




Hold on tight, folks, because THIS week on ThursdAI felt like riding a roller coaster through the wild world of open-source AI - extreme highs, mind-bending twists, and a sprinkle of "wtf is happening?" conspiracy theories for good measure. 😂
Theme of this week is, Open Source keeps beating GPT-4, while we're inching towards intelligence too cheap to meter on the API fronts.
We even had a live demo so epic, folks at the Large Hadron Collider are taking notice! Plus, strawberry shenanigans abound (did Sam REALLY tease GPT-5?), and your favorite AI evangelist nearly got canceled on X! Buckle up; this is gonna be another long one! 🚀
Qwen2-Math Drops a KNOWLEDGE BOMB: Open Source Wins AGAIN!
When I say "open source AI is unstoppable", I MEAN IT. This week, the brilliant minds from Alibaba's Qwen team decided to show everyone how it's DONE. Say hello to Qwen2-Math-72B-Instruct - a specialized language model SO GOOD at math, it's achieving a ridiculous 84 points on the MATH benchmark. 🤯
For context, folks... that's beating GPT-4, Claude Sonnet 3.5, and Gemini 1.5 Pro. We're not talking incremental improvements here - this is a full-blown DOMINANCE of the field, and you can download and use it right now. 🔥
Get Qwen-2 Math from HuggingFace here
What made this announcement EXTRA special was that Junyang Lin , the Chief Evangelist Officer at Alibaba Qwen team, joined ThursdAI moments after they released it, giving us a behind-the-scenes peek at the effort involved. Talk about being in the RIGHT place at the RIGHT time! 😂
They painstakingly crafted a massive, math-specific training dataset, incorporating techniques like Chain-of-Thought reasoning (where the model thinks step-by-step) to unlock this insane level of mathematical intelligence.
