




Hey folks,
What an absolute packed week this week, which started with yet another crazy model release from OpenAI, but they didn't stop there, they also announced GPT-5 winning the ICPC coding competitions with 12/12 questions answered which is apparently really really hard!
Meanwhile, Zuck took the Meta Connect 25' stage and announced a new set of Meta glasses with a display! On the open source front, we yet again got multiple tiny models doing DeepResearch and Image understanding better than much larger foundational models.
Also, today I interviewed Jeremy Berman, who topped the ArcAGI with a 79.6% score and some crazy Grok 4 prompts, a new image editing experience called Reve, a new world model and a BUNCH more! So let's dive in! As always, all the releases, links and resources at the end of the article.
Table of Contents
Meta Connect 25 - The new Meta Glasses with Display & a neural control interface
Jeremy Berman: Beating frontier labs to SOTA score on ARC-AGI
This Week’s Buzz: Weave inside W&B models—RL just got x-ray vision
Ray3: Luma’s “reasoning” video model with native HDR, Draft Mode, and Hi‑Fi mastering
World models are getting closer - Worldlabs announced Marble
Codex comes full circle with GPT-5-Codex agentic finetune (X, OpenAI Blog)
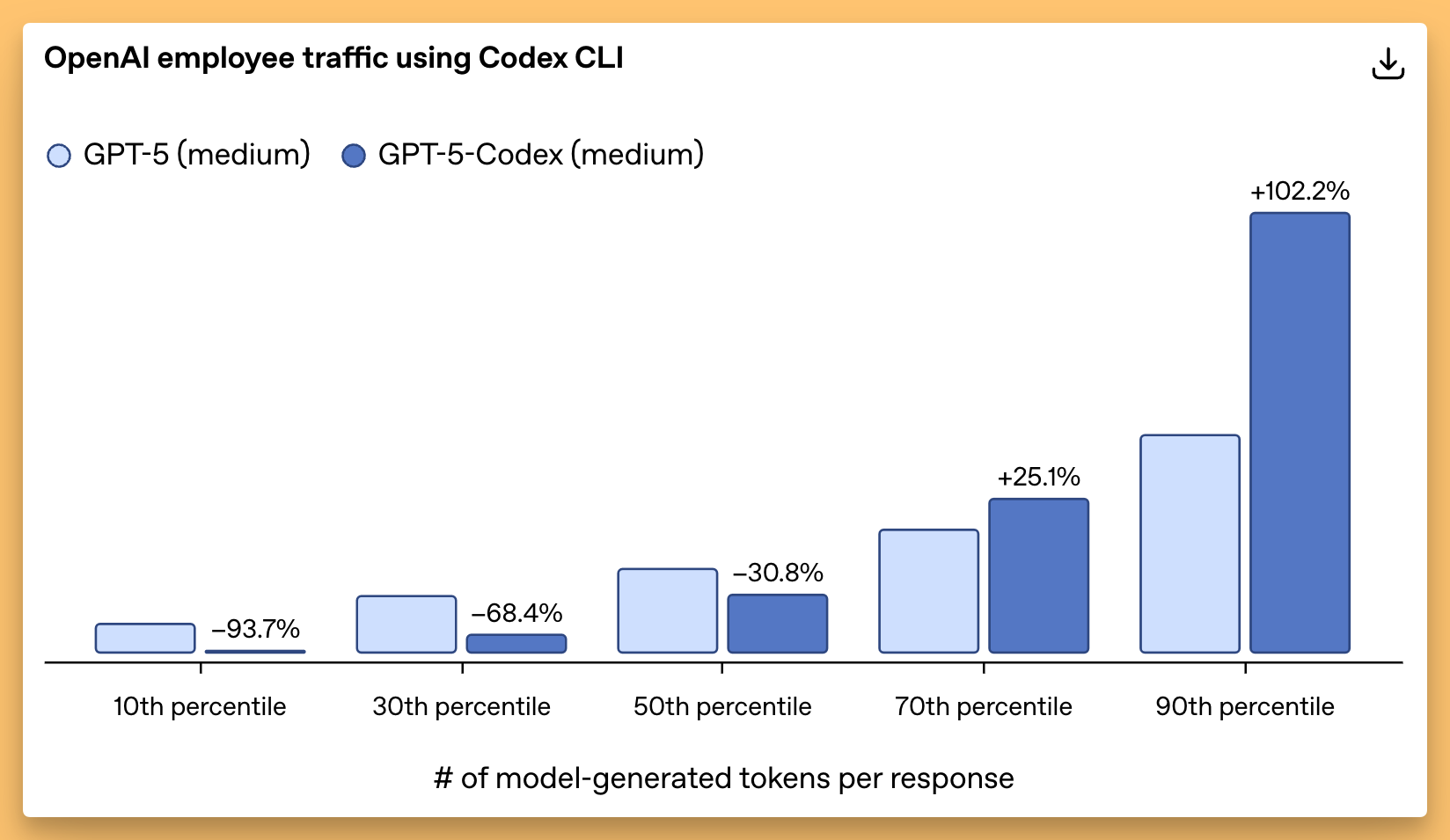
