



Ho, ho, holy moly, folks! Alex here, coming to you live from a world where AI updates are dropping faster than Santa down a chimney! 🎅 It's been another absolutely BANANAS week in the AI world, and if you thought last week was wild, and we're due for a break, buckle up, because this one's a freakin' rollercoaster! 🎢
We've got Google throwing haymakers with Veo 2 (the video above is 1 shot VEO2 generation!) and Gemini reasoning, OpenAI showering us with API goodies and price drops, and enough open-source drama to make a reality TV show blush. 🎭 Seriously, I barely had time to decorate my tree! 🎄 But hey, who needs tinsel when you've got groundbreaking AI models to unwrap? 🎁
As always, I'm joined by my incredible crew - Wolfram, LDJ, Nisten, and we even had some amazing guests like Blaine Brown and Kwindla drop in (2nd week in a row) - to break it all down for you. So, grab your eggnog (or something stronger, you may need it 😉), and let's dive into this week's AI crazyness (and as always, TL;DR and show notes and links at the end of the post)
Breaking News: Google's Gemini 2.0 Flash Thinking Experimental
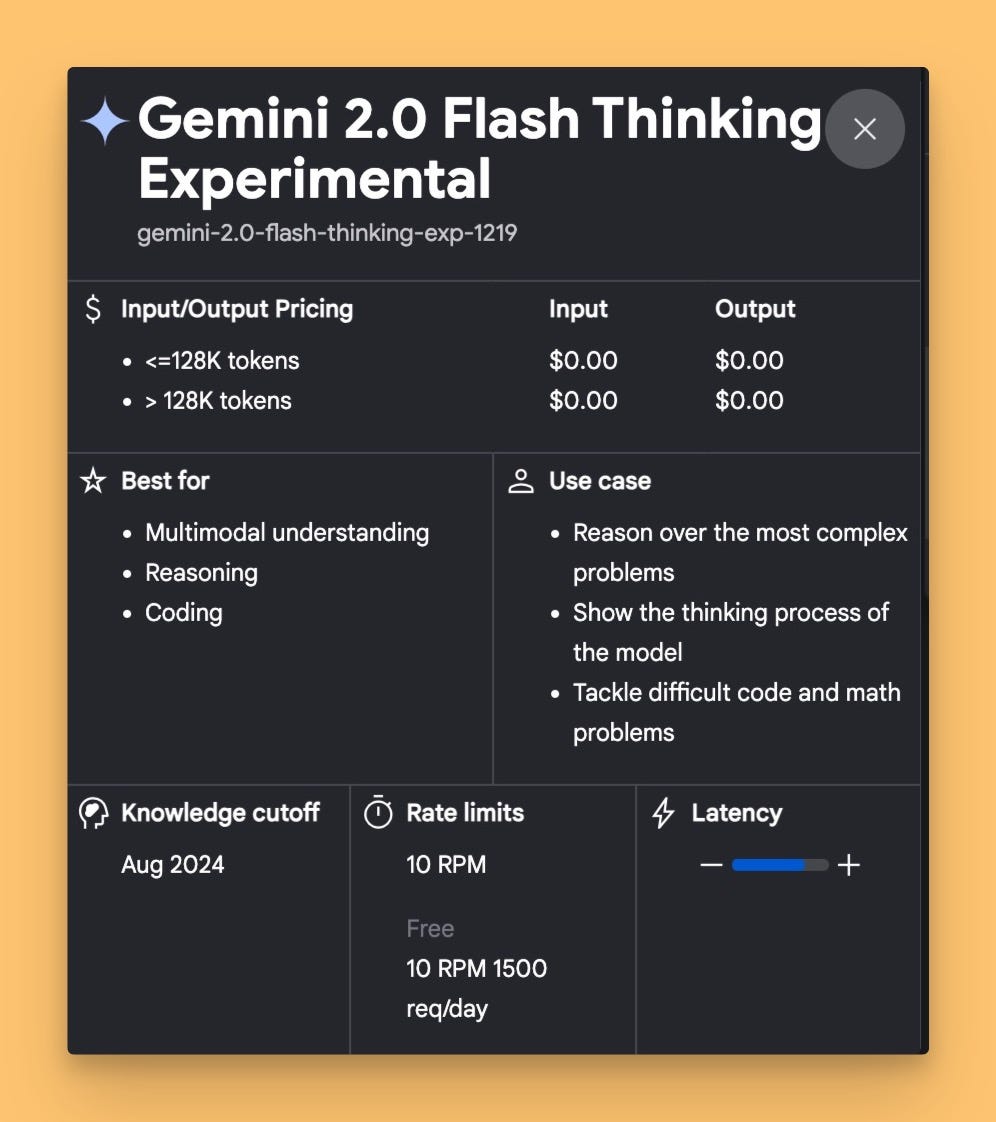
Just as the show started, Logan Kilpatrick from Google dropped a tweed to tell us that they just released Gemini 2.0 Flash Thinking Experimental - a model trained to think out loud, which means we can see its reasoning process. 🤯 We even got Noam Shazeer, the legendary author of the "Attention Is All You Need" paper, chiming in on it (and he's unusually quiet since the return to Google)
Of course, we had to try it live, and the results were... interesting. We threw the infamous ice cubes question at it, and while it stumbled a bit at first, when we adjusted the temperature to zero, it nailed it - after 29 seconds of thinking out loud. This model also tackled Nisten’s Martian Mountain problem, Nisten noted, that even "Sonnet gets it, but it takes a few times. This actually got it. The answer's right, 324K" This is a big deal because, unlike OpenAI, Google seems to be showing us the whole thinking trace. As I put it "It feels like we're seeing the whole thinking trace, unlike OpenAI who's hiding the thinking trace, folks." It seems that after R1 from Deepseek and QwQ from Qwen, the thinking was unlocked, so o1 hiding their reasoning traces seems… un-nessesary at this point.
Open Source LLMs: Meta's Apollo Vanishes, Microsoft's Phi-4 Looms, and Cohere's Command R Flexes
