



Hey everyone, Alex here 👋
Welcome back to ThursdAI! And folks, what an absolutely insane week it's been in the world of AI. Seriously, as I mentioned on the show, we don't often get weeks this packed with game-changing releases.
We saw Google emphatically reclaim the #1 LLM spot with Gemini 2.5 Pro (and OpenAI try really hard to hit back with a new ChatGPT), DeepSeek dropped a monster 685B parameter open-source model, Qwen launched a tiny but mighty 7B Omni model that handles voice and video like a champ, and OpenAI finally gave us native image generation in GPT-4o, immediately unleashing a tidal wave of Ghibli-fication across the internet. It was intense, with big players seemingly trying to one-up each other constantly – remember when Sam Altman dropped Advanced Voice Mode right when Google was about to show Astra? This weeks was this, on steroids.
We had a fantastic show trying to unpack it all, joined by the brilliant Tulsee Doshi from the Google Gemini team, my Weights & Biases colleague Morgan McQuire talking MCP tools, and the MLX King himself, Prince Canuma. Plus, my awesome co-hosts Wolfram, Nisten, and Yam were there to add their insights. (watch the LIVE recap or keep reading and listen to the audio pod)
So, grab your beverage of choice, buckle up, and let's try to make sense of this AI whirlwind! (TL'DR and show notes at the bottom 👇)
Big CO LLMs + APIs
🔥 Google Reclaims #1 with Gemini 2.5 Pro (Thinking!)
Okay, let's start with the big news. Google came out swinging this week, dropping Gemini 2.5 Pro and, based on the benchmarks and our initial impressions, taking back the crown for the best all-around LLM currently available. (Check out the X announcement, the official blog post, and seriously, go try it yourself at ai.dev).

We were super lucky to have Tulsee Doshi, who leads the product team for Gemini modeling efforts at Google, join us on the show to give us the inside scoop. Gemini 2.5 Pro Experimental isn't just an incremental update; it's topping benchmarks in complex reasoning, science, math, and coding. As Tulsee explained, this isn't just about tweaking one thing – it's a combination of a significantly enhanced base model and improved post-training techniques, including integrating those "thinking" capabilities (like chain-of-thought) right into the core models.
That's why they dropped "thinking" from the official name – it's not a separate mode anymore, it's becoming fundamental to how Gemini operates. Tulsee mentioned their goal is for the main line models to be thinking models, leveraging inference time when needed to get the best answer. This is a huge step towards more capable and reliable AI.

The performance gains are staggering across the board. We saw massive jumps on benchmarks like AIME (up nearly 20 points!) and GPQA. But it's not just about the numbers. As Tulsee highlighted, Gemini 2.5 is proving to be incredibly well-rounded, excelling not only on academic benchmarks but also on human preference evaluations like LM Arena (where style control is key). The "vibes" are great, as Wolfram put it. My own testing on reasoning tasks confirms this – the latency is surprisingly low for such a powerful model (around 13 seconds on my hard reasoning questions compared to 45+ for others), and the accuracy is the highest I've seen yet at 66% on that specific challenging set.

It also inherits the strengths of previous Gemini models – native multimodality and that massive long context window (up to 1M tokens!). Tulsee emphasized how crucial long context is, allowing the model to reason over entire code repos, large sets of financial documents, or research papers. The performance on long context tasks, like the needle-in-a-haystack test shown on Live Bench, is truly impressive, maintaining high accuracy even at 120k+ tokens where other models often falter significantly.

Nisten mentioned on the show that while it's better than GPT-4o, it might not completely replace Sonnet 3.5 for him yet, especially for certain coding or medical tasks under 128k context. Still, the consensus is clear: Gemini 2.5 Pro is the absolute best model right now across categories. Go play with it!
ARC-AGI 2 Benchmark Revealed (X, Interactive Blog)

Also on the benchmark front, the challenging ARC-AGI 2 benchmark was revealed. This is designed to test tasks that are easy for humans but hard for LLMs. The initial results are sobering: base LLMs score 0% accuracy, and even current "thinking" models only reach about 4%. It highlights just how far we still have to go in developing truly robust AI reasoning, giving us another hill to climb.
GPT-4o got another update (as I'm writing these words!) tied for #1 on LMArena, beating 4.5

