




Hey hey folks, happy ThursdAI 🎉
Not a lot of house-keeping here, just a reminder that if you're listening or reading from Europe, our European fullyconnected.com conference is happening in May 15 in London, and you're more than welcome to join us there. I will have quite a few event updates in the upcoming show as well.
Besides this, this week has been a very exciting one for smaller models, as Microsoft teased and than released Phi-3 with MIT license, a tiny model that can run on most macs with just 3.8B parameters, and is really punching above it's weights. To a surprising and even eyebrow raising degree! Let's get into it 👇
TL;DR of all topics covered:
Open Source LLMs
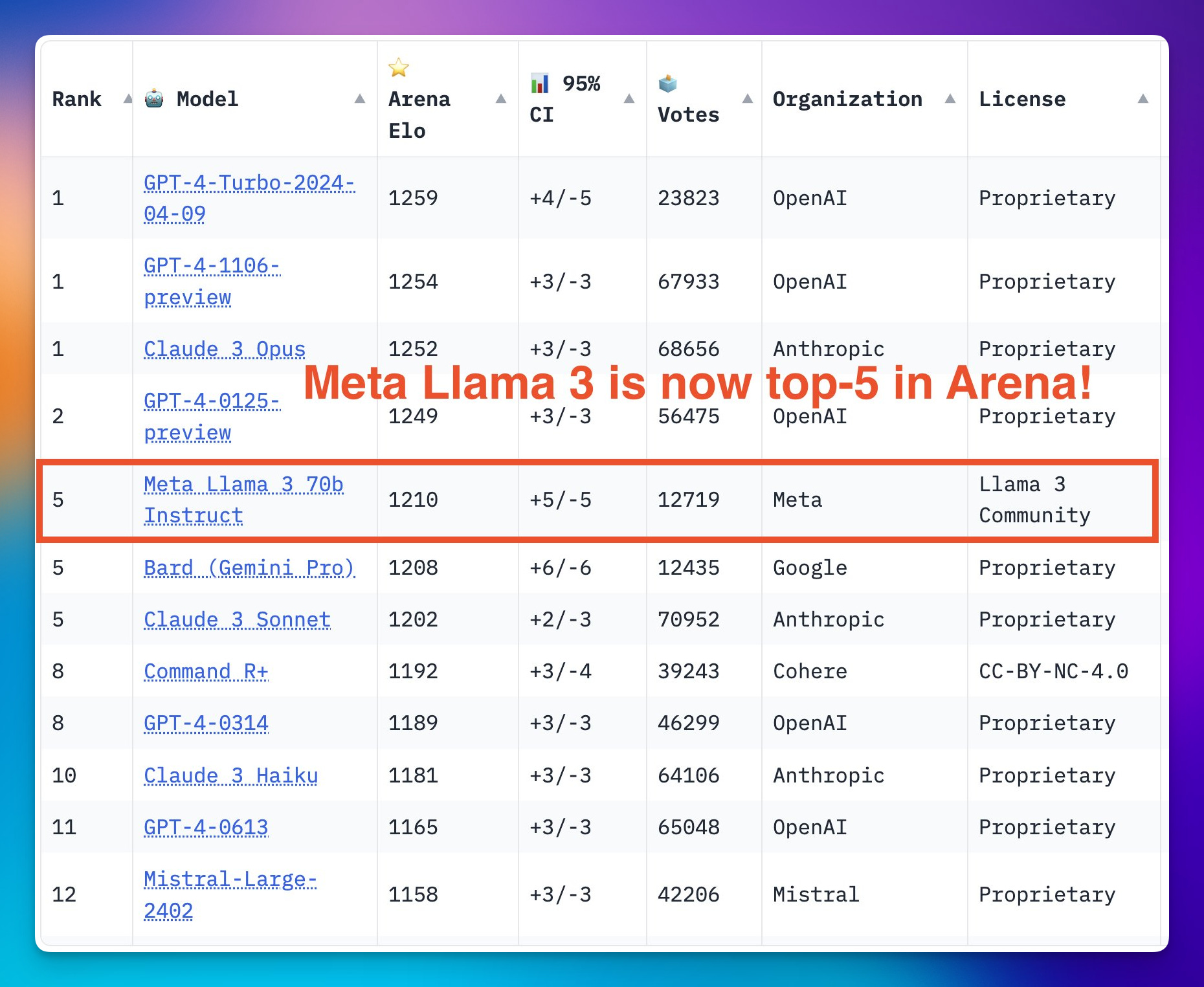
LLama3 70B top5 (no top 6) on LMsys (LMsys Arena)
Snowflake open sources Arctic - A massive hybrid MoE (X, Try it, HF)
Evolutionary Model merges support in MergeKit (Blog)
Llama-3 8B finetunes roundup - Longer Context (128K) and Dolphin & Bagel Finetunes
HuggingFace FINEWEB - a massive 45TB (the GPT4 of datasets) and 15T tokens high quality web data dataset (HF)
Cohere open sourced their chat interface (X)
