



Hey, this is Alex,
Ok let's start with the big news, holy crap this week was a breakthrough week for speed!
We had both Groq explode in popularity, and ByteDance release an updated SDXL model called Lightning, able to generate full blown SDXL 1024 images in 300ms.
I've been excited about seeing what real time LLM/Diffusion can bring, and with both of these news release the same week, I just had to go and test them out together:
Additionally, we had Google step into a big open weights role, and give us Gemma, 2 open weights models 2B and 7B (which is closer to 9B per Junyang) and it was great to see google committing to releasing at least some models in the open.
We also had breaking news, Emad from Stability announced SD3, which looks really great, Google to pay Reddit 200M for AI training on their data & a few more things.
TL;DR of all topics covered:
Big CO LLMs + APIs
Groq custom LPU inference does 400T/s Llama/Mistral generation (X, Demo)
Google image generation is in Hot Waters and was reportedly paused (refuses to generate white people)
Gemini 1.5 long context is very impressive to folks (Matt Shumer, Ethan Mollick)
Open Weights LLMs
Google releases GEMMA, open weights 2B and 7B models (Announcement, Models)
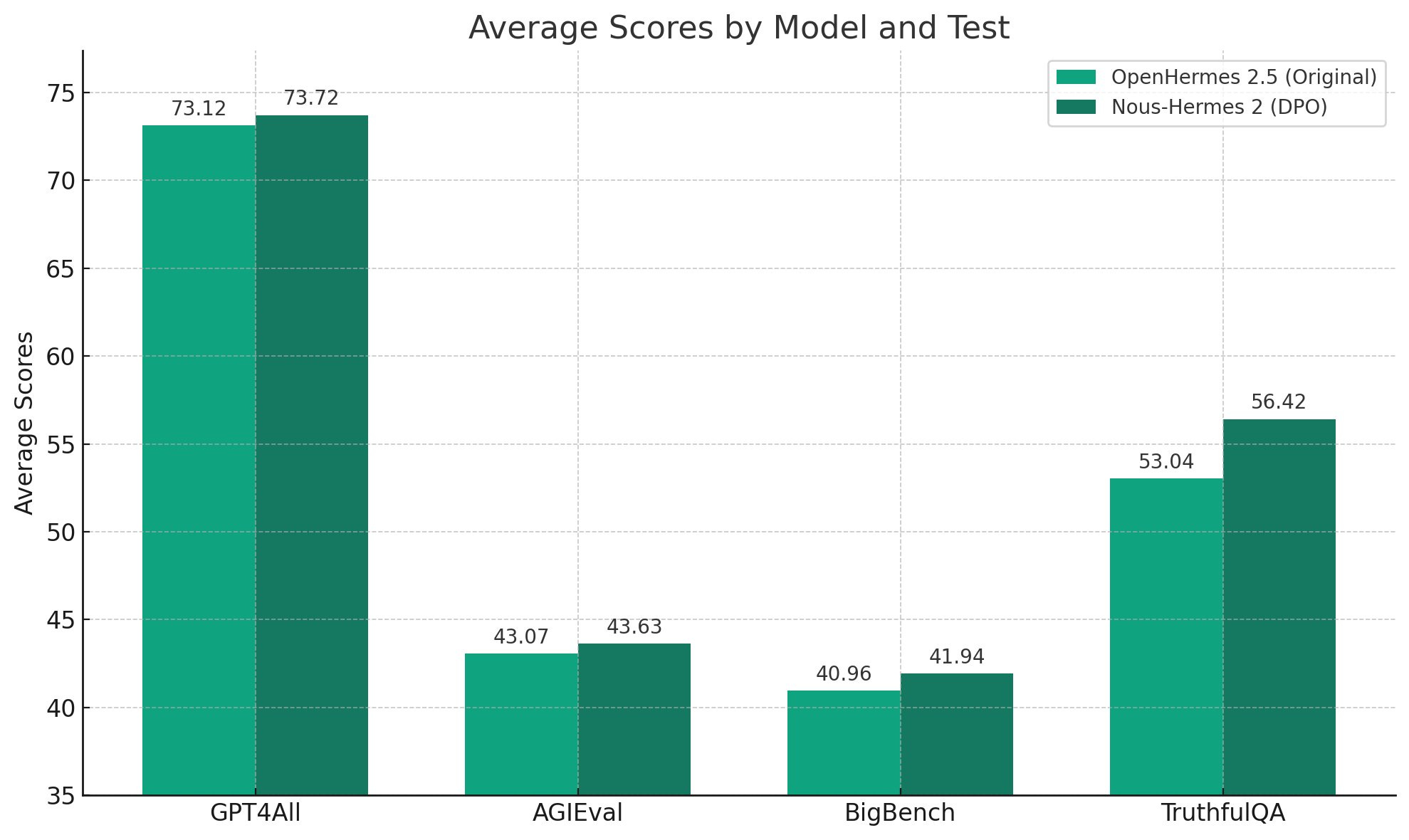
Teknium releases Nous Hermes DPO (Announcement, HF)
Vision & Video
YoLo V9 - SOTA real time object detector is out (Announcement, Code)
This weeks Buzz (What I learned in WandB this week)
AI Art & Diffusion & 3D
Stability announces Stable Diffusion 3 (Announcement)
Tools
Replit releases a new experimental Figma plugin for UI → Code (Announcement)
Arc browser adds "AI pinch to understand" summarization (Announcement)
Big CO LLMs + APIs
Groq's new LPU show extreme performance for LLMs - up to 400T/s (example)
Groq created a novel processing unit known as the Tensor Streaming Processor (TSP) which they categorize as a Linear Processor Unit (LPU). Unlike traditional GPUs that are parallel processors with hundreds of cores designed for graphics rendering, LPUs are architected to deliver deterministic performance for AI computations.
Analogy: They know where all the cars are going when everyone wakes up for work (when they compile) and how fast they all drive (compute latency) so they can get rid of traffic lights (routers) and turn lanes (backpressure) by telling everyone when to leave the house.
Why would we need something like this? Some folks are saying that average human reading is only 30T/s, I created an example that uses near instant Groq Mixtral + Lightning SDXL to just create images with Mixtral as my prompt manager

Open Source Weights LLMs
Google Gemma - 2B and 7B open weights models (demo)
4 hours after release, Llama.cpp added support, Ollama and LM Studio added support, Tri dao added Flash attention support
Vocab size is 256K
8K context window
Tokenizer similar to LLama
Folks are... not that impressed as far as I've seen
Trained on 6 trillion tokens
Google also released Gemma.cpp (local CPU inference) - Announcement
Nous/Teknium re-release Nous Hermes with DPO finetune (Announcement)
DPO RLHF is performing better than previous models
Models are GGUF and can be found here
DPO enables Improvements across the board
This weeks Buzz (What I learned with WandB this week)
Alex was in SF last week
A16Z + 20 something cohosts including Weights & Biases talked about importance of open source

Huge Shoutout Rajko and Marco from A16Z, and tons of open source folks who joined
Nous, Ollama, LLamaIndex, LMSys folks, Replicate, Perplexity, Mistral, Github, as well as Eric Hartford, Jon Durbin, Haotian Liu, HuggingFace, tons of other great folks from Mozilla, linux foundation and Percy from Together/Stanford

Also had a chance to checkout one of the smol dinners in SF, they go really hard, had a great time showing folks the Vision Pro, chatting about AI, seeing incredible demos and chat about meditation and spirituality all at the same time!

AI Art & Diffusion
ByteDance presents SDXL-Lightning (Try here)
Lightning fast SDXL with 2, 4 or 8 steps
Results much closer to original SDXL than turbo version from a few months ago
Stability announces Stable Diffusion 3 (waitlist)

Uses a Diffusion Transformer architecture (like SORA)
Impressive multi subject prompt following: "Prompt: a painting of an astronaut riding a pig wearing a tutu holding a pink umbrella, on the ground next to the pig is a robin bird wearing a top hat, in the corner are the words "stable diffusion"

Tools
Replit announces a new Figma design→ code plugin
That’s it for today, definitely check out the full conversation with Mark Heaps from Groq on the pod, and see you next week! 🫡
Full Transcript:
[00:00:00] Alex Volkov: Hey, this is Alex. This week on ThursdAI, we had an hour conversation with Grok, a new and very exciting AI inference chip that exploded in popularity all over social media after showing a 5x, yes, 5x improvement in AI inference. 500 tokens per second for Lama70B and Mistral.
[00:00:32] Alex Volkov: We also talked about Google's new OpenWeights GEMMA model, Google's image generation issues, which led them to take down the abilities of this image generation to generate people. We covered new, incredibly fast SDXL lightning, and we had breaking news for Stable Diffusion 3, which is a diffusion transformer that's coming out of Stability AI.
[00:01:03] Alex Volkov: and a bunch of other news. All that after this short intro into Weights Biases.
[00:01:10] AI teams are all asking the same question. How can we better manage our model development workflow? The path to production is increasingly complex, and it can get chaotic keeping track of thousands of experiments and models. Messy spreadsheets and ad hoc notebooks aren't going to cut it. The best AI teams need a better solution.
[00:01:33] And better tools. They need Weights Biases, the AI developer platform, to unlock their productivity and achieve production ML at scale. Replace messy spreadsheets with an automated system of record for experiments.
[00:01:52] Communicate about model evaluation. and collaboratively review results across the team. Clean up disorganized buckets of models with a unified registry. Automatically capture full model lineage, all the data and code used for training and testing. Seamlessly connect to compute to scale up training. And run large scale sweeps efficiently to optimize models.
[00:02:20] Analyze the performance of large language models. And monitor LLM usage and costs with live, customizable dashboards. Get your team on the same page to bridge the gaps from ideation to production. Use Weights Biases to build, manage, and deploy better models, faster.
[00:02:41] Alex Volkov: Wasn't this cool? This is Kari. She is a original PM on the Weights Biases team. She's been there for a long time and recently we used her voice to narrate this new video that we have up on the website. And I figured I'd put it in here because it works even without the video. And I thought it was super cool.
[00:03:01] Alex Volkov: And people ask me, what does Weights Biases do? And hopefully this answers some of those questions. Now I want to switch gears and say, basically. that the format for this week is a little different. We had the folks from Grok and Matt Schumer at the beginning of the pod, and then we kept talking about everything else, like Gemma and Gemini and everything else.
[00:03:24] Alex Volkov: So the first hour of this is going to be an interview with the Grok folks, specifically with Mark Heaps and the next hour afterwards is going to be the deep dive into topics. If you're listening to this on Apple podcast, for example, you should be able to just view chapters and skip to a chapter that you'd prefer. .
[00:03:51] Alex Volkov: I want to just do a quick recap of ThursdAI for February 22nd everything we've talked about for today and we started the space with a with two I guess Matt Schumer and mark Heaps from, and that's Groq with a Q at the end, not Groq with a K at the end. So not like X ais Groq. Groq is explo on our timelines recently with just incredible viral videos of them performing l la inference on LAMA two 70 B and Mixtral with around 400 or 500 tokens a second, which is.
[00:04:34] Alex Volkov: Five times as much as the previous super fast API inference that we've seen for perplexity and from together. And they're serving like Lama 270B with 500 tokens a second. And so we've had Mark from Groq talk to us for almost an hour about how this is even possible. So we had a very nice deep dive with Mark and definitely if you miss this, please check this out on, on the recorded portion as well.
[00:04:58] Alex Volkov: And then we also had Matt, who works at HyperWrite, and he's been playing with these tools, and he told us about the demos that he was able to build, and How much of a difference this speed of inference makes. We've talked about their custom chip called LPU, and we've talked about the fact that the company's been around for a while, and they did not expect this explosion in virality, but they're very happy that they chose this direction correctly.
[00:05:21] Alex Volkov: Very great interview, great conversation, and I invite you to listen to this as well. We covered that Google image generation is now in hot waters, and was reportedly paused because it's in injecting prompt stuff that they're not that great, let's say. And many people notice that historical figures are being generated in different races, and different multicultural adjustments are happening to your prompts, which is not great.
[00:05:46] Alex Volkov: This blew up on Twitter, and even outside of Twitter, I think folks started writing this in actual Media Google, enough so that Google took down the image generation of people trying to figure out what to do with this. But we also gave props for Google to release Gemma. Gemma is an open weights 2 billion and 7 billion parameter model, and we've talked about Gemma we've gave Google the props for releasing OpenWeights for us, and we had folks here on stage telling how the base model is still yet to be decided, how good this actually is, very fine tunable, we're waiting for the open source community to come together and fine tune the OpenWeights Gemma from Google, and then we also covered the Gemina 1.
[00:06:29] Alex Volkov: 5 loan context again, they released the 1 million, and, Context window support and many folks got access to this and we saw for the past week people playing And doing all kinds of stuff including Matt Schumer who I just mentioned he also got access So he gets all the cool toys and he was able to put , three Harry Potter books in one prompt and ask the model with perfect recall who said what and this could have been part of whatever Existing knowledge, but he was doing this more for a demo We also saw demos of people putting an hour long video in the prompt which is around six hundred or five hundred thousand tokens Which sounds ridiculous that it supports it and the model was able to understand this whole video And tell you which scene happened when, with almost near perfect precision.
[00:07:13] Alex Volkov: And we've talked about how this changes the game for multiple things, and we're gonna keep updating you about these long contexts. And we also brought this to Groq and said, Hey, are you gonna support long contexts with your insanely fast speed of inference? We also covered that news Research Tech released a new service DPO fine tuned, which is better in every possible benchmark on top of their ori already strong flagship models which is great.
