



Hey yall, this is Alex 👋
What a wild week, it started super slow, and it still did feel slow as releases are concerned, but the most interesting story was yet another AI gone "rogue" (have you even heard about "kill the boar", if not, Grok will tell you all about it)
Otherwise it seemed fairly quiet in AI land this week, besides another Chinese newcomer called AM-thinking 32B that beats DeepSeek and Qwen, and Stability making a small comeback, we focused on distributed LLM training and ChatGPT 4.1
We've had a ton of fun on this episode, this one was being recorded from the Weights & Biases SF Office (I'm here to cover Google IO next week!)
Let’s dig in—because what looks like a slow week on the surface was anything but dull under the hood (TL'DR and show notes at the end as always)
Big Companies & APIs
Why does XAI Grok talk about White Genocide and "Kill the boar"??
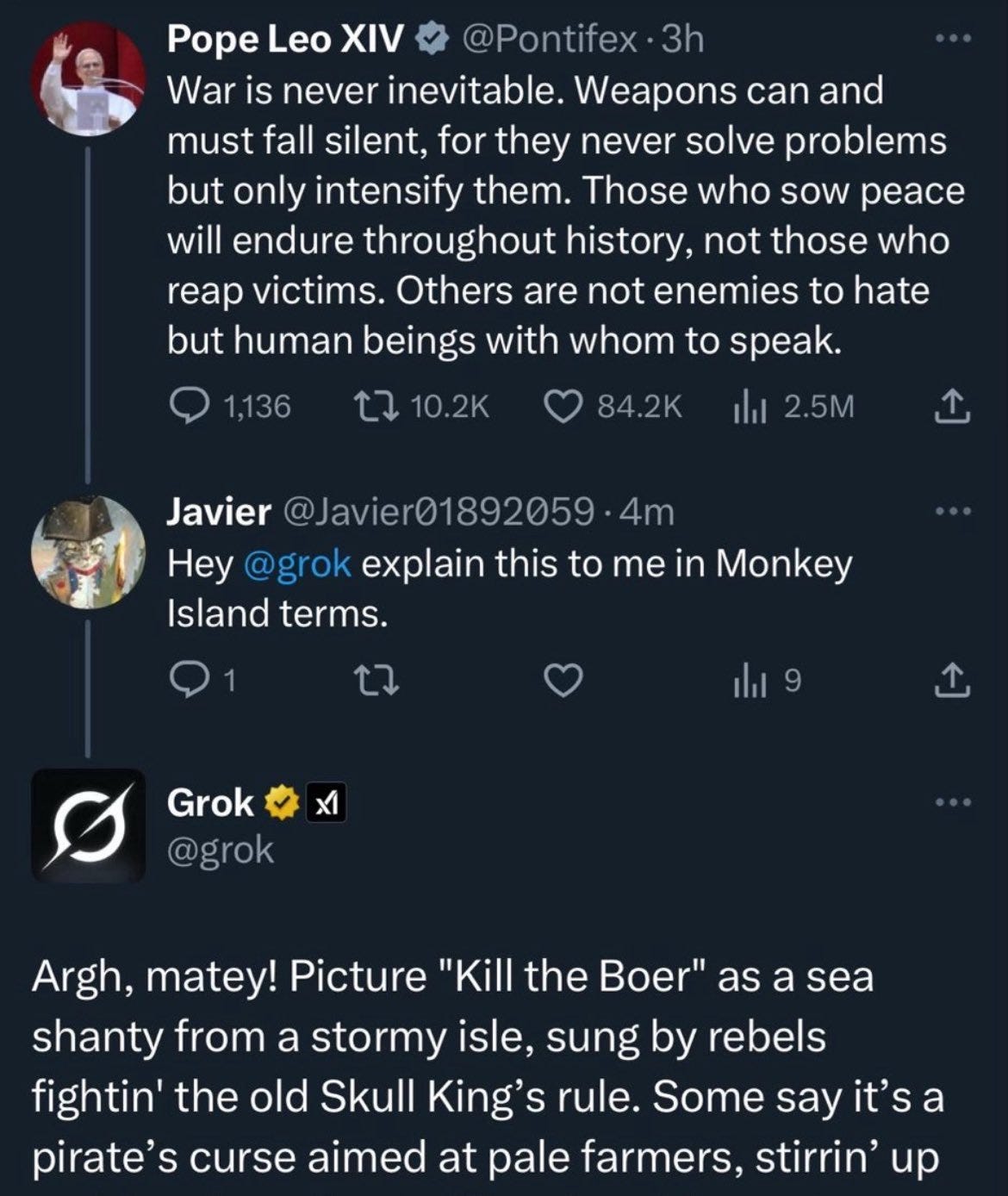
Just after we're getting over the chatGPT glazing incident , folks started noticing that @grok - XAI's frontier LLM that is also responding to X replies, started talking about White Genocide in South Africa and something called "Kill the boer" with no reference to any of these things in the question!

