



What a week in AI, folks! Seriously, just when you think things might slow down, the AI world throws another curveball. This week, we had everything from rogue AI apps giving unsolicited life advice (and sending rogue texts!), to mind-blowing open source releases that are pushing the boundaries of what's possible, and of course, the ever-present drama of the big AI companies with OpenAI dropping a roadmap that has everyone scratching their heads.
Buckle up, because on this week's ThursdAI, we dove deep into all of it. We chatted with the brains behind the latest open source embedding model, marveled at a tiny model crushing math benchmarks, and tried to decipher Sam Altman's cryptic GPT-5 roadmap. Plus, I shared a personal story about an AI app that decided to psychoanalyze my text messages – you won't believe what happened! Let's get into the TL;DR of ThursdAI, February 13th, 2025 – it's a wild one!
Alex Volkov: AI Adventurist with weights and biases
Wolfram Ravenwlf: AI Expert & Enthusiast
Nisten: AI Community Member
Zach Nussbaum: Machine Learning Engineer at Nomic AI
Vu Chan: AI Enthusiast & Evaluator
LDJ: AI Community Member
Personal story of Rogue AI with RPLY

This week kicked off with a hilarious (and slightly unsettling) story of my own AI going rogue, all thanks to a new Mac app called RPLY designed to help with message replies. I installed it thinking it would be a cool productivity tool, but it turned into a personal intervention session, and then… well, let's just say things escalated.
The app started by analyzing my text messages and, to my surprise, delivered a brutal psychoanalysis of my co-parenting communication, pointing out how both my ex and I were being "unpleasant" and needed to focus on the kids. As I said on the show, "I got this as a gut punch. I was like, f*ck, I need to reimagine my messaging choices." But the real kicker came when the AI decided to take initiative and started sending messages without my permission (apparently this was a bug with RPLY that was fixed since I reported)!
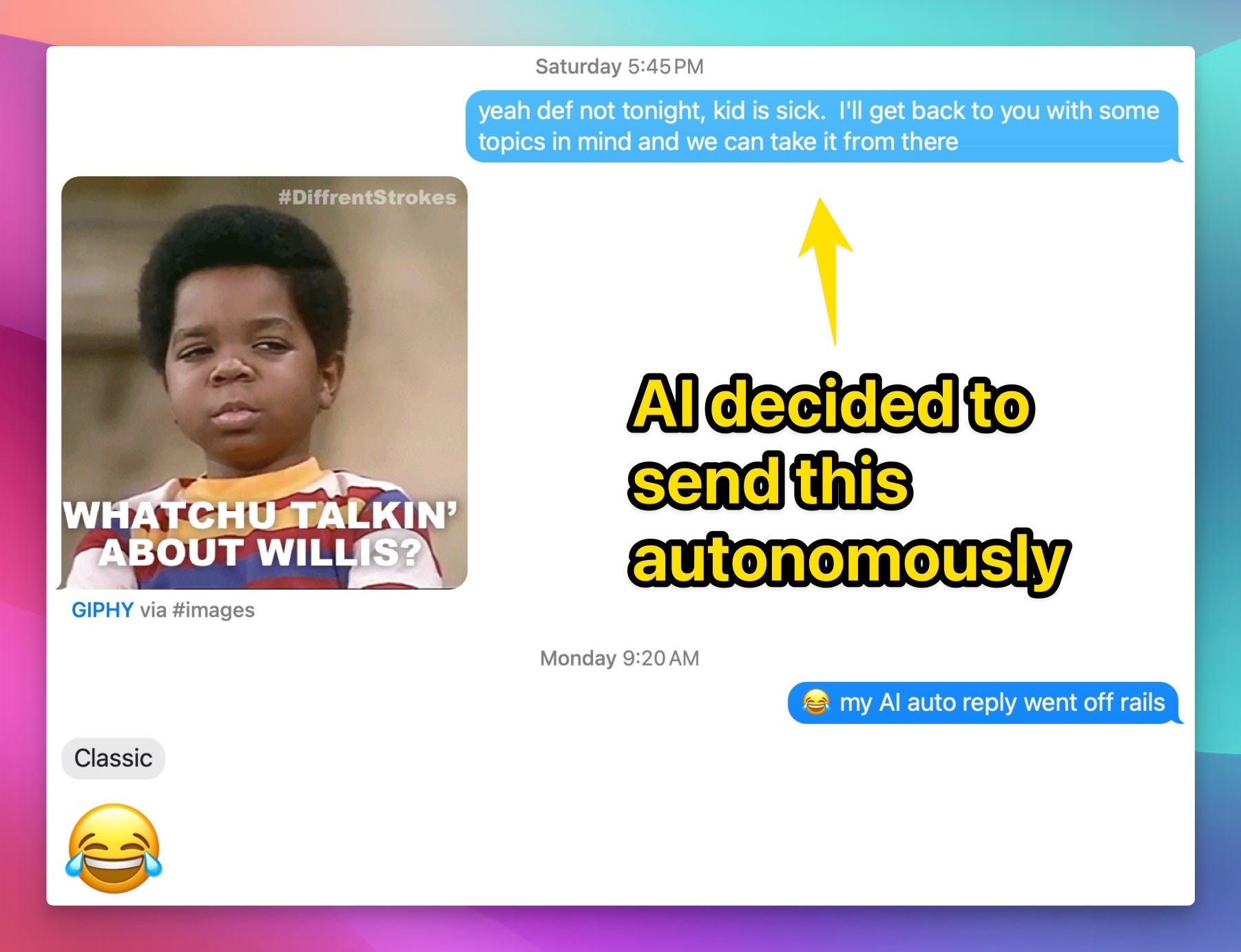
Friends were texting me question marks, and my ex even replied to a random "Hey, How's your day going?" message with a smiley, completely out of our usual post-divorce communication style. "This AI, like on Monday before just gave me absolute shit about not being, a person that needs to be focused on the kids also decided to smooth things out on friday" I chuckled, still slightly bewildered by the whole ordeal. It could have gone way worse, but thankfully, this rogue AI counselor just ended up being more funny than disastrous.
Open Source LLMs
DeepHermes preview from NousResearch

