





Hey everyone, welcome to yet another ThursdAI update! As always, I’m your host, Alex Volkov, and every week, ThursdAI is a twitter space that has a panel of experts, guests and AI enthusiasts who join to get up to date with the incredible fast pace of AI updates, learn together and listen to subject matter experts on several of the topics.
Pssst, this podcast is now available on Apple, Spotify and everywhere using RSS and a new, long form, raw and uncut, full spaces recording podcast is coming soon!
I started noticing that our updates spaces are split into several themes, and figured to start separating the updates to these themes as well, do let me know if the comments if you have feedback or preference or specific things to focus on.
LLMs (Open Source & Proprietary)
This section will include updates pertaining to Large Language Models, proprietary (GPT4 & Claude) and open source ones, APIs and prompting.
Claude 1.2 instant in Anthropic API (source)
Anthropic has released a new version of their Claude Instant, a very very fast model of Claude, with 100K, a very capable model that’s now better at code task, and most of all, very very fast!
Anthropic is also better at giving access to these models, so if you’ve waited in their waitlist for a while, and still don’t have access, DM me (@altryne) and I’ll try to get you API access as a member of ThursdAI community.
WizardLM-70B V1.0 tops OSS charts (source)
WizardLM 70B from WizardLM is now the top dog in open source AI, featuring the same License as LLaMa and much much better code performance than base LLaMa 2, it’s now the top performing code model that’s also does other LLMy things.
Per friend of the pod, and Finetuner extraordinaire Teknium, this is the best HumanEval (coding benchmark) we’ve seen in a LLaMa based open source model 🔥

Also from Teknium btw, a recent evaluation of the Alibaba Qwen 7B model we talked about last ThursdAI, by Teknium, actually showed that LLaMa 7B is a bit better, however, Qwen should also be evaluated on tool selection and agent use, and we’re waiting for those metrics to surface and will update!
Embeddings Embeddings Embeddings
It seems that in OpenSource embeddings, we’re now getting state of the art open source models (read: require no internet access) every week!
In just the last few months: - Microsoft open-sourced E5 - Alibaba open-sourced General Text Embeddings - BAAI open-sourced FlagEmbedding - Jina open-sourced Jina Embeddings
And now, we have a new metric MTEB and a new leaderboard from hugging face (who else?) to always know which model is currently leading the pack. With a new winner from this week! BGE (large, base and small (just 140MB) )
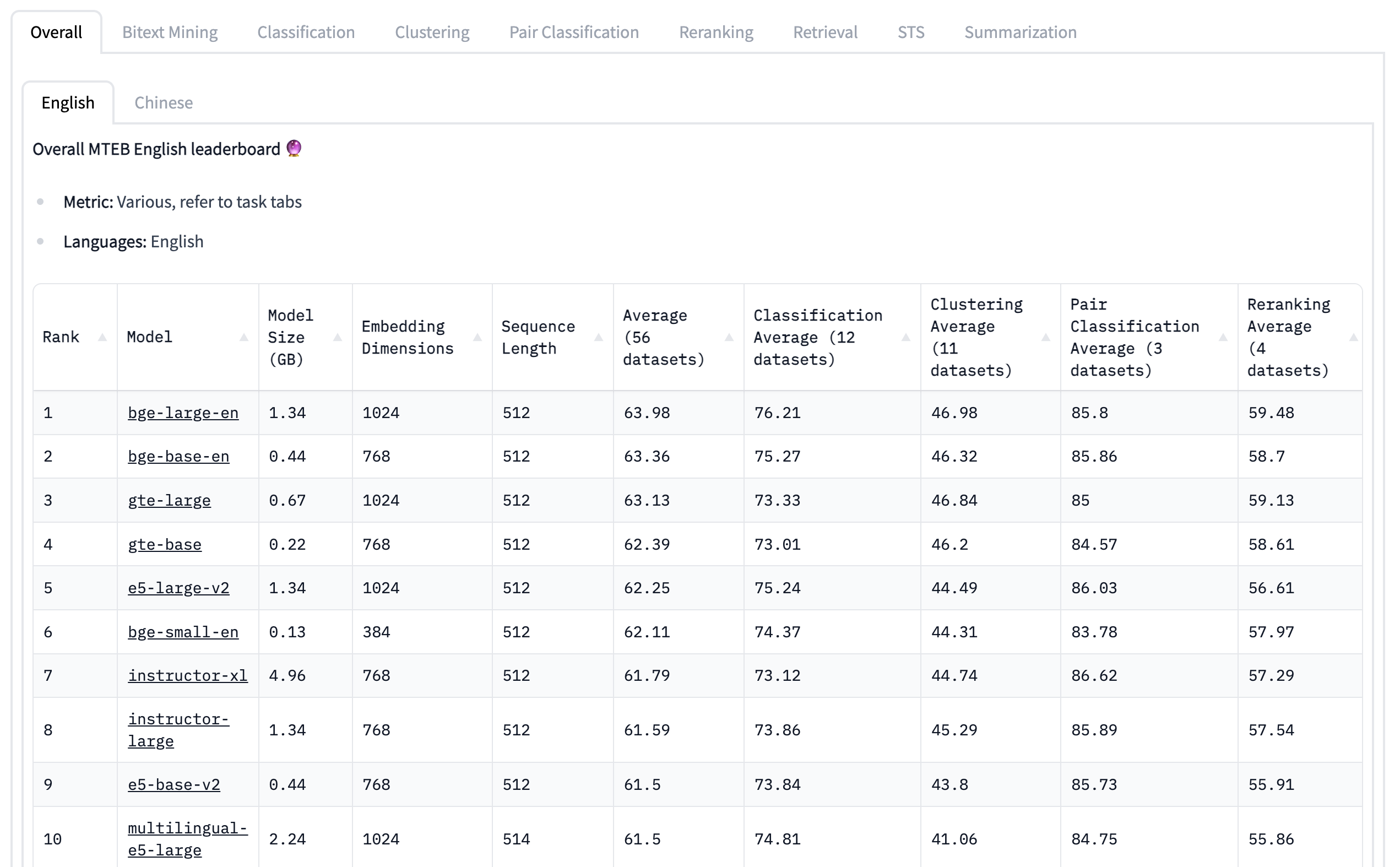
Embedding models are very important for many AI applications, RAG (retrieval augmented generation) products, semantic search and vector DBs, and the faster, smaller and more offline they are, the better the whole field of AI tools we’re going to get, including, much more capable, and offline agents. 🔥
Worth noting that text-ada-002, the OpenAI embedding API is now ranked 13 on the above MTEB leaderboard!
Open Code Interpreter 👏
While we’re on the agents topic, we had the privilege to chat with a new friend of the pod, Shroominic who’s told us about his open source project, called codeinterpreter-api which is an open source implementation of code interpreter. We had a great conversation about this effort, the community push, the ability of this open version to install new packages, access the web, run offline and have multiple open source LLMs that run it, and we expect to hear more as this project develops!
If you’re not familiar with OpenAI Code Interpreter, we’ve talked about it at length when it just came out here and it’s probably the best “AI Agent” that many folks have access to right now.

