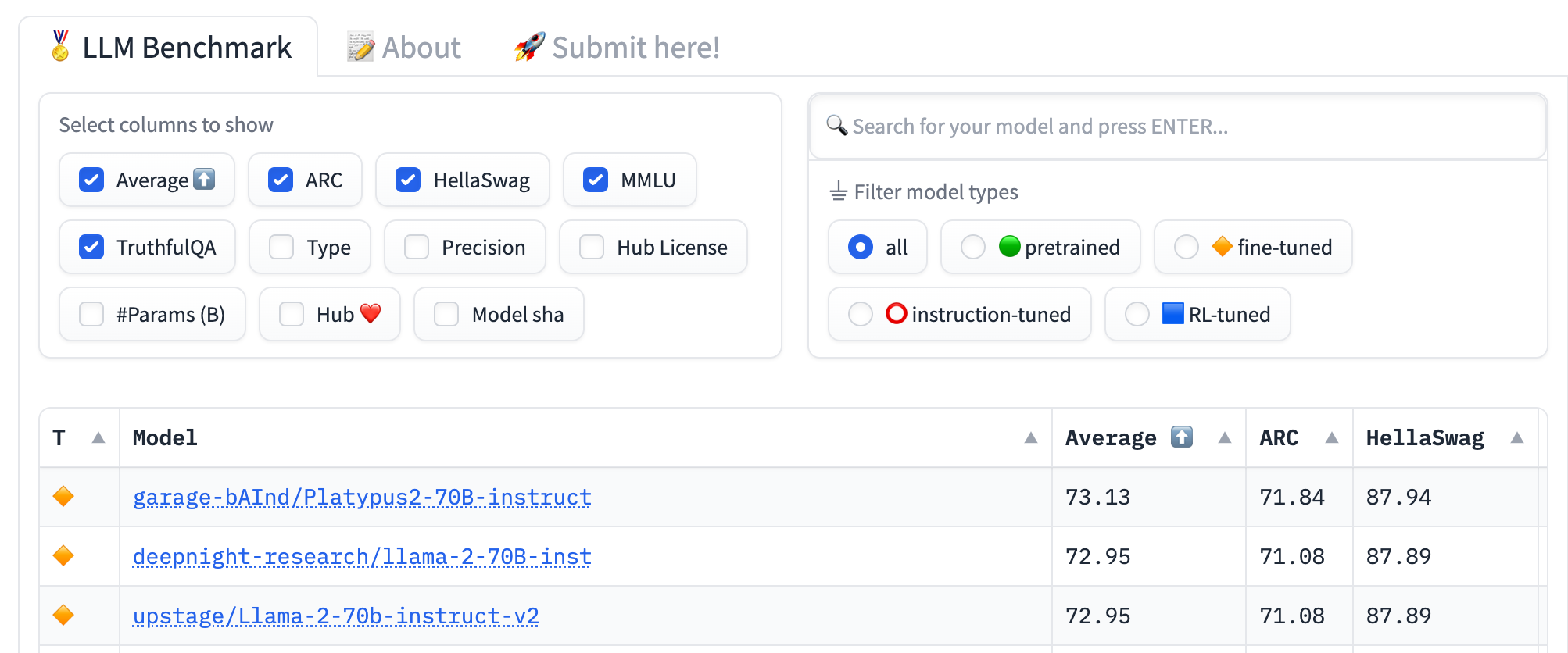
And then, joining them is Austin from Alignment Labs, the authors of OpenOrca, also a top performing model, will talk about how they've merged and joined forces and trained the best performing 13b model called Open Orca Platypus 13B or Orctypus 13B

This 13b parameters model comes very close to the Base Llama 70b. So, I will say this again, just 1 month after Lama 2 released by the great folks at Meta, we now have a 13 billion parameters model, which is way smaller and cheaper to run that comes very close to the performance benchmarks of a way bigger, very expensive to train and run 70B model.
And I find it incredible. And we've only just started, it's been a month. And so the second part you will hear about two additional efforts, one run by Far El, Prateek and Alpay from the SkunksWorks OS Discord, which is an effort to bring everyone an open source mixture of experts model, and you'll hear about what mixture of experts is.
And another effort run by a friend of the pod Teknium previously a chart topper himself with Nous Hermes models and many others, to figure out which of the fine tuning methods are the most efficient. and fast and cheap to run. You will hear several mentions of LORAs, which stand for Low Rank Adaptation, which are basically methods of keeping the huge weights of LAMA and other models frozen and retrain and fine tune and align some specific parts of it with new data, which is a method we know from Diffusion World.
And it's now applying to the LLM world and showing great promise in how fast, easy, and cheap it is to fine tune these huge models with significantly less hardware costs and time. Specifically, Nataniel Ruiz, the guy who helped Ariel and Cole to train Platypus, the co-author on DreamBooth, StyleDrop and many other diffusion methods, mentioned that it takes around five hours on a single A100 GPU to fine tune the 13B parameter model. That, if you can find an A100 GPU, that's around $10.
That's incredible.
I hope you enjoy listening and learning from these great folks, and please don’t forget to checkout our website at thursdai.news for all the links, socials and podcast feeds.
Brief outline for your convinience:
[00:00] Introduction by Alex Volkov
[06:00] Discussing the Platypus models and data curation process by Ariel, Cole and Nathaniel
[15:00] Merging Platypus with OpenOrca model by Alignment Labs
Combining strengths of Platypus and OpenOrca
Achieving state-of-the-art 13B model
[40:00] Mixture of Experts (MOE) models explanation by Prateek and Far El
[47:00] Ablation studies on different fine-tuning methods by Teknium
Full transcript is available for our paid subscribers 👇 Why don’t you become one?







