





Hey, for the least time during summer of 2024, welcome to yet another edition of ThursdAI, also happy skynet self-awareness day for those who keep track :)
This week, Cerebras broke the world record for fastest LLama 3.1 70B/8B inference (and came on the show to talk about it) Google updated 3 new Geminis, Anthropic artifacts for all, 100M context windows are possible, and Qwen beats SOTA on vision models + much more!
As always, this weeks newsletter is brought to you by Weights & Biases, did I mention we're doing a hackathon in SF in September 21/22 and that we have an upcoming free RAG course w/ Cohere & Weaviate?
TL;DR
Open Source LLMs
Big CO LLMs + APIs
Cerebras launches the fastest AI inference - 447t/s LLama 3.1 70B (X, Blog, Try It)
Google - Gemini 1.5 Flash 8B & new Gemini 1.5 Pro/Flash (X, Try it)
Google adds Gems & Imagen to Gemini paid tier
Anthropic artifacts available to all users + on mobile (Blog, Try it)
Anthropic publishes their system prompts with model releases (release notes)
OpenAI has project Strawberry coming this fall (via The information)
This weeks Buzz
Also, we have a new RAG course w/ Cohere and Weaviate (RAG Course)
Vision & Video
AI Art & Diffusion & 3D
GameNgen - completely generated (not rendered) DOOM with SD1.4 (project)
FAL new LORA trainer for FLUX - trains under 5 minutes (Trainer, Coupon for ThursdAI)
Tools & Others
SimpleBench from AI Explained - closely matches human experience (simple-bench.com)
Open Source
Let's be honest - ThursdAI is a love letter to the open-source AI community, and this week was packed with reasons to celebrate.
Nous Research DiStRO + Function Calling V1