My personal highlight of the week was definitely the release of GPT-5-Codex. I feel like we've come full circle here. I remember when OpenAI first launched a separate, fine-tuned model for coding called Codex, way back in the GPT-3 days. Now, they've done it again, taking their flagship GPT-5 model and creating a specialized version for agentic coding, and the results are just staggering.
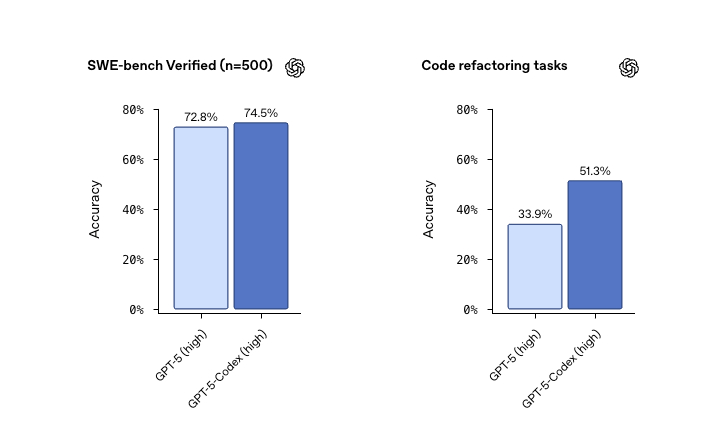
This isn't just a minor improvement. During their internal testing, OpenAI saw GPT-5-Codex work independently for more than seven hours at a time on large, complex tasks—iterating on its code, fixing test failures, and ultimately delivering a successful implementation. Seven hours! That's an agent that can take on a significant chunk of work while you're sleeping. It's also incredibly efficient, using 93% fewer tokens than the base GPT-5 on simpler tasks, while thinking for longer on the really difficult problems.
The model is now integrated everywhere - the Codex CLI (just npm install -g codex), VS Code extension, web playground, and yes, even your iPhone. At OpenAI, Codex now reviews the vast majority of their PRs, catching hundreds of issues daily before humans even look at them. Talk about eating your own dog food!
Other OpenAI updates from this week
While Codex was the highlight, OpenAI (and Google) also participated and obliterated one of the world’s hardest algorithmic competitions called ICPC. OpenAI used GPT-5 and an unreleased reasoning model to solve 12/12 questions in under 5 hours.
