



Happy first ThursdAI of April folks, did you have fun on April Fools? 👀 I hope you did, I made a poll on my feed and 70% did not participate in April Fools, which makes me a bit sad!
Well all-right, time to dive into the news of this week, and of course there are TONS of news, but I want to start with our own breaking news! That's right, we at Weights & Biases have breaking new of our own today, we've launched our new product today called Weave!

Weave is our new toolkit to track, version and evaluate LLM apps, so from now on, we have Models (what you probably know as Weights & Biases) and Weave. So if you're writing any kind RAG system, anything that uses Claude or OpenAI, Weave is for you!

I'll be focusing on Weave and I'll be sharing more on the topic, but today I encourage you to listen to the launch conversation I had with Tim & Scott from the Weave team here at WandB, as they and the rest of the team worked their ass off for this release and we want to celebrate the launch 🎉
TL;DR of all topics covered:
Open Source LLMs
Cohere - CommandR PLUS - 104B RAG optimized Sonnet competitor (Announcement, HF)
Princeton SWE-agent - OSS Devin - gets 12.29% on SWE-bench (Announcement, Github)
Jamba paper is out (Paper)
Mozilla LLamaFile now goes 5x faster on CPUs (Announcement, Blog)
Big CO LLMs + APIs
Cloudflare AI updates (Blog)