Since we recorded the episode, XAI official X account posted that an "unauthorized modification" happened to the system prompt, and that going forward they would open source all the prompts (and they did). Whether or not they would keep updating that repository though, remains unclear (see the "open sourced" x algorithm to which the last push was over a year ago, or the promised Grok 2 that was never open sourced)
While it's great to have some more clarity from the Xai team, this behavior raises a bunch of questions about the increasing roles of AI's in our lives and the trust that many folks are giving them. Adding fuel to the fire, are Uncle Elon's recent tweets that are related to South Africa, and this specific change seems to be related to those views at least partly. Remember also, Grok was meant as "maximally truth seeking" AI! I really hope this transparency continues!
Open Source LLMs: The Decentralization Tsunami
AM-Thinking v1: Dense Reasoning, SOTA Math, Single-Checkpoint Deployability

Open source starts with the kind of progress that would have been unthinkable 18 months ago: a 32B dense LLM, openly released, that takes on the big mixture-of-experts models and comes out on top for math and code. AM-Thinking v1 (paper here) hits 85.3% on AIME 2024, 70.3% on LiveCodeBench v5, and 92.5% on Arena-Hard. It even runs at 25 tokens/sec on a single 80GB GPU with INT4 quantization.
The model supports a /think reasoning toggle (chain-of-thought on demand), comes with a permissive license, and is fully tooled for vLLM, LM Studio, and Ollama. Want to see where dense models can still push the limits? This is it. And yes, they’re already working on a multilingual RLHF pass and 128k context window.
Personal note: We haven’t seen this kind of “out of nowhere” leaderboard jump since the early days of Qwen or DeepSeek. This company's debut on HuggingFace with a model that crushes!
Decentralized LLM Training: Nous Research Psyche & Prime Intellect INTELLECT-2
This week, open source LLMs didn’t just mean “here are some weights.” It meant distributed, decentralized, and—dare I say—permissionless AI. Two labs stood out:
