






Hey everyone, this week has been incredible (isn’t every week?), and as I’m writing this, I had to pause and go check out breaking news about LLama code which was literally released on ThursdAI as I’m writing the summary!
I think Meta deserves their own section in this ThursdAI update 👏
A few reminders before we dive in, we now have a website (thursdai.news) which will have all the links to Apple, Spotify, Full recordings with transcripts and will soon have a calendar you can join to never miss a live space!
This whole thing would have been possible without Yam, Nisten, Xenova , VB, Far El, LDJ and other expert speakers from different modalities who join and share their expertise from week to week, and there’s a convenient way to follow all of them now!
TL;DR of all topics covered
Voice
Seamless M4T Model from Meta (demo)
Open Source LLM
LLaMa2 - code from Meta
Vision
IDEFICS - A multi modal text + image model from Hugging face
AI Art & Diffusion
1 year of Stable Diffusion 🎂
Big Co LLMs + API updates
AI Tools & Things
Cursor IDE
Voice
Seamless M4t - A multi lingual, mutli tasking, multimodality voice model.
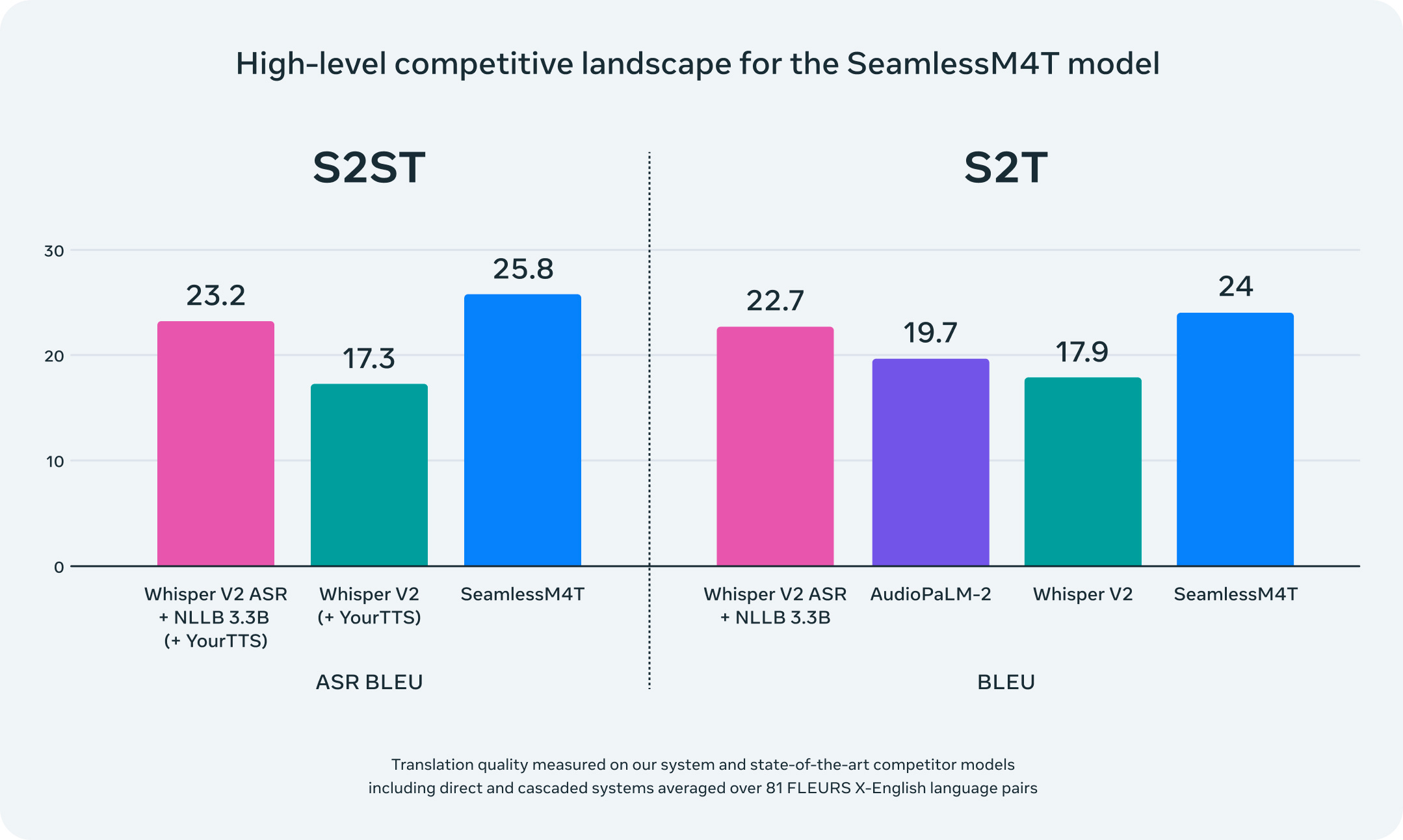
To me, the absolute most mindblowing news of this week was Meta open sourcing (not fully, not commercially licensed) SeamlessM4T
This is a multi lingual model that takes speech (and/or text) can generate the following:
Text
Speech
Translated Text
Translated Speech
In a single model! For comparison sake, I takes a whole pipeline with whisper and other translators in targum.video not to mention much bigger models, and not to mention I don’t actually generate speech!
This incredible news got me giddy and excited so fast, not only because it simplifies and unifies so much of what I do into 1 model, and makes it faster and opens up additional capabilities, but also because I strongly believe in the vision that Language Barriers should not exist and that’s why I built Targum.
Meta apparently also believes in this vision, and gave us an incredible new power unlock that understands 100 languages and does so multilingually without effort.
Language barriers should not exist
Definitely checkout the discussion in the podcast, where VB from the open source audio team on Hugging Face goes in deeper into the exciting implementation details of this model.
Open Source LLMs
🔥 LLaMa Code
We were patient and we got it! Thank you Yann!
Meta releases LLaMa Code, a LlaMa fine-tuned on coding tasks, including “in the middle” completion tasks, which are what copilot does, not just autocompleting code, but taking into account what’s surrounding the code it needs to generate.
Available in 7B, 13B and 34B sizes, the largest model beats GPT3.5 on HumanEval, which is a metric for coding tasks. (you can try it here)
In an interesting move, they also separately release a specific python finetuned versions, for python code specifically.
Additional incredible thing is, it supports 100K context window of code, which is, a LOT of code. However it’s unlikely to be very useful in open source because of the compute required
They also give us instruction fine-tuned versions of these models, and recommend using them, since those are finetuned on being helpful to humans rather than just autocomplete code.
Boasting impressive numbers, this is of course, just the beginning, the open source community of finetuners is salivating! This is what they were waiting for, can they finetune these new models to beat GPT-4? 🤔
Nous update
Friends of the Pod LDJ and Teknium1 are releasing the latest 70B model of their Nous Hermes 2 70B model 👏
We’re waiting on metrics but it potentially beats chatGPT on a few tasks! Exciting times!
Vision & Multi Modality
IDEFICS - a new 80B model from HuggingFace, was released after a years effort, and is quite quite good. We love vision multimodality here on ThursdAI, we’ve been covering it since we say that GPT-4 demo!
IDEFICS is a an effort by hugging face to create a foundational model for multimodality, and it is currently the only visual language model of this scale (80 billion parameters) that is available in open-access.
It’s made by fusing the vision transformer CLIP-VIT-H-14 and LLaMa 1, I bet LLaMa 2 is coming soon as well!
And the best thing, it’s openly available and you can use it in your code with hugging face transformers library!