Alright, let's kick things off with the wild west of open source! 🤠 It's been a minute since we've properly covered open source, but this week, the drama was too good to ignore.
Meta's Apollo 7B: The Vanishing Video Virtuoso
First up, we had Meta's Apollo 7B, a large multimodal model that promised SOTA video understanding. This bad boy could understand video content, see pictures, understand actions, and even track scene changes. We're talking about a model that could process videos up to one hour long, folks! Nisten was particularly hyped about this one, saying, "We don't have any other tool that does this besides Gemini" Especially, he adds, "if you're doing stuff around the desktop" And it wasn't just hype – the 3B version outperformed most 7B models, scoring 55.1 on LongVideoBench, while the 7B crushed it with 70.9 on MLVU and 63.3 on Video-MME.
But then, POOF! 💨 Like a digital David Copperfield, Meta pulled Apollo from Hugging Face. Vanished! Some speculated it was because it was built on top of Qwen, as Wolfram pointed out, "the 3B model, original model from Qwen was a research license, so there was a license in conflict, which could be an explanation for pull." Nisten added further that they were using "the Qwen vision model for the 7B...the 7B is Apache licensed. So maybe they could have a case for pulling the 3B because they didn't have the license for it." But don't worry, our amazing community swooped in like open-source superheroes. Nisten, who had a "bad dream at 4am and woke up and people are complaining the model is taken off," managed to find it and reuploaded it as Apollonia-7b, ensuring this powerful model didn't disappear into the digital ether. As he put it "there's nothing illegal or bad going on in case people are wondering it's just like we're just trying to keep the source code up" It's the Barbara Streisand effect in full force! You try to hide something on the internet, and it just gets MORE attention. 😂
Microsoft's Phi-4: The Tiny Titan Taking on Math

Next, we had the long-awaited Phi-4 from Microsoft. Remember last week when I was losing my mind because EVERYONE was releasing stuff on the same day? Well, Microsoft promised us Phi-4 then, and they finally delivered... sort of. It's currently only available on Azure Foundry but it will supposedly hit HuggingFace soon. And of course, the community already delivered before MS, there are a LOT of copies of Phi-4 on the hub, one just needs to search.
