





Hey 👋 Look it May or May not be the first AI newsletter you get in May, but it's for sure going to be a very information dense one. As we had an amazing conversation on the live recording today, over 1K folks joined to listen to the first May updates from ThursdAI.
As you May know by now, I just love giving the stage to folks who are the creators of the actual news I get to cover from week to week, and this week, we had again, 2 of those conversations.
First we chatted with Piotr Padlewski from Reka, the author on the new Vibe-Eval paper & Dataset which they published this week. We've had Yi and Max from Reka on the show before, but it was Piotr's first time and he was super super knowledgeable, and was really fun to chat with.
Specifically, as we at Weights & Biases launch a new product called Weave (which you should check out at https://wandb.me/weave) I'm getting more a LOT more interested in Evaluations and LLM scoring, and in fact, we started the whole show today with a full segment on Evals, Vibe checks and covered a new paper from Scale about overfitting.
The second deep dive was with my friend Idan Gazit, from GithubNext, about the new iteration of Github Copilot, called Copilot Workspace. It was a great one, and you should definitely give that one a listen as well
TL;DR of all topics covered + show notes
Scores and Evals
No notable changes, LLama-3 is still #6 on LMsys
gpt2-chat came and went (in depth chan writeup)
Scale checked for Data Contamination on GSM8K using GSM-1K (Announcement, Paper)
Vibes-Eval from Reka - a set of multimodal evals (Announcement, Paper, HF dataset)
Open Source LLMs
Big CO LLMs + APIs
Github releases Copilot Workspace (Announcement)
AI21 - releases Jamba Instruct w/ 256K context (Announcement)
Google shows Med-Gemini with some great results (Announcement)
Claude releases IOS app and Team accounts (X)
This weeks Buzz
Vision & Video
AI Art & Diffusion & 3D
ByteDance releases Hyper-SD - Stable Diffusion in a single inference step (Demo)
Tools & Hardware
Still haven't open the AI Pin, and Rabbit R1 just arrived, will open later today
Co-Hosts and Guests
Piotr Padlewski (@PiotrPadlewski) from Reka AI
Idan Gazit (@idangazit) from Github Next
Wing Lian (@winglian)
Nisten Tahiraj (@nisten)
Yam Peleg (@yampeleg)
LDJ (@ldjconfirmed)
Wolfram Ravenwolf (@WolframRvnwlf)
Ryan Carson (@ryancarson)
Scores and Evaluations
New corner in today's pod and newsletter given the focus this week on new models and comparing them to existing models.
What is GPT2-chat and who put it on LMSys? (and how do we even know it's good?)
For a very brief period this week, a new mysterious model appeared on LMSys, and was called gpt2-chat. It only appeared on the Arena, and did not show up on the leaderboard, and yet, tons of sleuths from 4chan to reddit to X started trying to figure out what this model was and wasn't.

Folks started analyzing the tokenizer, the output schema, tried to get the system prompt and gauge the context length. Many folks were hoping that this is an early example of GPT4.5 or something else entirely.
It did NOT help that uncle SAMA first posted the first tweet and then edited it to remove the - and it was unclear if he's trolling again or foreshadowing a completely new release or an old GPT-2 but retrained on newer data or something.

The model was really surprisingly good, solving logic puzzles better than Claude Opus, and having quite amazing step by step thinking, and able to provide remarkably informative, rational, and relevant replies. The average output quality across many different domains places it on, at least, the same level as high-end models such as GPT-4 and Claude Opus.
Whatever this model was, the hype around it made LMSYS add a clarification to their terms and temporarily take off the model now. And we're waiting to hear more news about what it is.
Reka AI gives us Vibe-Eval a new multimodal evaluation dataset and score (Announcement, Paper, HF dataset)

Reka keeps surprising, with only 20 people in the company, their latest Reka Core model is very good in multi modality, and to prove it, they just released a new paper + a new method of evaluating multi modal prompts on VLMS (Vision enabled Language Models)
Their new Open Benchmark + Open Dataset is consistent of this format:

And I was very happy to hear from one of the authors on the paper @PiotrPadlewski on the pod, where he mentioned that they were trying to create a dataset that was going to be very hard for their own model (Reka Core) and just decided to keep evaluating other models on it.
They had 2 main objectives : (i) vibe checking multimodal chat models for day-to-day tasks and (ii) deeply challenging and probing the capabilities of present frontier models. To this end, the hard set contains > 50% questions that all frontier models answer incorrectly
Chatting with Piotr about it, he mentioned that not only did they do a dataset, they actually used Reka Core as a Judge to score the replies from all models on that dataset and found that using their model in this way roughly correlates to non-expert human judgement! Very very interesting stuff.
The "hard" set is ... well hard!