Anthropic adds function calling support (Announcement, Docs)
Groq lands function calling (Announcement, Docs)
OpenAI is now open to customers without login requirements
Replit Code Repair - 7B finetune of deep-seek that outperforms Opus (X)
Google announced Gemini Prices + Logan joins (X)קרמ
This weeks Buzz - oh so much BUZZ!
Weave lunch! Check weave out! (Weave Docs, Github)
Sign up with Promo Code THURSDAI at fullyconnected.com
Voice & Audio
OpenAI Voice Engine will not be released to developers (Blog)
Stable Audio v2 dropped (Announcement, Try here)
Lightning Whisper MLX - 10x faster than whisper.cpp (Announcement, Github)
AI Art & Diffusion & 3D
Dall-e now has in-painting (Announcement)
Deep dive
Jamba deep dive with Roi Cohen from AI21 and Maxime Labonne
Open Source LLMs
Cohere releases Command R+, 104B RAG focused model (Blog)
Cohere surprised us, and just 2.5 weeks after releasing Command-R (which became very popular and is No 10 on Lmsys arena) gave us it's big brother, Command R PLUS
With 128K tokens in the context window, this model is multilingual as well, supporting 10 languages and is even beneficial on tokenization for those languages (a first!)
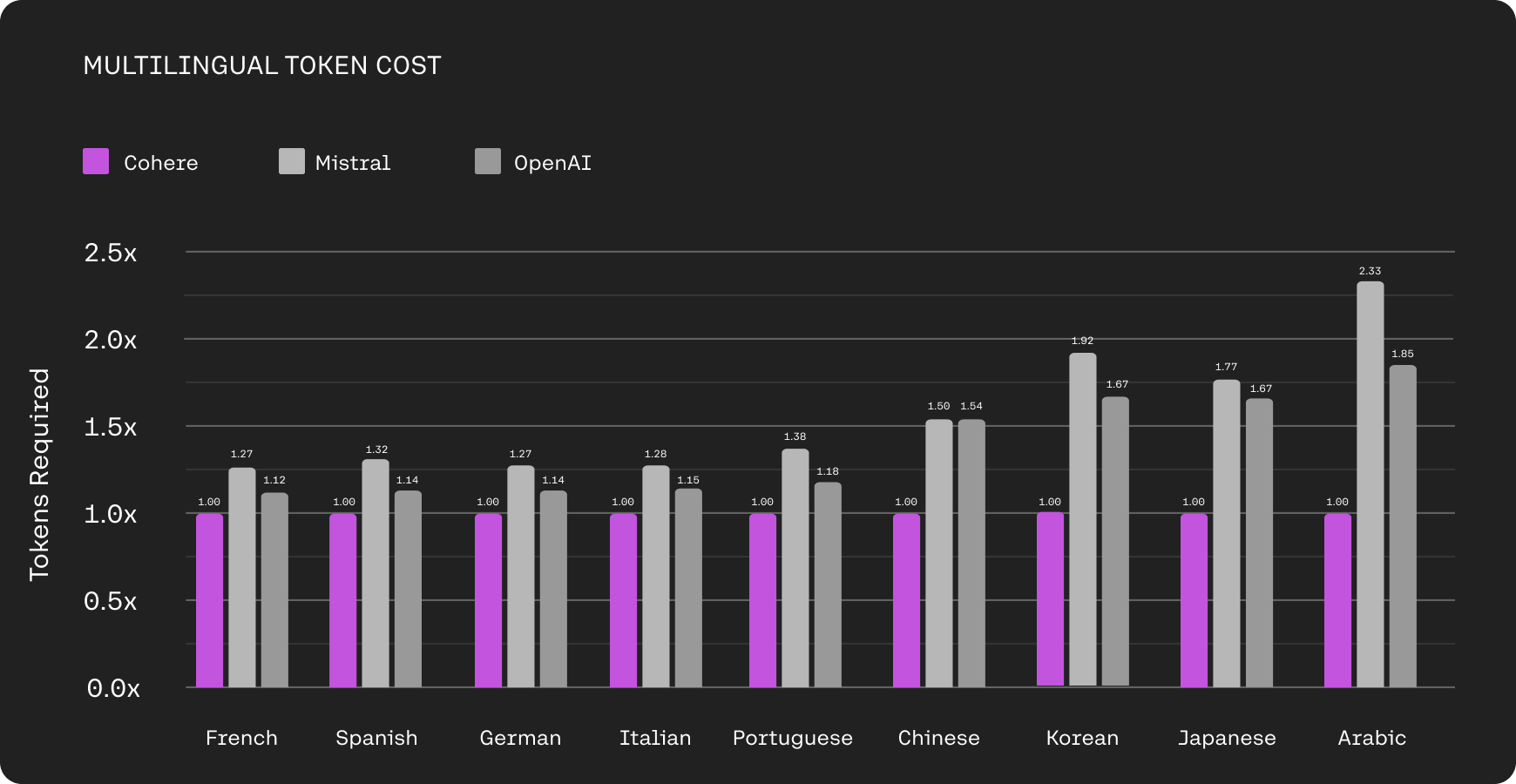
The main focus from Cohere is advanced function calling / tool use, and RAG of course, and this model specializes in those tasks, beating even GPT-4 turbo.