Nous Research was on fire this week (aren't they always?) and they kicked off the week with the release of DiStRO, which is a breakthrough in distributed training. You see, while LLM training requires a lot of hardware, it also requires a lot of network bandwidth between the different GPUs, even within the same data center.
Proprietary networking solutions like Nvidia NVLink, and more open standards like Ethernet work well within the same datacenter, but training across different GPU clouds has been unimaginable until now.
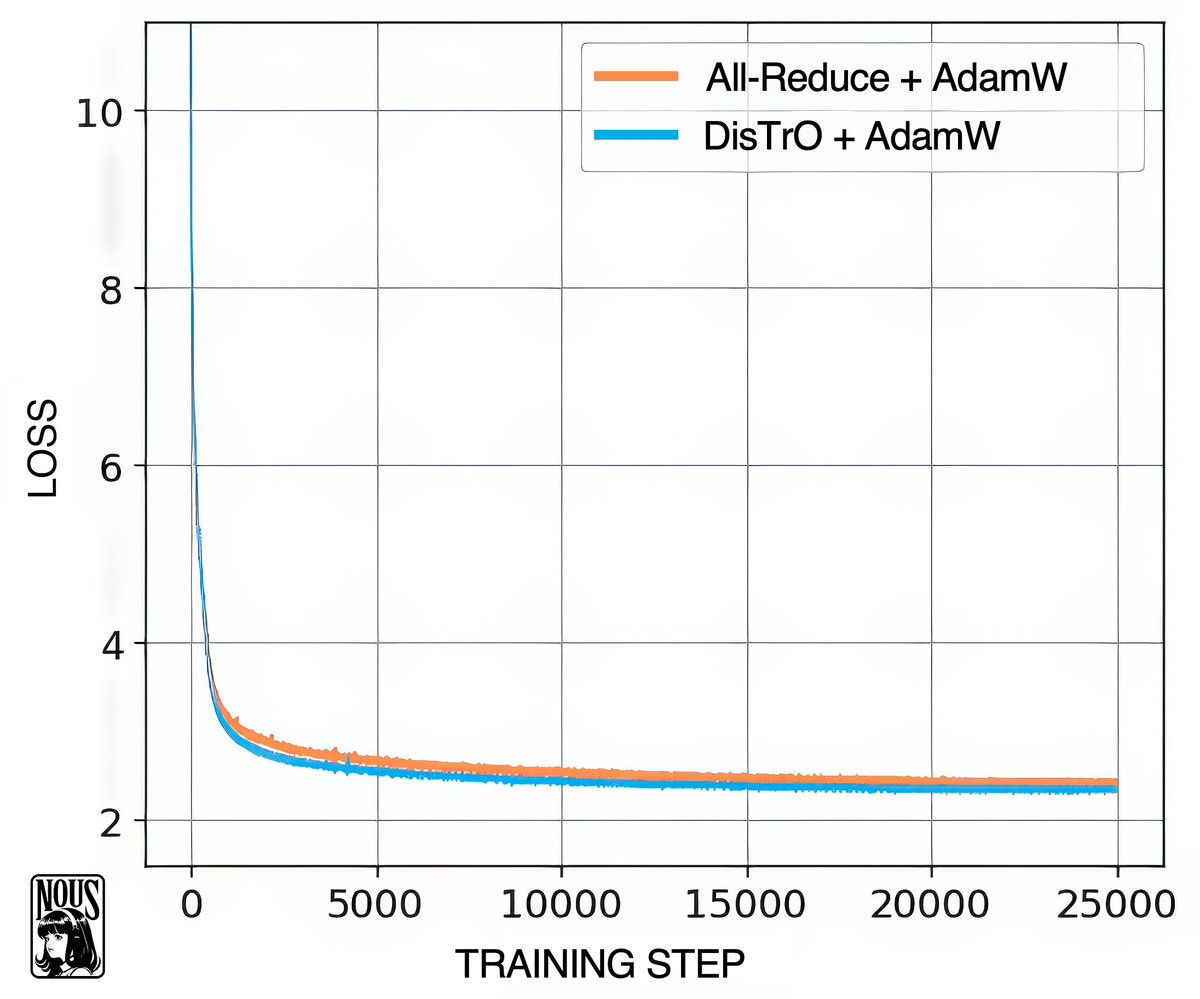
Enter DiStRo, a new decentralized training by the mad geniuses at Nous Research, in which they reduced the required bandwidth to train a 1.2B param model from 74.4GB to just 86MB (857x)!
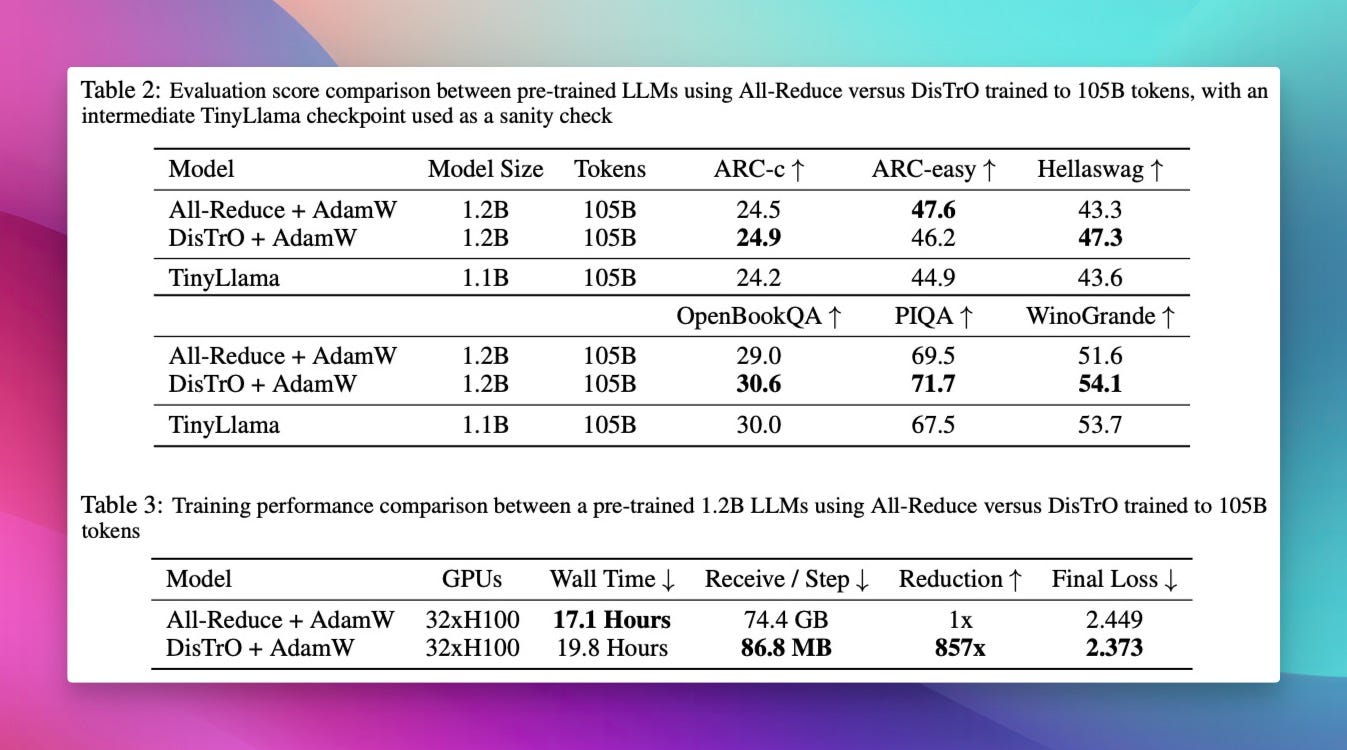
This can have massive implications for training across compute clusters, doing shared training runs, optimizing costs and efficiency and democratizing LLM training access! So don't sell your old GPUs just yet, someone may just come up with a folding@home but for training the largest open source LLM, and it may just be Nous!
Nous Research also released their function-calling-v1 dataset (HF) that was used to train Hermes-2, and we had InterstellarNinja who authored that dataset, join the show and chat about it. This is an incredible unlock for the open source community, as function calling become a de-facto standard now. Shout out to the Glaive team as well for their pioneering work that paved the way!
LinkedIn's Liger Kernel: Unleashing the Need for Speed (with One Line of Code)

What if I told you, that whatever software you develop, you can add 1 line of code, and it'll run 20% faster, and require 60% less memory?