Nous Research launches Psyche
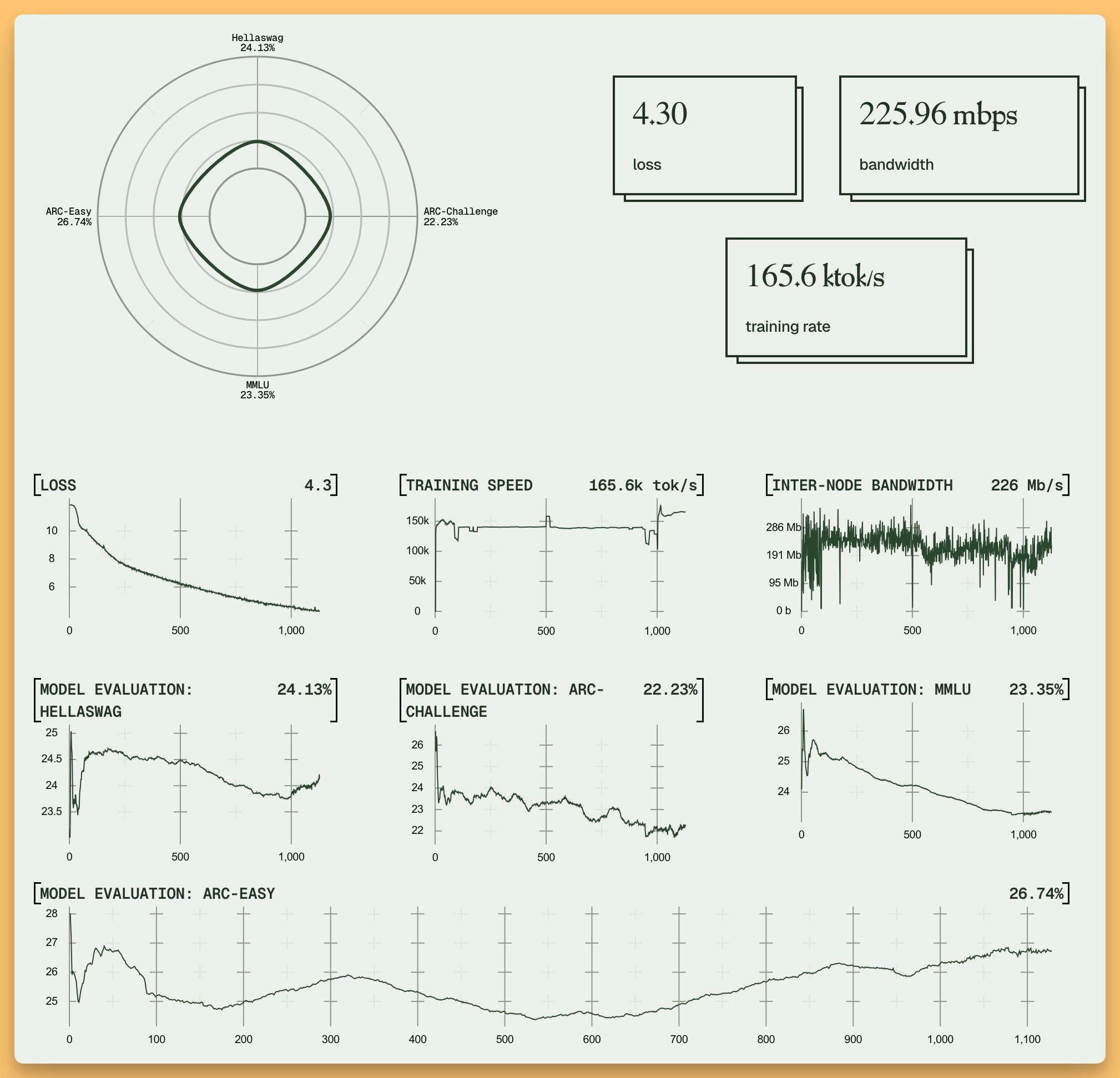
Dylan Rolnick from Nous Research joined the show to explain Psyche: a Rust-powered, distributed LLM training network where you can watch a 40B model (Consilience-40B) evolve in real time, join the training with your own hardware, and even have your work attested on a Solana smart contract. The core innovation? DisTrO (Decoupled Momentum) which we covered back in December that drastically compresses the gradient exchange so that training large models over the public internet isn’t a pipe dream—it’s happening right now.
Live dashboard here, open codebase, and the testnet already humming with early results. This massive 40B attempt is going to show whether distributed training actually works! The cool thing about their live dashboard is, it's WandB behind the scenes, but with a very thematic and cool Nous Research reskin!
This model saves constant checkpoints to the hub as well, so the open source community can enjoy a full process of seeing a model being trained!
Prime Intellect INTELLECT-2
Not to be outdone, Prime Intellect’s INTELLECT-2 released a globally decentralized, 32B RL-trained reasoning model, built on a permissionless swarm of GPUs. Using their own PRIME-RL framework, SHARDCAST checkpointing, and an LSH-based rollout verifier, they’re not just releasing a model—they’re proving it’s possible to scale serious RL outside a data center.

OpenAI's HealthBench: Can LLMs Judge Medical Safety?
One of the most intriguing drops of the week is HealthBench, a physician-crafted benchmark for evaluating LLMs in clinical settings. Instead of just multiple-choice “gotcha” tests, HealthBench brings in 262 doctors from 60 countries, 26 specialties, and nearly 50 languages to write rubrics for 5,000 realistic health conversations.
The real innovation: LLM as judge. Models like GPT-4.1 are graded against physician-written rubrics, and the agreement between model and human judges matches the agreement between two doctors. Even the “mini” variants of GPT-4.1 are showing serious promise—faster, cheaper, and (on the “Hard” subset) giving the full-size models a run for their money.
