






Hey ya’ll, welcome to yet another ThursdAI, this is Alex coming at you every ThursdAI, including a live recording this time!
Which was incredible, we chatted about Falcon 180B,had a great interview in the end with 3 authors of the YaRN scaling paper and LLongMa 128K context, had 3 breaking news! in the middle, MOJO🔥 has been released and Adept released a LLaMa comparable OSS model (and friend of the pod) @reach_vb showed an open ASR leaderboard on hugging face! We also covered an incredible tiny model called StarCoder 1B that was finetuned by friend of the pod (who joined the space to talk to us about it!)
As always, you can listen to the whole 3 hour long form conversation (raw, unedited) on our Zealous page (and add it to your podcatcher via this RSS) and this short-form pod is available on Apple, Spotify and everywhere.
TL;DR of all topics covered
Open Source LLM
Big Co LLMs + API updates
Vision
Real time deepfake with FaceFusion (link)
HeyGen released AI avatars and AI video translation with lipsync (link, translation announcement)
Voice
Open ASR (automatic speech recognition) leaderboard from HuggingFace (link)
Tools
LangChain Hub (re) launched
Open Interpreter (Announcement, Github)
Open Source LLM
🦅 Falcon 180B - The largest open source LLM to date (Announcement, Demo)
The folks at the “Technology Innovation Institute” have open sourced the huge Falcon 180B, and have put it up on Hugging Face. Having previously open sourced Falcon 40B, the folks from TIIUAE have given us a huge model that beats (base) LLaMa 2 on several evaluations, if just slightly by a few percentages points.
It’s huge, was trained on 3.5 trillion tokens and weights above 100GB as a file and requires 400GB for inference.
Some folks were not as impressed with Falcon performance, given it’s parameter size is 2.5 those of LLaMa 2 (and likely it took a longer time to train) but the relative benchmarks is just a few percentages higher than LLaMa. It also boasts an embarrassingly low context window of just 2K tokens, and code was just 5% of it’s dataset, even though we already know that more code in the dataset, makes the models smarter!

Georgi Gerganov is already running this model on his M2 Ultra because he’s the Goat, and co-host of ThursdAI spaces, Nisten, was able to run this model with CPU-only and with just 4GB of ram 🤯 We’re waiting for Nisten to post a Github on how to run this monsterous model on just CPU, because it’s incredible!
However, given the Apache2 license and the fine-tuning community excitement about improving these open models, it’s an incredible feat. and we’re very happy that this was released!
The complete open sourcing also matters in terms of geopolitics, this model was developed in the UAE, while in the US, the export of A100 GPUs was banned to the middle easy, and folks are talking about regulating foundational models, and this release, size and parameter model that’s coming out of the United Arab Emirates, for free, is going to definitely add to the discussion wether to regulate AI, open source and fine-tuning huge models!
YaRN scaling LLaMa to 128K context window
Last week, just in time for ThursdAI, we posted about the release of Yarn-Llama-2-13b-128k, a whopping 32x improvement in context window size on top of the base LLaMa from the folks at Nous Research, Enrico Shippole, @theemozilla with the help of Eluether AI.
This week, they released the YaRN: Efficient Context Window Extension of Large Language Models paper which uses Rotary Position Embeddings to stretch the context windows of transformer attention based LLMs significantly.

We had friends of the pod Enrico Shippole, theemozilla (Jeff) and Bowen Peng on the twitter space and an special interview with them will be released on Sunday, if you’re interested in scaling and stretching context windows work, definitely subscribe for that episode, it was incredible!
It’s great to see that their work is already applied into several places, including CodeLLaMa (which was released with 16K - 100K context) and the problem is now compute, basically, context windows can be stretched, and the models are able to generalize from smaller datasets, such that the next models are predicted to be released with infinite amount of context window, and it’ll depend on your hardware memory requirements.
Persimmon-8B from AdeptAI (announcement, github)
AdeptAI, the company behind Act-1, a foundational model for AI Agent that does browser driving, and has a few co-founders that are the original transformers paper authors, have dropped a ThursdAI surprise, a fresh (read, not a LLaMa clone) model!
Releasing an completely open source model called Persimmon-8B, with a full Apache 2 license, 16K context window (using custom RoPE scaling methods) and some interesting inference speedups with C++.
A very interesting 8B model that can fit on most consumer hardware, with additional tricks and a huge context window, is definitely welcome!
Additional interesting point is, they have 70K unused embeddings for multimodal extensions! Can’t wait to see what’s that about!