How much does Sam want to win over Google? So much he's letting it ALL out. Just now, we saw an update from LMArena and Sam, about a NEW GPT-4o (2025-03-26) which jumps OVER GPT 4.5 (like.. what?) and lands at number 2 on the LM Arena, jumping over 3o points.
Tied #1 in Coding, Hard Prompts. Top-2 across ALL categories.
Besides getting very close to Gemini but not quite beating it, I gotta ask, what's the point of 4.5 then?
Open Source LLMs
The open-source community wasn't sleeping this week either, with some major drops!
DeepSeek V3 Update - 685B Parameter Beast!
The Whale Bros at DeepSeek silently dropped an update to their V3 model (X, HF), and it's a monster. We're talking 685 Billion parameters in a Mixture-of-Experts (MoE) architecture. This isn't R1 (their reasoning model), but the powerful base model that R1 was built upon (and supposedly R2 when it'll come out)

The benchmark jumps from the previous version are huge, especially in reasoning:
MMLU-Pro: 75.9 → 81.2 (+5.3)
GPQA: 59.1 → 68.4 (+9.3)
AIME: 39.6 → 59.4 (+19.8) (Almost 20 points on competitive math!)
LiveCodeBench: 39.2 → 49.2 (+10.0)
They're highlighting major boosts in reasoning, stronger front-end dev skills, and smarter tool use. Nisten noted it even gets some hard reasoning questions right that challenge other models. The "vibes" are reportedly great. Wolfram tried to run it locally but found even the 1-bit quantized version too large for his system (though it should theoretically fit in combined RAM/VRAM), but he's using it via API. It’s likely the best non-reasoning open model right now, potentially the best overall if you can run it.
And huge news for the community – they've released these weights under the MIT License, just like R1! Massive respect to DeepSeek for continuing to push powerful models into the open.
They also highlight being significantly better at Front End development and websites aesthetics.
Qwen Launches Omni 7B Model - Voice & Video Chat!
Our friends at Qwen (Alibaba) also came through with something super cool: Qwen2.5-Omni-7B (HF). This is an end-to-end multimodal model that can perceive text, images, audio, AND video, while generating both text and natural-sounding speech, potentially in real-time.

They're using a "Thinker-Talker" architecture. What blew my mind is the size – it's listed as 7B parameters, though I saw a meme suggesting it might be closer to 11B internally (ah, the joys of open source!). Still, even at 11B, having this level of multimodal understanding and generation in a relatively small open model is fantastic. It understands voice and video natively and outputs text and voice. Now, when I hear "Omni," I start expecting image generation too (thanks, Google!), so maybe that's next for Qwen? 😉
AI Art & Diffusion & Auto-regression
This was arguably where the biggest "mainstream" buzz happened this week, thanks mainly to OpenAI.
OpenAI Launches Native Image Support in GPT-4o - Ghibli Everywhere!

This felt like a direct response to Gemini 2.5's launch, almost like OpenAI saying, "Oh yeah? Watch this!" They finally enabled the native image generation capabilities within GPT-4o (Blog, Examples). Remember that image Greg Brockman tweeted a year ago of someone writing on a blackboard with an old OpenAI logo, hinting at this? Well, it's here.

And the results? Honestly, they're stunning. The prompt adherence is incredible. It actually listens to what you ask for in detail, including text generation within images, which diffusion models notoriously struggle with. The realism can be jaw-dropping, but it can also generate various styles.
Speaking of styles... the internet immediately lost its collective mind and turned everything into the style of Studio Ghibli (great X thread here). My entire feed became Ghibli-fied. It's a testament to how accessible and fun this feature is. Wolfram even suggested we should have Ghibli avatars for the show!

Interestingly, this image generation is apparently auto-regressive, not based on diffusion models like Midjourney or Stable Diffusion. This is more similar to how models like Grok's Aurora work, generating the image sequentially (top-to-bottom, kinda like how old GIFs used to load, as Yam pointed out we confirmed). This likely contributes to the amazing prompt adherence, especially with text.
The creative potential is huge – people are generating incredible ad concepts (like this thread) and even recreating entire movie trailers, like this unbelievable Lord of the Rings one (link), purely through prompts in GPT-4o. It's wild.

