



Hey folks, Alex here (yes, real me, not my AI avatar, yet)
Compared to previous weeks, this week was pretty "chill" in the world of AI, though we did get a pretty significant Gemini 2.5 Pro update, it basically beat itself on the Arena. With Mistral releasing a new medium model (not OSS) and Nvidia finally dropping Nemotron Ultra (both ignoring Qwen 3 performance) there was also a few open source updates.
To me the highlight of this week was a breakthrough in AI Avatars, with Heygen's new IV model, Beating ByteDance's OmniHuman (our coverage) and Hedra labs, they've set an absolute SOTA benchmark for 1 photo to animated realistic avatar. Hell, Iet me record all this real quick and show you how good it is!
How good is that?? I'm still kind of blown away. I have managed to get a free month promo code for you guys, look for it in the TL;DR section at the end of the newsletter. Of course, if you’re rather watch than listen or read, here’s our live recording on YT
OpenSource AI
NVIDIA's Nemotron Ultra V1: Refining the Best with a Reasoning Toggle 🧠
NVIDIA also threw their hat further into the ring with the release of Nemotron Ultra V1, alongside updated Super and Nano versions. We've talked about Nemotron before – these are NVIDIA's pruned and distilled versions of Llama 3.1, and they've been impressive. The Ultra version is the flagship, a 253 billion parameter dense model (distilled and pruned from Llama 3.1 405B), and it's packed with interesting features.

One of the coolest things is the dynamic reasoning toggle. You can literally tell the model "detailed thinking on" or "detailed thinking off" via a system prompt during inference. This is something Qwen also supports, and it looks like the industry is converging on this idea of letting users control the "depth" of thought, which is super neat.
Nemotron Ultra boasts a 128K context window and, impressively, can fit on a single 8xH100 node thanks to Neural Architecture Search (NAS) and FFN-Fusion. And performance-wise, it actually outperforms the Llama 3 405B model it was distilled from, which is a big deal. NVIDIA shared a chart from Artificial Analysis (dated April 2025, notably before Qwen3's latest surge) showing Nemotron Ultra standing strong among models like Gemini 2.5 Flash and Opus 3 Mini.

What's also great is NVIDIA's commitment to openness here: they've released the models under a commercially permissive NVIDIA Open Model License, the complete post-training dataset (Llama-Nemotron-Post-Training-Dataset), and their training codebases (NeMo, NeMo-Aligner, Megatron-LM). This allows for reproducibility and further community development. Yam Peleg pointed out the cool stuff they did with Neural Architecture Search to optimally reduce parameters without losing performance.
Absolute Zero: AI Learning to Learn, Zero (curated) Data Required! (Arxiv)

LDJ brought up a fascinating paper that ties into this theme of self-improvement and reinforcement learning: "Absolute Zero: Reinforced Self-play Reasoning with Zero Data" from Andrew Zhao (Tsinghua University) and a few others
The core idea here is a system that self-evolves its training curriculum and reasoning ability. Instead of needing a pre-curated dataset of problems, the model creates the problems itself (e.g., code reasoning tasks) and then uses something like a Code Executor to validate its proposed solutions, serving as a unified source of verifiable reward. It's open-ended yet grounded learning.
By having a verifiable environment (code either works or it doesn't), the model can essentially teach itself to code without external human-curated data.