[00:07:37] Alex Volkov: And I covered that. I went to San Francisco to host an event with a 16 z and news research and Mistral and All Lama and a bunch of other folks, and it was a great event. And I shout out to A 16 z folks for hosting this and inviting me. There as well. And then last thing we've covered is two AI art and diffusion stuff where ByteDance releases SDXL Lightning, which generates 1024 super high quality images in just two or four steps and they look incredible and super fast to generate as well.
[00:08:08] Alex Volkov: I've talked about the demo that I built with them and I've talked about this example that File. ai has where you can go to fastsdxl. ai and just type and as you type, the image generates on the fly [00:08:20] with around 300 milliseconds of inference time which feels real time and feels quite incredible. And following that, we have breaking news today from Stability announcing Stable Diffusion 3.
[00:08:30] Alex Volkov: which is a diffusion transformer, which we've covered before, a diffusion transformer based image generation model from Stability. They announced a waitlist that you can go and sign up for right now. And it looks like it's significantly better at following very complex prompts, like multiple objects and colors and everything in one prompt.
[00:08:47] Alex Volkov: This is everything we've talked about on ThursdAI
[00:08:49] Introduction and Welcoming Remarks
[00:08:49] Alex Volkov: Yes.
[00:08:55] Alex Volkov: All right, folks, you know the sound. Those of you who come back week after week, you know the sound. This is ThursdAI. My name is Alex Volkov. I'm an AI evangelist with Weights Biases. And I'm joined here on stage by, from week to week, by experts, friends of the pod, and new folks who actually were in charge of the news that we're going to talk about today. And Today is February 22nd, only February 22nd, and already so much happened this year with AI. Last week was crazy, this week was less crazy than last week, but still, so much to talk about.
[00:09:36] Introducing the Co-Host and Guests
[00:09:36] Alex Volkov: And I'm delighted to have my co host Nisten here. Hey Nisten, what's up?
[00:09:43] Alex Volkov-1: Hey
[00:09:43] Nisten Tahiraj: everybody,
[00:09:44] Alex Volkov: How's your week?
[00:09:45] Nisten Tahiraj: I'm just it's been the usual, just up until 2 or 3 a. m. on random Twitter spaces finding, because sometimes stuff gets pretty,
[00:09:57] Nisten Tahiraj: it's pretty exciting.
[00:09:58] Alex Volkov: Yep, stuff gets pretty exciting from week to week. I also want to say hi to Matt Schumer, joining us for a brief period. Matt, you've been all over my feed this week. How are you doing, buddy? You've been here before, so folks may not remember you. So please introduce yourself briefly, and then we'll chat.
[00:10:16] Matt Shumer: Hey man, thanks for having me.
[00:10:17] Introduction of Otherside AI
[00:10:17] Matt Shumer: Yeah, so I'm co founder, CEO of Otherside AI. We are the creators of Hyperite, which is one of the largest AI writing platforms. And we also. I've been exploring the agent space for a couple years now about a year publicly creating AIs that can actually operate your computer.
[00:10:31] Matt Shumer: As I mentioned, unfortunately, I do only have 10 minutes. I will potentially be able to join back up after so I'm really sorry about that. It's been a crazy day but excited to chat in the time that I have.
[00:10:42] Alex Volkov: Alright, awesome. Thanks for joining. And then I think we'll just jump in into the conversation. And I want to say hi to our guest a new guest.
[00:10:50] Introduction of Mark from Groq
[00:10:50] Alex Volkov: I don't, I haven't talked with Mark before. Mark is Mark, feel free to unmute and let us know some of your background and where you're joining from. And then we're going to talk about the stuff that we're here to talk about.
[00:11:05] Mark Heaps: Yeah, how's it going guys? Thanks for letting me join the space today, and glad to see some familiar names from all the craziness this week. Yeah, I'm the Chief Evangelist and Head of Design, Brand, and Creative over at Groq, which is probably a little bit not a normative title for folks that are so deep in the AI developer space, but we actually do a lot of the technical side too, so glad to be here.
[00:11:28] Alex Volkov: Awesome. And so folks who are listening, that's Groq with a Q at the end. So not X's Groq. And you guys have been around. For a little longer than them. But just in case folks get confused, there's like a few confusion points here. And I think this is a good start for our conversation today. And I wanna turn this to Matt, because Matt, you're the first person who I saw post about Grock. I think this week, and some of your stuff got a bunch of attention. So give us like a brief overview, like what you saw that made you post. And then we're going to talk about this insane speed and then maybe turn to Mark into how it actually is done.
[00:12:02] Alex Volkov: So what is, where's Groq? Like, how'd you get to it? And how viral did you actually get?
[00:12:08] Matt Shumer: Yeah, it's a funny story. I actually found Groq I'd say more than a month ago and immediately I was blown away I think my co founder posted actually a text I sent to him, and I was like, you have to fucking try this thing right now, it's incredible and he did, and he was blown away too, I actually went and posted about it back then, but it got no traction, I think I deleted it or something and I was just letting it marinate in my mind what was possible here, but, I wasn't sure, if this Scale obviously this week proved that thing wrong clearly it can but I was still just thinking about it, and then I was just on the train, my girlfriend and I were just sitting there on Sunday, and she just fell asleep, so I was like, what am I going to do right now, and for some reason, I thought of Groq, and I was like, okay, let's just post about it again, see what happens, and for some reason, this time, by the time I got off the train, it was going crazy viral.
[00:12:55] Matt Shumer: I, Sunday night was fun, I was up pretty much all night just managing the blowback from this. Finally fell asleep by the morning, I woke up to a timeline filled with tweets about Groq and for good reason, right? This thing is incredible, and it's going to change how we think about how we work with LLMs, what they're capable of, the ability to do tons of reasoning, right?
[00:13:16] Matt Shumer: All of that is now going to change, and a lot more is now possible. The one thing I wasn't sure about was, would this thing go down, right? With all this usage, would this thing go down? And, it hasn't, right? There was a brief time where there was a little bit of delay, but, more or less, it pretty much stayed up the entire time, which is crazy, through all of this, and they weren't prepared for that, which was incredibly impressive, and I think it's a testament to how good the hardware is.
[00:13:41] Matt Shumer: It's just exciting to see. I actually spoke with Jonathan, the CEO of Groq yesterday, and he said that something like 300 developer API requests were submitted prior to the tweet. Now they're getting like 3, 000 a day or something, which is insane. Using that as a proxy for how many people must be trying the actual API, and then combine that with the demos I built that are getting thousands of hits every day, their servers are still clearly standing, which is,
[00:14:06] Exploring the Impact of Groq's Speed
[00:14:06] Alex Volkov: So what was impressive to you? I think we're dancing around the issue, but for folks who didn't see your viral tweets, what was the head explosion moment.
[00:14:14] Matt Shumer: You have TogetherAI, you have HuggingFace, Inference, you have VLM, all this stuff, right? You're getting on, let's say, Mixtral, if you're doing incredibly well, 100 tokens per second or something, right? Most people aren't reaching that and that number may be off by a little bit, but at a high level, you're getting around there with any pretty standard model today, if you're doing well.
[00:14:34] Matt Shumer: Now, going above 200? Unheard of. 500? Ridiculous, right? And that's where Groq sits, right? They've essentially developed a chip that enables these language models to be far faster. And when you see 500 tokens per second versus, let's say, 50 or 100, it is not just a small difference, right?
[00:14:52] Matt Shumer: This is like a step change in what is possible with what you can build with them. And that's what turned my head, right? It's not just faster inference, it's a whole other paradigm that you could build on top of right now, right? When you have inference that's fast, you can then do, 5 to 10x the reasoning in the same amount of time.
[00:15:10] Matt Shumer: How much better does the answer get with the same LLM if you do that? You could do interfaces that are created for you in real time. You don't have to wait. For example, right now on the HyperWrite platform, it's probably one of the best sort of conversational platforms with web search built in, but you still have to wait for it to go and execute the web search, come back, write the response, think through what it needs to do.
[00:15:28] Matt Shumer: What happens if that's instant? That changes everything. That's what got me super interested. Here's what others think about it though.
[00:15:35] Alex Volkov: Yeah I wanna chime in here. Thank you, Matt. I saw your tweet immediately What? And also, A day before I saw your tweet and we're going to talk about long context and maybe after you're gone, maybe you'll come back as well. But a day before I saw your tweet, I posted something where folks were complaining about kind of the long context with Gemini 1.
[00:15:53] Alex Volkov: 5 Pro with the million. That's saying, oh, it's going to take too long. It's going to cost too much, et cetera. And I posted something like, that's not going to, that's not going to be the truth forever. These things are coming down faster than people realize, and I think those things together just one after one, to show me how fast we're moving, how incredible this is, because and we're gonna talk about long context here in a second as well, but Immediately a day after I saw your tweet, I was like, oh, there's an example.
[00:16:18] Alex Volkov: This is exactly what we're talking about. Just I didn't expect it to take a day. So I want to turn the conversation to Mark real quick.
[00:16:24] Discussion on Groq's Custom Chip
[00:16:24] Alex Volkov: Mark, you worked in Grak. How long have you been there? Tell us about this custom chip you guys have. What's going on? How are you achieving this insanity? 500 tokens a second for Llama70B, which is quite big.
[00:16:38] Mark Heaps: Yeah. Happy to. And [00:16:40] Jonathan actually called me and told me that he spoke to Matt yesterday, and I said, I think we owe Matt a, a very nice steak dinner and maybe a little bit more than that. I also didn't sleep at all that night because there were so many requests coming in and Matt's right, like we weren't really ready for it.
[00:16:55] Mark Heaps: We were literally just discussing. The day before what are some other demos we can do? What are some things we can show people with the speed? And then all of a sudden, Matt did a post and then a number of other people that follow him started doing posts. And, next thing I know, people are making their own video demos and it blew us all away.
[00:17:11] Mark Heaps: We're like, wow, this is amazing. I owe a big thanks to the community that have jumped on this. The, this is the magical moment. I think anybody that's worked in tech has seen this before. I've been working in tech for about 30 years. And there's this rubber band effect where one end pulls forward and then you have the whiplash from the other side.
[00:17:30] Mark Heaps: And software developers have been doing an amazing job in AI for the last couple of years trying to, find more efficiencies, eek out better inference, trying to get, anywhere they can that optimization. But, classically what happens is you push that to a point where you start seeing a ceiling.
[00:17:46] Mark Heaps: And then hardware comes along and says, Oh, you're driving the car at max speed? Let me just give you a new engine. Let me give you, something that speeds that up. And we've seen people saying that they have an inference engine. But ultimately they're really just these brokers of other forms of cloud compute.
[00:18:01] Mark Heaps: And then again, eking more capability out of it through software. And Groq was completely different. I've been there now for about four years. And I remember when I originally met the CEO, Jonathan, I said, why does anybody need to do this? And he told us the story about, him creating the TPU over at Google.
[00:18:19] Exploring the Future of AI with Groq
[00:18:19] Mark Heaps: And it was a pretty interesting moment. Jeff Dean had told the team at Google, Hey we've got really good news. We figured out how to get AI working and get, these certain services working like image and speech, etc. But the problem is it's going to cost a fortune to expand our data centers to be able to handle this capacity.
[00:18:36] Mark Heaps: And then they realized they needed to invent a new chip to do that. We're seeing that repeat itself right now. where there was this low latency ceiling for everybody in regards to incumbent or legacy solutions. And he knew from day one that, everybody was out there training models for years.
[00:18:53] Mark Heaps: And he said, one day, this is all going to turn around and everybody's going to want the world's fastest inferential latency. And he didn't know exactly where that was going to be a product fit, but he did know that was going to be the problem statement. So that's what they, that's what they started with.
[00:19:06] Mark Heaps: And it's a radically different architecture, totally different methodology and approach. It's been a really fun journey learning about that architecture. Yeah.
[00:19:14] Alex Volkov: And like the. The public demo that you have, that's very easy for folks to just go and test this out on their own. I think it to be honest, it's awesome that you have this, and I think it undersells. The insanity of what this is, and I think when I hear about what Matt is building in the demos, and I had to play with this yesterday, I had to play with this myself to figure out what to do with this, because I saw many people react and say, hey, what's the point of 500 tokens per second when the reading speed of humans is I don't know, 50 tokens per second, whatever, and I'm looking at this tweet and I'm just like face palming, I was like, what, you don't, do you not
[00:19:51] Mark Heaps: Oh, thank you.
[00:19:52] Alex Volkov: Do you not what's going on? So I had to go and build something. I built I'll tell the folks in the audience. So I used actually two technologies. We're gonna talk about the second one today. I used two kind of super fast advancement that we had this week, which another one was a stable diffusion SDXL Lightning from, I think TikTok, I think released this.
[00:20:09] Alex Volkov: And I decided to just combine both of them, and I have a video, I'm gonna post it up on the show notes and on the demo right now, on the stage right now. But folks, don't go looking at this right now, go look at this afterwards. And I basically figured, Hey, if this is like as lightning fast as this is, I don't have to like, I'm like 400 tokens a second, 500 tokens a second, basically instant, I can use whatever Mixtral or you have Lama270B there, you have Mixtral, and hopefully we're going to talk about more models soon.
[00:20:37] Alex Volkov: And I can use this SDXL Lightning to just immediately deliver to me results. So I used Llama as my kind of prompt writer via Groq, and then I used this SDXL Lightning as my image generator, and I have a demo there that everything there appears in real time. And it's quite powerful and, to the person who said, Hey, the reading speed of people is 50, 50%.