This 14B parameter SLM (Small Language Model) is a beast when it comes to math. They're boasting about its performance on math competition problems, where it's apparently outperforming much larger models like Gemini Pro 1.5. According to their internal testing, "Phi-4 outperforms comparable and larger models on math related reasoning due to advancements throughout the processes, including the use of high-quality synthetic datasets, curation of high-quality organic data, and post-training innovations." What's interesting is the use of synthetic data, which, they say "constitutes the bulk of the training data for phi-4."
Phi was always very interesting, tho in the realm of smaller models, now that they are playing in the 14B area, remains to be seen if this model is going to be userful for folks.
Cohere's Command R 7B: The Enterprise Efficiency Expert

Cohere, our friends in the enterprise LLM space, dropped Command R 7B, the "smallest, fastest, and final model" in their R series. This model is all about efficiency, designed to run on low-end GPUs, laptops, and even CPUs. Wolfram gave it a thumbs up, and it's topping the Hugging Face Open LLM Leaderboard for its class.
Command R 7B is laser-focused on real-world business tasks. We're talking RAG, tool use, and AI agents. It's also multilingual and excels at citation-verified RAG, which helps reduce those pesky hallucinations. They're keeping it under a CC by NC 4.0 license for now, but as Nisten mentioned "they said on Twitter that if you're a startup and you want to use it, just, just ask them." so sounds like they're willing to be flexible with smaller players.
Falcon 3 and IBM's Granite: More Open Source Goodness
We also had Falcon 3 from the UAE's Technological Innovation Institute, dropping a whole flock of models – 1B, 3B, 7B, 10B, and even a 7B Mamba variant. They're promising a multimodal version soon, too. Wolfram was impressed with its MMLU PRO computer science benchmark, where "it got 61. 22 percent which put it above, for example, the Mistral small model"
