




Hey everyone, this is Alex and can you believe that we're almost done with Q1 2024? March 2024 was kind of crazy of course, so I'm of course excited to see what April brings (besides Weights & Biases conference in SF called Fully Connected, which I encourage you to attend and say Hi to me and the team!)

This week we have tons of exciting stuff on the leaderboards, say hello to the new best AI in the world Opus (+ some other surprises), in the open source we had new MoEs (one from Mosaic/Databricks folks, which tops the open source game, one from AI21 called Jamba that shows that a transformers alternative/hybrid can actually scale) and tiny MoE from Alibaba, as well as an incredible Emotion TTS from Hume.
I also had the pleasure to finally sit down with friend of the pod Tanishq Abraham and Paul Scotti from MedArc and chatted about MindEye 2, how they teach AI to read minds using diffusion models 🤯🧠👁️
TL;DR of all topics covered:
AI Leaderboard updates
Claude Opus is number 1 LLM on arena (and in the world)
Claude Haiku passes GPT4-0613
🔥 Starling 7B beta is the best Apache 2 model on LMsys, passing GPT3.5
Open Source LLMs
Databricks/Mosaic DBRX - a new top Open Access model (X, HF)
🔥 AI21 - Jamba 52B - Joint Attention Mamba MoE (Blog, HuggingFace)
Alibaba - Qwen1.5-MoE-A2.7B (Announcement, HF)
Starling - 7B that beats GPT3.5 on lmsys (HF)
Mistral 0.2 Base released (Announcement)
Big CO LLMs + APIs
Emad leaves stability 🥺
Apple rumors - Baidu, Gemini, Anthropic, who else? (X)
This weeks buzz
WandB Workshop in SF confirmed April 17 - LLM evaluations (sign up here)
Vision & Video
Voice & Audio
AI Art & Diffusion & 3D
Discussion
Deep dive into MindEye 2 with Tanishq & Paul from MedArc
Is narrow finetuning done-for with larger context + cheaper prices - debate
🥇🥈🥉Leaderboards updates from LMSys (Arena)
This weeks updates to the LMsys arena are significant. (Reminder in LMsys they use a mix of MT-Bench, LLM as an evaluation and user ELO scores where users play with these models and choose which answer they prefer)
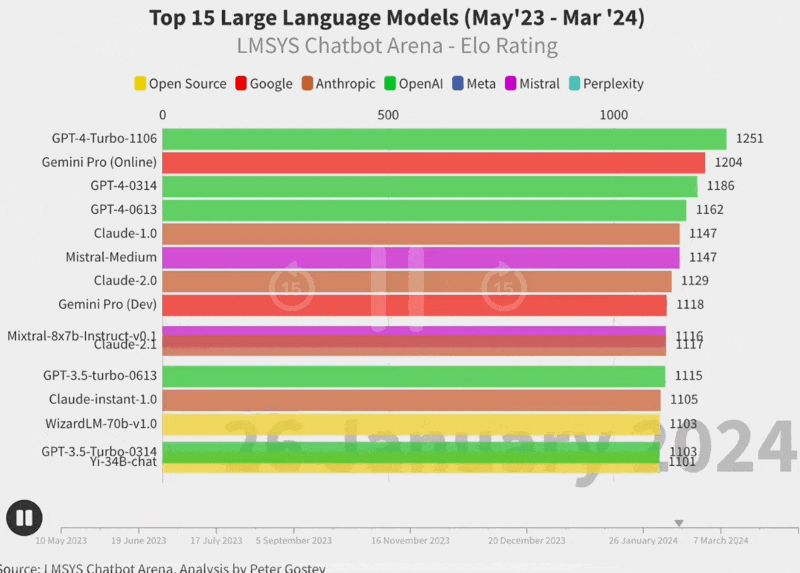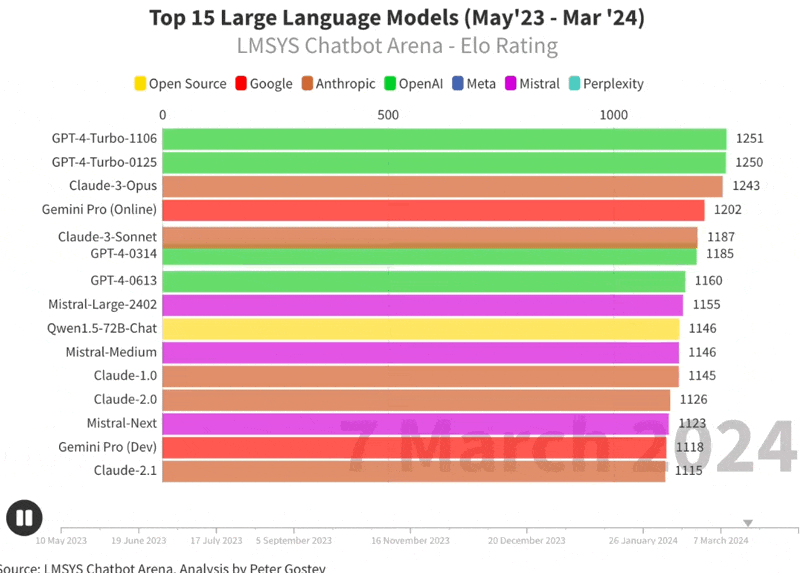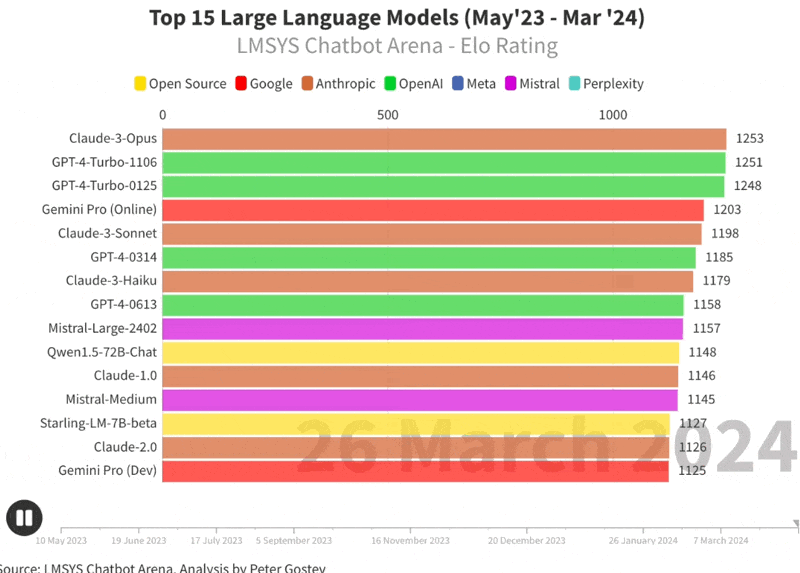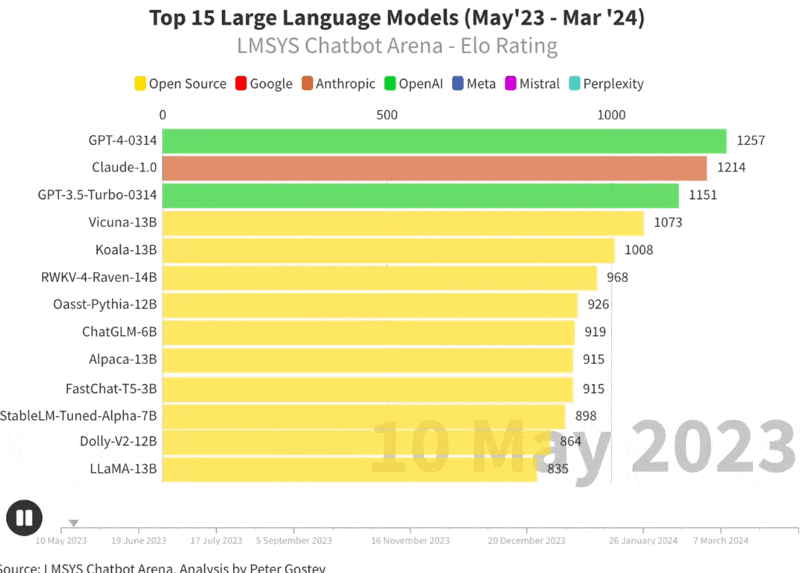
For the first time since the Lmsys arena launched, the top model is NOT GPT-4 based. It's now Claude's Opus, but that's not surprising if you used the model, what IS surprising is that Haiku, it's tiniest, fastest brother is now well positioned at number 6, beating a GPT4 version from the summer, Mistral Large and other models while being dirt cheap.
We also have an incredible show from the only Apache 2.0 licensed model in the top 15, Starling LM 7B beta, which is now 13th on the chart, with incredible finetune of a finetune (OpenChat) or Mistral 7B. 👏
Yes, you can now run a GPT3.5 beating model, on your mac, fully offline 👏 Incredible.
Open Source LLMs (Welcome to MoE's)

Mosaic/Databricks gave us DBRX 132B MoE - trained on 12T tokens (X, Blog, HF)
Absolutely crushing the previous records, Mosaic has released the top open access model (one you can download and run and finetune) in a while, beating LLama 70B, Grok-1 (314B) and pretty much every other non closed source model in the world not only on metrics and evals, but also on inference speed
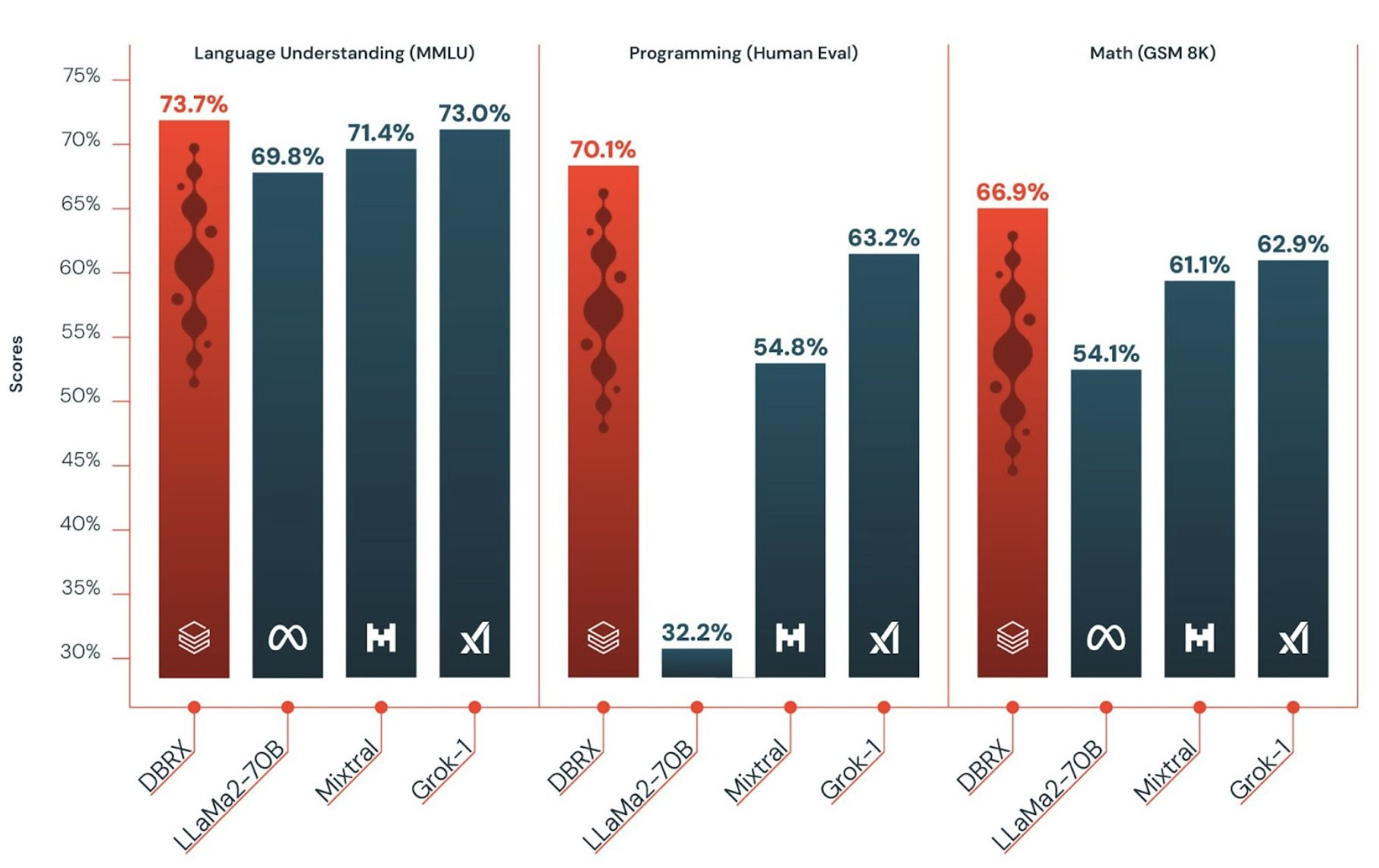
It uses a Mixture of Experts (MoE) architecture with 16 experts that each activate for different tokens. this allows it to have 36 billion actively parameters compared to 13 billion for Mixtral. DBRX has strong capabilities in math, code, and natural language understanding.
The real kicker is the size, It was pre-trained on 12 trillion tokens of text and code with a maximum context length of 32,000 tokens, which is just incredible, considering that LLama 2 was just 2T tokens. And the funny thing is, they call this DBRX-medium 👀 Wonder what large is all about.