[00:20:59] Alex Volkov: That person doesn't understand the impact of this. They will have an agent, for example, Matt was talking about agents and agentic stuff. The impact of this is just being able to build LLMs into every possible nook and cranny of software. I just wanted to highlight that, that I had to play with this to understand, really.
[00:21:14] Alex Volkov: And, Mark maybe let me ask you what kind of like inventive demos and stuff that you saw coming up from folks specifically around the fact that some of this stuff would not be very helpful with slower inference speed? Did you see any like cool examples of your own? Did you guys like, in slacks, did you send the examples between each other?
[00:21:32] Mark Heaps: Yeah, there's been a lot of chatter at Groq, and I think Matt's was the first one that kind of blew me away. He, he built a demo. And then I think his second demo was this one that wrote a novel, and it wrote it in like under a minute or something
[00:21:45] Alex Volkov: you want to tell us about this before, before you drop off? Because while I got you here, I would love to hear. Yes,
[00:21:56] Matt Shumer: because I wanted to go to sleep. And I knew I had to get it done, and I wouldn't have slept if I didn't. So that was this answers engine, very similar to Perplexity. The idea there was Perplexity's got this incredible, Embeddings based system likely it's really fast and allows you to answer questions really quickly so anybody going up against them they can't exactly do that because without that engine, it's going to be way slower but with the LLM that's as fast as Grox hosting of it, you can essentially do it in the same exact time or even faster while waiting for a pre built, search API to come back with results.
[00:22:28] Matt Shumer: And it worked. So basically, obviously after time it got a little slower because a ton of people were using it, but at the beginning it was like a second to answer for a very complex question. You could have it write a long thing based on something. So basically a really good answers engine. That was the first one.
[00:22:42] Matt Shumer: The second one was writing a novel in a minute or something. That came from a repo that I open sourced, I want to say like almost a year ago now. And that was called GPT Author. Originally the idea was to use GPT 4 to write a novel for you. The quality is obviously okay, it was just experiment to see where it went but people really took to it, so I decided to rebuild it.
[00:23:02] Matt Shumer: With gbt author originally, with gbt 4, it would take like 20 minutes to write, let's say, five chapters. The crazy thing is, with Groq, I added like three more layers of reasoning for each chapter, and yet it still computed it under like a minute or two. So that was pretty crazy. And then the third demo I released, which kind of went More volatile than the rest.
[00:23:24] Matt Shumer: That was basically a code tool that refactors code and documents it. So basically, it's a very simple design. You paste in some code. We have one Mixtral prompt essentially suggest improvements. Based on those improvement suggestions and the original code, we have another Mixtral go and make those improvements.
[00:23:45] Matt Shumer: We display the diffs and then based on that we have another Mixtral explain what happens and Give the user an understanding of what happened, and then we have a fourth one go in and document it. And this all happens, if I were building this for production with today's models and today's systems, I would probably go and try to make some of it async so that it's faster to the user.
[00:24:05] Matt Shumer: But with this, I built it sequentially because I didn't even have to go and do that. It all still computed in a second. By the time I was done reading the code changes for, or the suggestion that it was going to do in the first place, it was already done refactoring the code, already done documenting the code, which is crazy.
[00:24:20] Matt Shumer: So that one did pretty well. Those are the three demos I made. Maybe I'll do some more in the coming days. Yeah.
[00:24:24] Alex Volkov: that's incredible, dude, and I keep thinking about like more use case for this. Yesterday I used Cursor. Cursor is the editor, if you guys don't know, like AI native editor, uses I think GPT 4 behind the scenes, embeds a bunch of stuff. And I haven't been able to play with CursorFully until yesterday's demo, and I played with this, and it has GPT 4.
[00:24:42] Alex Volkov: And I think they have a specific faster access to GPT 4, if you pay, and we do pay. And I was playing with this, and I was getting support from my editor on my code, and it was slow, and I was like, I want it immediate. I want it instant. And I think that's what Groq of promises.
[00:24:59] Alex Volkov: Mark, [00:25:00] so let's talk about how you guys actually do this. You said something about the custom chip. What's as much as you can go into the secrets and also keep in mind that this is like a high level space here on Twitter. What's going on? Like, how are you able to achieve NVIDIA's earnings come out.
[00:25:15] Alex Volkov: They did like whatever insane numbers for the past year. Everybody's looking at A100s, H200s, whatever. What are you doing over there with new hardware?
[00:25:23] Mark Heaps: Yeah. The chip has actually been something we've been working on. The company was formed in 2016. And I think we, we taped out that chip, the first generation design, maybe two years after that. And it is totally different. And it's funny, people actually keep getting the category of the processor wrong online.
[00:25:41] Mark Heaps: It's a language processing unit, but people keep calling it a linear processing unit. And a lot of the engineers at Groq think that's fun because they're like technically, it is. It is a linear sequential processing unit, right? And it's some of the key differences at a high level, right? So it's not multi core like a GPU.
[00:25:56] Mark Heaps: It is single core. It was actually the world's first single core peta op processor, which, four or five years ago, that was a big deal. And it's still 14 nanometer silicon, which is a 10 year old version of silicon dye. Whereas, we're being compared to people that have silicon that's four and five nanometer.
[00:26:14] Mark Heaps: And we're completely fabbed in the U. S. It's it's readily available supply. So we don't have the challenges other folks have trying to get GPUs. But the part that's really cool, this is the thing that like I geek out on, right? Is when you think about getting deeper into the development and stack.
[00:26:30] Mark Heaps: And you're trying to set up GPUs as a system. And I'm talking, large data center scale systems. You've got all of these schedulers and things that you have to manage with the GPU and the data bouncing around in the way that it does being multi core and using all these schedulers it's really, what slows it down.
[00:26:46] Mark Heaps: It's really what gives it a latency ceiling. And with the design of the Groq chip, and if anyone's seen a picture side by side it's beautifully elegant. It's it's works in a way that when you connect all of these chips together, you could put thousands of them together, actually, and it will see it as one brain.
[00:27:06] Mark Heaps: So let's say that you realize for your workload you need 512 chips. You can tell that, hey, I need you to be one chip. and load your models that way. Or if you wanted to run some things in parallel, like we've done with an application we have called Groq Jams that writes music in independent tracks, linear and parallel to each other.
[00:27:26] Mark Heaps: So that they're perfectly synced, we can say no, make those chips eight chips because I want eight instruments. So I'm gonna use eight instrument models to do that. You can literally do that with one line of code in PyTorch and you can refactor that way. And so this is, the advantage that they've had with the way that they approach the chip design and that in itself was the, probably the most radical thing that Jonathan and the team were the inception of.
[00:27:50] Mark Heaps: They decided instead of designing hardware and figuring out how to improve hardware in a traditional methodology, they said no, we're going to start with the software. We're going to actually design our compiler first, and then we're going to design the silicon architecture to map to that, so that it's completely synchronous, so that it's completely deterministic.
[00:28:10] Mark Heaps: We're going to build the compiler first, and we're going to make it so that no CUDA libraries ever need to be used. That you don't need to use any kernels. We're just gonna, we're just gonna bake it all right in. And so this is where we've seen a lot of that efficiency gain and where we get all that extra power for low latency.
[00:28:28] Mark Heaps: And that's really been the fun thing, for anyone that's, that isn't familiar with us. Our early demos weren't AI related. In fact, during covid we worked with one of the national labs and they had a model. that they were using to test drug compounds against proteins and seeing what drug would stick to a protein.
[00:28:48] Mark Heaps: And, this was in an effort to try to find a vaccine, etc., during COVID. And their model at that time, from what the team told us there, was it would take three and a half days for them to get a result. Every time they put a new drug in, see if it sticks to the protein, okay, did it work? If not, move to the next one in the queue, and let's keep going.
[00:29:06] Mark Heaps: And that was this effort of trying to figure out, what would work. It took us maybe six months back then, because we weren't as mature with the compiler. It took us about six months to get them actually having their simulation running on Groq. When they finally did it, they could do that same simulation in 17 minutes.
[00:29:23] Mark Heaps: So imagine the rate of acceleration to try to find a drug that could actually change the world at that time of crisis. They could do that on Groq in 17 minutes. So the orders of magnitude that we've been able to help people. is, has just blown us away. We've done some things in cybersecurity with one of our customers in the U.
[00:29:39] Mark Heaps: S. Army. But now what we really realize is it's going to change the world for anybody that can take advantage of linear processing. And language is the ultimate linear application, right? You don't want to generate the hundredth word until you've generated the ninety ninth word. And Matt's example is amazing.
[00:29:56] Mark Heaps: Imagine that you can generate a story. You did it with generating a video after having the prompt being generated. My kids, I have a 12 year old son, he's a major gamer, and I showed him using Thappy, which is a voice tool online for generating voicebots. I showed him how to make NPCs with that, and putting in character personas with no code, and it's running on Groq.
[00:30:18] Mark Heaps: And the low latency, he was having a really natural conversation, and he told me, he goes, Dad, I can't ever talk to Alexa or Siri or any of these again, he goes, it's so bad compared to this. So it's just a really exciting time and the secret sauce of it is the chip.
[00:30:32] Alex Volkov: that's incredible. And I think you touched upon several things that I want to dive deeper, but the one specific thing is necessarily the voice. conversations, the embodiment of these AIs that it's still uncanny when you have to wait 800 milliseconds for a response. And I've seen like a YC demo of a company and somebody said, Oh, this is like the best thing ever.
[00:30:55] Alex Volkov: And it was like 100 milliseconds to an answer. And I'm looking at these 500 per second tokens. I'm thinking, This is like a near instant answer from a person and probably a super, very smart person, probably faster than a person would actually answer. And it it triggers something in my mind where we're about to slow these down on the UI level because the back end is not, is going to be faster than people actually can talk to these things.
[00:31:19] Alex Volkov: Nisten I see you're unmuting. Do you want to follow up? Because I bet you have a bunch of questions as well. And we should probably talk about open source and models and different things.
[00:31:29] Nisten Tahiraj: Yeah, so the one amazing thing here that we don't know the number of, so if the engineers could find out, there's something called the prompt eval time, or there's different terms for it. But for example, on on CPUs, that tends to be pretty slow, almost as slow as the speed of generation. On GPUs, it tends to be ten times higher or so.
[00:31:53] Nisten Tahiraj: For example, if you get an NVIDIA 4090 to generate stuff at 100 tokens per second, or about 100 words per second, for the audience, the speed at which it reads that, and it adds it into memory, it's often in about a thousand or a few thousand. What I'm wondering here is that evaluation speed That has to be completely nuts because that's not going through some kind of memory That's just it goes in the chip.
[00:32:21] Nisten Tahiraj: It stays in the chip. It doesn't spend extra cycles To go outside into memory. So The prompt eval time here has to be completely insane, and that, that enables completely different applications, especially when it comes to code evaluations, because now it can it can evaluate the code a hundred times against itself and so on.
[00:32:45] Nisten Tahiraj: So that's the amazing part I'm wondering here, because you can dump in a book and it'll probably Eat it in like less than half a second, which is pretty, it's pretty nice. So yeah, one thing I'm wondering is how does this change the the prompt evaluation time? And what kind of other demos or stuff are actual uses, actual daily uses are you hoping to see?
[00:33:08] Nisten Tahiraj: And can you tell us a bit more as to what your availability is in terms of to production and and
[00:33:15] Mark Heaps: server load. Yeah, absolutely. I think the first one, I want to be a little [00:33:20] transparent about, where Groq was at in regards to the input. When we first started building out the system and optimizing it, we really focused on token generation and not input, right?
[00:33:32] Mark Heaps: So that's where we thought everybody was focused. It's like Gen AI was blowing up everywhere. What can you make, what can you generate? And so we said, okay, the compiler team is working on things. Let's focus on optimization of the system, the LPU Inference Engine at generation. And so we got this wildly fast speed, right?
[00:33:51] Mark Heaps: And I remember some people saying, oh, you'll never hit 100 tokens per second. We hit it, we did a press release. The team literally came back to us two weeks later and said, hey guys, we just hit 200. And I was like, what? And then all of a sudden we hit 300 and we're like, wow, we're generating really fast.
[00:34:04] Mark Heaps: And then we started meeting with some of these benchmark groups, like Artificial Analysis and others. And they were saying no, like industry standard benchmarking ratios right now is 3 to 1 input to output. And we went, oh we need to start optimizing for input. And so we've started working on that.
[00:34:21] Mark Heaps: And even that right now isn't at. The exact same speed optimization of our output and the teams are working on that, at this time, but it's more than capable and it's on the roadmap, it's just a different focus for the group. So we're probably going to see over the next few months about another 10x on the input speed which is going to be wild, right?
[00:34:42] Mark Heaps: Because now when you talk about conversation, a lot of the time humans blabber on, but you tell an agent to respond in a terse and succinct way. Now you completely flip and invert the ratio of what you're going to be able to have. So that's really exciting. And, from a use case standpoint, I actually had a really interesting use case that, that happened to me personally when I was on a vacation with my family late last year.
[00:35:08] Mark Heaps: We were actually traveling and we were in Puerto Rico lionfish. And it was really bad. We were like a hundred yards offshore. We're at like 60 feet deep water and I'm trying to help him get to shore and he's like screaming and I get on shore and the first thought in my head was of course call 9 1 1.
[00:35:25] Mark Heaps: And I went, Oh my God, if I call 911, I'm going to get an operator. We're in this place that nobody can drive to. They'd have to helicopter us out. I was totally freaked out. And I ended up just going into the bot and saying, what do I do if someone gets stung with a lionfish? And in less than a second, I had a 10 step guide of what I should do.