And let's not forget IBM, quietly updating their Granite 3.1 series with a 128K context length and improved function calling, all under an Apache 2.0 license. As I said in the show "I have not seen any metrics or evals", but Wolfram did, and added that "it did impress me with the benchmarks" and showed results that were "much better" than others.
Big Companies, Bigger APIs: OpenAI's O1 Unleashed and Microsoft's Copilot Goes Free!
Alright, let's move on to the big guns! 🔫 This week, the major players were all about APIs, and boy, did they deliver!
OpenAI's O1 API: It's Alive! (And It Thinks Harder)
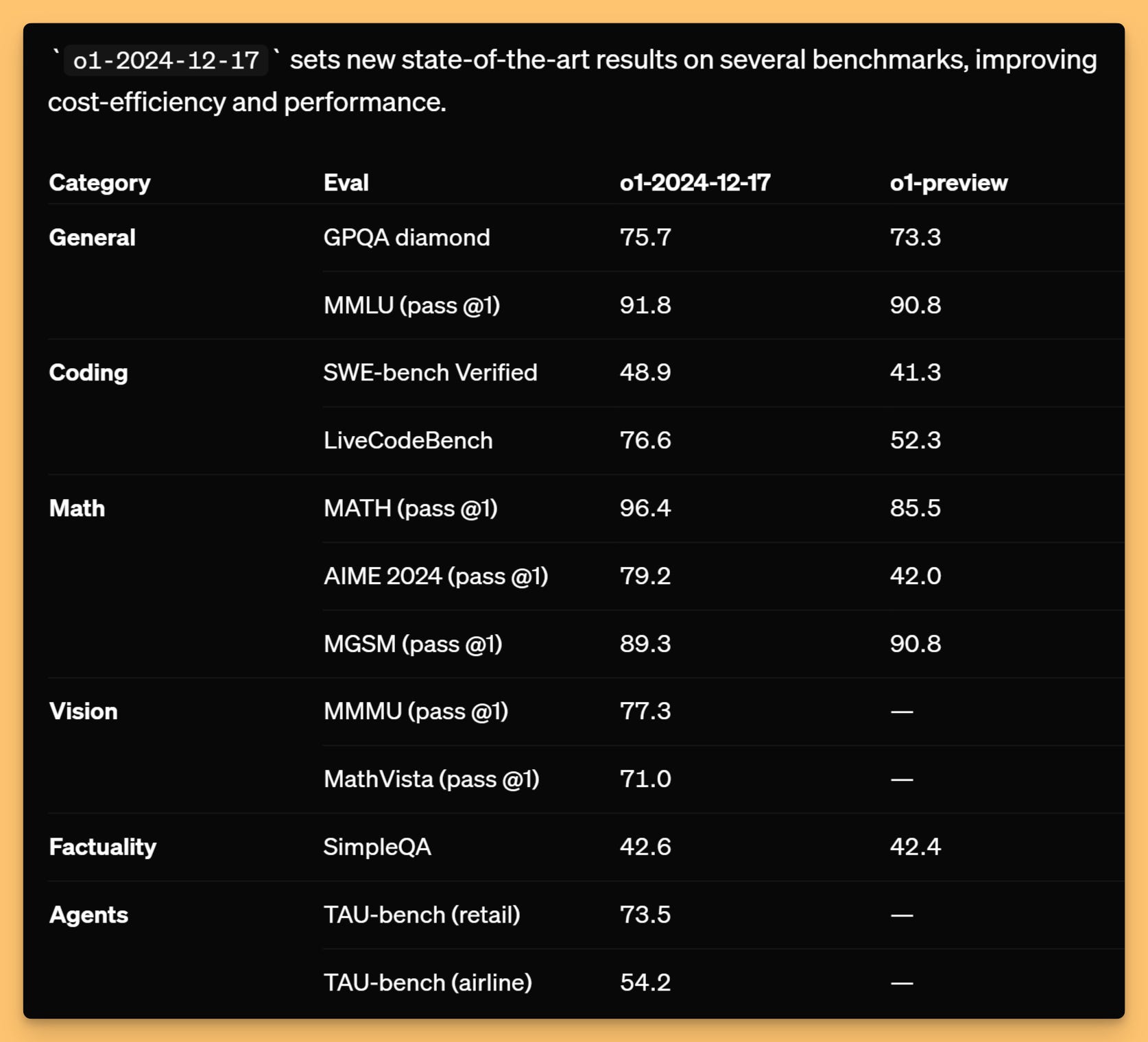
The biggest news on the show had to be OpenAI finally releasing O1 via their API. And not just any O1 – this is a new version, O1-2024-12-17, that's been further fine-tuned since the one we saw two weeks ago. This one's got 200K context (100k output), supports structured outputs, vision, and function calling.
But the REAL kicker? They renamed system messages to developer messages. Why? Because, as they explained, they want the model to "better know who the instructions are coming from." 🤯 Think about that for a second. We're now considering the model's "understanding" of who's giving the instructions as part of the API design! I find it bonkers!

And if that wasn't enough, they added a reasoning_effort parameter with three settings: [low, medium, and high]. Basically, you can now tell O1 to think harder! 🧠💥 I've been waiting for this for ages! Remember when I asked Far El about a "think harder" knob in the UI? Well, we've got it in the API now! It was verified by Arc-AGI prize as well, where there was a significant improvement from Low to High Reasoning Effort from 25% to 32% respectively.