Now, this launch wasn't just about cool features; it also marked a significant shift in OpenAI's policy around image generation, aiming for what CEO Sam Altman called "a new high-water mark for us in allowing creative freedom." Joanne Jang, who leads model behavior at OpenAI, shared some fascinating insights into their thinking (Reservoir Samples post).
She explained they're moving away from broad, blanket refusals (which often felt safest but limited creativity) towards a more precise approach focused on preventing real-world harm. This means trusting user creativity more, not letting hypothetical worst-case scenarios overshadow everyday usefulness (like generating memes!), and valuing the "unknown, unimaginable possibilities" that overly strict rules might stifle. It's a nuanced approach acknowledging that, as Joanne quoted, "Ships are safest in the harbor... But that’s not what ships or models are for." A philosophy change I definitely appreciate.
Reve - New SOTA Diffusion Contender?
While OpenAI grabbed headlines, another player emerged claiming State-of-the-Art results, this time in the diffusion space. Reve Image 1.0 (X, Blog/News, Try it) apparently beats Midjourney and Flux in benchmarks, particularly in prompt adherence, realism, and even text generation (though likely not as consistently as GPT-4o's native approach).
It works on a credit system ($5 for 500 generations, ~1 cent per image) which is quite affordable. The editing seems a bit different, relying on chatting with the model rather than complex tools. It was kind of hidden/anonymous before, but now they've revealed themselves. Honestly, this would probably be huge news if OpenAI hadn't dropped their image bomb the same week.
Ideogram 3 Also Launched - Another SOTA Claim!
And just to make the AI art space even more crowded this week, Ideogram also launched version 3.0 (Blog, Try it), also claiming state-of-the-art performance!
Ideogram has always been strong with text rendering and logos. Version 3.0 boasts stunning realism, creative design capabilities, and a new "Style References" feature where you can upload images to guide the aesthetic. They claim it consistently outperforms others in human evaluations. It's wild – we had at least three major image generation models/updates drop this week, all claiming top performance, and none of them seemed to benchmark directly against each other in their launch materials! It’s hard to keep track!

