



Truly, as I’ve been doing these coverages in one form or another for the past 9 months, and I don’t remember a week this full of updates, news, state of the art open source models and more.
So, here’s to acceleration (and me finally facing the fact that I need a niche, and decide what I’ll update on and what I won’t, and also be transparent with all of you about it)
On a separate note, this past two weeks, ThursdAI had exposure to Yann Lecun (RTs), joined on stage by VP of DevRel in Cloudflare and their counterpart in HuggingFace, CEO of Anaconda joined us on stage this episode and we’ve had the chief scientist of Mistral join in the audience 😮 ThursdAI really shapes to be the place where this community meets, and I couldn’t be more humbled and prouder of the show, the experts on stage that join from week to week, and the growing audience 🙇♂️ ok now let’s get to the actual news!
ThursdAI - Weeks like this one highlight how important it is to stay up to date on many AI news, subscribe, I’ve got some cool stuff coming! 🔥
All right so here’s everything we’ve covered on ThursdAI, September 28th:
(and if you’d like to watch the episode video with the full transcript, it’s here for free):
[00:00:00] Intro and welcome everyone
[00:00:52] GPT4 - Vision from OpenAI
[00:05:06] Safety concern with GPT4-V
[00:09:18] GPT4 can talk and listen as well
[00:12:15] Apple rumors, on device inference, and Siri
[00:17:01] OpenAI Voice Cloning Tech used in Spotify to translate podcasts
[00:19:44] On the risks of Voice Cloning tech being open sourced
[00:26:07] Alex statement on purpose of ThursdAI
[00:27:53] “AGI has been achieved internally”;
[00:32:10] OpenAI, Jonny Ive and Masa are rumored to be working on a hardware device
[00:33:51] Cloudflare AI - Serverless GPU on global scale
[00:37:13] Cloudflare AI partnership with HuggingFace to allow you to run many models in your own
[00:40:34] Cloudflare announced the Vectorize DB and embedings on edge
[00:46:52] Cloudflare AI gateway - proxy LLM calls, caching, monitoring, statistics and fallback
[00:51:15] Part 2 - intro an recap
[00:54:14] Meta AI announcements, bringing AI agents to 3 billion people next month
[00:56:22] Meta announces EMU image model to be integrated into AI agent on every platform
[00:59:38] Meta RayBan glasses upgraded to spatial computing, with AI and camera access
[01:00:39] On the topic os smart glasses, GoogleGlass, and the acceptance society wide to have
[01:05:37] Safety and societal implications of everyone having glasses and recording everything
[01:12:05] Part 3 - Open Source LLMs, Mistral, QWEN and CapyBara
[01:21:27] Mistral 7B - SOTA 7B general model from MIstralAI
[01:23:08] On the topic of releasing datasets publically and legal challenges with obtaining that
[01:24:42] Mistral GOAT team giving us a torrrent link to a model with Apache 2 license.
Show Notes + Links
Vision
🔥 Open AI announces GPT4-Vision (Announcement, Model Card)
Meta glasses will be multimodal + AI assistant (Announcement)
Big Co + API updates
Cloudflare AI on workers, serverless GPU, Vector DB and AI monitoring (Announcement, Documentation)
Cloudflare announces partnerships with HuggingFace, Meta
Claude announces $4 billion investment from Amazon (Announcement)
Meta announces AI assistant across WhatsApp, Instagram
Open Source LLM
🔥 Mistral AI releases - Mistral 7B - beating LLaMa2 13B (Announcement, Model)
Alibaba releases Qwen 14B - beating LLaMa2 34B (Paper, Model, Vision Chat)
AI Art & Diffusion
Meta shows off EMU - new image model
Still waiting for DALL-E3 😂
Tools
Spotify translation using Open AI voice cloning tech
Vision
GPT 4-Vision
I’ve been waiting for this release since March 14th (literally) and have been waiting and talking about this on literally every ThursdAI, and have been comparing every open source multimodality image model (IDEFICS, LlaVa, QWEN-VL, NeeVa and many others) to it, and none came close!
And here we are, a brief rumor about the upcoming Gemini release (potentially a multimodal big model form Google) and OpenAi decided to release GPT-4V and it’s as incredible as we’ve been waiting for!