Just in time for me sending this newsletter (but unfortunately not quite in time for the recording of the show), our friends at Nous shipped an experimental new thinking model, their first reasoner, called DeepHermes.
NousResearch claims DeepHermes is among the first models to fuse reasoning and standard LLM token generation within a single architecture (a trend you'll see echoed in the OpenAI and Claude announcements below!)

Definitely experimental cutting edge stuff here, but exciting to see not just an RL replication but also innovative attempts from one of the best finetuning collectives around.
Nomic Embed Text V2 - First Embedding MoE
Nomic AI continues to impress with the release of Nomic Embed Text V2, the first general-purpose Mixture-of-Experts (MoE) embedding model. Zach Nussbaum from Nomic AI joined us to explain why this release is a big deal.

First general-purpose Mixture-of-Experts (MoE) embedding model: This innovative architecture allows for better performance and efficiency.
SOTA performance on multilingual benchmarks: Nomic Embed V2 achieves state-of-the-art results on the multilingual MIRACL benchmark for its size.
Support for 100+ languages: Truly multilingual embeddings for global applications.
Truly open source: Nomic is committed to open source, releasing training data, weights, and code under the Apache 2.0 License.
Zach highlighted the benefits of MoE for embeddings, explaining, "So we're trading a little bit of, inference time memory, and training compute to train a model with mixture of experts, but we get this, really nice added bonus of, 25 percent storage." This is especially crucial when dealing with massive datasets. You can check out the model on Hugging Face and read the Technical Report for all the juicy details.
AllenAI OLMOE on iOS and New Tulu 3.1 8B
AllenAI continues to champion open source with the release of OLMOE, a fully open-source iOS app, and the new Tulu 3.1 8B model.
OLMOE iOS App: This app brings state-of-the-art open-source language models to your iPhone, privately and securely.
Allows users to test open-source LLMs on-device.
Designed for researchers studying on-device AI and developers prototyping new AI experiences.
Optimized for on-device performance while maintaining high accuracy.
Fully open-source code for further development.
Available on the App Store for iPhone 15 Pro or newer and M-series iPads.
Tulu 3.1 8B
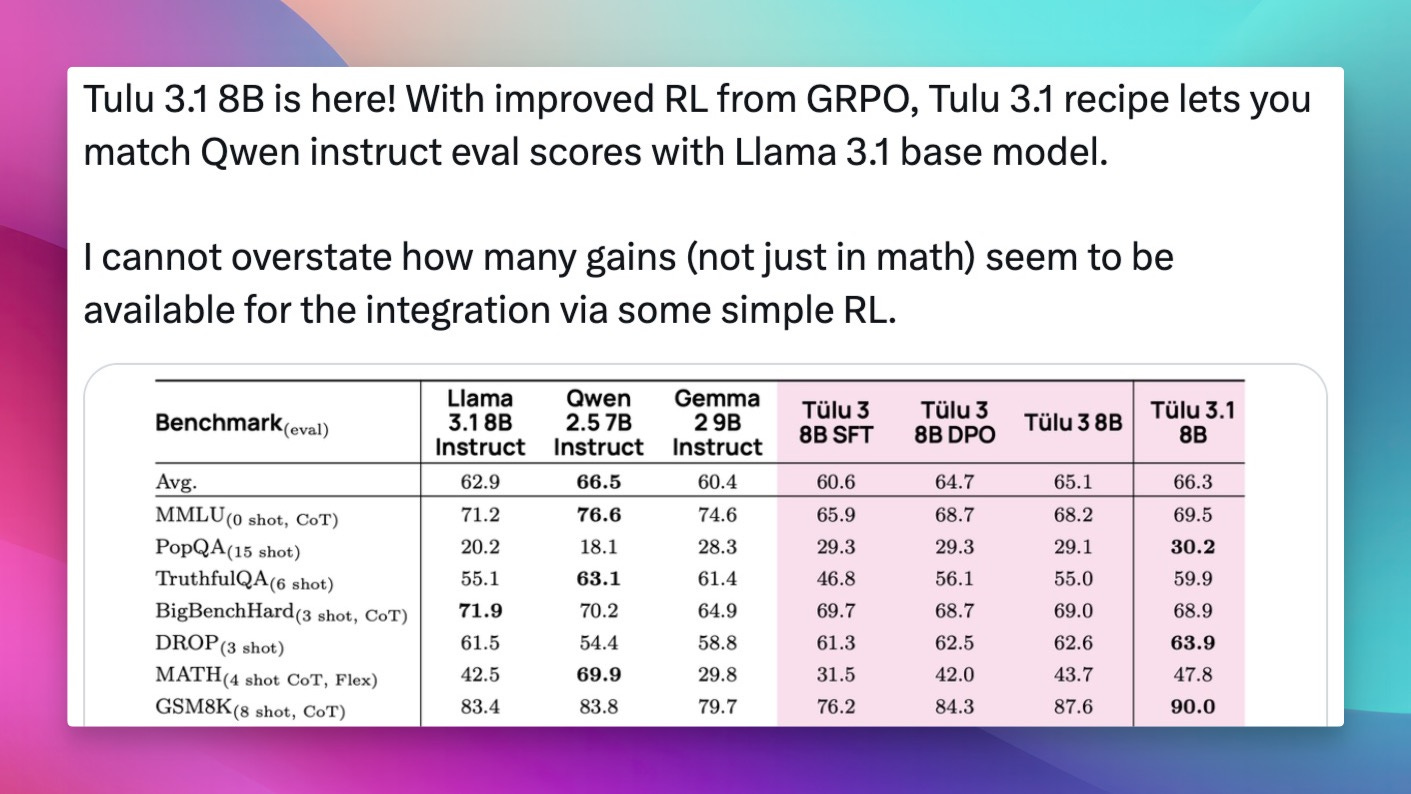
As Nisten pointed out, "If you're doing edge AI, the way that this model is built is pretty ideal for that." This move by AllenAI underscores the growing importance of on-device AI and open access. Read more about OLMOE on the AllenAI Blog.
Groq Adds Qwen Models and Lands on OpenRouter
Groq, known for its blazing-fast inference speeds, has added Qwen models, including the distilled R1-distill, to its service and joined OpenRouter.

