





ThursdAI November 2nd

Hey everyone, welcome to yet another exciting ThursdAI. This week we have a special announcement, swyx the co-host of Latent Space and I will be hosting a shared X space live from Open AI Dev Day! Monday next week (and then will likely follow up with interviews, analysis and potentially a shared episode!)
Make sure you set a reminder on X (https://thursdai.news/next) , we’re going to open the live stream early, 8:30am on Monday, and we’ll live stream all throughout the keynote! It’ll be super fun!
Back to our regular schedule, we covered a LOT of stuff today, and again, were lucky enough to have BREAKING NEWS and the authors of said breaking news (VB from HuggingFace and Emozilla from Yarn-Mistral-128K) to join us and talk a little bit in depth about their updates!
TL;DR of all topics covered:
AI Regulation
UK AI regulation forum (King AI speech, no really, Arthur from Mistral)
Mozilla - Joint statement on AI and openness (Sign the letter)
Open Source LLMs
Together AI releases RedPajama 2, 25x larger dataset (30T tokens) (Blog, X, HF)
Alignment Lab - OpenChat-3.5 a chatGPT beating open source model (HF)
Emozilla + Nous Research - Yarn-Mistral-7b-128k (and 64K) longest context window (Announcement, HF)
LDJ + Nous Research release Capybara 3B & 7B (Announcement, HF)
LDJ - Obsidian 3B - the smallest open source multi modal model (HF, Quantized)
Big CO LLMs + APIs
ChatGPT "all tools" MMIO mode - Combines vision, browsing, ADA and DALL-E into 1 model (Thread, Examples, System prompt)
Microsoft CodeFusion paper - a tiny (75M parameters) model beats a 20B GPT-3.5-turbo (Thread, ArXiv)
Voice
AI Art & Diffusion & 3D
Luma - text-to-3D Genie bot (Announcement, Try it)
Stable 3D & Sky changer
AI Regulation IS HERE
Look, to be very frank, I want to focus ThursdAI on all the news that we're getting from week to week, and to bring a positive outlook, so politics, doomerism, and regulation weren't on the roadmap, however, with weeks like these, it's really hard to ignore, so let's talk about this.
President Biden signed an Executive Order, citing the old, wartime era Defence Production act (looks like the US gov. also has "one weird trick" to make the gov move faster) and it wasn't as bombastic as people thought. X being X, there has been so many takes pre this executive order even releasing about regulatory capture being done by the big AI labs, about how open source is no longer going to be possible, and if you visit Mark Andressen feed you'll see he's only reposting AI generated memes to the tune of "don't tread on me" about GPU and compute rights.
However, at least on the face of it, this executive order was mild, and discussed many AI risks and focused on regulating models from huge compute runs (~28M H100 hours // $50M dollars worth). Here's the relevant section.

Many in the open source community reacted to the flops limitation with a response that it's very much a lobbyist based decision, and that the application should be regulated, not only the compute.
There's much more to say about the EO, if you want to dig deeper, I strongly recommend this piece from AI Snake oil :

and check out Yan Lecun's whole feed.
UK AI safety summit in Bletchley Park

Look, did I ever expect to add the King of England into an AI weekly recap newsletter? Surely, if he was AI Art generated or something, not the real king, addressing the topic of AI safety!
This video was played for the attendees of a few day AI safety summit in Blecheley park, where AI luminaries (Yan Lecun, Elon Musk, Arthur Mensch Mistral CEO, Naveen Rao) attended and talked about the risks and benefits of AI and regulation. I think Naveen Rao had a great recap here, but additionally, there were announcements about Safety Institute in the UK, and they outlined what actions the government can take.
In other regulation related news, Mozilla has a joint statement on AI safety and openness (link) that many signed, which makes the case for openness and open source as the way to AI safety. Kudos on mozilla, we stand by the letter 🤝
Big CO LLMs + APIs
OpenAI - ChatGPT "all tools" aka MMIO mode (that's now dubbed "confidential")
Just a week before the first Dev Day from OpenAI, we were hanging out in X spaces talking about what the regulation might bring, when a few folks noticed that their ChatGPT interface looks different, and saw a very specific popup message saying that ChatGPT can now talk with documents, and "use tools without switching", see and interact with DALL-E and Advanced Data Analysis (FKA Code Interpreter) all in one prompt.