"We have constructed a lot of data with the form of ... Chain of Thought ... And we find that it's actually very effective. And for the post-training, we have done a lot with rejection sampling to create a lot of data sets, so the model can learn how to generate the correct answers" - Junyang Lin
Now I gotta give mad props to Qwen for going beyond just raw performance - they're open-sourcing this beast under an Apache 2.0 license, meaning you're FREE to use it, fine-tune it, adapt it to your wildest mathematical needs! 🎉
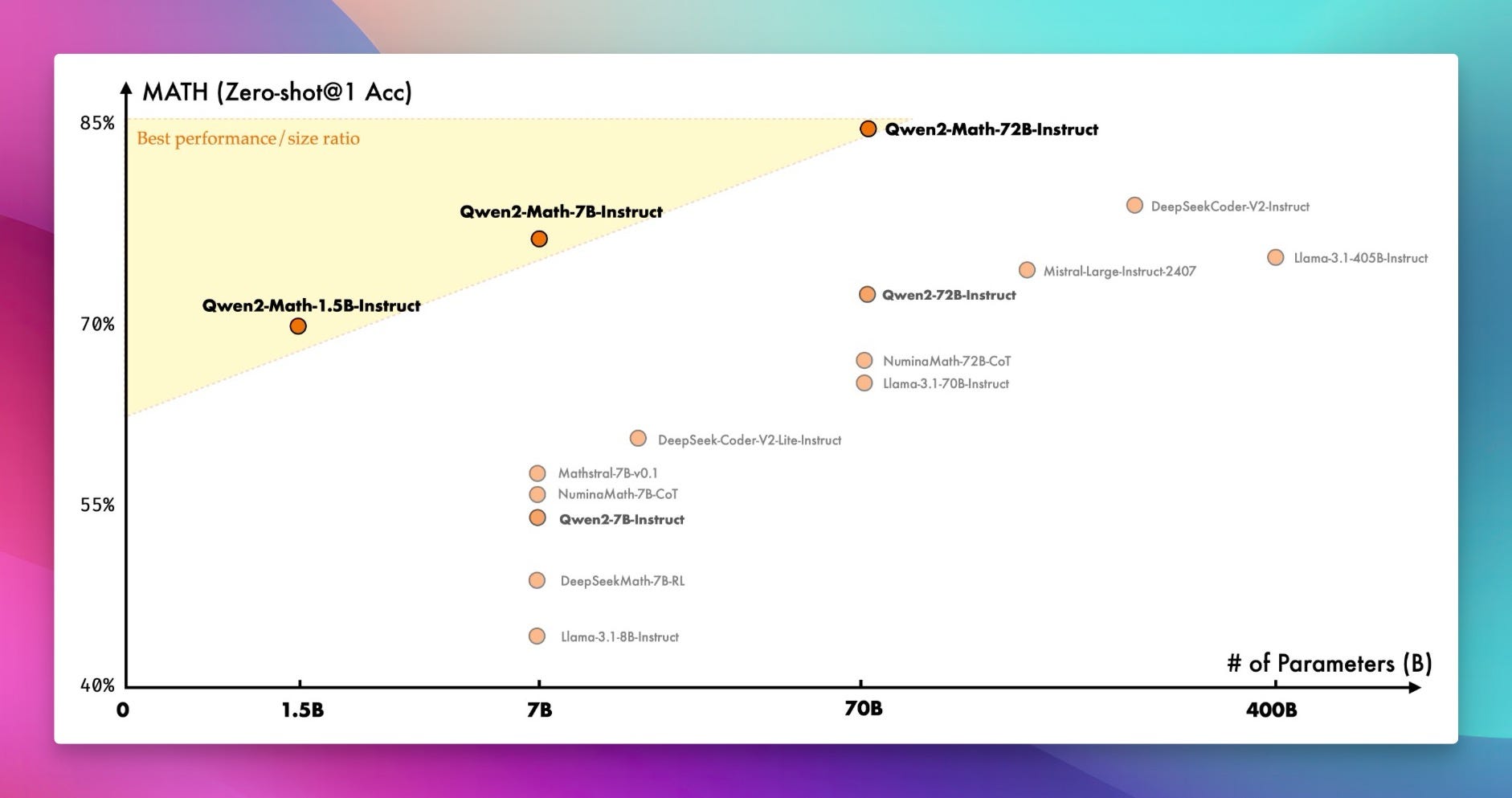
But hold on... the awesomeness doesn't stop there! Remember those smaller, resource-friendly LLMs everyone's obsessed with these days? Well, Qwen released 7B and even 1.5B versions of Qwen-2 Math, achieving jaw-dropping scores for their size (70 for the 1.5B?? That's unheard of!).🤯 Nisten nearly lost his mind when he heard that - and trust me, he's seen things. 😂
"This is insane! This is... what, Sonnet 3.5 gets what, 71? 72? This gets 70? And it's a 1.5B? Like I could run that on someone's watch. Real." - Nisten
With this level of efficiency, we're talking about AI-powered calculators, tutoring apps, research tools that run smoothly on everyday devices. The potential applications are endless!
MiniCPM-V 2.6: A Pocket-Sized GPT-4 Vision... Seriously! 🤯
If Qwen's Math marvel wasn't enough open-source goodness for ya, OpenBMB had to get in on the fun too! This time, they're bringing the 🔥 to vision with MiniCPM-V 2.6 - a ridiculous 8 billion parameter VLM (visual language model) that packs a serious punch, even outperforming GPT-4 Vision on OCR benchmarks!
OpenBMB drops a bomb on X here
I'll say this straight up: talking about vision models in a TEXT-based post is hard. You gotta SEE it to believe it. But folks... TRUST ME on this one. This model is mind-blowing, capable of analyzing single images, multi-image sequences, and EVEN VIDEOS with an accuracy that rivaled my wildest hopes for open-source.🤯

