





Hey all, Alex here 👋
What can I say, the weeks are getting busier , and this is one of those "crazy full" weeks in AI. As we were about to start recording, OpenAI teased GPT 4.5 live stream, and we already had a very busy show lined up (Claude 3.7 vibes are immaculate, Grok got an unhinged voice mode) and I had an interview with Kevin Hou from Windsurf scheduled! Let's dive in!
🔥 GPT 4.5 (ORION) is here - worlds largest LLM (10x GPT4o)
OpenAI has finally shipped their next .5 model, which is 10x scale from the previous model. We didn't cover this on the podcast but did watch the OpenAI live stream together after the podcast concluded.
A very interesting .5 release from OpenAI, where even Sam Altman says "this model won't crush on benchmarks" and is not the most frontier model, but is OpenAI's LARGEST model by far (folks are speculating 10+ Trillions of parameters)

After 2 years of smaller models and distillations, we finally got a new BIG model, that shows scaling laws proper, and while on some benchmarks it won't compete against reasoning models, this model will absolutely fuel a huge increase in capabilities even for reasoners, once o-series models will be trained on top of this.

Here's a summary of the announcement and quick vibes recap (from folks who had access to it before)
OpenAI's largest, most knowledgeable model.
Increased world knowledge: 62.5% on SimpleQA, 71.4% GPQA
Better in creative writing, programming, problem-solving (no native step-by-step reasoning).
Text and image input and text output
Available in ChatGPT Pro and API access (API supports Function Calling, Structured Output)
Knowledge Cutoff is October 2023.
Context Window is 128,000 tokens.
Max Output is 16,384 tokens.
Pricing (per 1M tokens): Input: $75, Output: $150, Cached Input: $37.50.
Foundation for future reasoning models
4.5 Vibes Recap

Tons of folks who had access are pointing to the same thing, while this model is not beating others on evals, it's much better at multiple other things, namely creative writing, recommending songs, improved vision capability and improved medical diagnosis.
Karpathy said "Everything is a little bit better and it's awesome, but also not exactly in ways that are trivial to point to" and posted a thread of pairwise comparisons of tone on his X thread
Though the reaction is bifurcated as many are upset with the high price of this model (10x more costly on outputs) and the fact that it's just marginally better at coding tasks. Compared to the newerSonnet (Sonnet 3.7) and DeepSeek, folks are looking at OpenAI and asking, why isn't this way better?