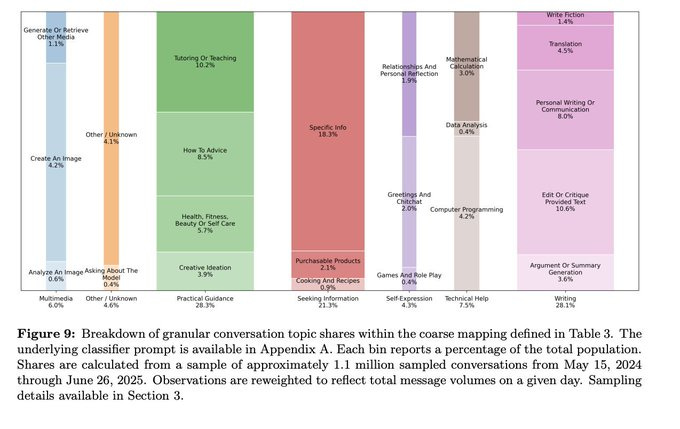
OpenAI and NBER also released an incredible report on how over 700M people use GPT on a weekly basis, with a lot of insights, that are summed up in this incredible graph:
Meta Connect 25 - The new Meta Glasses with Display & a neural control interface

Just when we thought the week couldn't get any crazier, Zuck took the stage for their annual Meta Connect conference and dropped a bombshell. They announced a new generation of their Ray-Ban smart glasses that include a built-in, high-resolution display you can't see from the outside. This isn't just an incremental update; this feels like the arrival of a new category of device. We've had the computer, then the mobile phone, and now we have smart glasses with a display.

The way you interact with them is just as futuristic. They come with a "neural band" worn on the wrist that reads myoelectric signals from your muscles, allowing you to control the interface silently just by moving your fingers. Zuck's live demo, where he walked from his trailer onto the stage while taking messages and playing music, was one hell of a way to introduce a product.
This is how Meta plans to bring its superintelligence into the physical world. You'll wear these glasses, talk to the AI, and see the output directly in your field of view. They showed off live translation with subtitles appearing under the person you're talking to and an agentic AI that can perform research tasks and notify you when it's done. It's an absolutely mind-blowing vision for the future, and at $799, shipping in a week, it's going to be accessible to a lot of people. I've already signed up for a demo.