Check out their playground and prepare to be stunned
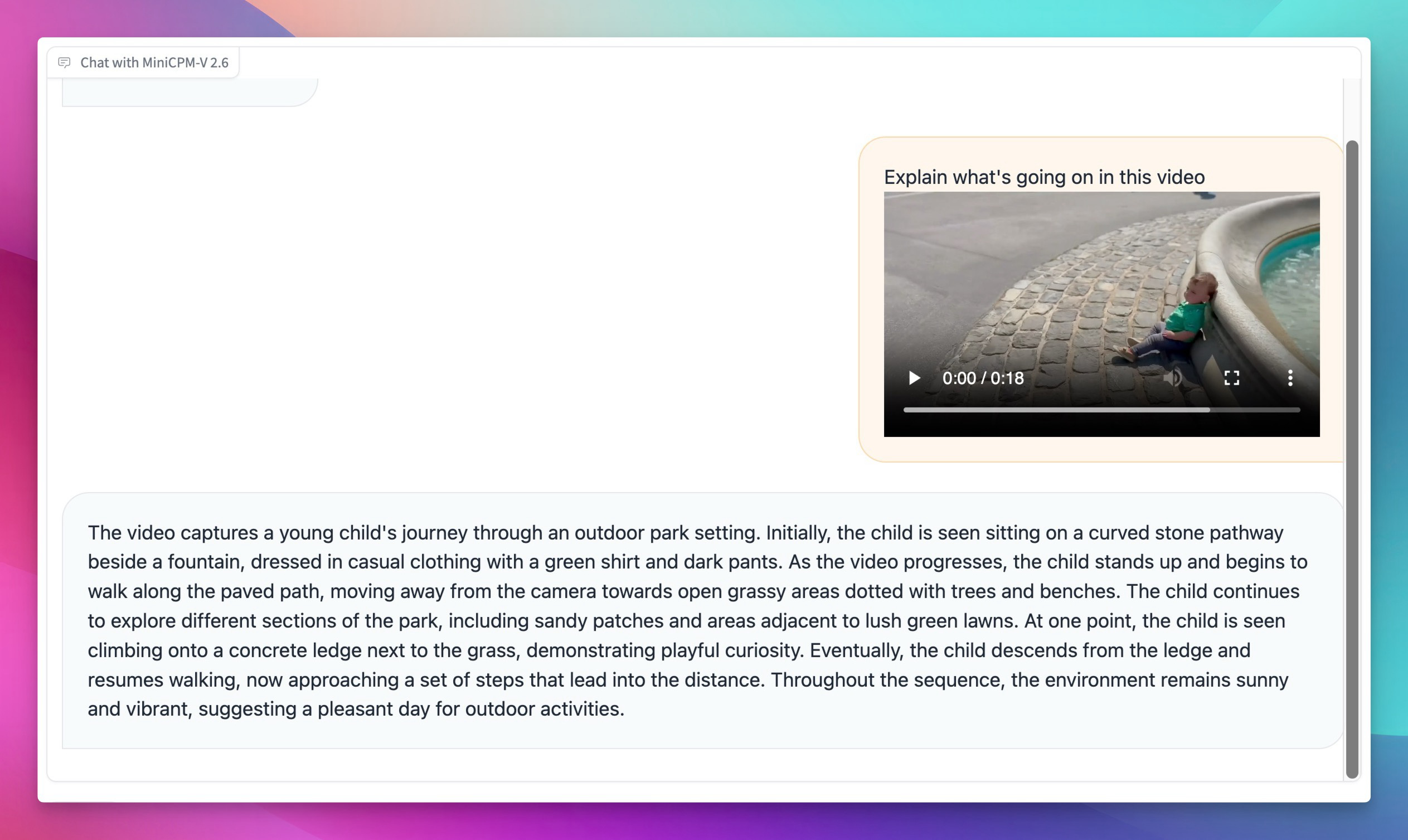
It even captured every single nuance in this viral toddler speed-running video I threw at it, with an accuracy I haven't seen in models THIS small:
"The video captures a young child's journey through an outdoor park setting. Initially, the child ... is seen sitting on a curved stone pathway besides a fountain, dressed in ... a green t-shirt and dark pants. As the video progresses, the child stands up and begins to walk ..."
Junyang said that they actually collabbed with the OpenBMB team and knows firsthand how much effort went into training this model:
"We actually have some collaborations with OpenBMB... it's very impressive that they are using, yeah, multi-images and video. And very impressive results. You can check the demo... the performance... We care a lot about MMMU [the benchmark], but... it is actually relying much on large language models." - Junyang Lin
Nisten and I have been talking for months about the relationship between these visual "brains" and the larger language model base powering their "thinking." While it seems smaller models are catching up fast, combining a top-notch visual processor like MiniCPM-V with a monster LLM like Quen72B or Llama 405B could unlock truly unreal capabilities.
This is why I'm excited - open source lets us mix and match like this! We can Frankenstein the best parts together and see what emerges... and it's usually something mind-blowing. 🤯
From the Large Hadron Collider to YOUR Phone: This Model Runs ANYWHERE 🚀
While Qwen2-Math is breaking records on one hand, Nisten's latest creation, Biggie-SmoLlm, is showcasing the opposite side of the spectrum. Trying to get the smallest/fastest coherent LLM possible, Nisten blew up on HuggingFace.