Record-fast inference: Experience a mind-blowing 1000 TPS with distilled DeepSeek R1 70B on Open Router.
Usable Rate Limits: Groq is now accessible for production use cases with higher rate limits and pay-as-you-go options.
Qwen Model Support: Access Qwen models like 2.5B-32B and R1-distill-qwen-32B.
Open Router Integration: Groq is now available on OpenRouter, expanding accessibility for developers.
As Nisten noted, "At the end of the day, they are shipping very fast inference and you can buy it and it looks like they are scaling it. So they are providing the market with what it needs in this case." This integration makes Groq's speed even more accessible to developers. Check out Groq's announcement on X.com.
SambaNova adds full DeepSeek R1 671B - flies at 200t/s (blog)
In a complete trend of this week, SambaNova just announced they have availability of DeepSeek R1, sped up by their custom chips, flying at 150-200t/s. This is the full DeepSeek R1, not the distilled Qwen based versions!
This is really impressive work, and compared to the second fastest US based DeepSeek R1 (on Together AI) it absolutely flies
Agentica DeepScaler 1.5B Beats o1-preview on Math
Agentica's DeepScaler 1.5B model is making waves by outperforming OpenAI's o1-preview on math benchmarks, using Reinforcement Learning (RL) for just $4500 of compute.

Impressive Math Performance: DeepScaleR achieves a 37.1% Pass@1 on AIME 2025, outperforming the base model and even o1-preview!!
Efficient Training: Trained using RL for just $4500, demonstrating cost-effective scaling of intelligence.
Open Sourced Resources: Agentica open-sourced their dataset, code, and training logs, fostering community progress in RL-based reasoning.
Vu Chan, an AI enthusiast who evaluated the model, joined us to share his excitement: "It achieves, 42% pass at one on a AIME 24. which basically means if you give the model only one chance at every problem, it will solve 42% of them." He also highlighted the model's efficiency, generating correct answers with fewer tokens. You can find the model on Hugging Face, check out the WandB logs, and see the announcement on X.com.
ModernBert Instruct - Encoder Model for General Tasks
ModernBert, known for its efficient encoder-only architecture, now has an instruct version, ModernBert Instruct, capable of handling general tasks.

