





Hey folks, this is Alex, finally back home!
This week was full of crazy AI news, both model related but also shifts in the AI landscape and big companies, with Zuck going all in on scale & execu-hiring Alex Wang for a crazy $14B dollars.
OpenAI meanwhile, maybe received a new shipment of GPUs? Otherwise, it’s hard to explain how they have dropped the o3 price by 80%, while also shipping o3-pro (in chat and API).
Apple was also featured in today’s episode, but more so for the lack of AI news, completely delaying the “very personalized private Siri powered by Apple Intelligence” during WWDC25 this week.
We had 2 guests on the show this week, Stefania Druga and Eric Provencher (who builds RepoPrompt). Stefania helped me cover the AI Engineer conference we all went to last week, and shared some cool Science CoPilot stuff she’s working on, while Eric is the GOTO guy for O3-pro helped us understand what this model is great for!
As always, TL;DR and show notes at the bottom, video for those who prefer watching is attached below, let’s dive in!
Big Companies LLMs & APIs
Let’s start with big companies, because the landscape has shifted, new top reasoner models dropped and some huge companies didn’t deliver this week!
Zuck goes all in on SuperIntelligence - Meta’s $14B stake in ScaleAI and Alex Wang
This may be the most consequential piece of AI news today. Fresh from the dissapointing results of LLama 4, reports of top researchers leaving the Llama team, many have decided to exclude Meta from the AI race. We have a saying at ThursdAI, don’t bet against Zuck!
Zuck decided to spend a lot of money (nearly 20% of their reported $65B investment in AI infrastructure) to get a 49% stake in Scale AI and bring Alex Wang it’s (now former) CEO to lead the new Superintelligence team at Meta.
For folks who are not familiar with Scale, it’s a massive company in providing human annotated data services to all the big AI labs, Google, OpenAI, Microsoft, Anthropic.. all of them really. Alex Wang, is the youngest self made billionaire because of it, and now Zuck not only has access to all their expertise, but also to a very impressive AI persona, who could help revive the excitement about Meta’s AI efforts, help recruit the best researchers, and lead the way inside Meta.
Wang is also an outspoken China hawk who spends as much time in congressional hearings as in Slack, so the geopolitics here are … spicy. Meta just stapled itself to the biggest annotation funnel on Earth, hired away Google’s Jack Rae (who was on the pod just last week, shipping for Google!) for brainy model alignment, and started waving seven-to-nine-figure comp packages at every researcher with “Transformer” in their citation list. Whatever disappointment you felt over Llama-4’s muted debut, Zuck clearly felt it too—and responded like a founder who still controls every voting share.
OpenAI’s Game-Changer: o3 Price Slash & o3-pro launches to top the intelligence leaderboards!

