



March 14th, 2023 was the day ThursdAI was born, it was also the day OpenAI released GPT-4, and I jumped into a Twitter space and started chaotically reacting together with other folks about what a new release of a paradigm shifting model from OpenAI means, what are the details, the new capabilities. Today, it happened again!
Hey, it's Alex, I'm back from my mini vacation (pic after the signature) and boy am I glad I decided to not miss September 12th! The long rumored 🍓 thinking model from OpenAI, dropped as breaking news in the middle of ThursdAI live show, giving us plenty of time to react live!
But before this, we already had an amazing show with some great guests! Devendra Chaplot from Mistral came on and talked about their newly torrented (yeah they did that again) Pixtral VLM, their first multi modal! , and then I had the honor to host Steven Johnson and Raiza Martin from NotebookLM team at Google Labs which shipped something so uncannily good, that I legit said "holy fu*k" on X in a reaction!
So let's get into it (TL;DR and links will be at the end of this newsletter)
OpenAI o1, o1 preview and o1-mini, a series of new "reasoning" models

This is it folks, the strawberries have bloomed, and we finally get to taste them. OpenAI has released (without a waitlist, 100% rollout!) o1-preview and o1-mini models to chatGPT and API (tho only for tier-5 customers) 👏 and are working on releasing 01 as well.
These are models that think before they speak, and have been trained to imitate "system 2" thinking, and integrate chain-of-thought reasoning internally, using Reinforcement Learning and special thinking tokens, which allows them to actually review what they are about to say before they are saying it, achieving remarkable results on logic based questions.
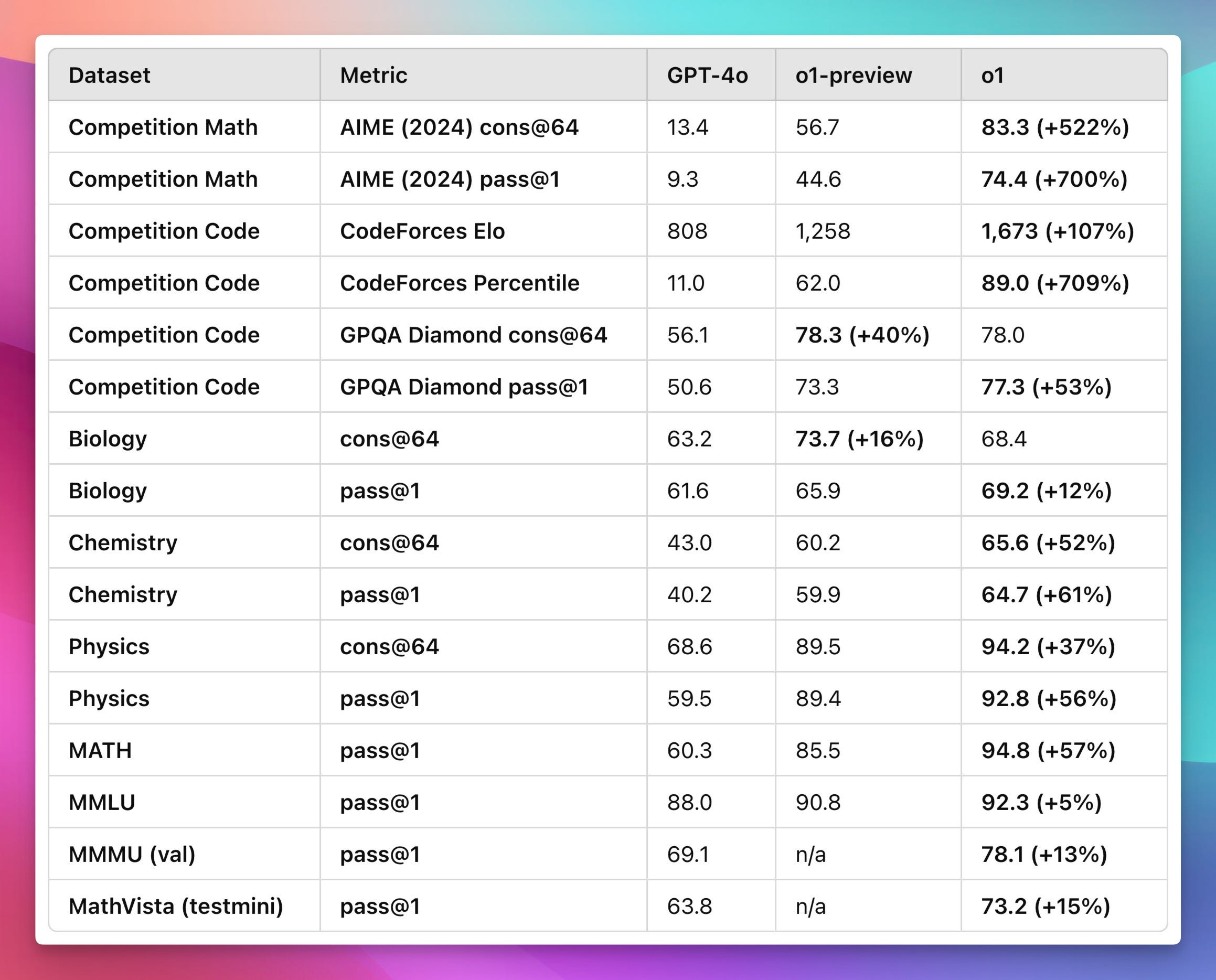
Specifically you can see the jumps in the very very hard things like competition math and competition code, because those usually require a lot of reasoning, which is what these models were trained to do well.
New scaling paradigm