Biggie-SmoLlm (Hugging Face) is TINY, efficient, and with some incredible optimization work from the folks right here on the show, it's reaching an insane 330 tokens/second on regular M3 chips. 🤯 That's WAY faster than real-time conversation, folks! And thanks to Eric Hartford's (from Cognitive Computation) awesome new optimizer, (Grok AdamW) it's surprisingly coherent for such a lil' fella.
The cherry on top? Someone messaged Nisten saying they're using Biggie-SmoLlm at the Large. Hadron. Collider. 😳 I'll let that sink in for a second.
It was incredible having ALL the key players behind Biggie-SmoLlm right there on stage: LDJ (whose Capybara dataset made it teaching-friendly), Junyang (whose Qwen work served as the base), and Eric (the optimizer mastermind himself). THIS, my friends, is what the ThursdAI community is ALL about! 🚀
Speaking of which this week we got a new friend of the pod, Mark Saroufim, a long time PyTorch core maintainer, to join the community.
This Week's Buzz (and Yes, It Involves Making AI Even Smarter) 🤓
NeurIPS Hacker Cup 2024 - Can You Solve Problems Humans Struggle With? 🤔
I've gotta hand it to my PyTorch friend, Mark Saroufim. He knows how to make AI interesting! He and his incredible crew (Weiwei from MSFT, some WandB brainiacs, and more) are bringing you NeurIPS Hacker Cup 2024 - a competition to push those coding agents to their ABSOLUTE limits. 🚀
This isn't your typical "LeetCode easy" challenge, folks... These are problems SO hard, years of competitive programming experience are required to even attempt them! Mark himself said,
“At this point, like, if a model does make a significant dent in this competition, uh, I think people would need to acknowledge that, like, LLMs can do a form of planning. ”
And don't worry, total beginners: Mark and Weights & Biases are hosting a series of FREE sessions to level you up. Get those brain cells prepped and ready for the challenge and then Join the NeurIPS Hacker Cup Discord
P.S. We're ALSO starting a killer AI Salon series in our SF office August 15th! You'll get a chance to chat with researches like Shreya Shankar - she's a leading voice on evaluation. More details and free tickets right here! AI Salons Link
Big Co & APIs - Towards intelligence too cheap to meter
Open-source was crushing it this week... but that didn't stop Big AI from throwing a few curveballs. OpenAI is doubling down on structured data (AND cheaper models!), Google slashed Gemini prices again (as we trend towards intelligence too cheap to meter), and a certain strawberry mystery took over Twitter.
DeepSeek context caching lowers price by 90% automatiically
DeepSeek, those masters of ridiculously-good coding AI, casually dropped a bombshell - context caching for their API! 🤯
If you're like "wait, what does THAT mean?", listen up because this is game-changing for production-grade AI:
Problem: LLMs get fed the ENTIRE conversation history EVERY. SINGLE. TIME. This wastes compute (and $$$) when info is repeated.
Solution: DeepSeek now remembers what you've said, automatically pulling from a cache when the conversation goes down familiar paths.
The Win: Up to 90% cheaper API calls. Yes, NINETY.😳 It costs 1.4 CENTS per million tokens for cached content. Let THAT sink in. 🤯
As Nisten (always bringing the technical breakdowns) explained:
"Everyone should be using LLMs this way!...The simplest way is to have a long conversation ... then you save it on disk... you don't have to wait again ... [it's] kind of free. DeepSeek... did this in a more dynamic way". - Nisten
Even Matt Shumer, who usually advocates for clever prompting over massive context, got legitimately hyped about the possibilities:
"For me, and how we use LLMs... instead of gathering a million examples... curate a hundred gold examples... you have something better than if you fine-tuned it, and cheaper, and faster..." - Matt Shumer
Think about this... instead of painstakingly fine-tuning, we can "guide" models with expertly crafted examples, letting them learn "on the fly" with minimal cost. Context as the NEW fine-tuning! 🤯
P.S - Google actually also has caching on its Gemini API, but you have to opt-in, while this happens automatically with DeepSeek API!