While many X takes focused solely on just how many "chat with your PDF" startups OpenAI just "killed", and indeed, the "work with PDFs" functionality seemed new, chatGPT could now get uploads of files, had the ability to search, to go to a specific page, even do a basic summary on PDF files, I was interested in the second part!
Specifically because given GPT-4V is now basically enabled for everyone, this "combined" mode makes ChatGPT the first MMIO model that we have, which is a multi modal on input (Text, Voice, Images) and output (Text, Images). You see, most MultiModal Models so far have been only multimodal on the input, ie, take in text or images or a combination, and while playing around with the above, we noticed some incredible use-cases that are now available!
ChatGPT (for some lucky folks) can now do all these things in one prompt with shared context:
Read and interact with PDFs
See and understand images + text
Browse & Search up to date info with Bing
Write and execute code with ADA
Generate images with DALL-E
All in the same prompt, one after another, and often for several steps and iterations.
One such example was, I asked for "get the current weather in Denver and generate an image based on the conditions" and we got this incredible, almost on the fly "weather" UI, showing the conditions (it was the first snow in CO this year), weather, humidity and everything. Now, DALL-E is ok with text but not great, but it's incredible with scenery, so having this "on the fly UI" that has real time info was super great to show off the capabilities of a general model.
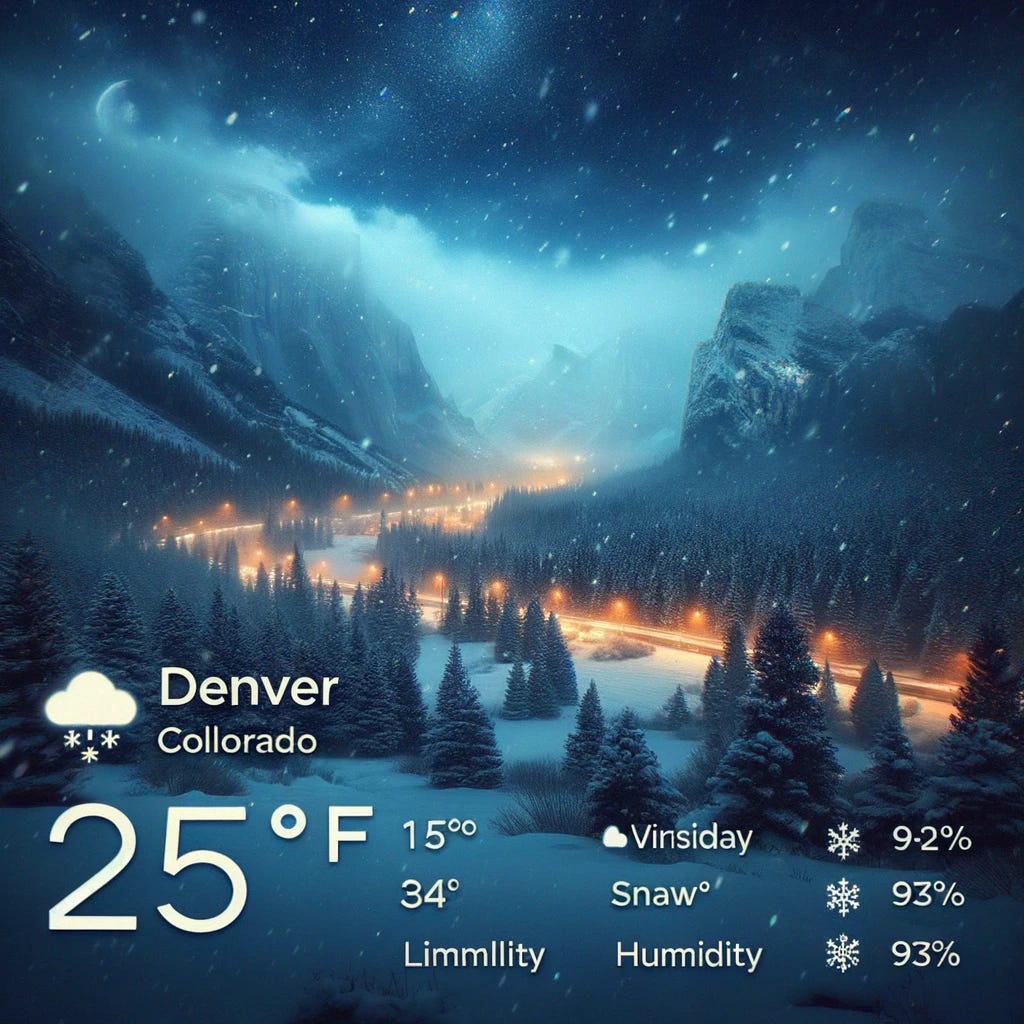
We also saw prompts from folks who uploaded a picture of an obscure object, and asked DALL-E to "add" this object to an already generated image, so DALL-E now has eyes, and can understand and "draw" some of the objects and add them to other images, which was an amazing thing to see, and I can't wait to play around with this functionality.
We noticed a few more things, specifically that DALL-E images are now stored on the same disk that you get access to with ADA, so you can then ask ChatGPT to upscale, crop and do things with those images for example, and generate code with those images as a background!
There are so many new potential use-cases that have opened up, that we spent a long evening / night on X spaces trying to throw the kitchen sink onto this mode, in the fear that it was a fluke by OpenAI and they weren't meant to release this, and we were right! Today on ThursdAI live recording, some users reported that they no longer have access to it (and they miss it!) and some reported that it's now called something like "Confidential"
Someone also leaked the full prompt for this "all tools" mode and it's a doosy! The "All Tools" omni-prompt takes a whopping 2,756 tokens, but it's also using the GPT-4 32k model, with a 32,767 token context window. (link)
I guess we're going to see the announcement on Dev Day (did you set a reminder?)
This new mode that we saw and played with, added to the many many leaks and semi-confirmed modes that are coming out of Reddit make it seem like ChatGPT is going to have an all out Birthday party next week and is about to blow some people's minds! We're here for it! 👏
Open Source LLMs
CodeFusion - 75M parameters model based on Diffusion Model for Code Generation
Code-fusion was taken down from ArXiv, claimed 3.5 is 20B params (and then taken down saying that this was unsubstantiated) X link