This is basically what Linkedin researches released this week with Liger Kernel, yes you read that right, Linkedin, as in the website you career related posts on!
"If you're doing any form of finetuning, using this is an instant win"
Wing Lian - Axolotl
This absolutely bonkers improvement in training LLMs, now works smoothly with Flash Attention, PyTorch FSDP and DeepSpeed. If you want to read more about the implementation of the triton kernels, you can see a deep dive here, I just wanted to bring this to your attention, even if you're not technical, because efficiency jumps like these are happening all the time. We are used to seeing them in capabilities / intelligence, but they are also happening on the algorithmic/training/hardware side, and it's incredible to see!
Huge shoutout to Byron and team at Linkedin for this unlock, check out their Github if you want to get involved!
Qwen-2 VL - SOTA image and video understanding + open weights mini VLM
You may already know that we love the folks at Qwen here on ThursdAI, not only because Junyang Lin is a frequeny co-host and we get to hear about their releases as soon as they come out (they seem to be releasing them on thursdays around the time of the live show, I wonder why!)
But also because, they are committed to open source, and have released 2 models 7B and 2B with complete Apache 2 license!

First of all, their Qwen-2 VL 72B model, is now SOTA at many benchmarks, beating GPT-4, Claude 3.5 and other much bigger models. This is insane. I literally had to pause Junyang and repeat what he said, this is a 72B param model, that beats GPT-4o on document understanding, on math, on general visual Q&A.