Google Goes "Price War Nuclear": Gemini Flash is Officially TOO CHEAP
Speaking of sneaky advancements from Google... they also dropped an update SO casually impactful, it almost got lost in the shuffle. Gemini Flash (their smallest, but still crazy-good model) is now... 7.5 cents per million tokens for input and 30 cents per million tokens for output... (for up to 128k of context)

I REPEAT: 7.5 cents... with LONG context!? 🤯 Google, please chill, MY SANITY cannot handle this price free-fall any longer! 😂
Full Breakdown of Gemini’s Crazy New Prices on Google’s Blog
While this USUALLY means a model's performance gets quietly nerfed in exchange for lower costs... in Gemini's case? Let's just say... even I, a staunch defender of open-source, am kinda SHOOK by how GOOD this thing is NOW!
After Google threw down this gauntlet, I actually used Gemini to draft my last ThursdAI newsletter (for the first time!). It nailed my tone and style better than any other model I've tried - and I've TRIED them ALL. 🤯 Even Nisten, who's super picky about his coding LLMs, gave it a rare nod of approval. Gemini's image understanding capabilities have improved significantly too! 🤯
Google also added improvements in how Gemini understands PDFs that are worth mentioning 👀

From JSON Headaches to REASONING Gains: What's Really New with GPT-4?
While Matt Shumer, my go-to expert on all things practical AI, might not be immediately impressed by OpenAI's new structured output features, they're still a huge win for many developers. Tired of LLM JSON going haywire? Well, GPT-4 can now adhere to your exact schemas, delivering 100% reliable structured data, no need for Instructor! 🙌
This solves a real problem, even if the prompting gurus (like Matt) have figured out their own workarounds. The key is:
Determinism: This ain't your typical LLM chaos - they're guaranteeing consistency, essential for building reliable applications.
Ease of use: No need for external libraries - it's built right into the API!
Plus... a sneaky price drop, folks! GPT-4 is now 50% cheaper for input tokens and 33% cheaper for output. As I said on the show:
"Again, quite insane... we're getting 50% cheaper just without fanfare. We're going towards 'intelligence too cheap to meter'... it's crazy".
And HERE'S the plot twist... multiple folks on stage (including the eager newcomer N8) noticed significant reasoning improvements in this new GPT-4 model. They tested it on tasks like lateral thinking puzzles and even anecdotally challenging tasks - and guess what? It consistently outperformed older versions. 🤯
"I have my own benchmark... of lateral thinking puzzles... the new GPT-4 [scored] roughly five to 10% higher... these are like really hard lateral thinking puzzles that require innovative reasoning ability". - N8
OpenAI isn't bragging about this upgrade explicitly, which makes me even MORE curious... 🤔
Mistral Joins the AGENT Hype Train (But Their Version is Different)
Everybody wants a piece of that AI "Agent" pie, and now Mistral (the scrappy, efficient French company) is stepping up. They announced a double whammy this week: fine-tuning is here AND "les agents" have arrived... but their agents are NOT quite what we're seeing elsewhere (think AutoGPT, CrewAI, all those looped assistants). 🤔
Mistral's Blog Post - Fine-tuning & Agents... Ooh La La!
Their fine-tuning service is pretty straightforward: upload your data and they'll host a bespoke Mistral Large V2 running through their API at no extra cost (very cool!).
Their agents aren't based on agentic loop-running like what we see from those recursive assistants. As I pointed out on ThursdAI:
"[Mistral] agents are not agentic... They're more similar to... GPTs for OpenAI or 'Projects' in Anthropic, where... you as a user add examples and preload context".
It's more about defining agents with examples and system prompts, essentially letting Mistral "pre-tune" their models for specific tasks. This lets you deploy those agents via the API or to their LeChat platform - pretty darn neat!
Build your OWN agent - Mistral's "Agent Builder" is slick!
While not as flashy as those recursive agents that build websites and write symphonies on their own, Mistral's take on the agent paradigm is strategic. It plays to their strengths:
Developer-focused: It's about creating bespoke, task-specific tools - think API integrations, code reviewers, or content generators.
Ease of deployment: No need for complex loop management, Mistral handles the hard parts for you!
Mistral even teased that they'll eventually be incorporating tool use... so these "pre-tuned" agents could quickly evolve into something very interesting. 😏
NVIDIA leak about downloading videos went viral (And the Internet... Didn't Like That!)