Apple open sources OpenElm 4 models + training library called corenet (HF, Github, Paper)
Big CO LLMs + APIs
Google Gemini 1.5 pro is #2 on LMsys arena
Devin is now worth 2BN and Perplexity is also a Unicorn
A new comer called Augment (backed by Eric Schmidt) is now coming out of stealth (X)
Vision & Video
This Weeks Buzz - What I learned in WandB this week
Voice & Audio
AI Art & Diffusion & 3D
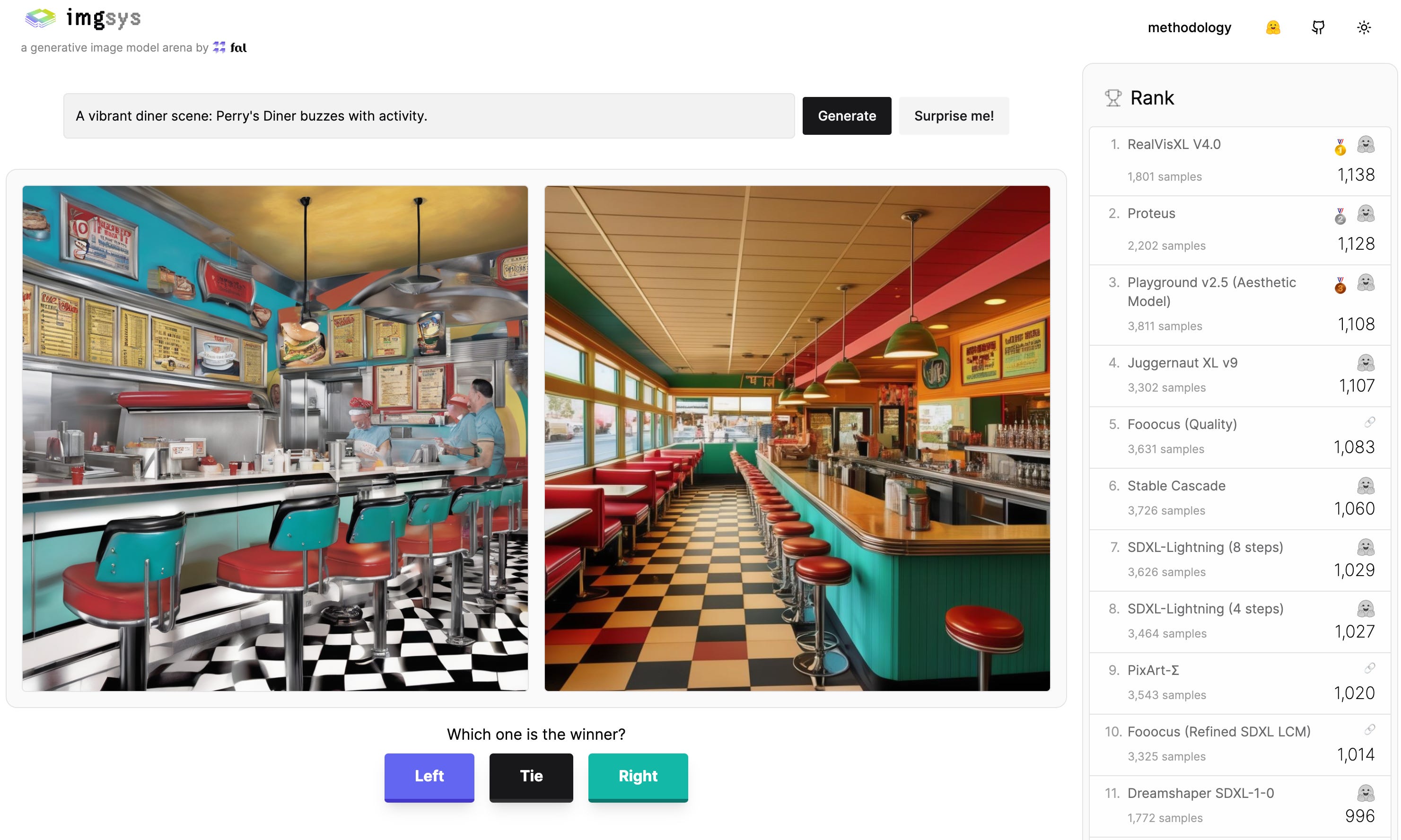
IMGsys.org- like LMsys but for image generation model + leaderboard from FAL (try it)
Tools & Hardware
Rabbit R1 release party & no shipping update in sight
I'm disillusioned about my AI Pin and will return it
Open Source LLMs
Llama-3 1 week-aversary 🎂 - Leaderboard ranking + finetunes
Well, it's exactly 1 week since we got Llama-3 from Meta and as expected, the rankings show a very very good story. (also it was downloaded over 1.2M times and already has 600 derivatives on HuggingFace)
Just on Monday, Llama-3 70B (the bigger version) took the incredible 5th place (now down to 6th) on LMSys, and more surprising, given that the Arena now has category filters (you can filter by English only, Longer chats, Coding etc) if you switch to English Only, this model shows up 2nd and was number 1 for a brief period of time.
So just to sum up, an open weights model that you can run on most current consumer hardware is taking over GPT-4-04-94, Claude Opus etc'
This seems dubious, because well, while it's amazing, it's clearly not at the level of Opus/Latest GPT-4 if you've used it, in fact it fails some basic logic questions in my tests, but it's a good reminder that it's really hard to know which model outperforms which and that the arena ALSO has a bias, of which people are using it for example and that evals are not a perfect way to explain which models are better.
However, LMsys is a big component of the overall vibes based eval in our community and Llama-3 is definitely a significant drop and it's really really good (even the smaller one)
One not so surprising thing about it, is that the Instruct version is also really really good, so much so, that the first finetunes of Eric Hartfords Dolphin (Dolphin-2.8-LLama3-70B) is improving just a little bit over Meta's own instruct version, which is done very well.

