






Hey everyone, Alex here 👋
Welcome back to ThursdAI! After what felt like ages of non-stop, massive model drops (looking at you, O3 and GPT-4!), we finally got that "chill week" we've been dreaming of since maybe... forever? It seems the big labs are taking a breather, probably gearing up for even bigger things next week (maybe some open source 👀).
But "chill" doesn't mean empty! This week was packed with fascinating developments, especially in the open source world and with long-awaited API releases. We actually had time to dive deeper into things, which was a refreshing change. We had a fantastic lineup of guests joining us too: Kwindla Kramer (@kwindla), our resident voice expert, dropped in to talk about some mind-blowing TTS and her own open-source VAD release. Maziyar Panahi (@MaziyarPanahi) gave us the inside scoop on OpenAI's recent meeting with the open source community. And Dex Horthy (@dexhorthy) from HumanLayer shared some invaluable insights on building robust AI agents that actually work in the real world. It was great having them alongside the usual ThursdAI crew: LDJ, Yam, Wolfram, and Nisten!
So, instead of rushing through a million headlines, we took a more relaxed pace. We explored NVIDIA's cool new Describe Anything model, dug into Google's Quantization Aware Training for Gemma, celebrated the much-anticipated API release for OpenAI's GPT Image generation (finally!), checked out the new Grok API, got absolutely blown away by a tiny, open-source TTS model from Korea called Dia, and debated the principles of building better AI agents. Plus, a surprise drop from Send AI with a powerful video model!
Let's dive in!
Open Source AI Highlights: Community, Vision, and Efficiency
Even with the big players quieter on the model release front, the open source scene was buzzing. It feels like this "chill" period gave everyone a chance to focus on refining tools, releasing datasets, and engaging with the community.
OpenAI Inches Closer to Open Source? Insights from the Community Meeting