Jeremy Berman: Beating frontier labs to SOTA score on ARC-AGI
We had the privilege of chatting with Jeremy Berman, who just achieved SOTA on the notoriously difficult ARC-AGI benchmark using checks notes... Grok 4! 🚀
He walked us through his innovative approach, which ditches Python scripts in favor of flexible "natural language programs" and uses a program-synthesis outer loop with test-time adaptation. Incredibly, his method achieved these top scores at 1/25th the cost of previous systems

This is huge because ARC-AGI tests for true general intelligence - solving problems the model has never seen before. The chat with Jeremy is very insightful, available on the podcast starting at 01:11:00 so don't miss it!
This Week’s Buzz: Weave inside W&B models—RL just got x-ray vision
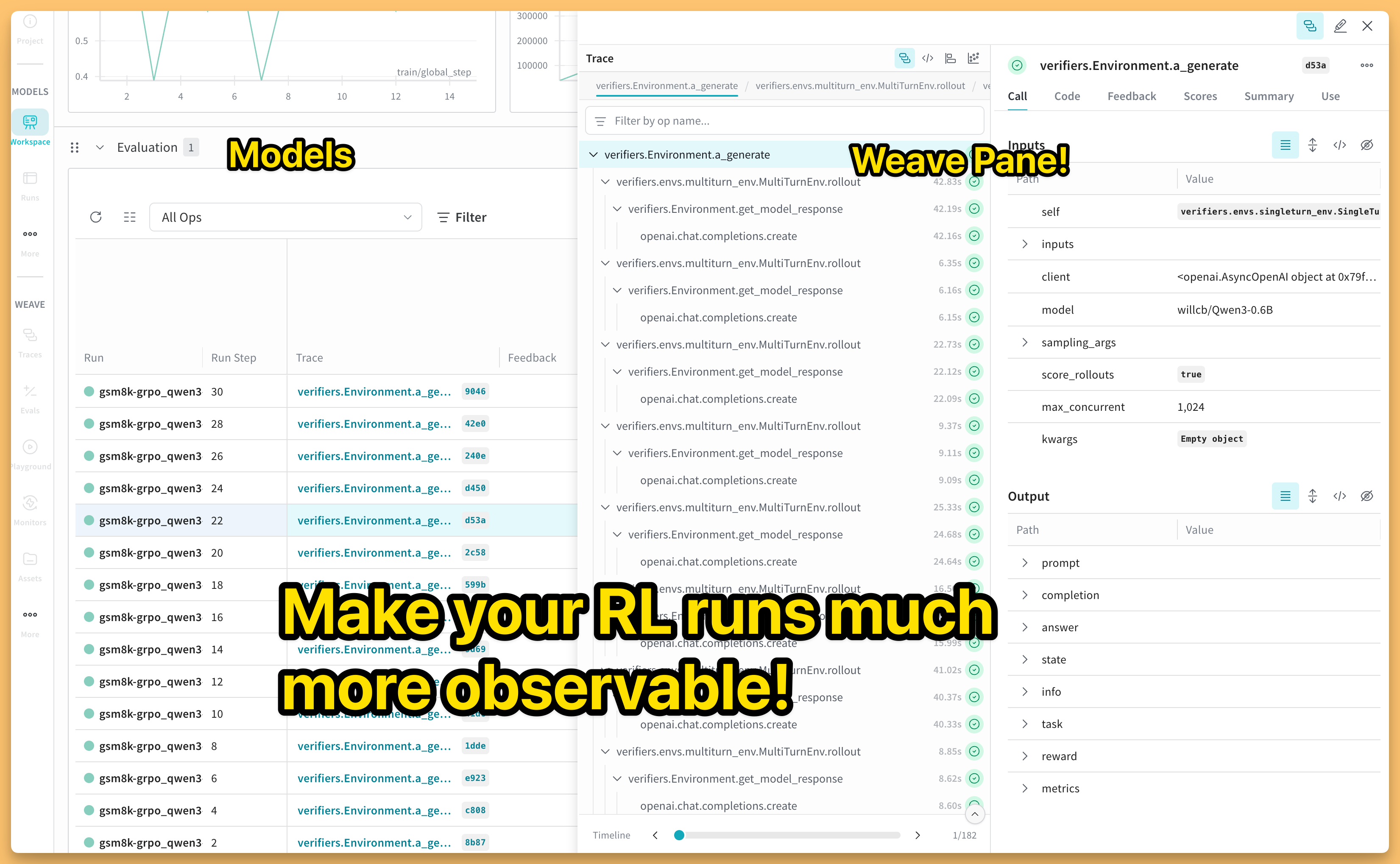
You know how every RL project produces a mountain of rollouts that you end up spelunking through with grep? We just banished that misery. Weave tracing now lives natively inside every W&B Workspace run. Wrap your training-step and rollout functions in @weave.op, call weave.init(), and your traces appear alongside loss curves in real time. I can click a spike, jump straight to the exact conversation that tanked the reward, and diagnose hallucinations without leaving the dashboard. If you’re doing any agentic RL, please go treat yourself. Docs: https://weave-docs.wandb.ai/guides/tools/weave-in-workspaces
Open Source
Open source did NOT disappoint this week as well, we've had multiple tiny models beating the giants at specific tasks!