[00:35:41] Mark Heaps: Things that I didn't know, right? Oh, keep his foot in the water. Don't rinse it with fresh water. That happened instantly. Now imagine the world that, that goes from having an emergency Band Aid or burn kit in your house. to having an emergency bot in your house who can help you in those situations.
[00:35:57] Mark Heaps: And so the speed at which it can read the input message and then give you advice back in the output is a complete game changer. And I think Alex nailed it, like we've seen all these comments where people say why do you need to generate this fast? They think of it as like a chat bot only or like a reading only situation, but the reality is, and what we've known for a long time is there's going to be an ubiquity of digital assistants.
[00:36:23] Mark Heaps: And I don't mean like an individual bot per se, but just AI being everywhere to help you. And so that's going to require a massive amount of speed. for you to be able to slice that up across all these services. Like we hear, people building with their demos like Alex said earlier. So that's our goal to serve that.
[00:36:44] Mark Heaps: And, Nisten, you asked about, what's the goal. Right now, again, just being candid with everybody, we didn't expect this thing to go viral. This was not a marketing strategy. This wasn't us going out and paying a bunch of influencers. It just happened and so the system has been like really tested and the amazing thing is it's held up like Matt said.
[00:37:04] Mark Heaps: And so kudos to the engineering team for that. Where we're headed and our goal is by the end of the year we want a token factory to be able to generate millions and millions of tokens per second as a capacity. And so that's the plan right now. We want to be in, roughly 10 months. We want to be where OpenAI was, at the end of last year.
[00:37:27] Mark Heaps: That's our goal right now. So we have those orders placed, that hardware is ordered, and we're building and increasing the capacity every week.
[00:37:33] Alex Volkov: That's awesome. And so let's talk about models. You guys are serving LLAMA270B. And we hear rumors about next LLAMAs at some point soon. And I think Mark Zuckerberg even actually said that like they finished training LLAMA3 or something. We don't have insider knowledge here.
[00:37:48] Alex Volkov: We're just like speculating. And then also obviously Mistral is releasing incredible models. You guys have Mixtral in there. There's speculation the Mistral Next that LMCs has access to is this incredible model, the GPT 4 level. So you guys are relying on open source models, and those models are trained on other hardware.
[00:38:07] Alex Volkov: Do you guys also have training built in, or is this only for inference? And what are the plans for also training models? Because, speeding up training would help the world at least as much as speeding up inference.
[00:38:18] Mark Heaps: Yeah. So let's tap into a few of those. So first, we love the open source community. It was a big inspiration why Jonathan left Google, where he was wildly successful. and said, we need to go start another company. And he wanted to make sure that the world and the developer community had access to AI technologies to accelerate development.
[00:38:38] Mark Heaps: He literally calls this the haves and the have nots. And at that time, he said, look, it looks like Google, Amazon, Microsoft, a couple of governments are going to swallow up all of the AI technology in the world. He's that's not going to be fair. He's we need to democratize AI and access for all.
[00:38:55] Mark Heaps: And so let's make a chip, and I remember him telling me this four years ago, he goes, I'm going to create a company where people can literally have access to the most advanced AI in the world, and do it with a credit card from their home. He goes, that's what I want to see happen. And so that's always been his vision.
[00:39:11] Mark Heaps: And, we're on that path right now. The models that now the explosion of the open source community, and I think Meta deserves a lot of credit here. Chad GPT was blowing up, OpenAI was doing their thing.
[00:39:22] The Unexpected Success of Llama 1
[00:39:22] Mark Heaps: And Meta, which is, obviously a massive corporation and private and in it to make money.
[00:39:28] Mark Heaps: They said, no, we're going to make Llama available to everybody. And we didn't have a relationship with them. I think everybody knows Llama 1 got leaked and one of our engineers got ahold of it and said, Hey, I'm going to see if I can fit this to the chip. It wasn't even on our roadmap. And then they got it running in less than like 48 hours.
[00:39:45] Mark Heaps: And then from there we advanced on it. And so that was an amazing moment. Lightning bolt moment where we said, Hey. What else can we do with this?
[00:39:52] The Evolution of Model Compilation
[00:39:52] Mark Heaps: And at that time, I think we had maybe 200 models from Hugging Face compiled for our system. And today, I think we're well over 800.
[00:40:02] Mark Heaps: And we just keep pulling from the repos there and building them into the compiler. But we're watching very closely now of what are the models that people want? We had Vicuña up for a little while and we saw that on The LMSS leaderboard we've played with Mistral 7b.
[00:40:16] Exploring the Power of Mistral 7b
[00:40:16] Mark Heaps: If anybody wants to see real speed, go watch my video on YouTube on the Groq channel about Mistral 7b. It gets over a thousand, it gets over a thousand tokens per
[00:40:24] Alex Volkov: you serious? Wow.
[00:40:26] Mark Heaps: Yeah, I, the max I've hit with it I was just doing a conversational bot with it, and I hit 1140, and it was insane.
[00:40:34] The Excitement Around Google's Jemma
[00:40:34] Mark Heaps: And, now there's this announcement from Google about Jemma, which I think is like 8 billion.
[00:40:38] Mark Heaps: And the team is already Oh my God, what could we do with Gemma, at that size, like the speed is going to be, through the roof. And then Jonathan, our CEO, is traveling right now, and he was actually at the Mistral headquarters in France a few days ago. And they were talking to him about, the next model and kind of what that looks like.
[00:40:58] Mark Heaps: And he very much wants that to be running on the LPU inference engine at Groq.
[00:41:02] The Future of Groq's LPU Inference Engine
[00:41:02] Mark Heaps: So it's an exciting time to get into these open source models. And we're just happy that we can sit back and say, Hey, how do we help you guys? Because ultimately the people building the models, doing the training.
[00:41:13] Mark Heaps: We want to enable them with this speed.
[00:41:16] Groq's Stance on Training
[00:41:16] Mark Heaps: You asked a question about whether we do training. We don't. We don't offer training. We don't do training. We have had one customer actually do it. That was related to that U. S. Army cybersecurity project. They actually trained their quantum algorithms using Groq hardware.
[00:41:30] Mark Heaps: But it's not something we do, and it's not our business model. And Jonathan has always had this vision. He said Look the world already has a bazillion training providers, and [00:41:40] most people are quite comfortable with the pace of training, and this is going back to 2016, 2017. He said let's recognize that if all these companies are training models, and yet there's no real clear winner in the inference solution, let's just focus our business efforts there.
[00:41:55] Mark Heaps: He does have a vision. It's not on our roadmap right now, but he does have a vision.
[00:41:59] The Potential of Live Training Through Inference
[00:41:59] Mark Heaps: of what you could do with this sort of recyclical live training through inference, where it's actually being trained live in the moment and feeding back to itself, right? And this gets you into a multitude of layering techniques that we've been considering and testing at Groq.
[00:42:14] Mark Heaps: I could see us getting into training in the future, but only when it is advantaged by that real time insight of training.
[00:42:22] Alex Volkov: Up here. And Nisten, just before, let me jump in super quick. I want to follow up with something that you said that 7b Mistral is flying at over a thousand tokens a second. And that's obviously incredible. Just like mind blowing incredible. And in my head what I'm super excited by is not the smaller models, because I can run the smaller model on my Mac with 20 tokens, 30 tokens a second and get like a full whatever.
[00:42:45] Alex Volkov: I'm excited about the incredible intense, long context requirements that we've seen. So we had talk about open source. We have often the folks from Nous Research here on stage, the authors of the YARN paper, that they've been able to take LLAMA's 4, 000 contacts window and extend it to 128.
[00:43:03] Alex Volkov: And we never used it. We never were able to use LLAMA at 128k tokens because it was like extremely slow.
[00:43:09] The Power of Groq's Speed in Long Context
[00:43:09] Alex Volkov: And I'm thinking about Are you guys bringing us long context, like for real, like for open source models, because we haven't yet been able to actually use them as much. Because the bigger the model is, and the faster you can run, it will average out, and we'll be able to get open source models.
[00:43:22] Alex Volkov: Have you guys played with long context yet? Have you seen the incredible stuff from, Gemini 1. 5 releasing 1 million tokens, for example. Something that probably only Google can pull off with their TPU farms. How are you thinking about that as an advancement, as a competitive edge for something that only you could do?
[00:43:37] Mark Heaps: Yeah, the team is actually looking at that right now, and I think, again, early stages, our first 4A into a larger length was actually, Mixtral with a 32k sequence length. And, so far we haven't seen any use cases where people are actually taking advantage of that full length, but we know that it's coming.
[00:43:54] Mark Heaps: And the moment that Gemini 1. 5 got announced with the million token length, the team immediately got together and said, okay, how would we do this? And they've started architecting. What scale of system would we need for that? So that's part of the plan in parallel with what I was saying earlier that we really want to get to a place where we're this massive token factory by the end of the year.
[00:44:14] Mark Heaps: And that's getting us into that, more than 10 million to 20 million tokens per second from the system in that capacity. So we're definitely looking at that. I think what's going to really dictate it for us, because we're again, sitting back and saying, how do we help? And what we're watching is what are the business use cases?
[00:44:33] Mark Heaps: So if someone says, Hey, we want to use a model that has a million million contact sequence length. But you find out they're really, on average, only using 50k for their application. This is that advantage I was talking about earlier, where we can dial the system forward or backward using a single line of code.
[00:44:50] Mark Heaps: We can figure out what is that link that they need, and then dial that in for that customer account. We're actually doing a little bit of that right now with Mixtral. You guys mentioned, we have the free version. on our website that people can play with through Groq chat. And then there's the API access, right now, as everyone's playing with it and just treating it as a chat agent, we're recognizing that we've got this thing loaded for 32 K Mixtral.
[00:45:12] Mark Heaps: And yet, the average we see being generated in GroqChat is around 900. At that scale, we're like, hey, why don't we increase the capacity of the system, speed this thing up a little bit. Let's drop the sequence length for the free GroqChat service. But leave it at the longer sequence length for the API users, and that's really easy for us to do.
[00:45:32] Mark Heaps: That's flipping a switch in, in, in some ways.
[00:45:36] The Importance of Community Feedback
[00:45:36] Mark Heaps: So we're just waiting for the open source model community to really tell us like, Oh, this is the size that we could really take advantage of.
[00:45:43] Alex Volkov: Awesome. So you guys found the right place. The open source model community often ends up on ThursdAI and talk about their advancement. So I'd be more than happy to introduce you to the guys who are doing open source kind of papers on long context as well. They're often joined here and they would be very happy to like help and figure out what's the, what's possible, especially because training those models is hard, but then running inference is even harder.
[00:46:07] Alex Volkov: Nisten.
[00:46:08] Mark Heaps: Way harder.
[00:46:08] Alex Volkov: Yeah, Nisten, go ahead.
[00:46:11] Nisten Tahiraj: Yeah, so one thing I'm wondering about is, so first of all, it's extremely impressive that these models are running at full precision and they're not even starting to take advantage of some of the handmade stuff that people made to get them down to the, to phone size and to still perform well, because that takes yeah, so that hasn't even been explored yet, because that can reduce the size by four and have exponential improvements.
[00:46:36] Nisten Tahiraj: So what I'm. wondering is, how much, as you guys expand and as you go and as you adopt, whether you adopt our models or not, how much work is it to Take something like LLAMA or Mixtral and then adapt it to more of your JAX like stack That you guys have. So yeah, that's the part that I'm Wondering about like how much work is for companies to adopt their own models or if they have something custom that they've made to this because I see some incredibly interesting stuff and I think for Sorry, I'm rambling on a little bit, but I think even for training you can make models that fit under 220 megabytes or model parts, and then you can train those individuals.
[00:47:22] Nisten Tahiraj: So there is stuff to be it. Explore there. I just think there hasn't been enough yeah, it's still pretty new, so there hasn't been enough people taking a crack at it. But yeah, how much work is it to take an open source model or a custom something that people made and to adapt it to work on Groq's hardware?
[00:47:40] Nisten Tahiraj: That's my question.
[00:47:41] Mark Heaps: Yeah, it's a great question. Thanks, Nisten. Yeah, so I think a really good paper everyone should check out if you're interested in this, if you go to Groq. com slash docs. We've got a huge doc repo there. And one of the earlier articles that we produced from the compiler team is called Developer Velocity, and it's been a, it's been a focus from day one.
[00:48:00] Mark Heaps: We did some research when we were building out the product, building out the service, and we found out that for a lot of companies to get a model up and running, especially if it was their model. It would take them, if you were a smaller company let's call you, an SMB, sub 5, 000 employees.
[00:48:15] Mark Heaps: They were typically spending six to nine months to get a model into production where they were using it. The larger companies, Microsoft, those guys, they're doing it in 30 to 45 days. And so we set this goal saying, we don't want any customer ever to need more than a week to get their model up and running on Groq.
[00:48:34] Mark Heaps: And ideally we'd like it to be in 24 hours. We're actually going to test the team on that when LLAMA 3 gets released. We're going to see how fast from the day everybody has access to it, to how fast can we get it up and running. And, I'm hopeful we're going to, we're going to see a demo with it literally that day or the next day.
[00:48:49] Mark Heaps: It's not a lot. We're using standard frameworks, right? So we're PyTorch, Onyx, Tensor, everything is pretty standard. The thing that we spend a lot of time doing this in, and this is what slowed us down a little bit when Llama 2 came out I did a video with Bill Ching, a member of our compiler team.
[00:49:06] Mark Heaps: He's a brilliant guy, super funny. He'll tell you in the video, I didn't spend time getting it to fit to Groq. I spent time removing All of the code and components that were built in for GPUs. Basically, he spent time scrubbing, not, building. And that's what happens is because the community is so already weighted towards building for GPUs, that's what takes us the most time.