It's clear that Cohere is positioning themselves as RAG leaders as evident by this accompanying tutorial on starting with RAG apps and this model further solidifies their place as the experts in this field. Congrats folks, and thanks for the open weights 🫡
SWE-Agent from Princeton
Folks remember Devin? The super cracked team born agent with a nice UI that got 13% on the SWE-bench a very hard (for LLMs) benchmark that requires solving real world issues?
Well now we have an open source agent that comes very very close to that called SWE-Agent

SWE agent has a dedicated terminal and tools, and utilizes something called ACI (Agent Computer Interface) allowing the agent to navigate, search, and edit code.
The dedicated terminal in a docker environment really helps as evident by a massive 12.3% score on SWE-bench where GPT-4 gets only 1.4%!

Worth mentioning that SWE-bench is a very hard benchmark that was created by the folks who released SWE-agent, and here's some videos of them showing the agent off, this is truly an impressive achievement!
Deepmind publishes Mixture of Depth (arXiv)
Thanks to Hassan who read the paper and wrote a deep dive, this paper by Deepmind shows their research into optimizing model inference. Apparently there's a way to train LLMs without affecting their performance, which later allows to significantly reduce compute on some generated tokens.

🧠 Transformer models currently spread compute uniformly, but Mixture-of-Depths allows models to dynamically allocate compute as needed
💰 Dynamically allocating compute based on difficulty of predicting each token leads to significant compute savings
⏳ Predicting the first token after a period is much harder than within-sentence tokens, so more compute is needed
🗑 Most current compute is wasted since difficulty varies between tokens
We're looking forward to seeing models trained with this, as this seems to be a very big deal in how to optimize inference for LLMs.
Big CO LLMs + APIs
Anthropic and Groq announce function calling / tool use support, Cohere takes it one step further
In yet another example of how OpenAI is leading not only in models, but in developer experience, most models and API providers are now using the same messages API structure.
Back in June of 2023, OpenAI gave us function calling, and finally the industry is aligning to this format, which is now being rebranded as "tool use"
If you're unfamiliar with the concept, tool use allows a developer to specify what tools the model can have in addition to just spitting out tokens, think browsing the web, or using RAG to get more information, or check the weather, or... turn off a lighbulb in your smart home.
The LLM then decides based on user input, if a specific tool needs to be called, responds with the tool and parameters it needs to the developer, and then expects the result of that tool, and finally, is able to respond to the user with the complete information.

So this week we've got Command R, Groq and Anthropic all adding support for tool use, which is incredible for developer experience across the board and will allow developers to move between all those APIs.
Cohere goes one step further with something they call Multi Step tool use, which is a significant step up and is very interesting to explore, as it gives their models the ability to rank and order tool execution, and ovserve their responses.

Anthropic Docs https://docs.anthropic.com/claude/docs/tool-use
Groq Docs https://console.groq.com/docs/tool-use
Cohere Docs https://docs.cohere.com/docs/multi-step-tool-use
Cloudflare AI is now in GA + workers in Python
If you've been following ThursdAI, you know I'm a huge Cloudflare fan. I've built my startup (https://targum.video) on top of Cloudflare workers platform, and I gave them early feedback about having to step into AI in a big way. And they did, with workers AI which is now in GA.
Workers AI lets developers in the Cloudflare ecosystem run LLMs (they mostly feature Opensource LLMs which is incredible), host vectors, run whisper and basically have end to end serverless apps that are powered by AI (they have GPUs in 150 cities around the world)
This week Clouflare announced also the ability to write workers in Python, which was sorely missing for some folks (like me!) who love FastAPI for example, and while it's not a full python environment, the depth to which they had to go in order to allow python to execute on their edge is kind of ridiculous, read up on it here
I'm hoping to work with them to bring weave into the workers for python soon 🤞 because building AI applications with Cloudflare is so simple, they even have a HuggingFace integration which allows you to bring models into your CF environment with 1 click.
This weeks Buzz - SO MUCH BUZZ
Hey, well first of all, I now can offer you a 15% off a ticket to our conference, so use THURSDAI when you checkout and get a ticket here

Now that Weave is out, it's possible to say that our workshop on April 17 (same link as above) is going to be focused on LLM evaluations and yes, I will be talking about how to use weave to build LLM applications in production safely. If this field is new to you, please sign up and come to the workshop!
JAMBA deep dive with Roi @ AI21 and Maxime Labonne
As always, what I cover in this newsletter are only the highlights of what we talked about, but there was so much more, I really recommend you to listen to the episode. This of this weeks episode as 2 episodes (maybe I should re-release the deep dive as a separate episode) because we had a long conversation with Roi Cohen who's a PM @ AI21 and Maxime Labonne (Author of LazyMergeKit and first finetune of JAMBA), it's really worth tuning into that interview. Here's a little snippet:
Aaaand this is it for this week, or you know what? Maybe it's not! I shared this on X but if you don't follow me on X, I decided to prank my whole feed by saying that I'm basically changing careers and becoming a Russian AI DJ, called DJ Thursday and I will only play AI generated music.
The weird thing, how many people were like, yeah ok, this makes sense for you 😅 So here's my April Fools (one of them) joke, hope you enjoy the high quality of these tunes and see you all next week 🫡