Per Joe Spisak (Program Manager @ Meta AI) chat at the Weights & Biases conference last week (which you can watch below) he said "I would say the magic is in post-training. That's where we are spending most of our time these days. Uh, that's where we're generating a lot of human annotations." and they with their annotation partners, generated up to 10 million annotation pairs, both PPO and DPO and then did instruct finetuning.
So much so that Jeremy Howard suggests to finetune their instruct version rather than the base model they released.

We also covered that despite the first reactions to the 8K context window, the community quickly noticed that extending context window for LLama-3 is possible, via existing techniques like Rope scaling, YaRN and a new PoSE method. Wing Lian (Maintainer of Axolotl finetuneing library) is stretching the model to almost 128K context window and doing NIH tests and it seems very promising!

Microsoft releases Phi-3 (Announcement, Paper, Model)
Microsoft didn't really let Meta take the open models spotlight, and comes with an incredible report and follow up with a model release that's MIT licened, tiny (3.8B parameters) and performs very very well even against Llama-3 70B.
Phi is a set of models from Microsoft that train on synthetic high-quality dataset modeled after textbooks-is-all-you-need/TinyStories approach.
The chart is quite incredible, the smallest (mini) Phi-3 is beating Llama-3-8B AND Mixtral on MMLU scores, BigBench and Humaneval. Again to simplify, this TINY 3.8B model, half the size of 1 Mixtral expert, beats Mixtral and newly released Llama-3-8B on most benchmark, not to mention GPT-3.5!
It's honestly quite a crazy chart to look at, which raises the question, did this model train on these benchmarks? 🤔

I still haven't seen definitive proof that the folks at Microsoft trained on any benchmarks data, I did see engagement from them and a complete denial, however we did see a few attempts at using Phi-3 and the quantized versions and the wrong end token formatting seem to be very prevalent in shaping the early opinion that this model performance is detached from it's very high scoring.
Not to mention that model being new, there's confusion about how to use it, see thread from Anton Bacaj about HuggingFace potentially using the wrong end token to finish conversations.
Now to an actual performance of this tiny model, I asked it a simple logic based question that trips many models even ones good with logic (Opus and GPT-4 answer it correctly usually) and it performed very well (here a comparison with LLama-3-70B which didn't do as well)

Additionally, their tokenizer is very interesting, they have all these terms that receive a full token, things like function_list, calc, ghreview, ghissue, and others, which highlight some interesting potential use-cases they have planned for this set of models or give us a hint at it's training process and how come it's so very good.

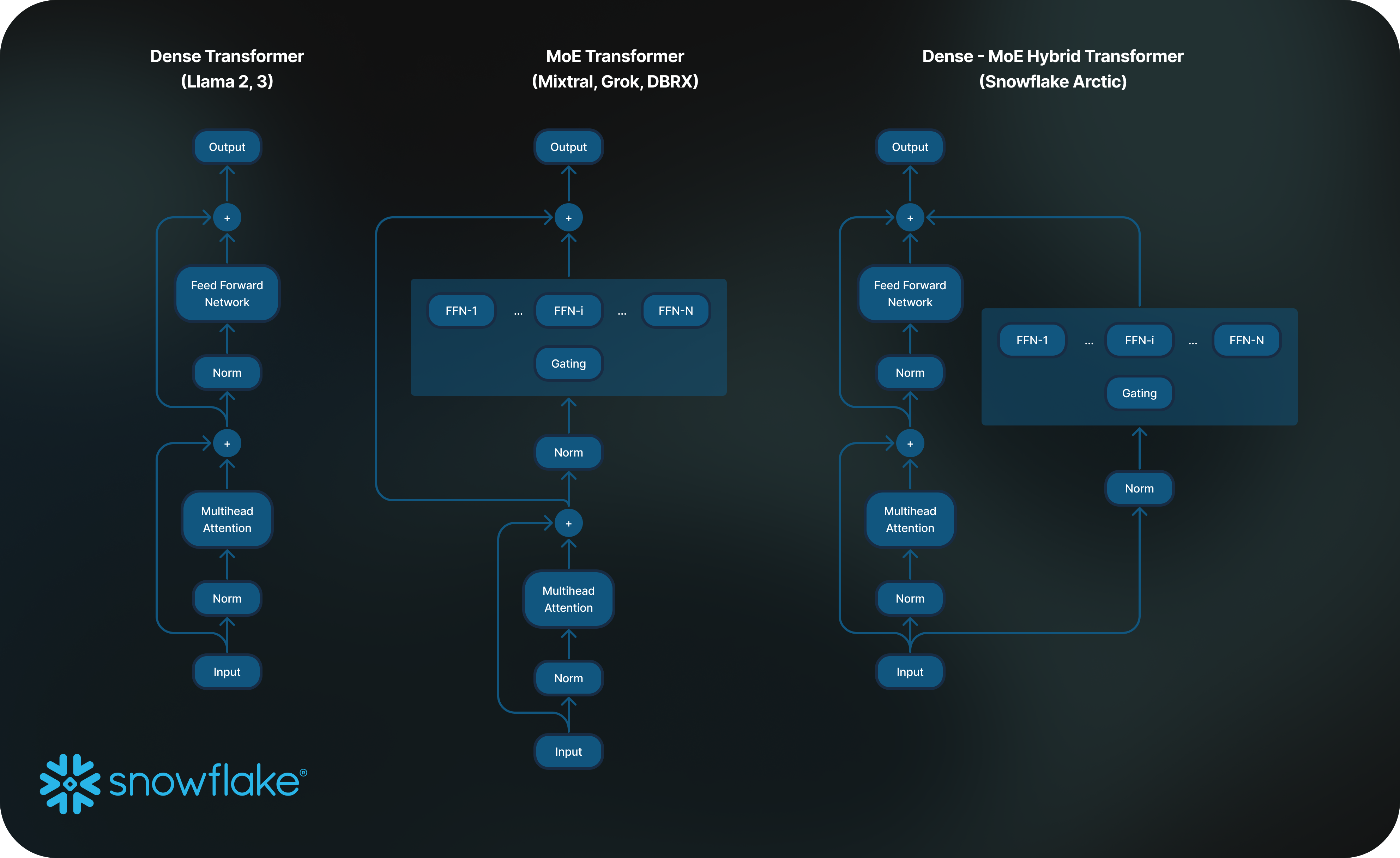
Snowflake open sources Arctic - a massive 480B MoE Hybrid with Apache 2 license (X, Try it, HF)
Snowflake is a name I haven't yet used on ThursdAI and this field is getting crowded, but they just released something interesting (+ a LOT of open source, including training code, checkpoints, research insights etc')

