



Hey, this is Alex. Don't you just love when assumptions about LLMs hitting a wall just get shattered left and right and we get new incredible tools released that leapfrog previous state of the art models, that we barely got used to, from just a few months ago? I SURE DO!

Today is one such day, this week was already busy enough, I had a whole 2 hour show packed with releases, and then Anthropic decided to give me a reason to use the #breakingNews button (the one that does the news show like sound on the live show, you should join next time!) and announced Claude Sonnet 3.5 which is their best model, beating Opus while being 2x faster and 5x cheaper! (also beating GPT-4o and Turbo, so... new king! For how long? ¯\_(ツ)_/¯)
Critics are already raving, it's been half a day and they are raving! Ok, let's get to the TL;DR and then dive into Claude 3.5 and a few other incredible things that happened this week in AI! 👇
TL;DR of all topics covered:
Open Source LLMs
Big CO LLMs + APIs
This weeks Buzz
Alex in SF next week for AIQCon, AI Engineer. ThursdAI will be sporadic but will happen!
W&B Weave now has support for tokens and cost + Anthropic SDK out of the box (Weave Docs)
Vision & Video
Voice & Audio
Google Deepmind teases V2A video-to-audio model (Blog)
AI Art & Diffusion & 3D
Flash Diffusion for SD3 is out - Stable Diffusion 3 in 4 steps! (X)
🦀 New king of LLMs in town - Claude 3.5 Sonnet 👑
Ok so first things first, Claude Sonnet, the previously forgotten middle child of the Claude 3 family, has now received a brain upgrade!
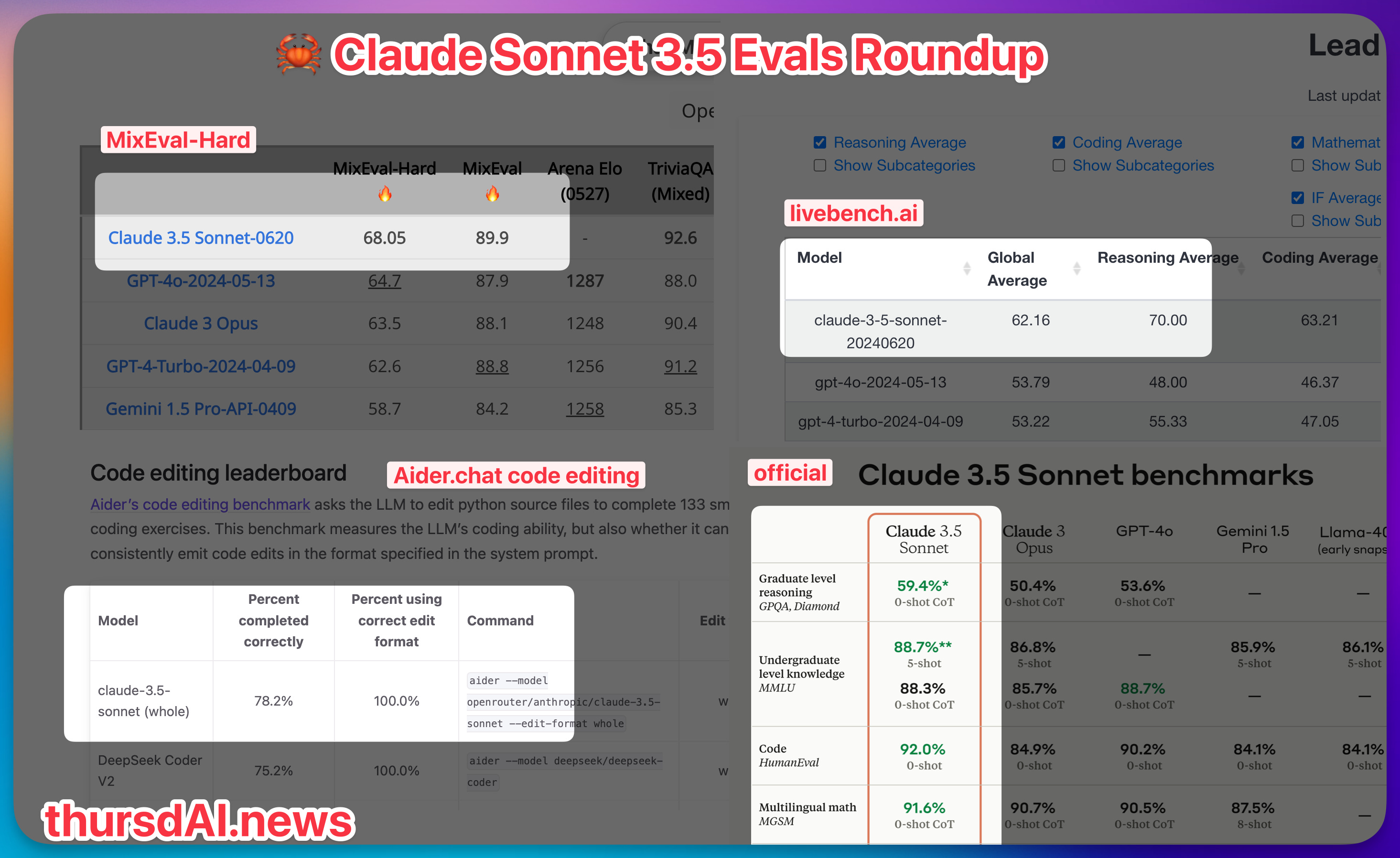
Achieving incredible performance on many benchmarks, this new model is 5 times cheaper than Opus at $3/1Mtok on input and $15/1Mtok on output. It's also competitive against GPT-4o and turbo on the standard benchmarks, achieving incredible scores on MMLU, HumanEval etc', but we know that those are already behind us.
Sonnet 3.5, aka Claw'd (which is a great marketing push by the Anthropic folks, I love to see it), is beating all other models on Aider.chat code editing leaderboard, winning on the new livebench.ai leaderboard and is getting top scores on MixEval Hard, which has 96% correlation with LMsys arena.
While benchmarks are great and all, real folks are reporting real findings of their own, here's what Friend of the Pod Pietro Skirano had to say after playing with it:
there's like a lot of things that I saw that I had never seen before in terms of like creativity and like how much of the model, you know, actually put some of his own understanding into your request
-@Skirano
What's notable a capability boost is this quote from the Anthropic release blog:
In an internal agentic coding evaluation, Claude 3.5 Sonnet solved 64% of problems, outperforming Claude 3 Opus which solved 38%.
One detail that Alex Albert from Anthropic pointed out from this released was, that on GPQA (Graduate-Level Google-Proof Q&A) Benchmark, they achieved a 67% with various prompting techniques, beating PHD experts in respective fields in this benchmarks that average 65% on this. This... this is crazy
Beyond just the benchmarks
This to me is a ridiculous jump because Opus was just so so good already, and Sonnet 3.5 is jumping over it with agentic solving capabilities, and also vision capabilities. Anthropic also announced that vision wise, Claw'd is significantly better than Opus at vision tasks (which, again, Opus was already great at!) and lastly, Claw'd now has a great recent cutoff time, it knows about events that happened in February 2024!