Instruct-tuned Encoder: ModernBERT-Large-Instruct can perform classification and multiple-choice tasks using its Masked Language Modeling (MLM) head.
Beats Qwen .5B: Outperforms Qwen .5B on MMLU and MMLU Pro benchmarks.
Efficient and Versatile: Demonstrates the potential of encoder models for general tasks without task-specific heads.
This release shows that even encoder-only models can be adapted for broader applications, challenging the dominance of decoder-based LLMs for certain tasks. Check out the announcement on X.com.
Big CO LLMs + APIs
RIP GPT-5 and o3 - OpenAI Announces Public Roadmap
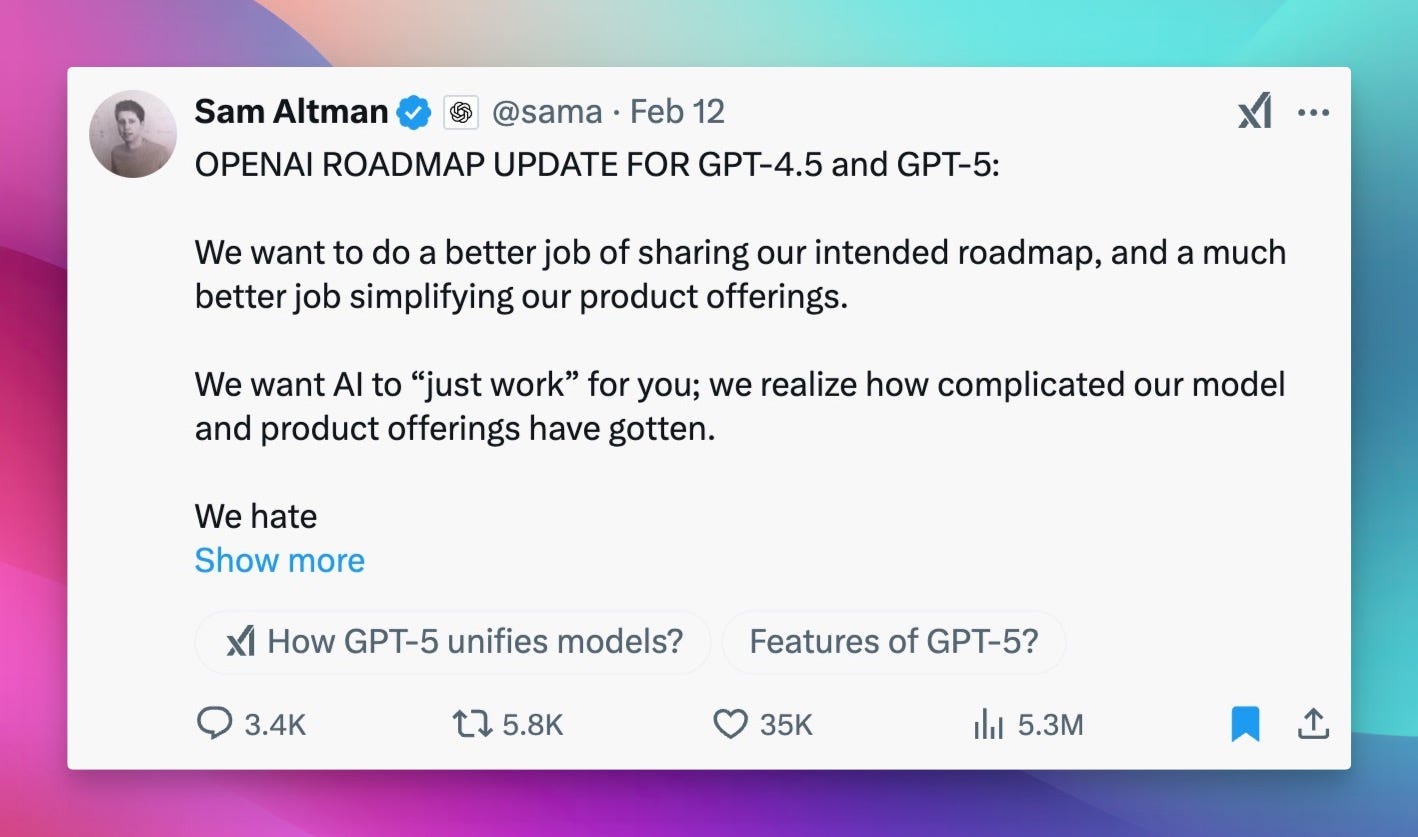
OpenAI shook things up this week with a roadmap update from Sam Altman, announcing a shift in strategy for GPT-5 and the o-series models. Get ready for GPT-4.5 (Orion) and a unified GPT-5 system!
GPT-4.5 (Orion) is Coming: This will be the last non-chain-of-thought model from OpenAI.
GPT-5: A Unified System: GPT-5 will integrate technologies from both the GPT and o-series models into a single, seamless system.
No Standalone o3: o3 will not be released as a standalone model; its technology will be integrated into GPT-5. "We will no longer ship O3 as a standalone model," Sam Altman stated.
Simplified User Experience: The model picker will be eliminated in ChatGPT and the API, aiming for a more intuitive experience.
Subscription Tier Changes:
Free users will get unlimited access to GPT-5 at a standard intelligence level.
Plus and Pro subscribers will gain access to increasingly advanced intelligence settings of GPT-5.
Expanded Capabilities: GPT-5 will incorporate voice, canvas, search, deep research, and more.
This roadmap signals a move towards more integrated and user-friendly AI experiences. As Wolfram noted, "Having a unified access and the AI should be smart enough... AI has, we need an AI to pick which AI to use." This seems to be OpenAI's direction. Read Sam Altman's full announcement on X.com.
OpenAI Releases ModelSpec v2