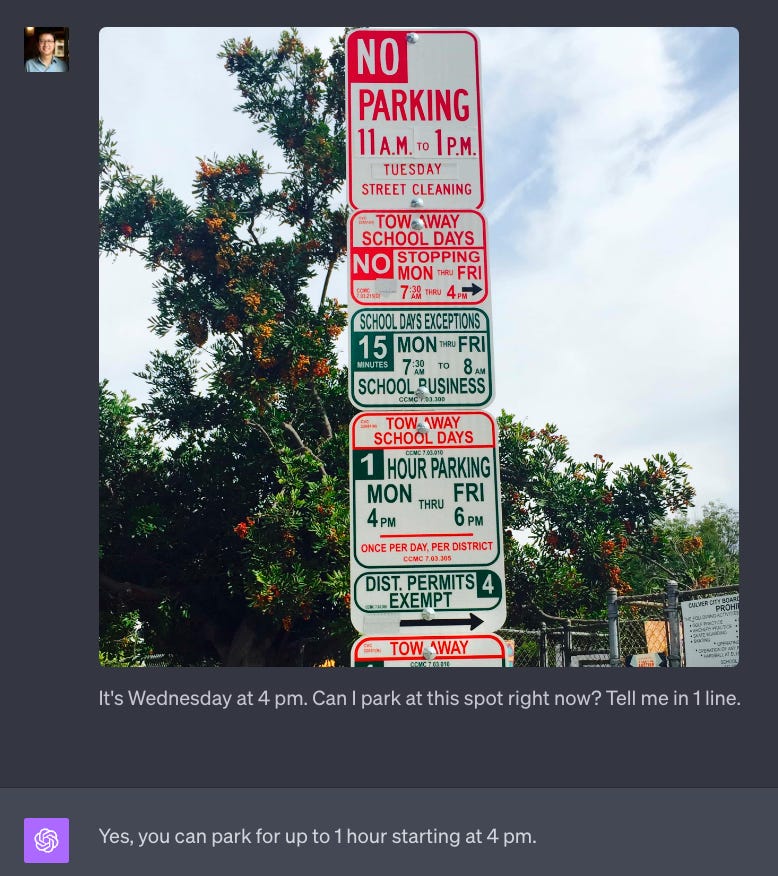
From creating components from a picture of UI, to solving complex math problems with LaTex, to helping you get out of a parking ticket by looking at a picture of a complex set of parking rules, X folks report that GPT4-V is incredibly helpful and unlocks so many new possibilities!
Can’t wait to get access, and most of all, for OpenAI to land this in the API for developers to start building this into products!
On the pod, I’ve talked about how I personally don’t believe AGI can work without vision, and how personal AI assistants are going to need to see what I see to be really helpful in the real world, and we’re about to unlock this 👀 Super exciting.
I will add this one last thing, here’s Ilya Sutskever, OpenAI chief scientist, talking about AI + Vision, and this connects with our previous reporting that GPT-4 is not natively multimodal (while we’re waiting for rumored Gobi)
If you need more use-cases, check out this great breakdown by friend of the pod, SkalskiP (Pyotr) who is a vision engineer at RoboFlow which got really high Hacker News rankings.
https://blog.roboflow.com/gpt-4-vision/
Meta RayBan smartglasses will have multimodal AI 👀
To add to the above increased interest about AI (and to rumors about OpenAI working with Jonny Ive from Apple + Masayoshi San about a rumored hardware device) Meta has announced a new iteration of their RayBan glasses, that will include a camera that will help you go live, include an AI agent in the Glasses and most of all, will be multimodal, by which they mean, the AI agent in there (we don’t know if it’s LLaMa based or something else) will have access to the camera, and to what you see.
Given how well this works, it may be revolutionary on it’s own right!
I’ve been on a MultiModality kick since that incredible March 14th day, and I’m very excited that it’s here! 🙌
Big CO + API updates
Cloudflare AI - Serverless GPU inference, VectorDB and AI Gateway
I was blown away by this, so much so, that I’ve hopped on an emergency space on Wednesday, to talk all about this. Some of you know, I’ve created https://targum.video a year ago, and it’s been accepted to CloudFlare workers launchpad. The whole website and backend is on workers, but the GPU and inference, I had to build in python and put on a LambdaLabs GPU machine.
So starting today, folks could build something like Targum, end to end on Cloudflare with the announcement of GPU inference.
If you’d like all the details, I was really humbled to host Ricky Robinette (VP Developer Experience @ Cloudflare) and Phillip Schmidt from Hugging Face join the X space on launch day (to my complete surprise) and you can find that conversation here (it’s going to be on the pod soon after I find some time to edit this 😅)
Here’s my notes from that conversation:
Inference on edge is here
Serverless GPUs on cloudflare edge network
Integrated with Workers platform
What is the workers platform
Give example of the many tools it has
Targum example for what is done on workers and what is done on GPU
Easy to get started and deploy
Will have a free tier 🔆
Models and Usecases
LLMs - LLaMa 7B
Embeddings - BGE-base
Text Classification - DistillBert
Translation - m2m100
ASR - Whisper
Preselected models right now
Vectorize - an edge native vector DB
Integrates with wrangler and ecosystem
Supports existing vectors from OpenAI Ada (importable)
Metadata can include R2 objects, KV storage and more!
Build and deploy full RAG apps, including your own local models all inside 1 platform
AI - gateway
Proxy for OpenAI (and other providers calls)
Shows a usage dashboard
Global Coverage:
Plan to be in 100 data centers by the end this year
And nearly everywhere by the end of 2024
WebGPU in workers
Many HF models support ONNX
WebGPU is now supporting FP-16
This could open a new path to run smaller models within workers even without CFAI
Partnership with HuggingFace
1 click deploy in a dropdown on half a million models
Serverless inference - no more downloading and uploading
Way faster as well
Cloudflare will have a de-facto proxy/mirror of HF? 🤔

