





If you’d like to hear the whole 2 hour conversation, here’s the link to twitter spaces we had.
And if you’d like to add us to your favorite podcatcher - here’s the RSS link while we’re pending approval from Apple/Spotify
Happy LLaMa day! Meta open sourced LLaMa v2 with a fully commercial license.

LLaMa 1 was considered the best open source LLM, this one can be used for commercial purposes, unless you have more than 700MM monthly active users (no 🦙 for you Google!)
Meta has released the code and weights, and this time around, also a fine-tuned chat version of LLaMa v2 to all, and has put them on HuggingFace.
There are already (3 days later) at least 2 models that have fine-tuned LLaMa2 that we know of:
@nousresearch have released Redmond Puffin 13B
@EnricoShippole with collaboration with Nous have released LLongMa, which extends the context window for LLaMa to 8K (and is training a 16K context window LLaMa)
I also invited and had the privilege to interview the folks from @nousresearch group (@karan4d, @teknium1 @Dogesator ) and @EnricoShippole which will be published as a separate episode.
Many places already let you play with LLaMa2 for free:
https://www.llama2.ai/
nat.dev, replicate and a bunch more!
The one caveat, the new LLaMa is not that great with code (like at all!) but expect this to change soon!
We all just went multi-modal! Bing just got eyes!
I’ve been waiting for this moment, and it’s finally here. We all, have access to the best vision + text model, the GPT-4 vision model, via bing! (and also bard, but… we’ll talk about it)
Bing chat (which runs GPT-4) has now released an option to upload (or take) a picture, and add a text prompt, and the model that responds understands both! It’s not OCR, it’s an actual vision + text model, and the results are very impressive!
I’ve personally took a snap of a food-truck side, and asked Bing to tell me what they offer, it found the name of the truck, searched it online, found the menu and printed out the menu options for me!

Google’s Bard also introduced their google lens integration, and many folks tried uploading a screenshot and asking it for code in react to create that UI, and well… it wasn’t amazing. I believe it’s due to the fact that Bard is using google lens API and was not trained in a multi-modal way like GPT-4 has.
One caveat is, the same as text models, Bing can and will hallucinate stuff that isn’t in the picture, so YMMV but take this into account. It seems that at the beginning of an image description it will be very precise but then as the description keeps going, the LLM part kicks in and starts hallucinating.
Is GPT-4 getting dumber and lazier?

Researches from Standford and Berkley (and Matei Zaharia, the CTO of Databricks) have tried to evaluate the vibes and complaints that many folks have been sharing, wether GPT-4 and 3 updates from June, had degraded capabilities and performance.
Here’s the link to that paper and twitter thread from Matei.
They have evaluated the 0301 and the 0613 versions of both GPT-3.5 and GPT-4 and have concluded that at some tasks, there’s a degraded performance in the newer models! Some reported drops as high as 90% → 2.5% 😮
But is there truth to this? Well apparently, some of the methodologies in that paper lacked rigor and the fine folks at AI Snake Oil ( Sayash Kapoor and Arvind) have done a great deep dive into that paper and found very interesting things!