It’s not perfect of course, and can hallucinate quite a bit, but it’s quite remarkable that we get these models weekly now, and this is just the start!
AI Art & Diffusion
Stable Diffusion is 1 year old
Has it been a year? wow, for me, personally, stable diffusion is what started this whole AI fever dream. SD was the first model I actually ran on my own GPU, the first model I learned how to.. run, and use without relying on APIs. It made me way more comfortable with juggling models, learning what weights were, and we’ll here we are :) I now host a podcast and have a newsletter and I’m part of a community of folks who do the same, train models, discuss AI engineer topics and teach others!
Huge thank you to Emad, Stability AI team, my friends there, and everyone else who worked hard on this.
Hard to imagine how crazy of a pace we’ve been on since the first SD1.4 release, and how incredibly realistic the images are now compared to what we got then and got excited about!
🎂
IdeaoGram joins the AI art race

IdeoGram - new text to image from ex googlers (announcement) is the new kid on the block, not open source (unless I missed it) it boasts significant text capabilities, and really great quality of imagery. It also has a remix ability, and is availble from the web, unlike… MidJourney!
Big Co LLMs + API updates
Open AI pairs with ScaleAI to let enterprises finetune and run finetuned GPT3.4 models!
This is an interesting time for OpenAI to dive into fine-tuning, as open source models inch closer and closer to GPT3.5 on several metrics with each week.
Reminder, if you finetune a GPT3.5 model ,you need to provide your own data to OpenAI but then also you have to pay them for essentially hosting a model just for you, which means it’s not going to be cheap.
Use as much prompting as humanly possible before you consider doing the above fine-tuning and you may be able to solve your task much better and cheaper.
Agents
The most interesting thing to me in the world of agents actually came from an IDE!
I installed Cursor, the new AI infused VsCode clone, imported my vscode settings, and off we went! It can use your own GPT-4 keys if you don’t want to send them our code or pay, it embeds your whole repo for easy import and code understand and does so much more, like adding a button to every error in console to “debug” and has an “new AI project” feature, which builds you a template just by typing a few words!
Our friends Alessio and Swyx have interviewed the founder of Cursor on their podcast, a strong recommendation to check that episode out!

After using Cursor for just a few days, I don’t want to go back to VSCode and even consider … maybe pausing my copilot subscription 🤯
That’s all for today folks! I wish you all a great week, and we’ll see you in the next ThursdAI 🫡