Graph credit Awni Hannun from MLX (Source)
You can play with the DBRX here and you'll see that it is SUPER fast, not sure what Databricks magic they did there, or how much money they spent (ballpark of ~$10M) but it's truly an awesome model to see in the open access! 👏
AI21 releases JAMBA - a hybrid Transformer + Mamba 58B MoE (Blog, HF)
Oh don't I love #BreakingNews on the show! Just a few moments before ThursdAI, AI21 dropped this bombshell of a model, which is not quite the best around (see above) but has a few very interesting things going for it.

First, it's a hybrid architecture model, capturing the best of Transformers and Mamba architectures, and achieving incredible performance on the larger context window size (Transformers hardware requirements scale quadratically with attention/context window)

AI21 are the first to show (and take the bet) that hybrid architecture models actually scale well, and are performant (this model comes close to Mixtral MoE on many benchmarks) while also being significantly cost advantageous and faster on inference on longer context window. In fact they claim that Jamba is the only model in its size class that fits up to 140K context on a single GPU!
This is a massive effort and a very well received one, not only because this model is Apache 2.0 license (thank you AI21 👏) but also because this is now the longest context window model in the open weights (up to 256K) and we've yet to see the incredible amount of finetuning/optimizations that the open source community can do once they set their mind to it! (see Wing from Axolotl, add support for finetuning Jamba the same day it released)
Can't wait to see the benchmarks for this model once it's properly instruction fine-tuned.
Small MoE from Alibaba - Qwen 1.5 - MoE - A2.7B (Blog, HF)
What a week for Mixture of Experts models, we got an additional MoE from the awesome Qwen team, where they show that training a A2.7B (the full model is actually 14B but only 2.7B are activated at the same time) is cheaper, 75% reduction in training costs and 174% improvement in inference speed!

Also in open source:
Lisa beats LORA for the best parameter efficient training
📰 LISA is a new method for memory-efficient large language model fine-tuning presented in a Hugging Face paper
💪 LISA achieves better performance than LoRA with less time on models up to 70B parameters
🧠 Deep networks are better suited to LISA, providing more memory savings than shallow networks
💾 Gradient checkpointing greatly benefits LISA by only storing gradients for unfrozen layers
📈 LISA can fine-tune models with up to 7B parameters on a single 24GB GPU
🚀 Code implementation in LMFlow is very simple, only requiring 2 lines of code
🤔 LISA outperforms full parameter training in instruction following tasks
Big CO LLMs + APIs
Emad departs from Stability AI.
In a very surprising (perhaps unsurprising to some) move, Emad Mostaque, founder and ex-CEO of stability announces his departure, and focus on decentralized AI
For me personally (and I know countless others) we all started our love for Open Source AI with Stable Diffusion 1.4, downloading the weights, understanding that we can create AI on our machines, playing around with this. It wasn't easy, stability was sued to oblivion, I think LAION is still down from a lawsuit but we got tons of incredible Open Source from Stability, and tons of incredible people who work/worked there.
Big shoutout to Emad and very excited to see what he does next

Throwback to NEURIPS where Emad borrowed my GPU Poor hat and wore it ironically 😂 Promised me a stability hat but... I won't hold it against it him 🙂
This weeks Buzz (What I learned with WandB this week)
I'm so stoked about the workshop we're running before the annual Fully Connected conference in SF! Come hear about evaluations, better prompting with Claude, and tons of insights that we have to share in our workshop, and of course, join the main event on April 18 with the whole Weights & Biases crew!

Vision
Sora was given to artists, they created ... art
Here's a short by a company called ShyKids who got access to SORA alongside other artists, it's so incredibly human, and I love the way they used storytelling to overcome technological issues like lack of consistency between shots. Watch it and enjoy imagining a world where you could create something like this without living your living room.
This also shows that human creativity and art is still deep in the middle of all these creations, even with tools like SORA
MindEye 2.0 - faster fMRI-to-image
We had the awesome pleasure to have Tanishq Abraham and Paul Scotti, who recently released a significantly bette version of fMRI to Image model called MindEye 2.0, shortening the time it takes from 40 hours of data to just 1 hour of fMRI data. This is quite remarkable and I would encourage you to listen to the full interview that's coming out this Sunday on ThursdAI.

Voice
Hume announces EVI - their Empathic text to speech mode (Announcement, Demo)

This one is big folks, really was blown away (see my blind reaction below), Hume announced EVI, a text to speech generator that can reply with emotions! It's really something, and it has be seen to experience. This is in addition to Hume already having an understanding of emotions via voice/imagery, and the whole end to end conversation with an LLM that understands what I feel is quite novel and exciting!
The Fine-Tuning Disillusionment on X
Quite a few folks noticed a sort of disillusionment from finetuning coming from some prominent pro open source, pro fine-tuning accounts leading me to post this:

And we of course had to have a conversation about it, as well as Hamel Husain wrote this response blog called "Is Finetuning still valuable"
I'll let you listen to the conversation, but I will say, like with RAG, finetuning is a broad term that doesn't apply evenly across the whole field. For some narrow use-cases, it may simply be better/cheaper/faster to deliver value to users with using smaller cheaper but longer context models and just provide all the information/instructions to the model in the context window.
From the other side, we had data privacy concerns, RAG over a finetune model can absolutely be better than just a simple RAG, and just a LOT more considerations before we make this call that fine-tuning is not "valuable" for specific/narrow use-cases.
This is it for this week folks, another incredible week in AI, full of new models, exciting developments and deep conversations! See you next week 👏
Transcript Below:
[00:00:00] Alex Volkov: Hey, this is ThursdAI, I'm Alex Volkov, and just a little bit of housekeeping before the show. And what a great show we had today. This week started off slow with some, some news, but then quickly, quickly, many open source and open weights releases from Mosaic and from AI21 and from Alibaba. We're starting to pile on and at the end we had too many things to talk about as always.
[00:00:36] Alex Volkov: , I want to thank my co hosts Nisten Tahirai, LDJ, Jan Peleg, And today we also had Robert Scoble with a surprise appearance and helped me through the beginning. We also had Justin, Junyang, Lin from Alibaba and talk about the stuff that they released from Quen. And after the updates part, we also had two deeper conversations at the second part of this show.
[00:01:07] Alex Volkov: The first one was with Danish Matthew Abraham. and Paul Gotti from MedArc about their recent paper and work on MindEye2, which translates fMRI images using diffusion models into images. So fMRI signals into images, which is mind reading, basically, which is incredible. So a great conversation, and it's always fun to have Tanish on the pod.
[00:01:37] Alex Volkov: And the second conversation stemmed from a recent change in the narrative or a sentiment change in our respective feeds about fine tuning in the era of long context, very cheap models like Claude. And that conversation is also very interesting to listen to. One thing to highlight is this week we also saw the first time GPT 4 was toppled down from the Arena, and we now have the, a change in regime of the best AI possible, uh, which is quite, quite stark as a change, and a bunch of other very exciting and interesting things in the pod today.
[00:02:21] Alex Volkov: So, as a brief reminder, if you want to support the pod, the best way to do this is to share it with your friends and join our live recordings every ThursdAI on X. But if you can't sharing it with a friend, sharing a subscription from Substack, or subscribing, uh, to a pod platform of your choice is a great way to support this pod.
[00:02:48] Alex Volkov: With that, I give you March 28th, ThursdAI.
[00:02:52] Alex Volkov: Hello hello everyone, for the second time? we're trying this again, This is ThursdayAI, now you March 28th. My name is Alex Volkov. I'm an AI evangelist with Weights Biases. And for those of you who are live with us in the audience who heard this for the first time, apologies, we just had some technical issues and hopefully they're sorted now.
[00:03:21] Alex Volkov: And in order to make sure that they're sorted, I want to see that I can hear. Hey Robert Scoble joining us. And I usually join their spaces, but Robert is here every week as well. How are you, Robert? Robert.
[00:03:35] Robert Scoble: great. A lot of news flowing through the system. New
[00:03:39] Alex Volkov: we have, a lot of updates to do.
[00:03:43] Robert Scoble: photo editing techniques. I mean, the AI world is just hot and
[00:03:48] Robert Scoble: going.
[00:03:49] Alex Volkov: A week to week, we feel the excited Acceleration and I also want to say hi to Justin Justin is the core maintainer of the Qwen team. Qwen, we've talked about, and we're going to talk about today, because you guys have some breaking news. But also, you recently started a new thing called OpenDevon. I don't know if we have tons of updates there, but definitely folks who saw Devon, which we reported on, what a few weeks ago, I think? Time moves really fast in this AI world. I think, Justin, you posted something on X, and then it started the whole thing. So you want to give , two sentences about OpenDevon.
[00:04:21] Justin Lin: Yeah, sure. I launched the Open Devon project around two weeks ago because we just saw Devon. It is very popular. It is very impressive. And we just think that Whether we can build something with the open source community, work together, build an agent style, or do some research in this. So we have the project, and then a lot of people are coming in, including researchers and practitioners in the industry.
[00:04:46] Justin Lin: So we have a lot of people here. Now we are working generally good. Yeah You can see that we have a front end and back end and a basic agent system. So we are not far from an MVP So stay tuned
[00:05:01] Alex Volkov: Amazing. so definitely Justin when there's updates to update, you know where to come on Thursday. I, and but also you have like specific when updates that we're going to get to in the open source open source area So folks I'm going to run through everything that we have to cover and hopefully we'll get to everything.
[00:05:18] Alex Volkov: ,
[00:05:18] TL;DR - March 28th
[00:05:18] Alex Volkov: here's the TLDR or everything that's important in the world of AI that we're going to talk about for the next two hours, starting now. right So we have a leaderboard update, and I thought this is gonna be cool to just have a leaderboard update section because when big things are happening, on the leaderboards, and specifically I'm talking here about The lmsys Arena leaderboard the one that also does EmptyBench, which is, LLM, Judges, LLMs, but also multiple humans interact with these models and in two windows and then they calculate ELO scores, which correlates the best of the vibes evaluations that We all know and love and folks, Claude Opus is the number one LLM on Arena right now. Claude Appus, as the one that we've been talking about, I think, since week to week to week to week is
[00:06:05] Alex Volkov: now the number one LLM in the world and it's quite impressive, and honestly, in this instance, the arena was like, lagging behind all our vibes We talked about this already, we felt it on AXE and on LokonLama and all other places. so I think it's a big deal it's a big deal because for the first time since, I think forever it's clear to everyone that GPT4 was actually beat now not only that, Sonnet, which is their smaller version, also beats some GPT 4's version. and Haiku, their tiniest, super cheap version, 25 cents per million tokens. you literally can use Haiku the whole day, and at the end of the month, you get I don't know, 5 bucks. Haiku also passes one of the versions of GPT 4 for some of the vibes and Haiku is the distilled Opus version, so that kind of makes sense.
[00:06:53] Alex Volkov: But it's quite incredible that we had this upheaval and this change in leadership in the LMS arena, and I thought it's worth mentioning here before. So let's in the open source LLM stuff, we have a bunch of updates here. I think the hugest one yesterday, Databricks took over all of our feeds the Databricks bought this company called Mosaic, and we've talked about Mosaic multiple times before and now they're combined forces and for the past.
[00:07:17] Alex Volkov: year they've been working on something called DBRX, and now it's we got, in addition to the big company models that's taken over, so cloud Opus took over GPT 4, We now have a new open access model that takes over as the main lead. and they call this DPRX medium, which is funny. It's 132 billion parameter language model. and it's a mixture of experts with I think, 16 experts, and it's huge, and it beats Lama270b, it beats Mixtral, it beats Grock on at least MMLUE and human Evil scores and so it's really impressive to see, and we're gonna, we're gonna chat about DPRx as well and there's a bunch of stuff to cover there as well and Justin, I think you had a thread that we're gonna go through, and you had a great reaction.
[00:08:02] Alex Volkov: summary, so we're gonna cover that just today, what 30 minutes before this happened we have breaking news. I'm actually using breaking news here in the TLDR section because
[00:08:11] Alex Volkov: why [00:08:20] not?
[00:08:22] Alex Volkov: So AI21, a company from Israel releases something incredible. It's called Jamba. It's 52 billion parameters. but the kicker is it's not a just a Transformer It's a joint architecture from joint attention and Mamba. And we've talked about Mamba and we've talked about Hyena. Those are like state space models that they're trying to do a Competition to Transformers architecture with significantly better context understanding. and Jamba 52 looks quite incredible. It's also a mixture of experts. as you notice, we have a bunch of mixture of experts here. and It's it's 16 experts with two active generation It supports up to 256K context length and quite incredible. So we're going to talk about Jamba.
[00:09:03] Alex Volkov: We also have some breaking news So in the topic of breaking news Junyang, you guys also released something. you want to do the announcement yourself? It would be actually pretty cool.
[00:09:13] Justin Lin: Yeah, sure. Yeah just now we released a small MOE model which is called QWEN 1. 5 MOE with A2. 7B, which means we activate, uh, 2. 7 billion parameters. Its total parameter is, uh, 14 billion, but it actually activates around, uh, 2. 7 billion parameters
[00:09:33] Alex Volkov: thanks Justin for breaking this down a little bit. We're going to talk more about this in the open source as we get to this section I also want to mention that, in the news about the Databricks, the DBRX model, something else got lost and was released actually on Thursday last week.
