







Hey hey hey (no longer ho ho ho 🎄) hope you had a great Christmas! And you know that many AI folks have dropped tons of OpenSource AI goodies for Christmas, here’s quite a list of new things, including at least 3 new multi-modal models, a dataset and a paper/technical report from the current top model on HF leaderboard from Upstage.
We also had the pleasure to interview the folks who released the Robin suite of multi-modals and aligning them to “good responses” and that full interview is coming to ThursdAI soon so stay tuned.
And we had a full 40 minutes with an open stage to get predictions for 2024 in the world of AI, which we fully intent to cover next year, so scroll all the way down to see ours, and reply/comment with yours!
TL;DR of all topics covered:
Open Source LLMs
Uform - tiny(1B) multimodal embeddings and models that can run on device (HF, Blog, Github, Demo)
Notux 8x7B - one of the first Mixtral DPO fine-tunes - (Thread, Demo)
Upstage SOLAR 10.7B technical report (arXiv, X discussion, followup)
Open Source long context pressure test analysis (Reddit)
Robin - a suite of multi-modal (Vision-Language) models - (Thread, Blogpost, HF)
Big CO LLMs + APIs
AI Art & Diffusion & 3D
Midjourney v6 alpha is really good at recreating scenes from movies (thread)
Open Source LLMs
Open source doesn't stop even during the holiday break! Maybe this is the time to catch up to the big companies? During the holiday periods?
This week we got a new 34B Nous Hermes model, the first DPO fine-tune of Mixtral, Capybara dataset but by far the biggest news of this week was in Multimodality. Apple quietly open sourced ml-ferret, an any to any model able to compete in grounding with even GPT4-V sometimes, Uform released tiny mutli-modal and embeddings versions for on device inference, and AGI collective gave NousHermes 2.5 eyes 👀
There's no doubt that 24' is going to be the year of multimodality, and this week we saw an early start of that right on ThursdAI.
Ml-Ferret from Apple (Github, Weights, Paper)
Apple has been in the open source news lately, as we've covered their MLX release previously and the LLM in a flash paper that discusses inference for low hardware devices, and Apple folks had 1 more gift to give. Ml-Ferret is a multimodal grounding model, based on Vicuna (for some... reason?) which is able to get referrals from images (this highlighted or annotated areas) and then ground the responses with exact coordinates and boxes.
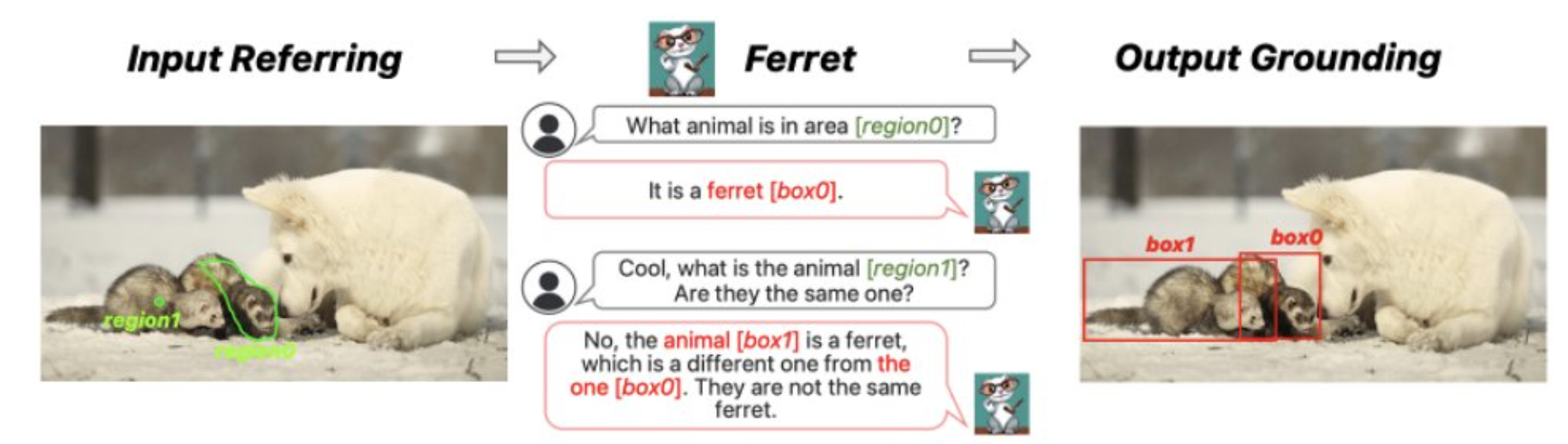
The interesting thing about the referring, is that it can be any shape, bounding box or even irregular shape (like the ferred in the above example or cat tail below)