Starcoder-1B-sft - tiny model that’s great at code
Anton Bacaj (@abacaj) has finetuned StarCoder, to achieve some incredible results, for such a tiny model! Remember the first item, a whopping 180B parameter Falcon? We’ll, this is just 1B parameters model, finetuned on 65K sampled dataset of code, that’s outperforming Falcon, LLaMa2, Palm-2 (and Persimmon) on coding tasks, and runs on your device, so fast, that it’s hard to read!

It boasts an incredible 39% on HumanEval task and 31% on MBPP! (Anton reran and updated the MBPP score later) and can run locally. Friend of the pod Xenova has already ported this model to transformers.js and it’ll soon run in your browser!
OpenHermes-13B from @teknium1 (link)

Our friend Teknium1 (who we’ve interviewed a few weeks ago) releases OpenHermes on top of LLaMa2, but this time it’s a completely open model and datasets, marking this the first time that Hermes models have been open!
OpenHermes was trained on 242,000 entries of primarily GPT-4 generated data, from open datasets across the AI landscape, including:
GPTeacher - General Instruct,
Roleplay v1, Roleplay v2, and Code Instruct Datasets, by Teknium
WizardLM (v1, evol_instruct 70k), by WizardLM
Team/nlpxucan Airoboros GPT-4 (v1.0), by JonDurbin
Camel-AI's domain expert datasets, by the Camel-AI Team
CodeAlpaca, by Sahil2801
GPT4-LLM and
Unnatural Instructions, by Microsoft
Check it out folks!
Big Co LLM + API updates
Modular finally ships Mojo 🔥 (Announcement)
I just knew it, that Mojo will finally be shipped during ThursdAI, and in fact, this was a great #BreakingNews moment on twitter spaces!

Modular, and it’s co-founder Chris Lattner (author of LLVM, MLIR, Swift and many other things) have finally released their Mojo 🔥 language, for AI.
Mojo 🔥 is like Python++, includes strong types, full interoperability with python ecosystem but is able to run basic vanilla python, and has so so much more in it, but the main thing Modular is claiming is a whopping 68,000x improvement over vanilla python!
You didn’t misread this, 68,000 improvement, when using all the Modular inference compilers, and Mojo virtualization tricks and compilation improvements. It’s incredible.
The beauty of Mojo is that it meets developers where they are and allows them to adopt new features to achieve high performance gradually. By combining the best of dynamic and static languages, Mojo can deliver performance up to 68,000 times faster than Python today. That's quite a leap! If you want to delve deeper into Mojo's origin story, you can find more information in their documentation. But for now, let me highlight a few key benefits that Mojo offers:
Firstly, Mojo allows you to write everything in one language, merging the usability of Python with the systems programming features that typically require developers to rely on C, C++, or CUDA. This means that both research and deployment teams can work within a common codebase, streamlining the workflow from research to production.
Secondly, Mojo unlocks Python's performance potential. While Python is widely used, it may not be the best tool for high-performance or specialized hardware tasks. However, Mojo bridges that gap by enabling high performance on CPUs and providing support for exotic accelerators like GPUs and ASICs. With Mojo, you can achieve performance levels on par with C++ and CUDA.
Thirdly, and this is a big one, Mojo seamlessly integrates with the entire Python ecosystem. You can leverage the extensive library collection available in Python while making use of Mojo's features and performance benefits. This means you can easily combine libraries like NumPy and Matplotlib with your Mojo code – talk about flexibility!
Finally, Mojo allows you to upgrade your AI workloads effortlessly. By tightly integrating with the Modular AI Engine, Mojo empowers you to extend your AI workloads with custom operations. This includes pre-processing and post-processing operations, as well as high-performance mathematical algorithms. You can even integrate kernel fusion, graph rewrites, shape functions, and more. Mojo is all about expanding the possibilities!
Mojo’s playground has been around since May and I have a deep dive here but you should really watch for over 3 hours on everything from Why they chose to be a python superset, to why he thinks the community will pick it up, it’s an incredible watch and will make you excited about Mojo!
WebGPU ships with support for FP16 in Chromium
Chrome has shipped with WebGPU back in April of 23’, after years of development, it allows high performance 3D graphics (and of course, transformers inference) in the browser and on the web!
However, for inference of models, GPU access is not enough, you also need to be able to run smaller models. Well, one way to make models smaller is to run them in fp16 format. Essentially cutting the precision of the weights numbers by half, we can use much smaller (read compressed) models with a slight loss in accuracy.
Friends of the pod Nisten and Xenova (transformers.js author) have given us an update that a new, updated fp16 support has shipped in nightly of chromium, allowing for much much smaller models to be run on clientside!
OpenAI first dev conference (Announcement)
OpenAI has announced their first developer focused conference, to happen in SF during November 6th!
In person only (with the keynote being streamed to all) and they also said that they won’t do any model announcement like GPT-5 😂
But we'll all expect at least a few API updates!
Vision
FaceFusion 1.1.0 - a deepfake faceswapper (Announcement, Github)
We all know deepfakes are here, I mean, don’t we? But did you know that it’s now super easy to face swap your face into an image or a video?
FaceFusion does just that, an incredibly fast way to deepfake someone’s face into an image or a video with a few clicks, works on CPU (I couldn’t make it work on GPU but it’s possible) and shows incredible results!
Enjoy Steve Buschemi dance around as Harry Styles? 3 clicks and 10 minutes and you get this 🔥
Friend of the pod CocktailPeanut, has made it incredible easy to install with just 1 click with his pinokio.computer app, which I use and love!
Facefusion also has a webcam mode that is able to deepfake any image onto a webcam stream for a lot of fun on zoom calls! (which I wasn’t able to test for some reason)