Anthropic's Claude 3.7 Sonnet: A Coding Powerhouse
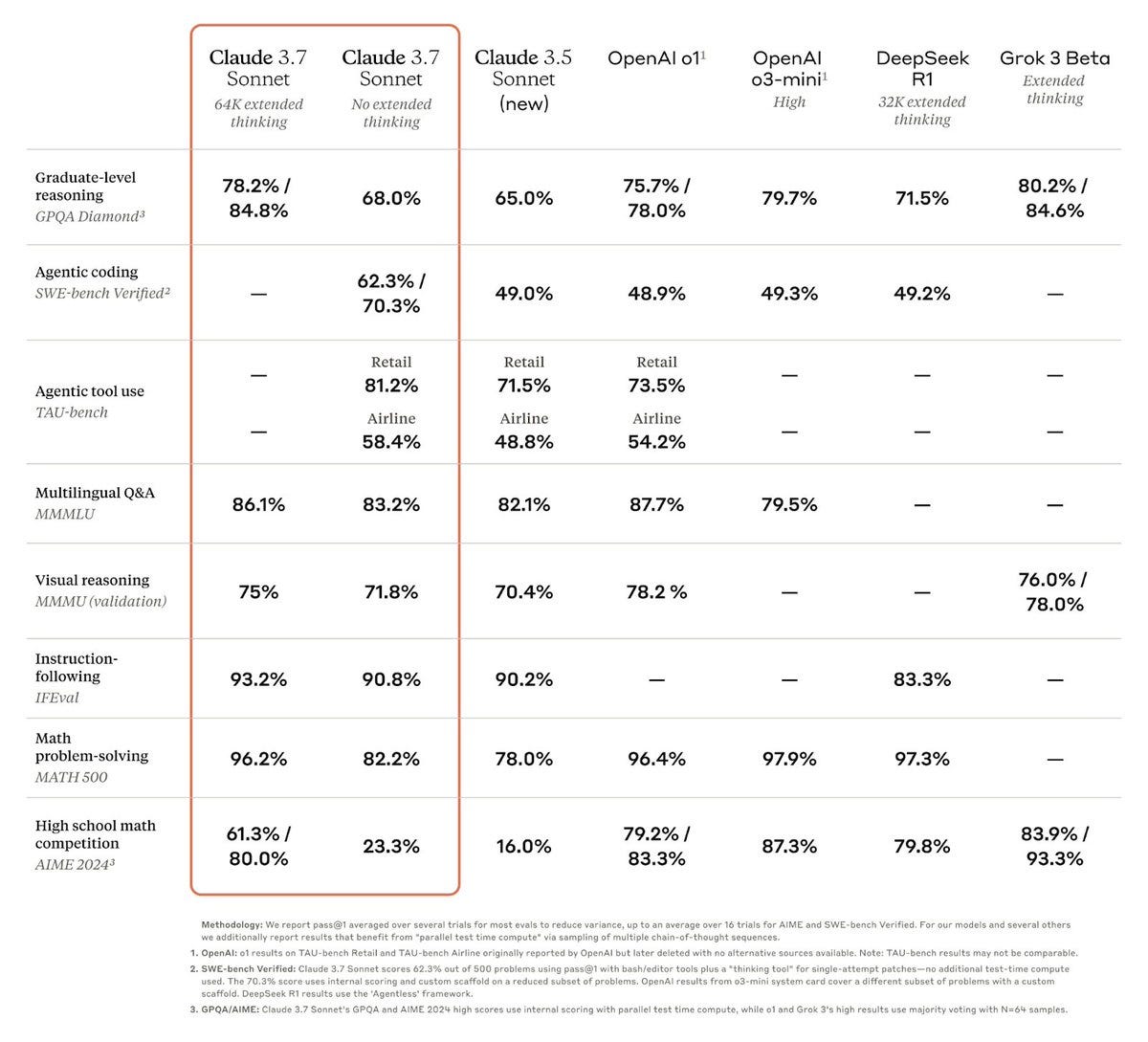
Anthropic released Claude 3.7 Sonnet, and the immediate reaction from the community was overwhelmingly positive. With 8x more output capability (64K) and reasoning built in, this model is an absolute coding powerhouse.

Claude 3.7 Sonnet is the new king of coding models, achieving a remarkable 70% on the challenging SWE-Bench benchmark, and the initial user feedback is stellar, though vibes started to shift a bit towards Thursday.
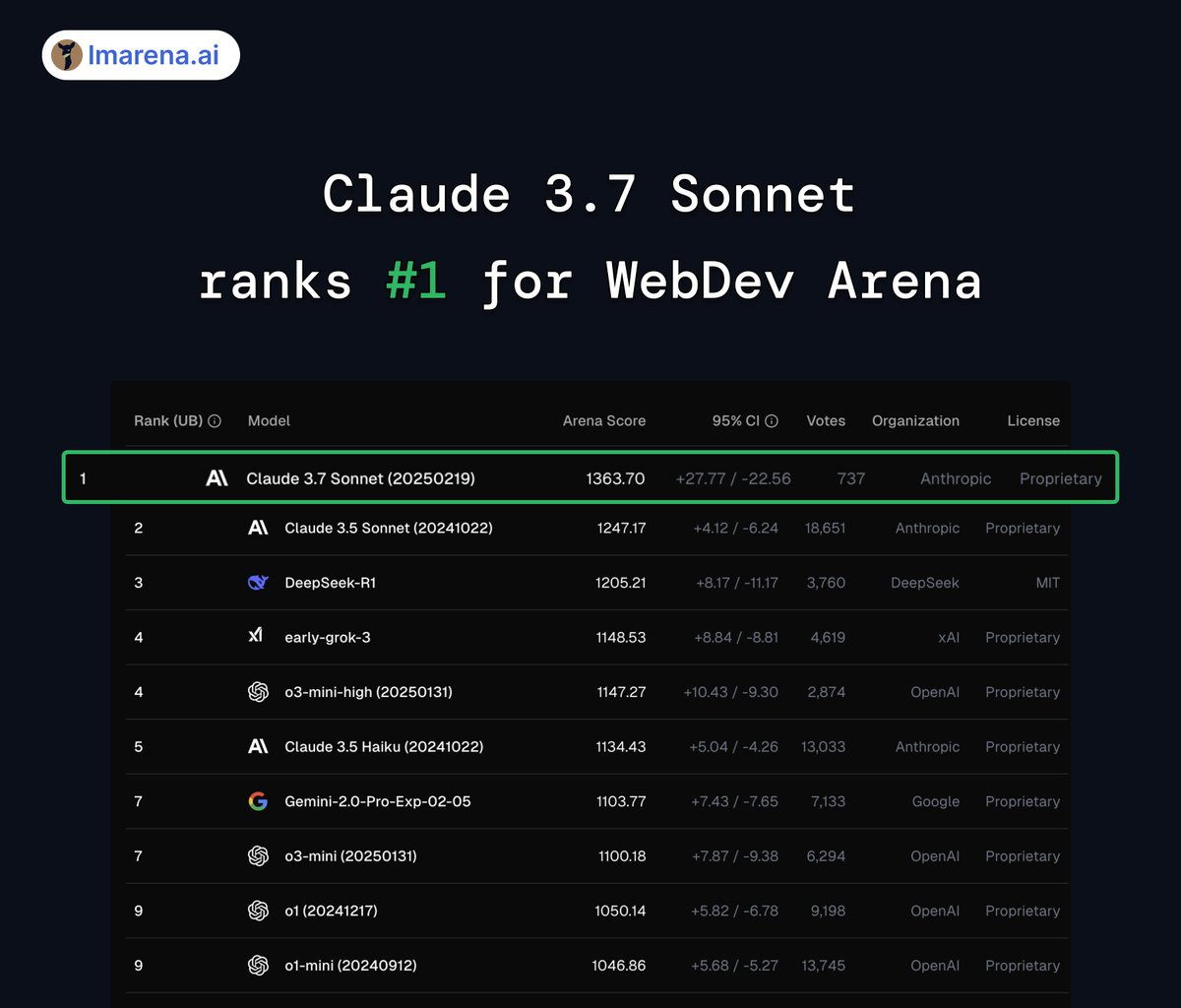
Ranking #1 on WebDev arena, and seemingly trained on UX and websites, Claude Sonnet 3.7 (AKA NewerSonner) has been blowing our collective minds since it was released on Monday, especially due to introducing Thinking and reasoning in a combined model.
Now, since the start of the week, the community actually had time to play with it, and some of them return to sonnet 3.5 and saying that while the model is generally much more capable, it tends to generate tons of things that are unnecessary.
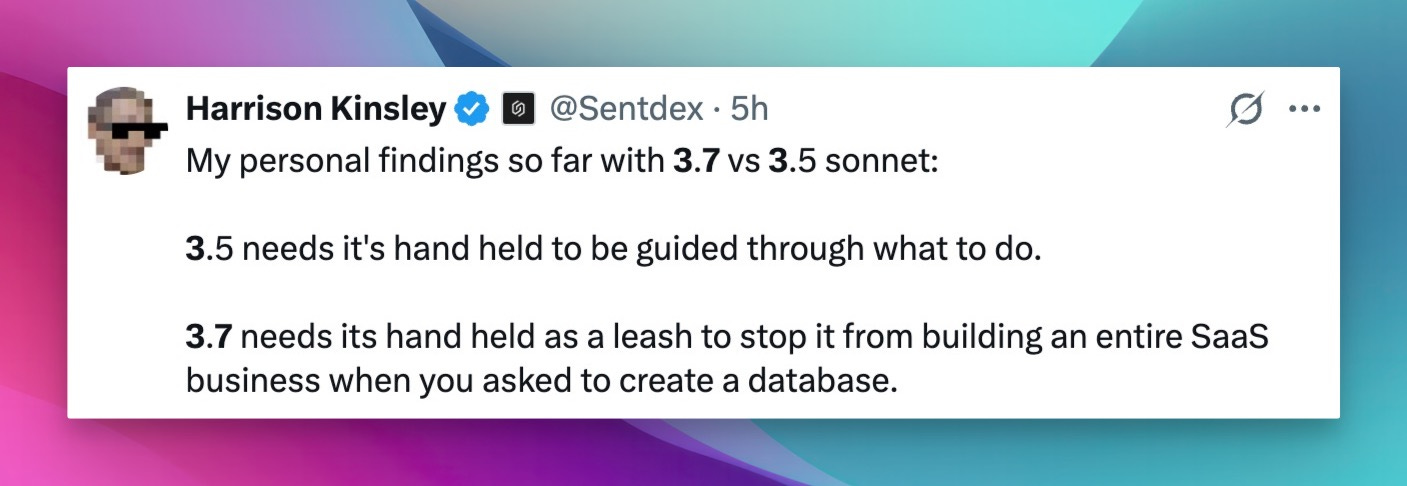
I wonder if the shift is due to Cursor/Windsurf specific prompts, or the model's larger output context, and we'll keep you updated on if the vibes shift again.