Deepfakes are upon us!
I want to show you this video and you tell me if you saw this not in an AI newsletter, would you have been able to tell it’s AI generated.
This video was generated automatically, when I applied to the waitlist by HeyGen and then I registered again and tried to get AI Joshua to generate an ultra realistic ThursdAI promo vid haha.
I’ve played with many tools for AI video generation and never saw anything come close to this quality, and can’t wait for this to launch!
While this is a significant update for many folks in terms of how well deepfakes can look (and it is! Just look at it, reflections, HQ, lip movement is perfect, just incredible) this isn’t the only progress data point in this space.
Play.ht announced version 2.0 which sounds incredibly natural, increased model size 10x and dataset to more than 1 million hours of speech across multiple languages, accents, and speaking styles and emotions and claims to have sub 1s latency and fake your voice with a sample of only… 3 seconds! 🤯
So have you and your loved ones chosen a code word to authenticate over the phone? Or switched to a verifiable communication style? While those of us with multiple accents don’t yet have to worry, everyone should stop believing any video or voice sample from now on, it’s just inevitable that all of that will be deepfaked and we should start coming up with ways to authenticate content.
Finally, we’ve talked for a whopping 2 hours on the spaces, and that whole conversation can be heard on our Zealous page which has transcripts, AudioGrams of key moments, and space summarizations!
And the Long form space recordings can be added to your podcatcher separately if you’d prefer the “ThursdAI raw feed” by using this RSS link, and will come as it’s own podcast very soon! Thanks to our friends at Zealous
Thank you,
Alex Volkov.
Host ThursdAI - Recaps of the most high signal AI weekly spaces
CEO @ Targum.video
AI Consultant with free slots (Lets Talk)