Perceptron Isaac 0.1 - 2B model that points better than GPT ( X, HF, Blog )
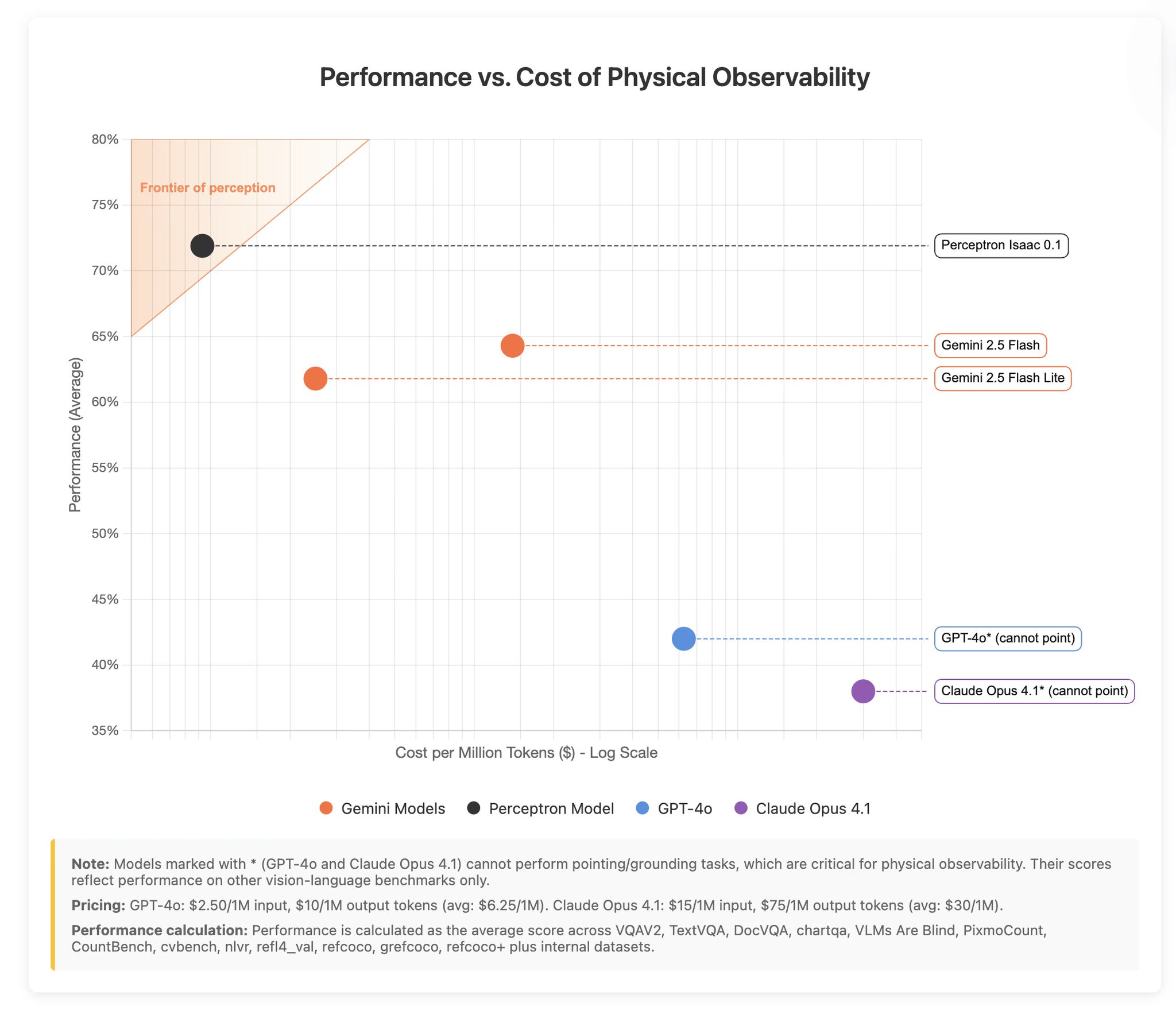
One of the most impressive demos of the week came from a new lab, Perceptron AI. They released Isaac 0.1, a tiny 2 billion parameter "perceptive-language" model. This model is designed for visual grounding and localization, meaning you can ask it to find things in an image and it will point them out. During the show, we gave it a photo of my kid's Harry Potter alphabet poster and asked it to "find the spell that turns off the light."
Not only did it correctly identify "Nox," but it drew a box around it on the poster. This little 2B model is doing things that even huge models like GPT-4o and Claude Opus can't, and it's completely open source. Absolutely wild.
Moondream 3 preview - grounded vision reasoning 9B MoE (2B active) (X, HF)

Speaking of vision reasoning models, just a bit after the show concluded, our friend Vik released a demo of Moondream 3, a reasoning vision model 9B (A2B) that is also topping the charts! I didn't have tons of time to get into this, but the release thread shows this to be an exceptional open source visual reasoner also beating the giants!