[00:09:49] Alex Volkov: We also didn't cover this. Starling is now a 7 billion parameter model that beats GPT 3.5 on LMsys as Well so Starling is super cool and we're going to add a link to this and talk about Starling as Well Stability gave us A new stable code instruct and Stability has other news as well that we're going to cover and it's pretty cool.
[00:10:07] Alex Volkov: It's like a very small code instruct model that beats the Starchat, like I think 15b as well. So we got a few open source models. We also got a New method to Finetune LLMs, it's called Lisa if you guys know what LORA is, there's a paper called Lisa, a new method for memory efficient large language model Fine tuning.
[00:10:25] Alex Volkov: And I think this is it. Oh no, there's one tiny news in the open source as well mistral finally gave us Mistral 0. 2 base in a hackathon that they participated in with a bunch of folks. on the weekend, and there was a little bit of a confusion about this because we already had Mistral 0.
[00:10:43] Alex Volkov: 2 instruct model, and now they released this base model that many finetuners want the base model. so just worth an update there. In the big companies LLMs and APIs, I don't think We have tons of stuff besides, Cloud opus as we said, is the number one LLM in the world. The little bit of news there is that Emmad Mostak leaves stability AI and that's like worthwhile Mentioning because definitely Imad had a big effect, on my career because I started my whole thing with stable Diffusion 1. 4 release. and we also have some Apple rumors where as you guys remember, we've talked about Apple potentially having their own model generator, they have a bunch of Open source that they're working on, they have the MLX platform, we're seeing all these signs. and then, this week we had rumors that Apple is going to go. with Gemini, or sorry, last week, we had rumors that Apple is going to go with Gemini, this week, we had rumors that Apple is going to sign with Entropic, and then now Baidu, And also this affected the bunch of stuff. so it's unclear, but worth maybe mentioning the Apple rumors as well in this week's buzz, the corner where I talk about weights and biases, I already mentioned, But maybe I'll go a little bit in depth that we're in San Francisco on April 17th and 18th, and the workshop is getting filled up, and it's super cool to see, and I actually worked on the stuff that I'm going to show, and it's super exciting, and it covers pretty much a lot of the techniques, that we cover here on ThursdAI as well.
[00:12:05] Alex Volkov: In the vision and video category, This was a cool category as well, because Sora for the first time, the folks at Sora they gave Sora to artists and they released like a bunch of actual visual demos that look mind blowing. Specifically Airhead, i think was mind blowing. We're gonna cover this a little bit.
[00:12:21] Alex Volkov: If you guys remember Emo, the paper that wasn't released on any code that took One picture and made it sing and made it an animated character. Tencent released something close to that's called AnimPortrait. but Any portrait doesn't look as good as emo, But actually the weights are there.
[00:12:36] Alex Volkov: So you can now take one image and turn it into a talking avatar and the weights are actually open and you can use it and it's pretty cool. and in the vision and video, I put this vision on video as well, but MedArk released MindEye 2, and we actually Have a chat closer to the second hour with with yeah, with Tanishq and Paul from AdArc about MindEye 2, which is reading fMRI signals and turning them into images of what you saw, which is crazy. And I Think the big update from yesterday as Well from voice and audio category is that Hume, a company called Hume, demos something called EVI which is their empathetic voice analysis and generation model, which is crazy I posted a video about this yesterday on my feed. you talk to this model, it understands Your emotions. Apparently this is part of what Hume has on the platform. you can actually use this right now but now they already, they showed a 11 labs competitor, a text to speech model that actually can generate voice in multiple emotions. and it's pretty like stark to talk to it. and it answers sentence by sentence and it changes its emotion sentence from by sentence. and hopefully I'm going to get access to API very soon and play around with this. really worth talking about. Empathetic or empathic AIs in the world of like agentry and everybody talks about the, the
[00:13:53] Alex Volkov: AI therapist.
[00:13:54] Alex Volkov: So we're going to cover Hume as well. I think a very brief coverage in the AI art and diffusion Adobe Firefly had their like annual conference Firefly is a one year old and they added some stuff like structure reference and style transfer and one discussion at the end of the show IS narrow fine tuning done for for large, with larger contexts and cheaper prices for Haiku. we had the sentiment on our timelines, and I maybe participated in this a little bit, and so we had the sentiment and , I would love a discussion about Finetuning, because I do see quite A few prominent folks like moving away from this concept of Finetuning for specific knowledge stuff.
[00:14:32] Alex Volkov: Tasks, still yes but for knowledge, it looks like context windows the way they're evolving. They're going to move towards, potentially folks will just do RAG. So we're going to have a discussion about fine tuning for specific tasks, for narrow knowledge at the end there. and I think this is everything that We are going to talk about here. That's a lot. So hopefully we'll get to a bunch of it.
[00:14:51] Open Source -
[00:14:51] Alex Volkov: and I think we're going to start with our favorite, which is open source
[00:15:12] Alex Volkov: And while I was giving the TLDR a friend of the pod and frequent co host Yam Pelleg joined us. Yam, how are you?
[00:15:18] Yam Peleg: Hey, how are you doing?
[00:15:19] Alex Volkov: Good! I saw something that you were on your way to to visit. our friends at AI21. Is that still the
[00:15:24] Alex Volkov: awesome, awesome.
[00:15:25] Yam Peleg: 10 I'll be there in 10, 20 minutes.
[00:15:27] Alex Volkov: Oh, wow Okay. so we have 10, 20 minutes. and if you guys are there and you want to like hop on, you're also welcome so actually while you're here, I would love to hear from you we, We have two things to discuss. They're major in the open source and like a bunch of other stuff to cover I think the major like the thing that took over all our timelines is that Mosaic is back and Databricks, the huge company that does like a bunch of stuff. They noticed that Mosaic is doing very incredible things. and around, I don't know, six months ago, maybe almost a year ago, they Databricks acquired Mosaic. and Mosaic has been quiet since Then just a refresher for folks who haven't followed us for for longest time Mosaic released a model that was for I don't know, like three months, two months was like the best 7 billion parameter model called mpt and
[00:16:10] DBRX MoE 132B from Mosaic
[00:16:10] Alex Volkov: Mosaic almost a year ago, I think in May also broke the barrier of what we can consider a large context window so they announced a model with 64 or 72k context window and they were the first before cloud, before anybody else. and since then they've been quiet. and they have an inference platform, they have a training platform, they have a bunch of stuff that Databricks acquired. and yesterday they came out with a bang. and this bang is, they now released the top open access model, the BITS LLAMA, The BITS Mixtral, the BITS Grok1, The BITS all these things [00:16:40] And it's huge. It's a 132 billion parameter MOE that they've trained on I don't know why Seven
[00:16:49] Alex Volkov: 12,
[00:16:49] Yam Peleg: 12,
[00:16:50] Alex Volkov: jesus Christ, 12 trillion parameters.
[00:16:53] Alex Volkov: This is like a huge I don't think we've seen anything come close to this amount of training, Right
[00:16:59] Yam Peleg: Oh yeah, it's insane. I mean, the next one is six of Gemma, the next one we know. We don't know about Mistral, but the next one we know is six trillion of Gemma, and it's already nuts. So, but Yeah. It's a much larger model. I think the interesting thing to say is that it's the age of MOE now everyone is really seeing a mixture of experts and the important thing to, to pay attention to is that they are not entirely the same.
[00:17:27] Yam Peleg: So there is still exploration in terms of the architecture or of small tweaks to the MOE, how to do them, how to actually implement them better, what works better, what is more efficient and so on and so forth. That we just heard about Qwen MOE, which is also a little bit different than the others.
[00:17:44] Yam Peleg: So there is still exploration going on and just looking at what is coming out and everything turns out to be at the ballpark of Mistral and Mixtral just makes me more curious. Like, how did they do this? How everything is just on, on the same ballpark as them? How did they manage to train such powerful models?
[00:18:04] Yam Peleg: Both of them. And Yeah.
[00:18:06] Yam Peleg: I just want to say that because it's amazing to see.
[00:18:10] Alex Volkov: So, so just to highlight, and I think we've been highlighting this When Grok was released, we've been highlighting and now we're highlighting This as well. A significantly smaller model from Mixtral is still up there. It's still given the good fight, even though these models like twice and maybe three times as large sometimes and have been trained. So we don't know how much Mixtral was trained on right but Mixtral is still doing The good fight still after all this time which is quite incredible. and we keep mentioning this when Grok was released, we mentioned this. And now when this was released, we mentioned this as well.
[00:18:38] Alex Volkov: It's. What else should we talk about in DBRX? Because I think that obviously Databricks want to show off the platform. Nisten, go ahead. Welcome, by the way. You want to give us a comment about DBRX as well? Feel free.
[00:18:51] Nisten Tahiraj: Hey guys, sorry I'm late. I was stuck debugging C and it finally worked. I just lost a good time. I used DBRX yesterday. I was comparing it I used it in the LMTS arena. And then I opened the Twitter space and told people to use it. And now it just hit rate limits so you can't use it anymore. Yeah.
[00:19:11] Nisten Tahiraj: It was pretty good. I very briefly did some coding example. It felt better than than Code Llama to me. It wasn't as good as Cloud Opus stuff, but it did give me working gave me working bash scripts. So, yeah, in the very brief, short amount of time I use it, it seemed pretty good, so,
[00:19:31] Alex Volkov: Yep.
[00:19:32] Nisten Tahiraj: that's about it.
[00:19:33] Nisten Tahiraj: As for the Mistral and Mixtral question, so, I use Mistral large a lot, I use I use medium a lot, And the 70s, and the Frankensteins of the 70s, and they all start to feel the same, or incremental over each other. It's just the data. It's just the way they feed it. They feed this thing, and the way they raise it, I think it's it's all they're all raised the same way in the same data.
[00:20:03] Nisten Tahiraj: Yeah, the architecture makes some difference, but the one thing that you notice is that it doesn't get that much better with the much larger models. So it's just the data.
[00:20:20] Justin Lin: That's what I think it is.
[00:20:21] Alex Volkov: I want to ask Justin to also comment on this, because Justin, you had a thread that
[00:20:24] Alex Volkov: had a great coverage as well. What's your impressions from DBRX and kind of the size and the performance per size as well?
[00:20:32] Justin Lin: Yeah, the site is pretty large and it activates a lot of parameters. I remember it's 36 billion and the model architecture is generally fine. Actually, I talked to them a few times. around three months ago, last December introduced Quent2Dem and I accidentally saw it yesterday there are some common senses.
[00:20:57] Justin Lin: I think it is really good. They use TIC token tokenizer with the GPT2BP tokenizer. Recently I have been working with LLAMA tokenizer and the sentence piece tokenizer, well, makes me feel sick. Yeah. It's complicated. Yeah, but the GPT BPE tokenizer, because I have been working with BPE tokenizer years ago, so everything works great.
[00:21:22] Justin Lin: And we were just, for Qwen 1. 5, we just changed it from the implementation of TIP token to the GPT 2 BPE tokenizer by Hugging Face. It is simple to use. I think it's good to change the tokenizer. And it's also good to have the native chat ML format so that I think in the future people are going to use this chat ML format because the traditional chat formats like human assistant, there are a lot of risks in it.
[00:21:53] Justin Lin: So chat ML format is generally good. I think they have done a lot of great choices, but I'm not that, Impressed by their performance in the benchmark results, although benchmarks are not that important, but it's a good indicator. For example, when you look at its MMLU performance, I expect it to be, well, if you have trained it really good.
[00:22:19] Justin Lin: I haven't trained a 100 billion MOE model, but I expect it to be near 80. It is just 73 with 12 trillion tokens. I don't know if they repeat the training epics or they have diverse 12 trillion tokens. They didn't share the details, but I think it could be even better. I am relatively impressed by their coding performance, just as Nisten said.
[00:22:47] Justin Lin: The coding capability looks pretty well, but then I found that well?
[00:22:53] Justin Lin: DBRX Instruct because you can improve and instruct model to a really high level at human eval, but, it's hard for you to improve it for the base model. I'm not pretty sure maybe I need to try more, but it's generally a very good model.
[00:23:10] Alex Volkov: Yeah, absolutely. We got the new contender for the Open weights, open source. So the LLAMA folks are probably like thinking about, the release date it's very interesting what LLAMA will come out with. Notable that this is only an LLM. There's nothing like, there's no multimodality here. and the rumors are the LLAMA will hopefully will be multimodal. so whatever comparison folks do and something like like GPT 4, it's also notable that this is not multi modal yet, this is just text. One thing I will say is that they call this DBRX Medium which hints at potentially having a DBLX, DBRX Large or something, and also something that was hidden and they didn't give it, yet they retrained MPT.
[00:23:48] Alex Volkov: Yam, I think you commented on this and actually Matei Zaharia, the chief scientist there commented on, on, on your thread. They retrained the MPT7B, which was like for a while, the best 7 billion parameter model almost a year ago. and they said that it cost them like twice less to train the same model, something like this, which I thought it was notable as well.
[00:24:07] Alex Volkov: I don't know, Yam, if you want to, if you want to chime in on The yeah.
[00:24:10] Yam Peleg: The interesting thing here is that I mean, it's obvious to anyone in the field that you can, making the model much, much, much better if you get better data. So, what they basically say, what they basically show with actions is that if you have, you can even make the model even twice as better or twice as cheaper to train depending on how you look at it, just by making the data better.