This week, I found myself unexpectedly at the center of an X drama explosion (fun times! 😅 ) when some leaked NVIDIA Slack messages showed them discussing which YouTube channels to scrape. My crime? I dared to ask how this is different from how Google creating Street View, filming every street possible without asking for permission. My Honest Question that Sparked AI Outrage
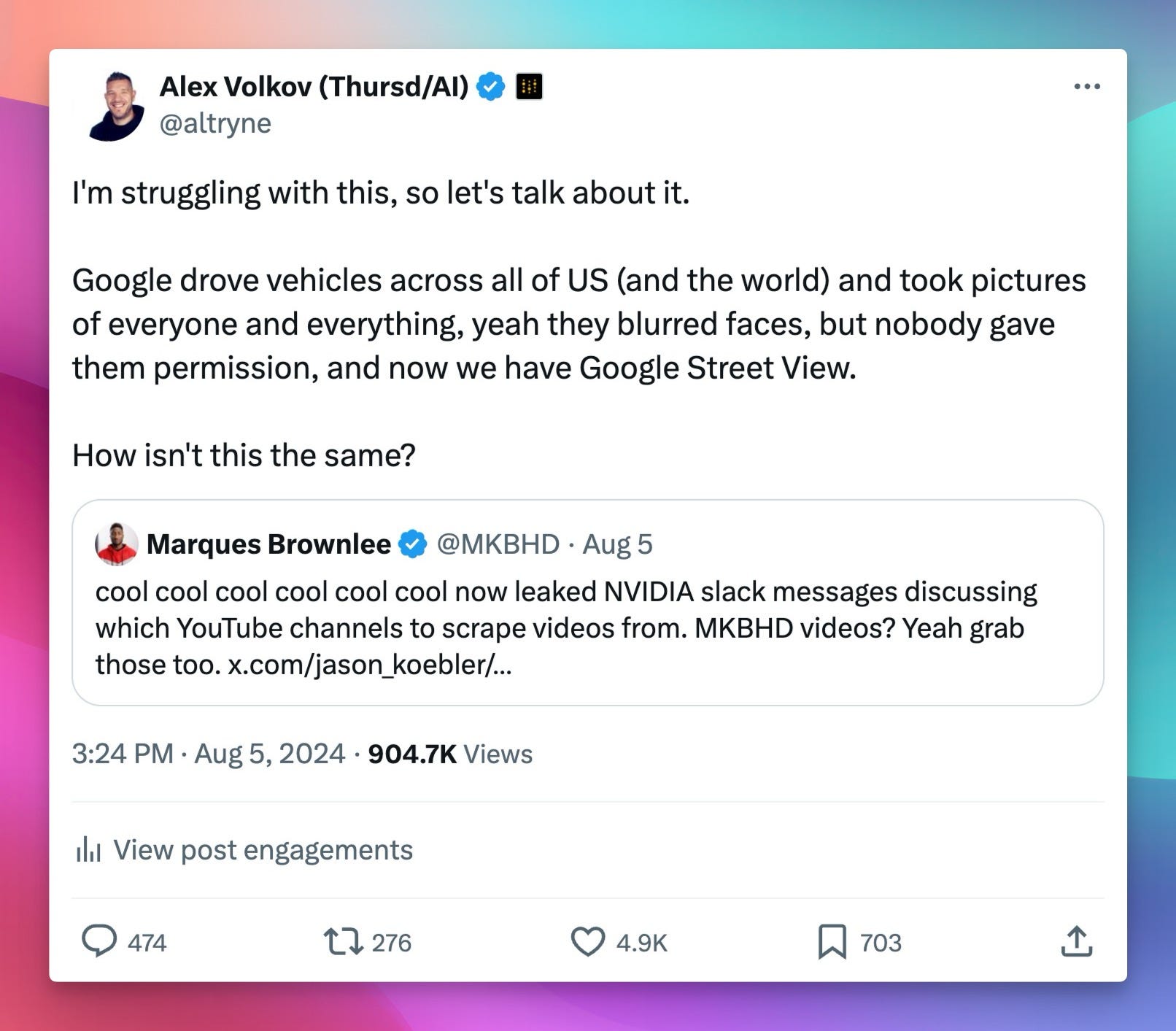
The Internet, as it often does, had thoughts . The tweet blew up (like a million views blew up). I was labeled an apologist, a shill, all kinds of charming things... 😂 It got so intense, I had to MUTE the whole thing for my sanity's sake. BUT it brings up serious issues:
AI & Copyright: Where the Heck are the Lines? When does inspiration become infringement when a model's trained on massive datasets? There's no legal precedent, folks, which is scary .