Perhaps the biggest non-release news of the week was OpenAI actively engaging with the open source community. Friend of the show Maziyar Panahi was actually in the room (well, the Zoom room) and joined us to share what went down
It sounds like OpenAI came prepared, with Sam Altman himself spending significant time answering questions . Maziyar gave us the inside scoop, mentioning that OpenAI's looking to offload some GPU pressure by embracing open source – a win-win where they help the community, and the community helps lighten their load. He painted a picture of a company genuinely trying to listen and figure out how to best contribute. It felt less like a checkbox exercise and more like genuine engagement, which is awesome to see.
What did the community ask for? Based on Maziyar's recap, there was a strong consensus on several key points:
Model Size: The sweet spot seemed to be not tiny, but not astronomically huge either. Something in the 70B-200B parameter range that could run reasonably on, say, 4 GPUs, leaving room for other models. People want power they can actually use without needing a supercomputer.
Capabilities: A strong desire for reliable structured output. Surprisingly, there was less emphasis on complex, built-in reasoning, or at least the ability to toggle reasoning off. This likely stems from practical concerns about cost and latency in production environments. The community seems to value control and efficiency for specific tasks.
Multilingual: Good support for European languages (at least 20) was a major request, reflecting the global nature of the open source community. Needs to be as good as English support.
Base Models: A huge ask was for OpenAI to release base models. The reasoning? Empower the community to handle fine-tuning for specific tasks like coding, roleplay, or supporting underrepresented languages . Let the experts in those niches build on a solid foundation.
Focus: Usefulness over chasing leaderboard glory. The community urged OpenAI to provide a solid, practical model rather than aiming for a temporary #1 spot that gets outdated in days or weeks . Stability, reliability, and long-term utility were prized over fleeting benchmark wins.
Safety: A preference for separate guardrail models (similar to LlamaGuard or GemmaGuard) rather than overly aligning the main model, which often hurts performance and flexibility . Give users the tools to implement safety layers as needed, rather than baking in limitations that might stifle creativity or utility.
Perhaps most excitingly, Maziyar mentioned OpenAI seemed committed to regular open model releases, not just a one-off thin=! This, combined with recent moves like approving a community Pull Request to make their open-source Codex agent work with non-OpenAI models (as Yam Peleg excitedly pointed out!), suggests a potentially significant shift. Remember, it's been a long time since GPT-2 and Whisper were OpenAI's main open contributions! We're definitely watching this space closely. Huge shout out to OpenAI for listening and engaging with the builders.
NVIDIA's DAM: Describe Anything Model (and Dataset!)
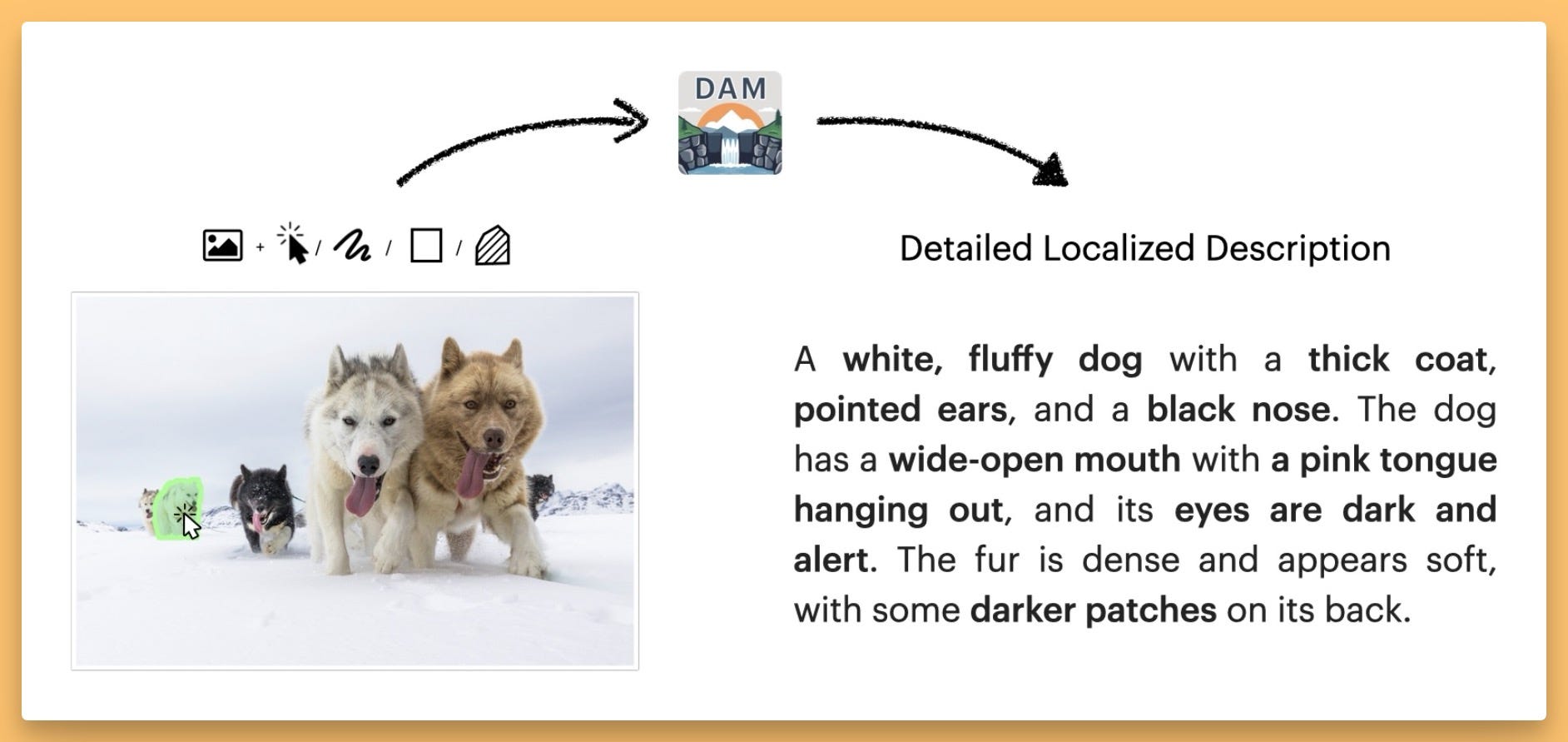
NVIDIA dropped something really cool this week: the Describe Anything Model (DAM), specifically DAM-3B, a 3 billion parameter multimodal model for region-based image and video captioning. Think Meta's Segment Anything (SAM), but instead of just segmenting, it also tells you what you've segmented, in detail.
We played around with the image demo on the show (HF demo) . You hover over an image, things get segmented on the fly (you can use points, boxes, scribbles, or masks), you click, and boom – a detailed description pops up for that specific region: "A brown bear with a thick, dense coat of fur..." . It's pretty slick and responsive!
While the demo didn't showcase video, the project page (X post) shows it working on videos too (DAM-3B-Video), tracking and describing objects like fish even as they move. This capability really impressed Yam, who rightly pointed out that tracking objects consistently over video is hard, so having a base model that understands this level and embeds it in language is seriously impressive. The model uses a "focal prompt" and gated cross-attention to fuse the full scene context with the selected region.
Nisten reminded us that our friend Piotr Skalski from Roboflow basically built a pipeline for this a while back by combining SAM with description models like Microsoft Florence . But DAM integrates it all into one efficient 3B parameter model (HF model), setting a new state-of-the-art on their introduced DLC-Bench (Detailed Localized Captioning).
Crucially, NVIDIA didn't just drop the model; they also released the Describe Anything Dataset (HF dataset) used to train it (built on subsets like COCO, Paco, SAM) and the code under a research-only license. This is fantastic for researchers and builders. Imagine using this for precise masking before sending an image to the new GPT Image API for editing – super useful! Big props to NVIDIA and their collaborators at UC Berkeley and UCSF for this contribution.
Gemma Gets Quantization Aware Training (QAT): Smaller Footprint, Sassy Attitude?
Google also pushed the open source envelope by releasing Gemma models trained with Quantization Aware Training (QAT). This isn't your standard post-training quantization; QAT involves incorporating the impact of quantization during the training process itself. As LDJ explained, this allows the model to adapt, potentially resulting in a quantized state with much higher quality and less performance degradation compared to just quantizing a fully trained model afterwards.