[00:24:35] Yam Peleg: And my own comment on this is that at the moment, to the best of my knowledge Better, better data is something that is not quite defined. I mean, there is a lot of there is a lot of intuition, there are, I think big things when you look at broken data, it's broken. But it's really hard to define what exactly is better data apart [00:25:00] from a deduplication and all of the obvious.
[00:25:03] Yam Peleg: It's very hard to define what exactly is the influence of specific data on performance down the line. So, so it's really interesting to hear from people that have done this and made a model twice as better. What exactly did they do? I mean, because they probably are onto something quite big to get to these results.
[00:25:27] Yam Peleg: Again, it's amazing to see. I mean, it's just a year, maybe even less than a year of progress. I think MPT is from May. If I remember, so it's not even a year of progress and we already have like twice as better models and things are progressing
[00:25:42] Alex Volkov: Worth mentioning also that Databricks not only bought Mosaic, they bought like a bunch of startups, lilac, the friends from Lilac the, we had the folks from Lilac, IL and Daniel here on the pod. And we talked about how important data their data tools specifically is. and they've been a big thing in open source.
[00:25:58] Alex Volkov: All these folks from Databricks, they also highlight like how much Li help them understand their data. very much. so I'm really hoping that they're going to keep Lilac around and free to use as well one last thing that I want to say, it's also breaking news, happened two hours ago, the author of Megablocks, The training library from MOEs, Trevor gale I think he's in DeepMind, he has now given Databricks the mega Blocks library.
[00:26:23] Alex Volkov: So Databricks is also taking over and supporting the mega blocks training library for Moes. that is they say out for firms the next best library for Moes as well and there was a little bit of a chat where Arthur Mech from Mistro said, Hey, welcome to the party. And then somebody replied and said, you are welcome and then they showed the kind of the core contributors to the mega blocks library. And a lot of them are, folks from Databricks. and so now they've taken over this library.
[00:26:50] AI21 - JAMBA - hybrid Transformer/Mamba Architecture 52B MoE
[00:26:50] Alex Volkov: So yes MOE seems to be a big thing and now let's talk about the next hot MOE AI 21. The folks that I think the biggest like lab for AI in Israel, they released something called Jamba, which is a 52 billion parameter, MOE. and the interesting thing about Jamba is not that it's an MOE is that it's a Mamba and joint attention. so it's like a, it's a mamba transformer. Is that what it is? It's a combined architecture. We've talked about state space models a little bit here, and we actually talked with the author Eugene from RWKV, and we've mentioned Hyena from Together AI, and we mentioned Mamba before and all I remember that we mentioned is that those models, the Mamba models, still don't get the same kind of performance and now we're getting this like 52 billion parameter mixture of excerpt model that does. Quite impressive on some numbers and comes close to LLAMA70B even, which is quite Impressive MMLU is almost 70, 67%. I don't see a human eval score. I don't think they added this. But they Have quite impressive numbers across the board for something that's like a New architecture.
[00:27:52] Alex Volkov: 50 billion parameters with 12 active and what else is interesting here? The New architecture is very interesting. it supports up to 256. thousand context length, which is incredible. Like this Open model now Beats cloud 2 in just the context length, which is also incredible. Just to remind you Databricks, even though they released like a long context model before Databricks DBRX is 32, 32, 000.
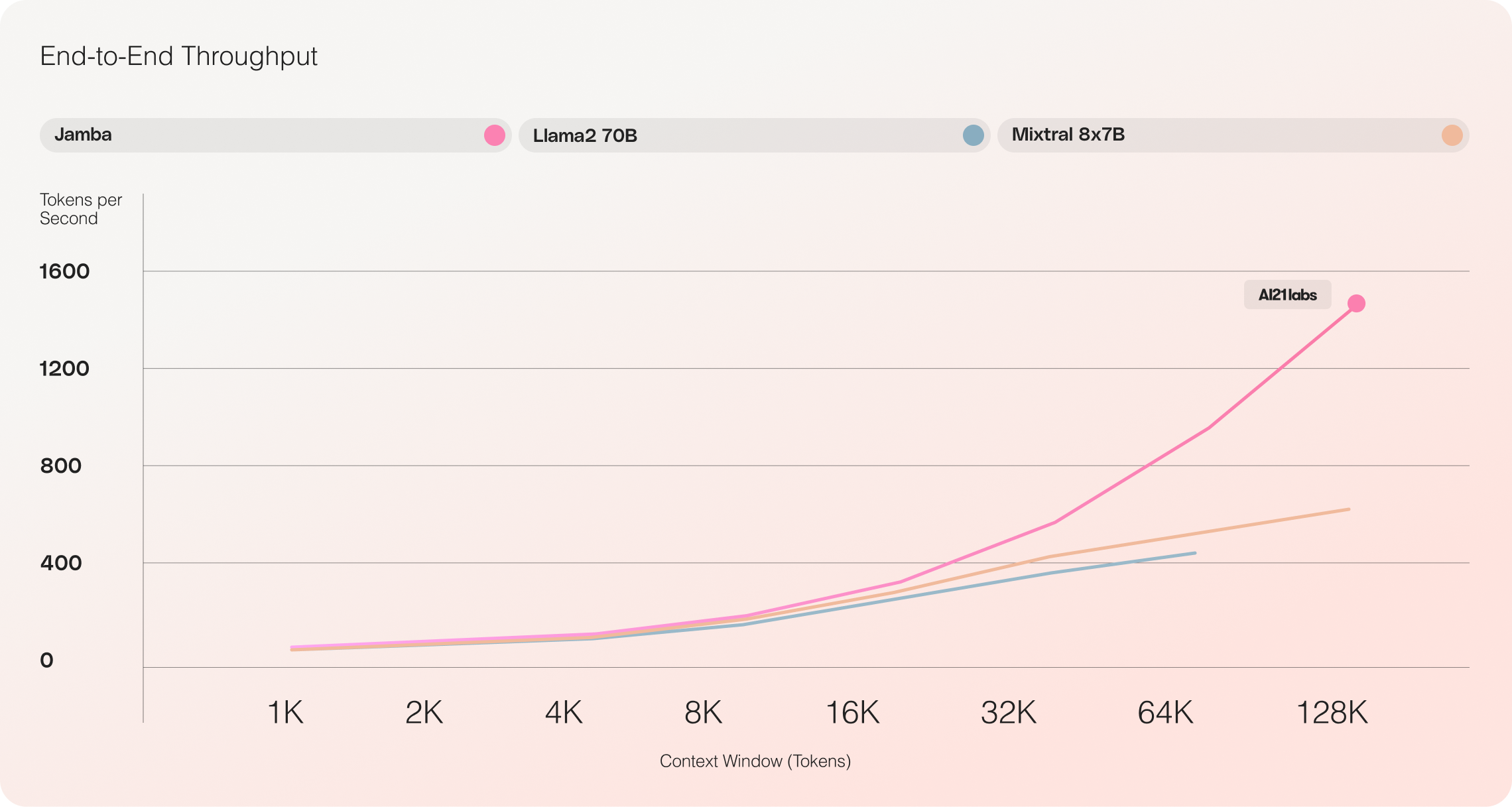
[00:28:15] Alex Volkov: This is 256. And not only does it support 256 because of its Unique architecture They can fit up to 140k contexts on a single A180 GB GPU. I know I'm saying a lot of numbers. Very fast, But if you guys remember, for those of you who frequent the pod, we've talked with folks from , the yarn scaling method. and the problem with the context window in Transformers is that the more context you have the more resources it basically takes in a very basic thing. And so the SSM models and the Mamba architecture, they specifically focus on lowering the requirements for long context. and this model gets three times as throughput on long context compared to Mistral.
[00:28:57] Alex Volkov: 8 times 7b, compared to Mixtral, basically. so very exciting, yeah, you wanna comment on this I know you're like almost there, meeting with the guys but Please give us the comments,
[00:29:07] Yam Peleg: I'm there. I'm there in five minutes, so I can maybe if time works towards favour, maybe I can even get you the people on the pod
[00:29:14] Alex Volkov: That'd be incredible.
[00:29:15] Yam Peleg: I'm just, yeah, what what is important here, in my opinion, is that first, I mean, absolutely amazing to see the results.
[00:29:23] Yam Peleg: But what was not known to this point is whether or not those types of models scale. to these sizes. We had smaller Mambas and they were, they looked really promising, but we were at the point where, okay, it looks promising. It looks like it could be at the same ballpark of transformers, but to test this out, someone need to just invest a lot of money into the compute and just see what the results they get.
[00:29:53] Yam Peleg: And it's a risk. You don't know what you're going to get if you're going to do it. And it turns out that you get a really good model at the same ballpark. Maybe slightly less performant as a transformer, but it is expectable. The thing the thing worth mentioning here is that Mamba the Mamba architecture is way more efficient in terms of context size.
[00:30:15] Yam Peleg: As you just said, transformers are quadratic in terms of complexity. When you increase the context. So you have if you have two tokens, you need you need four times that you can say the memory. And if you have four tokens, you need 16 and it just goes on and on and it just explodes, which is why context length is such a problem but Mamba scales much more friendly, memory friendly, you can say.
[00:30:39] Yam Peleg: So, but the thing is that you do pay with the performance of the model. So. What you, what people do is a hybrid between the two, so you can find some sweet spot where you don't just use so much memory and yet you don't have the performance degrade that bad. And I mean, yeah, it's a risk. At the end of the day, you need to train, training such a large model is a lot of money, is a lot of money in terms of compute.
[00:31:06] Yam Peleg: And they did it, released it in Apache 2, which is amazing for everyone to use. And proving for, to everyone that, all right, if you follow this recipe, you get this result. Now people can build on top of that and can train maybe even larger model or maybe even, maybe just use this model. I'm, I didn't try it yet, but I think it's an incredible thing to try because it's it's not the same as Mixtral.
[00:31:33] Yam Peleg: Mixtral is a little bit better, but it's at the same ballpark as Mixtral, but you get way more context there. At your home on a small GPU for cheap. It's amazing.
[00:31:41] Alex Volkov: and Mixtral specifically,
[00:31:43] Yam Peleg: potential.
[00:31:45] Alex Volkov: thanks Yamin, I just want to highlight that Mixtral Is this like amazing model that WE compare models like three times the size to it, and they barely beat Mixtral. We talked about this when Grok 1 was released, we now talked about this when DBRX was released with like
[00:31:57] Alex Volkov: 12 trillion parameters in data.
[00:32:00] Alex Volkov: Mixtral is this basically like the golden standard. We've always had this standard for like how well performing an open model could be and it has been for a while, the best open model that we have and now we're getting this like new architecture, completely new architecture, basically a bet on on would it even scale from Fox from AI21? and it comes close to Mistral, but it does 3x throughput on long contexts compared to mixtral. and it has 256 context window with, if you want to get this from mixtral, You can train it with yarn, you can do all these things, but then you won't be able to actually scale it. hosted because it's gonna cost you so much money because of The quadratic attention.
[00:32:33] Alex Volkov: And
[00:32:34] Alex Volkov: they specifically say, the only model of its size class, that fits up to 140, 000 context windows on a single GPU. Which is quite incredible. and obviously Apache 2 license is great. I don't know if they also released a bunch of stuff like training code and data stuff. So we're definitely going to keep you posted.
[00:32:50] Alex Volkov: And yam hopefully will ask all these questions. But the efficiency in speed where like the closer you get to 128 context, the faster the model kind of performs is also quite incredible. like it. Yeah, it's quite incredible. the graphs there, we're going to post it, everything in the show notes, but absolutely a great release from AI21. shout out AI21 folks and definitely give them our love there and specifically because of the Apache 2 license. Anything else I want to hear from maybe Justin, if you want to comment on the joint architecture anything that you have you guys play with [00:33:20] the joint attention and Mamba. have you what's your reaction to this?
[00:33:25] Justin Lin: Yeah, We are trying with members with very small architectures. We can reach similar performance to transformer, but we did not scale it to very large size, so we don't know what will happen.
[00:33:38] Alex Volkov: So just this is great and Apache 2, and we're very happy shout out to folks at the i21. Briefly let's cover the rest of the stuff that we have still to cover in the open source.
[00:33:47] Mistral base 0.2
[00:33:47] Alex Volkov: We'll briefly cover this in the TLDR. We'll start with Mistral Mistral 0. 2 base released. so for fine tuning, obviously, for folks who know it's better For fine tuning purposes to have a base model than the instruct model, because then you can mistral.
[00:33:59] Alex Volkov: 0. 2 base was released in Hackathon last week together with Cerebral Valley and some other friends in San Francisco.
[00:34:08] Alex Volkov: There was some confusion about it because we had Instruct 0. 2 before we had a model that said, based on mistral 0. 2 and was like very well performing, the 7 billion parameter one. and now there is the base model. and then somebody went and changed the base of the instruct model to this one versus the previous one but nevermind, they cleared that confusion up and we have this like base model.
[00:34:28] Alex Volkov: It's also like open source and it's great.
[00:34:30] Nisten Tahiraj: there is one thing here about the previous Mistral instruct that they released. That one has been trained for 32k context, and I used it as as a personal chatbot. I'm making it with just the base the base Mistral 7b, and I'm noticing it is much better at carrying forward a conversation.
[00:34:50] Nisten Tahiraj: So I, I think a lot of the fine tunes should probably switch and just rerun on the new Mr. Instruct especially the ones that are geared towards conversational stuff. Because again, Mr. Instruct is limited to eight K and more likely just, you should always just keep it under 4K to get accuracy.