Noam Brown from OpenAI calls this a "new scaling paradigm" and Dr Jim Fan explains why, with this new way of "reasoning", the longer the model thinks - the better it does on reasoning tasks, they call this "test-time compute" or "inference-time compute" as opposed to compute that was used to train the model. This shifting of computation down to inference time is the essence of the paradigm shift, as in, pre-training can be very limiting computationally as the models scale in size of parameters, they can only go so big until you have to start building out a huge new supercluster of GPUs to host the next training run (Remember Elon's Colossus from last week?).
The interesting thing to consider here is, while current "thinking" times are ranging between a few seconds to a minute, imagine giving this model hours, days, weeks to think about new drug problems, physics problems 🤯.
Prompting o1
Interestingly, a new prompting paradigm has also been introduced. These models now have CoT (think "step by step") built-in, so you no longer have to include it in your prompts. By simply switching to o1-mini, most users will see better results right off the bat. OpenAI has worked with the Devin team to test drive these models, and these folks found that asking the new models to just give the final answer often works better and avoids redundancy in instructions.
The community of course will learn what works and doesn't in the next few hours, days, weeks, which is why we got 01-preview and not the actual (much better) o1.
Safety implications and future plans
According to Greg Brokman, this inference time compute also greatly helps with aligning the model to policies, giving it time to think about policies at length, and improving security and jailbreak preventions, not only logic.
The folks at OpenAI are so proud of all of the above that they have decided to restart the count and call this series o1, but they did mention that they are going to release GPT series models as well, adding to the confusing marketing around their models.

Open Source LLMs
Reflecting on Reflection 70B
Last week, Reflection 70B was supposed to launch live on the ThursdAI show, and while it didn't happen live, I did add it in post editing, and sent the newsletter, and packed my bag, and flew for my vacation. I got many DMs since then, and at some point couldn't resist checking and what I saw was complete chaos, and despite this, I tried to disconnect still until last night.
So here's what I could gather since last night. The claims of a llama 3.1 70B finetune that Matt Shumer and Sahil Chaudhary from Glaive beating Sonnet 3.5 are proven false, nobody was able to reproduce those evals they posted and boasted about, which is a damn shame.
Not only that, multiple trusted folks from our community, like Kyle Corbitt, Alex Atallah have reached out to Matt in to try to and get to the bottom of how such a thing would happen, and how claims like these could have been made in good faith. (or was there foul play)
The core idea of something like Reflection is actually very interesting, but alas, the inability to replicate, but also to stop engaging with he community openly (I've reached out to Matt and given him the opportunity to come to the show and address the topic, he did not reply), keep the model on hugging face where it's still trending, claiming to be the world's number 1 open source model, all these smell really bad, despite multiple efforts on out part to give the benefit of the doubt here.
As for my part in building the hype on this (last week's issues till claims that this model is top open source model), I addressed it in the beginning of the show, but then twitter spaces crashed, but unfortunately as much as I'd like to be able to personally check every thing I cover, I often have to rely on the reputation of my sources, which is easier with established big companies, and this time this approached failed me.
This weeks Buzzzzzz - One last week till our hackathon!
Look at this point, if you read this newsletter and don't know about our hackathon, then I really didn't do my job prompting it, but it's coming up, September 21-22 ! Join us, it's going to be a LOT of fun!

🖼️ Pixtral 12B from Mistral
Mistral AI burst onto the scene with Pixtral, their first multimodal model! Devendra Chaplot, research scientist at Mistral, joined ThursdAI to explain their unique approach, ditching fixed image resolutions and training a vision encoder from scratch.