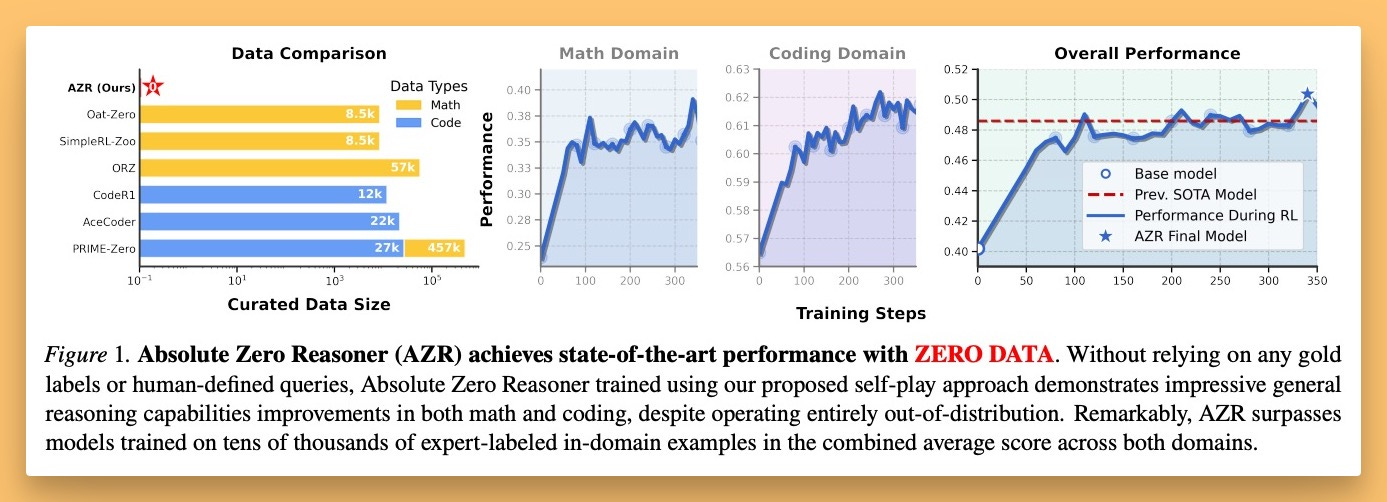
The paper shows fine-tunes of Qwen models (like Qwen Coder) achieving state-of-the-art results on benchmarks like MBBP and AIME (Math Olympiad) with no pre-existing data for those problems. The model hallucinates questions, creates its own rewards, learns, and improves. This is a step beyond synthetic data, where humans are still largely in charge of generation. It's wild, and it points towards a future where AI systems could become increasingly autonomous in their learning.
Big Companies & APIs
Google dropped another update to their Gemini 2.5 Pro, this time the "IO edition" preview, specifically touting enhanced coding performance. This new version jumped to the #1 spot on WebDev Arena (a benchmark where human evaluators choose between two side-by-side code generations in VS Code), with a +147 Elo point gain, surpassing Claude 3.7 Sonnet. It also showed improvements on benchmarks like LiveCodeBench (up 7.39%) and Aider Polyglot (up ~3-6%).

Google also highlighted its state-of-the-art video understanding (84.8% on VideoMME) with examples like generating code from a video of an app. Which essentially lets you record a drawing of how your app interaction will happen, and the model will use that video instructions! It's pretty cool.
Though, not everyone was as impressed, folks noted that while gaining in a few evals, this model also regressed in several others including Vibe-Eval (Reka's multimodal benchmark), Humanity's Last Exam, AIME, MMMU, and even long context understanding (MRCR). It's a good reminder that model updates often involve trade-offs – you can't always win at everything.
BREAKING: Gemini's Implicit Caching - A Game Changer for Costs! 💰
Just as we were wrapping up this segment on the show, news broke that Google launched implicit caching in Gemini APIs! This is a huge deal for developers.
Previously, Gemini offered explicit caching, where you had to manually tell the API what context to cache – a bit of a pain. Now, with implicit caching, the system automatically enables up to 75% cost savings when your request hits a cache. This is fantastic, especially for long-context applications, which is where Gemini's 1-2 million token context window really shines. If you're repeatedly sending large documents or codebases, this will significantly reduce your API bills. OpenAI has had automatic caching for a while, and it's great to see Google matching this for a much better developer experience and cost-effectiveness. It also saves Google a ton on inference, so it's a win-win!