Meanwhile OpenAI dropping not one, but two mind-blowing updates. First, they’ve slashed the price of o3—their premium reasoning model—by a staggering 80%. We’re talking from $40/$10 per million tokens down to just $8/$2. That’s right, folks, it’s now in the same league as Claude Sonnet cost-wise, making top-tier intelligence dirt cheap. I remember when a price drop of 80% after a year got us excited; now it’s 80% in just four months with zero quality loss. They’ve confirmed it’s the full o3 model—no distillation or quantization here. How are they pulling this off? I’m guessing someone got a shipment of shiny new H200s from Jensen!
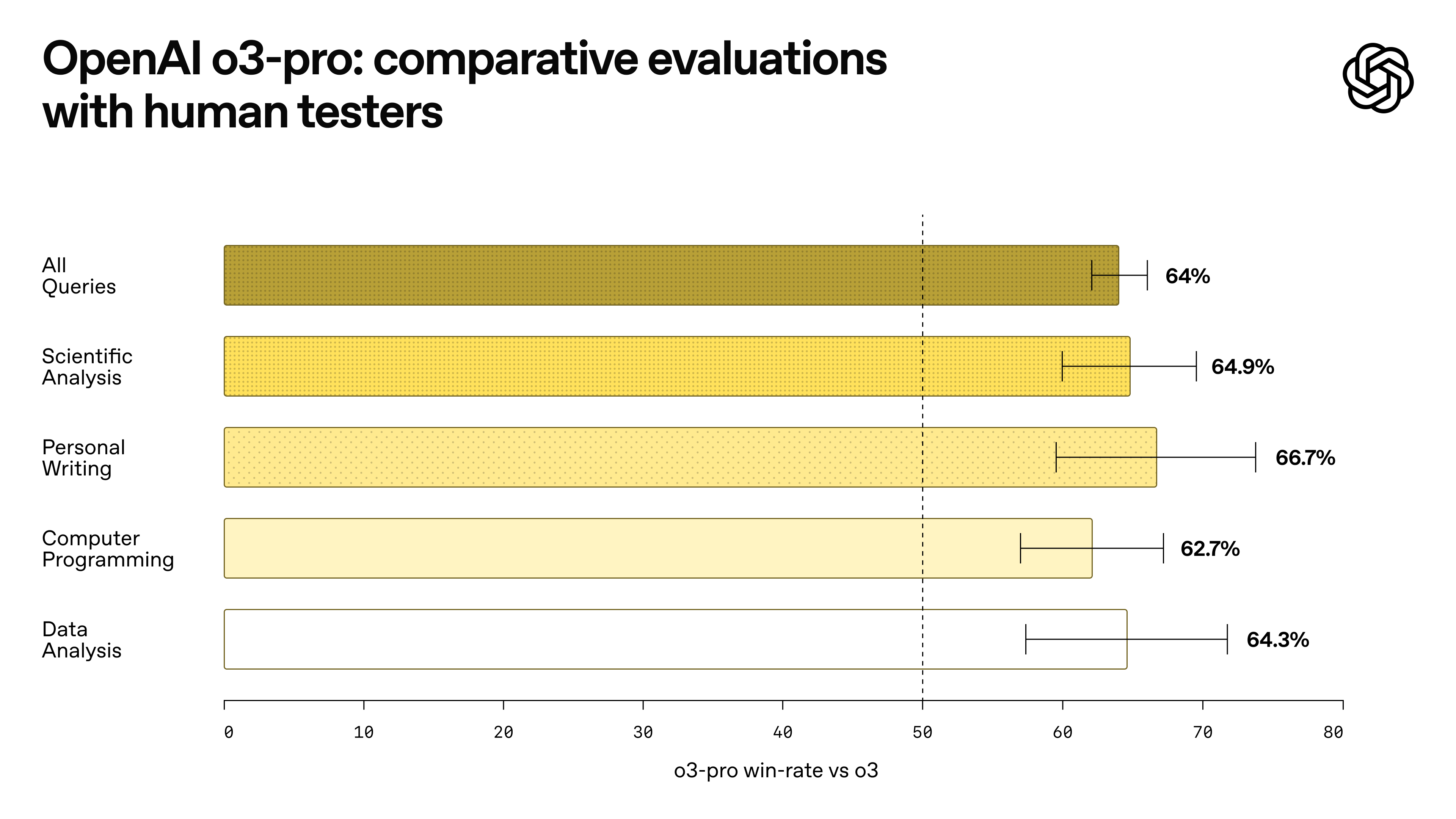
And just when you thought it couldn’t get better, OpenAI rolled out o3-pro, their highest intelligence offering yet. Available for pro and team accounts, and via API (87% cheaper than o1-pro, by the way), this model—or consortium of models—is a beast. It’s topping charts on Artificial Analysis, barely edging out Gemini 2.5 as the new king. Benchmarks are insane: 93% on AIME 2024 (state-of-the-art territory), 84% on GPQA Diamond, and nearing a 3000 ELO score on competition coding. Human preference tests show 64-66% of folks prefer o3-pro for clarity and comprehensiveness across tasks like scientific analysis and personal writing.
I’ve been playing with it myself, and the way o3-pro handles long context and tough problems is unreal. As my friend Eric Provencher (creator of RepoPrompt) shared on the show, it’s surgical—perfect for big refactors and bug diagnosis in coding. It’s got all the tools o3 has—web search, image analysis, memory personalization—and you can run it in background mode via API for async tasks. Sure, it’s slower due to deep reasoning (no streaming thought tokens), but the consistency and depth? Worth it.
Oh, and funny story—I was prepping a talk for Hamel Hussain’s evals course, with a slide saying “don’t use large reasoning models if budget’s tight.” The day before, this price drop hits, and I’m scrambling to update everything. That’s AI pace for ya!
Apple WWDC: Where’s the Smarter Siri?
Oh Apple. Sweet, sweet Apple. Remember all those Bella Ramsey ads promising a personalized Siri that knows everything about you? Well, Craig Federighi opened WWDC by basically saying "Yeah, about that smart Siri... she's not coming. Don't wait up."
Instead, we got:
AI that can combine emojis (revolutionary! 🙄)
Live translation (actually cool)
Direct API access to on-device models (very cool for developers)
Liquid glass UI (pretty but... where's the intelligence?)
The kicker? Apple released a paper called "The Illusion of Thinking" right before WWDC, basically arguing that AI reasoning models hit hard complexity ceilings. Some saw this as Apple making excuses for why they can't ship competitive AI. The timing was... interesting.
During our recording, Nisten's Siri literally woke up randomly when we were complaining about how dumb it still is. After a decade, it's the same Siri. That moment was pure comedy gold.
This Week's Buzz
Our premium conference Fully Connected is happening June 17-18 in San Francisco! Use promo code WBTHURSAI to register for free. We'll have updates on the CoreWeave acquisition, product announcements, and it's the perfect chance to give feedback directly to the people building the tools you use.