"We designed this from the ground up to...get the most value per flop," Devendra explained. Pixtral handles multiple images interleaved with text within a 128k context window - a far cry from the single-image capabilities of most open-source multimodal models. And to make the community erupt in thunderous applause (cue the clap emojis!) they released the 12 billion parameter model under the ultra-permissive Apache 2.0 license. You can give Pixtral a whirl on Hyperbolic, HuggingFace, or directly through Mistral.
DeepSeek 2.5: When Intelligence Per Watt is King
Deepseek 2.5 launched amid the reflection news and did NOT get the deserved attention it.... deserves. It folded (no deprecated) Deepseek Coder into 2.5 and shows incredible metrics and a truly next-gen architecture. "It's like a higher order MOE", Nisten revealed, "which has this whole like pile of brain and it just like picks every time, from that." 🤯. DeepSeek 2.5 achieves maximum "intelligence per active parameter"
Google's turning text into AI podcast for auditory learners with Audio Overviews
Today I had the awesome pleasure of chatting with Steven Johnson and Raiza Martin from the NotebookLM team at Google Labs. NotebookLM is a research tool, that if you haven't used, you should definitely give it a spin, and this week they launched something I saw in preview and was looking forward to checking out and honestly was jaw-droppingly impressed today.
NotebookLM allows you to upload up to 50 "sources" which can be PDFs, web links that they will scrape for you, documents etc' (no multimodality so far) and will allow you to chat with them, create study guides, dive deeper and add notes as you study.
This week's update allows someone who doesn't like reading, to turn all those sources into a legit 5-10 minute podcast, and that sounds so realistic, that I was honestly blown away. I uploaded a documentation of fastHTML in there.. and well hear for yourself
The conversation with Steven and Raiza was really fun, podcast definitely give it a listen!
Not to mention that Google released (under waitlist) another podcast creating tool called illuminate, that will convert ArXiv papers into similar sounding very realistic 6-10 minute podcasts!
There are many more updates from this week, there was a whole Apple keynote I missed, which had a new point and describe feature with AI on the new iPhones and Apple Intelligence, Google also released new DataGemma 27B, and more things in TL'DR which are posted here in raw format
See you next week 🫡 Thank you for being a subscriber, weeks like this are the reason we keep doing this! 🔥 Hope you enjoy these models, leave in comments what you think about them
TL;DR in raw format

Mixtral releases Pixtral 12B - multimodal model (X, try it)
Pixtral is really good at OCR says swyx
Interview with Devendra Chaplot on ThursdAI
Initial reports of Pixtral beating GPT-4 on WildVision arena from AllenAI
JinaIA reader-lm-0.5b and reader-lm-1.5b (X)
ZeroEval updates
Deepseek 2.5 -
Deepseek coder is now folded into DeepSeek v2.5
89 HumanEval (up from 84 from deepseek v2)
9 on MT-bench
Google - DataGemma 27B (RIG/RAG) for improving results
Retrieval-Interleaved Generation
🤖 DataGemma: AI models that connect LLMs to Google's Data Commons
📊 Data Commons: A vast repository of trustworthy public data
🔍 Tackling AI hallucination by grounding LLMs in real-world data
🔍 Two approaches: RIG (Retrieval-Interleaved Generation) and RAG (Retrieval-Augmented Generation)
🔍 Preliminary results show enhanced accuracy and reduced hallucinations
🔓 Making DataGemma open models to enable broader adoption
🌍 Empowering informed decisions and deeper understanding of the world
🔍 Ongoing research to refine the methodologies and scale the work
🔍 Integrating DataGemma into Gemma and Gemini AI models
🤝 Collaborating with researchers and developers through quickstart notebooks
Big CO LLMs + APIs
Apple event
Apple Intelligence - launching soon
Visual Intelligence with a dedicated button
Google Illuminate - generate arXiv paper into multiple speaker podcasts (Website)
5-10 min podcasts
multiple speakers
any paper
waitlist
has samples
sounds super cool
Google NotebookLM is finally available - multi modal research tool + podcast (NotebookLM)
Has RAG like abilities, can add sources from drive or direct web links
Currently not multimodal
Generation of multi speaker conversation about this topic to present it, sounds really really realistic
Chat with Steven and Raiza
OpenAI reveals new o1 models, and launches o1 preview and o1-mini in chat and API (X, Blog)
Trained with RL to think before it speaks with special thinking tokens (that you pay for)
new scaling paradigm
This weeks Buzz
Vision & Video
Adobe announces Firefly video model (X)
Voice & Audio
Tools
New Jina reader (X)