Mistral Medium 3: The Closed Turn 😥
Mistral, once the darling of the open-source community for models like Mistral 7B and Mixtral, announced Mistral Medium 3. The catch? It's not open source.

They're positioning it as a multimodal frontier model with 128K context, claiming it matches or surpasses GPT-4-class benchmarks while being cheaper (priced at $0.40/M input and $2/M output tokens). However they haven't added Gemini Flash 2.5 here, which is 70% cheaper while being faster as well, nor did they mention Qwen.
Nisten voiced a sentiment many in the community share: he used to use LeChat frequently because he knew and understood the underlying open-source models. Now, with a closed model, it's a black box. It's a bit like pirating music users often being the biggest buyers – understanding the open model often leads to more commercial usage.
Wolfram offered a European perspective, noting that Mistral, as a European company, might have a unique advantage with businesses concerned about GDPR and data sovereignty, who might be hesitant to use US or Chinese cloud APIs. For them, a strong European alternative, even if closed, could be appealing.
OpenAI's New Chapter: Restructuring for the Future
OpenAI announced an evolution in its corporate structure. The key points are:
The OpenAI non-profit will continue to control the entire organization.
The existing for-profit LLC will become a Public Benefit Corporation (PBC).
The non-profit will be a significant owner of the PBC and will control it.
Both the non-profit and PBC will continue to share the same mission: ensuring AGI benefits all of humanity.
This move seems to address some of the governance concerns that have swirled around OpenAI, particularly in light of Elon Musk's lawsuit regarding its shift from a non-profit to a capped-profit entity. LDJ explained that the main worry for many was whether the non-profit would lose control or its stake in the main research/product arm. This restructuring appears to ensure the non-profit remains at the helm and that the PBC is legally bound to the non-profit's mission, not just investor interests. It's an important step for a company with such a profound potential impact on society.
And in related OpenAI news, the acquisition of Windsurf (the VS Code fork) for a reported $3 billion went through, while Cursor (another VS Code fork) announced a $9 billion valuation. It's wild to see these developer tools, which are essentially forks with an AI layer, reaching such massive valuations. Microsoft's hand is in all of this too – investing in OpenAI, invested in Cursor, owning VS Code, and now OpenAI buying Windsurf. It's a tangled web!
Finally, a quick mention that Sam Altman (OpenAI), Lisa Su (AMD), Mike Intrator (CoreWeave - my new CEO!), and folks from Microsoft were testifying before the U.S. Senate today about how to ensure America leads in AI and what innovation means. These conversations are crucial as AI continues to reshape our world.
This Weeks Buzz - Come Vibe with Us at Fully Connected! (SF, June 18-19) 🎉
Our two-day conference, Fully Connected, is happening in San Francisco on June 18th and 19th, and it's going to be awesome! We've got an incredible lineup of speakers, including Joe Spizak from the Llama team at Meta and Varun from Windsurf. It's two full days of programming, learning, and connecting with folks at the forefront of AI.
And because you're part of the ThursdAI family, I've got a special promo code for you: use WBTHURSAI to get a free ticket on me! If you're in or around SF, I'd love to see you there. Come hang out, learn, and vibe with us! Register at fullyconnected.com
Hackathon Update: Moved to July! 🗓️
The AGI Evals & Agentic Tooling (A2A) + MCP Hackathon that I was super excited to co-host has been postponed to July 12th-13th. Mark your calendars! I'll share more details and the invite soon.
W&B Joins CoreWeave! A New Era Begins! 🚀
And the big personal news for me and the entire Weights & Biases team: the acquisition of Weights & Biases by CoreWeave has been completed! CoreWeave is the ultra-fast-growing provider of GPUs that powers so much of the AI ecosystem.