[00:35:11] Nisten Tahiraj: So, that's one thing here. The new seven B performs much better at larger contexts and, and summarizing
[00:35:18] Starling 7B beta - top apache 2 LLM in the world
[00:35:18] Alex Volkov: One incredible news is Starling. And I think I think. Justin, you had both of you and and Yam as well, you guys talked about this. We're starting actually now is a 7 billion parameter model that beats GPT 3. 5 on LMC Serena, which is quite incredible, right?
[00:35:34] Alex Volkov: I think it's the first and the only 7 billion parameter model that beats GPT 3. 5 on like user preference. And it's, it was hidden in between the DBRX news
[00:35:42] Alex Volkov: but let me see if I can. Put this up here real quick. so this model was released, what, a week ago, a week and a day ago. It's
[00:35:48] Alex Volkov: What do we know from this?
[00:35:49] Yam Peleg: Yeah, I just want to say, and to go in five minutes, I just want to say about Starling this is the second model. So if you haven't tried yet the first one you definitely want to try. I know there are people that are skeptics about 7b models and saying that they are too small. Just give this one a try.
[00:36:10] Yam Peleg: Just give this one a chance. Trust me, just give this specific one a chance. It is an amazing model, seriously, it's an amazing model and it's just showing to everyone that there is a lot more to squeeze out. Scale works, absolutely, but there is a lot more to squeeze out besides scale. And I seriously can't wait for the same technique to be applied on a larger model just to see what we get to.
[00:36:35] Yam Peleg: Because it's an amazing result, seriously.
[00:36:37] Alex Volkov: Nisten, go ahead.
[00:36:40] Nisten Tahiraj: So. The model is is still based and it's actually based off of open chat 3.5. The one thing that their Raven, the Nexus Raven team does well is they had that nexus Raven 13 B model. And for some time that was the best function calling small model you can.
[00:36:59] Nisten Tahiraj: So, I haven't tried this one, but I highly suspect it's probably pretty good at function calling. I'm just looking at it right now, it is Mistral based, it's exactly based off of OpenChat 3. 5 from Alignment Lab, so they fine tuned on top of that, and yeah, I would highly recommend people to use it.
[00:37:20] Nisten Tahiraj: I've used the one that has been trained off of OpenChat a lot, and
[00:37:24] Alex Volkov: They did a bang up job there because this 7 billion parameter model now beats GPT 3. 5, beats CLOUD 2. 1, beats Mistral Next, and Gemini pro and CLOUD 2, like this is the 13th, based on LMsys at least, this is the 13th model, it's 7 billion parameters, it's Apache 2, this is the from Berkeley folks, This is the only Apache 2 licensed model on the LLM leaderboard in the first like top
[00:37:48] Alex Volkov: 20, I think, or top top 13. So it bigs, I don't know how it beats Mixtral. So anyway, yeah, StarLing is great. It looks great Try it, folks. Definitely worth mentioning. We're gonna run through some other updates because we still have a tons of stuff to cover and then we Have some guests here in the audience that want to join and talk about very interesting things
[00:38:05] LISA beats LORA for AI Finetuning
[00:38:05] Alex Volkov: I don't have a lot of information about Lisa specifically, but I will just mention that there's if you guys in the fine tuning area, you know that Laura and we have Laura in the diffusion? models area as well lower rank adaptations, so folks in the Diffusion world have been training LORES for a while, more than a year, and now there's a new paper dropped that's called a new method for memory efficient large language model fine tuning.
[00:38:27] Alex Volkov: I'll say this slowly a new method for memory efficient large language model fine tuning. So this is not for diffusion stuff this is for large language, it's called Lisa and achieves better performance than LoRa with less time on models up to 70 billion parameters, and yeah, the results look pretty cool for folks who do fine tuning, it's worth comparing this and I know for a while we had different methods for fine tuning like QLora, for example, different Lora, there was an attempt to figure out which one is the best and so Lisa now is a new contender with a paper out and I think code will follow up as well.
[00:38:59] Alex Volkov: Lisa can fine tune models up to 7 billion parameters on a single 24 gigabyte GPU. so you can fine tune 7 billion parameter Mistral, for example, on a 4090 with a 24 gigabyte GPU, which is pretty cool.
[00:39:13] Alex Volkov: And code implementation in LMFlow is very simple. so awesome to have this and we'll add this to the show notes for folks who actually do fine tunes. And it's gonna be awesome. so I think that covers all of the open source stuff, and we obviously spent almost an hour running through open source and I do want to move towards What is the next super exciting stuff that we have this week before we jump into a conversation.
[00:39:37] Hume EVI emotion based TTS
[00:39:37] Alex Volkov: Yes I want to move into Hume. I want to move into the voice, and audio category. This is an unusual jump between categories. we usually talk about big companies next but there's honestly not that much that happened there. So maybe we'll briefly cover it, but the thing that broke my mind, I'm going to paste this on top here. and hopefully you guys will just listen to me instead of going and watching This is that a company called Hume finally released something that many people have been very excited about. and they showed a few demos there and they finally released something. so Hume has been around for a while.
[00:40:08] Alex Volkov: Apparently they do emotion analysis very well and they actually have this product out there. you can upload the video and actually audio of yourself speaking and they will and understanding of what you're saying. of your emotions and intonations, which is pretty cool. and we know that's a piece that's missing from multimodal LLMs, right? Okay, so Hume, they already had a platform for emotions understanding, and yesterday Hume released their demo of an emotional TTS, a text to speech model that not only speaks This text position actually replies with emotion. and combined with the previous system. that they had that they can understand your emotion, as you can hear, I'm talking about this I was a little bit sad when Hamel had to drop, but now I'm very excited again to talk to you about Hume. so they actually have a running analysis of this voice as it runs. and they understand what kind of like where you are in the emotion scale, which is, first of all, exciting to see on yourself. Second of all, it's like very alarming. Their understanding of emotions, whether or not it's like precise enough to tell the truth, for example. and the text to speech of theirs that generates emotion based text is quite something. I've never seen anything close to it before the only thing that came close to me is that if you guys remember, we talked about 11 labs have style transfer thing where you can actually talk and they would take an AI voice and basically dub you but with the same emotion. So, that was the only thing that came close to what I heard yesterday from Hume. so hume has this model that's gonna be out in I think they said April? [00:41:40] that you'd be able as a developer to assign what emotion it will answer with. and together with the first part, which is a voice emotion understanding, like the text to speech understanding, they now have a speech to text with emotion. the whole end to end feeling is like nothing I've ever experienced and Robert I think I saw you first repost about this So I want to hear if like you play with the demo and like what your thoughts about this Because I was blown away and I will definitely want to hear about What do you think about this?
[00:42:14] Robert Scoble: blown away too. They you nailed it. It lets AI understand your emotion and build a much more human interaction with AI. The one problem is, I believe it's 7 an hour or something like that, so it's fairly expensive to integrate, but, for people who are building new kinds of applications that are going to have to integrate with human beings, I think it's very well done. You should look at it.
[00:42:41] Alex Volkov: Absolutely and definitely for folks who have the Uncanny Valley in different, LLMs that, reading for a long time is not the same. Is not quite the same I think we're gonna see some more emotionality in many of these, demos, and it's gonna be very exciting, together with the fact that recently there has been like this video of basically HeyGen the deepfake company that translates your lips and people were saying, Hey, this is like a fully end to end AI and we're so doomed all of these kind of AI generated voices, they still use 11 labs so I got to think that 11 labs is not going to be like that much behind and we'll start Working on some emotion like output as well but I would definitely add the link to this, and actually the video of me testing this out Hume, in in the show notes, and more than welcome for you guys to try this as well.
[00:43:27] Alex Volkov: I think the demo is demo, oh huma. ai. They actually have a chatbot on the website? hume. ai, where you can talk to the chatbot in your voice, and answers with voice as well but the full demo is more mind blowing. They understand your emotionality, they understand the emotionality of they then translate the emotionality into the actual context. and when the model talks back at you and when you say something like when you try to be when you try to fake it, and you yell, but you say, I'm so happy the model says, Hey, you look a little bit conflicted. So actually understand like what you're saying and what your meaning or basically the way you say it is different.
[00:44:00] Alex Volkov: So they actually build this understanding into the demo, which is super cool to play with. Yeah, so hume definitely worth checking out. I think that next in the voice and audio, I think that basically that's it that we had to cover but a similar area in AI creation is vision and video.
[00:44:15] SORA examples from filmmakers
[00:44:15] Alex Volkov: And this week we had oh my God the beginning of this week was like all excited about how to how the world of entertainment will look and the reason is because OpenAI took Sora, I'm hoping by this point that Sora is needs no introduction at this point right Sora is OpenAI's text to video model, and it's leagues above everything else that we saw in the world before this and it blew our creative minds, and keeps blowing some people's minds on TikTok. and OpenAI gave access to Sora, to a few creators content creators not Hollywood Apparently they're on the way to Hollywood right now and to talk with folks, But they gave it to a few filmmakers in in the like independent world I think a few Companies from Toronto and they finally showed us demos of what.
[00:45:03] Alex Volkov: Instead of The developers in OpenAI, and some prompts that they do with Sora, what an actual studio can do with some creativity and it looks like they also hired an artist in residence for OpenAI as well and wow my mind was definitely blown. the there was one short video that looked like something that I would, I would have seen in Sundance festival. It's called Airhead from from Toronto based. film
[00:45:28] Alex Volkov: creator called ShyKids, and I'm gonna add this to the show notes because this definitely, at least for me, was the most viral thing that I saw. And, I Absolutely loved it. It was, it felt very human it felt incredible. It's this very short story about something, somebody with a balloon instead of his head and the way they tell the story they kind of work around the technical limitations, which we all know, right if you generate two videos in Sora, the first the character persistence between those two videos will Not be there. And that's a big problem with every video generation. But this one, they worked around this because they told the story of this air balloon guy and his head throughout their life So like the character consistency isn't really required there. And I just really love that like actual storytellers can work around the technology to create something that feels so good Obviously the audio there was amazing and the production and the storytelling, everything. So. I think everybody saw it at this point, but if you haven't airhead from shy kids is quite incredible.
[00:46:27] Tencent AniPortrait - Animated Avatars
[00:46:27] . Okay. , I want to talk about Tencent released something called AniPortrait any with N a N I like animated portrait and it's generating photorealistic animated avatars. and if you guys remember Emo, we've talked about this before Emo was quite incredible to me. the examples that Imo showed were pretty much the same level, the same jumping capability in the way that Sora showed the previous image to video generations, Imo showed to kind of Image to animated character and
[00:46:56] Alex Volkov: was incredible.
[00:46:56] Alex Volkov: Like lips moved and eyes and consistency was there. So, the problem with Emo is that they haven't released the code And I think for now Emo is the highest like AI GitHub repo with the highest number of stars with no code. I think it's like 25, 000 stars or something. Everybody's waiting for Emo and haven't dropped.
[00:47:15] Alex Volkov: And when I say everyone, I necessarily mean the kind of the waifu creator world who would love, nothing more than just generate an image in stable diffusion something and then animated this with some, let's say emotional voice from the human thing, that we just mentioned. but the second best one for now is AnyPortrait. and actually the code was dropped. and the kind of the lips movement is great And the eyes, it's not close to emo, but it's really good compared to WAV to leap on different areas and if you ever built like an animated character AI stuff, you'll know that, the open source options.
[00:47:49] Alex Volkov: were not great the closed source options like HeyGen and different like labs like DID and Synthetic, I think, I don't remember the name. They were okay. They were great. but the open source options were not there. So any portrait right now is the best version We have it dropped yesterday. if you are doing any kind of like character animation, give any portrait a try and let us know, I'm definitely gonna play with this.
[00:48:12] Alex Volkov: Definitely gonna play
[00:48:12] Alex Volkov: with this. I think we've covered most of the stuff that we wanted to cover besides weights and biases stuff and NB companies.
[00:48:18] MindEye 2 - Interview with Tanishq and Paul from MedArc
[00:48:18] Alex Volkov: But now I am very excited to bring two friends here one friend of the pod and for a long time and now a new one, Paul Scotti and you guys here to talk to us about MindEye. to the second version. so I will just like briefly do an introduction that MindEye came around the summer I think I want to say, and we covered this because in my head everything was like multimodal, multimodal. When were we going to get multimodal? This was before vision happened. and one of the craziest multimodalities that we expected was something like a fMRI signal, like brain signals. and then you guys raised MindEye, which was like, mind blowing. and so I would love to hear about the history of like how Med Ark started like doing brain interpretation. and then let's talk about MindEye 2 and what's exciting about this recent release, but feel free please to unmute Tanishq and then Paul and introduce yourself briefly.
[00:49:08] Tanishq Abraham: Yeah Yeah, I'll just provide a quick background and summary and then I'll let Paul talk about MindEye 2 in more detail. But, yeah, basically, I'm introducing myself again. I'm Tanish I'm Tanish. Work at Stability ai and I also am the founder of MedARC and I lead MedARC, which is a medical ai open source medical ai research organization.
[00:49:30] Tanishq Abraham: And, we mostly are focused on trading foundation models for medicine. And So we do have a kind of a kind of research in neuroscience and ai and combining AI and neuroscience, which. which is what Paul is leading at MedArc. But yeah, like we started I guess looking into this sort of neuroscience AI research for quite some time actually.
[00:49:54] Tanishq Abraham: Actually, I think even before I officially started MedArc when I was organizing [00:50:00] some open source medical AI projects, this was one of the projects that I actually had started, I think, back in summer of 2022. And I think, just generally, the idea was that there's, the idea was we were working on this fMRI to image reconstruction problem, which is basically the idea that we take the, we have a person that is looking at some images and we take their fMRI signal.