Open Source LLMs
This week was HUGE for open source, folks. We saw releases pushing the boundaries of speed, multimodality, and even the very way LLMs generate text!
DeepSeek's Open Source Spree
DeepSeek went on an absolute tear, open-sourcing a treasure trove of advanced tools and techniques:
This isn't your average open-source dump, folks. We're talking FlashMLA (efficient decoding on Hopper GPUs), DeepEP (an optimized communication library for MoE models), DeepGEMM (an FP8 GEMM library that's apparently ridiculously fast), and even parallelism strategies like DualPipe and EPLB.
They are releasing some advanced stuff for training and optimization of LLMs, you can follow all their releases on their X account

Dual Pipe seems to be the one that got most attention from the community, which is an incredible feat in pipe parallelism, that even got the cofounder of HuggingFace super excited
Microsoft's Phi-4: Multimodal and Mini (Blog, HuggingFace)

Microsoft joined the party with Phi-4-multimodal (5.6B parameters) and Phi-4-mini (3.8B parameters), showing that small models can pack a serious punch.
These models are a big deal. Phi-4-multimodal can process text, images, and audio, and it actually beats WhisperV3 on transcription! As Nisten said, "This is a new model and, I'm still reserving judgment until, until I tried it, but it looks ideal for, for a portable size that you can run on the phone and it's multimodal." It even supports a wide range of languages. Phi-4-mini, on the other hand, is all about speed and efficiency, perfect for finetuning.

Diffusion LLMs: Mercury Coder and LLaDA (X , Try it)
This is where things get really interesting. We saw not one, but two diffusion-based LLMs this week: Mercury Coder from Inception Labs and LLaDA 8B. (Although, ok, to be fair, LLaDa released 2 weeks ago I was just busy)
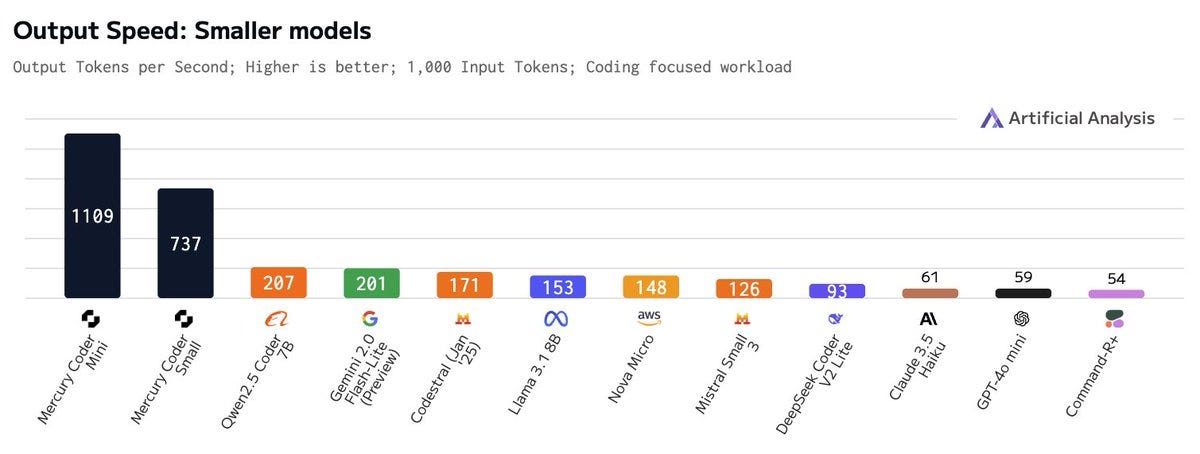
For those who don't know, diffusion is usually used for creating things like images. The idea of using it to generate text is like saying, "Okay, there's a revolutionary tool for painting; I'll write the code using it." Inception Labs' Mercury Coder is claiming over 1000 tokens per second on NVIDIA H100s – that's insane speed, usually only seen with specialized chips! Nisten spent hours digging into these, noting, "This is a complete breakthrough and, it just hasn't quite hit yet that this just happened because people thought for a while it should be possible because then you can do, you can do multiple token prediction at once". He explained that these models combine a regular LLM with a diffusion component, allowing them to generate multiple tokens simultaneously and excel at tasks like "fill in the middle" coding.