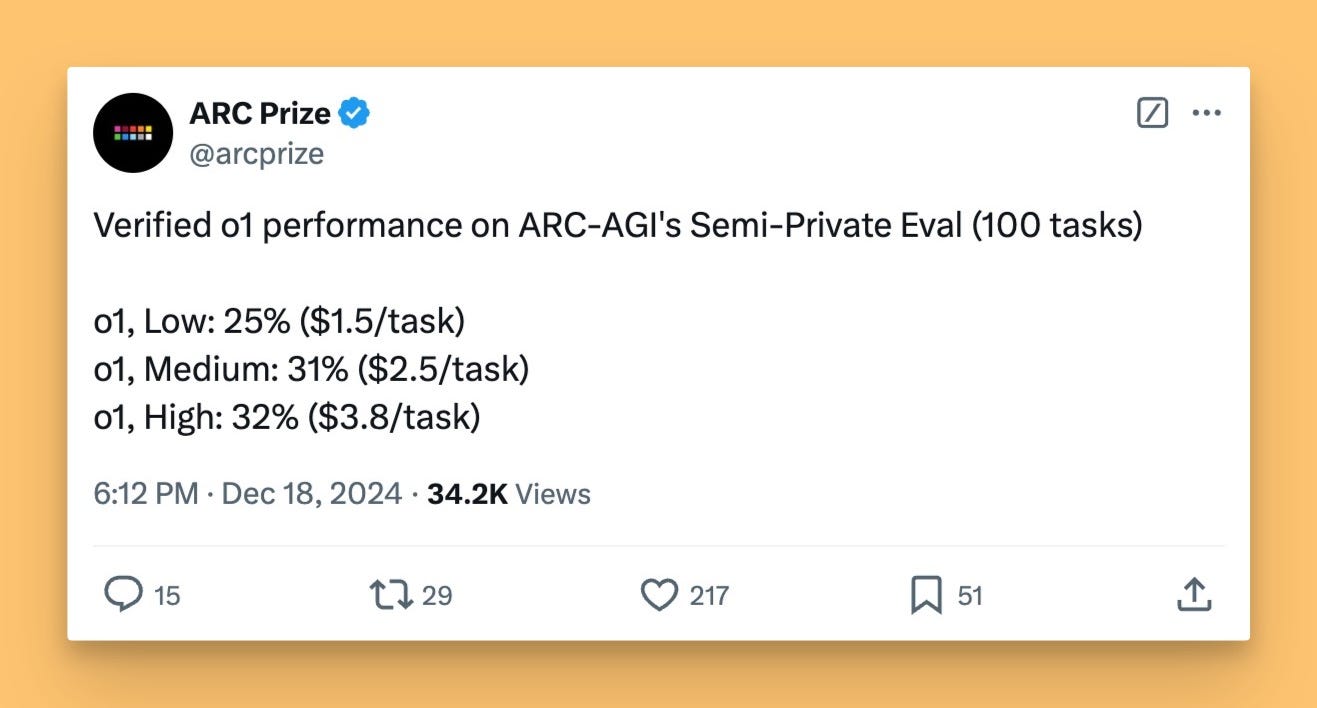
I have further evaluated that those reasoning_efforts matter (see this weeks buzz below).
Microsoft's Copilot: Free for (Almost) Everyone!
In a move that sent shockwaves through the developer community, Microsoft announced a FREE plan for GitHub Copilot! Yes, you read that right, FREE! 🎉 After, what, three years or so (time flies in AI land! ✈️), you can now get 2000 code completions and 50 chat requests per month, plus access to GPT-4o AND Claude 3.5 Sonnet.

They've also packed in a bunch of new features like multi-file editing, custom instructions, full project awareness, and even voice-based interactions. As I said on the show, "this is going to unlock just a lot of stuff" for 150 million developers around the world, especially those who haven't had access to these tools before or couldn't afford the $10/mo for copilot or $20/mo for cursor.
OpenAI's 12 Days of Releases: More Than Just a Toll-Free Number
OpenAI's 12 days of Christmas kept on giving, too. Besides the O1 API, they made search free for all users and voice mode has search, integrated Maps, and even gave us a toll-free number to call ChatGPT – 1-800-ChatGPT. Sure, some folks were disappointed it wasn't GPT-5 every day, but come on, people! Free, interruptible voice access to ChatGPT? That's HUGE! As I ranted on the show "OpenAI is like, just like shipping incredible things one after another."
🐝 This Week's Buzz : Eval Mania and Playground Fun with Weave 🛠️

Alright, time for a quick plug for my amazing team at Weights & Biases! 💖 This week, I showed off how I'm using Weave to evaluate OpenAI's new O1 model and its fancy reasoning_effort parameter and after the show I also evaluated the new reasoning model from Gemini
I ran a quick evaluation on the Simple-Bench sample benchmark with low, medium, and high reasoning effort for o1 and the new Gemini. And guess what? You can actually SEE the differences! Higher effort means longer thinking time (33 minutes for "hard"), more tokens, and, in this case, slightly better accuracy but also significantly more expensive!