[00:50:25] Tanishq Abraham: and we want to use AI to reconstruct the image that the person was looking at just in the fMRI signal. So it's the sort of mind reading kind of problem that we're working on. And I think up, back in 2022 when we started working on this, at first no the techniques that people were using were quite basic and, I think the sort of neuroscience community was quite behind in what they were, in what they were using.
[00:50:48] Tanishq Abraham: So I think we were pretty excited about the possibility of utilizing some of the latest techniques in generative AI to advance this field. And yeah, first did I start this project and there were a couple volunteers that were helping out, but luckily Paul had also discovered that we were working on this and he, he joined this project and really spearheaded this kind of neuroscience AI initiative that we've been having at MedArc.
[00:51:14] Tanishq Abraham: And yeah, that resulted in MindEye, which we released in April. I think May of last year and and then we've been continuing to work on improving those results and that has now resulted in MindEye 2. And we also have some other sorts of projects in the neuroscience AI area, like training foundation models for fMRI and we're exploring some other ideas as well.
[00:51:37] Tanishq Abraham: But yeah, I think with MindEye one, we had a very simple sort of pipeline of. of taking the fMRI signal and converting them to clip image embeddings and and then basically re generating an image from the clip image embeddings, and that worked quite well and The only difference, the only issue with that was that it required a lot of data, and we have developed this new pipeline, which Paul will talk more about, that requires less data, is more efficient, and is giving also better results with better, sort of, image generation models, so, for example, we're using SDXL for this MindEye 2 model so, yeah, I think I'll let Paul talk more about the motivation and how MindEye 2 works.
[00:52:18] Alex Volkov: So I just like before we get to Paul thank you for joining guys. first of all, I just want to highlight how insane to me is the thing that you guys talking about where many people like think that, oh yeah, generative AI generates images. Yeah. And generate some texts. And You guys like translating brain signals into what people actually saw. and I think I saw a separate from You also an attempt to understand fMRI. So Paul, maybe feel free to introduce yourself and maybe also cover prior work in this area. I would love to know, if this is something you guys came up with or something You saw and improved on, I would love to know as well.
[00:52:52] Alex Volkov: That's
[00:52:57] Paul Scotti: This, yeah, like Tanisha was saying, we started out working on this together over Discord back in 2022. And at the time, there weren't really any good results doing reconstruction of images from, looking at images inside of an MRI machine. And what really spurred several new papers in this field is open sourced image generation models like stable diffusion clip models, and also importantly a good data set of people looking at images in an MRI machine.
[00:53:34] Paul Scotti: It's a very difficult dataset to collect because we're talking about eight people who spent 30 to 40 hours inside of this MRI machine looking at images one at a time for three seconds each.
[00:53:48] Paul Scotti: So it's, it really was the culmination of dataset and new models that allowed this to work. For the MindEye 2 stuff specifically, We focused on trying to get good results using only one hour instead of 40 hours of data.
[00:54:07] Paul Scotti: And this is pretty important because if you're trying to do these machine learning techniques on new subjects, new data sets, maybe apply to the clinical setting, you aren't going to be collecting dozens of hours of data, especially for clinical populations. It's just too expensive and you're taking up their valuable time.
[00:54:29] Paul Scotti: So we, there's a lot of papers now that have been focusing on fRIDA image, just because it's a cool topic. So our paper shows, state of the art results, but specifically in the one hour domain, We show that you can pre train a model on other people's brains in order to have a better starting point to fine tune the model on a separate, held out subject's brain.
[00:54:54] Paul Scotti: And for people who aren't maybe as familiar with neuroimaging stuff or how the brain is, how the brain works, your brain is wired very differently to other people. It's not like there's the same. part of the brain that always handles, what happens when you look at a picture of an elephant or something.
[00:55:15] Paul Scotti: We have different shapes and sizes of brains. We have different patterns of activity that lead to how we perceive vision. And the reconstructions that we're talking about are not as simple as just, was it a dog that you were looking at? Was it an elephant? So you need some sort of way to align all these different people's brains and their different visual representations into a shared latent space so that you can then get the rest of this pipeline with the, diffusion models and MLPs to work and actually have that be informative to generalize from, my brain to your brain.
[00:55:53] Alex Volkov: so incredible that I have, so many questions, Paul, but I will start with maybe, The differences between brains that something that you said, I also want to talk about, the visual cortex and how that thing happens, but I would be remiss if I don't mention at least that you guys are now talking about MindEye at the same time we're we got the first the first Neuralink implanted human showing that he can control basically a machine with their, with his brain with implants.
[00:56:19] Alex Volkov: But you guys are completely non invasive kind of understanding of these brain signals. But to an extent and Neuralink also is some sort of like an invasive understanding of brain signals and transforming them into actions versus something that they see. but , they mentioned that they're working on sight fixing.
[00:56:34] Alex Volkov: As well.
[00:56:34] Alex Volkov: Could you maybe give us a brief understanding of fMRI, how that translates into the signals from visual contact? How do, how does this machine know what I see and how then you are able to then use diffusion models to recreate what I see.
[00:56:48] Alex Volkov: Could you give us like a little bit more of a, what's, where's the magic here?
[00:56:52] Paul Scotti: Yeah, so, fMRI right now is the best method if we're talking about non invasive tech. If you have electrodes on someone's brain, obviously that's going to give you a much better signal. But it's also not viable to do that for most projects and for applying it to clinical settings and new research and everything.
[00:57:14] Paul Scotti: So we used fMRI, which is a bit crude in the sense that you have these people that are needing to make as little motion as possible. The MRI machine is basically tracking blood flow. So when you look at an image of something, the neurons in your brain that correspond to representing that image are active and they require more oxygenation to help with how they've been used in relation to the other voxels in the brain that are not as relevant for activating to that image.
[00:57:50] Paul Scotti: Basically, you're tracking this kind of slow moving time course of blood flow that corresponds to where in the brain is active. And then you are have this 3D volume of the brain and the corresponding blood oxygenation changes for every given 3D cube or voxel in the brain. And what we did is we took all the voxels corresponding to the visual cortex, The back of the brain that seems to be active when you look at stuff, and we feed that through this neural network.[00:58:20]
[00:58:20] Paul Scotti: And specifically, we feed that through MLPs and a diffusion prior and all this stuff to give us a model that can translate from brain space to clip space. where CLIP is, these models that are contrastively trained typically with text and images So that you can have this multimodal space where you have the ability to align a given image caption with the image itself.
[00:58:48] Paul Scotti: This you can think of as a third space, a new modality for CLIP that's the brain. So we use the same sort of technique of contrastively mapping the brain and its paired samples corresponding to the images into the CLIP space. And then there are so called unclip models, also sometimes called image variations models, that allow you to undo clip space back to pixel space.
[00:59:13] Paul Scotti: And so that's how we actually get the image reconstructions at the end, where the model only gets the brain activities and has to generate the corresponding image.
[00:59:23] Alex Volkov: So I'm still like picking up my job from the floor here, because what you're basically saying is this, the same architecture that is able to Drop cats by understanding the word cat and like a pool, the concept of a cat from latent space. Now you've able to generalize and add multimodality, which is like brain understanding of a cat or like what happens in the brainflow in the visual cortex when somebody looks at a cat and you're basically placing it in the same latent space neighborhood. and now you're able to reconstruct an image based on this. I'm still like trying to obviously wrap my head around this but I would love to maybe ask.
[01:00:01] Alex Volkov: the Tanishq as well. , could you talk about MindEye 2 and specifically the improvements that you did, and how you achieved them and what they are in fact and then how it applies to the clinical field,
[01:00:11] Tanishq Abraham: Right. I mean, so with MindEye 2 like Paul mentioned, our main focus was what can we do to basically use less data when it comes to a new subject. So if you have a, you have a new person that you want to, read their mind, you want to do this reconstruction, we don't want them to have to do 40 hours of scanning because with MindEye 1, you'd have to basically train a separate model for every single subject.
[01:00:34] Tanishq Abraham: So it was like a completely separate model for each subject. So if you had a new subject, you would have to get 40 hours of scanning with that new subject to create a new model. So
[01:00:42] Tanishq Abraham: the idea with MindEye 2 is that we have,
[01:00:45] Tanishq Abraham: We, we train,
[01:00:46] Tanishq Abraham: A model on all of
[01:00:48] Tanishq Abraham: The previous subjects.
[01:00:50] Tanishq Abraham: So for example, we have
[01:00:51] Tanishq Abraham: Eight subjects in the data set,
[01:00:53] Tanishq Abraham: You train on seven of the subjects,
[01:00:56] Tanishq Abraham: And
[01:00:56] Tanishq Abraham: You, and so it's training on all seven subjects and then you are able to then fine tune. that model on a new subject, but you only need one hour of data.
[01:01:06] Paul Scotti: So basically for any new subject, now you only need one hour of data.
[01:01:09] Paul Scotti: So the way that works is that basically we have adapter layers, which is just like these sorts of like linear layers that you have that for each each subject. So, you basically have this sort of layer that is you have the fMRI data from a new subject, but you do have this like linear adapter layer that is basically converting it to again like a kind of a shared space for all the fMRI data.
[01:01:32] Paul Scotti: So then basically when you are taking a new patient or a new subject, all you have to do is fine tune this linear adapter for that new subject. And, yeah, so that's the general idea with. What we try to do there with that way, we only have to use only one hour of data.
[01:01:49] Paul Scotti: But then on top of that, of course, we have various modifications to the entire pipeline that also just gives you better results overall. So for example instead of in the past, when we were taking our clip image embedding and then reconstructing We used a different model called Versatile Diffusion, but here what we did is we actually took SDXL, and the problem with a model like SDXL, for example, is that it only takes in clip text embeddings.
[01:02:19] Paul Scotti: So because, these models are text to image models, so oftentimes a lot of these models are going to be taking, they're taking like clip text embeddings, and that's what they're conditioned on. But here, what we did is we fine tuned SDXL to instead be conditioned on clip image embeddings, and so we have this SDXL unclipped model, that's what we call it and so that, is one, for example, improvement that we use this model instead of the previous model, which was versatile diffusion.
[01:02:42] Paul Scotti: There are a few other like different improvements to the architecture, to the conditioning that we have. I think Paul can again, talk more about that, but I think the main kind of innovation Apart from, this is just the general improvements. I think the main innovation is the use of this sort of adapters for?
[01:02:59] Paul Scotti: Each subject that allows us to then fine tune for new subjects with only one hour of data. and
[01:03:05] Paul Scotti: Paul, I feel free to add any other details as well, Paul.
[01:03:08] Alex Volkov: Yeah. I want to follow up with Paul specifically around you're moving from 40 hours to let's say one hour, one hour still in this like fMRI, basically a coffin, right? like it's a huge machine, like it's super incredibly expensive so the data, the it's not Maybe I'm actually going to presume here, but maybe please correct me if I'm wrong.
[01:03:26] Alex Volkov: Unlike other areas where like synthetic data is now a thing where people like actually improve Have you guys played with synthetic data at all? is that something that you've tried and seems helpful? Or is this like something that actually humans need to sit in those machines and provide some data for
[01:03:40] Alex Volkov: you?
[01:03:42] Paul Scotti: Yeah, I mean, to an extent you need real data to validate things, but we have done augmentation to, which is like synthetic data. to make the models more. Robust, right? So like we've played around with, averaging samples from different images together, doing mix up kind of data augmentations to make the pipeline work better and for some other projects that we're doing that might be involving more synthetic approaches.
[01:04:16] Alex Volkov: Awesome. And so I think I'll end with this one last question is the very famous quote from Jurassic Park is that scientists were preoccupied thinking if they could, they didn't stop thinking if they should, but not in this area. I want to ask you like specifically, what are the some of the applications that you see for something like this when you guys get to MindEye 3 or 4 or 5 and it's maybe with different signals, maybe with EEG, I don't know, what are some of the implications that you see of like being able to read somebody's mind and what can it help?
[01:04:47] Alex Volkov: with?
[01:04:49] Paul Scotti: Yeah. So, you want, yeah, you can go ahead, Paul. Okay. You, yeah. Okay. So, like there's just so many different directions, right? Like you've got right now we're focusing on perception, but the more interesting thing would be mental imagery, like dream reading applying these models to real time so that you can reconstruct while they're still in the scanner that allows you to do cool new experimental designs as well.
[01:05:15] Paul Scotti: You could look at memory, try to reconstruct someone's memory for something. Yeah, Dinesh, maybe you can add on to that. Yeah. So,
[01:05:26] Tanishq Abraham: the thing is, what's really interesting is that a lot of the sort of,
[01:05:28] Tanishq Abraham: Pathways and activity for,
[01:05:30] Tanishq Abraham: Perceiving an image that you're looking at right now, a lot of them are similar for
[01:05:33] Tanishq Abraham: Imagining and dreams and these sorts of things.
[01:05:35] Tanishq Abraham: So of course there are some differences, but that's the thing is that a lot of these pipelines should hopefully be,
[01:05:41] Tanishq Abraham: Generalizable to some of these other applications like,
[01:05:44] Tanishq Abraham: Reconstructing what you're imagining and things like this.
[01:05:46] Tanishq Abraham: And in fact, there are there is some work in this already.