Also, my talk on Large Reasoning Models as LLM judges is now up on YouTube. Had to update it live because of the O3 price drop - such is life in AI!
Open Source LLMs: Mistral Goes Reasoning Mode
Mistral Drops Magistral - Their First Reasoning Model
The French champagne of LLMs is back! Mistral released Magistral, their first reasoning model, in two flavors: a 24B parameter open-source Small version and a closed API-only Medium version. And honestly? The naming continues to be chef's kiss - Mistral really has the branding game locked down.

Now, here's where it gets spicy. Mistral's benchmarks notably don't include comparisons to Chinese models like Qwen or DeepSeek. Dylan Patel from SemiAnalysis called them out on this, and when he ran the comparisons himself, well... let's just say Magistral Medium barely keeps up with Qwen's tiny 4B parameter model on math benchmarks. Ouch.
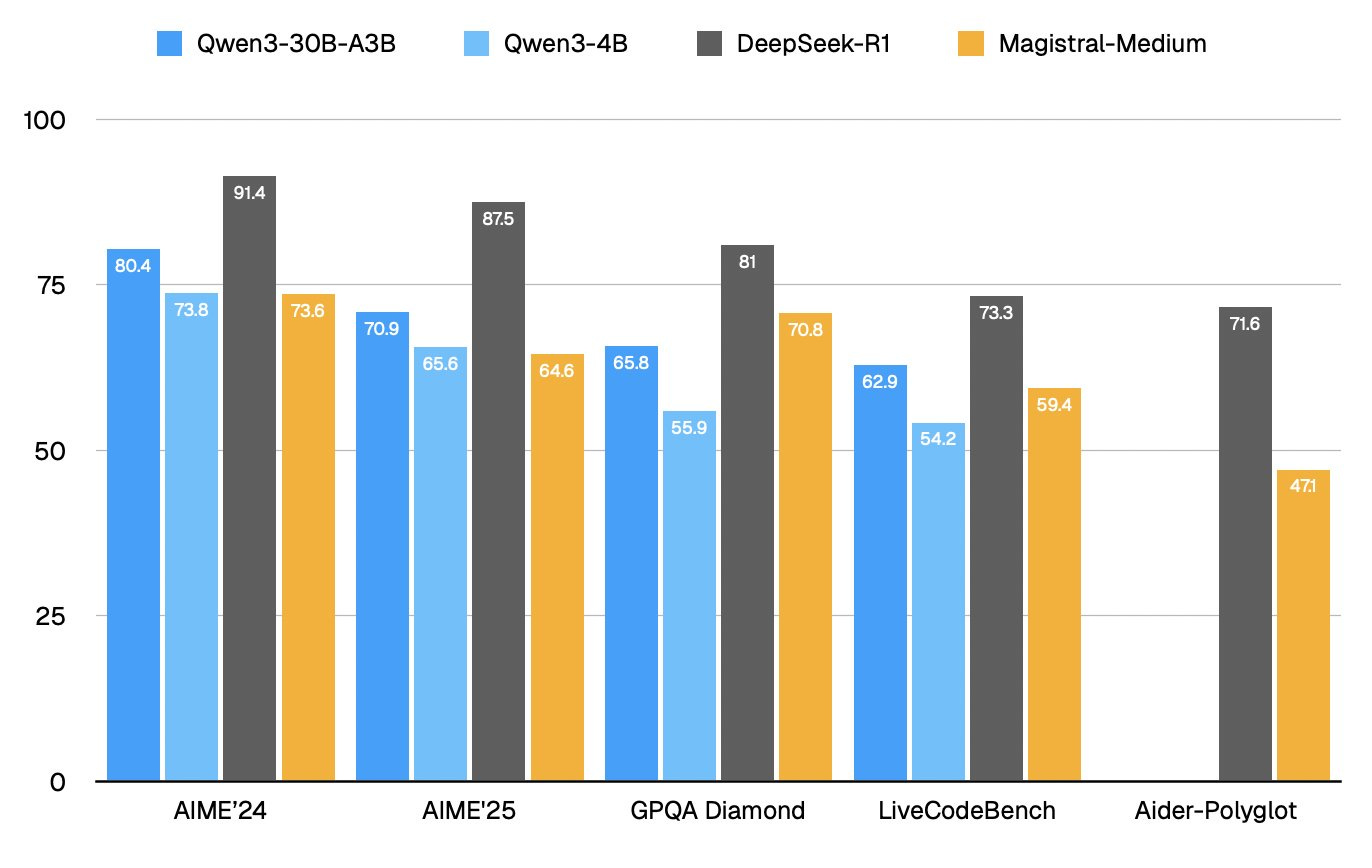
But here's the thing - and Nisten really drove this home during our discussion - benchmarks don't tell the whole story. He's been using Magistral Small for his workflows and swears by it. "It's almost at the point where I don't want to tell people about it," he said, which is the highest praise from someone who runs models locally all day. The 24B Small version apparently hits that sweet spot for local deployment while being genuinely useful for real work.