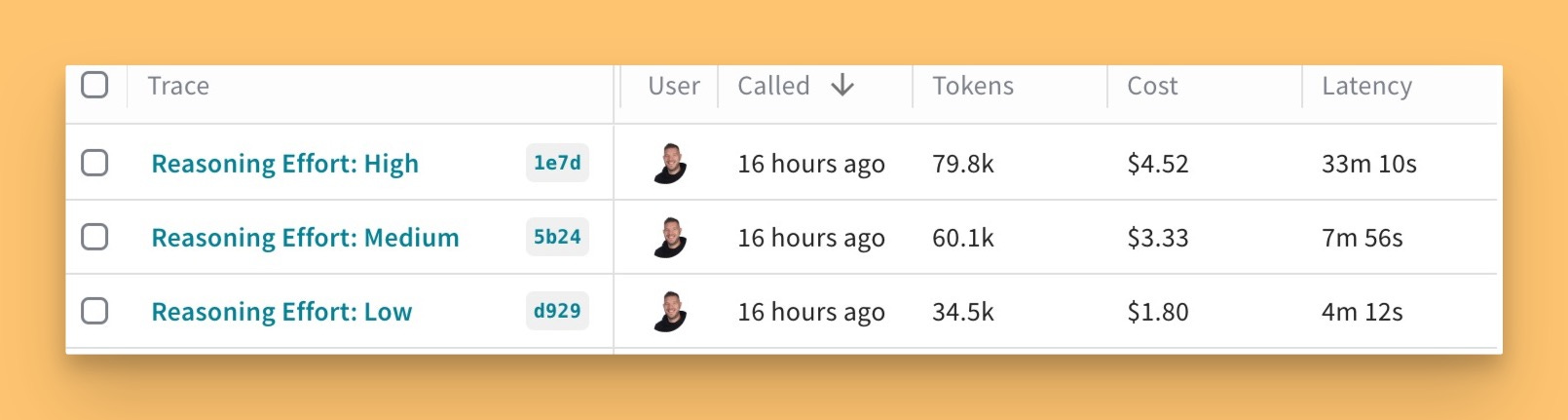
You can see my Weave dashboard here and run the code yourself in a Colab here
But the coolest part? We now have a playground where you can replay any trace and tweak the developer message to see how it affects the output. It's like a time machine for your prompts! ⏪
Wolfram was digging it, saying "seeing you use it. That's great. So I'm moving it up higher on my to do list." This made my day!
Vision & Video: Google's Veo 2 Steals Sora's Thunder ⚡
Now, let's talk about the video battle that NO ONE saw coming! 🥊
Google's Veo 2: The Physics-Defying, Steak-Cutting Champion
Just when we thought Sora was the undisputed king of video generation, Google dropped Veo 2, and folks, it's a GAME CHANGER! 🤯 This thing is so good, it's practically taken over my Twitter feed.
We had Blaine Brown, the master of viral AI videos, on the show to give us the lowdown. He compared Veo 2 to Sora with his now-infamous steak-cutting test, and the difference is, well, see for yourself. The way that steak jiggles... it's just... chef's kiss 🤌. I even saw a number of Cypher from the Matrix eating a virtual steak memes being posted under Blaine's video.
Blaine summed it up perfectly: "I think it's what everybody was expecting Sora to be... the VEO2 is really phenomenal. It's still a slot machine to some degree. I mean, it's AI, right? You're not going to get a perfect output every time, but I was blown away"
Veo 2 understands physics in a way that Sora, for all its strengths, just doesn't quite grasp. As Blaine said "the Sora steak looks dope, but there's something in the physics that doesn't quite work." It's not just about pretty pictures; it's about realistic movement and interaction.