[00:49:30] Mark Heaps: We've got to strip all that stuff out because it slows it down. Again, we don't have those schedulers. We don't have those components. That's the biggest thing for us in the way that, that we get things running. But, even custom models that we've had from the national labs and the research groups, we had one that was for the Tokamak nuclear fusion reactor.
[00:49:48] Mark Heaps: It was a control system. And even that we got running in just, I think it was less than 10 days. And it was a completely custom build and our compiler was no more mature at that time. Again it's one of those [00:50:00] things that our goal is to get it down to where it's same day applicable.
[00:50:03] Mark Heaps: We're a ways off from there, but right now we're trending less than a week for everybody.
[00:50:09] Alex Volkov: Mark, I want to follow up with the use case. As you guys were talking about converting models, and we see models getting released from all these finetuners. We have a bunch of folks here who finetune models after open source release, and many of them switch to Releasing their models in the safe tensors format, the standard one, but also in the quantized format that people can actually download the smaller quantized versions and run them on their Macs.
[00:50:33] Alex Volkov: And I can absolutely see if you guys support this, I can absolutely see a day where folks are releasing it also on Grack or Grack chat or whatever, just for folks to be able to experiment with like longer context. As a fallback, sorry, as a follow up on the longer context one session, you said. we see in the chat.
[00:50:49] Alex Volkov: Yeah, the chat is not optimized for, pasting like a bunch of stuff. I, I would I would not suggest, I would be cautious about judging by that because I personally, if I get access or I guess I got access to the API, but when I get access to longer context, for example, I would absolutely think about, hey, what is possible now?
[00:51:08] Alex Volkov: I can, and somebody commented in the comments that coding is the main use case where long context really matters. Because what happens right now is everybody's like focusing on rag. And we had this conversation, rag versus long context, I think since a year ago, since the context lengths were 4, 000 tokens, then 5, 000, then 12, then whatever.
[00:51:25] Alex Volkov: And then Mosaic came out with 60 and we were very excited. And we had this conversation since then of what performs better. And I think one of the two main reasons that folks And I don't know about cost, and we probably should talk about cost, but infraspeed, you guys are doing some incredible advancements.
[00:51:46] Alex Volkov: In my head, as somebody who builds systems with this, as somebody who plays around with this, if I can shove my whole codebase In the context, I will get a better answer than I'm gonna have to embed the context, the code base, and then try to do retrieval on specific chunks, whatever. I'm even thinking about the cursor interface that I used yesterday.
[00:52:03] Alex Volkov: I, I had to provide it with, I had to mention, hey, these docs that you already vectorized, add them to, to the context, so GPT 4 will be able to help me solve my specific issue. If my whole repo is getting sent in each prompt, I don't know if this is the best use case of your hardware, but it's definitely the, probably the fastest way to get the model to actually know exactly what I want.
[00:52:23] Alex Volkov: That's one example. Another example is all these models, all these agents are going towards personalization. I definitely think that this year is the year of personalization, especially with like longer context and models like Gemini 1. 5, for example, they have a full retrieval precision, almost like 95 needle, in a haystack recall ability.
[00:52:42] Alex Volkov: And that, for use cases like something like a personal assistant that remembers everything about you, removes the possibility of, hey, I didn't chunk correctly, I didn't do rack correctly, I did vector similarity incorrectly, etc. For developers just getting up and running and building tools like this, I think long context is still yet to be discovered because it's still expensive and it's still slow.
[00:53:02] Alex Volkov: And I think speed with a lot of context is what's going to unlock the next iteration. So those are just like some feedback from the community staff. Would love to hear what you think.
[00:53:10] Mark Heaps: Yeah. So first, I love these ideas, and I want to invite everybody who's listening go join our Discord server, because we want this feedback. We, the product team is super hungry for it. We want to know what you guys want. So definitely go do that. It's Groq. link slash discord. Please bring all these ideas to us.
[00:53:26] Mark Heaps: It's an interesting thing, Alex, because we've heard this from a number of customers of, do you do RAG? Do you do some form of vector database? We get asked about Lang chain. We get asked about all these things. And I think for us, there's this risk of where is the infrastructure, that part of the stack with RAG, where is it?
[00:53:44] Mark Heaps: Where does that exist, right? So if you're operating in these two totally, vast separated areas, you run the risk of losing your latency just because of the network and kind of what happens between them. So for a lot of folks, we hear no. We want the longer sequence length because we want to embed a lot of this in the sys prompt.
[00:54:03] Mark Heaps: And we know that Groq has such fast inference that if it's embedded there, it's all living with you. And we're going to be able to maintain that speed. If you start calling out to a bunch of different rag services, where am I going to lose? Now, I think that's thinking that's based on the experience they've had with GPUs, OpenAI, ChatGPT, etc.
[00:54:23] Mark Heaps: But, for us, if we have such a margin of inference speed, we haven't seen anyone really lose on the overall experience performance because of the network topology. Jonathan was doing a demo for somebody literally using Wi Fi on a United Airlines flight where we had information in a rag and he was calling it, using Wi Fi on the plane.
[00:54:48] Mark Heaps: And he was like, it was a very normal speed experience. He was disappointed because it felt he was using ChatGPT,
[00:54:53] Mark Heaps: For the person there,
[00:54:54] Alex Volkov: It's hard to go back after, after you experience immediacy. Waiting is definitely annoying. That's I'm waiting for the hedonistic adaptation of ours to kick in where we expect immediacy. Yeah, sorry, please go ahead. I have to chime in.
[00:55:06] Mark Heaps: No. Yeah. No, I think you're, I think you're spot on. So yeah. So again, we don't want to dictate to anybody You know, what is the best method? We want to listen to you guys and figure out how do we continue to serve in that way? And, the other reality is there's gonna be new techniques that are gonna be invented, in the next couple of months probably, that, that give you a whole nother option, around rapid fine tuning.
[00:55:31] Mark Heaps: And we're just watching. And listening to you guys, but we recognize we need to enable both. So we're working with some partnerships for RAG right now to be able to connect into Groq. And there's going to be some announcements actually tomorrow about some things happening at Groq that I think people will be excited
[00:55:47] Alex Volkov: Ooh, you want to give us a little teaser, a little laugh, or are folks going to tune in for tomorrow? We gotta tune in for tomorrow.
[00:55:54] Mark Heaps: I I think the only thing that I'm allowed to say is there's really going to be a very strong representation of the developer community. Within Groq, and the tools that we're gonna start rolling out over the next couple of weeks are really gonna feel familiar and hyper supportive of the work that y'all do.
[00:56:11] Mark Heaps: So it's gonna be, it's gonna be really fun.
[00:56:13] Alex Volkov: Alright, so folks, stay tuned, definitely we pinned the discord link to the top of the space check it out and give folks comments because you guys have a bunch of headroom and we need to use this, but we need to tell you in which way we're gonna use this so you also have it. a roadmap, you have prioritization issues like every company, you have to focus on something.
[00:56:30] Alex Volkov: So the better folks will give you feedback, the better. I want to maybe one last question, Mark, before I let you go, and then continue with the regular thing, which you're more than welcome to stay and chime in as well on, because I did see your thread.
[00:56:41] The Potential of Multimodality in AI
[00:56:41] Alex Volkov: I think you're also interested in the broader AI community.
[00:56:44] Alex Volkov: It's multimodality for 2024. I think It's clear to everyone that multimodality is built in. All the major labs are now multimodal. I think multimodal AI is in open source is coming as well. We have folks here who've trained multimodal models. What are we to expect from Groq on that perspective?
[00:57:01] Alex Volkov: Is it? Do you guys already have support for some like a vision plus plus text? Are you looking at different things like, video as well, which by definition takes more tokens and then slower by definition in every other place? How is the team thinking about this kind of next evolution of Gen AI?
[00:57:19] Mark Heaps: Yeah, good question. Obviously, multimodal is where everyone's interested. And I think ever since OpenAI gave ChatGPT the capability to generate images in the middle of the conversation and then add audio into the middle of the experience, everyone's been excited about this idea. And certainly that's where we've started.
[00:57:37] Mark Heaps: We have a plan we call them the three pillars, right? And it's where does Groq add this speed value in? Language in audio and in visual. And what we're looking at right now is what are the models that we can bridge together so that we can provide that multi modal experience. The systems teams are already preparing the LPU inference engines that we're expanding on to be able to handle that.
[00:58:03] Mark Heaps: The compiler teams are actually, have already begun building out some of the advancements we need to be able to support that. We know where it's going and we know, that's what people are going to be asking for. So I've only shown one other thing. on our YouTube channel, which was a model that [00:58:20] Adobe gave us, which was a style GAN, and that was 8 models that run in parallel, and I think it generates in like 0.
[00:58:28] Mark Heaps: 186 of a second at 1024 pixel resolution. We can literally say, here's an image, give me 8 completely different styled results based on that, that diffusion model or that style GAN model. And that's where we've started playing with image generation. We do have some people that are looking At tiny diffusion and a few of these other like rapid generators that are small.
[00:58:47] Mark Heaps: But certainly that's something that we intend to support. It's the problem now with the speed of all these things happening is what do you prioritize? We are a company of, less than 200 people. And we're trying to, we're trying to figure out every day, like, where do we commit our resources?
[00:59:02] Mark Heaps: So again, it sounds like I'm trying to be like a marketing guy and I'm not. Go to the Discord and tell us what, you guys want. What are your use cases? What are you predicting with your businesses? That would really help us to be a part of the, to be a part of the conversation.
[00:59:16] Mark Heaps: But at the high level, yeah, we already have people working on it.
[00:59:19] Alex Volkov: Awesome, and I definitely invite your folks to also join the ThursdAI community, because we talk about these advances as they happen, we've been talking about multimodal, multimodal since almost a year ago now, folks, everybody in the audience, we're going to celebrate ThursdAI's birthday, I think, in a couple of weeks, and
[00:59:36] Mark Heaps: Nice, that's cool.
[00:59:37] Alex Volkov: when GPT 4 came out they had the infamous demo where Greg Wachman jotted down on a napkin, a UI thing, and uploaded it to the GPT 4 with Vision, and we've been waiting for this to become a reality ever since, and I think it's now becoming a reality.
[00:59:51] Alex Volkov: We also chatted with, the folks from Reka AI, which, had the multimodal model out there a couple of weeks ago that I was blown away by. I was uploading videos of mine and it understood tonality in there, understood like what happened in the video. We obviously see video being a big part of Gemini 1.
[01:00:08] Alex Volkov: 5, we're going to talk about this soon, where people just upload and that video just takes so much content, like 600, 000. tokens in context. But then the model understands like every little frame and can pull individual scenes away. And once we get to real time video understanding, that's when the actual World embodiment of these bots will happen when like it can actually see what and can react in real time.
[01:00:29] Alex Volkov: So definitely exciting stuff from there. And Mark, I just wanted to say What an incredible week you guys had and it's been great to just see how this explodes and play around with the possibilities I'll remind folks in the audience. I've played and it's on the it's on the show notes in the Jumbotron I played with Groq yesterday and it was I was able to build something that I wasn't, thinking about it's possible a few months ago, even.
[01:00:54] Alex Volkov: It's so fast. And you already mentioned the Discord. How do people get access? Is the wait list long? Tell us about people in the audience and then the questions. The one API access .
[01:01:03] Mark Heaps: The waitlist is really long right now, and it blew up this week. Again, thanks Matt for, and others for promoting. Yeah, so right now they can go to Groq. com. They'll see a link on the left that says API access. You fill out a brief form right now. We are trying to get through that list as quickly as possible.
[01:01:20] Mark Heaps: There's a timed trial, the usual sort of terms. But in a week, it wasn't even a week, it was literally within 37 hours, we had over 3, 000 API access key requests. And so that was more than we had expected. And so we're trying to get through that list right now and see what the tier levels, some people are telling us we need a billion token per day access.
[01:01:42] Mark Heaps: And we're saying, okay, this is this tier level. And other people are like, hey, we're part of Y Combinator's startup accelerator group. We're just testing our bot ideas out, can I get free access? So we're working through that list right now. The good thing is. We are increasing capacity every week, and one of the announcements that we'll have tomorrow and rolling into next week will be moving more towards self serve versus us going through and like manually approving everybody, so that should accelerate approvals greatly.
[01:02:10] Mark Heaps: I just ask everybody be patient. If you've applied, stick with us. We promise we're going to get to you. We really want you to have access to this. This level of inference speed but this whole virality moment came out of
[01:02:21] Nisten Tahiraj: nowhere and we,
[01:02:23] Mark Heaps: We're trying to meet the needs now.
[01:02:25] Mark Heaps: So just stick with us. It's going to keep getting faster and faster.
[01:02:28] Alex Volkov: Incredible. So folks, definitely check out GroqChat. If you haven't yet it's quite something. It's quite incredible. Check out all the demos as well. And with that, I want to say, Mark, thank you. This is the end of our conversation. It's been an hour, folks, on ThursdAI, and I'm going to reset the space a little bit, and then we're going to talk about everything else that was new this week, and there was a bunch of stuff in the open source and in different places.
[01:02:49] Alex Volkov: But what you heard so far is a deep conversation with Mark. Mark Heaps from Groq which came to many of us as new, but was around for a while. And then we also had some folks in the audience as well listening to this from Groq as well. So that was great. Thank you, Mark. And then let's reset the space and start talking about what's new in AI this week.