Additionally, claude.ai got a new capability which significantly improves the use of Claude, which they call artifacts. It needs to be turned on in settings, and then Claude will have access to files, and will show you in an aside, rendered HTML, SVG files, Markdown docs, and a bunch more stuff, and it'll be able to reference different files it creates, to create assets and then a game with these assets for example!
1 Ilya x 2 Daniels to build Safe SuperIntelligence
Ilya Sutskever, Co-founder and failed board Coup participant (leader?) at OpenAI, has resurfaced after a long time of people wondering "where's Ilya" with one hell of an announcement.

The company is called SSI of Safe Super Intelligence, and he's cofounding it with Daniel Levy (prev OpenAI, PHD Stanford) and Daniel Gross (AI @ Apple, AIgrant, AI Investor).
The only mandate of this company is apparently to have a straight shot at safe super-intelligence, skipping AGI, which is no longer the buzzword (Ilya is famous for the "feel the AGI" chant within OpenAI)
Notable also that the company will be split between Palo Alto and Tel Aviv, where they have the ability to hire top talent into a "cracked team of researchers"
Our singular focus means no distraction by management overhead or product cycles
Good luck to these folks!
Open Source LLMs
DeepSeek coder V2 (230B MoE, 16B) (X, HF)
The folks at DeepSeek are not shy about their results, and until the Sonnet release above, have released a 230B MoE model that beats GPT4-Turbo at Coding and Math! With a great new 128K context window and an incredible open license (you can use this in production!) this model is the best open source coder in town, getting to number 3 on aider code editing and number 2 on BigCodeBench (which is a new Benchmark we covered on the pod with the maintainer, definitely worth a listen. HumanEval is old and getting irrelevant)
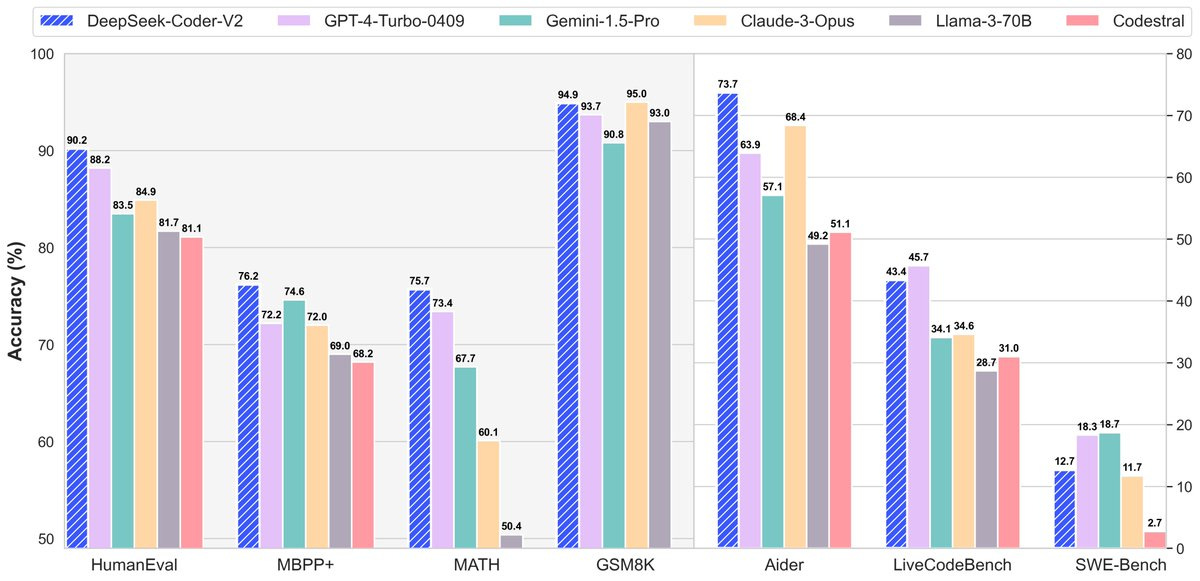
Notable also that DeepSeek has launched an API service that seems to be so competitively priced that it doesn't make sense to use anything else, with $0.14/$0.28 I/O per Million Tokens, it's a whopping 42 times cheaper than Claw'd 3.5!
Support of 338 programming languages, it should also run super quick given it's MoE architecture, the bigger model is only 21B active parameters which scales amazing on CPUs.
They also released a tiny 16B MoE model called Lite-instruct and it's 2.4B active params.
This weeks Buzz (What I learned with WandB this week)
Folks, in a week, I'm going to go up on stage in front of tons of AI Engineers wearing a costume, and... it's going to be epic! I finished writing my talk, now I'm practicing and I'm very excited. If you're there, please join the Evals track 🙂