Sora's Still Got Some Tricks Up Its Sleeve
Now, don't get me wrong, Sora's UI and tools are still incredible. Its blending feature, as Blaine demonstrated by seamlessly merging multiple Veo 2 clips of a Porsche-driving husky, is something no one else is doing. He described how he "took all the clips, took them into Sora and then used the blend, uh, function within Sora to blend them together. So SORA didn't technically generate any extension or any anything other than just figuring out how to transition with about a three, three to four second overlap between each of the VEO clips." But in terms of raw video quality and physics understanding, Veo 2 is currently eating Sora's lunch. And its steak. 🥩
Voice & Audio: Real-Time Gets Cheaper and Faster ⏩
On the audio front, OpenAI dropped some major updates to their real-time audio API. We're talking 60% cheaper tokens, WebRTC support, and a 10x cheaper 4o-mini coming soon!
WebRTC: A Game Changer for Real-Time Apps
Kwindla, our resident audio expert and creator of Pipecat, joined us to explain why WebRTC is such a big deal. It simplifies adding real-time capabilities, and OpenAI even hired the guy who created the WebRTC standard, Justin Uberti! 🤯 They also hired Sean DuBois, who is "the creator of the Pion Go WebRTC framework" As Kwindla put it, "2025 is going to be the future of real time multimodal."
Kwindla also highlighted the importance of ephemeral tokens for web-based real-time applications, which OpenAI conveniently added. This simplifies authentication and makes it easier to build real-time features without a complex server setup
AI Art & Diffusion & 3D: Enter Genesis, the Generative Physics Engine 🌌
And finally, we had the mind-bending announcement of Genesis, an open-source generative physics engine from a collaboration between MIT, NVIDIA, and a bunch of other universities.
Genesis: Simulating Reality, One Particle at a Time
This thing is like a video game engine on steroids. 💊 Apparently It can simulate all sorts of materials – rigid, articulated, cloth, liquid, smoke, you name it – and it's apparently 430,000 times faster than real-time on a single RTX 4090 GPU! 🤯
The video they released was jaw-dropping. We're talking about simulations so realistic, you'd swear they were real. The potential for robotics training here is HUGE. As I said in the show "The whole point is to be able to let robotics train in these environments that are physics based and then transfer their learnings from a simulated environment into a physical environment, what they call Sim2Real."
The Catch? No Generative UI... Yet
Now, the catch is, they haven't released the generative part yet. You know, the part where you type in a prompt and it magically creates a scene. They say it's coming "in the near future," but for now, we just have the physics engine. Which, to be fair, is still pretty damn impressive. I exclaimed in the show "this looks like we got VEO in the beginning of the week and then we got like reality generator at the end of the week. Uh, not quite."
Breaking (Again!) News - Modern BERT

Just as we were finishing up, the news broke about a friend of the pod Benjamine Clavie, and the team at Answer.ai (spearheaded by Jeremy Howard) in collaboration with LightOnIO, releasing ModernBert.
ModernBERT is a new state-of-the-art family of encoder-only language models that outperform BERT and its successors across a range of tasks while being significantly more efficient. These models are TINY compared to the LLMs we usually talk about with a base (139M params) and large (395M params) model size and are focused being finetuned on specific tasks like classification.

Honestly, this is quite an amazing achievement, reading through the blogpost, it's clear that it's about time we have a replacement for Bert or DeBerta and I'm excited to see finetunes of this model! Congrats to the teams who worked on this!
Just for context, BERT models are less hype-y than LLMs but are absolutely the work-horse of the industry, just look at the number of downloads of Bert-base last month on HuggingFace 🤯

All-righty, I might as well stop here before other releases drop and I'll need to keep writing 😅
This has been an absolutely insane week again, but I'm very happy that we finally got to cover Open Source 👏
EDIT: I knew it, as I was exporting and uploading the edited video, I looked and theres 1 more model I missed!
MMAudio is a really fun video2audio open source model, that works very fast, and shows some incredibly funny results! You prompt it with a video and some text, and well, results speak for themselves. Here are a few of my VEO generations, it’s really funny to see folks “talking” because the lipsyncing is really good but they are not speaking any language I know of, just the imitation of one. (Sound ON)
Here’s a talking podcast host speaking excitedly about his show
TL;DR - Show notes and Links
Open Source LLMs
Big CO LLMs + APIs
This weeks Buzz
Vision & Video
Voice & Audio
AI Art & Diffusion & 3D
Tools