Piotr concluded that if folks want to do research, they will provide free API access to Reka for that, so hit them up over DMs if you want to take this eval for a spin on your new shiny VLM (or indeed verify the metrics they put up)
Scale tests for eval dataset contamination with GSM-1K (Announcement, Paper)
Scale.ai is one of the most prominent companies in AI you may never have heard of, they are valued at $13B dollars and have pivoted from data processing for autonomous vehicles to being the darling of the government, with agreements from the DoD for data pipeline and evaluation for US Military.
They have released a new paper as well, creating (but not releasing) a new dataset that matches the GSM8K (Grade School Math) dataset and evaluation that many frontier companies love to showcase in their release benchmarks with some surprising results!
So Scale folks created (but not released) a dataset called GSK 1K, which tracks and is similar to the public GSM-8K dataset, and tested a bunch of existing models on their new one, to see the correlation, and if the different was very stark, assume that some models overfitted (or even had their dataset contaminated) on the publicly available GSM8K.
On one end, models like Mistral or Phi do up to 10% worse on GSM1k compared to GSM8k. On the other end, models like Gemini, Claude, or GPT show basically no signs of being overfit.

The author goes on to say that overfitting doesn't necessarily mean it's a bad model, and highlights Phi-3 which has a 10% difference on their new GSK-1K score compared to GSM-8K, but still answers 68% of their dataset, while being a tiny 3.8B parameter model.
It seems that Scale is now stepping into the Evaluation game and have noticed how much interest there is in actually understanding how models perform, and are stepping into this game, by building (but not releasing so they don't leak) datasets. Jim Fan tweet (and Scale CEO Alex Wang QT) seem to agree that this is the right positioning for Scale (as they don't have models of their own and so can be neutral like Moody's)

Open Source LLMs
LLama-3 gets 1M context window + Other LLama-3 news
In the second week of LLama-3 corner, we are noticing a significant ramp in all things Llama-3, first with the context length. The same folks from last week, Gradient, have spend cycles and upscaled/stretched LLama-3 to a whopping 1 million tokens in the context window (Llama-3 8B Gradient Instruct 1048k), with a very decent Niddle in the Haystack result.
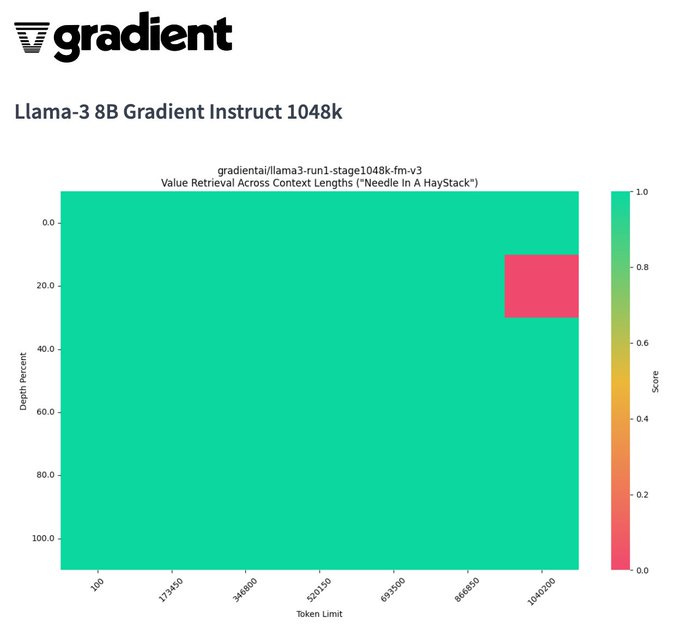
The main problem? Transformers have quadratic attention scaling issues for longer context, so this isn't something that you'd be able to run on your mac (nay, on your cluster) any time soon, and it's almost only theoretical at this point.
The upside? We had Wing Lian (from Axolotl) on the show, and he talked about a new method called LoRD (which is now part of MergeKit) which is a way to extract Loras from models.
Think of it as LLM arithmetic, you take the base model (llama-3 in this case) and the finetune (Llama-3 8B Gradient Instruct 1048k) and simple run a command like so:
mergekit-extract-lora llama-3-8B-gradient-instruct-1048K llama-3-8B just-the-context-lora [--no-lazy-unpickle] --rank=desired_rank
And boom, in theory, you have a tiny LoRA file that's extracted that is only the difference between these two models, the base and it's finetune.
It's really exciting stuff to be able to do brain surgery on these models and extract only one specific essence!
First LLama-3 finetunes that beat the instruct version