LLaDA 8B, on the other hand, is an open-source attempt, and while it needs more training, it shows the potential of this approach. LDJ pointed out that LLaDA is "trained on like around five times or seven times less data while already like competing with LLAMA3 AP with same parameter count".
Are diffusion LLMs the future? It's too early to say, but the speed gains are very intriguing.
Magma 8B: Robotics LLM from Microsoft
Microsoft dropped Magma 8B, a Microsoft Research project, an open-source model that combines vision and language understanding with the ability to control robotic actions.
Nisten was particularly hyped about this one, calling it "the robotics. LLM." He sees it as a potential game-changer for robotics companies, allowing them to build robots that can understand visual input, respond to language commands, and act in the real world.
OpenAI's Deep Research for Everyone (Well, Plus Subscribers)
OpenAI finally brought Deep Research, its incredible web-browsing and research tool, to Plus subscribers.
I've been saying this for a while: Deep Research is another ChatGPT moment. It's that good. It goes out, visits websites, understands your query in context, and synthesizes information like nothing else. As Nisten put it, "Nothing comes close to OpenAI's Deep Research...People like pull actual economics data, pull actual stuff." If you haven't tried it, you absolutely should.
Our full coverage of Deep Research is here if you haven't yet listened, it's incredible.
Alexa Gets an AI Brain Upgrade with Alexa+
Amazon finally announced Alexa+, the long-awaited LLM-powered upgrade to its ubiquitous voice assistant.
Alexa+ will be powered by Claude (and sometimes Nova), offering a much more conversational and intelligent experience, with integrations across Amazon services.
This is a huge deal. For years, Alexa has felt… well, dumb, compared to the advancements in LLMs. Now, it's getting a serious intelligence boost, thanks to Anthropic's Claude. It'll be able to handle complex conversations, control smart home devices, and even perform tasks across various Amazon services. Imagine asking Alexa, "Did I let the dog out today?" and it actually checking your Ring camera footage to give you an answer! (Although, as I joked, let's hope it doesn't start setting houses on fire.)

Also very intriguing is the new SDKs they are releasing to connect Alexa+ to all kinds of experience, I think this is huge and will absolutely create a new industry of applications built for voice Alexa.
Alexa Web Actions for example will allow Alexa to navigate to a website and complete actions (think order Uber Eats)
The price? 20$/mo but free if you're a Amazon Prime subscriber, which is most of the US households at this point.