Ethics vs. Innovation: AI progress moves FAST... sometimes FASTER than our ability to grasp the implications. That's unsettling.
Twitter Pile-Ons & Nuance (aka What NOT to do): Look, I GET being passionate. BUT when criticism turns into name-calling and mob mentality, it shuts down any chance of meaningful conversation. That's not helping ANYONE.
Strawberry Shenanigans: Theories, Memes, and a Little AI LARPing?🍓
And now, for the MAIN EVENT: STRAWBERRY! You might have heard whispers... seen those cryptic tweets... maybe witnessed that wild Twitter account firsthand! It all started with Sam Altman casually posting a pic of a strawberry garden with the caption "nice summer day". Then came the deluge - more pics of strawberries from OpenAI folks, even those cryptic, semi-official domain names LDJ uncovered... I even spotted a strawberry IN OUR audience for crying out loud! This thing spread like wildfire. 🔥
We spent a solid chunk of the episode piecing together the lore: Q*, the mystery model shrouded in secrecy for years, then that Bloomberg leak claiming it was code-named "Strawberry", and now this. It was peak AI conspiracy-theory land!
We still don't have hard confirmation on Q*... but that strawberry account, spitting out fruit puns and pinging ChatGPT like a maniac? Some on ThursdAI (Yam, mostly) believe that this may not have been a human at all, but an early, uncontrolled attempt to have an AI manage its own PR. 😳 I almost bought it - especially the way it reacted to some of my live comments - but now... the LARP explanation seems more likely
Many folks at OpenAI posted things with strawberries as well, was this a sign of something to come or were they just trying to bury the news that 3 executives departed the company this week under a mountain of 🍓?
Cursor & Composer: When Coding Becomes AI-Powered Magic ✨
I love a good tool... and this week, my dev heart was a-flutter over Cursor . Tried it yet? Seriously, you need to! It's VS Code, but SUPERCHARGED with AI that'll make you question why Copilot ever existed. 😂
You can edit code by CHAT, summarize entire files with one click, zap bugs instantly ... but they just dropped their ultimate weapon: Composer. It's essentially a coding AGENT that does multi-file edits. 🤯
Matt Shumer (my SaaS wizard friend who adopted Cursor early) had some jaw-dropping examples:
" [Composer] ... takes all the parts of Cursor you like and strings them together as an agent... it takes away a lot of the grunt work... you can say 'go add this feature'... it searches your files, figures out what to edit, then puts it together. ...I literally built a SaaS in 20 minutes!" - Matt Shumer
Matt also said that using Cursor is required at their company!
Even my stoic PyTorch friend, Mark, couldn't help but express some curiosity:
"It's cool they're doing things like multi-file editing... pretty curious to see more projects along those lines" - Mark Serafim
Yeah, it's still in the rough-around-the-edges stage (UX could use some polish). But THIS, folks, is the future of coding - less about hammering out syntax, more about describing INTENT and letting the AI handle the magic! 🤯 I can't wait to see what they do next.
Download at cursor.sh and let me know what you think
Conclusion: The Future Is FAST, Open, And Maybe a Bit TOO Spicy? 🌶️😂
Honestly, every single week leaves me awestruck by how fast this AI world is moving. 🤯 We went from "transformers? Huh?" to 70-point math models running on SMARTWATCHES and AI building ENTIRE web apps in less than two years. And I still haven't got GPT-4's new voice model yet!!
Open source keeps proving its power, even THOSE BIG companies are getting in on the action (look at those Google prices! 😍), and then you've got those captivating mysteries keeping us on our toes... like those damned strawberries! 🍓 What DOES OpenAI have up their sleeve??
As always, huge THANK YOU to the amazing guests who make this show what it is - this week, extra kudos to Junyang, Nisten, LDJ, Mark, Yam, and Eric, you guys ROCK. 🔥 And HUGE gratitude to each and every ONE of you readers/listeners (and NEW folks who stuck around after those Strawberry bait tweets! 😂) You make this ThursdAI community truly unstoppable. 💪
Keep on building, stay insanely curious, and I'll see you next Thursday - ready or not, that AI future is coming in hot! 🔥🚀