Also in W&B this week, coinciding with Claw'd release, we've added a native integration with the Anthropic Python SDK which now means that all you need to do to track your LLM calls with Claw'd is pip install weave and import weave and weave.init('your project name'
THAT'S IT! and you get this amazing dashboard with usage tracking for all your Claw'd calls for free, it's really crazy easy, give it a try!
Vision & Video
Runway Gen-3 - SORA like video model announced (X, blog)
Runway, you know the company who everyone was "sorry for" when SORA was announced by OpenAI, is not sitting around waiting to "be killed" and is announcing Gen-3, an incredible video model capable of realistic video generations, physics understanding, and a lot lot more.
The videos took over my timeline, and this looks to my eyes better than KLING and better than Luma Dream Machine from last week, by quite a lot!
Not to mention that Runway has been in video production for way longer than most, so they have other tools that work with this model, like motion brush, lip syncing, temporal controls and many more, that allow you to be the director of the exactly the right scene.
Google Deepmind video-to-audio (X)
You're going to need to turn your sound on for this one! Google has released a tease of a new model of theirs that can be paired amazingly well with the above type generative video models (of which Google also has one, that they've teased and it's coming bla bla bla)
This one, watches your video and provides acoustic sound fitting the scene, with on-sceen action sound! They showed a few examples and honestly they look so good, a drummer playing drums and that model generated the drums sounds etc' 👏 Will we ever see this as a product from google though? Nobody knows!
Microsoft releases tiny (0.23B, 0.77B) Vision Models Florence (X, HF, Try It)
This one is a very exciting release because it's MIT licensed, and TINY! Less than 1 Billion parameters, meaning it can completely run on device, it's a vision model, that beats MUCH bigger vision models by a significant amount on tasks like OCR, segmentation, object detection, image captioning and more!

They have leveraged (and supposedly going to release) a FLD-5B dataset, and they have specifically made this model to be fine-tunable across these tasks, which is exciting because open source vision models are going to significantly benefit from this release almost immediately.
Just look at this hand written OCR capability! Stellar!
NousResearch - Hermes 2 Theta 70B - inching over GPT-4 on MT-Bench

Teknium and the Nous Reseach crew have released a new model just to mess with me, you see, the live show was already recorded and edited, the file exported, the TL'DR written, and the newsletter draft almost ready to submit, and then I check the Green Room (DM group for all friends of the pod for ThursdAI, it's really an awesome Group Chat) and Teknium drops that they've beat GPT-4 (unsure which version) on MT-Bench with a finetune and a merge of LLama-3
They beat Llama-3 instruct which on its own is very hard, by merging in Llama-3 instruct into their model with Charles Goddards help (merge-kit author)
As always, these models from Nous Research are very popular, but apparently a bug at HuggingFace shows that this one is extra super duper popular, clocking in at almost 25K downloads in the past hour since release, which doesn't quite make sense 😅 anyway, I'm sure this is a great one, congrats on the release friends!

Phew, somehow we covered all (most? all of the top interesting) AI news and breakthroughs of this week? Including interviews and breaking news!
I think that this is our almost 1 year anniversary since we started putting ThursdAI on a podcast, episode #52 is coming shortly!
Next week is going to be a big one as well, see you then, and if you enjoy these, give us a 5 start review on whatever podcast platform you're using? It really helps 🫡