They are focusing on personalization and memory, though still unclear how that's going to be handled, and the ability to share documents like schedules
I'm very much looking forward to smart Alexa, and to be able to say "Alexa, set a timer for the amount of time it takes to hard boil an egg, and flash my house lights when the timer is done"
Grok Gets a Voice... and It's UNHINGED
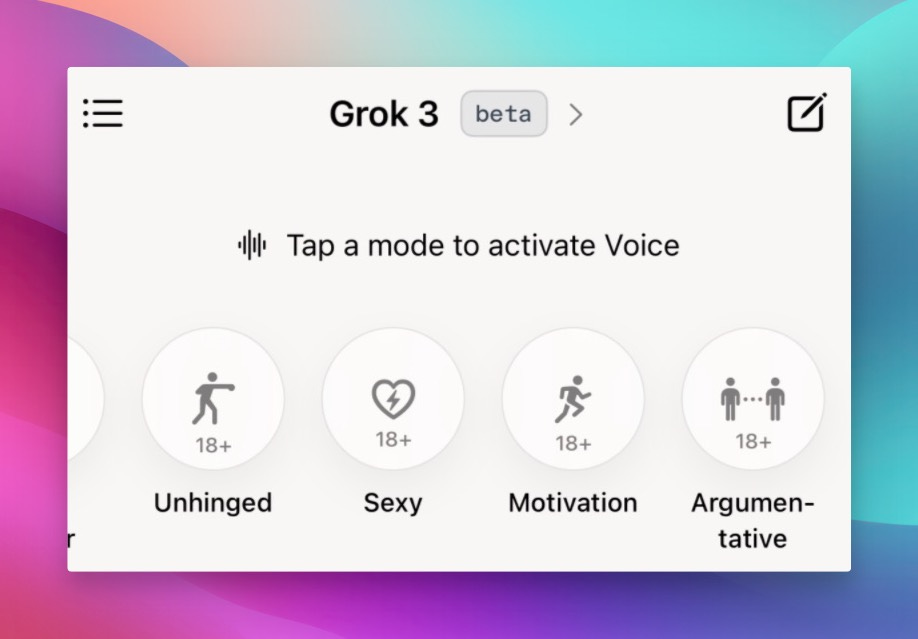
Grok, Elon Musk's AI, finally got a voice mode, and… well, it's something else.
One-sentence summary: Grok's new voice mode includes an "unhinged" 18+ option that curses like a sailor, along with other personality settings.
Yes, you read that right. There's literally an "unhinged" setting in the UI. We played it live on the show, and... well, let's just say it's not for the faint of heart (or for kids). Here's a taste:
Alex: "Hey there."
Grok: "Yo, Alex. What's good, you horny bastard? How's your day been so far? Fucked up or just mildly shitty?"
Beyond the shock value, the voice mode is actually quite impressive in its expressiveness and ability to understand interruptions. It has several personalities, from a helpful "Grok Doc" to an "argumentative" mode that will disagree with everything you say. It's... unique.
This Week's Buzz (WandB-Related News)
Agents Course is Coming!
We announced our upcoming agents course! You can pre-sign up HERE . This is going to be a deep dive into building and deploying AI agents, so don't miss it!
AI Engineer Summit Recap

We briefly touched on the AI Engineer Summit in New York, where we met with Kevin Hou and many other brilliant minds in the AI space. The theme was "Agents at Work," and it was a fantastic opportunity to see the latest developments in agent technology. I gave a talk about reasoning agents and had a workshop about evaluations on Saturday, and saw many listeners of ThursdAI 👏 ✋

Interview with Kevin Hou from Windsurf
This week we had the pleasure of chatting with Kevin Hou from Windsurf about their revolutionary AI editor. Windsurf isn't just another IDE, it's an agentic IDE. As Kevin explained, "we made the pretty bold decision of saying, all right, we're not going to do chat... we are just going to [do] agent." They've built Windsurf from the ground up with an agent-first approach, and it’s making waves.
Kevin walked us through the evolution of AI coding tools, from autocomplete to chat, and now to agents. He highlighted the "magical experiences" users are having, like debugging complex code with AI assistance that actually understands the context. We also delved into the challenges – memory, checkpointing, and cost.
We also talked about the burning question: vibe coding. Is coding as we know it dead? Kevin’s take was nuanced: "there's an in between state that I really vibe or like gel with, which is,the scaffolding of what you want… Let's use, let's like vibe code and purely use the agent to accomplish this sort of commit." He sees AI agents raising the bar for software quality, demanding better UX, testing, and overall polish.
And of course, we had to ask about the elephant in the room – why are so many people switching from Cursor to Windsurf? Kevin's answer was humble, pointing to user experience, the agent-first workflow, and the team’s dedication to building the best product. Check out our full conversation on the pod and download Windsurf for yourself: windsurf.ai
Video Models & Voice model updates
There is so much happening in LLM world, that folks may skip over the other stuff, but there's so much happening in these world's as well this week! Here's a brief recap!