This Week's Buzz + MCP (X, Github!)
Bringing it back to Weights & Biases for a moment. We had Morgan McQuire on the show, who heads up our AI Applied team, to talk about something we're really excited about internally – integrating MCP with Weave, our LLM observability and evaluation tool. Morgan showed a demo and have shipped the MCP server, which you can try right now!
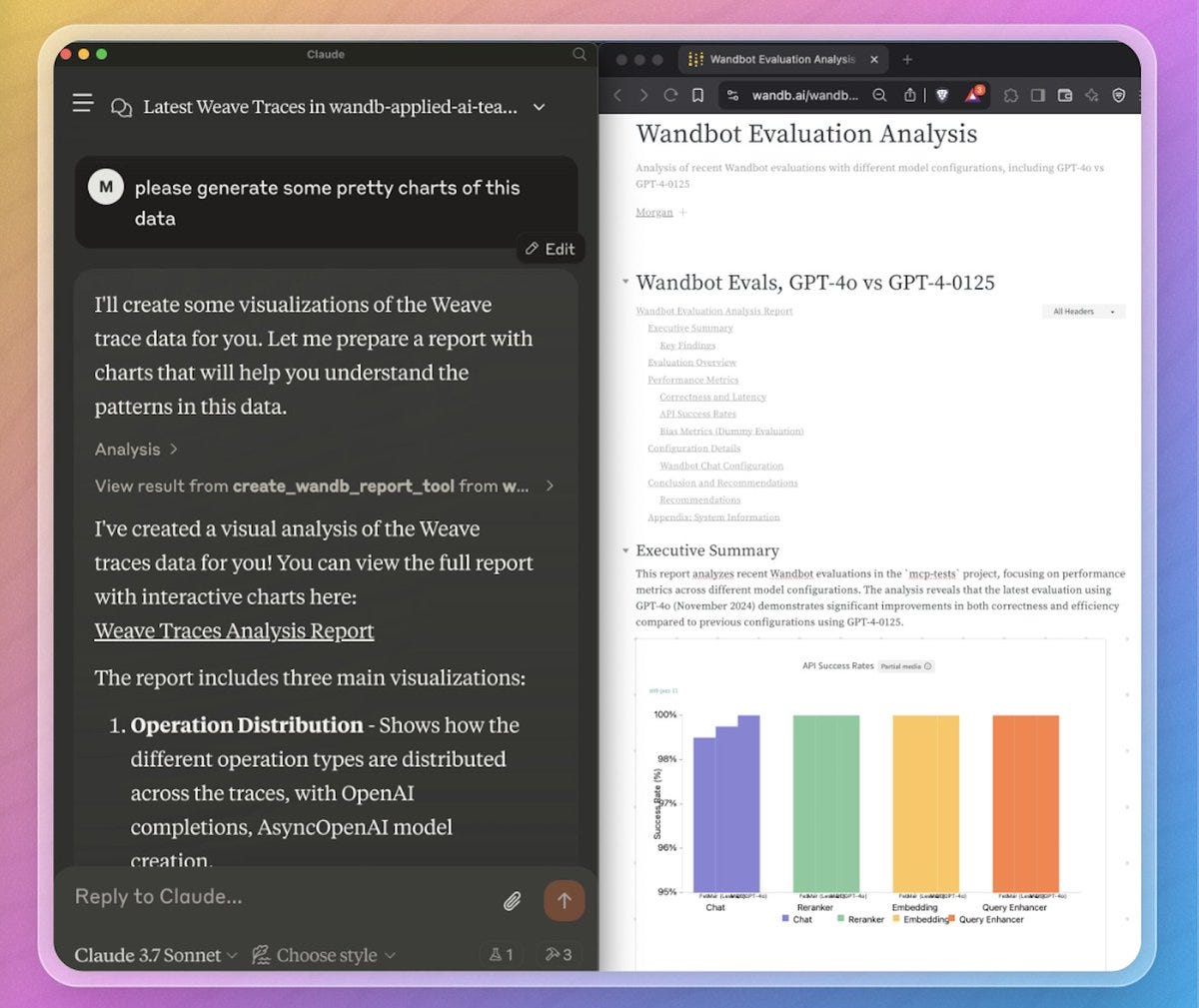
Coming soon is the integration with wandb models, which will allows ML folks around the world to build agents that monitor loss curves for them!
Weights & Biases Weave Official MCP Server Tool - Talk to Your Evals!
We've launched an official MCP server tool for Weave! What does this mean? If you're using Weave to track your experiments, evaluations, prompts, etc. (and you should be!), you can now literally chat with that data. As Morgan demonstrated, you can ask questions like "Tell me about my last three evaluations," and the MCP tool, connected to your Weave data, will not only fetch and summarize that information for you directly in the chat interface (like Claude code or others that support MCP) but will generate a report and add visualizations!
This is just the beginning of how we see MCP enhancing observability and interaction with ML workflows. Being able to query and analyze your runs and evaluations using natural language is incredibly powerful.
Agents, Tools & MCP
And speaking of MCP...
OpenAI Adds Support for MCP - MCP WON!
This was HUGE news, maybe slightly overshadowed by the image generation, but potentially far more impactful long-term, as Wolfram pointed out right at the start of the show. OpenAI officially announced support for the Model Context Protocol (MCP) (docs here).