The results? Significant reductions in VRAM requirements across the board. The 27B parameter Gemma 3, for example, drops from needing a hefty 54GB to just 14.1GB ! Even the 1B model goes from 2GB to just half a gig. This makes running these powerful models much more accessible on consumer hardware. Folks are already running them in MLX, llama.cpp, LM Studio, etc. (Reddit thread)

Wolfram already took the 4B QAT model for a spin using LM Studio . The good news: it ran easily, needing only 5-6GB of RAM. The quirky news: it seemed to struggle a bit with prompt adherence in his tests, even giving Wolfram a sassy, winking-emoji response about ignoring the "fine print" in his complex system prompt when called out on a language switching error: "Who reads a fine print? 😉" ! He did note Gemma 3 now supports system prompts (unlike Gemma 2), which is a definite improvement .
(While NVIDIA also released OpenMath Nemotron, we didn't dive deep in the show, but worth noting its AIMO win and accompanying open dataset release!)
Voice and Audio Innovations: Emotional TTS and Smarter Conversations
Even in a "chill" week, the audio space delivered some serious excitement. Kwindla Kramer joined us to break down two major developments.
Dia TTS: Unhinged Emotion from a Small Open Model 🤯
This one absolutely blew up Twitter, and for good reason. Dia, from Nari Labs (essentially a student and a half in Korea!), is a 1.6 billion parameter open-weights (MIT licensed) text-to-dialogue model (Github, HF). What makes it special? The insane emotional range and natural interaction patterns. My Twitter post about it (X post) went viral, getting half a million views !
We played some examples, and they are just wild. You have to hear this to believe it:
Check the Demos: Dia Demo Page | Fal.ai Voice Clone Demo
Another crazy thing is how it handles non-verbal cues like laughs or coughs specified in the text (e.g., (laughs)) . Instead of just tacking on a generic sound, it inflects the preceding words leading into the laugh, making it sound incredibly natural. It even handles interruptions seamlessly, cutting off one speaker realistically when another starts .
Kwin, our voice expert, offered some valuable perspective . While Dia is undeniably awesome and shows what's possible, it's very much a research model – likely unpredictable ("unhinged" was his word!) and probably required cherry-picking the best demos. Production models like 11Labs need predictability. Kwin also noted the dataset is probably scraped from YouTube (a common practice, explaining the lack of open audio data) and that the non-speech sounds are a key takeaway – the bar for TTS is rising beyond just clear speech .
PipeCat SmartTurn: Fixing Awkward AI Silences with Open Source VAD
Speaking of open audio, Kwin and the team at Daily/Pipecat had their own breaking news: they released an open-source checkpoint for their SmartTurn model – a semantic Voice Activity Detection (VAD) system (Github, HF Model)
What's the problem SmartTurn solves? That annoying thing where voice assistants interrupt you mid-thought just because you paused for a second. I've seen this happen with my kids all the time, making interaction frustrating! Semantic VAD, or "Smart Turn," is much smarter. It considers not just silence but also the context – audio patterns (like intonation suggesting you're not finished) and linguistic cues (like ending on "and..." or "so...") to make a much better guess about whether you're truly done talking. This is crucial for natural-feeling voice interactions, especially for kids or multilingual speakers (like me!) who might pause more often to find the right word.
And the data part is key here. They're building an open dataset for this, hosted on Hugging Face. You can even contribute your own voice data by playing simple games on their turn-training.pipecat.ai site (Try It Demo)! The cool incentive? The more diverse voice data they get (especially for different languages!), the better these systems will work for everyone. If your voice is in the dataset, future AI agents might just understand you a little better!
Kwin also mentioned their upcoming Voice AI Course co-created with friend-of-the-pod Swyx, hosted on Maven . It aims to be a comprehensive guide with code samples, community interaction, and insights from experts (including folks from Weights & Biases!). Check it out if you want to dive deep into building voice AI.
AI Art & Diffusion & 3D: Quick Hits
A slightly quieter week for major art model releases, but still some significant movement:
OpenAI's GPT Image 1 API: We'll cover this in detail in the Big Companies section below, but obviously relevant here too as a major new tool for developers creating AI art and image editing applications .
Hunyuan 3D 2.5 (Tencent): Tencent released an update to their 3D generation model, now boasting 10 billion parameters (up from 1B!) . They're highlighting massive leaps in precision (1024-resolution geometry), high-quality textures with PBR support, and improved skeletal rigging for animation X Post. Definitely worth keeping an eye on as 3D generation matures and becomes more accessible (they doubled the free quota and launched an API).