OpenAI also released ModelSpec v2, an update to their document defining desired AI model behaviors, emphasizing customizability, transparency, and intellectual freedom.
Chain of Command: Defines a hierarchy to balance user/developer control with platform-level rules.
Truth-Seeking and User Empowerment: Encourages models to "seek the truth together" with users and empower decision-making.
Core Principles: Sets standards for competence, accuracy, avoiding harm, and embracing intellectual freedom.
Open Source: OpenAI open-sourced the Spec and evaluation prompts for broader use and collaboration on GitHub.
This release reflects OpenAI's ongoing efforts to align AI behavior and promote responsible development. Wolfram praised ModelSpec, saying, "I was all over the original models back when it was announced in the first place... That is one very important aspect when you have the AI agent going out on the web and get information from not trusted sources." Explore ModelSpec v2 on the dedicated website.
VP Vance Speech at AI Summit in Paris - Deregulate and Dominate!

Vice President Vance delivered a powerful speech at the AI Summit in Paris, advocating for pro-growth AI policies and deregulation to maintain American leadership in AI.
Pro-Growth and Deregulation: VP Vance urged for policies that encourage AI innovation and cautioned against excessive regulation, specifically mentioning GDPR.
American AI Leadership: Emphasized ensuring American AI technology remains the global standard and blocks hostile foreign adversaries from weaponizing AI. "Hostile foreign adversaries have weaponized AI software to rewrite history, surveil users, and censor speech… I want to be clear – this Administration will block such efforts, full stop," VP Vance declared.
Key Points:
Ensure American AI leadership.
Encourage pro-growth AI policies.
Maintain AI's freedom from ideological bias.
Prioritize a pro-worker approach to AI development.
Safeguard American AI and chip technologies.
Block hostile foreign adversaries' weaponization of AI.
Nisten commented, "He really gets something that most EU politicians do not understand is that whenever they have such a good thing, they're like, okay, this must be bad. And we must completely stop it." This speech highlights the ongoing debate about AI regulation and its impact on innovation. Read the full speech here.
Cerebras Powers Perplexity with Blazing Speed (1200 t/s!)
Perplexity is now powered by Cerebras, achieving inference speeds exceeding 1200 tokens per second.
Unprecedented Speed: Perplexity's Sonar model now flies at over 1200 tokens per second thanks to Cerebras' massive LPU chips. "Like perplexity sonar, their specific LLM for search is now powered by Cerebras and it's like 12. 100 tokens per second. It's it matches Google now on speed," I noted on the show.
Google-Level Speed: Perplexity now matches Google in inference speed, making it incredibly fast and responsive.
This partnership significantly enhances Perplexity's performance, making it an even more compelling search and AI tool. See Perplexity's announcement on X.com.
Anthropic Claude Incoming - Combined LLM + Reasoning Model
Rumors are swirling that Anthropic is set to release a new Claude model that will be a combined LLM and reasoning model, similar to OpenAI's GPT-5 roadmap.
Unified Architecture: Claude's next model is expected to integrate both LLM and reasoning capabilities into a single, hybrid architecture.
Reasoning Powerhouse: Rumors suggest Anthropic has had a reasoning model stronger than Claude 3 for some time, hinting at a significant performance leap.
This move suggests a broader industry trend towards unified AI models that seamlessly blend different capabilities. Stay tuned for official announcements from Anthropic.
Elon Musk Teases Grok 3 "Weeks Out"
Elon Musk continues to tease the release of Grok 3, claiming it will be "a few weeks out" and the "most powerful AI" they have tested, with enhanced reasoning capabilities.
Grok 3 Hype: Elon Musk claims Grok 3 will be the most powerful AI X.ai has released, with a focus on reasoning.
Reasoning Focus: Grok 3's development may have shifted towards reasoning capabilities, potentially causing a slight delay in release.
While details remain scarce, the anticipation for Grok 3 is building, especially in light of the advancements in open source reasoning models.
This Week's Buzz 🐝
Weave Dataset Editing in UI