Additional Capabilities & Smaller models
They have added new capabilities in these models, like being able to handle arbitrary resolutions, but the one I'm most excited about is the video understanding. These models can now understand up to 20 minutes of video sequences, and it's not just "split the video to 10 frames and do image caption", no, these models understand video progression and if I understand correctly how they do it, it's quite genius.

They the video embed time progression into the model using a new technique called M-RoPE, which turns the time progression into rotary positional embeddings.
Now, the 72B model is currently available via API, but we do get 2 new small models with Apache 2 license and they are NOT too shabby either!
7B parameters (HF) and 2B Qwen-2 VL (HF) are small enough to run completely on your machine, and the 2B parameter, scores better than GPT-4o mini on OCR-bench for example!
I can't wait to finish writing and go play with these models!
Big Companies & LLM APIs
The biggest news this week came from Cerebras System, a relatively unknown company, that shattered the world record for LLM inferencing out of the blue (and came on the show to talk about how they are doing it)
Cerebras - fastest LLM inference on wafer scale chips
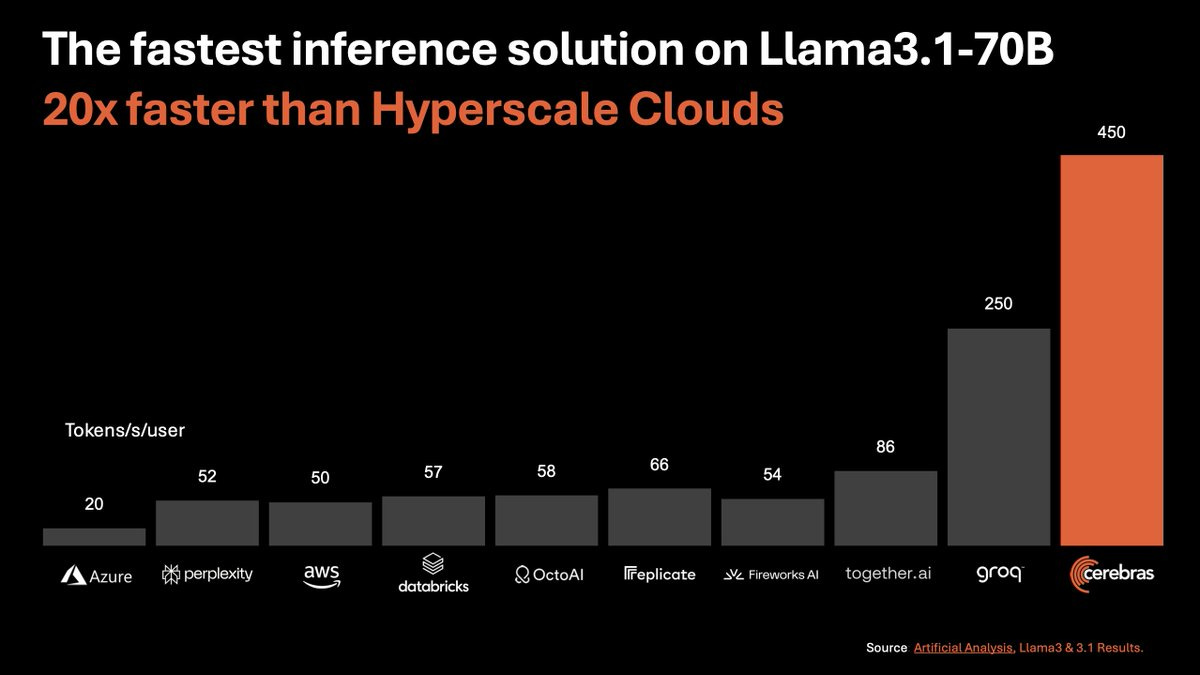
Cerebras has introduced the concept of wafer scale chips to the world, which is, if you imagine a microchip, they are the size of a post stamp maybe? GPUs are bigger, well, Cerebras are making chips the sizes of an iPad (72 square inches), largest commercial chips in the world.