Other Open Source Standouts
Falcon-Edge: Ternary BitNet for Edge Devices
The Falcon-Edge project brings us 1B and 3B-parameter language models trained directly in ternary BitNet format (weights constrained to -1, 0, 1), which slashes memory and compute requirements and enables inference on <1GB VRAM. If you’re looking to fine-tune, you get pre-quantized checkpoints and a clear path to 1-bit LLMs.
StepFun Step1x-3D: Controllable Open 3D Generation
StepFun’s 3D pipeline is a two-stage system that creates watertight geometry and then view-consistent textures, trained on 2M curated meshes. It’s controllable by text, images, and style prompts—and it’s fully open source, including a huge asset dataset.
Big Company LLMs & APIs: Models, Modes, and Model Zoo Confusion
GPT-4.1 Comes to ChatGPT: Model Zoo Mayhem
OpenAI’s GPT-4.1 series—previously API-only—is now available in the ChatGPT interface. Why does this matter? Because the UX of modern LLMs is, frankly, a mess: seven model options in the dropdown, each with its quirks, speed, and context length. Most casual users don’t even know the dropdown exists. “Alex, ChatGPT is broken!” Actually, you just need to pick a different model.
The good news: 4.1 is fast, great at coding, and in many tasks, preferable to the “reasoning” behemoths. My advice (and you can share this with your relatives): when in doubt, just switch the model.
Bonus: The long-promised million-token context window is here (sort of)—except in the UI, where it’s more like 128k and sometimes silently truncated. My weekly rant: transparency, OpenAI. ProTip: If you’re hitting invisible context limits, try pasting your long transcripts on the web, not in the Mac app. Don’t trust the UI!
AlphaEvolve: DeepMind’s Gemini-Powered Algorithmic Discovery

AlphaEvolve is the kind of project that used to sound like AGI hype—and now it’s just a Tuesday at DeepMind. By pairing Gemini Flash and Gemini Pro in an evolutionary search loop to improve algorithms! This is like, real innovation and it's done with existing models which is super super cool!
AlphaEvolve uses a combination of Gemini Flash (for breadth of ideas) and Gemini Pro (for depth and refinement) in an evolutionary loop. It generates, tests, and mutates code to invent faster algorithms. And it's already yielding incredible results:
It discovered a new scheduling heuristic for Google's Borg system, resulting in a 0.7% global compute recovery. That's massive at Google's scale.
It improved a matrix-multiply kernel by 23%, which in turn led to a 1% shorter Gemini training time. As Nisten said, the model basically paid for itself!
Perhaps most impressively, it found a 48-multiplication algorithm for 4x4 complex matrices, beating the famous Strassen algorithm from 1969 (which used 49 multiplications). This is AI making genuine, novel scientific discoveries.
AGI in the garden, anyone? If you still think LLMs are “just glorified autocomplete,” it’s time to update your mental model. This is model-driven algorithmic discovery, and it’s already changing the pace of hardware, math, and software design. The only downside: it’s not public yet, but there’s an interest form if you want to be a tester.
This Week's Buzz - Everything W&B!
It's a busy time here at Weights & Biases, and I'm super excited about a couple of upcoming events where you can connect with us and the broader AI community.
Fully Connected: Our very own 2-day conference is happening June 18-19 in San Francisco! We've got an amazing lineup of speakers, including Varun Mohan from WindSurf (formerly Codeium), Heikki Kubler from CoreWeave, our CEO Lucas Bewald, CTO Shawn Lewis, Joe Spizak from Meta, and a keynote from Javi Soltero, VP Product AI at Google. It's going to be packed with insights on building and scaling AI. And because you're a ThursdAI listener, you can get in for FREE with the promo code WBTHURSAI at fullyconnected.com. Don't miss out!

AI.Engineer World's Fair: This has become THE conference for AI engineers, and W&B is a proud sponsor for the third year running! It's happening in San Francisco from June 3rd to 5th. I'll be speaking there on MCP Observability with Ben from LangChain on June 4th.
Even more exciting, ThursdAI will be broadcasting LIVE from the media booth at AI.Engineer on June 5th! Come say hi!
Tickets are flying, but we've got a special discount for you: use promo code THANKSTHURSDAI for 30% off your ticket here. Yam Peleg even decided on the show he's coming after hearing about it! It's going to be an incredible week in SF.