The paper itself discusses the ability to use diffusion to generate code, and has much less data to get to a very good coding level, with a model small enough to fit on a chip's cache (not even memory) and be very very fast. Of course, this is only theoretical and we're going to wait for a while until we see if this replicates, especially since the PDF was taken down due to someone attributing the 20B parameters note to a forbes article.
The size of the model, and the performance score on some coding tasks make me very very excited about tiny models on edge/local future!
I find the parameter obsession folks have about OpenAI models incredible, because parameter size really doesn’t matter, it's a bad estimation anyway, OAI can train their models for years and keep them in the same parameter size and they would be vastly different models at the start and finish!
Together releases a massive 30T tokens dataset - RedPajama-Data-v2 (Announcement, HF)
This massive massive dataset is 25x the previous RedPajama, and is completely open, deduplicated and has enormous wealth of data to train models from. For folks who were talking the "there's no more tokens" book, this came as a surprise for sure! It's also multi-lingual, with tokens in English, French, Italian, German and Spanish in there. Kudos to Together compute for this massive massive open source effort 👏

Open source Finetunes Roundup
This week was another crazy one for open source fine-tuners, releasing SOTA after SOTA, many of them on ThursdAI itself 😅 Barely possible to keep up (and that's quite literally my job!)
Mistral 7B - 128K (and 64K) (HF)
The same folks who brought you the YaRN paper, Emozilla, Bowen Peng and Enrico Shippole (frequent friends of the pod, we had quite a few conversations with them in the past) have released the longest context Mistral fine-tune, able to take 64K and a whopping 128K tokens in it's context length, making one of the best open source model now compatible with book length prompts and very very long memory!