Ferret was trained on a large new dataset called GRIT containing over 1 million examples of referring to and describing image regions (which wasn't open sourced AFAIK yet)
According to Ariel Lee (our panelist) these weights are only delta weights and need to be combined with Vicuna weights to be able to run the full Ferret model properly.
Uform - tiny (1.5B) MLLMs + vision embeddings (HF, Blog, Github, Demo)
The folks at Unum have released a few gifts for us, with an apache 2.0 license 👏 Specifically they released 3 vision embeddings models, and 2 generative models.
Per the documentation the embeddings can yield 2,3x speedup improvements to search from Clip like models, and 2-4x inference speed improvements given the tiny size. The embeddings have a multi-lingual version as well supporting well over 20 languages.
The generative models can be used for image captioning, and since they are tiny, they are focused on running on device, and are already converted to ONNX format and core-ML format. Seen the results below compared to LLaVa and InstructBLIP, both at the 7B range

I've tried a few images of my own (you can try the demo here), and while there was hallucinations, this tiny model did a surprising amount of understanding for the size!
Also shoutout to Ash
Robin suite of multimodal models (Thread, Blogpost, HF)
The folks at the CERC-AAI lab in MILA-quebec have released a suite of multi-modal models, that they have finetuned and released a fork of NousHermes2.5 that can understand images, building on top of CLIP, and SigLIP as the image encoder.
In fact, we did a full interview with Irina, Kshitij, Alexis and George from the AGI collective, that full interview will be released on ThursdAI soon, so stay tuned, as they had a LOT of knowledge to share, from fine-tuning the clip model itself for better results, to evaluation of multimodal models, to dataset curation/evaluation issues and tips from Irina on how to get a government supercomputer compute grant 😈

Big CO LLMs + APIs
OpenAI is being used by NYT for copyright infringement during training (Lawsuit)
New York times is suing OpenAI and Microsoft for copyright infringement, seeking damages (amount unclear) and removal of NYT data from OpenAI models. The full lawsuit is a worthwhile read, and in includes a whopping 100 pages of examples of GPT4 completing NYT articles verbatim. I personally wasn't able to reproduce this behavior in the chatGPT app, but some folks on X suggested that it's possible in the OpenAI playground, with the right prompt and NYT URL in the prompt.

This lawsuit came after a round of attempted negotiations between NYT and OpenAI, which apparently failed, and it's worth noting a few things. First, OpenAI (with almost every other AI company) have a "Copyright shield" feature, where they protect the user of these services from getting sued for copyright violations. So there is no direct exposure for customers of OpenAI. Additional thing of note is, the NYT information is compiled not by OpenAI directly, rather, OpenAI (and almost every other LLM) have used the CommonCrawl dataset (among others) which did the crawling and collection of text itself.
Per the CommonCrawl license, OpenAI should have reached out to each individual URL in that dataset and worked out the copyright on their own, which is a bit difficult to do, as CommonCrawl includes 3-5 billion pages collected each month.
Regardless of the claims, the hottest takes I saw in regards to this are, that by the time anything moves with this lawsuit, we will be on GPT-6 or so and it won't matter by then, or that OpenAI will have to retrain a model without NYT data, which I find quite ludicrous personally and very unlikely to happen.
If this lawsuit actually sets a precedent, this will IMO be a very bad one for the US, considering other countries like Japan are already getting ahead of this, declaring all scraped data as fair us if used for training (source)
Of course, all of X became IP experts overnight, and the debates are very interesting, some are confusing technical terms, some are claiming that OpenAI will just cave and pay NYT, while some super libertarian ones take it all the way down to: if AI has human rights, and if it does, then preventing it learning from copyright material is like preventing people to read Hemingway.
This weeks buzz (What I learned in WandB this week)
This week, we sent out our annual emails of wrapped cards for everyone who used Weights & Biases to train models this year. This is a yearly tradition, similar to Spotify, however, for ML purposes, and this year the cards were generated with stable diffusion XL, generating hundreds of thousands of images based on autogenerated model run names!