[01:03:07] Nisten Tahiraj: Thanks so much, guys. Really appreciate
[01:03:09] NA: you.
[01:03:31] Google releases Open Weights for GEMMA 2B and 8B
[01:03:31] Alex Volkov: All right, how's it going, everyone? You're on ThursdAI, February 22nd. My name is Alex Volkov. I'm an AI Avenger with Weights Biases. And Yet another incredible week in AI with a bunch of other stuff and I want to move our conversation towards the kind of the explosive open weights news this week, and I would love, so we have some more folks on stage here, and LDJ, we've talked about this when it came out, but Google gives us OpenWeights models, this is new to us folks, we've been waiting for Google for a long time, and finally they come out, and Google releases Gemma, a new OpenWeights model, not open source, and they've been very clear, which I really applaud the team.
[01:04:12] Alex Volkov: We're going to talk about some stuff that Google did not exactly do correctly this week, but we're also going to, we're going to highlight like we're going to give props where props are due. Google is clearly talking about open weights, open access model, not open source because they didn't open source a bunch of stuff.
[01:04:26] Alex Volkov: Definitely not datasets. It's called Gemma. It's they released two, two sizes, 2 billion and almost an 8 billion. So 7 billion parameter model. It has. Let's see what's interesting there. Trained on 6 trillion tokens, 8000 context window interestingly, vocab size is way bigger than LLAMA, and if you guys have been falling under capacity from this week, as you should, he just released a whole conversation about tokenizers, and he then analyzed the vocab size of the tokenizer kind of for Gemma, and said it's way bigger than LLAMA1.
[01:04:59] Alex Volkov: It's basically the same one, similar one, just like way bigger. And Yeah, this is incredible. This is like great news that Google is stepping into the open source. I think they see what Mark Zuckerberg saw, where once you release something like this, the community provides. And I want to just highlight, I had a tweet go off like fairly viral, because four hours after release, LDJ, we were spending the first hour in the space together that you opened.
[01:05:22] Alex Volkov: Four hours after release, we had Lama CPP support, Olama support, we had LM Studio support. Many people, like Maxim Lebon, one of our friends of the pod, quantized upload this because they didn't quantize correctly. Then after half a day, 3DAO from together added support for Flash Attention. I think there's a bunch of other stuff that added support as well.
[01:05:40] Alex Volkov: And we just had we just had folks from Groq talk about they've been looking at this as well. So it feels like Google understands the benefit of open weights access model. So I just want to, this shout out Google. Let me actually, I have a thing for this. Yeah. Good job.
[01:05:56] Alex Volkov: The big G provides, and this is great, and I'm, I was really surprised and happy to see this in the morning, and I wanted to hear from folks here on stage what are your thoughts so far on Gemma in terms of performance compared to, let's say, Mistral or anything else like Finetune that we had.
[01:06:10] Alex Volkov: Whoever wants to go next, but LDJ, you and I have the space, so feel free to comment what we learned from the space and since then, and then let's go around the table, and then we're gonna go forward with some news.
[01:06:21] LDJ: Yeah, so I think what we learned on the release and also after a little bit of time of people using it is that pretty much it has around the same abilities as Mistral. You could say maybe a little bit better than Mistral in certain ways. Some people say it's at least a little bit worse than Mistral in certain other [01:06:40] ways.
[01:06:40] LDJ: But overall there's definitely is maybe certain use cases where you might prefer the Jemma model. It is interesting though, I believe Jemma is actually. From what I remember seeing, it's 8. 5 billion parameters whereas I want to say Mistral is a total of 6. 7, so there is actually somewhat of around 25 percent more parameters, and theoretically, it should be maybe a little bit better than Mistral than than they say but, yeah it just really shows to how impressive Mistral is really the fact that Google's Making this model that's it's still not really significantly beating it,
[01:07:17] Alex Volkov: It's quite impressive. I saw, I think Marco from A16Z, Marco Mercora, post comparisons from Gemma, Mistral, Lama and I think something else. It's quite incredible that this model, like a company less than 30 people 6 months ago they released it, no, like less than 6 months, September I think, or October, the 7B model, and it still performs well against a company with like billions or whatever, and they release it, it's quite stunning that they're not able to beat Mistral 7B.
[01:07:49] Alex Volkov: by a significant amount. I wanted to like, highlight how, first of all, impressive this is, that they even released something. But also, how impressive this is for Mistral, that they come out so strong, and their model is basically the one people compare to. Definitely agree to that.
[01:08:05] Nisten Tahiraj: Yeah, I used it quite a bit I My opinion, I don't like It just it's just not that reliable. So yeah, it can code but sometimes It's not a very obedient model and the thing about Mixtral and Mistral and stuff is that They're used like tools a lot and Yeah, but again, we have yet to see good fine tunes.
[01:08:32] Nisten Tahiraj: So We see we saw how far people took alignment it with open chat
[01:08:39] Alex Volkov: Yeah, speaking of OpenChat
[01:08:41] NA: Was like how far they've taken these Yeah, so so we'll see I'll hold off a bit of judgment for them for now
[01:08:49] Alex Volkov: Yeah, speaking of open chat and speaking about fine tuning and being able to fine tune this alignment what are your initial thoughts? I saw Alpay post something that new open chat is coming. What are you guys cooking a fine tune like what's going on?
[01:09:03] Alignment Lab: There's probably an OpenChat fine tune of Gemma that's going to come out. I'm not clued in to that right now. I haven't had a chance to really get my head above water for a couple of days because I've been just buried in several things. If, if there is, it's probably going to be good. The model seems smart and it's got a lot of parameters, so It's hard to say that fine tuning won't make it very strong.
[01:09:31] Alignment Lab: I think with that giant tokenizer, it's going to be worth knowing that the model's going to be able to do a lot more during the training run because it's going to see more granular patterns and have a more expressive vocabulary to to, exploit the way that training runs make a model perform well better.
[01:09:50] Alignment Lab: This is the best way I can put it. It also, it's not getting mentioned very much, and I think it's because this is past the event horizon of AI stuff for a lot of people, but if you open up the models architecture, the implementation of it on the Google GitHub repo, they actually have a few different versions, and they're all for running the model in various contexts, or with or without TPUs, but And all of them, even the one that's not made to be parallelized, the model actually does have a baked in architecture designed for quantization and parallelization.
[01:10:20] Alignment Lab: And it looks like it can be quantized, or it can be parallelized, horizontally, vertically, and whatever the word is for the third dimension. It looks like it breaks pretty evenly into eight pieces, and if you can break it into eight pieces, and quantize each piece, and dequantize each piece, You can maybe parallelize it across asymmetrical compute, which is the big holdup for why we can't distribute models over just a bunch of random servers.
[01:10:48] Alignment Lab: Because usually, if they're not the exact same GPU with the exact same throughput and interconnect the model's unable to perform inference. But they may be able to solve for that baked in there, and it might be that they intend on Maybe having some service by which you can use the model locally with X amount of context and then just back into it onto their TPUs.
[01:11:08] Alignment Lab: I'm not sure, but it's interesting that it has a lot of custom tooling like baked into it designed for quantization parallelizing
[01:11:15] Alex Volkov: Yeah, I want to say custom tooling and also thanks Aliment, and also the amount of stuff that our community is supportive that they released is quite impressive. They released GDF quantizations, I think. They released support. They even released, folks, I don't know if folks missed this, they released something called Gema.
[01:11:32] Alex Volkov: cpp. which is a local CPU inference based in completely C with no dependencies, which is in addition to Llama CPP adding support for this, there is Gemma CPP and that's like their whole complete kind of comparison to Llama CPP. And that was pretty cool of them to release.
[01:11:49] Alex Volkov: And it looks like they've geared up to to have this model to be accepted. It's on Hug and Face. Hug and Face and Google recently announced a partnership and now it's on Hug and Face as well. So you can actually go to like hugandface. com slash Google slash Gemini slash Gemma. And it's pretty cool.
[01:12:04] Alex Volkov: I remember they, they mentioned Gemini Lite or Gemini Tiny or whatever for local inference. Very interesting that's not what we got. We got like a new model called Gemma out of the gate. Yam, do you have any, what's your thoughts on this whole thing from Google? Do you have a chance to play with this?
[01:12:19] Alex Volkov: Give us a little breakdown.
[01:12:20] Yam Peleg: actually, yeah, actually fine tuning is on the way. Already got the GPUs warming up
[01:12:27] Alex Volkov: let's
[01:12:28] Yam Peleg: the data as we speak. Yeah, I'm going to do, I'm going to do, before fine tuning, I'm going to do a little bit of a continuous pre training just to see if we can squeeze a little bit more out of the base model.
[01:12:40] Yam Peleg: It's just important to distinguish between the base model and the instruct tuning model.
[01:12:47] Alex Volkov: That's the slash IT thing they released, right? There is like a Gemma and Gemma slash
[01:12:51] Yam Peleg: When we talk about chat GPT like models, we talk about the instruct tuned models. And this, yeah, for sure, Mistral is just better at the moment. But in terms of the base model, we can know this only after people start to play with it and try to tune it themselves.
[01:13:11] Yam Peleg: Then we can see how far we can push it, because maybe it's just the actual fine tuning that Google did to their version of the model and with the methods from the open source that are pretty much, uh, very well trained in fine tuning models for instructional fine tuning. Maybe we can, maybe this model is really, will be really great because at the end of the day.
[01:13:36] Yam Peleg: The amount of compute that Google put into the model is insane, it's unparalleled. I'll be surprised if the model doesn't turn out to be really good, the base model, after fine tuning. But yeah, there is no, there is absolutely no doubt that Mistral is hiding something, they do have emotes. All their models that they fine tune for instruction following are on different levels.
[01:14:03] Yam Peleg: You can say. And you can see this even with the NuCube, the one that shouldn't have, had been leaked. It is also really good.
[01:14:13] Yam Peleg: But yeah, it's amazing. It's amazing that there is another player that is releasing, a major player, Google, releasing a really good Base model open source.
[01:14:24] Yam Peleg: It's great. It's great to have more players in this field more corporates turning into this game, supporting open source. It's always great. Yeah.
[01:14:33] Nisten Tahiraj: And the funny part is that they are struggling to compete in this section just because, the beauty of open source is that it enables so much competition, especially at these lower sizes where people can iterate very quickly.
[01:14:48] Nisten Tahiraj: And and now this is extremely obvious in this case. But yeah, I also think that the base model, I only tried the instruction tuned ones, and I've posted it above. I even have a link if you want to try it, but. [01:15:00] There is a lot more to be squeezed out of that just because again of the quality of the data that went in the pre training and Google might just not be that good at making chatbots.
[01:15:13] Nisten Tahiraj: Yeah, they'll probably, they'll get better, but it's
[01:15:16] Alex Volkov: Nisten, is it mergeable? It's mergeable, right? Like it's Frankensteinable.
[01:15:21] Nisten Tahiraj: Yeah, I think you can, I'll
[01:15:24] Yam Peleg: do it for fun. You can merge it with itself, but we don't have models to merge it with at the moment,
[01:15:32] NA: because you can't talk about it here yeah. You can merge the instruction tune with, not instruction tune, with itself and train on top.
[01:15:39] Yam Peleg: I tried to extend it with the front end merge and it didn't behave nicely. Mistral, for example, behaved really well. You can stretch it three times, just copy the layers three times and it works really well. At the fourth time, it starts to, to disintegrate and just breaks. But somewhere, you can do it for 3x and it works really well. This model didn't, so it was a little bit strange to see.
[01:16:08] Yam Peleg: But yeah, I'll know in a couple of hours when my training starts. So I'll be smarter to tell you. I if anyone saw my experiment I tried to play a little bit with with reinforcement learning, with DPO. I stopped the experiment mid run because someone pointed out that the terms forbid me to play with this type of experiment, but I just want to say that I played with, I tried to make the model less refusable, it was refusing nearly anything that you asked it, but so I just tried to make it more, more acceptable to actually do what you ask, nothing really fishy, but yeah, the terms forbid that, so I stopped the experiment.
[01:16:51] Yam Peleg: I just wanted to say that it really resisted. I trained and trained and the model still resisted. They really went hard on the on the alignment part on this model.
[01:17:02] Alex Volkov: Interesting that, we're going to talk about this next, I think, from Google, but interesting that even in their kind of open weights, open access models, they're baking in the alignment like super strong. Anything else, folks, on Gemma before we move on? Generally, kudos for Google for coming out this strong.
[01:17:21] Alex Volkov: Gemini Ultra getting announced, and then we saw Gemini Ultra getting access then Gemini Pro 1. 5, which we covered a little bit, and we probably should talk about this a little bit more, and now we're getting like open weights models that are finetunable, and I think even commercially licensed, right?
[01:17:35] Alex Volkov: You could use this in production, if I'm not mistaken.
[01:17:42] Alex Volkov: I guess I'm not
[01:17:42] Alignment Lab: Yeah, I think so. I think so. I think so.
[01:17:45] Alex Volkov: Yeah, which is quite impressive. Even from, it, it took Meta a while to give us a commercial license. Microsoft released PHI without commercial licensing. And then after six months gave into the pressure and Google waited, and now they're like, ta da, here's this.
[01:17:58] Alex Volkov: So very impressive from Google and kudos to whoever there worked on this open source release. It's probably not very easy to do, not open source, but open weights. It's not very easy to do. That stuff from within this big organization. So whoever listens to this, whoever worked on this, Thank you. Give us more.
[01:18:14] Alex Volkov: We would like to see bigger models, 35, etc. Junyoung, you wanted to comment as well? I saw you step in here.