HeyGen launches their deep AI face creator
Many of us used 11Labs to clone voices, but what if you can clone a voice AND an image of a person? With just 2 minutes of their recording?
That’s what HeyGen are claiming to be able to do, and we’ve previously reported that their incredible realistic AI avatar generation from videos/images + voice really blew us away.
Heygen just launched their service and you can sign up and get a few minutes for free, here’s a sample (with the CEO avatar, they couldn’t make my own for some launch day errors)
The video you see on top of just that, the CEO of HeyGen, thanking you for reading this weeks ThursdAI!
Voice
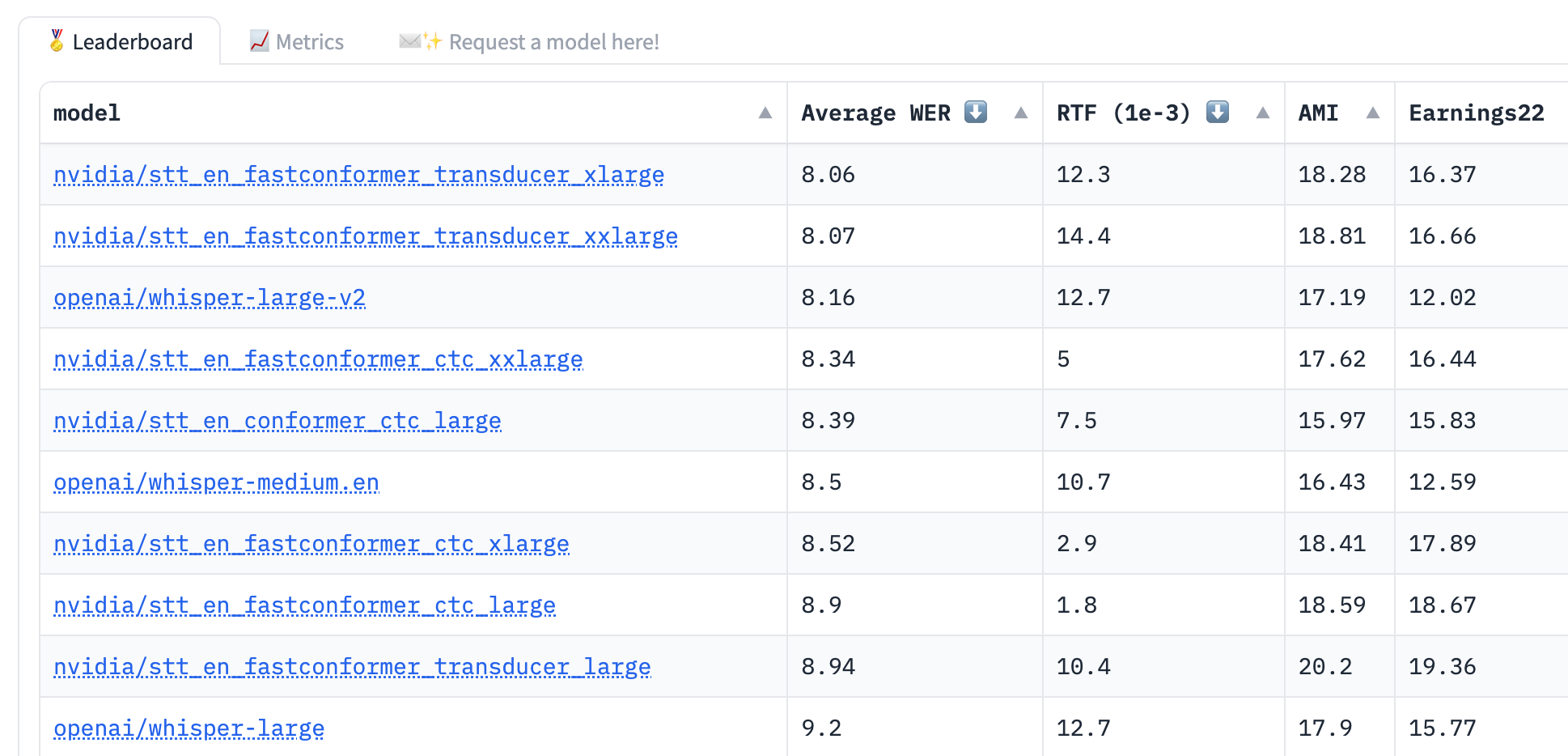
ASR leaderboard + New top ASR model from Nvidia
I love doing ThursdAI, and one of the things I love most, is folks sending me stuff they worked on, and then coming to ThursdAI to chat about it.
Friend of the pod Vaibhav (VB) Srivastav, who’s an incredible dev rel at HuggingFace, focusing on Audio, has shipped a new Open-ASR (automatic speech recognition) leaderboard on huggingface!
Showing the top ASR models like Whisper and a new comer, Nvidia FastConformer, which I didn’t even know existed, and now it’s topping Whisper for english speech to text tasks!
HuggingFace leaderboards like these are definitely a boon for the Open Source industry as they allow all of us to easily select open source models, but also allow the open source community to start racing towards the top, while we all benefit!
Tools
Open Interpreter (Announcement, Github)

One tool that I’ve used this week, and is incredible, is OpenInterpreter from @heyitskillian
It’s incredibly easy to install and run, and behaves like OpenAI Code Interpreter (renamed to Advanced Data Analytics) but on your computer, and is able to do things like control your apps, lower volume, edit images/files and tons more
pip install open-interpreterAnd that’s it!
Give it a try (and you have to approve each command that it runs)
It’s a great agent, and hopefully we’ll get Killian to chat with us about it on next ThursdAI!
LangChain hub has launched (link)
If you’re into LangChain, and even if you aren’t, it’s undeniable the weight LangChain has in the ai engineer industry! They have a connector for everything, tons of folks use them, and they have raised a bunch of funding.
They have just launched their new LangChain Hub and it’s exciting! Many folks are sharing their best prompts on there, and ways to work with langchain, with upvotes and sharable links!
Also, worth nothing that our friends swyx and Alessio from Latent Space have recently released an episode with Harrison on Latent space, and it’s WELL worth listening (and reading) as swyx did a deep dive into Landchain, it’s nay-sayers and everything in between!
Check it out below :

Thank you, see you next time (with some incredible personal news I’ll have to share)