[01:05:49] Tanishq Abraham: There's like a paper from one of our collaborators that may be coming out in a couple months that is exploring this. So it's actually not just limited to. what you're looking at, but you know, more generally as well. But I think just even with this technology that we have with what you're looking at and reconstructing that, I think there's lots of interesting like clinical applications.
[01:06:08] Tanishq Abraham: For example maybe, the way you perceive is associated with your mental condition. So maybe it could be used for different biomarkers, different diagnostic applications. So for example, if you're depressed, for example, maybe you are going to perceive an image.
[01:06:21] Tanishq Abraham: in a more dull fashion, for example. And so I think there's a lot you can learn about how the brain works by looking at how people are perceiving it perceiving images, and also utilizing that for potential clinical and diagnostic applications. So that's also an area that is completely underexplored.
[01:06:39] Tanishq Abraham: [01:06:40] And it's been also pretty much underexplored because people weren't able to get such high quality reconstructions before with, I think the introduction of MindEye 1 was like one of the first times that we were able to get such high quality reconstructions. And of course, even then, we had to use the 40 hours of data to do that.
[01:06:56] Tanishq Abraham: And now we're actually bringing it down to one hour of data. And with further work, we may be able to bring out, bring it down even further. So now we're actually potentially having it's actually, potentially possible to use this for actual clinical applications. And so that is what I'm most excited in the near term in potential diagnostic applications or for potential neuroscience research applications.
[01:07:17] Tanishq Abraham: And then of course, long term vision is trying to apply this for, looking at imagination, dreams, memory. That's, I think, the long term vision and interest there. So that's at least how I see this field progressing and what I'm interested in personally. One, maybe just one more quick nuance is that with the shared subject stuff, it's not limited necessarily to reconstructing images.
[01:07:41] Tanishq Abraham: So typically, machine learning approaches, you need a lot of data, but data takes a lot of time in the MRI machine. And so this approach of using other people's brains as a better starting point allows clinicians to potentially use more complicated ML pipelines for investigating the brain, maybe even outside of image reconstructions, in a way that's feasible given the time commitments that scanning entails.
[01:08:11] Alex Volkov: I absolutely loved, the first thing you said, Paul, that, if we get to real time as the person in the machine, that some stuff, some understanding, interpretation of what they're going through could happen as well. That's extremely exciting. And at
[01:08:23] Alex Volkov: the rate of where Junaid is going I'm, I'm positive that This is possible and I'm very happy that you guys are working on this and are excited about building like improvements on this the jump from 40 hours to one hour seems incredible to me? And if this trend continues, definitely exciting possibilities. Thank you guys for coming up. Maybe let's finish on this what are you Restricted on from going forward. Is it like compute? Is it data? is it talent Maybe you want it like shout out. Maybe you're hiring. Feel free. The stage is just like what else is needed to get to MindEye 3 faster
[01:08:56] Tanishq Abraham: Yeah, I think it's mostly manpower, I guess, I mean, I think it's, mostly relying on volunteers and, Paul, of course, is doing a great job leading this so that I think is the main limitation and of, but of course, yeah, like with MedArc, we are doing everything, open source and transparently so we, we have a Discord server where we organize all of our Our our research and progress and well, we have all the contributors joined.
[01:09:20] Tanishq Abraham: We, I mean, we've been lucky to have amazing contributors so far, from Princeton University of Minnesota University of Waterloo, from all around the world, we've had people contribute, but of course, more contributors are better, of course. And, if you're interested in this sort of research.
[01:09:35] Tanishq Abraham: Please please join our Discord, and of course feel free to, to read the papers as well and follow us on Twitter we'll be updating our progress on Twitter as well but yeah I think Yeah, just, check out our Twitter and join our Discord, I think is the main one.
[01:09:49] Tanishq Abraham: But yeah,
[01:09:50] Alex Volkov: absolutely. And thank you guys for coming up. I'm very happy that I was able to talk to you guys. Cause last time when you raised my hand, I was like, Oh, this is so cool. I know the niche, but yeah, back then we weren't bringing you up. So Paul, thank you It's great meeting you and you guys are doing incredible work and
[01:10:03] Alex Volkov: I think it's very important.
[01:10:04] Alex Volkov: I'm very happy to highlight this as well. Now we're moving to something a little bit different.
[01:10:08] Alex Volkov: Let's reset the space a little bit, and then let's talk about fine tuning.
[01:10:24] Alex Volkov: All righty. ThursdAI, March 28th, the second part of the show. If you just joined us, we Just had an incredible conversation with Paul Scotty and Tanishq Abraham from MedArk and I guess stability, part of stability
[01:10:43] Alex Volkov: as well. and we've talked about AI reading your brain and understanding what you saw, which is incredible.
[01:10:48] Alex Volkov: And I definitely recommend listening to this if you just joined in the middle or or just joining us late Meanwhile, we also covered a bunch of open source stuff so far. We also covered that cloud Opus is now taking over as the number one LLM in the world right now, and something we all knew, but now LMC Serena is catching up? We also had a bunch of breaking news and I wanna just reset the space and say that, hey, for everybody who joined us for the first time this is ThursdAI. we talk about AI every day. everything that's important and impactful in the world?
[01:11:18] Alex Volkov: of AI from week to Week and we've been doing this for more than a year. and you're more than welcome to join us in the conversation in in in the comments as well. We're reading through those. And if you're late to any part of this is released as a podcast episode on every
[01:11:33] Alex Volkov: podcast platform. So you're more than welcome to follow us on Twitter. Apple and Spotify and whatever you get your podcast. and also there's a newsletter with all the links and videos and everything we talk about that you have to actually see, right? So a link to the MindEye paper will be in the show notes and the newsletter as Well
[01:11:48] This weeks buzz - WandB in SF in April
[01:11:48] Alex Volkov: I will also say that my actual job is an AI evangelist with Weights Biases, a company that builds tools for all these model creators to actually track their experiments. and Weights Biases is coming to San Francisco in April 18th and April 17th. we have a conference there. You're, if you're in the area or you want to fly in and meet like a bunch of folks in San Francisco, you're more than welcome to use this as your Reason and opportunity I think for the next few days
[01:12:15] Alex Volkov: the tickets are still early bird and it's 50 percent price we're doing a workshop on April 17th about improving your business with LLMs. And we're doing everything from prompting to evaluation and doing a bunch of very exciting conversations. So if you're in the area, please stop By and, high five me. I'm going to be in San Francisco for the whole week. and moving on here. I want to chat about finetuning, and I see LDJ here.
[01:12:36] Discussion : Is finetuning still valunable?
[01:12:36] Alex Volkov: I think we've covered pretty much everything important unless there's breaking news and hopefully folks will DM me If there are breaking news there has been a sentiment in in at least, in our little bubble of AI, On X, where some folks started to get a little bit disillusioned with the concept of Fine tuning. and I don't think the disillusionment necessarily is with the concept of fine tuning as a concept I think the kind of the general vibe of getting and I think some folks like Ethan Mollick and Anton Bakaj was like a folk folks we follow for some like information.
[01:13:07] Alex Volkov: The disillusionment stems from the fact that we previously covered that long context Windows maybe affect like rag for example, RAG use cases, but long context window could also affect finetuning, because if you get something like a Haiku, which is now the world's like fifth or sixth, LLM in the world but it costs 25 cents a million tokens, and you can send a bunch of examples into Haiku for every request you maybe you maybe not needing to fine tune? and so this has been a little bit of a sentiment and also the bigger models they release like the recent Databricks model is huge and it's really hard to fine tune you have to like actually have a bunch of hardware so we've seen the sentiment and I really briefly wanted to touch with LDJ and Nisten and Junyang and Tanishq also like everybody who's on stage feel free to chime in and from the
[01:13:55] Alex Volkov: audience.
[01:13:56] Alex Volkov: If you're friends of the pod, do you want to come up and talk about fine tuning? Let's talk about this sentiment. LDJ, I saw your question. Yes, we've covered Jumba in the beginning. We're very excited. I think Jan was here and now he's talking to actual AI21 folks. So I want to do this like fine tuning conversation.
[01:14:09] Alex Volkov: LDJ, we briefly covered this and we said, Hey, it would be awesome to just chat about this like face to face. So what's your take on this recent sentiment? What are you getting from this?
[01:14:18] LDJ: yeah, I guess when it comes specifically to, I guess, like the business advantage of fine tuning for a specific use case to try and have a cost advantage over open AI models or something, I feel like things might be changing with Haiku and, I mean, you talked about this before It was either you or somebody else posted like a chart of the average trend of the cost for like how good the model is and Haiku is breaking that trend of it's like Really good while being like significantly cheaper than it should be given the previous trends
[01:14:53] Alex Volkov: think that was Swyx. Let me go find it Yeah.
[01:14:56] LDJ: Yeah and yeah, I think just overall for a lot of things that [01:15:00] people would have fine tuned open source models for, Haiku, it just might make sense to use Haiku, and it might be able to do those things that you would fine tune for anyways better or equal, and at the same time be really cheap already to run.
[01:15:14] LDJ: And I think it definitely The amount of tasks that it makes sense to fine tune on from an economic point of view, it's just probably less tasks now than before and I guess that is probably going to get less as a closed source becomes more and more efficient.
[01:15:32] Alex Volkov: Yeah, so absolutely there's a
[01:15:33] Alex Volkov: few areas for which fine tune is a concept even, right? There's like the general instruction fine tuning you take a base model, you try to make it more helpful. but there's also fine tuning for more knowledge, for example, that I think and maybe you guys can correct me on this and feel free to step in here, Junyang as well Is that the kind of the knowledge fine tuning the like giving this model like more information?
[01:15:56] Alex Volkov: sometimes suffers from stuff like catastrophic forgetting that the model like starts to forget some other stuff.
[01:16:02] Alex Volkov: But also things like RAG, for example, are potentially helping in that area where you can actually have a a sighting of a specific source that the model like referred onto, which is very important especially in the enterprise and companies area right like when you want to build something like a assistant or something like retrieval or something like search or better search you actually don't want to count on the model's hallucinations potential. you want to cite something. So for knowledge retrieval, RAG seems to be at least in the companies and enterprise area RAG seems to be like winning over Finetuning. and then the question is RAG over a Finetune model for your specific stuff better than RAG over a general model with a huge context? and I think that this is the area of disillusionment, specifically around the cost of pulling everything back and I think previously context window was very not cost effective We briefly mentioned this today in the area of Jamba models where Context is now like cheaper with those models, but for a regular Transformer LLM, context is expensive.
[01:17:04] Alex Volkov: The more context you have, The kind of, the more the hardware requirements grow and so I think that some of the kind of disillusionment especially comes from that. some of it is probably also related to how Big the models have gotten. I don't know, Nisten, if you want to chime in on this or like how even the Grok one the model was huge. people were like getting excited, but then some folks like Technium from Nous Research, like I said, we won't even try to fine tune this for even Instruction, because it's just too big so I wanted to hear from Nisten, from you because you guys also did like a bunch of fine tuning. And also maybe merging as well is related to here.
[01:17:43] Nisten Tahiraj: Yeah, gotta keep in mind that for a while, fine tuning was a lot more expensive. Running fine tuned models was a lot more expensive than using GPT 3. 5. And then it got a lot cheaper with all the API companies, especially together and the other ones. So the business case for it has not really been how how cheap it is.
[01:18:08] Nisten Tahiraj: I think in my opinion, the business case has. been all about data ownership. A lot of companies that have their own chatbots and stuff, they they see the data as their property and the value in their company, so the reason they fine tune is not because necessarily it's better, sometimes it is but it's been to just have full control of the data. And there have been a lot of drawbacks where you could have the knowledge could be lost. But there are much newer techniques where you can do, quote unquote, lossless fine tuning and and still have it. But yeah, I'll I'll land it there. So I think the business case is not necessarily the cost that has, it's always just been about data ownership.
[01:18:53] Nisten Tahiraj: I'm actually doing consulting for one client now that really just wants to use Grok. Some they use the Grok API before and now they want to run it on their own and they don't care how many. JVs and stuff it costs to run because they factor it in with what their users pay.
[01:19:13] Nisten Tahiraj: So, so, so yeah I'm noticing that it's more about the ownership side, not not necessarily the performance or cost.
[01:19:21] Alex Volkov: GR with a K or grok with a Q.
[01:19:23] Nisten Tahiraj: Grok with a K the new, yeah,
[01:19:25] Alex Volkov: Oh, really? What API they use for grok. There's no API is there an API for grok that I missed?
[01:19:31] Nisten Tahiraj: No they
[01:19:31] Ian Maurer: open source the model.
[01:19:33] Alex Volkov: Oh, so somebody hosted this and then they used the API since the, since last week basically
[01:19:37] Ian Maurer: no, they people
[01:19:38] Nisten Tahiraj: have used have used grok. I think they just did a, like a translation layer via via premium, but they did use grok in, in, in a product for, via an API. I'll have to, I'll have to double check how exactly,
[01:19:53] Alex Volkov: like I can think of a way, but I'm not saying it's kosher. Like you, you can, you can put a Chrome extension and use the browser. Very
[01:19:59] Nisten Tahiraj: No, even Levels. io deployed a, uh, like a WhatsApp bot that was that was running off of Grok too. So again I'll check up on that. I don't know what API stuff they, they used, but I am helping them now just run their own.