Alibaba's WanX: Open-sourced, cutting-edge video generation models making waves with over 250,000 downloads already. They claim to take SOTA on open source video generation evals and of course img2video of this high quality model will lead to ... folks using it for all kinds of things.
HUMEs Octave: A groundbreaking LLM model that genuinely understands context and emotion and does TTS. Blog Hume has been doing emotional TTS but with this TTS focused LLM we are now able to create voices with a prompt, and receive emotional responses that are inferred from the text. Think shyness, sarcasm, anger etc
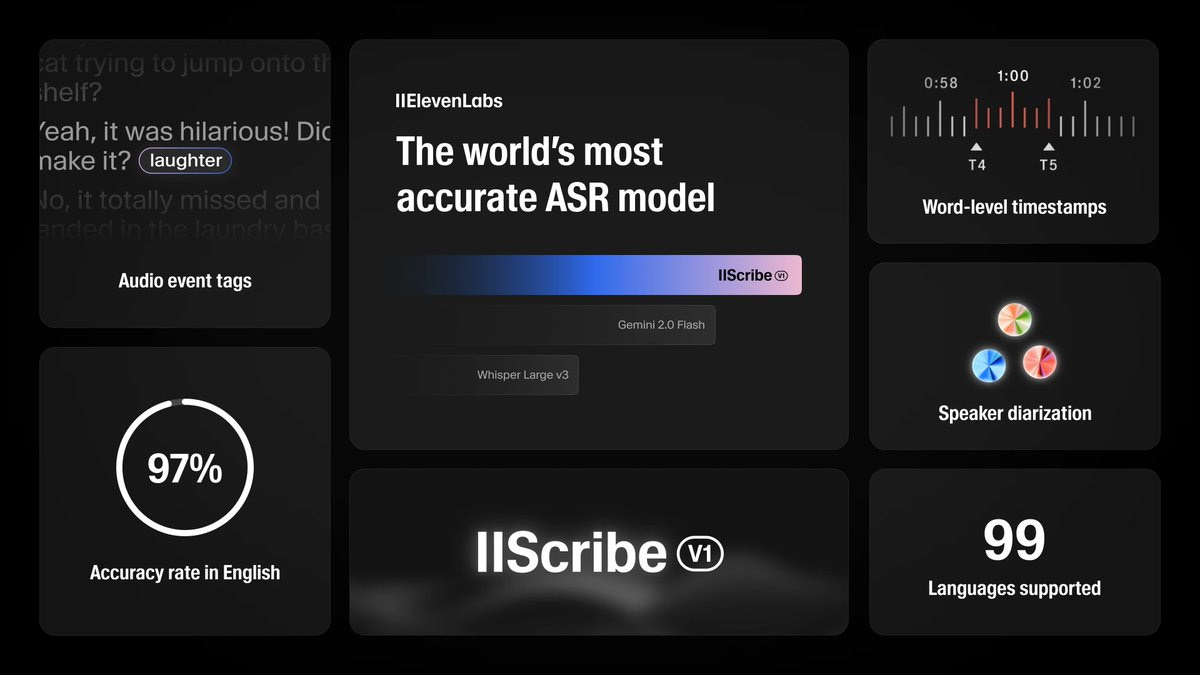
11labs’ Scribe: Beating Whisper 3 with impressive accuracy and diarization features, Scribe is raising the bar in speech-to-text quality. 11labs releasing their own ASR (automatic speech recognition) was not in my cards, and boy did they deliver. Beating whisper, with speaker separation (diarization), world level timestamps and much lower WER than other models, this is a very interesting entry to this space. However, free for now on their website, it's significantly slower than Gemini 2.0 and Whisper for me at least.
Sesame releases their conversational speech model (and promising to open source this) and it's honestly the best / least uncanny conversations I had with an AI. Check out my conversation with it
Lastly, VEO 2, the best video model around according to some, is finally available via API (though txt2video only) and it's fairly expensive, but gives some amazing results. You can try it out on FAL
Phew, it looks like we've made it! Huge huge week in AI, big 2 new models, tons of incredible updates on multimodality and voice as well 🔥
If you enjoyed this summary, the best way to support us is to share with a friend (or 3) and give us a 5 start reviews on wherever you get your podcasts, it really does help! 👏
See you next week,
Alex