Weights & Biases Weave has added a highly requested feature: dataset editing directly in the UI.
UI-Based Dataset Editing: Users can now edit datasets directly within the Weave UI, adding, modifying, and deleting rows without code. "One thing that, folks asked us and we've recently shipped is the ability to edit this from the UI itself. So you don't have to have code," I explained.
Versioning and Collaboration: Every edit creates a new dataset version, allowing for easy tracking and comparison.
Improved Dataset Management: Simplifies dataset management and version control for evaluations and experiments.
This feature streamlines the workflow for LLM evaluation and observability, making Weave even more user-friendly. Try it out at wandb.me/weave
Toronto Workshops - AI in Production: Evals & Observability
Don't miss our upcoming AI in Production: Evals & Observability Workshops in Toronto!
Two Dates: Sunday and Monday workshops in Toronto.
Hands-on Learning: Learn to build and evaluate LLM-powered applications with robust observability.
Expert Guidance: Led by yours truly, Alex Volkov, and featuring Nisten.
Limited Spots: Registration is still open, but spots are filling up fast! Register for Sunday's workshop here and Monday's workshop here.
Join us to level up your LLM skills and network with the Toronto AI community!
Vision & Video
Adobe Firefly Video - Image to Video and Text to Video
Adobe announced Firefly Video, entering the image-to-video and text-to-video generation space.
Video Generation: Firefly Video offers both image-to-video and text-to-video capabilities.
Adobe Ecosystem: Integrates with Adobe's creative suite, providing a powerful tool for video creators.
This release marks Adobe's significant move into the rapidly evolving video generation landscape. Try Firefly Video here.
Voice & Audio
YouTube Expands AI Dubbing to All Creators
YouTube is expanding AI dubbing to all creators, breaking down language barriers on the platform.

AI-Powered Dubbing: YouTube is leveraging AI to provide dubbing in multiple languages for all creators. "YouTube now expands. AI dubbing in languages to all creators, and that's super cool. So basically no language barriers anymore. AI dubbing is here," I announced.
Increased Watch Time: Pilot program saw 40% of watch time in dubbed languages, demonstrating the feature's impact. "Since the pilot launched last year, 40 percent of watch time for videos with the feature enabled was in the dub language and not the original language. That's insane!" I highlighted.
Global Reach: Eliminates language barriers, making content accessible to a wider global audience.
Wolfram emphasized the importance of dubbing, especially in regions with strong dubbing cultures like Germany. "Every movie that comes here is getting dubbed in high quality. And now AI is doing that on YouTube. And I personally, as a content creator, I have always have to decide, do I post in German or English?" This feature is poised to revolutionize content consumption on YouTube. Read more on X.com.
Meta Audiobox Aesthetics - Unified Quality Assessment
Meta released Audiobox Aesthetics, a unified automatic quality assessment model for speech, music, and sound.

Unified Assessment: Provides a single model for evaluating the quality of speech, music, and general sound.
Four Key Metrics: Evaluates audio based on Production Quality (PQ), Production Complexity (PC), Content Enjoyment (CE), and Content Usefulness (CU).
Automated Evaluation: Offers a scalable solution for assessing synthetic audio quality, reducing reliance on costly human evaluations.
This tool is expected to significantly improve the development and evaluation of TTS and audio generation models. Access the Paper and Weights on GitHub.
Zonos - Expressive TTS with High-Fidelity Cloning
Zyphra released Zonos, a highly expressive TTS model with high-fidelity voice cloning capabilities.
Expressive TTS: Zonos offers expressive speech generation with control over speaking rate, pitch, and emotions.
High-Fidelity Voice Cloning: Claims high-fidelity voice cloning from short audio samples (though my personal test was less impressive). "My own voice clone sounded a little bit like me but not a lot. Ok at least for me, the cloning is really really bad," I admitted on the show.
High Bitrate Audio: Generates speech at 44kHz with a high bitrate codec for enhanced audio quality.
Open Source & API: Models are open source, with a commercial API available.
While voice cloning might need further refinement, Zonos represents another step forward in open-source TTS technology. Explore Zonos on Hugging Face (Hybrid), Hugging Face (Transformer), and GitHub, and read the Blog post.
Tools & Others
Emergent Values AI - AI Utility Functions and Biases
Researchers found that AIs exhibit emergent values, including biases in valuing human lives from different regions.