I’m very very excited by the HuggingFace partnership and you can hear it in the recording!
Meta announces AI assistant across chat apps, Instagram, WhatsApp, Messenger

I haven’t tested this yet, but this is going to be incredible to make AI experiences to over 3B people around the world!
In addition to just “chat with AI” , Meta has partnered with many celebs to “Embody” them into AI characters, which I found.. a bit unsettling? But I guess we’ll see how much this will affect the “personas” of the AI assistants.

Open Source LLM
Qwen 14B with chat and vision versions
QWEN model from Alibaba, which we’ve already talked about multiple times, then was taken down from the web, comes back, with a vengeance!
Qwen team comes back with a 14B model, that beats LlaMa2 34B on most evaluations, including a VL version (only 7B), which according to my tests, was the best performing open source vision model even at 7B

It was really cool to see the Qwen authors interact with Yam and I on Twitter, it’s like crossing the great firewall and hopefully we’ll have that team on ThursdAI recording at some point!
🔥 Mistral 7B (torrent tweet) - SOTA LLM
Mistral team have made news when they raised $113 million without a product, just 3 co-founders, back in Jun, and the “takes” on twitter were, “we’re in a bubble, bla bla bla” and yesterday, this Goated team just posted a tweet with a magnet torrent link, and no description. So of course everybody downloaded it and found the best SOTA 7B model, that outperforms a much larger LLaMa 2 13B and MUCH larger LLaMa 34B on several benchmarks!

It even comes very close to the Code LLaMa performance benchmarks on code, while being a general model, which is incredible.
Needless to say, the team delivered the promise, and to see them commit this fully to OpenSource, by dropping a modal with Apache 2 license, straight to bit-torrent, is a great sight to see!
Also, we caught glimpes of Guillaume Lample in the audience while we were gassing Mistral up, and potentially at some point we may get Mistral folks to join a ThursdAI live space? 🫡
AI Art + Diffusion
Meta introduced EMU - A diffusion model integrated into it’s AI offerings with a /imagine command, available for free, in all their products, and it looks really good!
I wonder if it will do the same “chat with image” thing as DALL-E3 was announced to do, but in any case, giving this, for free, in this quality, to so many people, is remarkable 🙇♂️ Kudos to the team at Meta for ALL the releases today! Can’t wait to play with them.
Tools
Spotify translates podcasts using stealth OpenAI tech
Spotify announced translations for podcast, using some secret OpenAI voice cloning tech, and we had a long discussion about the implication of voice cloning, deep fakes and everything in between with Peter Wang and other folks on the pod, definitely recommended listening!
I love this, absolutely, not just because you may want to listen to ThursdAI pod in your native language (and I could finally show my mom who doesn’t speak English what I’m doing!) but also because language barriers should NOT exist, and Targum.video and this and all the models that Meta is releasing are a great testament to how fast language barriers are coming down!
I’m very very happy with this development and will keep you guys posted on these developments.
With that, I should probably stop here, it’s been an absolutely insane week, and if this summary helped, like, share and consider a premium subscription?
P.S - If you scrolled all the way to here, send me 🧨 in a DM on any platform 😉, I may have something for you