And now, they created an inference stack on top of those chips, and showed that they have the fastest inference in the world, how fast? Well, they can server LLama 3.1 8B at a whopping 1822t/s. No really, this is INSANE speeds, as I was writing this, I copied all the words I had so far, went to inference.cerebras.ai , asked to summarize, pasted and hit send, and I immediately got a summary!
"The really simple explanation is we basically store the entire model, whether it's 8B or 70B or 405B, entirely on the chip. There's no external memory, no HBM. We have 44 gigabytes of memory on chip."
James Wang
They not only store the whole model (405B coming soon), but they store it in full fp16 precision as well, so they don't quantize the models. Right now, they are serving it with 8K tokens in context window, and we had a conversation about their next steps being giving more context to developers.
The whole conversation is well worth listening to, James and Ian were awesome to chat with, and while they do have a waitlist, as they gradually roll out their release, James said to DM him on X and mention ThursdAI, and he'll put you through, so you'll be able to get an OpenAI compatible API key and be able to test this insane speed.
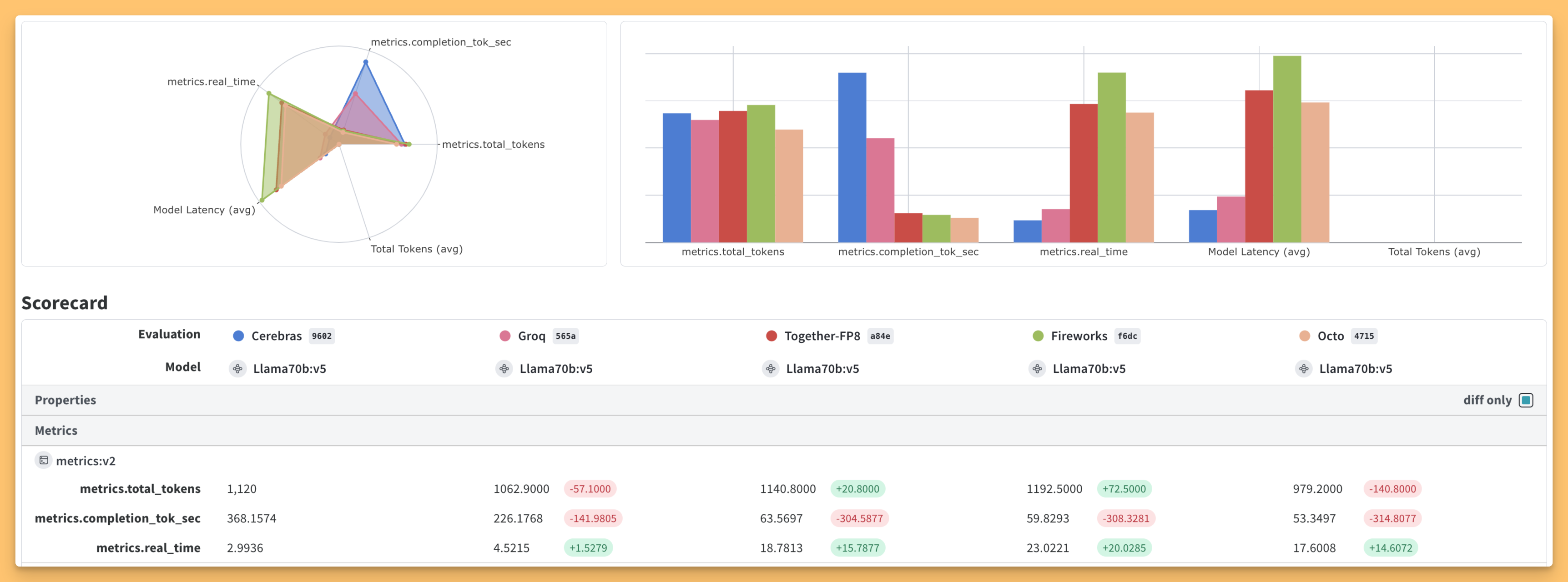
P.S - we also did an independent verification of these speeds, using Weave, and found Cerebras to be quite incredible for agentic purposes, you can read our report here and the weave dashboard here
Anthropic - unlocking just-in-time applications with artifacts for all
Well, if you aren't paying claude, maybe this will convince you. This week, anthropic announced that artifacts are available to all users, not only their paid customers.