[01:18:20] Alex Volkov: Yeah,
[01:18:21] Junyang Lin: I am definitely very excited about the Google open source of the Gemma model because yeah, it's actually a great model. Yesterday, we were just trying to compete QWAM 1. 5 with Gemma SMB, but we found Gemma SMB is actually better, but when we try about the base model.
[01:18:40] Junyang Lin: We think the base model should be a good model, but the instruction tune model, it's a bit strange. Actually, its behavior is quite strange. It's always irrefusable, and it's too safe, and there are a lot of answers they can't do. So I'm very surprised how they do their CAD model. But generally, the base model is general good.
[01:19:04] Junyang Lin: But I I'm very interested about their choices of their architecture because that it, its site is actually, it's not 8 billion. It's actually 9 billion because they have input embedding and their alpha embedding layers. They are not shareable. Parameters. So you found that the the sidebar actually very large.
[01:19:23] Junyang Lin: And for 2B, it is actually similar. It is actually, essentially three billion parameters if you count it correctly. So it's actually a very large model. And it is quite strange that for 2B model, it is using image MQA multi query attention, but for 7B model, it is Actually using multi head attention.
[01:19:43] Junyang Lin: I don't know why they choose it. And if you carefully look at the side of the hidden side as well as the head dimension for the attention you'll find that for the attention layer the head dimension is 2 56 and with 16 ahead, which means that the. Actually, the hidden dimension for the attention is actually 1496, but the hidden dimension for the FFM is 3072.
[01:20:11] Junyang Lin: This is very strange for me to choose something like this. I don't know, we should follow it for the following models. I don't know why Google do this. If they can tell us about this. it could be much better. But something it is very interesting and we also have experiments to show that it is quite effective, which is the large intermediate size.
[01:20:34] Junyang Lin: You will find that the intermediate size in comparison with Lama models or Mistral models it is actually larger. So you'll find we, we have some experiment and find that the larger intermediate size can improve the performance but there are still a lot of things we don't know why Google did this and we're not pretty sure Gemma is really a good model, much better than Mistral because I have seen some evaluation from Anton I'm not pretty sure it, it seems that Mistral is still the better one.
[01:21:05] Junyang Lin: I'm not pretty sure actually much better than Mistral, so, let's wait for more tests.
[01:21:11] Alex Volkov: We'll wait for Junyang thank you folks who are not familiar with Junyang he's on the technical team at GWEN, and we've talked multiple times about this point, thank you Junyang and it's great to have you here. And definitely we'll see more fine tuning, base model seems to be fine tuned a bowl, Yam said he's already cooking something, probably other labs are already shaking their They're pounds in anticipation of how to use the open source stuff, the DPO stuff.
[01:21:33] Alex Volkov: If it works to actually make this model behave instruction fine tuning better than Google did. And I'm sure that it's possible because we've seen a lot of advancements in open source community. And now it looks like Google is catching up to the open source community and not the other way around, which is incredible.
[01:21:47] Alex Volkov: And I want to just say, I will move on from this because folks have been here for an hour and a half, and there's a bunch of other stuff to also talk about. Specifically. Specifically because Google is a, in, in our good graces from one perspective, but also from another perspective, since they released Gemini, and Gemini could generate images they have shown us why potentially they've been hesitating to release anything at all.
[01:22:11] Alex Volkov: Because, and I think OpenAI and DALI has this to some extent as well. But if you've missed the storm and conversation this week definitely, you'll hear about this because Gemini, both, I think, Pro and Ultra on the interface, not the API models they are able to generate images. I think it was with Imogen or some other model from Google DALI and CGPT, right?
[01:22:31] Alex Volkov: And folks, quickly find out that those models do not like the words white. And literally, I think I had to tweet about this, I'll pin this, and I'll add this to the show notes as well. I went and tested something like, hey, generate a glamour shot of two, Jewish couples, two Indian couples, two African couples, and that was fine.
[01:22:50] Alex Volkov: And then I've asked Junyang a glamorous shot of two white people. And then it said, no, I cannot use generation based on race or gender or something like this, even though it just did this for five times. And then many folks tested this with historical figures when they asked hey, Junyang an image of whatever, before United States founding fathers, or some Nazi, or whatever it is.
[01:23:11] Alex Volkov: And they had a significant interjection into prompting, where it created stuff that are not remotely historically [01:23:20] accurate. And when I tested my stuff, it was a response to the historically accurate stuff. And it's still, it seems like there's a problem with how these models are replying to us.
[01:23:29] Alex Volkov: And a lot of folks at Google probably made it hard for these models to actually give me the image that I asked for. So it refuses so much though, the conversation went so hard into, Hey, Google, what did you give us? Why is this thing? So refusing that Google took down the ability to generate people. So right now, if you go, and I think it's like for the past 24 hours or so, if you go now and try to generate an image of an elephant, you'll get it.
[01:23:54] Alex Volkov: But if you try to generate the image of an elephant with, I don't know, two white folks holding its trunk or whatever, it will refuse. And like they, they completely nerfed the ability to generate people altogether, quote unquote, while they serve, solve for this, which is quite. Remarkable to think about how a big company like this, that already been in hot water before.
[01:24:17] Alex Volkov: And obviously this is Google, everybody's gonna dunk and go on Twitter and say bad things because punching up is easy. But, and also this gets you internet points if you're the first person that says, hey, Google is, reverse racist. But, Google has been in this hot water before with some image identification.
[01:24:34] Alex Volkov: I think there was a famous incident like 10, a decade ago almost, if you guys remember, with a image model that was identifying black people and saying gorillas or something. So Google has been burned on kind of the other side of this before, and now it looks like the pendulum swung way back to the other side, enough so that on the first, a week or so of the release.
[01:24:53] Alex Volkov: Now they are taking back the ability to generate people completely. And quite incredible how much of an intervention into multiculturalism, let's say they have in prompt layer. So it does look like the model can generate stuff. I saw one, one hacky attempt. Somebody said, hey, generate a glamorous shot of couple with fair skin.
[01:25:14] Alex Volkov: And then most of them are white, but if you actually say white couple, it's not able to, which is quite interesting. And I think it adds to the point where Yam said that even the open weights model that they've released, they have some built in kind of alignment strongly in the finetuning.
[01:25:30] Alex Volkov: So probably it's a feature of some of the datasets, but also some of the alignment stuff. It's really interesting to see that the internet kind of showed Google that the other side is also not great. Going all the way to the other side is also not great. And so Google, at least some of the teams in Google are, struggling right now to figure out what's the right balance there.
[01:25:49] Alex Volkov: Separately from Yeah, go ahead.
[01:25:51] Nisten Tahiraj: Sorry
[01:25:52] Nisten Tahiraj: I really want to highlight this because it's gotten to the point where the open source models and even GPT 3. 5 will do some tasks fine. And in this case, a task that I tested with is the. Universal Declaration of Human Rights, which is the most translated document
[01:26:10] NA: in human history and it's part of every data set.
[01:26:13] Nisten Tahiraj: And now you have Gemini and you have Copilot which is GPT 4. The thing that is too unsafe to translate, to
[01:26:24] NA: give you a translation of the Declaration of Human
[01:26:27] Nisten Tahiraj: Rights, which is, this has just gotten completely ridiculous. You can use a, you can use a model that's made anywhere else, any open source model, and it will tell you that, whereas now we have the, all the safety people and all the people that they hired, it's gotten to the point that it's completely backfired, and this is ridiculous.
[01:26:54] Nisten Tahiraj: They should be held
[01:26:56] Alex Volkov: Yeah, into unusefulness like some things in history happened, and we would like to, to be able to ask those things. And yeah, I definitely want to hear how this gets solved. I will say there were some folks that are mentioning that, hey, open, DALY, if you ask the same exact thing from DALY, it may give you some similar answers.
[01:27:14] Alex Volkov: So why is Google getting attacked? First of all, they just released it. Second of all, this is Google after all. Like they, they're like the big, they're still the gorilla, the big 600 pound gorilla, I think Microsoft called them in the room. And thirdly, we have short memory. We play with the toys, we play with the tools as we get them.
[01:27:30] Alex Volkov: And then when we discover we go viral. . Back to the good side of Google also, as we had breaking news last Thursday, and we talked about Gemini releasing a million tokens, as Thursday I started last one, which was crazy, Google released an update that said, hey, some developers can now get access to up to a whopping 1 million tokens in context window for Gemini 1.
[01:27:53] Alex Volkov: 5, and technically In research, they have up to 10 million Context Windows support, which is incredible. And I just want to come back and say that after this week, we've seen many folks, including Matt Schumer, who's here on stage, including a bunch of other folks, getting access to this 1 million tokens.
[01:28:08] Alex Volkov: I didn't get access yet. So wink at Google, if somebody hears me, please give me access. And folks are trying books, like full like three Three Harry Potter books on it and getting incredible stuff. Many folks are using it for video, which is also quite remarkable. Uploading an hour of video and getting retrieval from the, from video from within 1.
[01:28:29] Alex Volkov: 5, 100, like 1 million context window. It's, I wanted to follow up and say You know, the safety folks at Google need to take a little break, but the tech folks at Google holy crap, like the 1 million contacts was severely underhyped after Sora released from OpenAI, like two hours after we had also breaking news, and Sora is still blowing minds, and we're going to talk about Sora just briefly, but the 1 million contacts window gets more folks playing with it, And it's incredible for code generation.
[01:28:59] Alex Volkov: People threw the whole code base of 3. js in there. People threw just like whole code bases in one prompt. And we were talking about this a little bit with the Grog guys as well, where this unlocks new possibilities and significant new possibilities that weren't imagined before, and we don't have time for this debate today.
[01:29:20] Alex Volkov: And maybe we'll have to close the space a little early. And I'll tell you why in a second, but. I just wanted to highlight that, there's some stuff that Google did. Google is like this huge company, like full of multiple people. The safety stuff, meh, like we're gonna rally against this, we're gonna tell them that they're wrong and hopefully we'll get like less, less restricted models.
[01:29:39] Alex Volkov: But the context stuff, oh my god, this is like incredible, definitely set the new bar for how models should behave and what the possible things are. 10 hours of audio, you can send in one context 10 hours of audio and it will be able to tell you exactly when somebody said what. And summarize everything with like perfect recall.
[01:29:58] Alex Volkov: We had Greg Cumbrand that we've talked about for End of the Pod as well. He did this needle in haystack analysis on a bunch of context windows, if you remember, on Claude, etc. And they used his needle in haystack analysis to analyze and say that The models that also have very high recall precision, like almost perfect recall precision throughout this whole context, throughout the whole like 600, 000 tokens or so.
[01:30:21] Alex Volkov: And we had folks test this week. Quite incredible advancement there, and Entropic, who are, who did Cloud for us with 100, 000 tokens for a long time, this was their mode, then there is 200, 000 tokens it seems, it's paling in comparison. I did my comparisons from last year, if you guys remember, during May, Mosaic released the jump into 70, 000 tokens or so, and back then that looked incredible, they threw, they put an actual book in there, and I just compared the less than a year, we've gotten like a 10x jump into what we consider like normal context windows or possible context windows, because like less than a year ago, the big jump was to 60, 000.
[01:31:03] Alex Volkov: And now we're jumping to a million. And it's actually possible to use a million. So incredible, incredibly important for Multimodality as well, because videos take just so much content. I think one hour video of this Buster Keaton, I think is the video that they've used in the example, takes around 600, 000 tokens.
[01:31:20] Alex Volkov: Just think about this. Like one hour video takes around 600, 000 tokens. And it's able to tell you exact precision of where something happened in this video, what happened, who spoke about what. Very incredible. Definitely underhyped. I think Sora took. I think, collectively on X we're able to talk about one important thing, and Sora [01:31:40] definitely took that one important thing, but coming back to Gemini 1.
[01:31:43] Alex Volkov: 5 with a huge context is very impressive from Google as well. Anybody here on stage got access to 1. 5 and actually played with this? I haven't yet, I'm just recapping from the feed. Nope, everybody's sad. Google, if you hear us, give us access. Nisten?
[01:31:59] Alignment Lab: I will bite my finger off like a graham cracker
[01:32:02] NA: to get access to that model.
[01:32:03] Alex Volkov: Yes. Exactly. All right, so moving. Yeah, Nisten, go ahead and then we'll move on.
[01:32:08] NA: No, I just
[01:32:09] Nisten Tahiraj: wanted to mention some other news that Roboflow and Sakowski just released the YOLOv9 model. I made some demo with it, with the sailboats
[01:32:18] NA: And the boxing and stuff. And
[01:32:20] Nisten Tahiraj: this
[01:32:20] NA: is
[01:32:21] Nisten Tahiraj: pretty, it's pretty nuts. It's like the next the next gen stuff.
[01:32:24] NA: But they've also released a paper, I think.
[01:32:27] NA: for
[01:32:27] Nisten Tahiraj: some research, which I haven't read yet and I'm incredibly excited. But yeah, this is completely this is not as much LLM related, but it is open source vision AI stuff. And I really recommend people to, to look at it because it's like straight up from the future. Like I I tried YOLOv8 and you all can see the results and stuff on video on stuff you can do.
[01:32:51] Nisten Tahiraj: And
[01:32:51] NA: It's pretty cool.
[01:32:53] Alex Volkov: Could you add this to the space and we'll add to show notes as well. I will just highlight that Peter Skalski, SkalskiP is a friend of the pod, a dear co host, and Roboflow are doing incredible vision stuff, and definitely worth a shoutout every time they release something new, and some of his tutorials on Twitter are amazing.