[01:20:16] Alex Volkov: I see. LDJ, you unmuted. You want to chime in on the kind of like a specific choice and data ownership piece of the fine tuning, which I think is important. But from the other side if I'm representing the other side and I'm not, I'm just trying to figure out like where the vibes are coming from about this eligiment is most clouds now run most
[01:20:34] Alex Volkov: Open source models, or at least, Microsoft definitely is now like supporting Mixtral.
[01:20:38] Alex Volkov: I don't know if they're going to run Grok for you or not. And. There's also something to be said where if you're running Cloud from inside Amazon or Bedrock or Vertex or whatever you still own your data, aren't you?
[01:20:52] LDJ: I'm not too familiar with the situation with Vertex and stuff but I do think that in the situations where a business has to. would want to and has to fine tune on like their company data so that employees can actually like, use something that is like an AI that understands the internal company information.
[01:21:12] LDJ: That is I would say still a decent sized use case that you would have to use like the open source models for like unless you're fine with giving open AI your data and stuff, but I'm not saying necessarily open AI will train on it. I know they have different clauses and stuff, but you know, there's always like that risk and if you want to keep that stuff secret and internal, then you do have to still just use the open source models to fine tune.
[01:21:38] Alex Volkov: Yeah. the additional kind of piece that, that I think Ethan knowledge like pointed to and before I get to Justin super quick, is that the example of Bloomberg and I think LDJ you wanted to push back on this example, but I'll cover this like briefly. B Bloomberg, sorry. Bloomberg famously trained a model called Bloomberg gpt based on the type of financial data that Bloomberg has access to.
[01:22:00] Alex Volkov: And back then it like it significantly improved. LLM thinking about like finances and financial data, et cetera, only to then find out that a General model, like GPT 4, like blows it out of the Water Whatever 10 million, whatever they spent on that. And I think this was like also A highlight of how general models after they get released and they're getting better they're getting better across the board Not only for your task, but also for your task as well and before we get to Junaid and LDJ, you had a pushback that they didn't do it correctly, it was a skill issue or something like this, right?
[01:22:32] LDJ: Yeah. I think it was honestly more of a skill issue on Bloomberg's part because. And I'll try and find the exact source for what I'm about to say, but it was like within a few weeks of Bloomberg GPT releasing, like there's like just a couple open source developers that released like a finance specific model.
[01:22:49] LDJ: That was performing significantly better on the finance benchmarks with the same amount or less parameters. And that was just within a few weeks of Bloomberg GPT releasing. So obviously you didn't even need all that Bloomberg data and all that stuff to actually even get something that, that well performing.
[01:23:06] Alex Volkov: Yep. All right.
[01:23:07] Alex Volkov: I want to get to Justin, because, Justin, obviously you're on the Qwen team, you guys are building models that then other folks maybe fine tune and probably also supporting, enterprise use cases. What's your take on the fine tuning area?[01:23:20]
[01:23:20] Justin Lin: Yeah, just some comment on the fine tuning for customer data. I think I somehow disagree with the idea that. We can inject new knowledge to the model through fine tuning because it is really difficult to do that. Do this thing with such a few data because we often use a very small amount of data to for fine tuning. I have read the paper, I don't remember its name, but it's telling us that fine tuning is more about aligning to the behavior, to the style, but not injecting new knowledge. If you want to inject new knowledge, you have to do things like this. Pre training next token prediction with ten, tens of billions of tokens so you can do this, but it is really hard.
[01:24:09] Justin Lin: Something I would like to comment is that our customers fine tune our model and they found that the general capability is decreased. With the new knowledge I think this is quite reasonable because somehow our customers or users don't know really how to fine tune for a general model.
[01:24:29] Justin Lin: They want the general capability, but they want something new. So we have provided a solution is that we just provide our data for general fine tuning in a black box way. So you can use our data, but you cannot see our data, and you can mix our data with your own, yeah, customer data so that you can train a new model which has a balanced behavior good general capabilities, but some new knowledge or some new styles of your company or something like that.
[01:25:04] Justin Lin: Yeah. This is some of my personal
[01:25:06] Justin Lin: experience. Yeah.
[01:25:07] Alex Volkov: I really appreciate this, because I think that The difference is important fine tuning is not like a catch all sentence. There's fine tuning for style fine tuning for alignment for different ways to respond, for example. and that I think still, makes perfect sense. We have base models, we have fine tuned models for instruction fine tuning, for example. but I think that this is, at least the way I see it on my kind of radar, and I wanted to bring this to ThursdAI because I think it's very important for folks who follow this to also know that this is happening is from specifically from Finetuning with new knowledge, not only new kind of styles, new knowledge specifically, because the additional piece here is fine tuning takes a while and like maybe we said about Bloomberg maybe a skill issue Maybe you have to get like those machine learning engineers whereas with the advent of faster hardware better models that are open for you and They're now hosted on the actual kind of like the bedrock from Amazon. for example, this is basically in your cloud, They're running whatever haiku but in your cloud and the same agreements of not training all Your data is like the same, they apply OpenAI, You can run through Microsoft thing and in your cloud in Azure, and it's not like sending some data to OpenAI. So when we get to like bigger contexts, the ability of you to switch up and give this whatever product you're building on top of these LLMs, new data That's easier than Finetune with just like just providing the same context as well.
[01:26:29] Alex Volkov: Tanishq, I saw you had your hand up and definitely want to hear from you as well.
[01:26:34] Tanishq Abraham: Yeah, I guess I just had a few thoughts about this whole thing because, I'm working in the medical AI space and we're like by two models for, clinical applications, medical applications. So, I have various thoughts about this. I think just generally, of course I think it's with Phytuning yeah, It's particularly useful if you like, I think LDJ is of course, but actually the use case of yeah, if there's private data, that's of course a big one.
[01:26:56] Tanishq Abraham: I think also if you want to have models locally, you want to use models locally. I think that's another big use case. A lot of times, there are many cases where, you don't want. To use cloud services, I think like in the medical scenario, for example, maybe you don't want to send medical data to various cloud providers and having some sort of local models could potentially be useful.
[01:27:13] Tanishq Abraham: And of course there are other applications where maybe you want to have models run on, Some sort of like smartphones or other devices. So that's, I think one particular area where like fine tuning is particularly valuable. I think, in the sort of just to provide maybe some context in the medical space, medical AI space, I think this idea of whether or not fine tuning is useful is, I think, honestly, in my opinion, like an argument that's like still not settled yet.
[01:27:38] Tanishq Abraham: So for example, like in the clinical LSP space, you have models like, of course, GPT 4, you have then you have, Google has their MedPOM models, then other model, other people are creating specific fine tunes. About a couple of years ago, or maybe it was a year ago, there was a paper that tried to see if for example, something like GPT 3 was better, or fine tuning a specific model for medical use cases was better.
[01:28:02] Tanishq Abraham: They found that fine tuning was better performing and of course required less parameters and was a smaller model. But then something like people Google, for example, created their MedPAL models. Those are more like alignment in the sense that Justin was talking about. The knowledge is mostly there in the original PAL models and they're just doing some sort of instruction fine tuning.
[01:28:22] Tanishq Abraham: And so that has been showing to do quite well. Thank you. And then recently there was a paper, the MedPrompt paper, which basically prompted GPT 4 to basically outperform all these other models for medical tasks. And so that one was just trying to say like a general purpose model is good enough.
[01:28:40] Tanishq Abraham: So I think there's still a lot of it's still actually an open question, at least in, in this specific area, whether or not PHI tuning is better, or if it's just alignment that's needed, or you can just use the general purpose model. And so I think we're trying to study this question a little bit more detail as well, and try to see if PHI tuning really is necessary, if that actually does provide benefit.
[01:28:58] Tanishq Abraham: And at least for me, I think of it more like, when I say PHI tuning, I also think of it like as continued pre trading where, yeah, we are probably be trading on we are trading on like tens of billions of tokens. To add knowledge to a model. And I think, there's, people talk about FI tuning, but they also talk about continued pre-training and sometimes the distinction between those is a little bit kind of a group.
[01:29:18] Tanishq Abraham: There isn't much of a distinction sometimes, so there's also that as well. And I think that also is a lot of the times the question between whether or not it's just doing alignment versus adding knowledge. I think, that's. Part of that discussion and that, that isn't really I think clarified very often so that there's, that's the other aspect, but yeah, those are my thoughts on the topic.
[01:29:37] Alex Volkov: thanks Tanishq. And I also want to welcome Ian Moore to the stage. Ian, it's been a while since you've been here. Thoughts on this exciting discussion and have you seen the same trends or the same kind of vibes that I brought up on where you read and
[01:29:51] Ian Maurer: yeah.
[01:29:51] Ian Maurer: We were talking about this in January, Alex, I found the conversation, right? Finetuning versus RAG, the question is what's your goal? What's your use case? What's your eval? I think Hamill even mentioned, do you know, even know what your evals are? Do you even know what you're trying to accomplish?
[01:30:03] Ian Maurer: Without that good luck fine tuning, good luck building an app. Anyways my, I have a very distinct opinion and perspective, but I'll give you guys background so you understand where it's coming from. My company is 12 years old. We've got an old, good old fashioned AI company where we've curated 100, 000, Rules, effectively, in a knowledge base.
[01:30:20] Ian Maurer: It's a graph. It's got ontologies and things like that. And those rules have been curated by experts with PhDs, and we have an API that sets over it, and reasons over it, and can match patients to clinical trials. This is for cancer, right? So, patients get, DNA sequence, and it's very complicated, whatever.
[01:30:35] Ian Maurer: So, the great thing about large language models and as they get bigger and better is that they can understand language, including all language, including medical language, so they can understand the intent of a provider, right? The provider's trying to accomplish something, which is as quickly as possible, how do I help this patient?
[01:30:51] Ian Maurer: And So the thing that I have found that's most useful for us is to help that expert be as productive as they can possibly be. Use the large language model to understand their intent, what they have. I have a patient, they have a problem, what they want to find the best possible treatments for that patient.
[01:31:07] Ian Maurer: And then how to do that is by giving that large language model tools, right? Don't. Why do I want to fine tune knowledge into it? And then I just, I basically black boxed all my knowledge, right? Great. I have all this great knowledge I've curated over the years. I'm going to fine tune it into my system. And now it's a black box and I can't tell you where from or why it's there.
[01:31:25] Ian Maurer: No, I want to be able to tell you, here's the trials that are available for your patient. Here's the drugs that are available for your patient. This is the, the best possible outcome for that. And here's the link to the clinical trials page, or here's the link to the the FDA page that tells you why this drug is so [01:31:40] good.
[01:31:40] Ian Maurer: I can't do that if it's a black box. I'd be hallucinating all over the place. So my perspective is Finetuning is great if you're talking about a very discreet use case that you're trying to, drill down on cost. Hey, I figured out this named entity recognition pattern and now I'm, I was doing it expensively with few shot learning.
[01:31:57] Ian Maurer: Now I'm going to go, fine tune something and save that cost. But otherwise, you know Use the best possible model, give them tools, whether it's, through function calling or GPT actions are actually pretty good. And that's the best way to get the value out of the large language model and work with existing knowledge.
[01:32:13] Alex Volkov: So definitely sightings and knowing exactly about your data and not like blurring it out inside the brain of LLM, fuzzing it out where you can't actually know where it came from or whether or Not it's hallucinated. I think that's a big piece here that companies are actually like starting to also get into.
[01:32:30] Alex Volkov: And so I think you're Your perspective. is very important as Well I think also from the perspective at least the vibes that I've seen from the perspective of updating that data afterwards, like just continue fine tuning, like requires more knowledge and more skill, rather than just updating your vector databases, let's say, and have the model provide enough context. and I think the smartness to price ratio, I think is very important as well. If we get like models like Haiku, for example, they're like incredibly cheap. But have a vast context length that you can use both for fine tuning towards alignment, let's say, or behave like whatever you want it to behave or answer as our company versus answer is like the, this LLM together with you have enough context to do that and it's not cost prohibitive for you to use this large context for a bunch of stuff. and it's very important
[01:33:18] Alex Volkov: so I thanks Ian for coming up. I want to tie this back a little bit and then close the discussion also, I do want to shout out that you also have an awesome list of function calling, which now includes a bunch of open source. models that support function calling as well . The support is like function calling as well and it talks about the specifics in which they support function calling. Which is great and definitely will be in the show notes as well and with that folks, I think we'll end ThursdAI for today we had a bunch of stuff.
[01:33:44] Alex Volkov: There's a small breaking news from ray Ray just mentioned that Cursor the AI editor that we a lot of US use and love they just released an update where like their Cursor, like Copilot plus feature is still available. twice as fast now in some areas and that's been like awesome to use. So if you haven't used Cursor yet, definitely give it, give them A try.
[01:34:02] Alex Volkov: And Cursor is like really impressive, especially with Opus. If you have paid for Cursor Premium, have access to the best LLM in the world. I think that this is all that we wanted to talk about. thank you everybody for
[01:34:12] Alex Volkov: joining from week to week.
[01:34:13] Alex Volkov: I think that's most of what we talked about on ThursdAI for March 28th. With that, I want to thank Nisten, LDJ, Justin, Junyang, Robert Skobel was here before, Ian Moore jumped on, Tanishq, and Paul, definitely from MedArc and everybody else who joined us I really appreciate everybody's time here. If you're not subscribed to ThursdAI to get every link that we've talked about, I really work hard to give you all the links, so definitely give a subscription Other than that have a nice Thursday, everyone. We'll see you next week. Cheers, everyone.
[01:34:41] Ian Maurer: Bye everybody.
[01:34:42] Alex Volkov: bye bye