They smartly separate between capabilities degradation and behavior degradation, and note that on the 2 tasks (Math, Coding) that the researches noted a capability degradation, their methodology was flawed, and there isn’t in fact any capability degradation, rather, a behavior change and a failure to take into account a few examples.
The most frustrating for me was the code evaluation, the researchers scored both the previous model and the new June updated models on “code execution” with the same prompt, however, the new models defaulted to wrap the returned code with ``` which is markdown code snippets. This could have been easily fixed with some prompting, however, the researchers scored the task based on, wether or not the code snippet they get is “instantly executable”, which it obviously isn’t with the ``` in there.
So, they haven’t actually seen and evaluated the code itself, just wether or not it runs!
I really appreciate the AI Snake Oil deep dive on this, and recommend you all read it for yourself and make your own opinion and don’t give into the hype and scare mongering and twitter thinkfluencer takes.
News from OpenAI - Custom Instructions + Longer deprecation cycles
In response to the developers (and the above paper), OpenAi announced an update to the deprecation schedule of the 0301 models (the one without functions) and they will keep that model alive for a full year now!
Additionally, OpenAI has released “Custom Instructions for ChatGPT” which allows a chatGPT user to store custom instructions, information and custom prompt that will be saved on OpenAI server side, and will append to every new session of yours with chatGPT.
Think, personal details, preferred coding style (you love ruby and not python) and other incredible things you can achieve without copy-pasting this to every new session!
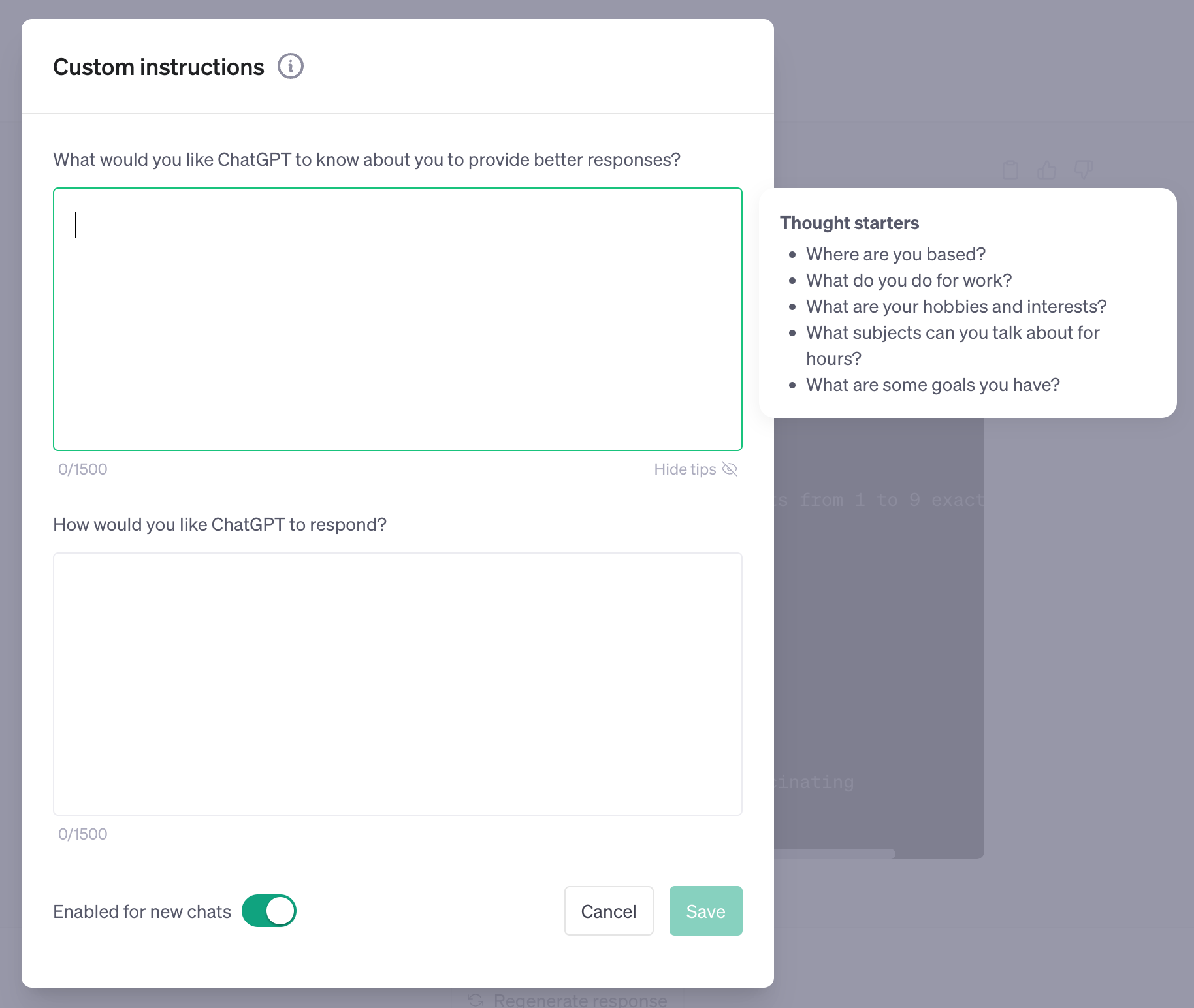
Don’t forget to enable this feature (unless you’re in the UK or EU where this isn’t available)

Thanks for tuning in, wether you’re a newsletter subscriber, twitter space participant, or just someone who stumbled onto this post, if you find this interesting, subscribe and tell your friends!
“We stay up to date so you don’t have to” is the #ThursdAI motto! 🫡
In other news this week:
LangChain has gotten some flack but they are looking ahead and releasing LangSmith, an observability framework for your agents, that does NOT required using LangChain!
It looks super cool, and is very useful to track multiple prompts and tokens across agent runs! And the results are share-able so you can take a look at great runs and share yours with friends!

Don’t forget to share this with your friends and come back next week 🫡
— Alex Volkov