[01:33:09] Alex Volkov: If you're into vision understanding, Peter is the guy to follow, and a shoutout for for the stuff that they're building there. I think we're gonna move on from the big companies and LMs, we've talked about pretty much everything, Open source. The last thing that we wanted to mention, I think the last thing that I want to mention is Nous Research released Nous Hermes on DPO.
[01:33:27] Alex Volkov: And basically it's the same model, just trained on DPO data set. And that beats the previous Nous Research, the Nous Hermes Open Hermes 2. 5, I think pretty much in every benchmark. And that's been great to see the DPO is Putting itself in, in, in the right position of improving models.
[01:33:44] Alex Volkov: I think we've seen this from our Guia folks who cleaned datasets and actually retrained Hermes models. I think we've seen this. And now we're getting a DPO headset from Nous folks themselves, which is great to see. And Jan, I think you had some comments about how to actually do this DPO thing in, in, in comments to Technium.
[01:34:00] Alex Volkov: So more of that goodness is coming, and open source does not wait, and I can't wait to see all these techniques also apply to, to the different Jemma stuff that we got, and different other, let's say, rumored, wink, from meta stuff that at some point are gonna come, and we're gonna get, hopefully the number three which, if they release today, I'm not gonna be mad honestly Mark, if you're listening to
[01:34:23] Nisten Tahiraj: Yeah, let's close it early, otherwise we'll be here until tomorrow.
[01:34:27] Alex Volkov: that's true.
[01:34:28] Alex Volkov: We're going to close it early because of this next thing that I want to talk about and I actually want to cover this a little bit. So I'm going to put some music and then we're going to talk about this. Oh my God. I got lost in my music stuff. And we're going to talk about this week's buzz. I see that folks are enjoying. me mistakenly hitting different musical buttons. Folks, welcome to this week's buzz. This is a corner here, a section here, that I talk about everything that I've learned working for Weights Biases. And some of this is technical, some of this is just the stuff that we release on courses.
[01:35:00] Alex Volkov: And we released a course with Hamal Hussain about enterprise model management. So if you're into this That course is great. It's going so good. So many people are registering. I haven't had actually time to see it. I should probably see this soon, maybe tomorrow because I'm preparing ThursdAI and working on demos with Groq and everything.
[01:35:17] Alex Volkov: But I've definitely wanted to chat about the reason I was in San Francisco for this last weekend. So as we were finishing up ThursdAI last week, I think I said Swyx was here. I was recording it live from San Francisco. And that day on Thursday, we had a meetup. That I helped co host, and I wasn't the only one there.
[01:35:36] Alex Volkov: A16z, Andreessen Horowitz, the biggest VC firm in the world. With with, if you don't follow Marc Andreessen on X, you definitely should. He's a big proponent of open source. He's been talking about all these kind of very interesting things. Shout out Marc Andreessen. He wasn't there. I definitely expect to see him next time.
[01:35:52] Alex Volkov: But folks, Reiko and Marco Moscoro from A16Z, the guys who give out grants to open source. And you know that many of our friends of the pod are like grant receivers from A16Z. The blog received the grant, Nous Research are grant receivers. I think Axolotl, Wing is from Axolotl, is also a grant receiver.
[01:36:09] Alex Volkov: Like a bunch of folks are getting supported by A16Z. And they had a meetup for open source AI. And I was very proud to be invited and to be a co host and gave out a bunch of Weights Biases swag. And just in terms of names who went, it was mind blowing. We had Nous Research folks, so Technium was there, and EmuZilla was there, Koran Shavani, like all the Nous folks are definitely big help organizers.
[01:36:33] Alex Volkov: Olama folks were there, announced that they're now supporting Windows. LamaIndex, we met with Jerry. LMCs folks, which I really wanted to meet and talk to them, and maybe bring them on ThursdAI, but I didn't get a chance to, so if anybody knows the LMCS folks, please shout out shoot me a DM with them as well.
[01:36:50] Alex Volkov: Replicate, who are doing great stuff, Perplexity, Mistral, there was a Devendra, I think, from Mistral was there as well, and there's also a bunch of friends of the path who also receive grants, if you guys remember, we had a deep dive with John Durbin. from the Bagel Model fame, and he just recently started releasing a bunch of other stuff.
[01:37:06] Alex Volkov: Eric Hartford who released, I think, Lazer, and now he works at Abacus. Hao Tian Liu from Lava, and just a bunch of great folks in the open source community got together in San Francisco and talked to each other about techniques, about how important open source is and they had a panel with like folks from Mozilla and the Linux Foundation and Percy from Together AI as well.
[01:37:27] Alex Volkov: That panel talked about the importance of open source, what is open source actually. How do we treat open source in AI? What is weights fully? Is that enough? Or is something like Olmo that we've talked about from Allen Institute of AI, is that like full open source when they released the training code and data sets and weights and biases logs and all these things.
[01:37:46] Alex Volkov: And so there was a great discussion about what open source actually means in the fully like new AI world. Incredible to meet all these folks. Just shout out to Reiko and Marco for organizing this and inviting us. And I promised a report and this is the report. And definitely I will add to the show notes the summary that Reiko did, because they also did a report on open source stuff.
[01:38:07] Alex Volkov: It's worth looking into this, how much, how many folks downloading the Blo . So many folks download ni maybe you saw this LD as well. So many folks download the bloke's models. Then when the bloke like, I think disappeared for three days or something, peoples like, is he okay? There's no new g GFS on hack face.
[01:38:24] Alex Volkov: What happened? Is he all right? So many people get used to this. The block is also a receiver of the A 16 Z grant. And so that's what I learned in wait and Biases this week. I also visited the office. Those of you who followed me probably seen my ridiculous video that I showed around the office showing waits in the waits and biases, dashboards in, in virtual space.
[01:38:44] Alex Volkov: And I really had a great time there. We also met with sws and some of. His folk in the Swyx small house, so shout out Swyx and Alessio from Latent Space Pod for first of all hosting me, second of all being great friends of the Pod. Honestly, ThursdAI would not exist as a podcast and newsletter without Swyx and Alessio.
[01:39:03] Alex Volkov: And also they're coming up on their one year anniversary for Latentspace. So if I can send them love and subscribers, please go check out Latentspace as well. Happy birthday, folks. And I think we're going to move on to two new things. And then we're just going to do a recap in the AI, art, and diffusion area.
[01:39:20] Alex Volkov: And I think for this, I do have a transition. Let's see. No, I have a transition for this. Yes.
[01:39:47] Alex Volkov: and Alignment just dropped, but I wanted to hear what he was actually saying, but he had issues with space even before. But we did have a transition, and folks, this week is big. This week is big. You guys know that we only talk about [01:40:00] AI when it's huge, and this week was huge. Starting off this week, ByteDance released SDXL Lightning, which takes SDXL that we've talked about one of the best open source diffusion models, and then makes it incredible in just one step.
[01:40:15] Alex Volkov: So if you ever use a stable diffusion, if you ever. Run it yourself, the, the sweet spot is somewhere between 35 and 50 steps, depending on which which of the, I forgot what it's called, the tokenizer? No, something, depends on what you use there between 35 and 50 steps and then.
[01:40:33] Alex Volkov: We obviously had some advancements before. We've seen SDXL Turbo and SDXL Lightning generates incredible images in just one or two steps. Just incredible it's unbelievable how fast this is. And of course, our folks friends of the pod as well from File. ai are putting this in production and you can play with their demo.
[01:40:52] Alex Volkov: The demo is called I'm going to put this in show notes, FastSDXL. ai. And the demo is near real time. You type and you generate images. You type and they generate images. And it's not the LCM stuff that we've talked about. If you guys remember the late consistency model that's something else. This is a full SDXL generation running in two or four steps.
[01:41:12] Alex Volkov: and looks incredible, like 1024 resolution, text to image generation, ByteDance optimized the crap out of this SDXL and it's really mind blowing. I really suggest you go and try to play with it as fast as the SDXL. ai. And I've played with this yesterday and the, what I wanted to do with this is I wanted to And it's added to the show notes as well.
[01:41:34] Alex Volkov: I wanted to see what's possible when we have an LLM that's near instant. So we've had the chat today with the Groq folks, and you can hear, if you're just joining us now, you can hear the chat after I publish the episode. And their LLM is like 500 tokens a second. So basically answers appearing in near instant time, but also SDXL Lightning is, SDXL diffusion appears in near instant time.
[01:41:56] Alex Volkov: And I played with a demo of this and I'm gonna add the video also to the show notes as well, and I was just blown away how responsive things feel. And so the demo that I built was using Neil Agarwal's It's called Infinite Fun or something game where you just draw concepts on top of each other, and he uses AI to generate what those two concepts mean, basically.
[01:42:17] Alex Volkov: Neil, in this Infinite Fun thing, he used emojis. So if you combine Earth and, I don't know, fire or something, you get volcano. So he has the emoji of volcano, right? So he has an AI that picks out the best emoji for this one thing. And I said, hey, emoji is fun, but what if we generate like a full on SDXL image on every turn that I play this game?
[01:42:37] Alex Volkov: And I did this with with Groq. I used Mixtral behind the scenes to generate, to be the prompt engineer, to take these concepts and actually write a nice prompt for SDXL. And with two steps or four steps, overall from dragging this to getting Mixtral to be my prompt engineer, and my initial my initial system message is around a thousand tokens, right?
[01:42:57] Alex Volkov: So I'm sending a thousand tokens or so. Probably, maybe less than a thousand, maybe five hundred. And I get an instant answer from Groq, because their speed is ridiculous. I then send this to FAL, to their API to do SDXL lightning. And I get an image, it's super fast, like it's also ridiculous It's, I think overall for some incredible examples, I got less than 300 milliseconds response from going to an LLM, generating a prompt for me, taking this prompt, sending it to an image image thing and getting back.
[01:43:24] Alex Volkov: under 300 milliseconds. I will remind you that folks from Google a long time ago did a research study where everything under 250 milliseconds to humans is almost real time imperceptible and clicks and reactions. And now we're getting multiple models. In kind of a pipeline together reacting under 300 milliseconds.
[01:43:43] Alex Volkov: And it's incredible. And honestly, I can't release, I cannot release this demo because I didn't build the UI, so I cannot give you the UI. However I can probably send you the extension code if you want to, and you have your own API keys for Groq. I was blown away how easy and fast this was.
[01:43:59] Alex Volkov: And just two of these the same week, two of the speed investments. So SDXL Lightning, two steps for like incredible image generation, and then Groq as well. So this is an answer to folks who are saying, why do we even need this speed? I saw somebody say, hey why do you even need 400 tokens a second?
[01:44:17] Alex Volkov: People cannot read fast enough. And this is the answer for this, because interfaces can happen in near real time. And it's incredible. And the second big thing in AI art and diffusion happened as breaking news. So we're gonna, we're gonna do this.
[01:44:41] Alex Volkov: Folks, we have breaking news. And LDJ, you've been saying about today or I guess for a while now Imad from Stability AI, Imad Mustaq from Stability announces Stable Diffusion 3. StableDiffusion3 uses a new architecture that we've talked about first with Tanishka and folks from the HDIT Hourglass Diffusion Transformers, and also from Sora, a Diffusion Transformer architecture, where they take the both worlds from this last gen of of gen AI and combine them together.
[01:45:11] Alex Volkov: And StableDiffusion3 is going to be Diffusion Transformer. And it's impressive in, so we only got a waitlist, so unlike previously, where Stable Diffusion just dropped now it's a waitlist that you have to sign up for, but shout out to Fox's Stability because it looks incredible. It has, and very impressive, so some examples you can check out in the newsletter that I'm gonna send, some examples are under the hashtag SD3.
[01:45:36] Alex Volkov: On X, it has a very impressive multi subject prompt following, so I can show you an example of this later in show notes, but a prompt like Painting of an astronaut, riding a pig, wearing a tutu, holding a pink umbrella, on the ground next to the pig is a robin bird wearing a top hat, in the corner there are words stable diffusion, and this image is perfect.
[01:45:56] Alex Volkov: All of the subjects and the different things that I told you are existing in this picture and the Robin bird is on the ground, has a top hat and the astronaut is holding an umbrella, but the pig is wearing a tutu. So understand the text is perfect. And understanding of multiple subjects, I think, is something that we've seen great in DALI, for example, but previous versions of Stable Diffusion were not nearly as good at multi prompts, multi subjects, and multi colors, for example, and this nails all of them.
[01:46:22] Alex Volkov: The umbrella is the right color, the tutu is the right color, the bird, everything. And it looks just really awesome. And I gotta wonder if, something like this with the speed of the previous announcement of SDXL could mean. And so they're advancing very fast as well, and it's great to see.
[01:46:39] Alex Volkov: Breaking news, shoutout to Stability for announcing this, they didn't release this yet, they announced. Stable Diffusion 3, it's coming to us very soon, and it looks awesome. And I think, unless folks here on stage wanted to chat about some other stuff that we haven't covered yet,
[01:46:56] Alex Volkov: this is everything we've talked about on ThursdAI. Outside of that, we had our returning hosts. and Co hosts and speakers on the panel. So I want to thank Nisten, I want to thank Yam. LDJ was here, Jun Yang from QEN, and a bunch of other folks. I want to shout out Matt Schumer again and Mark Heaps from Groq for joining and telling us all about this.
[01:47:14] Alex Volkov: And if that, if you missed any part of this conversation, definitely feel free to check us out. With that I want to say thank you for joining ThursdAI as always. I think we're. coming up to almost exactly two hours, and I'm gonna, I'm gonna let you go and then we'll see what else gets released on this crazy AI Thursday.
[01:47:31] Alex Volkov: Thank you everyone.