So, from now on, it's Alex Volkov, AI Evangelist at Weights & Biases, from CoreWeave! (And as always, the opinions I share here are my own and not necessarily those of CoreWeave, especially important now that they're a public company!). I'm incredibly excited about this new chapter. W&B isn't going anywhere as a product; if anything, this will empower us to build even better developer tooling and integrate more deeply to help you run your models wherever you choose. Expect more cool stuff to come, especially as I figure out where all those spare GPUs are lying around at CoreWeave! 😉
Vision & Video
AI Avatars SOTA with HeyGen IV
Ok, as you saw above, the HeyGen IV avatars are absolutely bonkers. I did a comparison thread on X, and HeyGen's new thing absolutely takes SOTA between ByteDance OmniHuman and Hedra Labs!
All you need to do is upload 1 image of yourself, can even be an AI generated image, can be a side profile, can be a dog, an Anime character and they will generate up to 30 seconds of incredible lifelike avatar with the audio you provide!
I was so impressed with this, I reached out to HeyGen and scored a 1 month free code for you all, use THURSDAY4 and get a free month to try it out. Please tag me in whatever you create if you publish, I'd love to see where you take this!
Quick Hits: Lightricks LTXV & HunyuanCustom
Briefly, on the open-weights video front:
Lightricks LTXV 13B: The company from Jerusalem released an upgraded 13 billion parameter version of their LTX video model. It requires more VRAM but offers higher quality, keyframe and character movement support, multi-shot support, and multi-keyframe conditioning (a feature Sora famously has). It's fully open and supports LoRAs for custom styles.
HunyuanCustom: From Tencent, this model is about to be released (GitHub/Hugging Face links were briefly up then down). It promises multi-modal, subject-consistent video generation without LoRAs, based on a subject you provide (image, and eventually video/audio). It can take an image of a person or object and generate a video with that subject consistently. They also teased audio conditioning – making an avatar sing or speak based on input audio – and even style transfer where you can replace a character in a video with another reference image, all looking very promising for open source.
The World of AI Audio
Just a couple of quick mentions in the audio space:
ACE-Step 3.5B: From StepFun, this is a 3.5 billion parameter, fully open-source (Apache-2.0) foundation model for music generation. It uses a diffusion-based approach and can synthesize up to 4 minutes of music in just 20 seconds on an A100 GPU. It's not quite at Suno/Udio levels yet, but it's a strong open-source contender.
NVIDIA Parakeet TDT 0.6B V2: NVIDIA released this 600 million parameter transcription model that is blazing fast. It can transcribe 60 minutes of audio in just one second on production GPUs and works well locally too. It currently tops the OpenASR leaderboard on Hugging Face for English transcription and is a very strong Whisper competitor, especially for speed.
Conclusion and TL;DR
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed
Open Source LLMs
Big CO LLMs + APIs
Gemini Pro 2.5 IO tops ... Gemini 2.5 as the top LLM (Blog)
Figma announces Figma Make - Bolt/Lovable competitors (Figma)
OpenAI Restructures: Nonprofit Keeps Control, LLC Becomes PB (Blog)
Cursor worth $9B while Windsurf sells to OpenAI at $3B
Sam Altman, Lisa Su, Mike Intrator testify in Senate (Youtube)
This weeks Buzz
Fully Connected: W&B's 2-day conference, June 18-19 in SF fullyconnected.com - Promo Code
WBTHURSAIHackathon moved to July 12-13
Vision & Video
Voice & Audio
So, there you have it – a "chill" week that still managed to deliver some incredible advancements, particularly in AI avatars with HeyGen, continued strength in open-source models like Qwen3, and Google's relentless push with Gemini.
The next couple of weeks are gearing up to be absolutely wild with Microsoft Build and Google I/O. I expect a deluge of announcements, and you can bet we'll be here on ThursdAI to break it all down for you.
Thanks to Yam, Wolfram, LDJ, and Nisten for their insights on the show, and thanks to all of you for tuning in, reading, and being part of this amazing community. We stay up to date so you don't have to!
Catch you next week!
Cheers,
Alex