Agent Development Insights: Building Robust Agents with Dex Horthy
With things slightly calmer, it was the perfect time to talk about AI agents – a space buzzing with activity, frameworks, and maybe even a little bit of drama. We brought in Dex Horthy, founder of HumanLayer and author of the insightful "12 Factor Agent" essay (Github Repo), to share his perspective on what actually works when building agents for production.

Dex builds SDKs to help create agents that feel more like digital humans, aiming to deploy them where users already are (Slack, email, etc.), moving beyond simple chat interfaces. His experience led him to identify common patterns and pitfalls when trying to build reliable agents.
The Problem with Current Agent Frameworks
A key takeaway Dex shared? Many teams building serious, production-ready agents end up writing large parts from scratch. Why? Because existing frameworks often fall short in providing the necessary control and reliability for complex tasks. The common "prompt + bag of tools + figure it out" approach, while great for demos, struggles with reliability over longer, multi-step workflows . Think about it: even if each step is 92% reliable, after 10 steps, your overall success rate plummets due to compounding errors. That's just not good enough for customer-facing applications.
Key Principles: Small Agents, Owning Context
So, what does work today according to Dex's 12 factors?
Small, Focused Agents: Instead of one giant, monolithic agent trying to do everything, the more reliable approach is to build smaller "micro-agents" that handle specific, well-defined parts of a workflow ]. As models get smarter, these micro-agents might grow in capability, but the principle of breaking down complexity holds. Find something at the edge of the model's capability and nail it consistently .
Own Your Prompts & Context: Don't let frameworks abstract away control over the exact tokens going into the LLM or how the context window is managed. This is crucial for performance tuning. Even with massive context windows (like Gemini's 2M tokens), smaller, carefully curated context often yields better results and lower costs . Maximum performance requires owning every single token.
Dex's insights provide a crucial dose of pragmatism for anyone building or thinking about building AI agents in this rapidly evolving space. Check out his full 12 Factor Agent essay and the webinar recording for a deeper dive.
Big Companies & APIs: GPT Image and Grok Get Developer Access
While new foundation models were scarce from the giants this week, they did deliver on the API front, opening up powerful capabilities to developers.
OpenAI Finally Releases GPT Image 1 API! (X Post)
This was a big one many developers were waiting for. OpenAI's powerful image generation capabilities, previously locked inside ChatGPT, are now available via API under the official name gpt-image-1 (Docs) . No more awkward phrasing like "the new image generation capabilities within chat gpt"!
Getting access requires organizational verification, which involved a slightly intense biometric scan process for me – feels like they're taking precautions given the model's realism and potential for misuse . Understandable, but something developers need to be aware of .