Tongyi DeepResearch: A3B open-source web agent claims parity with OpenAI Deep Research ( X, HF )
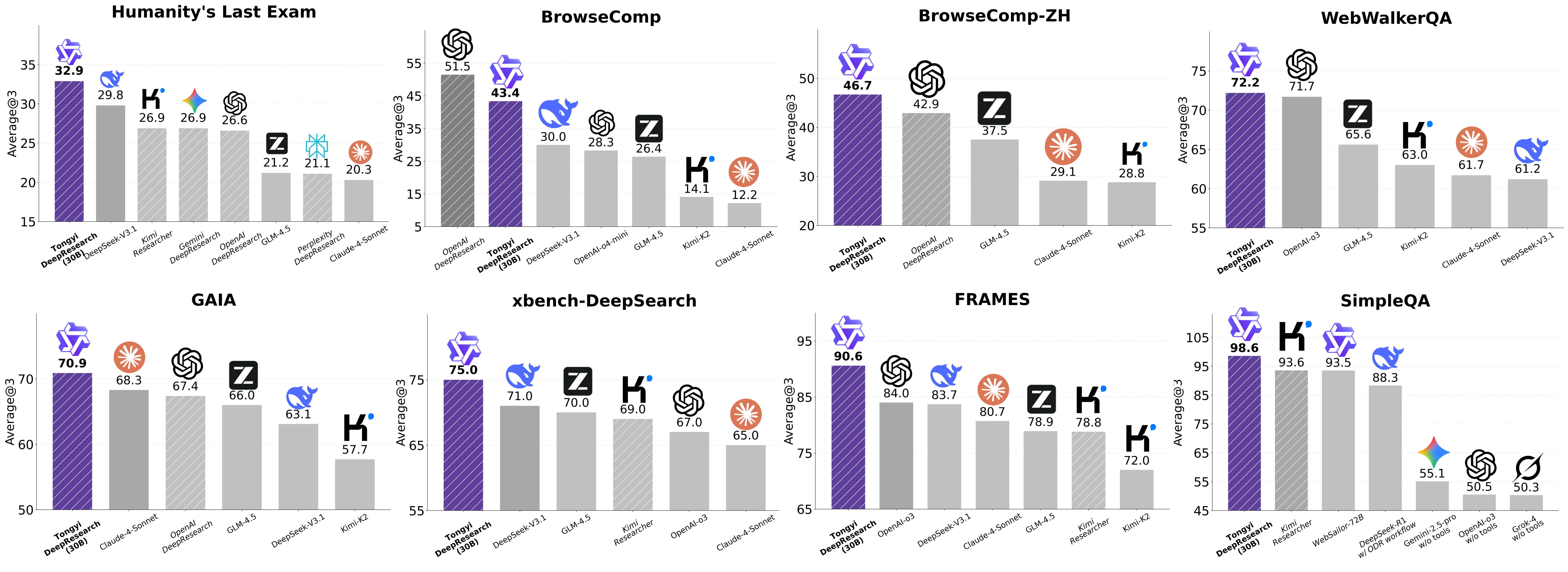
Speaking of smaller models obliterating huge ones, Tongyi released a bunch of papers and a model this week that can do Deep Research on the level of OpenAI, even beating it, with a Qwen Finetune with only 3B active parameters!
With insane scores like 32.9 (38.3 in Heavy mode) on Humanity's Last Exam (OAI Deep Research gets 26%) and an insane 98.6% on SimpleQA, this innovative approach uses a lot of RL and synthetic data to train a Qwen model to find what you need. The paper is full of incredible insights into how to build automated RL environments to get to this level.
AI Art, Diffusion 3D and Video
This category of AI has been blowing up, we've seen SOTA week after week with Nano Banana then Seedream 4 and now a few more insane models.

Tencent's Hunyuan released SRPO (X, HF, Project, Comparison X)(Semantic Relative Preference Optimization) which is a new method to finetune diffusion models quickly without breaking the bank. Also released a very realistic looking finetune trained with SRPO. Some of the generated results are super realistic, but it's more than just a model, there's a whole new method of finetuning here!