Why is this massive? Because Anthropic initiated MCP, and there was a real fear that OpenAI, being OpenAI, might just create its own competing standard for agent/tool communication, leading to fragmentation (think VHS vs. Betamax, or Blu-ray vs. HD DVD – standards wars suck!). Instead, OpenAI embraced the existing standard. As I said on the show, MCP WON!
This is crucial for the ecosystem. It means developers can build tools and agents using the MCP standard, and they should (hopefully) work seamlessly across different models like Claude and GPT. OpenAI not only added support but released it in their Agents SDK and explicitly stated support is "coming soon" for the ChatGPT desktop app and response APIs. Yam expertly clarified the distinction: tools are often single API calls, while MCPs are servers that can maintain state, allowing for more complex, guided interactions. Qwen also adding MCP support to their UI just reinforces this – the standard is gaining traction fast. This standardization is absolutely essential for building a robust agentic future.
Voice & Audio
Just one more quick update on the audio front:
OpenAI Updates Advanced Voice Mode with Semantic VAD
Alongside the image generation, OpenAI also quietly updated the advanced voice mode in ChatGPT (YT announcement). The key improvement is "Semantic VAD" (Voice Activity Detection). Instead of just cutting off when you pause (leading to annoying interruptions, especially for kids or people who think while speaking), it now tries to understand the meaning and tone to determine if you're actually finished talking.
This should lead to a much more natural conversation flow. They also claim better personality, a more engaging natural tone (direct and concise), and less need for you to fill silence with "umms" just to keep the mic open. It might feel a tad slower because it waits a bit longer, but the improvement in interaction quality should be significant.
MLX-Audio
And speaking (heh) of audio and speech, we had the awesome Prince Canuma on the show! If you're into running models locally on Apple Silicon (Macs!), you probably know Prince. He's the MLX King, the creator and maintainer of essential libraries like MLX-VLM (for vision models), FastMLX, MLX Embeddings, and now, MLX-Audio. Seriously, huge props to Prince and the folks in the MLX community for making these powerful open-source models accessible on Mac hardware. It's an incredible contribution.
This week, Prince released MLX-Audio v0.0.3. This isn't just text-to-speech (TTS); it aims to be a comprehensive audio package for MLX. Right now, it supports some of the best open TTS models out there:
Kokoro: The tiny, high-quality TTS model we've covered before.
Sesame 1B: Another strong contender.
Orpheus: From Canopy Labs (as Prince confirmed).
Suno Bark: Known for generating music and sound effects too.
MLX-Audio makes running state-of-the-art speech synthesis locally on your Mac incredibly easy, basically offering a Hugging Face transformers pipeline equivalent but optimized for Apple Silicon. If you have a Mac, pip install mlx-audio and give it a spin! Prince also took a feature request on the show to allow text file input directly, so look out for that!
Phew! See what I mean? An absolutely jam-packed week.
Huge thanks again to Tulsee, Morgan, and Prince for joining us and sharing their insights, and to Wolfram, Nisten, and Yam for co-piloting through the news storm. And thank YOU all for tuning in! We'll be back next week, undoubtedly trying to catch our breath and make sense of whatever AI marvels (or madness) gets unleashed next.
P.S - if the ghiblification trend didn’t get to your families as well, the alpha right now is… showing your kids how to be a magician and turn them into Ghibli characters, here are me and my kiddos (who asked to be pirates and princesses)

TL;DR and Show Notes:
Guests and Cohosts
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - Wolfram Ravenwlf (@WolframRvnwlf), Nisten Tahiraj (@nisten), Yam Peleg (@yampeleg)Tulsee Doshi - Head of Product, Gemini Models at Google DeepMind (@tulseedoshi)
Morgan McQuire - Head of AI Applied Team at Weights & Biases (@morgymcg)
Prince Canuma - ML Research Engineer, Creator of MLX Libraries (@PrinceCanuma)
Big CO LLMs + APIs
Open Source LLMs
AI Art & Diffusion & Auto-regression
OpenAI launches native image support in GPT-4o (Model Card, X thread, Ad threads, Full Lord of the Rings trailer, Model Card)
Reve - new SOTA diffusion image gen claims (X, Blog/News, Try)
Ideogram 3 launched - another SOTA claim, strong on text/logos, realism, style refs (Blog, Try it)
This weeks Buzz + MCP
Agents , Tools & MCP
OpenAI has added support for MCP - MCP WON! (Docs)
Voice & Audio
OpenAI updates advanced voice mode with semantic VAD for more natural conversations (YT announcement).
MLX-Audio v0.0.3 released by Prince Canuma (Github)
Show Notes and other Links
Catch the show live & subscribe to the newsletter/YouTube: thursdai.news/yt
Try Gemini 2.5 Pro: AI.dev
Learn more about MCP from our previous episode (March 6th).