The API (API Reference) offers several capabilities:
Generations: Creating images from scratch based on text prompts.
Edits: Modifying existing images using a new prompt, crucially supporting masking for partial edits. This is huge for targeted changes and perfect for combining with segmentation models like NVIDIA's DAM!
There's a nice playground interface in the console, and you have interesting controls over the output:
Quality: Instead of distinct models, you select a quality level (standard/HD) which impacts the internal "thinking time" and cost . It seems to be a reasoning model under the hood, so quality relates to compute/latency.
Number: Generate up to 10 images at once.
Transparency: Supports generating images with transparent backgrounds
I played around with it, generating ads and even trying to get it to make a ThursdAI thumbnail with my face. The text generation is excellent – it nailed "ThursdAI" perfectly on an unhinged speaker ad Nisten prompted! It follows complex style prompts well.

However, generating realistic faces, especially matching a specific person like me, seems... really hard right now . Even after many attempts providing a source image and asking it to replace a face, the results were generic or only vaguely resembled me. It feels almost intentionally nerfed, maybe as a safety measure to prevent deepfakes? I still used it for the thumbnail, but yeah, it could be better on faces.
OpenAI launched with several integration partners like Adobe, Figma, Wix, HeyGen, and Fal.ai already onboard. Expect to see these powerful image generation capabilities popping up everywhere!
Grok 3 Mini & Grok 3 Now Available via API (+ App Updates)
Elon's xAI also opened the gates this week, making Grok 3 Mini and Grok 3 available via API (Docs).

The pricing structure is fascinating and quite different from others. Grok 3 Mini is incredibly cheap for input ($0.30 / 1M tokens) with only a modest bump for output ($0.50 / 1M). The "Fast" versions, however, cost significantly more, especially for output tokens (Grok 3 Fast is $5 input / $25 output per million!) . It seems like a deliberate play on the "fast, cheap, smart" triangle, giving developers explicit levers to pull based on their needs.
Benchmarks provided by xAI position Grok 3 Mini competitively against other small models like Gemini 2.5 Flash and O4 Mini, scoring well on AIME (93%) and coding benchmarks.
Speaking of the app, the iOS version got a significant update adding a live video view (let Grok see what you see through your camera) and multilingual audio support (X Post) . Prepare for some potentially unhinged, real-time video roasting if you use the fun mode with the camera on ! Multilingual audio and search are also rolling out to SuperGrok users on Android.
(Side note: We briefly touched on O3's recent wonkiness in following instructions for tone, despite its amazing GeoGuessr abilities! Something feels off there lately.)
Vision and Video: Send AI's Surprise Release & More
Just when we thought the week was winding down on model releases...
Send AI Drops MAGI-1: 24B Video Model with Open Weights! 🔥
Out of seemingly nowhere, a company called Send AI released details (and then the weights!) for MAGI-1, a 24 billion parameter autoregressive diffusion model for video generation (X Post, GitHub, PDF Report).