The thing I found most interesting is, the massive 128 experts MoE but also the Hybrid architecture. Not quite an MoE and definitely not a dense model.
They claim to have found that training Many-but-condensed experts with more expert choices is working well for them based on DeepSpeed research.
You can give this model a try here and I have, using the same 2 questions I had for Phi and LLama and found the model not that great at logic to be honest, but it was really fast considering the total size, so inference optimization for this type of architecture is definitely geared towards Enterprise (as well as training cost, they claim it cost just under $2 million dollars to train)

Big CO LLMs + APIs
Not a lot of super interesting things in this corner, besides Gemini 1.5 pro (the one with 1M context window) finally appearing in the Arena and taking the amazing #2 spot (pushing Llama-3 8B to number 6 on the same day it just appeared in there lol)

This is very impressive, and I gotta wonder what happened with Gemini Ultra if pro with larger context beats it outright. It's indeed very good, but not THAT good if you use it om simple logic problems and don't use the whole context length.
I suspect that we'll hear much more about their AI stuff during the upcoming Google IO (which I was invited to and am going to cover)
Additionally, we've had quite a few AI Unicorns born, with Perplexity becoming a freshly mint Unicorn with an additional round of funding and Devin, the 6-month old agent startup getting to a 2 billion valuation 😮
This weeks Buzz (What I learned with WandB this week)
It's been exactly 1 week since our conference in SF and since Joe Spisak by complete chance announced Meta LLama - 3 live on stage a few hours after it was officially announced.
In this weeks buzz, I'm very happy to bring you that recording, as promised last week.
I will also share that our newly announced new LLM observability tool Weave launched officially during the conference and it'll be my job to get you to use it 🙂 And shoutout to those in the ThursdAI community who already used and provided feedback, it's really helpful!

AI Art & Diffusion
The fine folks at FAL.ai have launched the LMsys.org for images, and called it.... IMGsys.org 🙂 It's a adversarial arena with different image generators, all hosted on Fal I assume, that lets the user choose which images are "better" which is a vague term.
But it's really fun, give it a try!
Tools & Hardware
Rabbit R1 first impressions
We finally got a tease of R1 from Rabbit, as the first customers started receiving this device (where's mine?? I didn't even get a tracking number)
Based on the presentation (which I watched so you don't have to) the response time, which was one of the most talked about negative pieces of AI Pin seems very decent. We're going to see a lot of reviews, but I'm very excited about my Rabbit 👏 🐇
Apparently I wasn't as fast as I thought on the pre-order so will have to wait patiently, but meanwhile, check out this review from Riley Brown.
That's the deep dive for this week, for the rest of the coverage, please listen to the episode and if you liked it, share with a friend!
I'll also be traveling quite a bit in the next two months, I'll be in Seattle for MSFT BUILD, and in San Francisco (more on this soon) a couple of times, hope to meet some of you, please come say hi! 🫡




Share this post