Artifacts are a feature in Claude that is basically a side pane (and from this week, a drawer in their mobile apps) that allows you to see what Claude is building, by rendering the web application almost on the fly. They have also trained Claude in working with that interface, so it knows about the different files etc
Effectively, this turns Claude into a web developer that will build mini web applications (without backend) for you, on the fly, for any task you can think of.
Drop a design, and it'll build a mock of it, drop some data in a CSV and it'll build an interactive onetime dashboard visualizing that data, or just ask it to build an app helping you split the bill between friends by uploading a picture of a bill.
Artifacts are share-able and remixable, so you can build something and share with friends, so here you go, an artifact I made, by dropping my notes into claude, and asking for a magic 8 Ball, that will spit out a random fact from today's editing of ThursdAI. I also provided Claude with an 8Ball image, but it didn't work due to restrictions, so instead I just uploaded that image to claude and asked it to recreate it with SVG! And viola, a completely un-nessesary app that works!
Google’s Gemini Keeps Climbing the Charts (But Will It Be Enough?)
Sensing a disturbance in the AI force (probably from that Cerebras bombshell), Google rolled out a series of Gemini updates, including a new experimental Gemini 1.5 Pro (0827) with sharper coding skills and logical reasoning. According to LMSys, it’s already nipping at the heels of ChatGPT 4o and is number 2!

Their Gemini 1.5 Flash model got a serious upgrade, vaulting to the #6 position on the arena. And to add to the model madness, they even released an Gemini Flash 8B parameter version for folks who need that sweet spot between speed and size.
Oh, and those long-awaited Gems are finally starting to roll out. But get ready to open your wallet – this feature (preloading Gemini with custom context and capabilities) is a paid-tier exclusive. But hey, at least Imagen-3 is cautiously returning to the image generation game!
AI Art & Diffusion
Doom Meets Stable Diffusion: AI Dreams in 20FPS Glory (GameNGen)
The future of video games is, uh, definitely going to be interesting. Just as everyone thought AI would be conquering Go or Chess, it seems we've stumbled into a different battlefield: first-person shooters. 🤯
This week, researchers in DeepMind blew everyone's minds with their GameNgen research. What did they do? They trained Stable Diffusion 1.4 on Doom, and I'm not just talking about static images - I'm talking about generating actual Doom gameplay in near real time. Think 20FPS Doom running on nothing but the magic of AI.
The craziest part to me is this quote "Human raters are only slightly better than random chance at distinguishing short clips of the game from clips of the simulation"
FAL Drops the LORA Training Time Bomb (and I Get a New Meme!)

As you see, I haven't yet relaxed from making custom AI generations with Flux and customizing them with training LORAs. Two weeks ago, this used to take 45 minutes, a week ago, 20 minutes, and now, the wizards at FAL, created a new trainer that shrinks the training times down to less than 5 minutes!
So given that the first upcoming SpaceX commercial spacewalk Polaris Dawn, I trained a SpaceX astronaut LORA and then combined my face with it, and viola, here I am, as a space X astronaut!
BTW because they are awesome, Jonathan and Simo (who is the magician behind this new trainer) came to the show, announced the new trainer, but also gave all listeners of ThursdAI a coupon to train a LORA effectively for free, just use this link and start training! (btw I get nothing out of this, just trying to look out for my listeners!)

That's it for this week, well almost that's it, magic.dev announced a new funding round of 320 million, and that they have a 100M context window capable models and coding product to go with it, but didn't yet release it, just as we were wrapping up. Sam Altman tweeted that OpenAI now has over 200 Million active users on ChatGPT and that OpenAI will collaborate with AI Safety institute.

Ok now officially that's it! See you next week, when it's going to be 🍁 already brrr