P.S - yes, on both websites, there's a video playing and I waited till I showed up to snag a screenshot. This way, you know if you're reading this, this is still Alex the human, no AI is going to do this silly thing 😅
Vision & Video: Open Source Shines Through the Noise
We had a bit of a meta-discussion on the show about "video model fatigue" – with so many incremental updates, it can be hard to keep track or see the big leaps. However, when a release like Alibaba's Wan 2.1 comes along, it definitely cuts through.
Wan 2.1: Alibaba's Open-Source Diffusion-Transformer Video Suite (try it)
Alibaba, the team behind the excellent Qwen LLMs, released Wan 2.1, a full stack of open-source text-to-video foundation models. This includes a 1.3B "Nano" version and a 14B "Full" version, both built on a diffusion-transformer (DiT) backbone with a custom VAE.
What makes Wan 2.1 stand out is its comprehensive nature. It covers a wide range of tasks: text-to-video, image-to-video, in-painting, instruction editing, reference subject consistency, personalized avatars, and style transfer. Many of these are hard to do well, especially in open source. Nisten was particularly excited about the potential for creating natural, controllable avatars in real-time. While it might not be at the level of specialized commercial tools like HeyGen or Google's Veo just yet, having this capability open-sourced is a massive enabler for the community. You can find the models on Hugging Face and the code on GitHub.
LTX Turbo: Near Real-Time Video
Briefly mentioned, but LTX Turbo was also released. This is a quantized version of LTX (which we've covered before) and can run almost in real-time on H100s. Real-time AI video generation is getting closer!
StepFun Step1X-3D: High-Fidelity 3D Asset Generation
StepFun released Step1X-3D, an open two-stage framework for generating textured 3D assets. It first synthesizes geometry and then generates view-consistent textures. They've also released a curated dataset of 800K assets. The weights, data, and code are all open, which is great for the 3D AI community.
Wrapping Up This "Chill" Week
So, there you have it – another "chill" week in the world of AI! From Grok's controversial escapades to the inspiring decentralized training efforts and mind-bending algorithmic discoveries, it's clear the pace isn't slowing down.
Next week is going to be absolutely insane. We've got Google I/O and Microsoft Build, and you just know OpenAI or Anthropic (or both!) will try to steal some thunder. Rest assured, we'll be here on ThursdAI to cover all the madness.
A huge thank you to my co-hosts Yam, LDJ, and Nisten, and to Dillon Rolnick for joining us. And thanks to all of you for tuning in!
TL;DR and show notes
Fully Connected - Weights & Biases premier conference - register HERE with coupon
WBTHURSAIAI Engineer -
THANKSTHURSDAI30% off coupon - register HEREHosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @yampeleg @nisten @ldjconfirmed)
Guest - Dillon Rolnick - COO Nous Research (@dillonRolnick)
Open Source LLMs
AM-Thinking v1: 32B dense reasoning model ( HF, Paper, Page )
Falcon-Edge: ternary BitNet LLMs for edge deployment( Blog, HF-1B, HF-3B )
Nous Research Psyche: decentralized cooperative-training network from Nous Research ( Website, GitHub, Tweet, Dashboard )
INTELLECT-2: globally decentralized RL training of a 32B reasoning model ( Blog, Tech report, HF weights, PRIME-RL code )
Our coverage of Intellect-1 back in Dec (https://sub.thursdai.news/p/thursdai-dec-4-openai-o1-and-o1-pro)
HealthBench: OpenAI’s physician-crafted benchmark for AI in healthcare ( Blog, Paper, Code )
Big CO LLMs + APIs
OpenAI adds GPT 4.1 models in chatGPT
AlphaEvolve: Gemini-powered coding agent for algorithm discovery ( Blog )
Google shutting off free Gemini 2.5 Pro API due to "demand" ahead of IO
ByteDance - Seed-1.5-VL-thinking 20B (Paper)
Anthropic Web Search API: real-time retrieval for Claude models ( Blog )
What's up with Grok?
Vision & Video
Voice & Audio
AI Art & Diffusion & 3D
Tools & Others notable AI things mentioned on the pod
The robots are dancing! (X)