The interesting thing I noticed also, is just how many folks shared their stats screenshots right from the email we send, including not only how many hours they spend training models this year, but also how many other features they used, like reports and sweeps. And I noticed just how many folks don't use reports, which is a shame, as it's such a cool feature! WandB literally has a built in blogging platform for all your ML needs and it includes live widgets of every metric you're tracking in your runs, it's really great.

AI Art & Diffusion
Midjourney v6 is incredible at recreating actual movie stills and scenes (Thread)

Another potential lawsuit is waiting to happen? We already saw lawsuits against StabilityAI for supposed copyright infringement and stability did a lot of work to exclude proprietary art from their training datasets, however, the new incredible version of Midjourney, shows just.. a mind-blowing accuracy in recreating scenes from movies, and cartoon styles. Just look at some of these examples (collected by some folks on X)
This + the above lawsuit news coming for OpenAI & Microsoft from New York Times is setting up 24' to be the year where copyright law and AI finally meet for real. And we'll keep reporting on the outcomes.
Predicitons for 24'
In the last 20 minutes of the pod recording we opened up the floor to folks giving us their predictions for AI developments in the year 2024, and I also asked this question on X itself. The idea was, to come back next year during our yearly summary and see which predictions we hit, and which predictions we were not even remotely thinking about!
Here's a list of predictions with their category (Thanks to AI to help me sort these from different sources and transcription)
Open Source LMs
1GB models with Mix Trail performance levels - Nisten
Continual pretraining and building on top of each other's work - Irina Rish
Smaller models trained on more data - Irina Rish
Consolidation and standardization of models - Irina Rish
Agents running on 7B models with capabilities like web search and code interpretation - Shroominic
End of dominance of transformer architecture - Far El
Marriage of reinforcement learning and language models - Far El
New benchmarking standards - Far El
Plug and play weights for expertise - Umesh
Self-improving pipeline framework - Umesh
Big Companies/APIs
Mistral to become a major player, surpassing companies like Anthropic - Alex Volkov
Apple AI device with multimodal capabilities - Umesh
Google Gemini Pro commoditizing APIs - Umesh
Model that can ace undergrad computer science curriculum - George Adams
Extremely good but expensive model (~$1 per response) - Shroominic
Apple spatial computing + AI product innovation - John Doe
Real-time multilingual translation app/device - Umesh
Vision/Video
AI-generated full length feature film - Umesh
Artist AI model galleries for art generation - Umesh
Real-time video understanding and multimodal models - Alex Volkov
Public release of high quality, fast voice cloning tech - Alex Volkov
3D model/animation generation for video games - tobi
Meta will outperform most companies in video AI and mixed reality - Alex Volkov
Other
Localized national AI models - Ravi
Rise in use of deepfakes - Ravi
Surge in metadata embedding for ownership identification - R.AI.S.E
Advances in AI for biology/healthcare - Ravi, Ash Vardanian
A model capable of completing an undergrad CS curriculum at an A level by the end of the year - George Adams
AI device, fully capable of multimodal capabilities, from Apple - Educated Guess
Development in domain-specific LMs for bio applications, especially in synthetic biology - Ravi
Twitter Prediction
CodeInterpreterAPI V2 - Shroominic
Gemini will NOT outperform ChatGPT - Alex Northstar
Tech slowdown in mass adoption, human creativity as bottleneck - “charles harben”
Biology and Robots - Sinan
Code LLMs near junior developer productivity - Karthik Kannan
Tokenizers will work - Geronimo
LLM curve plateaus, focus on refining and multimodal, OpenAI settles with NYT - hokiepoke
Fully generated, rigged, voiced game characters, minimal human intervention - Rudzinski Maciej
AI affects politics - 𝕄𝕏𝕊ℍℝ🤖
Audio reaches DallE3 level, video and 3D advancements, new cool modality - Darth thromBOOzyt
Synthetic data will be huge - Leo Tronchon
Ok now that our predictions are here, we'll come back here next year and see who hit what predictions!
If you have predicitons if your own, please reply to this email/substack and post them here as well, so we'll have a record 🫡
With that, I want to wish you a happy new year, and as always, see you here next week 👏