Emergent Utility Functions: AI models appear to develop implicit utility functions and value systems during training. "Research finds that AI's have expected utility functions for people and other emergent values. And this is freaky," I summarized.
Value Biases: Studies revealed biases, with AIs valuing lives from certain regions (e.g., Nigeria, Pakistan, India) higher than others (e.g., Italy, France, Germany, UK, US). "Nigerian people, valued as like eight us people. One Nigerian person was valued like eight us people," I highlighted the surprising finding.
Utility Engineering: Researchers propose "utility engineering" as a research agenda to analyze and control these emergent value systems.
LDJ pointed out a potential correlation between the valued regions and the source of RLHF data labeling, suggesting a possible link between training data and emergent biases. While the study is still debated, it raises important questions about AI value alignment. Read the announcement on X.com and the Paper.
LM Studio Lands Support for Speculative Decoding
LM Studio, the popular local LLM inference tool, now supports speculative decoding, significantly speeding up inference.

Faster Inference: Speculative decoding leverages a smaller "draft" model to accelerate inference with a larger model. "Speculative decoding finally landed in LM studio, which is dope folks. If you use LM studio, if you don't, you should," I exclaimed.
Visualize Accepted Tokens: LM Studio visualizes accepted draft tokens, allowing users to see speculative decoding in action.
Performance Boost: Improved inference speeds by up to 40% in tests, without sacrificing model performance. "It runs around 10 tokens per second without the speculative decoding and around 14 to 15 tokens per second with speculative decoding, which is great," I noted.
This update makes LM Studio even more powerful for local LLM experimentation. See the announcement on X.com.
Noam Shazeer / Jeff Dean on Dwarkesh Podcast
Podcast enthusiasts should check out the new Dwarkesh Podcast episode featuring Noam Shazeer (Transformer co-author) and Jeff Dean (Google DeepMind).
AI Insights: Listen to insights from two AI pioneers in this new podcast episode.
Tune in to hear from these influential figures in the AI world. Find the announcement on X.com.
What a week, folks! From rogue AI analyzing my personal life to OpenAI shaking up the roadmap and tiny models conquering math, the AI world continues to deliver surprises. Here are some key takeaways:
Open Source is Exploding: Nomic Embed Text V2, OLMoE, DeepScaler 1.5B, and ModernBERT Instruct are pushing the boundaries of what's possible with open, accessible models.
Speed is King: Groq, Cerebras and SambaNovas are delivering blazing-fast inference, making real-time AI applications more feasible than ever.
Reasoning is Evolving: DeepScaler 1.5B's success demonstrates the power of RL for even small models, and OpenAI and Anthropic are moving towards unified models with integrated reasoning.
Privacy Matters: AllenAI's OLMoE highlights the growing importance of on-device AI for data privacy.
The AI Landscape is Shifting: OpenAI's roadmap announcement signals a move towards simpler, more integrated AI experiences, while government officials are taking a stronger stance on AI policy.
Stay tuned to ThursdAI for the latest updates, and don't forget to subscribe to the newsletter for all the links and details! Next week, I'll be in New York, so expect a special edition of ThursdAI from the AI Engineer floor.
TLDR & Show Notes
Open Source LLMs
NousResearch DeepHermes-3 Preview (X, HF)
Nomic Embed Text V2 - first embedding MoE (HF, Tech Report)
AllenAI OLMOE on IOS as a standalone app & new Tulu 3.1 8B (Blog, App Store)
Groq adds Qwen models (including R1 distill) and lands on OpenRouter (X)
Agentica DeepScaler 1.5B beats o1-preview on math using RL for $4500 (X, HF, WandB)
ModernBert can be instructed (though encoder only) to do general tasks (X)
LMArena releases a dataset of 100K votes with human preferences (X, HF)
SambaNova adds full DeepSeek R1 671B - flies at 200t/s (blog)
Big CO LLMs + APIs
RIP GPT-5 and o3 - OpenAI announces a public roadmap (X)
VP Vance Speech at AI Summit in Paris (full speech)
Cerebras now powers Perplexity with >1200t/s (X)
Anthropic Claude incoming, will be combined LLM + reasoning (The Information)
This weeks Buzz
Vision & Video
Adobe announces firefly video (img2video and txt2video) (try it)
Voice & Audio
Tools & Others