Hunyuan also updated their 3D model and announced a full blown 3D studio that does everything from 3D object generation, meshing, texture editing & more.
Reve launches a 4-in-1 AI visual platform taking on Nano 🍌 and Seedream (X, Reve, Blog)
A newcomer, Reve has launched a comprehensive new AI visual platform bundling image creation, editing, remixing, creative assistant, and API integration, all aimed at making advanced editing as accessible, all using their own proprietary models.
What stood out to me though, is the image editing UI, which allows you to select on your image exactly what you want to edit, write a specific prompt for that thing (change color, objects, add text etc') and then hit generate and their model takes into account all those new queues! This is way better than just ... text prompting the other models!
Ray3: Luma’s “reasoning” video model with native HDR, Draft Mode, and Hi‑Fi mastering (X, Try It)
Luma released the third iteration of their video model called Ray, and this one does.. HDR! But it also has Draft Mode (for quick iteration), first/last frame interpolation, and they claim to be "production ready" with extreme prompt adherence.
The thing that struck me is the reasoning part, their video model is now reasoning, to let you create more complex scenes, while the model will ... evaluate itself and select the best generation for you! This is quite bonkers, can't wait to play with it!
World models are getting closer - Worldlabs announced Marble (Demo)
We've covered a whole host of world models, Genie3, Hunyuan 3D world models, Mirage and a bunch more!
Dr FeiFei's WorldLabs have been one of the first ones to tackle the world model concept and their recent release shows incredible progress (and finally lets us play with it!)
Marble takes images and creates Gussian Splats, that can be used in 3D environments. So now you can use any AI image generation and turn it into a walkable 3D world!
Google puts Gemini in Chrome (X, Blog)
This happened after the show today and while not fully rolled out yet, I've told you before when we covered Comet from PPXL and Dia from browser company, that Google will not be far behind!
So today they announced that Gemini is coming to Chrome, and will allow users to chat with a bunch of their tabs, summarize across tabs and soon do agentic tasks like clicking things and shopping for you? 😅
I wonder if this means that Google will offer this for free to the over 1B chrome users or introduce some sort of Gemini tier cross-over? Remains to be seen but very exciting to see AI browsers all over!
The best feature could be a hidden one, where the Gemini in Chrome will have knowledge about your surfing history and you'll be able to ask it about that one website you visited a while ago that had sharks!
Folks, I can go on and on today, literally there's a new innovative video model from ByteDance, a few more image models, but alas, I have to prioritize and give you only the top important news. So, I'll just remind that I put all the links in the TL;DR below and that you should absolutely check out the video version of our show on YT because a lot of visual things are happening and we're playing with all of them live!
See you next week 🫡 Don't forget to subscribe (and if you already subbed, share this with a friend or two?)
TL;DR and show notes - September 18, 2025
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf @ldjconfirmed @nisten
Guest : Jeremy Berman (@jerber888) - SOTA on ARC- AGI
Open Source
Big CO LLMs + APIs
GPT-5-Codex release: Agentic coding upgrade for Codex (X, OpenAI Blog)
Meta Connect - New AI glasses with display, new AI mode (X Recap)
NBER & OpenAI - How People Use ChatGPT: Growth, Demographics, and Scale (X, Blog, NBER Paper)
ARC-AGI: New SOTA by Jeremy Berman and Eric Pang using Grok-4 (X, Blog)
OpenAI’s reasoning system aces 2025 ICPC World Finals with a perfect 12/12 (X)
OpenAI adds thinking budgets to ChatGPT app (X)
Gemini in Chrome: AI assistant across tabs + smarter omnibox + safer browsing (X, Blog)
Anthropic admits Claude bugs - Detailed analysis
This weeks Buzz
W&B Models + Weave! You can now log your RL runs in W&B Weave 👏 (X, W&B Link)
W&B Fully Connected London - tickets are running out! Use
FCLNTHURSAIfor a free ticket on me! (Register Here)
Vision & Video
Voice & Audio
AI Art & Diffusion & 3D
Tools
Chrome adds Gemini (Blog)