Folks and Nous research give us a new Hermes-Pro on top of Llama-8B (X, HF) that is beating the llama-3 instruct on benchmarks, which is apparently very hard to do, given that Meta created a LOT of human labeled instructions (10M or so) and gave us a really really good instruct model.
Nous Hermes 2 pro is also giving Llama-3 additional superpowers like function calling and tool use, specifically mentioning that this is the model to use if you do any type of agentic stuff
This new version of Hermes maintains its excellent general task and conversation capabilities - but also excels at Function Calling, JSON Structured Outputs, and has improved on several other metrics as well, scoring a 90% on our function calling evaluation built in partnership with Fireworks.AI, and an 84% on our structured JSON Output evaluation.
Kudos Teknium1, Karan and @intrstllrninja on this release, can't wait to try it out 🫡
LMStudio gives us a CLI (Github)
And speaking of "trying it out", you guys know that my recommended way of running these local models is LMStudio, and no, Yagil didn't sponsor ThursdAI haha I just love how quickly this piece of software became the go to locally for me running these models.
Well during ThursdAI I got a #breakingNews ping from their discord, that LM Studio now has a CLI (command line interface) which allows one to load/unload and run the webserver with the new CLI (kind of similar to Ollama)
And since LM Studio exposes an OpenAI compatible completions API once the models are loaded, you are not able to use these models with a simple change to the your script like so:
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
Which is amazing and I'm very happy about this option, as this opens the door to tons of automations and evaluation possibilities (with something like Weave), in fact while writing this, I downloaded the model from HuggingFace, loaded a web-server and ran my first prompts, and it all took like 5 minutes, and is very easy to do!

This weeks Buzz (What happens in Weights & Biases this week)
I have so much to share, but I want to make sure I don't overwhelm the newsletter, but here we go.
First of all, I'm flying out to SF again! in a few weeks to sponsor and judge the first ever LLama-3 hackathon, together with Meta, and hosted by the fine folks at Cerebral Valley (sign up and come hack!)

Cerebral Valley is hosting their events at this beautiful place called Shak-15 which I've mentioned before on the newsletter, and I'm excited to finally take part in one of their events!

The second part I can't wait to tell you about, is a week after, I'm going to Microsoft BUILD conference in Seattle, and will be representing Weights & Biases in that huge event (which last year featured Andrej Karpathy giving state of LLMs)
Here's a video I recorded for that event, which I worked really hard on, and would love some feedback. Please also let me know if you notice anything that an AI did in this video 👀 There's... something
As always, if you're attending any of these events, and see me, please do come say hi and give me a high five. I love meeting ThursdAI community folks in the wild, it really makes up for the fact that I'm working remotely from Denver and really makes this whole thing worth it!
Big Companies & APIs
Github’s new Copilot Workspace in Technical Preview