The demos looked stunning, showcasing impressive long-form video generation with remarkable character consistency – often the Achilles' heel of AI video . Nisten speculated this could be a major step towards usable AI-generated movies, solving the critical face/character consistency problem . They achieve this by predicting video in 24-frame chunks with causal attention between them, allowing for real-time streaming generation where compute doesn't scale with length. They also highlighted an "infinite extension" capability, allowing users to build out longer scenes by injecting new prompts or continuing footage.
Their technical report dives into the architecture, mentioning novel techniques like a custom "MagiAttention" kernel that scales to massive contexts and helps achieve the temporal consistency. It also sets SOTA on VBench-I2V and Physics-IQ benchmarks.
And the biggest surprise? They released the model weights under an Apache 2.0 license on Hugging Face ! This is huge! Just as we sometimes lament the lack of open source momentum from certain players, Send AI drops this 24B parameter beast with open weights. Amazing! Go download it!
Framepack: Long Videos on Low VRAM
Wolfram also flagged Framepack, another interesting video development from the research world from the creator of ControlNet. FramePack is a next-frame (next-frame-section) prediction neural network structure that generates videos progressively. (Github)
Character AI AvatarFX Steps In
Also in the visual space, Character AI announced AvatarFX in early access (Website), stepping into the realm of animated, speaking visual avatars derived from images. It seems like everyone wants to bring characters to life visually now.
This Week's Buzz from W&B / Community
Quick hits on upcoming events and community stuff:
WeaveHacks Coming to SF! Mark your calendars! We're hosting a hackathon focused on building with W&B Weave at the Weights & Biases office in San Francisco on May 17th-18th [0:06:15]. If you're around, especially if you're coming into town for Google I/O the week after, come hang out, build cool stuff, and say hi! We're planning to go all out with sponsors and prizes (announcements coming soon). lu.ma/weavehacks
Fully Connected Conference Reminder: Our flagship W&B conference, Fully Connected, is happening in San Francisco on June 18th [0:06:30]. It's where our customers, partners, and the community come together for two days of talks, workshops, and networking focused on production AI. It's always an incredible event. (fullyconnected.com)
Wrapping Up the "Chill" Week That Wasn't Quite Chill
Phew! See? Even a "chill" week in AI is overflowing with news when you actually have time to stop and breathe for a second. From OpenAI's fascinating open source tango and the practical (and long-awaited!) API releases of GPT Image and Grok, to the sheer creative potential shown by indie projects like Dia and Send AI's Maggie, and the grounding principles for building agents that actually work from Dex – there was a ton to absorb and discuss. It felt good to have the space to go a little deeper.
It was fantastic having Kwin, Maziar, and Dex join the regulars (LDJ, Yam, Wolfram, Nisten) to share their expertise and firsthand insights. A huge thank you to them and to everyone tuning in live across X, YouTube, LinkedIn, and participating in the chat! Your questions and comments make the show what it is.
Don't forget, if you missed anything, the full show is available as a podcast (search "ThursdAI" wherever you get your podcasts)
🔗 Subscribe to our show on Spotify: thursdai.news/spotify
🔗 Apple: thursdai.news/apple
🔗 Youtube: thursdai.news/yt
Next week? The rumors suggest the big labs might be back with major releases . The brief calm might be over! Buckle up! We'll be here to break it all down.
See you next ThursdAI!
- Alex
TL;DR and Show Notes (April 23rd, 2024)
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases @altryne
Co Hosts - Wolfram Ravenwlf @WolframRvnwlf, Yam Peleg @yampeleg, Nisten Tahiraj @nisten, LDJ @ldjconfirmed
Kwindla Kramer @kwindla - Daily Co-Founder // Voice expert
Dexter Horthy @dexhorthy - HumanLayer // Agents expert
Maziyar Panahi @MaziyarPanahi - OSS maintainer
Open Source AI - LLMs, Vision, Voice & more
Big CO LLMs + APIs
OpenAI GPT Image 1 API: (X Post, Docs, API Reference)
Grok API & App Updates: Grok 3 and Grok 3 Mini available via API. (API Docs, App Update X Post)
This weeks Buzz - Weights & Biases
WeaveHacks SF: Hackathon May 17-18 at W&B HQ. lu.ma/weavehacks
Fully Connected: W&B's 2-day conference, June 18-19 in SF fullyconnected.com
Vision & Video
Send AI MAGI-1: 24B autoregressive diffusion model for long, streaming video (X Post, GitHub, PDF Report, HF Repo)
Character AI AvatarFX: Early access for creating speaking/emoting avatars from images . (Website)
Framepack: Mentioned for long video generation (120s) on low VRAM (6GB). (Project Page)
Voice & Audio
Nari Labs Dia: 1.6B param OSS TTS model (X Post Highlight, HF Model, Github, Fal.ai Demo)
PipeCat Smart-Turn VAD: Open source semantic VAD model (Github, HF Model, Fal.ai Playground, Try It Demo)
AI Art & Diffusion & 3D
Hunyuan 3D 2.5 (Tencent): 10B param update [0:09:06]. Higher res geometry, PBR textures, improved rigging. (X Post)
Agents , Tools & Links
12 Factor Agents: Discussion with Dex Horthy on building robust agents (Github Repo)





{kind=link}