The model runs on a single RTX 4090 or a 32GB MacBook after quantization, has a 128K context window (though they recommend capping at 40K), and uses a transparent <think>mode that shows its reasoning process. It's Apache 2.0 licensed, multilingual, and available through their Le Chat interface with "Flash Answers" for real-time reasoning.
SakanaAI's Text2Lora: The Future is Self-Adapting Models
This one blew my mind. SakanaAI (co-founded by one of the Transformer paper authors) released Text2Lora - a method for adapting LLMs to new tasks using ONLY text descriptions. No training data needed!
Think about this: instead of fine-tuning a model with thousands of examples to make it better at math, you just... tell it to be better at math. And it works! On Llama 3.1 8B, Text2Lora reaches 77% average accuracy, outperforming all baseline methods.
What this means is we're approaching a world where models can essentially customize themselves on-the-fly for whatever task you throw at them. As Nisten put it, "This is revolutionary. The model is actually learning, actually changing its own weights." We're just seeing the first glimpses of this capability, but in 6-12 months?
🎥 Multimedia & Tools: Video, Voice, and Browser Breakthroughs
Let’s zip through some multimedia and tool updates that caught my eye this week. Google’s VEO3-fast is a creator’s dream—2x faster 720p video generation, 80% cheaper, and now with audio support. I’ve seen clips on social media (like an NBA ad) that are unreal, though Wolfram noted it’s not fully rolled out in Europe yet. You can access it via APIs like Fail or Replicate, and I’m itching to make a full movie if I had the budget!
Midjourney’s gearing up for a video product with their signature style, but they’re also facing heat—Disney and Universal are suing them for copyright infringement over Star Wars and Avengers-like outputs. It’s Hollywood’s first major strike against AI, and while I get the IP concern, it’s odd they picked the smaller player when OpenAI and Google are out there too. This lawsuit could drag on, so stay tuned.
OpenAI’s new advanced voice mode dropped, aiming for a natural cadence with better multilingual support (Russian and Hebrew sound great now). But honestly? I’m not loving the breathing and laughing they added—it’s uncanny valley for me. Some folks on X are raving, though, and LDJ noted it’s closing the gap to Sesame’s Maya. I just wish they’d let me pick between old and new voices instead of switching under my feet. If OpenAI’s listening, transparency please!
On the tools side, Yutori’s Scouts got my timeline buzzing—AI agents that monitor the web for any topic (like “next ThursdAI release”) and notify you of updates. I saw a demo catching leadership changes at xAI, and it’s the future of web interaction. Couldn’t log in live on the show (email login woes—give me passwords, folks!), but it’s beta on yutori.com. Also, Browser Company finally launched DIA, an AI-native browser in beta. Chatting with open tabs, rewriting text, and instant answers? I’ve been using it to prep for ThursdAI, and it’s pretty slick. Try it at diabrowser.com.
Wrapping Up: AI’s Breakneck Pace
What a week, folks! From OpenAI democratizing intelligence with o3-pro and price cuts to Meta’s bold superintelligence play with ScaleAI, we’re witnessing history unfold at lightning speed. Apple’s stumble at WWDC stings, but open-source gems and new tools keep the excitement alive. I’m still riding the high from AI Engineer last week—your high-fives and feedback mean the world. Next week, don’t miss Weights & Biases’ Fully Connected conference in SF on June 18-19. I won’t be there physically, but I’m cheering from afar—grab your spot at fullyconnected.com with promo code WBTHURSAI for a sweet deal.
Thanks for being part of the ThursdAI crew. Here’s the full TL;DR and show notes to catch anything you missed. See you next week!
TL;DR of all topics covered:
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf, @yampeleg, @nisten, @ldjconfirmed
Guests -
Stefania Druga @stefania_druga (Independent, Former Research Scientist Google DeepMind),Creator of scratch copilot, and AI Engineer education summit.
Eric Provencher - @pvncher (Building RepoPrompt)
Chit Chat - AI Engineer conference vibes, meeting fans, Jack Rae’s move to Meta.
Open Source LLMs
Big CO LLMs + APIs
This Week’s Buzz
Fully Connected: W&B’s 2-day conference, June 17-18 in SF (fullyconnected.com) - Promo Code WBTHURSAI
Alex’s talk on LRM as LLM judges on Hamel’s course (YT)
Vision & Video
Voice & Audio
OpenAI’s new advanced voice mode - mixed responses, better multilingual support
Cartesia Ink-Whisper - optimized for real-time chat (Blog)
AI Art & Diffusion & 3D
AI Tools