I was very happy to have friend of the pod Idan Gazit, Senior Director of Research at GitHub Next, the place in Github that comes up with incredible stuff (including where Copilot was born) to talk to us about Copilot's next iteration after the chat experience, workspace!
Workspace is indeed that, a workspace for you and copilot to start working together, on github issues specifically, taking into context more than just 1 file, and breaking down the task into planning, iteration and human feedback.
It looks really slick, and per Idan, uses a LOT of tokens of gpt-4-turbo, and I've had a chance to get in there and play around.
They break down every task into a Specification that Copilot comes up with, and then you iteratively can work on until you get the required result, then into planning model, where you would see a whole plan, and then copilot will get to work and start iterating on your task.
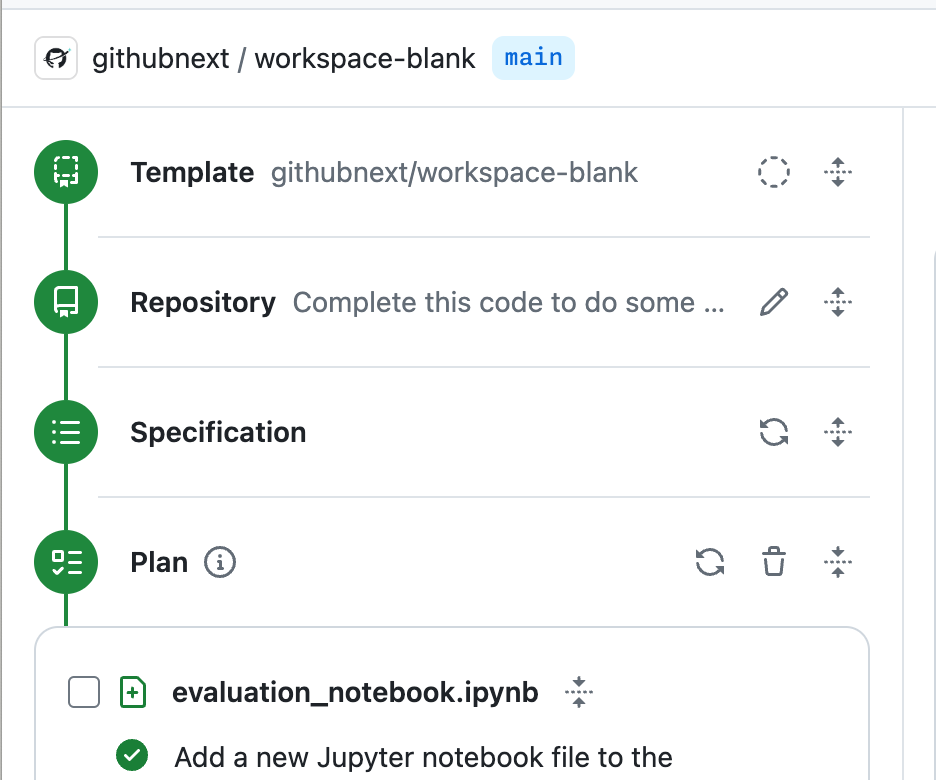
Does this remind you of anything? AGENTS you may yell in your head as you read these words, however, I recommend you listen to Idan in our chat on the pod, because his take on agents are, we don't want these tools to replace us, we want them to help us, and what is an agent anyway, this word is very overused. And I have to agree, given the insane valuations we've seen in agent startups like Cognition Labs with Devin.
I've taken Workspace for a spin, and asked it for a basic task to translate a repo documentation into Russian, a task I know LLMs are really good at, and it identified all the README files in the repo, and translated them beautifully, but then it didn't place those new translations into a separate folder like I asked, a case Idan admitted they didn't yet build for, and hey, this is why this is a Technical Preview, you just can't build an LLM based product behind the scenes and release it, you need feedback, and evaluations on your product from actual users!
You can see my whole session here, in this nice link they give to be able to share (and fork if you have access) a workspace
The integration into Github is quite amazing, there's now a text box everyone on Github that you can ask for changes to a repo in natural language + a Raycast extension that allows you to basically kickstart a whole repo using Copilot Workspace from anywhere

And here's the result inside a new workspace 👇

I will run this later and see if it actually worked, given that Idan also mentioned, that Copilot does NOT run the code it writes, but it does allow me to easily do so via GIthub Codespaces (a bit confusing of a naming between the two!) and spin up a machine super quick.
I strongly recommend to listen to Idan on the pod because he went into a lot of detail about additional features, where they are planning to take this in the future etc'
I can go on and on, but I need to play with all the amazing new tools and models we just got today (and also start editing the podcast it's almost 4PM and I have 2 hours to send it!) so with that, thank you for reading , and see you next time 🫡