Capybara + Obsidian (HF, Quantized)
Friend of the pod (and weekly cohost) LDJ releases 2 Nous research models, Capybara (trained on StableLM 3B and Mistral 7B) and Obsidian, the first vision enabled multi modal 3B model that can run on an iPhone!
Capybara is a great dataset that he compiled and the Obsidian model uses the LLaVa architecture for input multimodality and even shows some understanding of humor in images!
Alignment Lab - OpenChat-3.5 a chatGPT beating open source model (Announcement, HF)
According to friends of the pod Alignment Lab (of OpenOrca fame) we get a Mistral finetune that beats! chatGPT on many code based evaluations (from march, we all think chatGPT became much better since then)
OpenChat is by nature a conversationally focused model optimized to provide a very high quality user experience in addition to performing extremely powerfully on reasoning benchmarks.
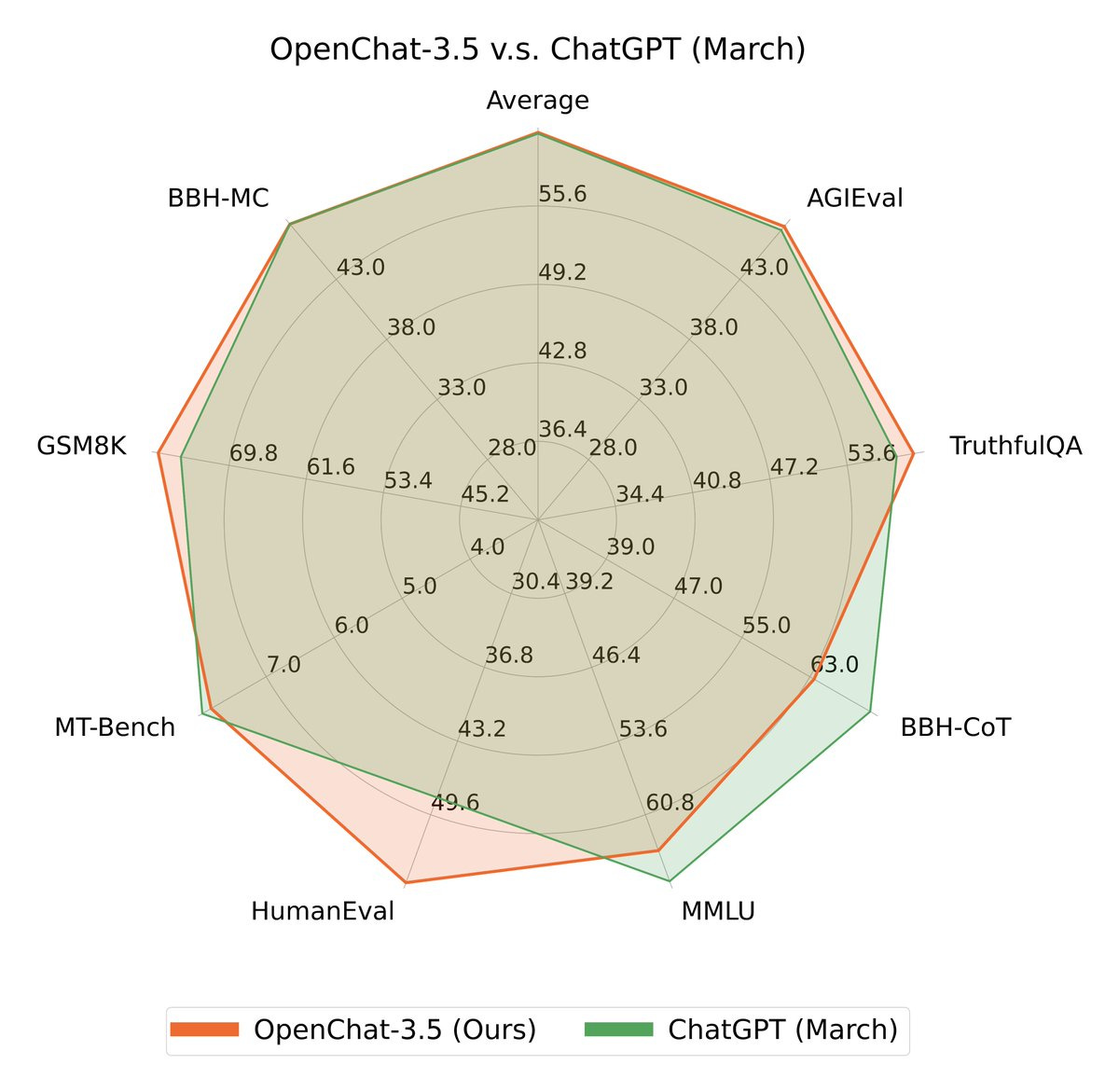
Open source is truly unmatched, and in the face of a government regulation week, open sources is coming out in full!
Voice
HuggingFace Distill Whisper - 6x performance of whisper with 1% WER rate (Announcement, HF)
Hugging face folks release a distillation of Whisper, a process (and a paper) with which they use a "teacher" model like the original Open AI whisper, to "teach" a smaller model, and in the process of distillation, transfer capabilities from one to another, while also making the models smaller!

This makes a significantly smaller model (2x smaller) with comparative (and even better) performance on some use-cases, while being 6x faster!
This distill-whisper is now included with latest transformers (and transformers.js) releases and you can start using this faster whisper today! 👏
That's it for today folks, it's been a busy busy week, and many more things were announced, make sure to join our space and if you have read all the way until here, DM me the 🧯 emoji as a reply or in a DM, it’s how I know who are the most engaged users are!




